 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Optimal Data Augmentation Policies via Bayesian Optimization for Image Classification Tasks
May 23, 2019
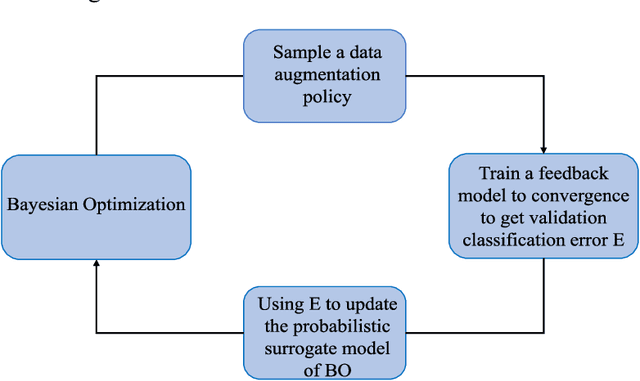
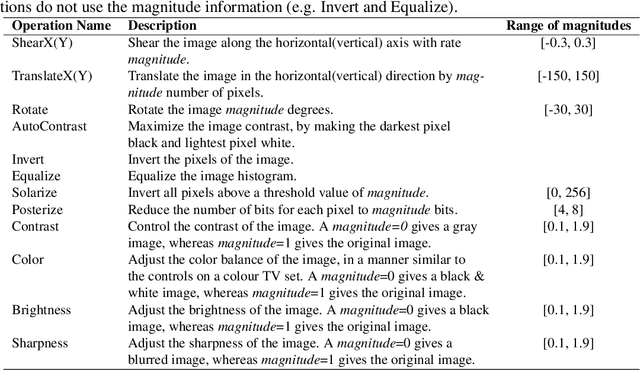

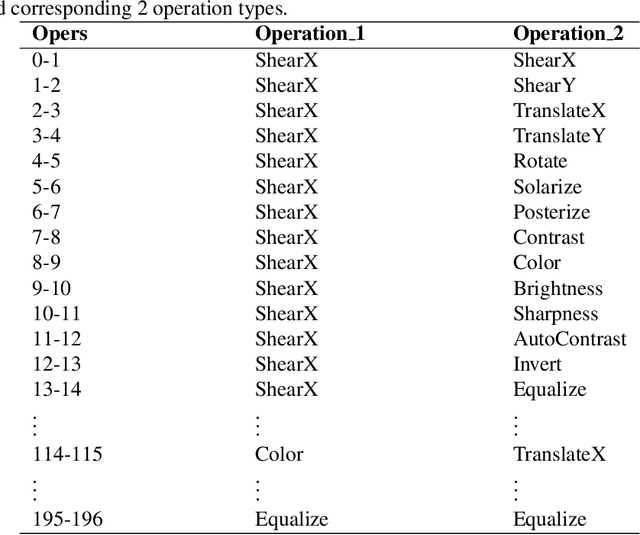
In recent years, deep learning has achieved remarkable achievements in many fields, including computer vision, natural language processing, speech recognition and others. Adequate training data is the key to ensure the effectiveness of the deep models. However, obtaining valid data requires a lot of time and labor resources. Data augmentation (DA) is an effective alternative approach, which can generate new labeled data based on existing data using label-preserving transformations. Although we can benefit a lot from DA, designing appropriate DA policies requires a lot of expert experience and time consumption, and the evaluation of searching the optimal policies is costly. So we raise a new question in this paper: how to achieve automated data augmentation at as low cost as possible? We propose a method named BO-Aug for automating the process by finding the optimal DA policies using the Bayesian optimization approach. Our method can find the optimal policies at a relatively low search cost, and the searched policies based on a specific dataset are transferable across different neural network architectures or even different datasets. We validate the BO-Aug on three widely used image classification datasets, including CIFAR-10, CIFAR-100 and SVHN. Experimental results show that the proposed method can achieve state-of-the-art or near advanced classification accuracy. Code to reproduce our experiments is available at https://github.com/zhangxiaozao/BO-Aug.
