 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Time-Supervised Primary Object Segmentation
Aug 16, 2020
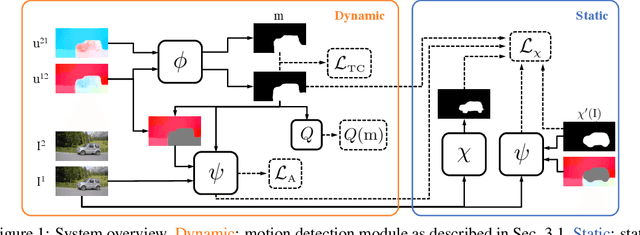



We describe an unsupervised method to detect and segment portions of live scenes that, at some point in time, are seen moving as a coherent whole, which we refer to as primary objects. Our method first segments motions by minimizing the mutual information between partitions of the image domain, which bootstraps a static object detection model that takes a single image as input. The two models are mutually reinforced within a feedback loop, enabling extrapolation to previously unseen classes of objects. Our method requires video for training, but can be used on either static images or videos at inference time. As the volume of our training sets grows, more and more objects are seen moving, thus turning our method into unsupervised (or time-supervised) training to segment primary objects. The resulting system outperforms the state-of-the-art in both video object segmentation and salient object detection benchmarks, even when compared to methods that use explicit manual annotation.
Multiple Infrared Small Targets Detection based on Hierarchical Maximal Entropy Random Walk
Oct 02, 2020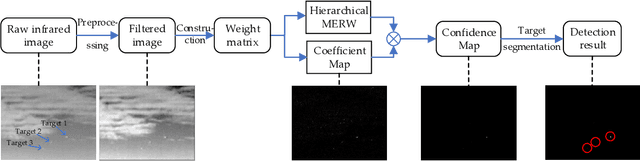

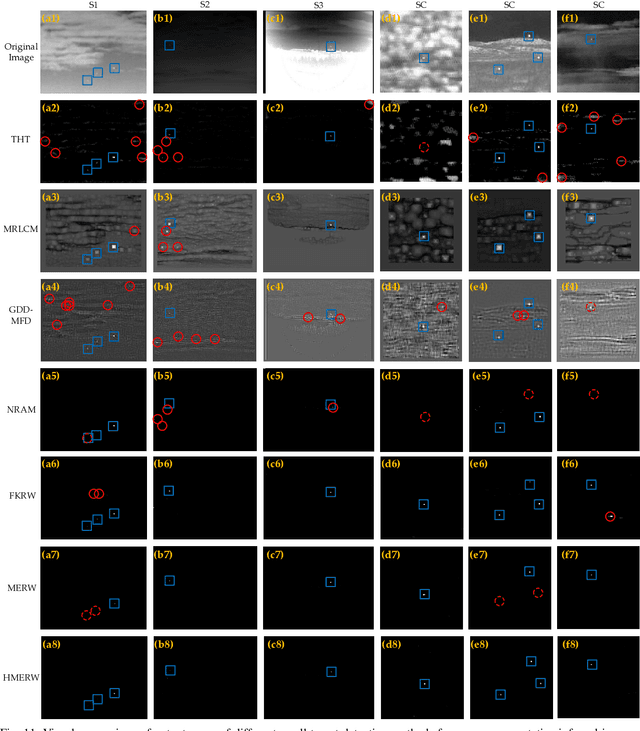
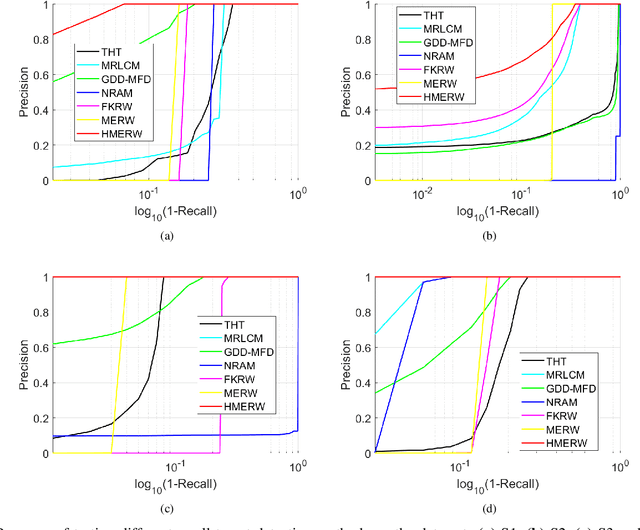
The technique of detecting multiple dim and small targets with low signal-to-clutter ratios (SCR) is very important for infrared search and tracking systems. In this paper, we establish a detection method derived from maximal entropy random walk (MERW) to robustly detect multiple small targets. Initially, we introduce the primal MERW and analyze the feasibility of applying it to small target detection. However, the original weight matrix of the MERW is sensitive to interferences. Therefore, a specific weight matrix is designed for the MERW in principle of enhancing characteristics of small targets and suppressing strong clutters. Moreover, the primal MERW has a critical limitation of strong bias to the most salient small target. To achieve multiple small targets detection, we develop a hierarchical version of the MERW method. Based on the hierarchical MERW (HMERW), we propose a small target detection method as follows. First, filtering technique is used to smooth the infrared image. Second, an output map is obtained by importing the filtered image into the HMERW. Then, a coefficient map is constructed to fuse the stationary dirtribution map of the HMERW. Finally, an adaptive threshold is used to segment multiple small targets from the fusion map. Extensive experiments on practical data sets demonstrate that the proposed method is superior to the state-of-the-art methods in terms of target enhancement, background suppression and multiple small targets detection.
