 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Face morphing detection in the presence of printing/scanning and heterogeneous image sources
Jan 25, 2019
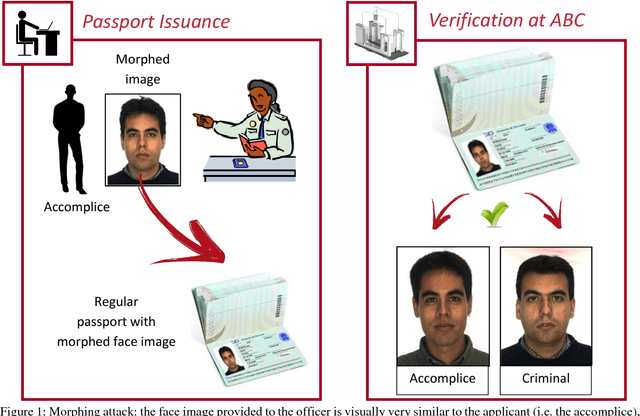

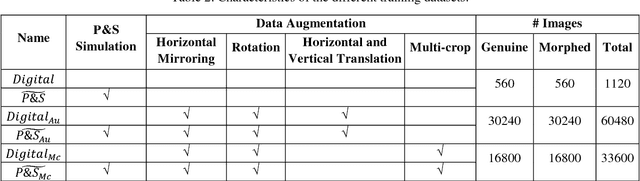

Face morphing represents nowadays a big security threat in the context of electronic identity documents as well as an interesting challenge for researchers in the field of face recognition. Despite of the good performance obtained by state-of-the-art approaches on digital images, no satisfactory solutions have been identified so far to deal with cross-database testing and printed-scanned images (typically used in many countries for document issuing). In this work, novel approaches are proposed to train Deep Neural Networks for morphing detection: in particular generation of simulated printed-scanned images together with other data augmentation strategies and pre-training on large face recognition datasets, allowed to reach state-of-the-art accuracy on challenging datasets from heterogeneous image sources.
End-to-end Learning of Image based Lane-Change Decision
Jun 26, 2017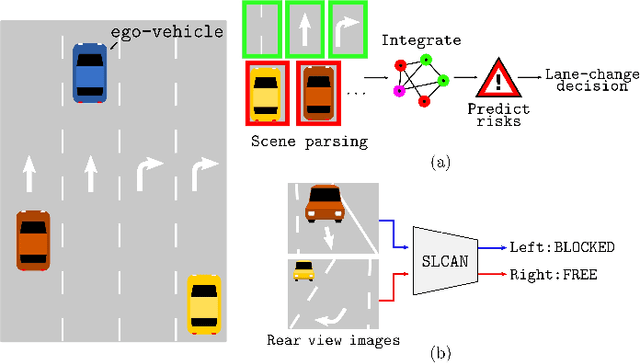
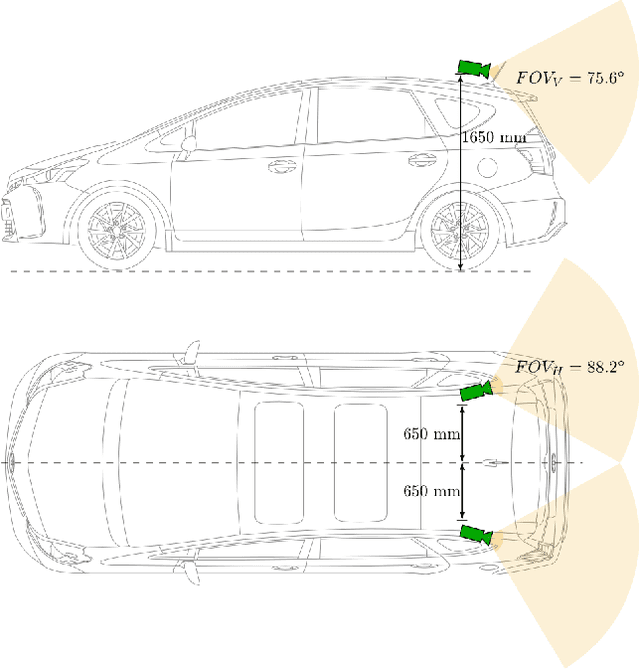

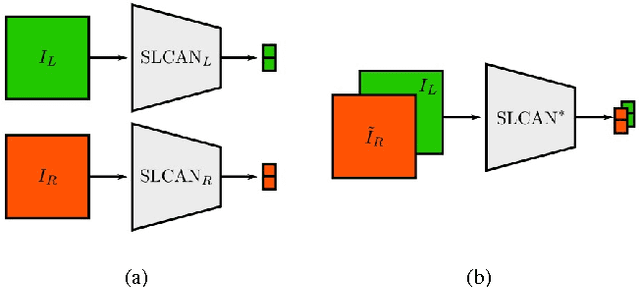
We propose an image based end-to-end learning framework that helps lane-change decisions for human drivers and autonomous vehicles. The proposed system, Safe Lane-Change Aid Network (SLCAN), trains a deep convolutional neural network to classify the status of adjacent lanes from rear view images acquired by cameras mounted on both sides of the vehicle. Rather than depending on any explicit object detection or tracking scheme, SLCAN reads the whole input image and directly decides whether initiation of the lane-change at the moment is safe or not. We collected and annotated 77,273 rear side view images to train and test SLCAN. Experimental results show that the proposed framework achieves 96.98% classification accuracy although the test images are from unseen roadways. We also visualize the saliency map to understand which part of image SLCAN looks at for correct decisions.