Quasi-homography warps in image stitching
Mar 18, 2018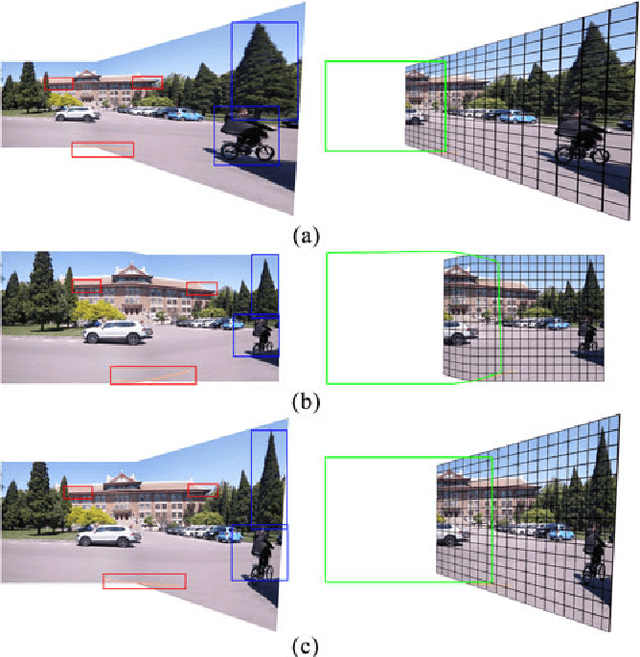
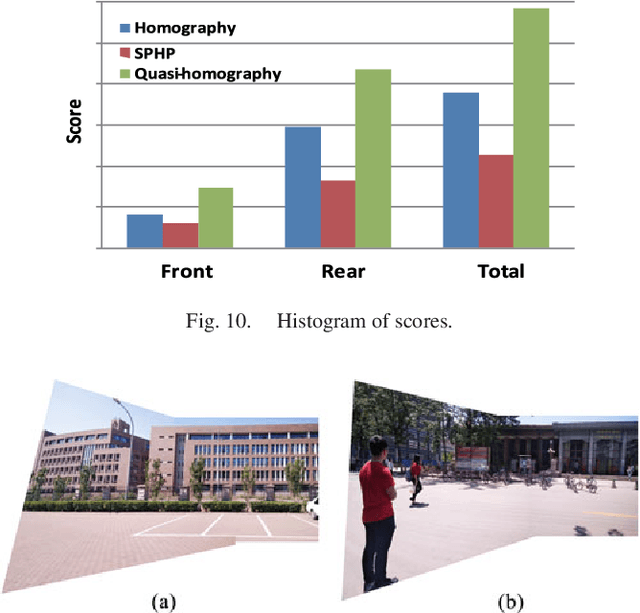

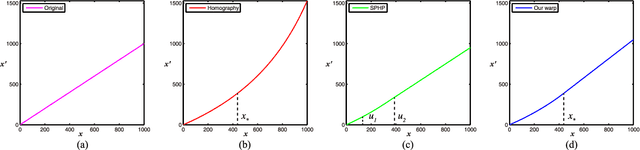
The naturalness of warps is gaining extensive attentions in image stitching. Recent warps such as SPHP and AANAP, use global similarity warps to mitigate projective distortion (which enlarges regions), however, they necessarily bring in perspective distortion (which generates inconsistencies). In this paper, we propose a novel quasi-homography warp, which effectively balances the perspective distortion against the projective distortion in the non-overlapping region to create a more natural-looking panorama. Our approach formulates the warp as the solution of a bivariate system, where perspective distortion and projective distortion are characterized as slope preservation and scale linearization respectively. Because our proposed warp only relies on a global homography, thus it is totally parameter-free. A comprehensive experiment shows that a quasi-homography warp outperforms some state-of-the-art warps in urban scenes, including homography, AutoStitch and SPHP. A user study demonstrates that it wins most users' favor, comparing to homography and SPHP.
