 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Review of Visual Descriptors and Classification Techniques Used in Leaf Species Identification
Sep 13, 2020

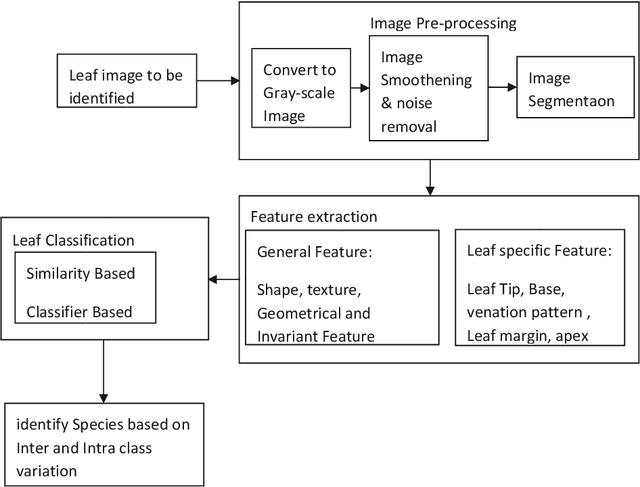
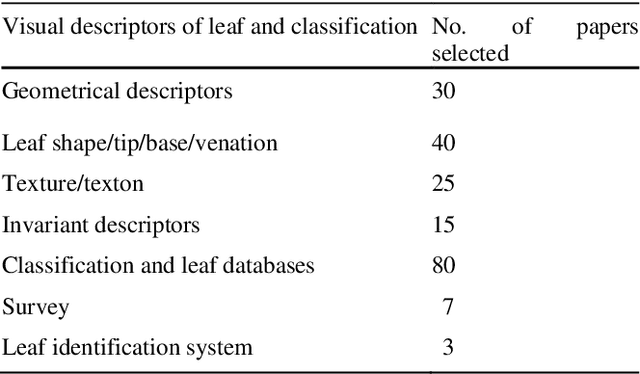
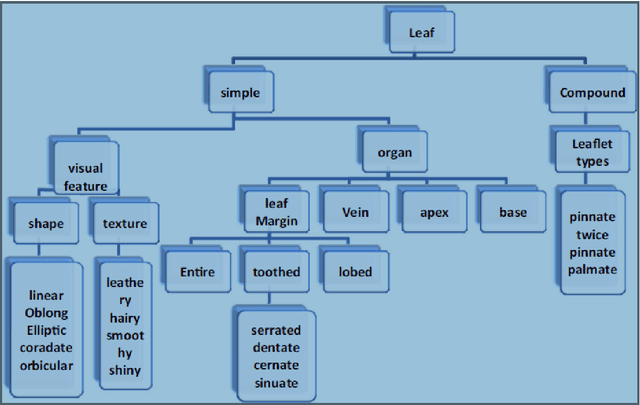
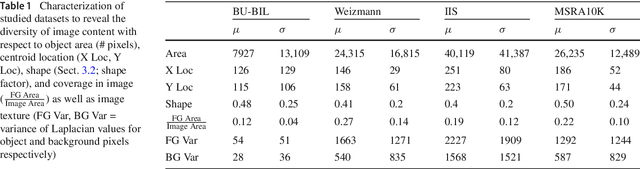
Plants are fundamentally important to life. Key research areas in plant science include plant species identification, weed classification using hyper spectral images, monitoring plant health and tracing leaf growth, and the semantic interpretation of leaf information. Botanists easily identify plant species by discriminating between the shape of the leaf, tip, base, leaf margin and leaf vein, as well as the texture of the leaf and the arrangement of leaflets of compound leaves. Because of the increasing demand for experts and calls for biodiversity, there is a need for intelligent systems that recognize and characterize leaves so as to scrutinize a particular species, the diseases that affect them, the pattern of leaf growth, and so on. We review several image processing methods in the feature extraction of leaves, given that feature extraction is a crucial technique in computer vision. As computers cannot comprehend images, they are required to be converted into features by individually analysing image shapes, colours, textures and moments. Images that look the same may deviate in terms of geometric and photometric variations. In our study, we also discuss certain machine learning classifiers for an analysis of different species of leaves.