Improved Multi-Source Domain Adaptation by Preservation of Factors
Oct 16, 2020

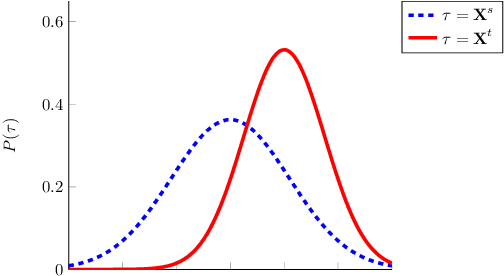
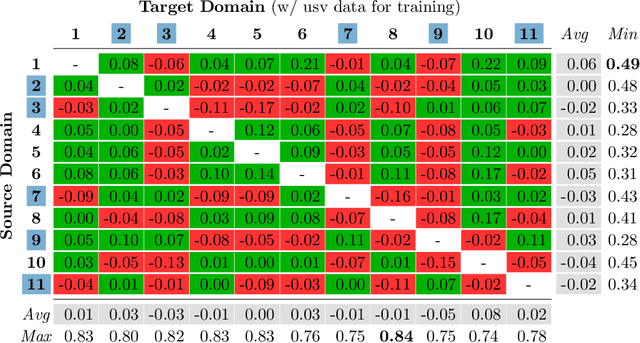
Domain Adaptation (DA) is a highly relevant research topic when it comes to image classification with deep neural networks. Combining multiple source domains in a sophisticated way to optimize a classification model can improve the generalization to a target domain. Here, the difference in data distributions of source and target image datasets plays a major role. In this paper, we describe based on a theory of visual factors how real-world scenes appear in images in general and how recent DA datasets are composed of such. We show that different domains can be described by a set of so called domain factors, whose values are consistent within a domain, but can change across domains. Many DA approaches try to remove all domain factors from the feature representation to be domain invariant. In this paper we show that this can lead to negative transfer since task-informative factors can get lost as well. To address this, we propose Factor-Preserving DA (FP-DA), a method to train a deep adversarial unsupervised DA model, which is able to preserve specific task relevant factors in a multi-domain scenario. We demonstrate on CORe50, a dataset with many domains, how such factors can be identified by standard one-to-one transfer experiments between single domains combined with PCA. By applying FP-DA, we show that the highest average and minimum performance can be achieved.
