 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image classification using local tensor singular value decompositions
Jun 29, 2017
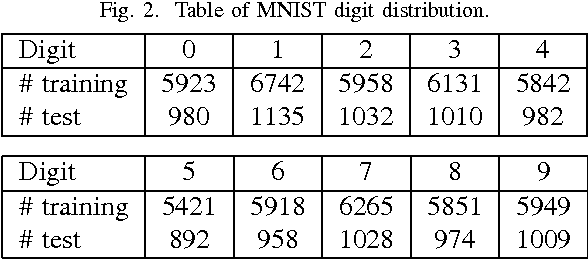
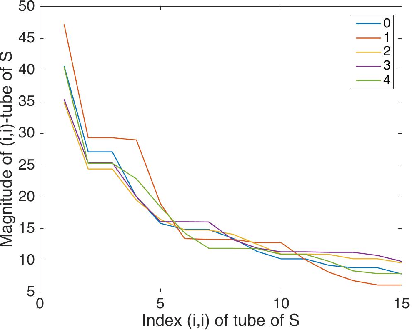
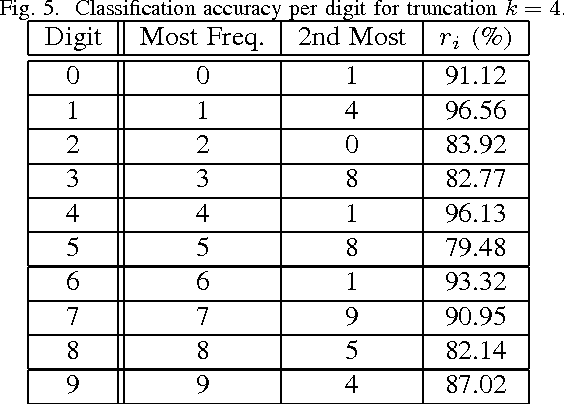
From linear classifiers to neural networks, image classification has been a widely explored topic in mathematics, and many algorithms have proven to be effective classifiers. However, the most accurate classifiers typically have significantly high storage costs, or require complicated procedures that may be computationally expensive. We present a novel (nonlinear) classification approach using truncation of local tensor singular value decompositions (tSVD) that robustly offers accurate results, while maintaining manageable storage costs. Our approach takes advantage of the optimality of the representation under the tensor algebra described to determine to which class an image belongs. We extend our approach to a method that can determine specific pairwise match scores, which could be useful in, for example, object recognition problems where pose/position are different. We demonstrate the promise of our new techniques on the MNIST data set.
Exploring Adversarial Fake Images on Face Manifold
Jan 09, 2021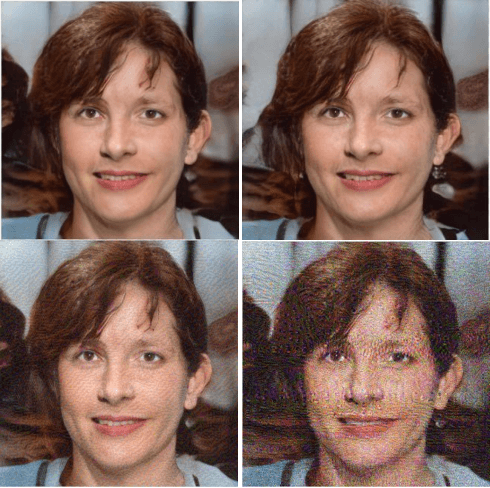
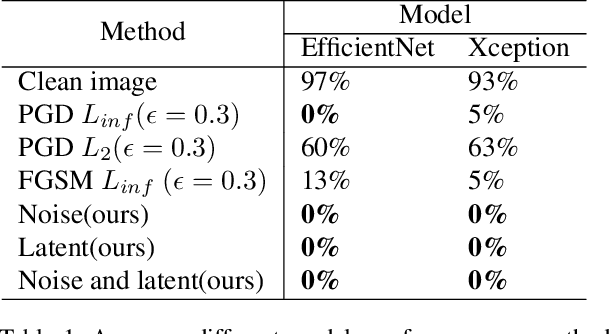
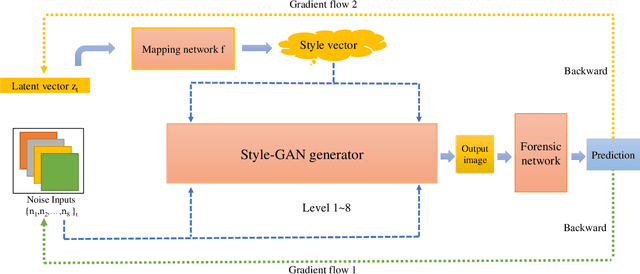
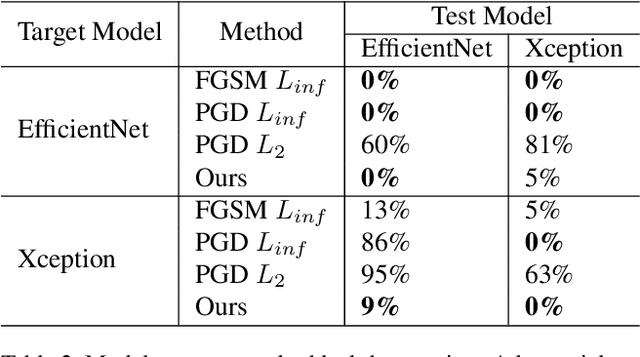
Images synthesized by powerful generative adversarial network (GAN) based methods have drawn moral and privacy concerns. Although image forensic models have reached great performance in detecting fake images from real ones, these models can be easily fooled with a simple adversarial attack. But, the noise adding adversarial samples are also arousing suspicion. In this paper, instead of adding adversarial noise, we optimally search adversarial points on face manifold to generate anti-forensic fake face images. We iteratively do a gradient-descent with each small step in the latent space of a generative model, e.g. Style-GAN, to find an adversarial latent vector, which is similar to