 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Guided Fine-Tuning for Large-Scale Material Transfer
Jul 08, 2020
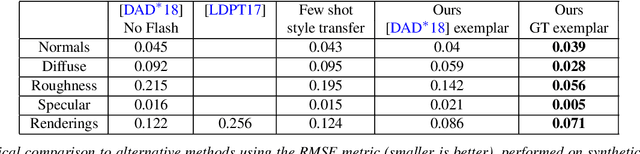
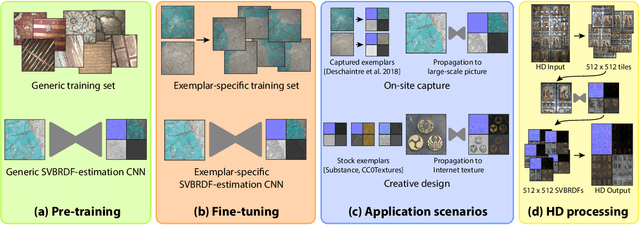
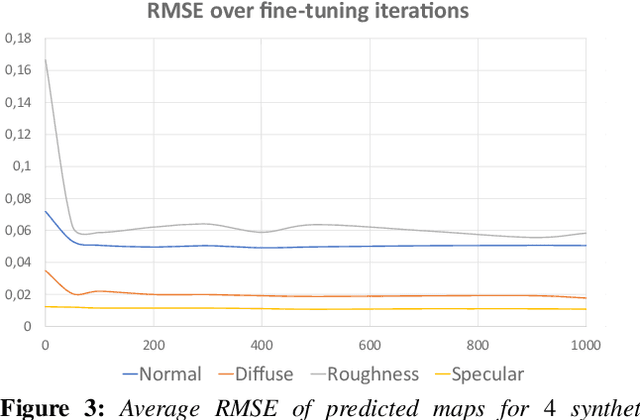

We present a method to transfer the appearance of one or a few exemplar SVBRDFs to a target image representing similar materials. Our solution is extremely simple: we fine-tune a deep appearance-capture network on the provided exemplars, such that it learns to extract similar SVBRDF values from the target image. We introduce two novel material capture and design workflows that demonstrate the strength of this simple approach. Our first workflow allows to produce plausible SVBRDFs of large-scale objects from only a few pictures. Specifically, users only need take a single picture of a large surface and a few close-up flash pictures of some of its details. We use existing methods to extract SVBRDF parameters from the close-ups, and our method to transfer these parameters to the entire surface, enabling the lightweight capture of surfaces several meters wide such as murals, floors and furniture. In our second workflow, we provide a powerful way for users to create large SVBRDFs from internet pictures by transferring the appearance of existing, pre-designed SVBRDFs. By selecting different exemplars, users can control the materials assigned to the target image, greatly enhancing the creative possibilities offered by deep appearance capture.