Unsupervised Discovery of Disentangled Manifolds in GANs
Nov 29, 2020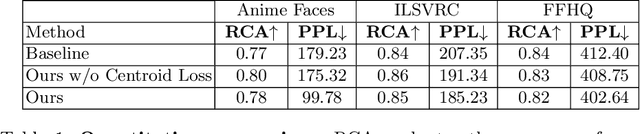
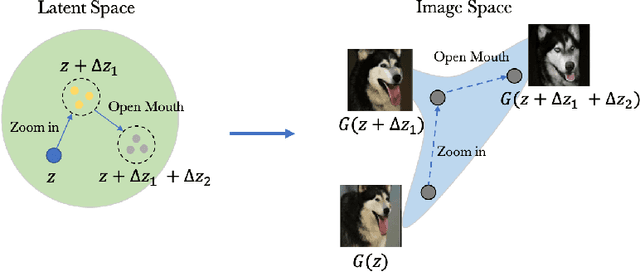
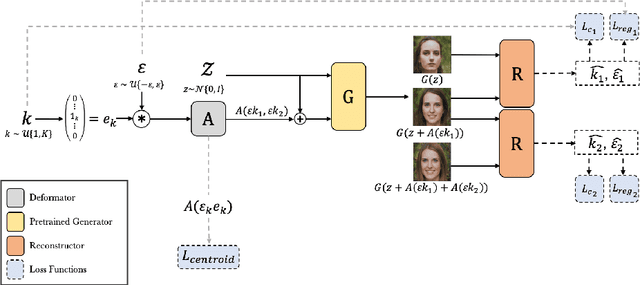

As recent generative models can generate photo-realistic images, people seek to understand the mechanism behind the generation process. Interpretable generation process is beneficial to various image editing applications. In this work, we propose a framework to discover interpretable directions in the latent space given arbitrary pre-trained generative adversarial networks. We propose to learn the transformation from prior one-hot vectors representing different attributes to the latent space used by pre-trained models. Furthermore, we apply a centroid loss function to improve consistency and smoothness while traversing through different directions. We demonstrate the efficacy of the proposed framework on a wide range of datasets. The discovered direction vectors are shown to be visually corresponding to various distinct attributes and thus enable attribute editing.
GIFnets: Differentiable GIF Encoding Framework
Jun 24, 2020
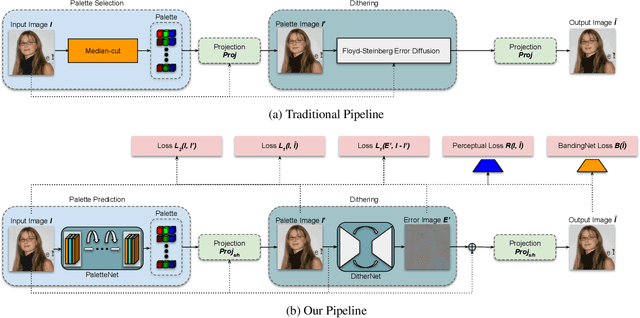
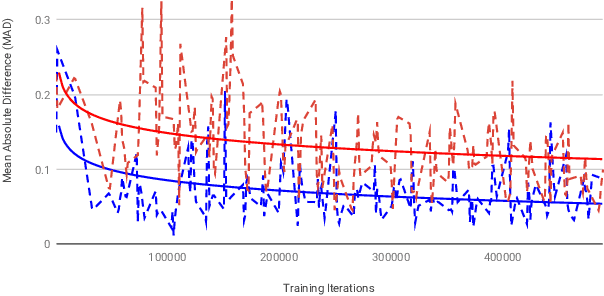
Graphics Interchange Format (GIF) is a widely used image file format. Due to the limited number of palette colors, GIF encoding often introduces color banding artifacts. Traditionally, dithering is applied to reduce color banding, but introducing dotted-pattern artifacts. To reduce artifacts and provide a better and more efficient GIF encoding, we introduce a differentiable GIF encoding pipeline, which includes three novel neural networks: PaletteNet, DitherNet, and BandingNet. Each of these three networks provides an important functionality within the GIF encoding pipeline. PaletteNet predicts a near-optimal color palette given an input image. DitherNet manipulates the input image to reduce color banding artifacts and provides an alternative to traditional dithering. Finally, BandingNet is designed to detect color banding, and provides a new perceptual loss specifically for GIF images. As far as we know, this is the first fully differentiable GIF encoding pipeline based on deep neural networks and compatible with existing GIF decoders. User study shows that our algorithm is better than Floyd-Steinberg based GIF encoding.