norm-based adversarial attack but in latent space. Then, the generated fake images driven by the adversarial latent vectors with the help of GANs can defeat main-stream forensic models. For examples, they make the accuracy of deepfake detection models based on Xception or EfficientNet drop from over 90% to nearly 0%, meanwhile maintaining high visual quality. In addition, we find manipulating style vector $z$ or noise vectors $n$ at different levels have impacts on attack success rate. The generated adversarial images mainly have facial texture or face attributes changing.
BoxNet: Deep Learning Based Biomedical Image Segmentation Using Boxes Only Annotation
Jun 02, 2018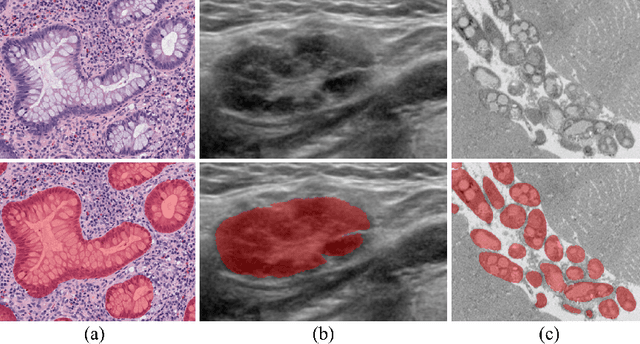
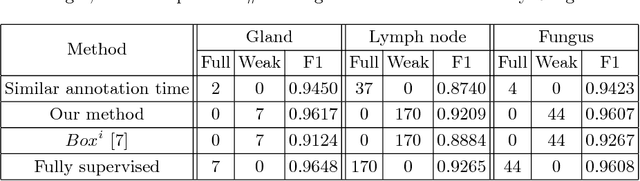


In recent years, deep learning (DL) methods have become powerful tools for biomedical image segmentation. However, high annotation efforts and costs are commonly needed to acquire sufficient biomedical training data for DL models. To alleviate the burden of manual annotation, in this paper, we propose a new weakly supervised DL approach for biomedical image segmentation using boxes only annotation. First, we develop a method to combine graph search (GS) and DL to generate fine object masks from box annotation, in which DL uses box annotation to compute a rough segmentation for GS and then GS is applied to locate the optimal object boundaries. During the mask generation process, we carefully utilize information from box annotation to filter out potential errors, and then use the generated masks to train an accurate DL segmentation network. Extensive experiments on gland segmentation in histology images, lymph node segmentation in ultrasound images, and fungus segmentation in electron microscopy images show that our approach attains superior performance over the best known state-of-the-art weakly supervised DL method and is able to achieve (1) nearly the same accuracy compared to fully supervised DL methods with far less annotation effort, (2) significantly better results with similar annotation time, and (3) robust performance in various applications.