GOCor: Bringing Globally Optimized Correspondence Volumes into Your Neural Network
Sep 16, 2020
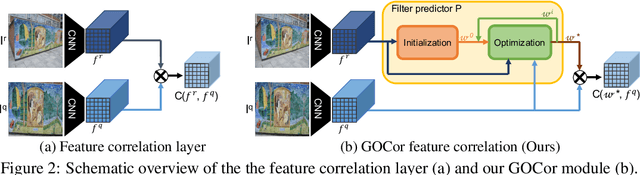
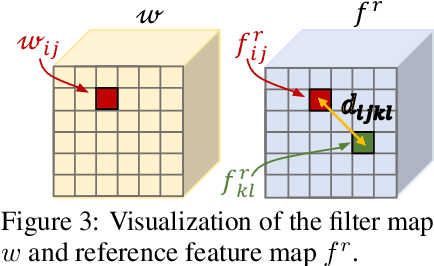
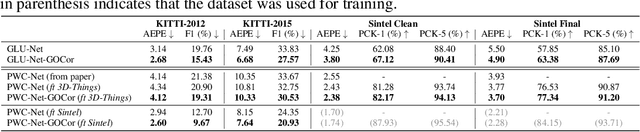
The feature correlation layer serves as a key neural network module in numerous computer vision problems that involve dense correspondences between image pairs. It predicts a correspondence volume by evaluating dense scalar products between feature vectors extracted from pairs of locations in two images. However, this point-to-point feature comparison is insufficient when disambiguating multiple similar regions in an image, severely affecting the performance of the end task. We propose GOCor, a fully differentiable dense matching module, acting as a direct replacement to the feature correlation layer. The correspondence volume generated by our module is the result of an internal optimization procedure that explicitly accounts for similar regions in the scene. Moreover, our approach is capable of effectively learning spatial matching priors to resolve further matching ambiguities. We analyze our GOCor module in extensive ablative experiments. When integrated into state-of-the-art networks, our approach significantly outperforms the feature correlation layer for the tasks of geometric matching, optical flow, and dense semantic matching. The code and trained models will be made available at github.com/PruneTruong/GOCor.
Transferable Universal Adversarial Perturbations Using Generative Models
Oct 29, 2020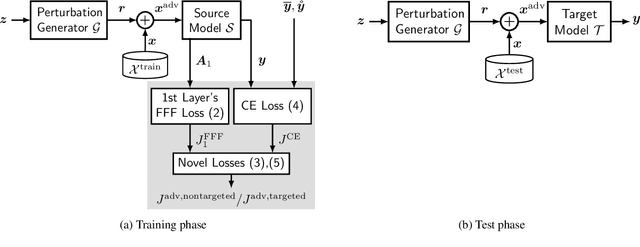
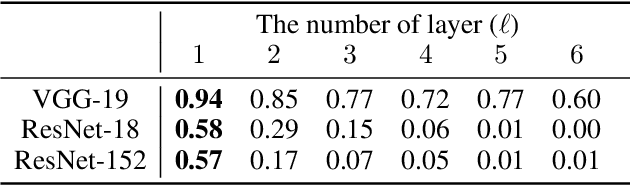

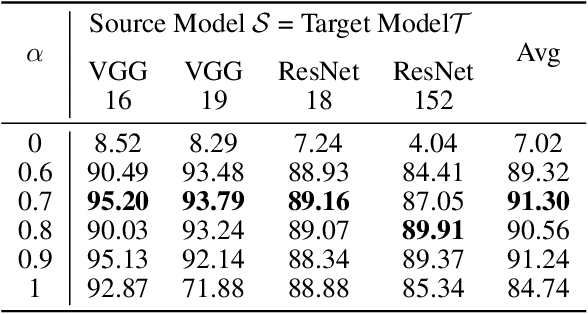
Deep neural networks tend to be vulnerable to adversarial perturbations, which by adding to a natural image can fool a respective model with high confidence. Recently, the existence of image-agnostic perturbations, also known as universal adversarial perturbations (UAPs), were discovered. However, existing UAPs still lack a sufficiently high fooling rate, when being applied to an unknown target model. In this paper, we propose a novel deep learning technique for generating more transferable UAPs. We utilize a perturbation generator and some given pretrained networks so-called source models to generate UAPs using the ImageNet dataset. Due to the similar feature representation of various model architectures in the first layer, we propose a loss formulation that focuses on the adversarial energy only in the respective first layer of the source models. This supports the transferability of our generated UAPs to any other target model. We further empirically analyze our generated UAPs and demonstrate that these perturbations generalize very well towards different target models. Surpassing the current state of the art in both, fooling rate and model-transferability, we can show the superiority of our proposed approach. Using our generated non-targeted UAPs, we obtain an average fooling rate of 93.36% on the source models (state of the art: 82.16%). Generating our UAPs on the deep ResNet-152, we obtain about a 12% absolute fooling rate advantage vs. cutting-edge methods on VGG-16 and VGG-19 target models.
