 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pairwise Relation Learning for Semi-supervised Gland Segmentation
Aug 06, 2020
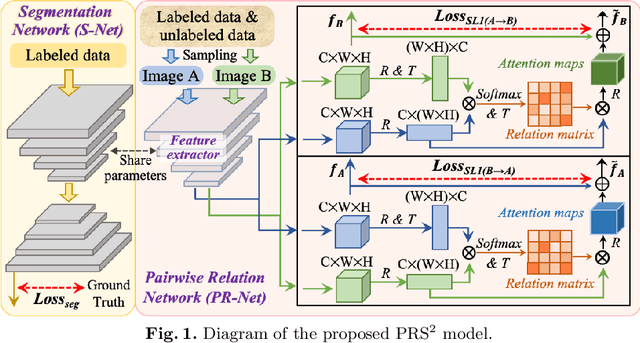
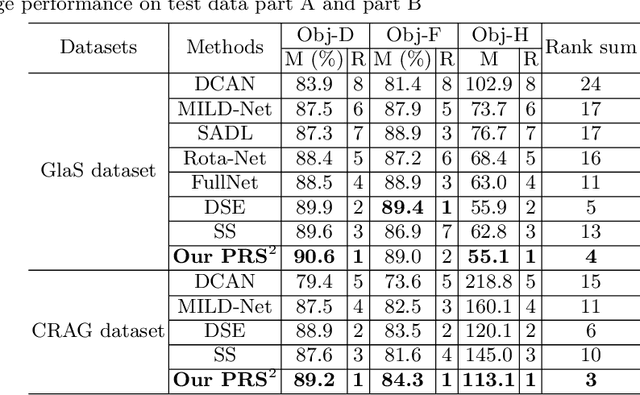
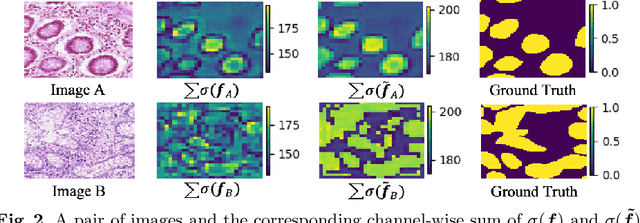
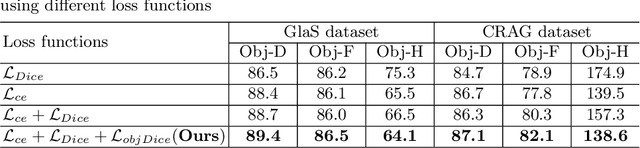
Accurate and automated gland segmentation on histology tissue images is an essential but challenging task in the computer-aided diagnosis of adenocarcinoma. Despite their prevalence, deep learning models always require a myriad number of densely annotated training images, which are difficult to obtain due to extensive labor and associated expert costs related to histology image annotations. In this paper, we propose the pairwise relation-based semi-supervised (PRS^2) model for gland segmentation on histology images. This model consists of a segmentation network (S-Net) and a pairwise relation network (PR-Net). The S-Net is trained on labeled data for segmentation, and PR-Net is trained on both labeled and unlabeled data in an unsupervised way to enhance its image representation ability via exploiting the semantic consistency between each pair of images in the feature space. Since both networks share their encoders, the image representation ability learned by PR-Net can be transferred to S-Net to improve its segmentation performance. We also design the object-level Dice loss to address the issues caused by touching glands and combine it with other two loss functions for S-Net. We evaluated our model against five recent methods on the GlaS dataset and three recent methods on the CRAG dataset. Our results not only demonstrate the effectiveness of the proposed PR-Net and object-level Dice loss, but also indicate that our PRS^2 model achieves the state-of-the-art gland segmentation performance on both benchmarks.