High Resolution, Deep Imaging Using Confocal Time-of-flight Diffuse Optical Tomography
Jan 27, 2021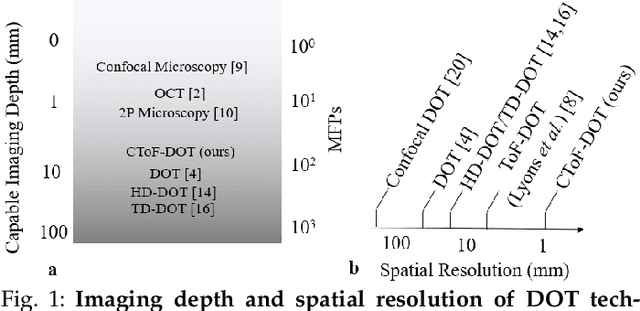
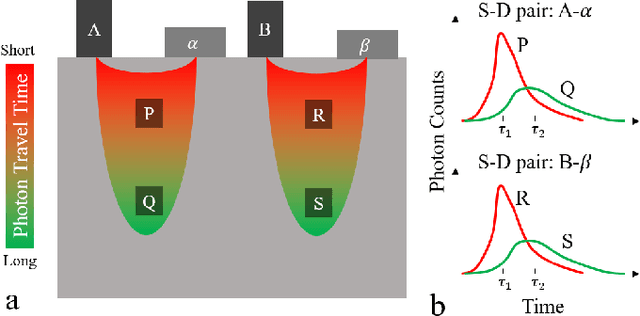
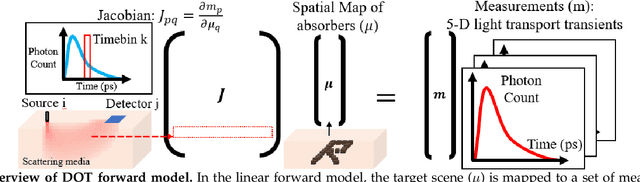
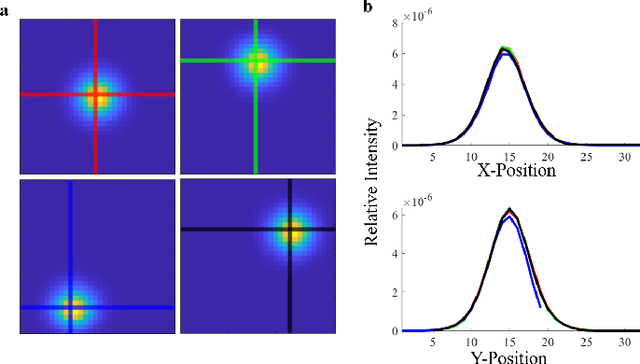
Light scattering by tissue severely limits both how deep beneath the surface one can image, and at what spatial resolution one can obtain from these images. Diffuse optical tomography (DOT) has emerged as one of the most powerful techniques for imaging deep within tissue -- well beyond the conventional $\sim$ 10-15 mean scattering lengths tolerated by ballistic imaging techniques such as confocal and two-photon microscopy. Unfortunately, existing DOT systems are quite limited and achieve only centimeter-scale resolution. Furthermore, they also suffer from slow acquisition times and extremely slow reconstruction speeds making real-time imaging infeasible. We show that time-of-flight diffuse optical tomography (ToF-DOT) and its confocal variant (CToF-DOT), by exploiting the photon travel time information, allow us to achieve millimeter spatial resolution in the highly scattered diffusion regime ($>50$ mean free paths). In addition, we demonstrate that two additional innovations: focusing on confocal measurements, and multiplexing the illumination sources allow us to significantly reduce the scan time to acquire measurements. Finally, we also rely on a novel convolutional approximation that allows us to develop a fast reconstruction algorithm achieving a 100 $\times$ speedup in reconstruction time compared to traditional DOT reconstruction techniques. Together, we believe that these technical advances, serve as the first step towards real-time, millimeter resolution, deep tissue imaging using diffuse optical tomography.