Indexing of CNN Features for Large Scale Image Search
Feb 01, 2018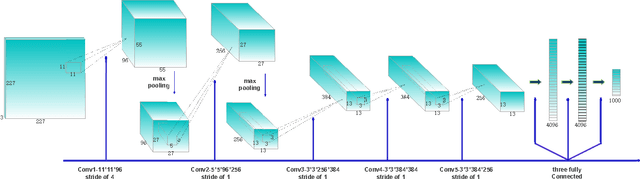
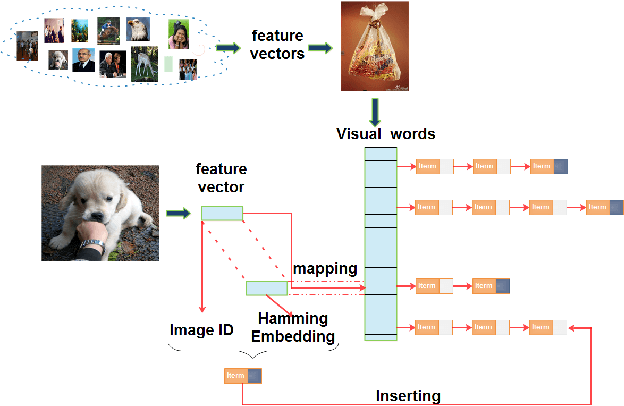
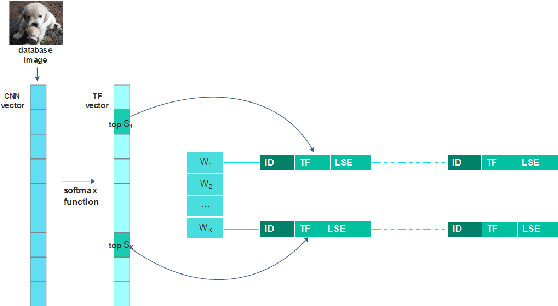
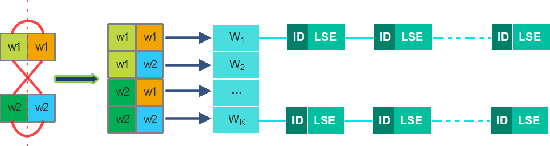
The convolutional neural network (CNN) features can give a good description of image content, which usually represent images with unique global vectors. Although they are compact compared to local descriptors, they still cannot efficiently deal with large-scale image retrieval due to the cost of the linear incremental computation and storage. To address this issue, we build a simple but effective indexing framework based on inverted table, which significantly decreases both the search time and memory usage. In addition, several strategies are fully investigated under an indexing framework to adapt it to CNN features and compensate for quantization errors. First, we use multiple assignment for the query and database images to increase the probability of relevant images' co-existing in the same Voronoi cells obtained via the clustering algorithm. Then, we introduce embedding codes to further improve precision by removing false matches during a search. We demonstrate that by using hashing schemes to calculate the embedding codes and by changing the ranking rule, indexing framework speeds can be greatly improved. Extensive experiments conducted on several unsupervised and supervised benchmarks support these results and the superiority of the proposed indexing framework. We also provide a fair comparison between the popular CNN features.