Who Will Share My Image? Predicting the Content Diffusion Path in Online Social Networks
Nov 29, 2017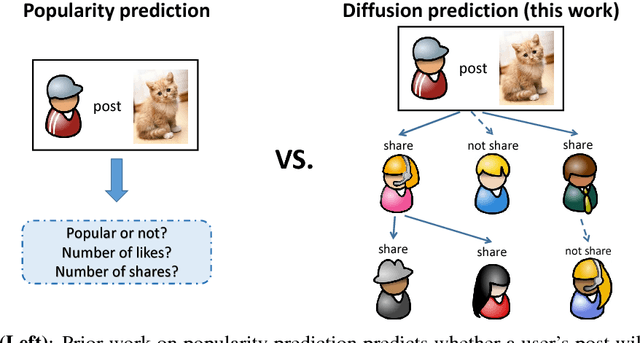



Content popularity prediction has been extensively studied due to its importance and interest for both users and hosts of social media sites like Facebook, Instagram, Twitter, and Pinterest. However, existing work mainly focuses on modeling popularity using a single metric such as the total number of likes or shares. In this work, we propose Diffusion-LSTM, a memory-based deep recurrent network that learns to recursively predict the entire diffusion path of an image through a social network. By combining user social features and image features, and encoding the diffusion path taken thus far with an explicit memory cell, our model predicts the diffusion path of an image more accurately compared to alternate baselines that either encode only image or social features, or lack memory. By mapping individual users to user prototypes, our model can generalize to new users not seen during training. Finally, we demonstrate our model's capability of generating diffusion trees, and show that the generated trees closely resemble ground-truth trees.
Deep reinforcement learning for portfolio management
Dec 26, 2020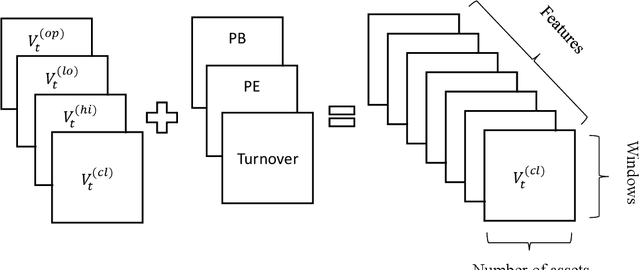
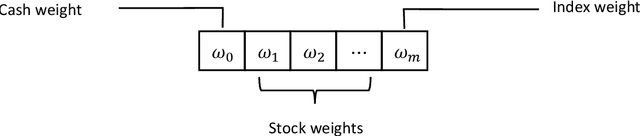
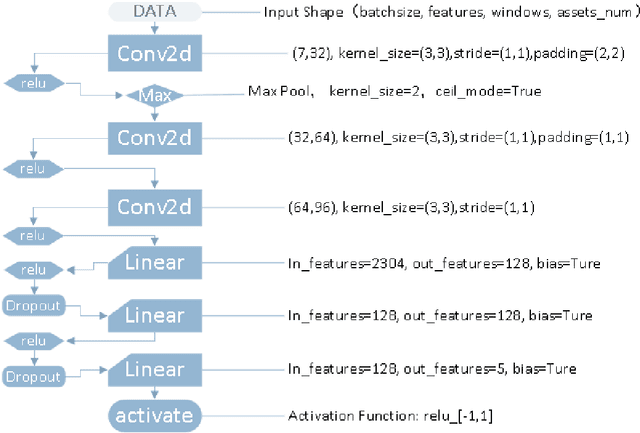

The objective of this paper is to verify that current cutting-edge artificial intelligence technology, deep reinforcement learning, can be applied to portfolio management. We improve on the existing Deep Reinforcement Learning Portfolio model and make many innovations. Unlike many previous studies on discrete trading signals in portfolio management, we make the agent to short in a continuous action space, design an arbitrage mechanism based on Arbitrage Pricing Theory,and redesign the activation function for acquiring action vectors, in addition, we redesign neural networks for reinforcement learning with reference to deep neural networks that process image data. In experiments, we use our model in several randomly selected portfolios which include CSI300 that represents the market's rate of return and the randomly selected constituents of CSI500. The experimental results show that no matter what stocks we select in our portfolios, we can almost get a higher return than the market itself. That is to say, we can defeat market by using deep reinforcement learning.