Deep learning within a priori temporal feature spaces for large-scale dynamic MR image reconstruction: Application to 5-D cardiac MR Multitasking
Oct 02, 2019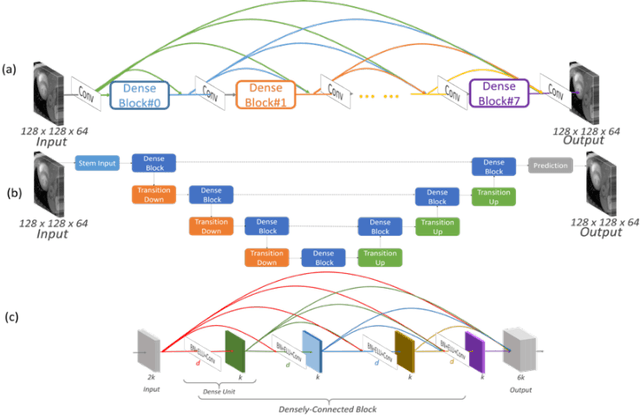
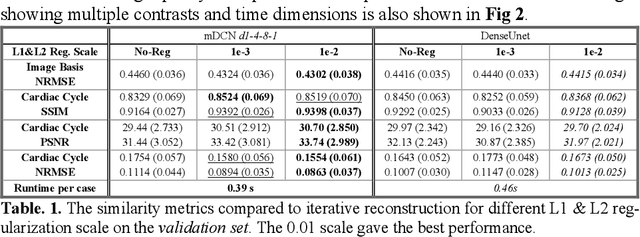
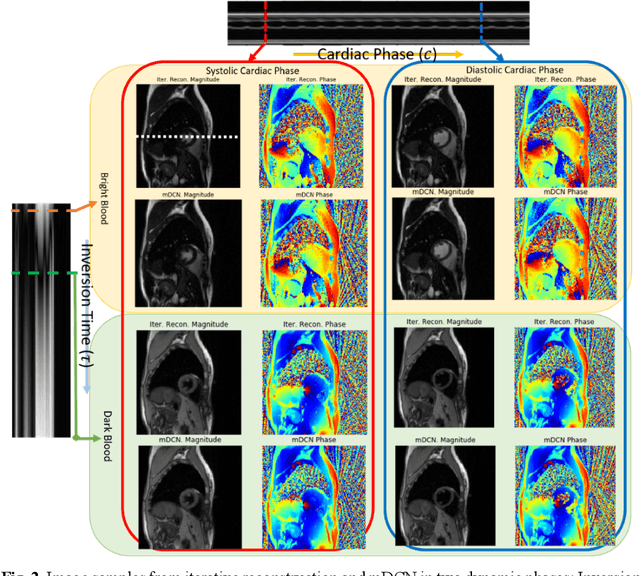
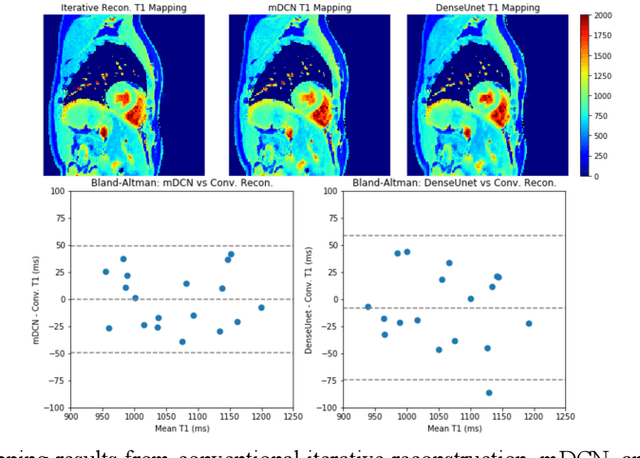
High spatiotemporal resolution dynamic magnetic resonance imaging (MRI) is a powerful clinical tool for imaging moving structures as well as to reveal and quantify other physical and physiological dynamics. The low speed of MRI necessitates acceleration methods such as deep learning reconstruction from under-sampled data. However, the massive size of many dynamic MRI problems prevents deep learning networks from directly exploiting global temporal relationships. In this work, we show that by applying deep neural networks inside a priori calculated temporal feature spaces, we enable deep learning reconstruction with global temporal modeling even for image sequences with >40,000 frames. One proposed variation of our approach using dilated multi-level Densely Connected Network (mDCN) speeds up feature space coordinate calculation by 3000x compared to conventional iterative methods, from 20 minutes to 0.39 seconds. Thus, the combination of low-rank tensor and deep learning models not only makes large-scale dynamic MRI feasible but also practical for routine clinical application.
PanoNet3D: Combining Semantic and Geometric Understanding for LiDARPoint Cloud Detection
Dec 17, 2020

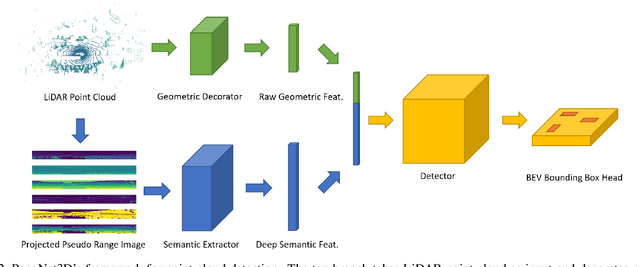

Visual data in autonomous driving perception, such as camera image and LiDAR point cloud, can be interpreted as a mixture of two aspects: semantic feature and geometric structure. Semantics come from the appearance and context of objects to the sensor, while geometric structure is the actual 3D shape of point clouds. Most detectors on LiDAR