GAP++: Learning to generate target-conditioned adversarial examples
Jun 09, 2020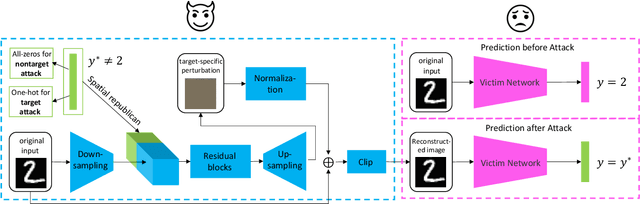
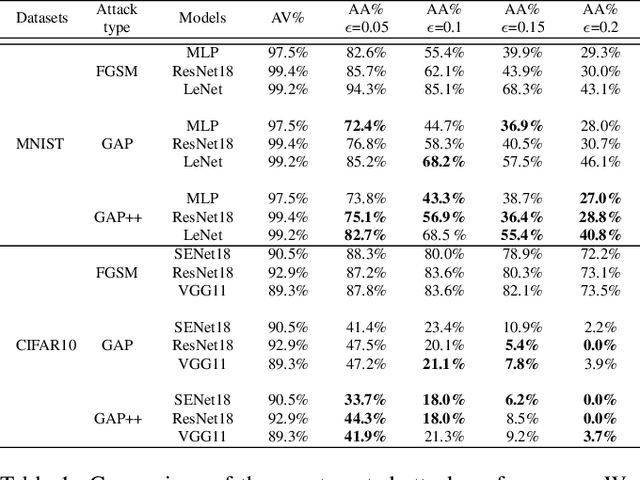
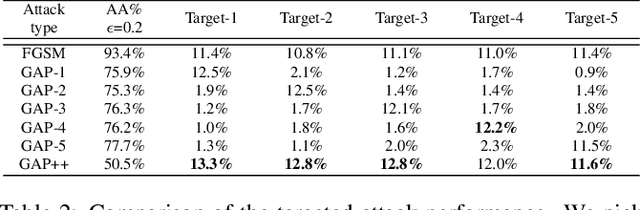
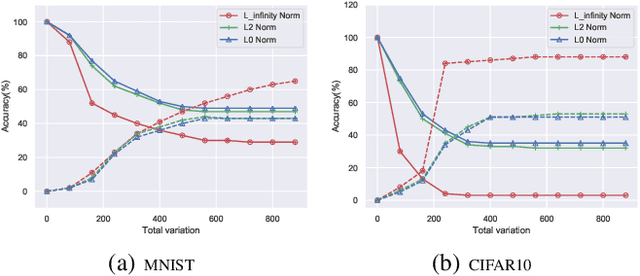
Adversarial examples are perturbed inputs which can cause a serious threat for machine learning models. Finding these perturbations is such a hard task that we can only use the iterative methods to traverse. For computational efficiency, recent works use adversarial generative networks to model the distribution of both the universal or image-dependent perturbations directly. However, these methods generate perturbations only rely on input images. In this work, we propose a more general-purpose framework which infers target-conditioned perturbations dependent on both input image and target label. Different from previous single-target attack models, our model can conduct target-conditioned attacks by learning the relations of attack target and the semantics in image. Using extensive experiments on the datasets of MNIST and CIFAR10, we show that our method achieves superior performance with single target attack models and obtains high fooling rates with small perturbation norms.
Fusion of an Ensemble of Augmented Image Detectors for Robust Object Detection
Mar 17, 2018
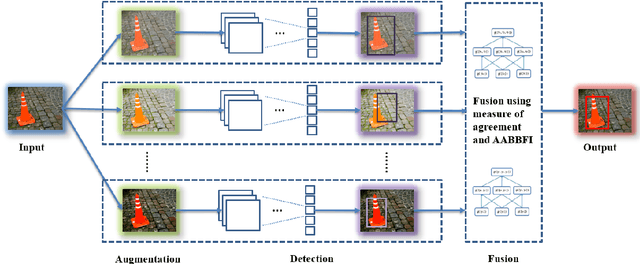
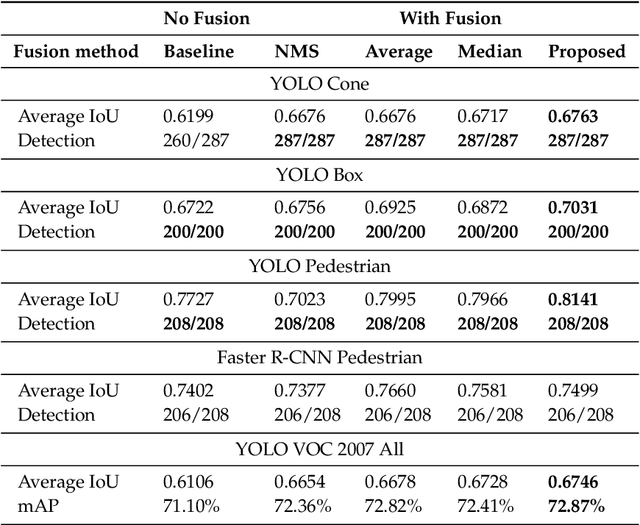
A significant challenge in object detection is accurate identification of an object's position in image space, whereas one algorithm with one set of parameters is usually not enough, and the fusion of multiple algorithms and/or parameters can lead to more robust results. Herein, a new computational intelligence fusion approach based on the dynamic analysis of agreement among object detection outputs is proposed. Furthermore, we propose an online versus just in training image augmentation strategy. Experiments comparing the results both with and without fusion are presented. We demonstrate that the augmented and fused combination results are the best, with respect to higher accuracy rates and reduction of outlier influences. The approach is demonstrated in the context of cone, pedestrian and box detection for Advanced Driver Assistance Systems (ADAS) applications.