The Image Torque Operator for Contour Processing
Jan 18, 2016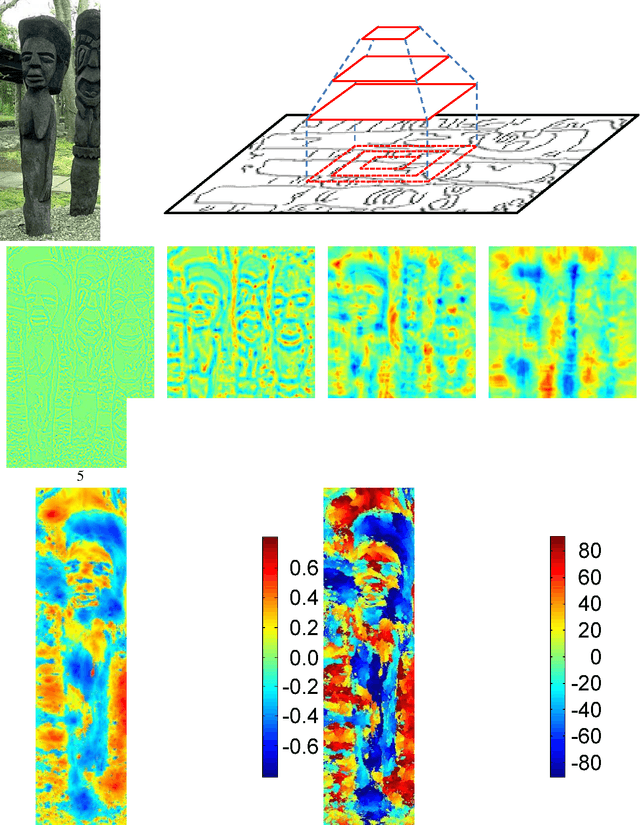
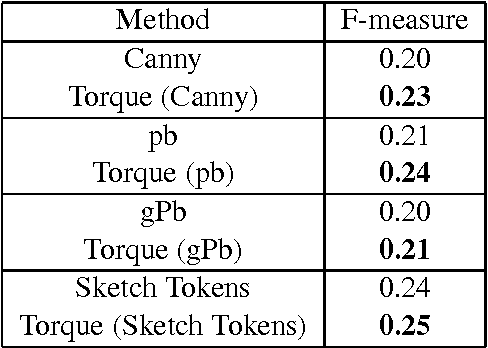
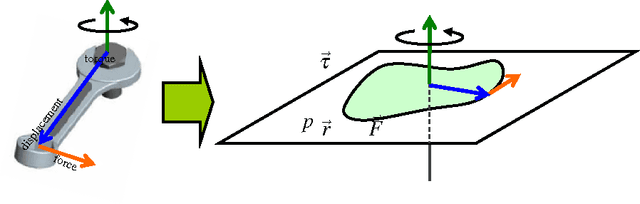
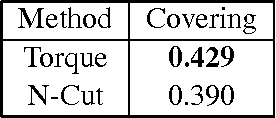
Contours are salient features for image description, but the detection and localization of boundary contours is still considered a challenging problem. This paper introduces a new tool for edge processing implementing the Gestaltism idea of edge grouping. This tool is a mid-level image operator, called the Torque operator, that is designed to help detect closed contours in images. The torque operator takes as input the raw image and creates an image map by computing from the image gradients within regions of multiple sizes a measure of how well the edges are aligned to form closed convex contours. Fundamental properties of the torque are explored and illustrated through examples. Then it is applied in pure bottom-up processing in a variety of applications, including edge detection, visual attention and segmentation and experimentally demonstrated a useful tool that can improve existing techniques. Finally, its extension as a more general grouping mechanism and application in object recognition is discussed.