point clouds focus only on analyzing the geometric structure of objects in real 3D space. Unlike previous works, we propose to learn both semantic feature and geometric structure via a unified multi-view framework. Our method exploits the nature of LiDAR scans -- 2D range images, and applies well-studied 2D convolutions to extract semantic features. By fusing semantic and geometric features, our method outperforms state-of-the-art approaches in all categories by a large margin. The methodology of combining semantic and geometric features provides a unique perspective of looking at the problems in real-world 3D point cloud detection.
A Resilient Image Matching Method with an Affine Invariant Feature Detector and Descriptor
Dec 29, 2017
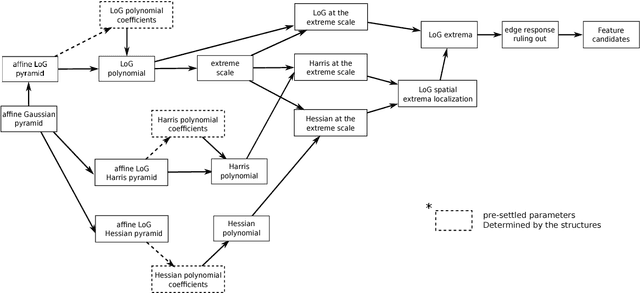
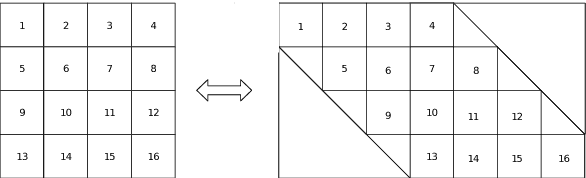
Image feature matching is to seek, localize and identify the similarities across the images. The matched local features between different images can indicate the similarities of their content. Resilience of image feature matching to large view point changes is challenging for a lot of applications such as 3D object reconstruction, object recognition and navigation, etc, which need accurate and robust feature matching from quite different view points. In this paper we propose a novel image feature matching algorithm, integrating our previous proposed Affine Invariant Feature Detector (AIFD) and new proposed Affine Invariant Feature Descriptor (AIFDd). Both stages of this new proposed algorithm can provide sufficient resilience to view point changes. With systematic experiments, we can prove that the proposed method of feature detector and descriptor outperforms other state-of-the-art feature matching algorithms especially on view points robustness. It also performs well under other conditions such as the change of illumination, rotation and compression, etc.