Materials for Masses: SVBRDF Acquisition with a Single Mobile Phone Image
Apr 16, 2018

We propose a material acquisition approach to recover the spatially-varying BRDF and normal map of a near-planar surface from a single image captured by a handheld mobile phone camera. Our method images the surface under arbitrary environment lighting with the flash turned on, thereby avoiding shadows while simultaneously capturing high-frequency specular highlights. We train a CNN to regress an SVBRDF and surface normals from this image. Our network is trained using a large-scale SVBRDF dataset and designed to incorporate physical insights for material estimation, including an in-network rendering layer to model appearance and a material classifier to provide additional supervision during training. We refine the results from the network using a dense CRF module whose terms are designed specifically for our task. The framework is trained end-to-end and produces high quality results for a variety of materials. We provide extensive ablation studies to evaluate our network on both synthetic and real data, while demonstrating significant improvements in comparisons with prior works.
Learning to do multiframe blind deconvolution unsupervisedly
Jun 02, 2020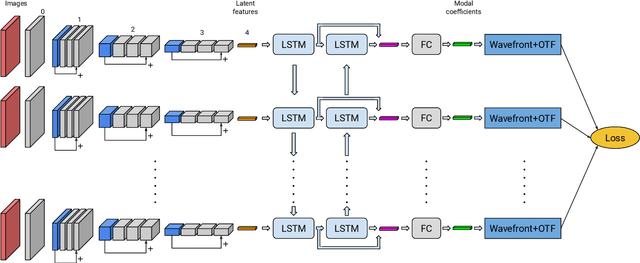

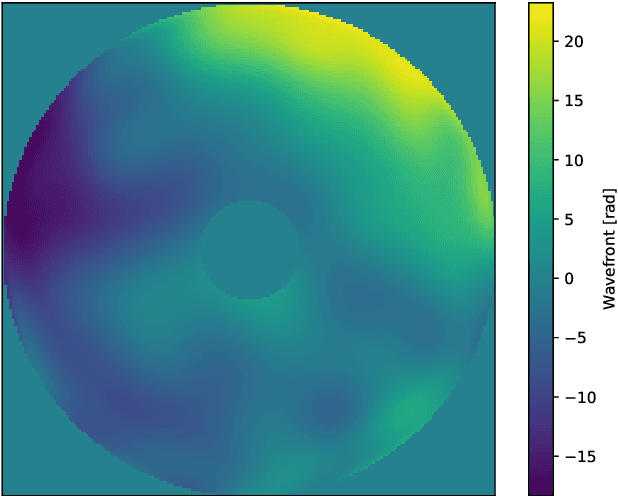

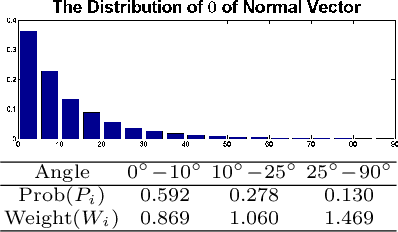
Observation from ground based telescopes are affected by the presence of the Earth atmosphere, which severely perturbs them. The use of adaptive optics techniques has allowed us to partly beat this limitation. However, image selection or post-facto image reconstruction methods are routinely needed to reach the diffraction limit of telescopes. Deep learning has been recently used to accelerate these image reconstructions. Currently, these deep neural networks are trained with supervision, so that standard deconvolution algorithms need to be applied a-priori to generate the training sets. Our aim is to propose an unsupervised method which can then be trained simply with observations and check it with data from the FastCam instrument. We use a neural model composed of three neural networks that are trained end-to-end by leveraging the linear image formation theory to construct a physically-motivated loss function. The analysis of the trained neural model shows that multiframe blind deconvolution can be trained self-supervisedly, i.e., using only observations. The output of the network are the corrected images and also estimations of the instantaneous wavefronts. The network model is of the order of 1000 times faster than applying standard deconvolution based on optimization. With some work, the model can bed used on real-time at the telescope.