Self-Supervised Person Detection in 2D Range Data using a Calibrated Camera
Dec 16, 2020

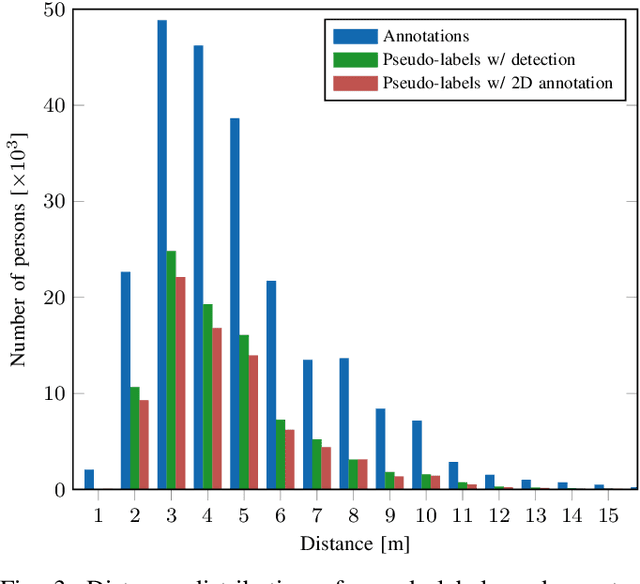
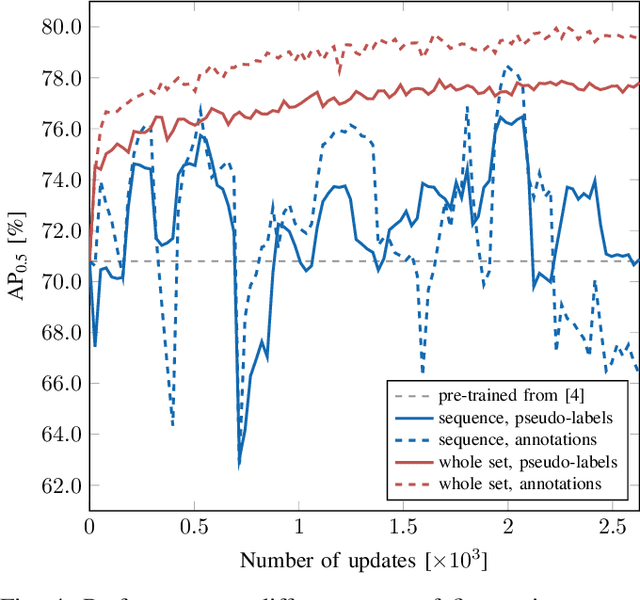
Deep learning is the essential building block of state-of-the-art person detectors in 2D range data. However, only a few annotated datasets are available for training and testing these deep networks, potentially limiting their performance when deployed in new environments or with different LiDAR models. We propose a method, which uses bounding boxes from an image-based detector (e.g. Faster R-CNN) on a calibrated camera to automatically generate training labels (called pseudo-labels) for 2D LiDAR-based person detectors. Through experiments on the JackRabbot dataset with two detector models, DROW3 and DR-SPAAM, we show that self-supervised detectors, trained or fine-tuned with pseudo-labels, outperform detectors trained using manual annotations from a different dataset. Combined with robust training techniques, the self-supervised detectors reach a performance close to the ones trained using manual annotations. Our method is an effective way to improve person detectors during deployment without any additional labeling effort, and we release our source code to support relevant robotic applications.