SRPGAN: Perceptual Generative Adversarial Network for Single Image Super Resolution
Dec 20, 2017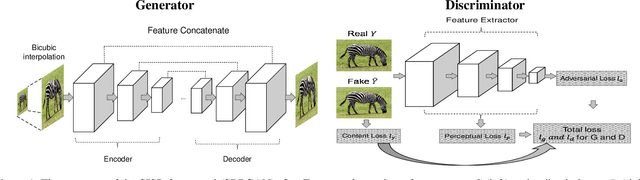
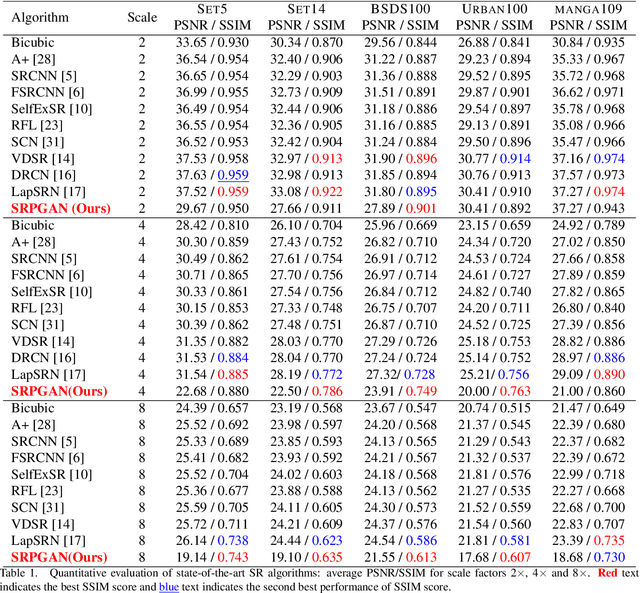
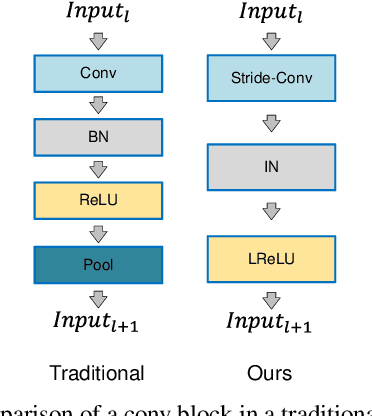

Single image super resolution (SISR) is to reconstruct a high resolution image from a single low resolution image. The SISR task has been a very attractive research topic over the last two decades. In recent years, convolutional neural network (CNN) based models have achieved great performance on SISR task. Despite the breakthroughs achieved by using CNN models, there are still some problems remaining unsolved, such as how to recover high frequency details of high resolution images. Previous CNN based models always use a pixel wise loss, such as l2 loss. Although the high resolution images constructed by these models have high peak signal-to-noise ratio (PSNR), they often tend to be blurry and lack high-frequency details, especially at a large scaling factor. In this paper, we build a super resolution perceptual generative adversarial network (SRPGAN) framework for SISR tasks. In the framework, we propose a robust perceptual loss based on the discriminator of the built SRPGAN model. We use the Charbonnier loss function to build the content loss and combine it with the proposed perceptual loss and the adversarial loss. Compared with other state-of-the-art methods, our method has demonstrated great ability to construct images with sharp edges and rich details. We also evaluate our method on different benchmarks and compare it with previous CNN based methods. The results show that our method can achieve much higher structural similarity index (SSIM) scores on most of the benchmarks than the previous state-of-art methods.