High Resolution, Deep Imaging Using Confocal Time-of-flight Diffuse Optical Tomography
Jan 27, 2021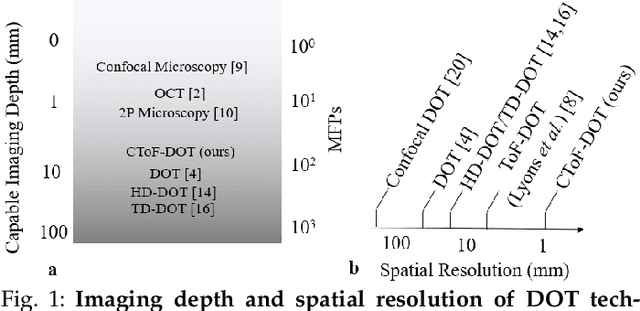
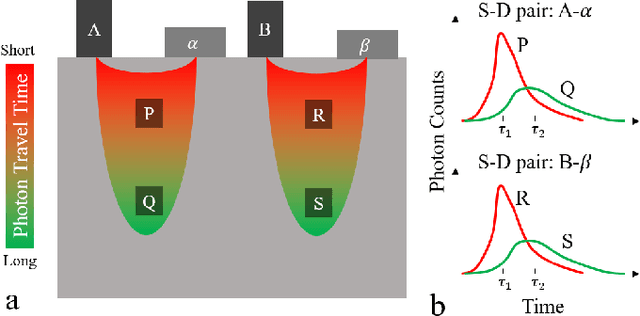
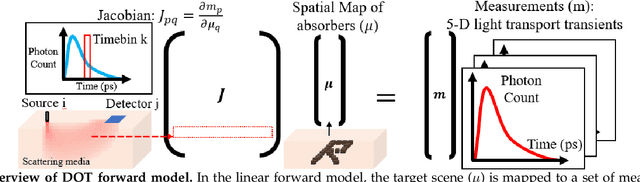
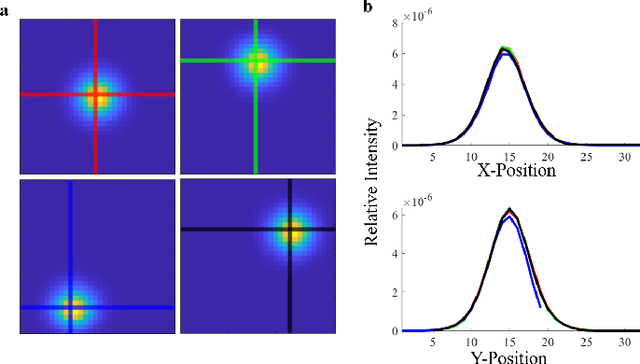
Light scattering by tissue severely limits both how deep beneath the surface one can image, and at what spatial resolution one can obtain from these images. Diffuse optical tomography (DOT) has emerged as one of the most powerful techniques for imaging deep within tissue -- well beyond the conventional $\sim$ 10-15 mean scattering lengths tolerated by ballistic imaging techniques such as confocal and two-photon microscopy. Unfortunately, existing DOT systems are quite limited and achieve only centimeter-scale resolution. Furthermore, they also suffer from slow acquisition times and extremely slow reconstruction speeds making real-time imaging infeasible. We show that time-of-flight diffuse optical tomography (ToF-DOT) and its confocal variant (CToF-DOT), by exploiting the photon travel time information, allow us to achieve millimeter spatial resolution in the highly scattered diffusion regime ($>50$ mean free paths). In addition, we demonstrate that two additional innovations: focusing on confocal measurements, and multiplexing the illumination sources allow us to significantly reduce the scan time to acquire measurements. Finally, we also rely on a novel convolutional approximation that allows us to develop a fast reconstruction algorithm achieving a 100 $\times$ speedup in reconstruction time compared to traditional DOT reconstruction techniques. Together, we believe that these technical advances, serve as the first step towards real-time, millimeter resolution, deep tissue imaging using diffuse optical tomography.