PyMatting: A Python Library for Alpha Matting
Mar 25, 2020
An important step of many image editing tasks is to extract specific objects from an image in order to place them in a scene of a movie or compose them onto another background. Alpha matting describes the problem of separating the objects in the foreground from the background of an image given only a rough sketch. We introduce the PyMatting package for Python which implements various approaches to solve the alpha matting problem. Our toolbox is also able to extract the foreground of an image given the alpha matte. The implementation aims to be computationally efficient and easy to use. The source code of PyMatting is available under an open-source license at https://github.com/pymatting/pymatting.
A Novel Approach for Image Segmentation based on Histograms computed from Hue-data
Jul 30, 2017
Computer Vision is growing day by day in terms of user specific applications. The first step of any such application is segmenting an image. In this paper, we propose a novel and grass-root level image segmentation algorithm for cases in which the background has uniform color distribution. This algorithm can be used for images of flowers, birds, insects and many more where such background conditions occur. By image segmentation, the visualization of a computer increases manifolds and it can even attain near-human accuracy during classification.
* 4 pages
Support Vector Machine and YOLO for a Mobile Food Grading System
Jan 05, 2021


Food quality and safety are of great concern to society since it is an essential guarantee not only for human health but also for social development, and stability. Ensuring food quality and safety is a complex process. All food processing stages should be considered, from cultivating, harvesting and storage to preparation and consumption. Grading is one of the essential processes to control food quality. This paper proposed a mobile visual-based system to evaluate food grading. Specifically, the proposed system acquires images of bananas when they are on moving conveyors. A two-layer image processing system based on machine learning is used to grade bananas, and these two layers are allocated on edge devices and cloud servers, respectively. Support Vector Machine (SVM) is the first layer to classify bananas based on an extracted feature vector composed of color and texture features. Then, the a You Only Look Once (YOLO) v3 model further locating the peel's defected area and determining if the inputs belong to the mid-ripened or well-ripened class. According to experimental results, the first layer's performance achieved an accuracy of 98.5% while the accuracy of the second layer is 85.7%, and the overall accuracy is 96.4%.
One-Shot Free-View Neural Talking-Head Synthesis for Video Conferencing
Nov 30, 2020
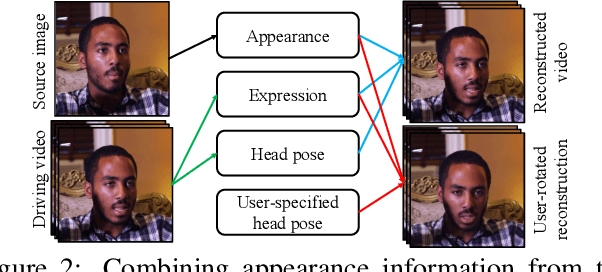

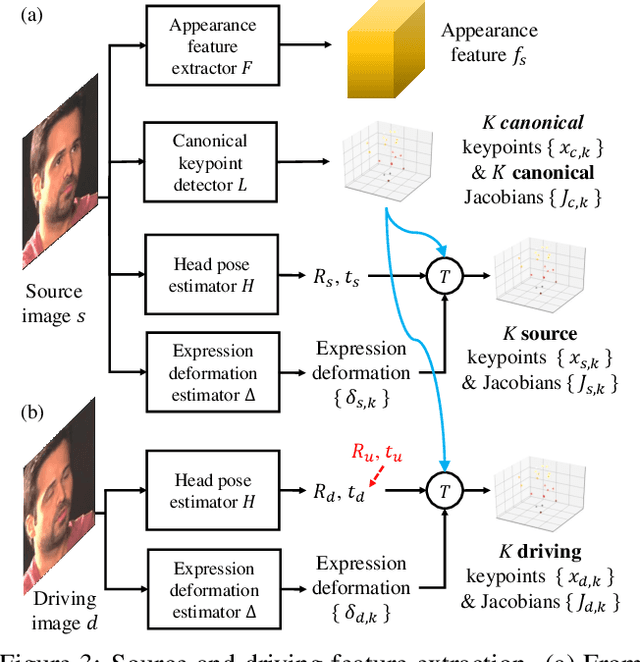
We propose a neural talking-head video synthesis model and demonstrate its application to video conferencing. Our model learns to synthesize a talking-head video using a source image containing the target person's appearance and a driving video that dictates the motion in the output. Our motion is encoded based on a novel keypoint representation, where the identity-specific and motion-related information is decomposed unsupervisedly. Extensive experimental validation shows that our model outperforms competing methods on benchmark datasets. Moreover, our compact keypoint representation enables a video conferencing system that achieves the same visual quality as the commercial H.264 standard while only using one-tenth of the bandwidth. Besides, we show our keypoint representation allows the user to rotate the head during synthesis, which is useful for simulating a face-to-face video conferencing experience.