A range characterization of the single-quadrant ADRT
Oct 11, 2020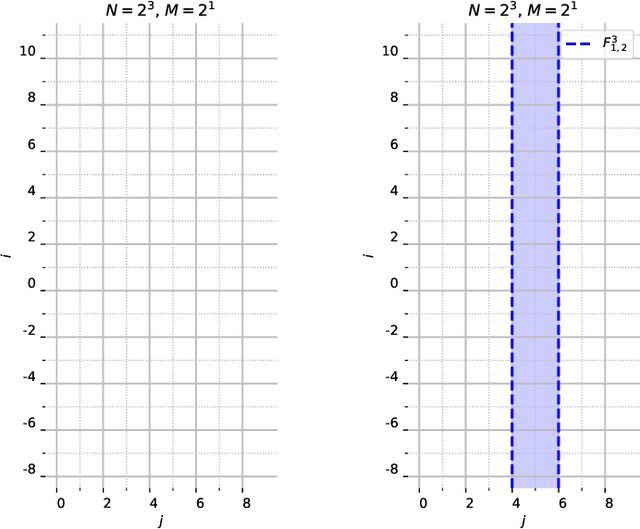
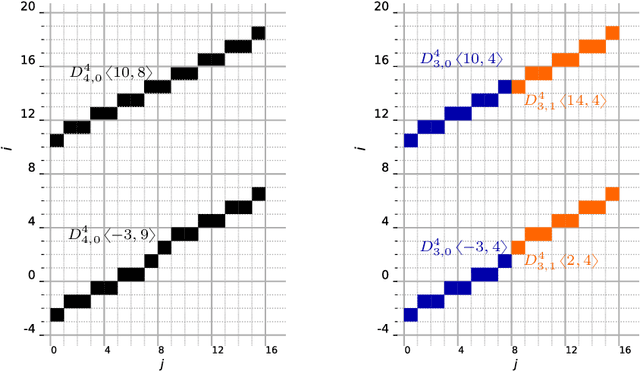
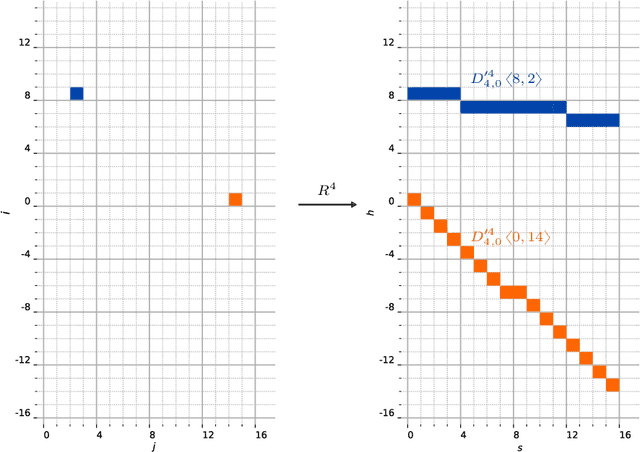
This work characterizes the range of the single-quadrant approximate discrete Radon transform (ADRT) of square images. The characterization is given in the form of linear constraints that ensure the exact and fast inversion formula [Rim, Appl. Math. Lett. 102 106159, 2020] yields a square image in a stable manner. The range characterization is obtained by first showing that the transform is a bijection between images supported on infinite half-strips, then identifying the linear subspaces that stay finitely supported under the inversion formula.