An Asynchronous Kalman Filter for Hybrid Event Cameras
Dec 10, 2020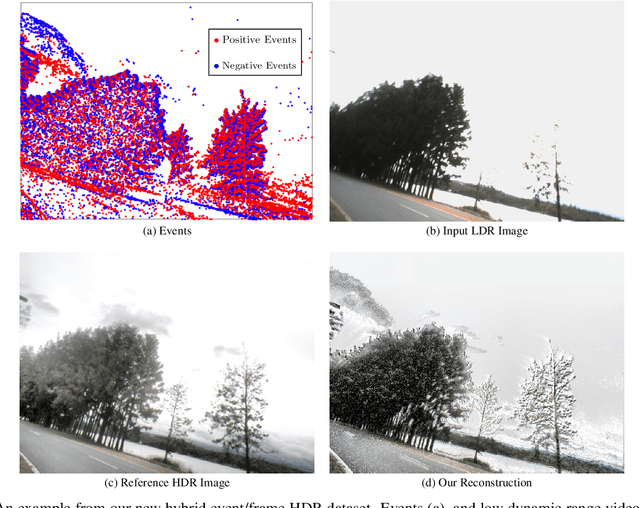
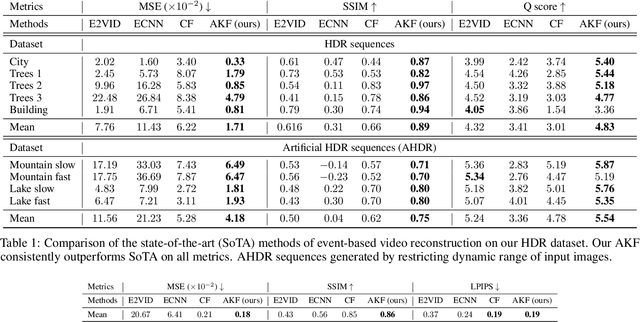
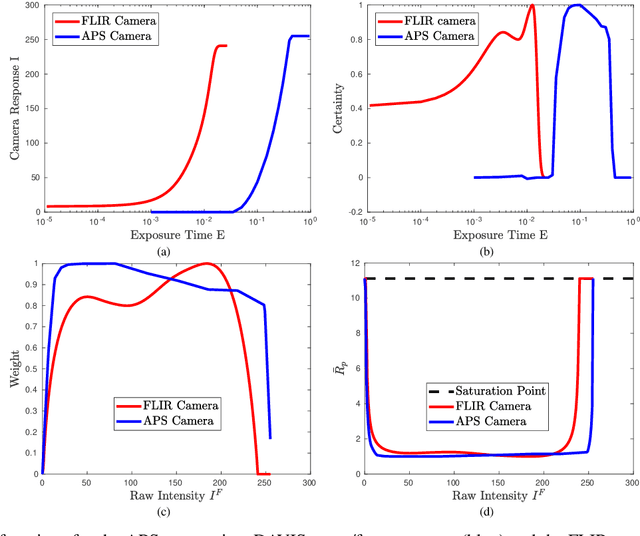
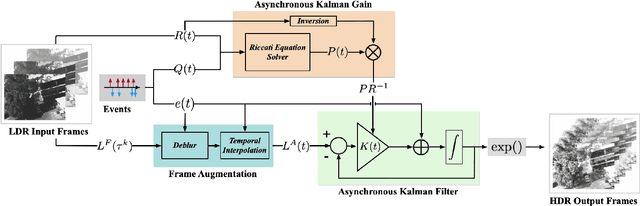
We present an Asynchronous Kalman Filter (AKF) to reconstruct High Dynamic Range (HDR) videos by fusing low-dynamic range images with event data. Event cameras are ideally suited to capture HDR visual information without blur but perform poorly on static or slowly changing scenes. Conversely, conventional image sensors measure absolute intensity of slowly changing scenes effectively but do poorly on quickly changing scenes with high dynamic range. The proposed approach exploits advantages of hybrid sensors under a unifying uncertainty model for both conventional frames and events. We present a novel dataset targeting challenging HDR and fast motion scenes captured on two separate sensors: an RGB frame-based camera and an event camera. Our video reconstruction outperforms the state-of-the-art algorithms on existing datasets and our targeted HDR dataset.