* 44 pages, 7 figures, "for final published version, see https://link.springer.com/article/10.1007/s11831-018-9266-3"
Unconstrained Matching of 2D and 3D Descriptors for 6-DOF Pose Estimation
May 29, 2020


This paper proposes a novel concept to directly match feature descriptors extracted from 2D images with feature descriptors extracted from 3D point clouds. We use this concept to directly localize images in a 3D point cloud. We generate a dataset of matching 2D and 3D points and their corresponding feature descriptors, which is used to learn a Descriptor-Matcher classifier. To localize the pose of an image at test time, we extract keypoints and feature descriptors from the query image. The trained Descriptor-Matcher is then used to match the features from the image and the point cloud. The locations of the matched features are used in a robust pose estimation algorithm to predict the location and orientation of the query image. We carried out an extensive evaluation of the proposed method for indoor and outdoor scenarios and with different types of point clouds to verify the feasibility of our approach. Experimental results demonstrate that direct matching of feature descriptors from images and point clouds is not only a viable idea but can also be reliably used to estimate the 6-DOF poses of query cameras in any type of 3D point cloud in an unconstrained manner with high precision.
Where to drive: free space detection with one fisheye camera
Nov 11, 2020The development in the field of autonomous driving goes hand in hand with ever new developments in the field of image processing and machine learning methods. In order to fully exploit the advantages of deep learning, it is necessary to have sufficient labeled training data available. This is especially not the case for omnidirectional fisheye cameras. As a solution, we propose in this paper to use synthetic training data based on Unity3D. A five-pass algorithm is used to create a virtual fisheye camera. This synthetic training data is evaluated for the application of free space detection for different deep learning network architectures. The results indicate that synthetic fisheye images can be used in deep learning context.
* Accepted at International Conference on Machine Vision 2019 (ICMV 2019)
What Do Deep Nets Learn? Class-wise Patterns Revealed in the Input Space
Jan 18, 2021
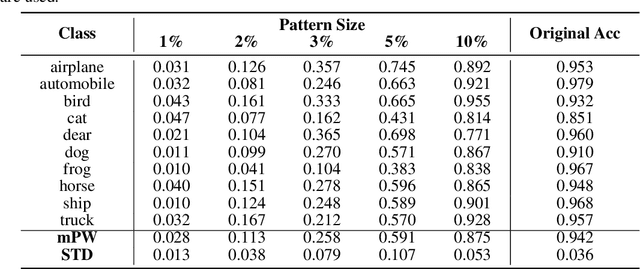

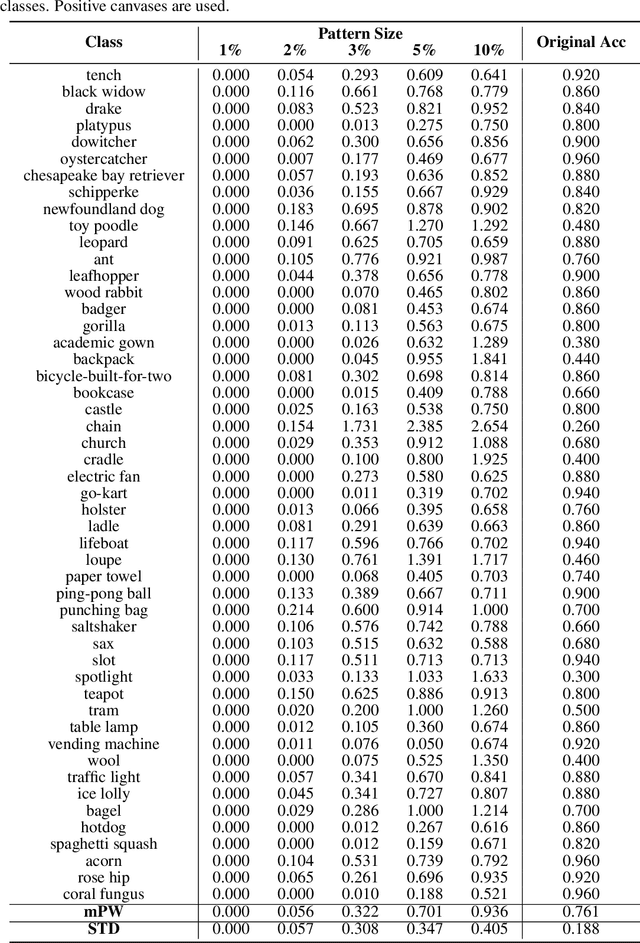
Deep neural networks (DNNs) have been widely adopted in different applications to achieve state-of-the-art performance. However, they are often applied as a black box with limited understanding of what the model has learned from the data. In this paper, we focus on image classification and propose a method to visualize and understand the class-wise patterns learned by DNNs trained under three different settings including natural, backdoored and adversarial. Different from existing class-wise deep representation visualizations, our method searches for a single predictive pattern in the input (i.e. pixel) space for each class. Based on the proposed method, we show that DNNs trained on natural (clean) data learn abstract shapes along with some texture, and backdoored models learn a small but highly predictive pattern for the backdoor target class. Interestingly, the existence of class-wise predictive patterns in the input space indicates that even DNNs trained on clean data can have backdoors, and the class-wise patterns identified by our method can be readily applied to "backdoor" attack the model. In the adversarial setting, we show that adversarially trained models learn more simplified shape patterns. Our method can serve as a useful tool to better understand DNNs trained on different datasets under different settings.