Conditional Entropy Coding for Efficient Video Compression
Aug 20, 2020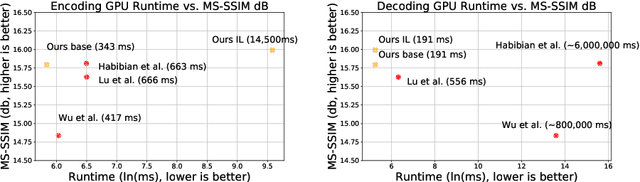
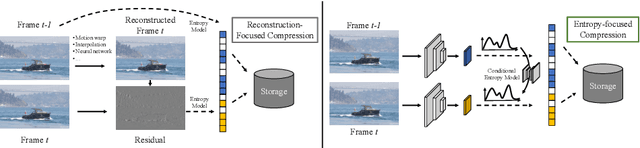
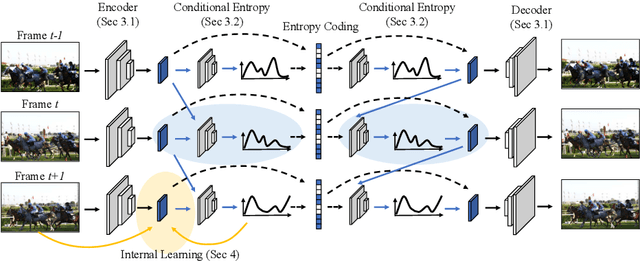
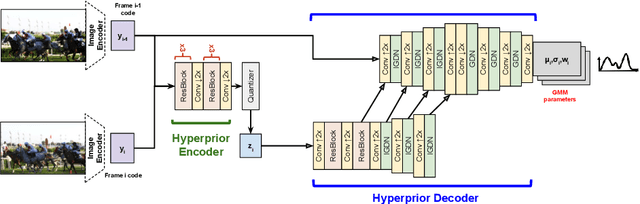
We propose a very simple and efficient video compression framework that only focuses on modeling the conditional entropy between frames. Unlike prior learning-based approaches, we reduce complexity by not performing any form of explicit transformations between frames and assume each frame is encoded with an independent state-of-the-art deep image compressor. We first show that a simple architecture modeling the entropy between the image latent codes is as competitive as other neural video compression works and video codecs while being much faster and easier to implement. We then propose a novel internal learning extension on top of this architecture that brings an additional 10% bitrate savings without trading off decoding speed. Importantly, we show that our approach outperforms H.265 and other deep learning baselines in MS-SSIM on higher bitrate UVG video, and against all video codecs on lower framerates, while being thousands of times faster in decoding than deep models utilizing an autoregressive entropy model.
ImagiFilter: A resource to enable the semi-automatic mining of images at scale
Aug 20, 2020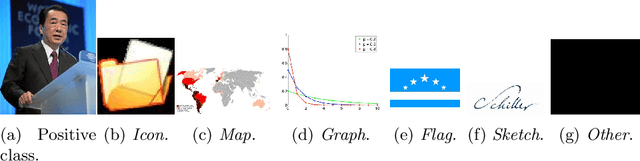
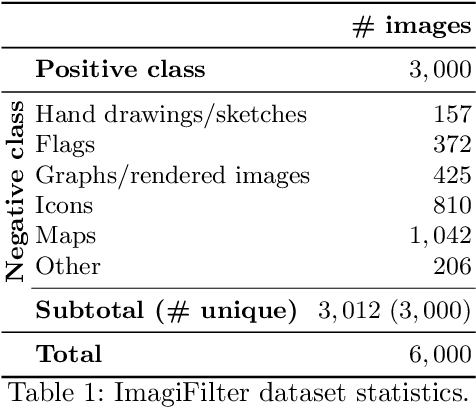
Datasets (semi-)automatically collected from the web can easily scale to millions of entries, but a dataset's usefulness is directly related to how clean and high-quality its examples are. In this paper, we describe and publicly release an image dataset along with pretrained models designed to (semi-)automatically filter out undesirable images from very large image collections, possibly obtained from the web. Our dataset focusses on photographic and/or natural images, a very common use-case in computer vision research. We provide annotations for coarse prediction, i.e. photographic vs. non-photographic, and smaller fine-grained prediction tasks where we further break down the non-photographic class into five classes: maps, drawings, graphs, icons, and sketches. Results on held out validation data show that a model architecture with reduced memory footprint achieves over 96% accuracy on coarse-prediction. Our best model achieves 88% accuracy on the hardest fine-grained classification task available. Dataset and pretrained models are available at: https://github.com/houda96/imagi-filter.