Adaptive convolutional neural networks for k-space data interpolation in fast magnetic resonance imaging
Jun 02, 2020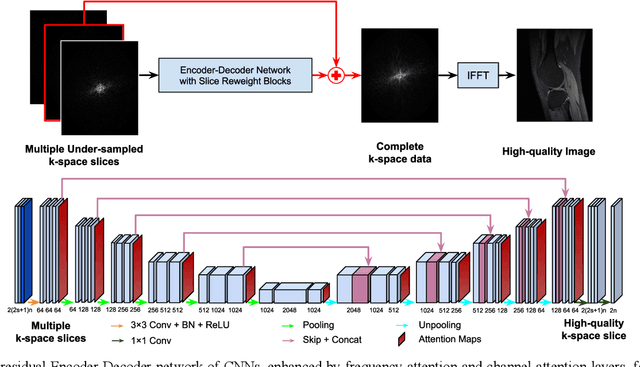
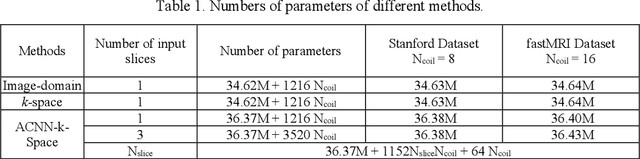
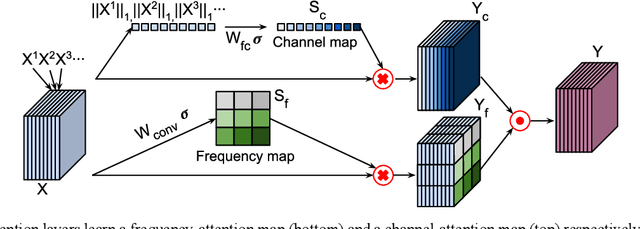
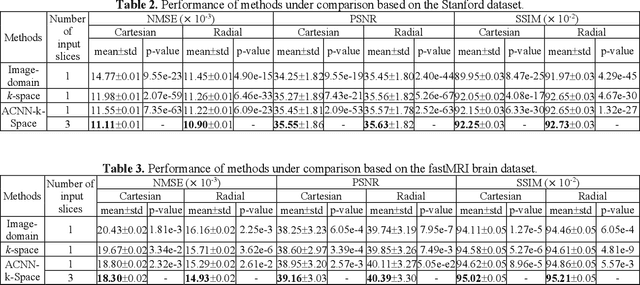
Deep learning in k-space has demonstrated great potential for image reconstruction from undersampled k-space data in fast magnetic resonance imaging (MRI). However, existing deep learning-based image reconstruction methods typically apply weight-sharing convolutional neural networks (CNNs) to k-space data without taking into consideration the k-space data's spatial frequency properties, leading to ineffective learning of the image reconstruction models. Moreover, complementary information of spatially adjacent slices is often ignored in existing deep learning methods. To overcome such limitations, we develop a deep learning algorithm, referred to as adaptive convolutional neural networks for k-space data interpolation (ACNN-k-Space), which adopts a residual Encoder-Decoder network architecture to interpolate the undersampled k-space data by integrating spatially contiguous slices as multi-channel input, along with k-space data from multiple coils if available. The network is enhanced by self-attention layers to adaptively focus on k-space data at different spatial frequencies and channels. We have evaluated our method on two public datasets and compared it with state-of-the-art existing methods. Ablation studies and experimental results demonstrate that our method effectively reconstructs images from undersampled k-space data and achieves significantly better image reconstruction performance than current state-of-the-art techniques.