MakeupBag: Disentangling Makeup Extraction and Application
Dec 03, 2020
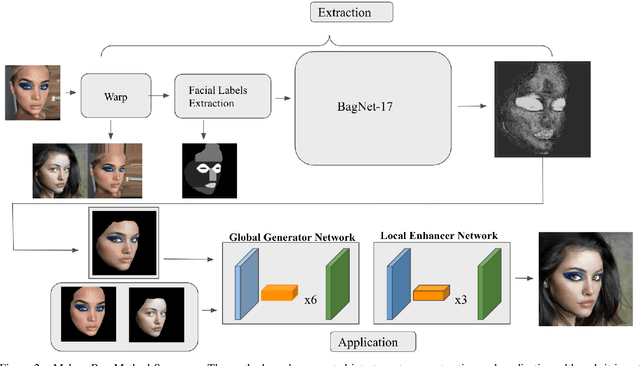


This paper introduces MakeupBag, a novel method for automatic makeup style transfer. Our proposed technique can transfer a new makeup style from a reference face image to another previously unseen facial photograph. We solve makeup disentanglement and facial makeup application as separable objectives, in contrast to other current deep methods that entangle the two tasks. MakeupBag presents a significant advantage for our approach as it allows customization and pixel specific modification of the extracted makeup style, which is not possible using current methods. Extensive experiments, both qualitative and numerical, are conducted demonstrating the high quality and accuracy of the images produced by our method. Furthermore, in contrast to most other current methods, MakeupBag tackles both classical and extreme and costume makeup transfer. In a comparative analysis, MakeupBag is shown to outperform current state-of-the-art approaches.
DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs
Dec 20, 2017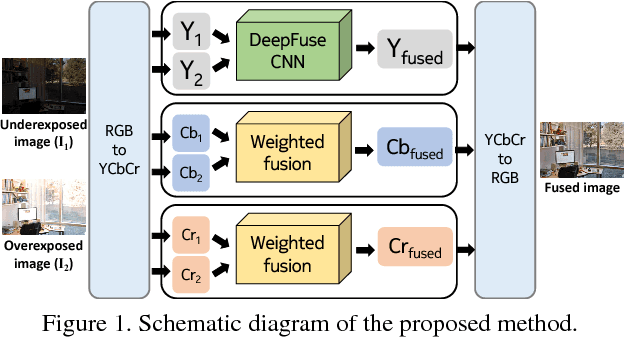
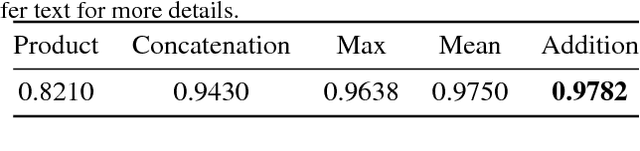
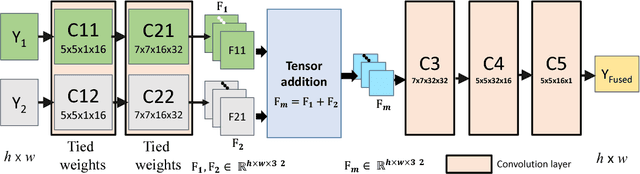
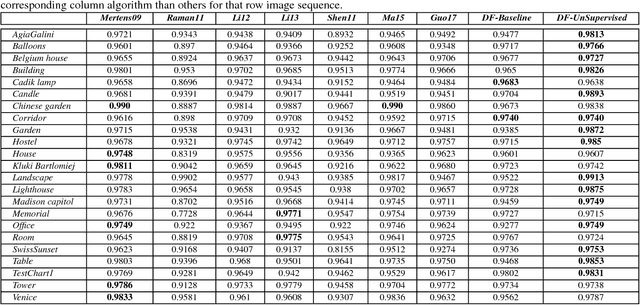
We present a novel deep learning architecture for fusing static multi-exposure images. Current multi-exposure fusion (MEF) approaches use hand-crafted features to fuse input sequence. However, the weak hand-crafted representations are not robust to varying input conditions. Moreover, they perform poorly for extreme exposure image pairs. Thus, it is highly desirable to have a method that is robust to varying input conditions and capable of handling extreme exposure without artifacts. Deep representations have known to be robust to input conditions and have shown phenomenal performance in a supervised setting. However, the stumbling block in using deep learning for MEF was the lack of sufficient training data and an oracle to provide the ground-truth for supervision. To address the above issues, we have gathered a