Rethinking movie genre classification with fine-grained semantic clustering
Dec 07, 2020
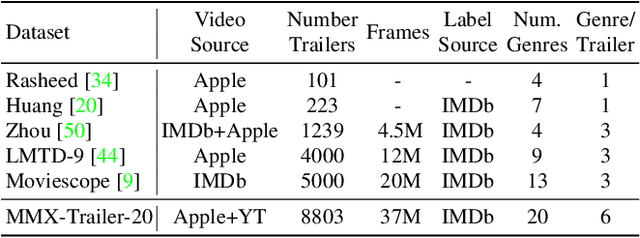
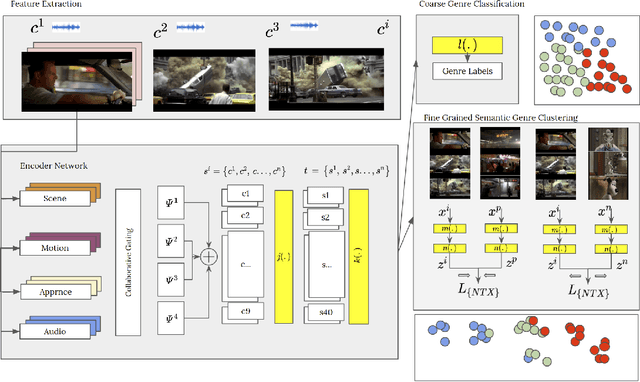
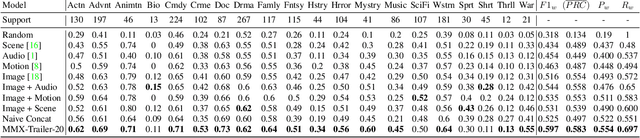
Movie genre classification is an active research area in machine learning. However, due to the limited labels available, there can be large semantic variations between movies within a single genre definition. We expand these 'coarse' genre labels by identifying 'fine-grained' semantic information within the multi-modal content of movies. By leveraging pre-trained 'expert' networks, we learn the influence of different combinations of modes for multi-label genre classification. Using a contrastive loss, we continue to fine-tune this 'coarse' genre classification network to identify high-level intertextual similarities between the movies across all genre labels. This leads to a more 'fine-grained' and detailed clustering, based on semantic similarities while still retaining some genre information. Our approach is demonstrated on a newly introduced multi-modal 37,866,450 frame, 8,800 movie trailer dataset, MMX-Trailer-20, which includes pre-computed audio, location, motion, and image embeddings.
Virtual ID Discovery from E-commerce Media at Alibaba: Exploiting Richness of User Click Behavior for Visual Search Relevance
Feb 09, 2021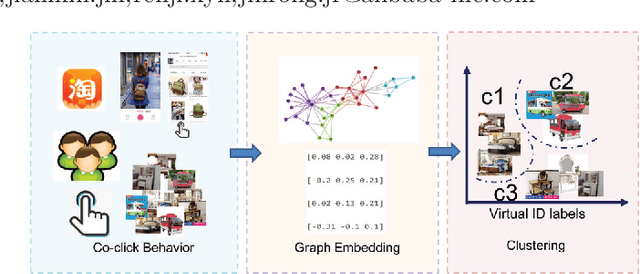

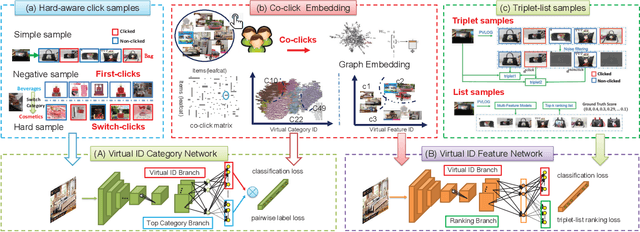
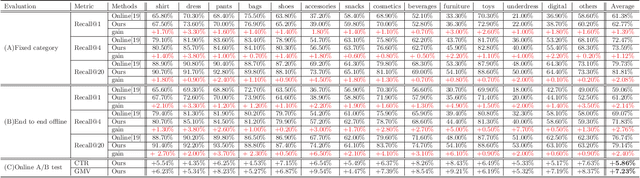
Visual search plays an essential role for E-commerce. To meet the search demands of users and promote shopping experience at Alibaba, visual search relevance of real-shot images is becoming the bottleneck. Traditional visual search paradigm is usually based upon supervised learning with labeled data. However, large-scale categorical labels are required with expensive human annotations, which limits its applicability and also usually fails in distinguishing the real-shot images. In this paper, we propose to