Generative Image Modeling Using Spatial LSTMs
Sep 18, 2015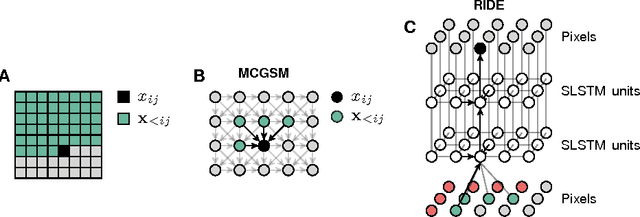
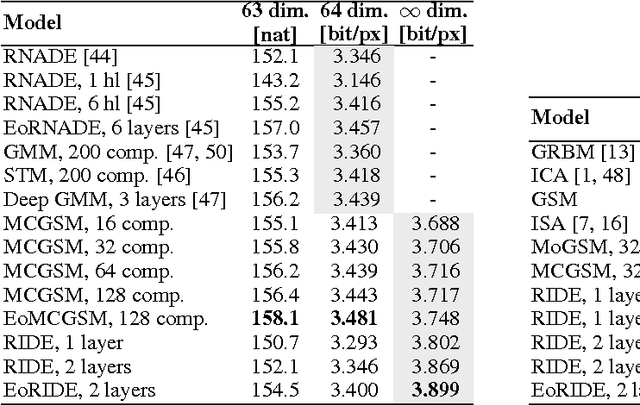
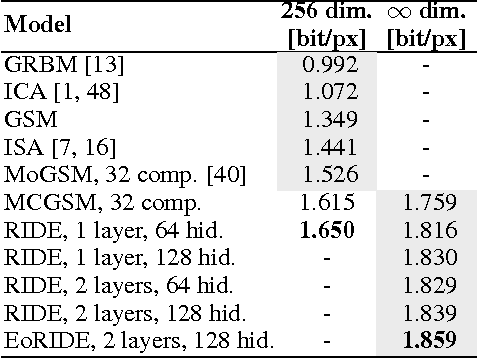
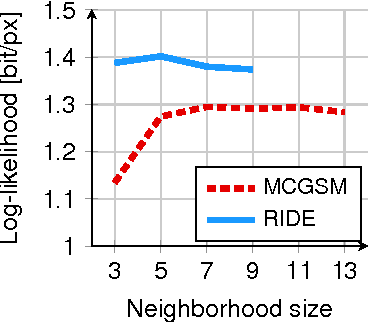
Modeling the distribution of natural images is challenging, partly because of strong statistical dependencies which can extend over hundreds of pixels. Recurrent neural networks have been successful in capturing long-range dependencies in a number of problems but only recently have found their way into generative image models. We here introduce a recurrent image model based on multi-dimensional long short-term memory units which are particularly suited for image modeling due to their spatial structure. Our model scales to images of arbitrary size and its likelihood is computationally tractable. We find that it outperforms the state of the art in quantitative comparisons on several image datasets and produces promising results when used for texture synthesis and inpainting.
Pyramidal Convolution: Rethinking Convolutional Neural Networks for Visual Recognition
Jun 20, 2020
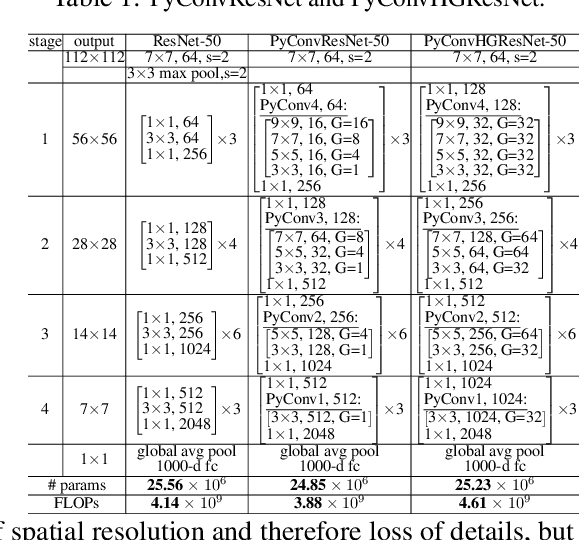
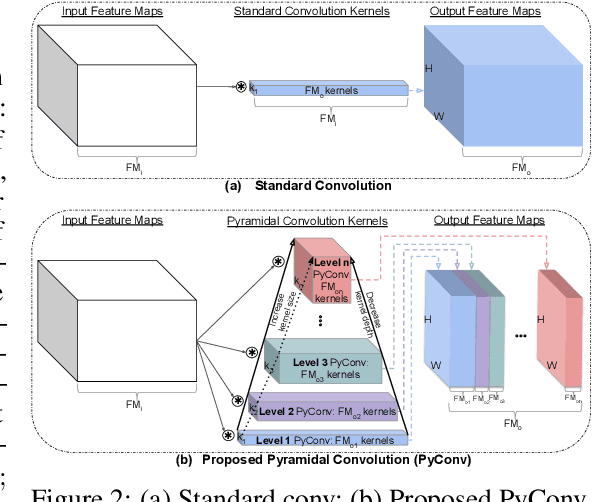

This work introduces pyramidal convolution (PyConv), which is capable of processing the input at multiple filter scales. PyConv contains a pyramid of kernels, where each level involves different types of filters with varying size and depth, which are able to capture different levels of details in the scene. On top of these improved recognition capabilities, PyConv is also efficient and, with our formulation, it does not increase the computational cost and parameters compared to standard convolution. Moreover, it is very flexible and extensible, providing a large space of potential network architectures for different applications. PyConv has the potential to impact nearly every computer vision task and, in this work, we present different architectures based on PyConv for four main tasks on visual recognition: image classification, video action classification/recognition, object detection and semantic image segmentation/parsing. Our approach shows