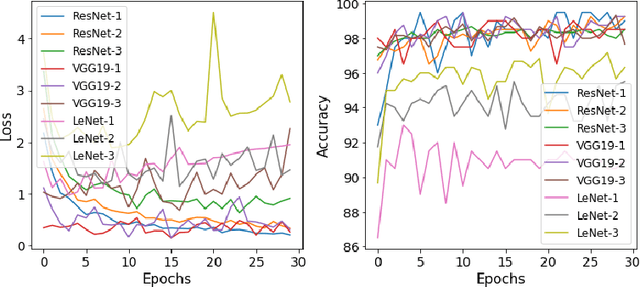
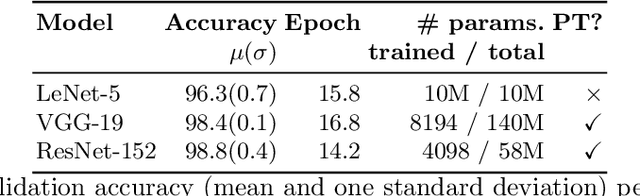
Deep Learning Based Defect Detection for Solder Joints on Industrial X-Ray Circuit Board Images
Aug 06, 2020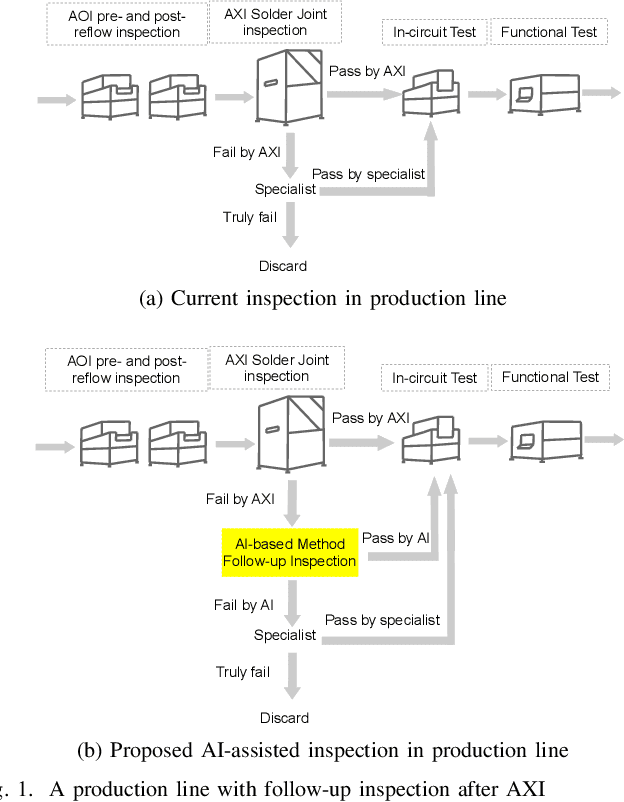


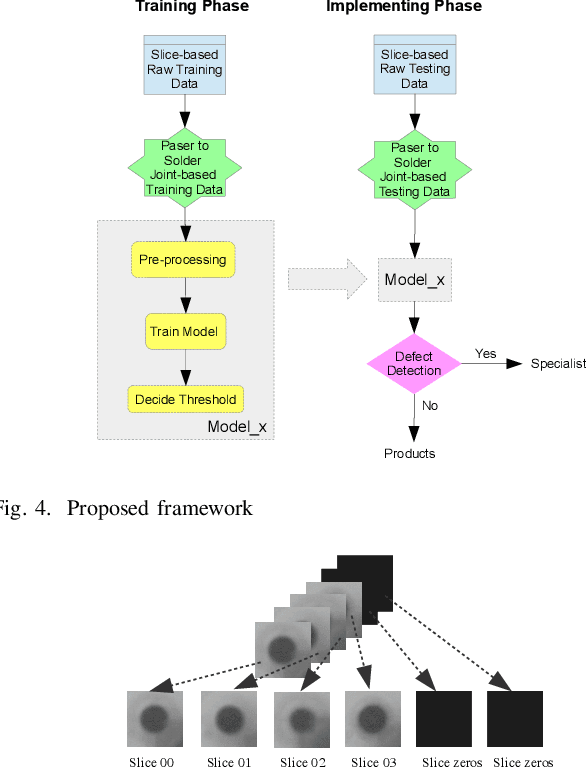
Quality control is of vital importance during electronics production. As the methods of producing electronic circuits improve, there is an increasing chance of solder defects during assembling the printed circuit board (PCB). Many technologies have been incorporated for inspecting failed soldering, such as X-ray imaging, optical imaging, and thermal imaging. With some advanced algorithms, the new technologies are expected to control the production quality based on the digital images. However, current algorithms sometimes are not accurate enough to meet the quality control. Specialists are needed to do a follow-up checking. For automated X-ray inspection, joint of interest on the X-ray image is located by region of interest (ROI) and inspected by some algorithms. Some incorrect ROIs deteriorate the inspection algorithm. The high dimension of X-ray images and the varying sizes of image dimensions also challenge the inspection algorithms. On the other hand, recent advances on deep learning shed light on image-based tasks and are competitive to human levels. In this paper, deep learning is incorporated in X-ray imaging based quality control during PCB quality inspection. Two artificial intelligence (AI) based models are proposed and compared for joint defect detection. The noised ROI problem and the varying sizes of imaging dimension problem are addressed. The efficacy of the proposed methods are verified through experimenting on a real-world 3D X-ray dataset. By incorporating the proposed methods, specialist inspection workload is largely saved.