discover Virtual ID from user click behavior to improve visual search relevance at Alibaba. As a totally click-data driven approach, we collect various types of click data for training deep networks without any human annotations at all. In particular, Virtual ID are learned as classification supervision with co-click embedding, which explores image relationship from user co-click behaviors to guide category prediction and feature learning. Concretely, we deploy Virtual ID Category Network by integrating first-clicks and switch-clicks as regularizer. Incorporating triplets and list constraints, Virtual ID Feature Network is trained in a joint classification and ranking manner. Benefiting from exploration of user click data, our networks are more effective to encode richer supervision and better distinguish real-shot images in terms of category and feature. To validate our method for visual search relevance, we conduct an extensive set of offline and online experiments on the collected real-shot images. We consistently achieve better experimental results across all components, compared with alternative and state-of-the-art methods.
* accepted by CIKM 2019
VisualWordGrid: Information Extraction From Scanned Documents Using A Multimodal Approach
Oct 13, 2020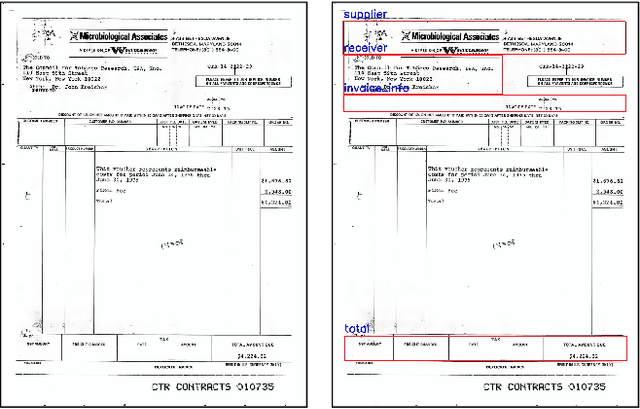

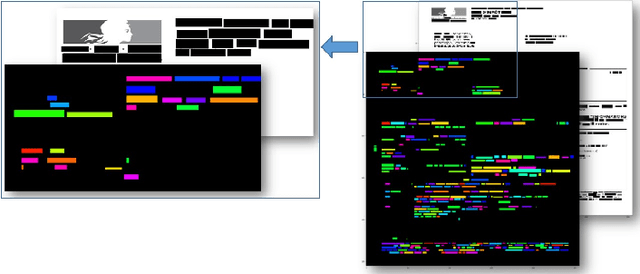
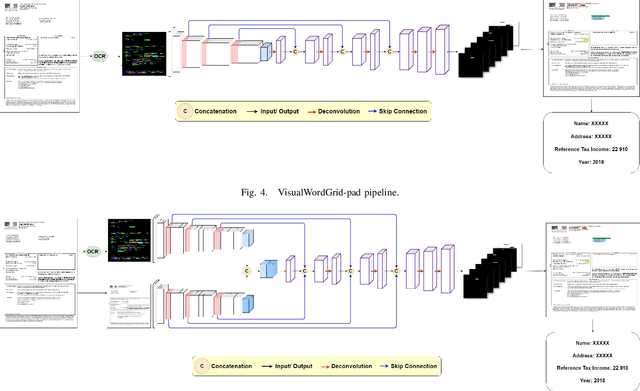
We introduce a novel approach for scanned document representation to perform field extraction. It allows the simultaneous encoding of the textual, visual and layout information in a 3D matrix used as an input to a segmentation model. We improve the recent Chargrid and Wordgrid models in several ways, first by taking into account the visual modality, then by boosting its robustness in regards to small datasets while keeping the inference time low. Our approach is tested on public and private document-image datasets, showing higher performances compared to the recent state-of-the-art methods.