significant improvements over all these core tasks in comparison with the baselines. For instance, on image recognition, our 50-layers network outperforms in terms of recognition performance on ImageNet dataset its counterpart baseline ResNet with 152 layers, while having 2.39 times less parameters, 2.52 times lower computational complexity and more than 3 times less layers. On image segmentation, our novel framework sets a new state-of-the-art on the challenging ADE20K benchmark for scene parsing. Code is available at: https://github.com/iduta/pyconv
Stochastic Segmentation Networks: Modelling Spatially Correlated Aleatoric Uncertainty
Jun 10, 2020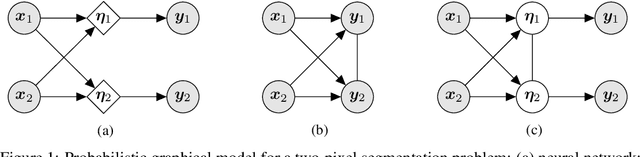
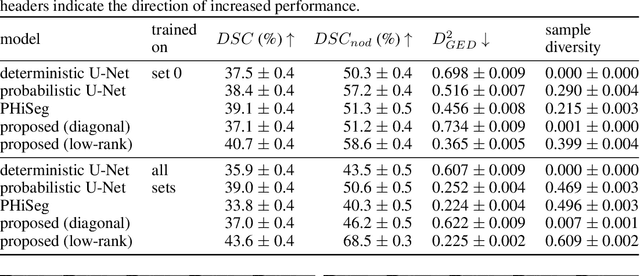

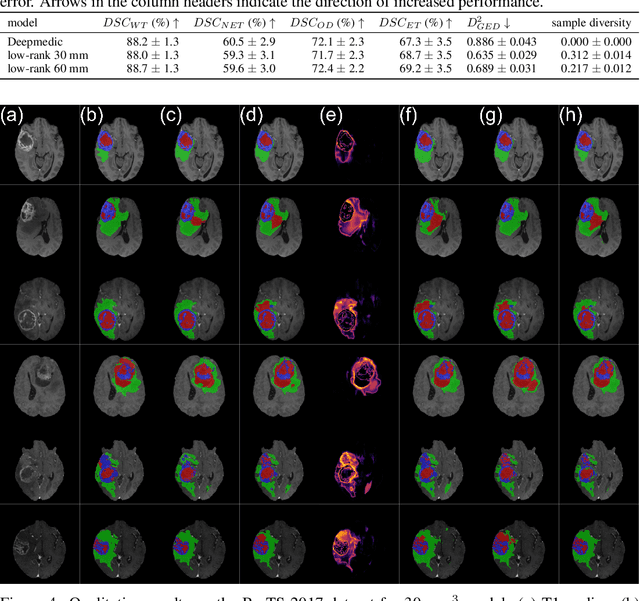
In image segmentation, there is often more than one plausible solution for a given input. In medical imaging, for example, experts will often disagree about the exact location of object boundaries. Estimating this inherent uncertainty and predicting multiple plausible hypotheses is of great interest in many applications, yet this ability is lacking in most current deep learning methods. In this paper, we introduce stochastic segmentation networks (SSNs), an efficient probabilistic method for modelling aleatoric uncertainty with any image segmentation network architecture. In contrast to approaches that produce pixel-wise estimates, SSNs model joint distributions over entire label maps and thus can generate multiple spatially coherent hypotheses for a single image. By using a low-rank multivariate normal distribution over the logit space to model the probability of the label map given the image, we obtain a spatially consistent probability distribution that can be efficiently computed by a neural network without any changes to the underlying architecture. We tested our method on the segmentation of real-world medical data, including lung nodules in 2D CT and brain tumours in 3D multimodal MRI scans. SSNs outperform state-of-the-art for modelling correlated uncertainty in ambiguous images while being much simpler, more flexible, and more efficient.