Automatic construction of Chinese herbal prescription from tongue image via CNNs and auxiliary latent therapy topics
Mar 01, 2018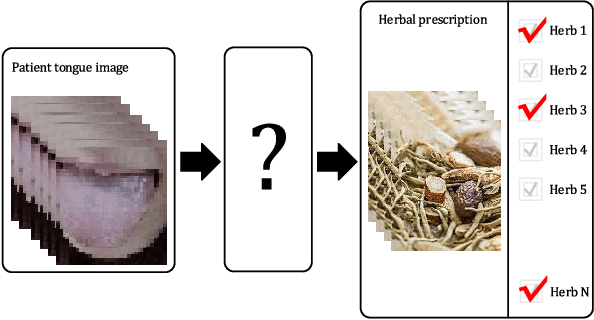
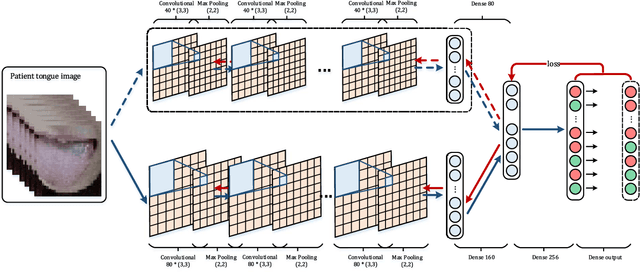
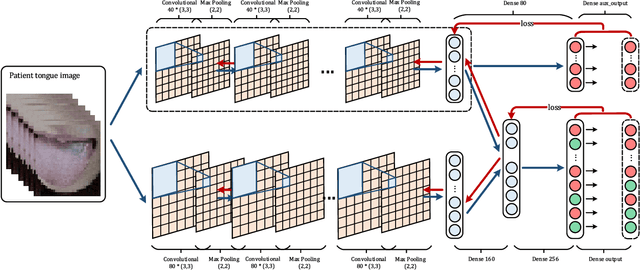
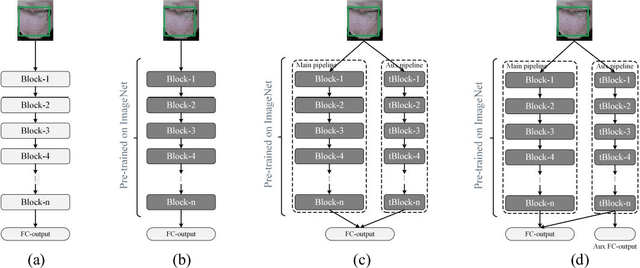
The tongue image is an important physical information of human, it is of great importance to the diagnosis and treatment in clinical medicine. Herbal prescriptions are simple, noninvasive and low side effects, and are widely applied in China. Researches on automatic construction technology of herbal prescription based on tongue image have great significance for deep learning to explore the relevance from tongue image to herbal prescription, and can be applied to healthcare services in mobile medical system. In order to adapt to the tongue image in a variety of photographing environments and construct the herbal prescriptions, a neural network framework for prescriptions construction is designed, which includes single / double convolution channels and fully connected layers, and propose the mechanism of auxiliary therapy topic loss to model the therapy of Chinese doctors then alleviate the interference of sparse output labels to the diversity of results. The experimental data include the patient tongue images and their corresponding prescriptions from real world outpatient clinic, and the experiment results can generate the prescriptions that are close to the real samples, which verifies the feasibility of the proposed method for automatic construction of herbal prescription from tongue image. Also, provides a reference for automatic herbal prescription construction from more physical information (or integrated body information).