Multi-mode Core Tensor Factorization based Low-Rankness and Its Applications to Tensor Completion
Dec 03, 2020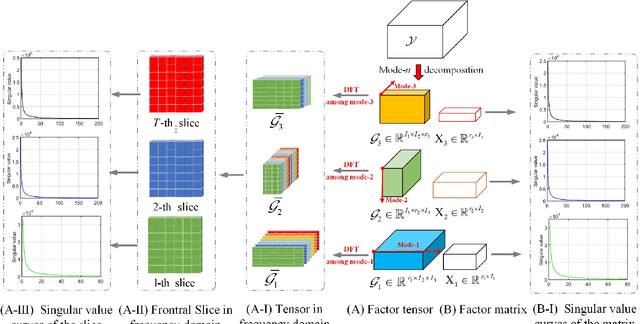

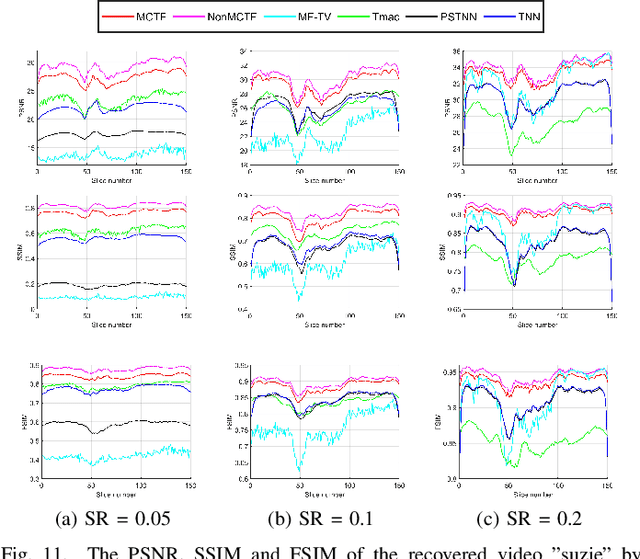
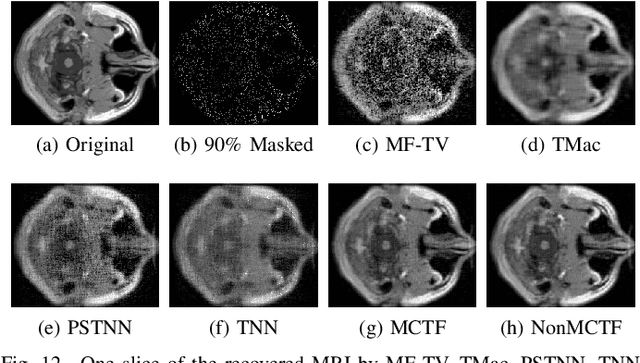
Low-rank tensor completion has been widely used in computer vision and machine learning. This paper develops a tensor low-rank decomposition method together with a tensor low-rankness measure (MCTF) and a better nonconvex relaxation form of it (NonMCTF). This is the first method that can accurately restore the clean data of intrinsic low-rank structure based on few known inputs. This metric encodes low-rank insights for general tensors provided by Tucker and T-SVD. Furthermore, we studied the MCTF and NonMCTF regularization minimization problem, and designed an effective BSUM algorithm to solve the problem. This efficient solver can extend MCTF to various tasks, such as tensor completion and tensor robust principal component analysis. A series of experiments, including hyperspectral image (HSI) denoising, video completion and MRI restoration, confirmed the superior performance of the proposed method
An Inductive Transfer Learning Approach using Cycle-consistent Adversarial Domain Adaptation with Application to Brain Tumor Segmentation
May 11, 2020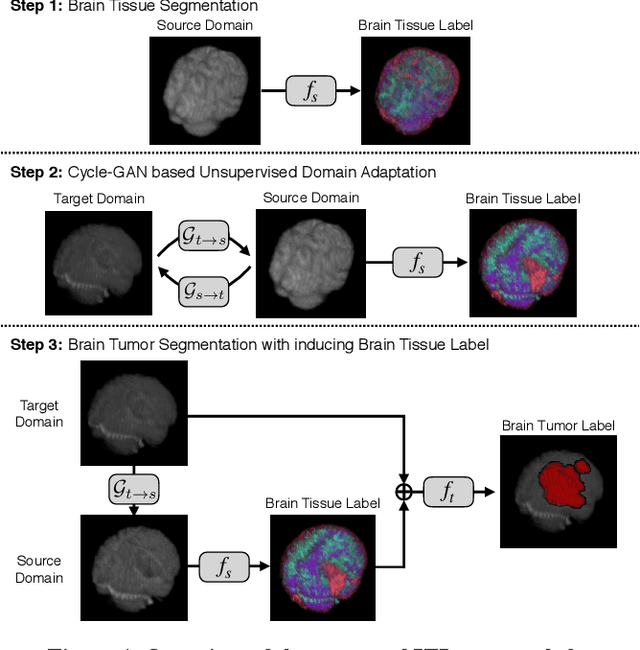