large dataset of multi-exposure image stacks for training and to circumvent the need for ground truth images, we propose an unsupervised deep learning framework for MEF utilizing a no-reference quality metric as loss function. The proposed approach uses a novel CNN architecture trained to learn the fusion operation without reference ground truth image. The model fuses a set of common low level features extracted from each image to generate artifact-free perceptually pleasing results. We perform extensive quantitative and qualitative evaluation and show that the proposed technique outperforms existing state-of-the-art approaches for a variety of natural images.
Learning Geometry-Disentangled Representation for Complementary Understanding of 3D Object Point Cloud
Jan 08, 2021



In 2D image processing, some attempts decompose images into high and low frequency components for describing edge and smooth parts respectively. Similarly, the contour and flat area of 3D objects, such as the boundary and seat area of a chair, describe different but also complementary geometries. However, such investigation is lost in previous deep networks that understand point clouds by directly treating all points or local patches equally. To solve this problem, we propose Geometry-Disentangled Attention Network (GDANet). GDANet introduces Geometry-Disentangle Module to dynamically disentangle point clouds into the contour and flat part of 3D objects, respectively denoted by sharp and gentle variation components. Then GDANet exploits Sharp-Gentle Complementary Attention Module that regards the features from sharp and gentle variation components as two holistic representations, and pays different attentions to them while fusing them respectively with original point cloud features. In this way, our method captures and refines the holistic and complementary 3D geometric semantics from two distinct disentangled components to supplement the local information. Extensive experiments on 3D object classification and segmentation benchmarks demonstrate that GDANet achieves the state-of-the-arts with fewer parameters.