Bootstrapping Deep Neural Networks from Image Processing and Computer Vision Pipelines
Nov 29, 2018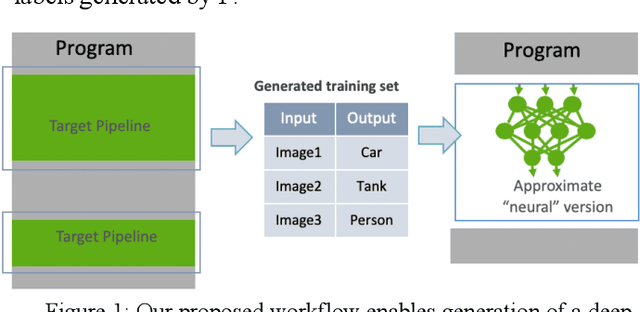
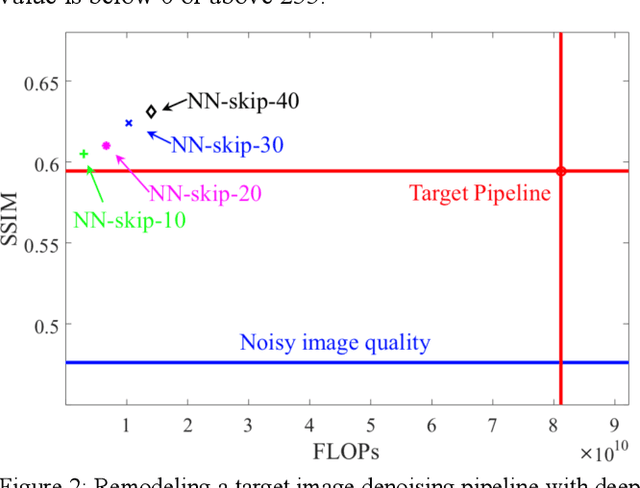
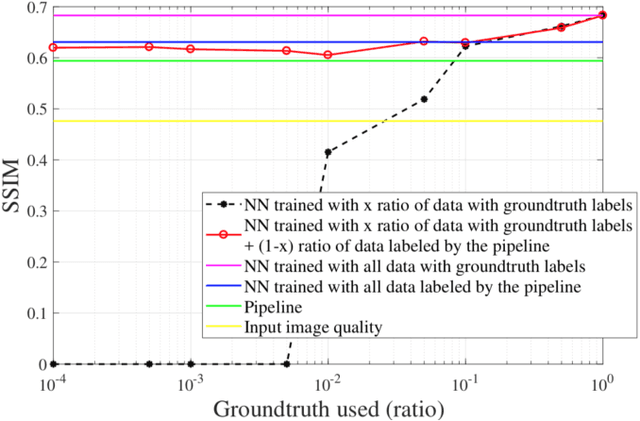
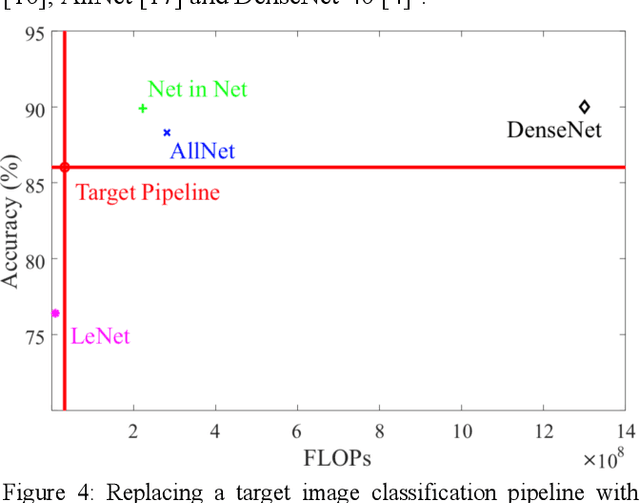
Complex image processing and computer vision systems often consist of a "pipeline" of "black boxes" that each solve part of the problem. We intend to replace parts or all of a target pipeline with deep neural networks to achieve benefits such as increased accuracy or reduced computational requirement. To acquire a large amounts of labeled data necessary to train the deep neural network, we propose a workflow that leverages the target pipeline to create a significantly larger labeled training set automatically, without prior domain knowledge of the target pipeline. We show experimentally that despite the noise introduced by automated labeling and only using a very small initially labeled data set, the trained deep neural networks can achieve similar or even better performance than the components they replace, while in some cases also reducing computational requirements.