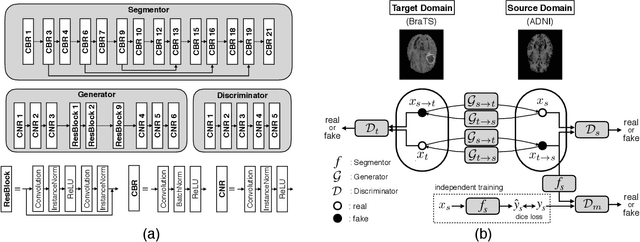
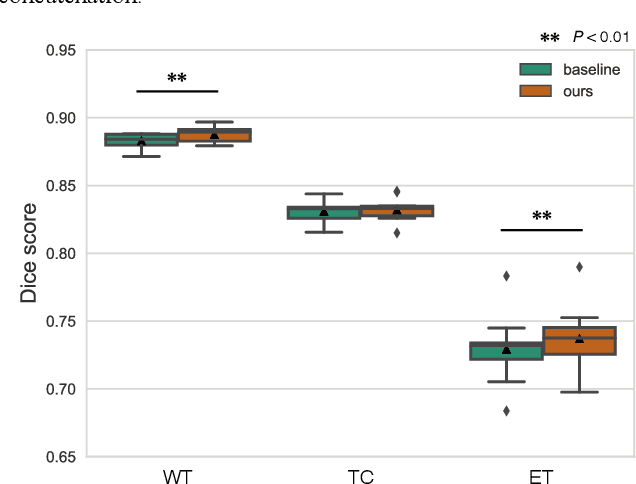
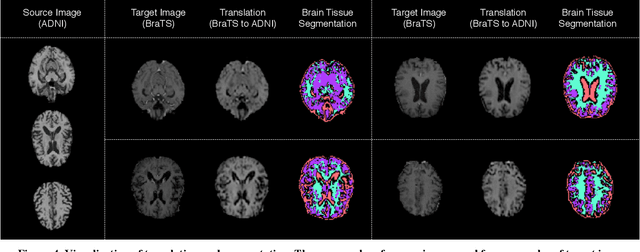
With recent advances in supervised machine learning for medical image analysis applications, the annotated medical image datasets of various domains are being shared extensively. Given that the annotation labelling requires medical expertise, such labels should be applied to as many learning tasks as possible. However, the multi-modal nature of each annotated image renders it difficult to share the annotation label among diverse tasks. In this work, we provide an inductive transfer learning (ITL) approach to adopt the annotation label of the source domain datasets to tasks of the target domain datasets using Cycle-GAN based unsupervised domain adaptation (UDA). To evaluate the applicability of the ITL approach, we adopted the brain tissue annotation label on the source domain dataset of Magnetic Resonance Imaging (MRI) images to the task of brain tumor segmentation on the target domain dataset of MRI. The results confirm that the segmentation accuracy of brain tumor segmentation improved significantly. The proposed ITL approach can make significant contribution to the field of medical image analysis, as we develop a fundamental tool to improve and promote various tasks using medical images.