Exploring Adversarial Fake Images on Face Manifold
Jan 09, 2021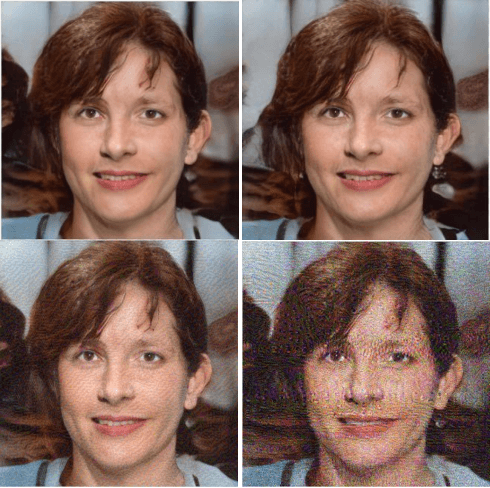
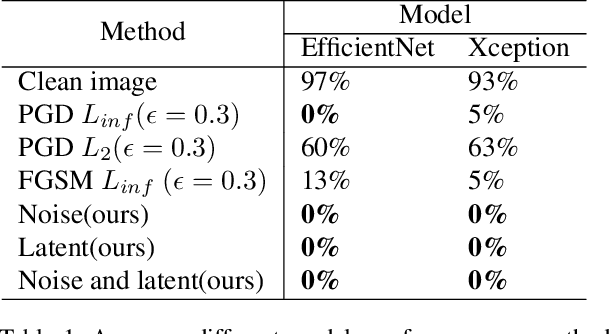
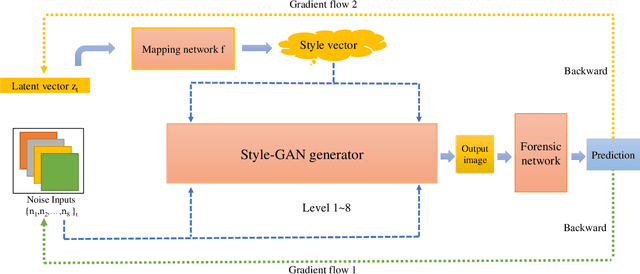
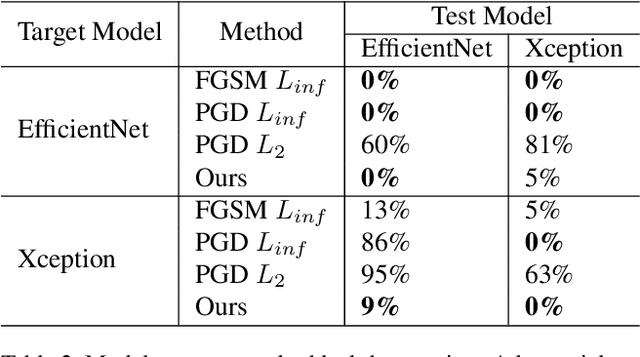
Images synthesized by powerful generative adversarial network (GAN) based methods have drawn moral and privacy concerns. Although image forensic models have reached great performance in detecting fake images from real ones, these models can be easily fooled with a simple adversarial attack. But, the noise adding adversarial samples are also arousing suspicion. In this paper, instead of adding adversarial noise, we optimally search adversarial points on face manifold to generate anti-forensic fake face images. We iteratively do a gradient-descent with each small step in the latent space of a generative model, e.g. Style-GAN, to find an adversarial latent vector, which is similar to norm-based adversarial attack but in latent space. Then, the generated fake images driven by the adversarial latent vectors with the help of GANs can defeat main-stream forensic models. For examples, they make the accuracy of deepfake detection models based on Xception or EfficientNet drop from over 90% to nearly 0%, meanwhile maintaining high visual quality. In addition, we find manipulating style vector $z$ or noise vectors $n$ at different levels have impacts on attack success rate. The generated adversarial images mainly have facial texture or face attributes changing.