Collaborative Teacher-Student Learning via Multiple Knowledge Transfer
Jan 21, 2021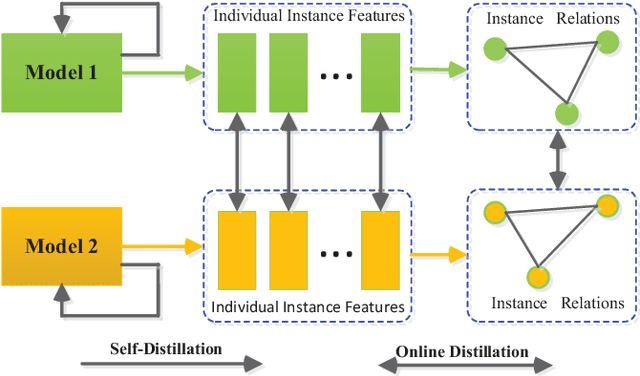

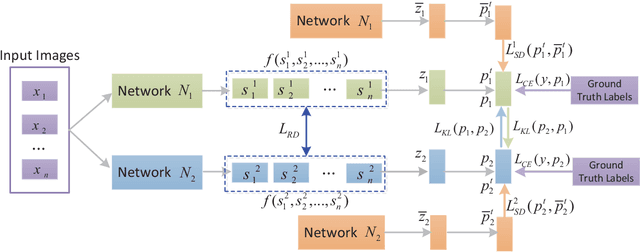
Knowledge distillation (KD), as an efficient and effective model compression technique, has been receiving considerable attention in deep learning. The key to its success is to transfer knowledge from a large teacher network to a small student one. However, most of the existing knowledge distillation methods consider only one type of knowledge learned from either instance features or instance relations via a specific distillation strategy in teacher-student learning. There are few works that explore the idea of transferring different types of knowledge with different distillation strategies in a unified framework. Moreover, the frequently used offline distillation suffers from a limited learning capacity due to the fixed teacher-student architecture. In this paper we propose a collaborative teacher-student learning via multiple knowledge transfer (CTSL-MKT) that prompts both self-learning and collaborative learning. It allows multiple students learn knowledge from both individual instances and instance relations in a collaborative way. While learning from themselves with self-distillation, they can also guide each other via online distillation. The experiments and ablation studies on four image datasets demonstrate that the proposed CTSL-MKT significantly outperforms the state-of-the-art KD methods.