Predicting How to Distribute Work Between Algorithms and Humans to Segment an Image Batch
Apr 30, 2019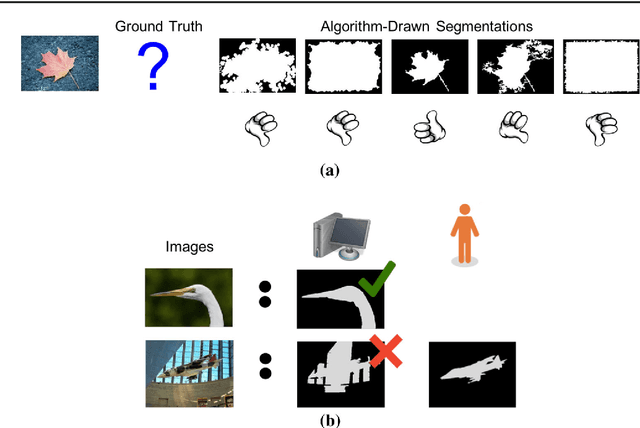
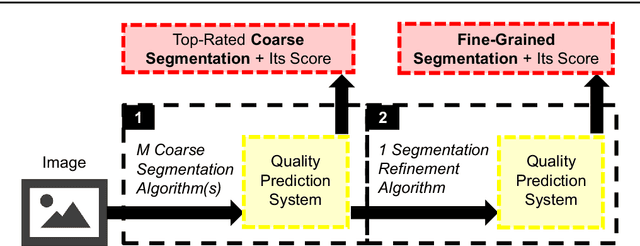

Foreground object segmentation is a critical step for many image analysis tasks. While automated methods can produce high-quality results, their failures disappoint users in need of practical solutions. We propose a resource allocation framework for predicting how best to allocate a fixed budget of human annotation effort in order to collect higher quality segmentations for a given batch of images and automated methods. The framework is based on a prediction module that estimates the quality of given algorithm-drawn segmentations. We demonstrate the value of the framework for two novel tasks related to predicting how to distribute annotation efforts between algorithms and humans. Specifically, we develop two systems that automatically decide, for a batch of images, when to recruit humans versus computers to create 1) coarse segmentations required to initialize segmentation tools and 2) final, fine-grained segmentations. Experiments demonstrate the advantage of relying on a mix of human and computer efforts over relying on either resource alone for segmenting objects in images coming from three diverse modalities (visible, phase contrast microscopy, and fluorescence microscopy).
Robust RGB-based 6-DoF Pose Estimation without Real Pose Annotations
Aug 19, 2020
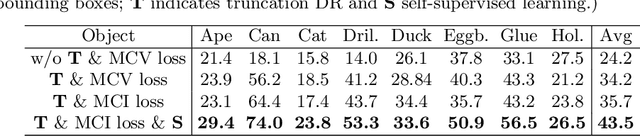
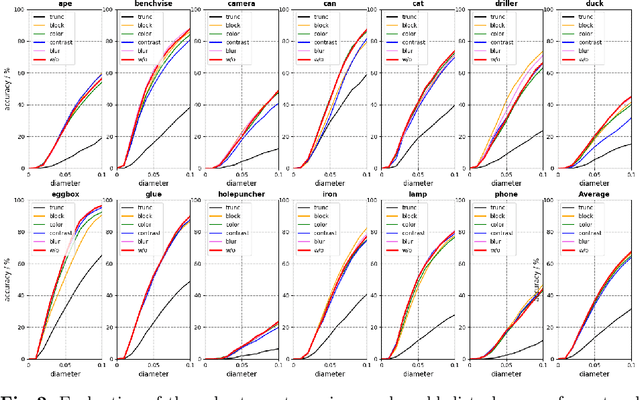

While much progress has been made in 6-DoF object pose estimation from a single RGB image, the current leading approaches heavily rely on real-annotation data. As such, they remain sensitive to severe occlusions, because covering all possible occlusions with annotated data is intractable. In this paper, we introduce an approach to robustly and accurately estimate the 6-DoF pose in challenging conditions and without using any real pose annotations. To this end, we leverage the intuition that the poses predicted by a network from an image and from its counterpart synthetically altered to mimic occlusion should be consistent, and translate this to a self-supervised loss function. Our experiments on LINEMOD, Occluded-LINEMOD, YCB and new Randomization LINEMOD dataset evidence the robustness of our approach. We achieve state of the art performance on LINEMOD, and OccludedLINEMOD in without real-pose setting, even outperforming methods that rely on real annotations during training on Occluded-LINEMOD.
Synthetic Augmentation pix2pix using Tri-category Label with Edge structure for Accurate Segmentation architectures
Apr 21, 2020In medical image diagnosis, pathology image analysis using semantic segmentation becomes important for efficient screening as a field of digital pathology. The spatial augmentation is ordinarily used for semantic segmentation. Images of malignant tumor are rare, and annotating the labels of the nuclei region is a time-consuming process. An effective use of the data set is required to maximize the segmentation accuracy. It is expected that augmentation to transform generalized images influences the segmentation performance. We propose a synthetic augmentation using label-to-image translation, mapping from a semantic label with an edge structure to a real image. This paper deals with the stain slides of nuclei in tumor. We demonstrate several segmentation algorithms applied to the initial data set that contains real images and labels using synthetic augmentation in order to add their generalized images. We compute and report that a proposed synthetic augmentation procedure improves the accuracy indices.