Improved training of binary networks for human pose estimation and image recognition
Apr 11, 2019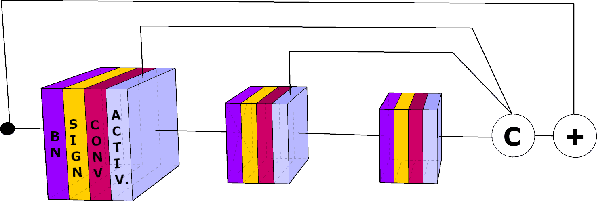
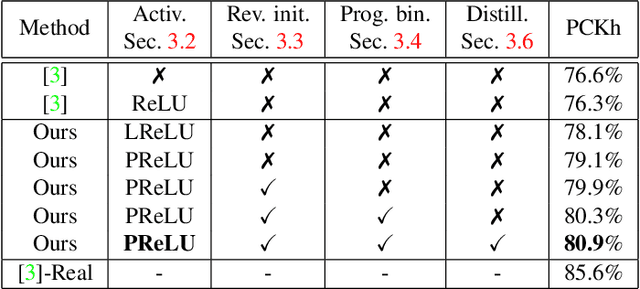

Big neural networks trained on large datasets have advanced the state-of-the-art for a large variety of challenging problems, improving performance by a large margin. However, under low memory and limited computational power constraints, the accuracy on the same problems drops considerable. In this paper, we propose a series of techniques that significantly improve the accuracy of binarized neural networks (i.e networks where both the features and the weights are binary). We evaluate the proposed improvements on two diverse tasks: fine-grained recognition (human pose estimation) and large-scale image recognition (ImageNet classification). Specifically, we introduce a series of novel methodological changes including: (a) more appropriate activation functions, (b) reverse-order initialization, (c) progressive quantization, and (d) network stacking and show that these additions improve existing state-of-the-art network binarization techniques, significantly. Additionally, for the first time, we also investigate the extent to which network binarization and knowledge distillation can be combined. When tested on the challenging MPII dataset, our method shows a performance improvement of more than 4% in absolute terms. Finally, we further validate our findings by applying the proposed techniques for large-scale object recognition on the Imagenet dataset, on which we report a reduction of error rate by 4%.
Where to drive: free space detection with one fisheye camera
Nov 11, 2020The development in the field of autonomous driving goes hand in hand with ever new developments in the field of image processing and machine learning methods. In order to fully exploit the advantages of deep learning, it is necessary to have sufficient labeled training data available. This is especially not the case for omnidirectional fisheye cameras. As a solution, we propose in this paper to use synthetic training data based on Unity3D. A five-pass algorithm is used to create a virtual fisheye camera. This synthetic training data is evaluated for the application of free space detection for different deep learning network architectures. The results indicate that synthetic fisheye images can be used in deep learning context.
* Accepted at International Conference on Machine Vision 2019 (ICMV 2019)