Domain-Adversarial Learning for Multi-Centre, Multi-Vendor, and Multi-Disease Cardiac MR Image Segmentation
Aug 26, 2020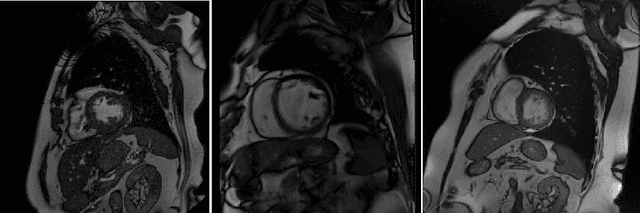
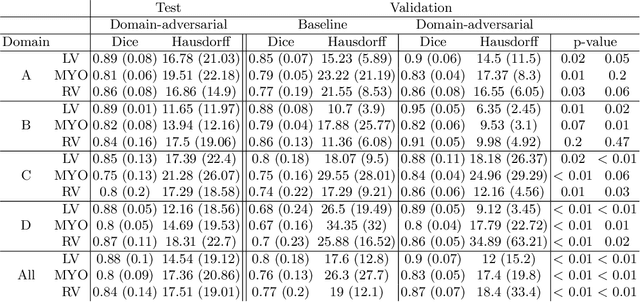
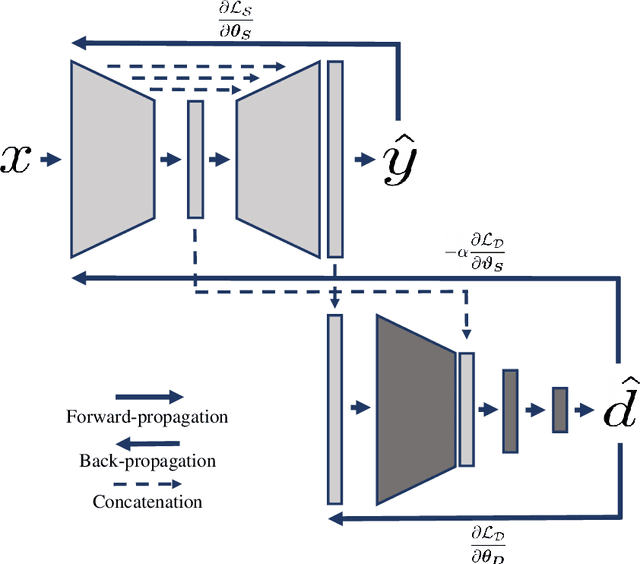
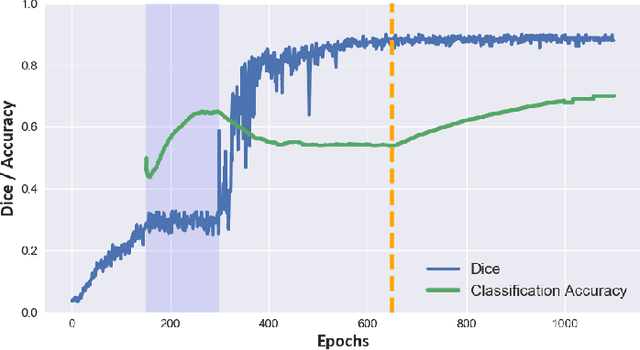
Cine cardiac magnetic resonance (CMR) has become the gold standard for the non-invasive evaluation of cardiac function. In particular, it allows the accurate quantification of functional parameters including the chamber volumes and ejection fraction. Deep learning has shown the potential to automate the requisite cardiac structure segmentation. However, the lack of robustness of deep learning models has hindered their widespread clinical adoption. Due to differences in the data characteristics, neural networks trained on data from a specific scanner are not guaranteed to generalise well to data acquired at a different centre or with a different scanner. In this work, we propose a principled solution to the problem of this domain shift. Domain-adversarial learning is used to train a domain-invariant 2D U-Net using labelled and unlabelled data. This approach is evaluated on both seen and unseen domains from the M\&Ms challenge dataset and the domain-adversarial approach shows improved performance as compared to standard training. Additionally, we show that the domain information cannot be recovered from the learned features.