Learning Hyperbolic Representations for Unsupervised 3D Segmentation
Dec 03, 2020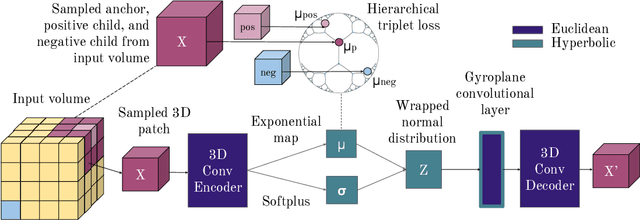
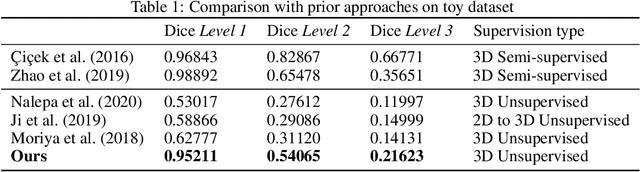
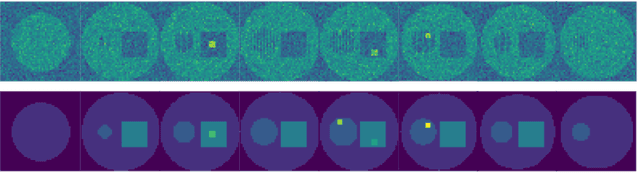
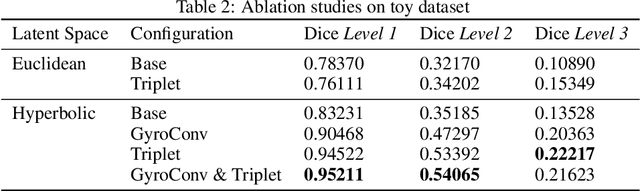
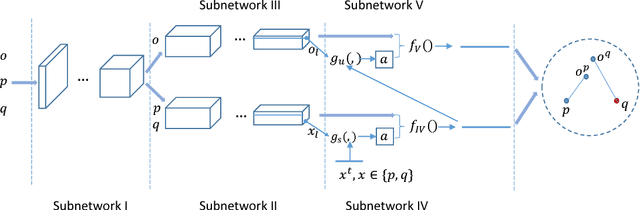
There exists a need for unsupervised 3D segmentation on complex volumetric data, particularly when annotation ability is limited or discovery of new categories is desired. Using the observation that much of 3D volumetric data is innately hierarchical, we propose learning effective representations of 3D patches for unsupervised segmentation through a variational autoencoder (VAE) with a hyperbolic latent space and a proposed gyroplane convolutional layer, which better models the underlying hierarchical structure within a 3D image. We also introduce a hierarchical triplet loss and multi-scale patch sampling scheme to embed relationships across varying levels of granularity. We demonstrate the effectiveness of our hyperbolic representations for unsupervised 3D segmentation on a hierarchical toy dataset, BraTS whole tumor dataset, and cryogenic electron microscopy data.
Cross-Domain Image Retrieval with Attention Modeling
Sep 06, 2017

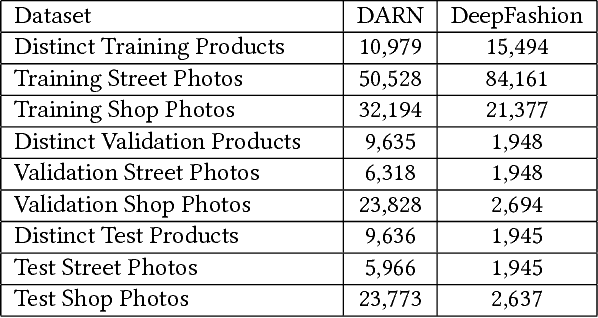
With the proliferation of e-commerce websites and the ubiquitousness of smart phones, cross-domain image retrieval using images taken by smart phones as queries to search products on e-commerce websites is emerging as a popular application. One challenge of this task is to locate the attention of both the query and database images. In particular, database images, e.g. of fashion products, on e-commerce websites are typically displayed with other accessories, and the images taken by users contain noisy background and large variations in orientation and lighting. Consequently, their attention is difficult to locate. In this paper, we exploit the rich tag information available on the e-commerce websites to locate the attention of database images. For query images, we use each candidate image in the database as the context to locate the query attention. Novel deep convolutional neural network architectures, namely TagYNet and CtxYNet, are proposed to learn the attention weights and then extract effective representations of the images. Experimental results on public datasets confirm that our approaches have significant improvement over the existing methods in terms of the retrieval accuracy and efficiency.
* 8 pages with an extra reference page