Learning unbiased registration and joint segmentation: evaluation on longitudinal diffusion MRI
Nov 03, 2020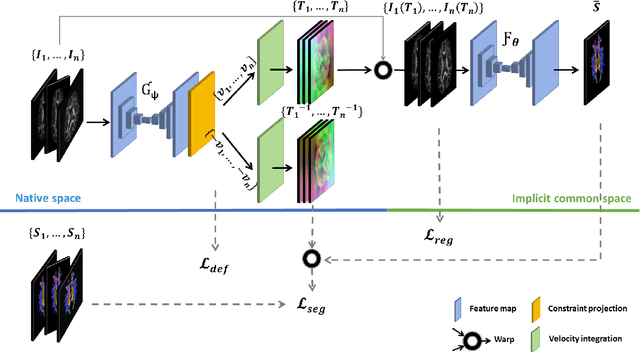
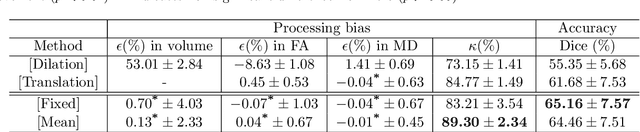
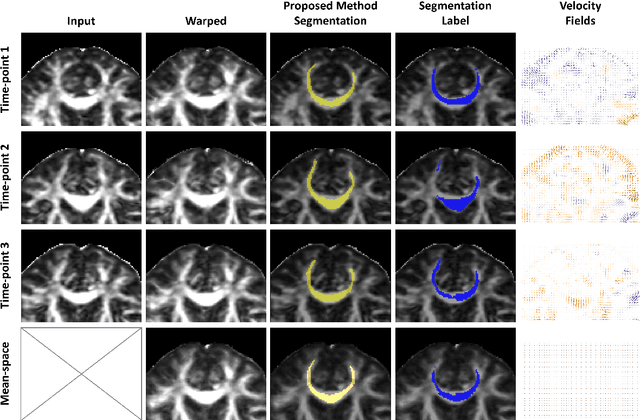
Analysis of longitudinal changes in imaging studies often involves both segmentation of structures of interest and registration of multiple timeframes. The accuracy of such analysis could benefit from a tailored framework that jointly optimizes both tasks to fully exploit the information available in the longitudinal data. Most learning-based registration algorithms, including joint optimization approaches, currently suffer from bias due to selection of a fixed reference frame and only support pairwise transformations. We here propose an analytical framework based on an unbiased learning strategy for group-wise registration that simultaneously registers images to the mean space of a group to obtain consistent segmentations. We evaluate the proposed method on longitudinal analysis of a white matter tract in a brain MRI dataset with 2-3 time-points for 3249 individuals, i.e., 8045 images in total. The reproducibility of the method is evaluated on test-retest data from 97 individuals. The results confirm that the implicit reference image is an average of the input image. In addition, the proposed framework leads to consistent segmentations and significantly lower processing bias than that of a pair-wise fixed-reference approach. This processing bias is even smaller than those obtained when translating segmentations by only one voxel, which can be attributed to subtle numerical instabilities and interpolation. Therefore, we postulate that the proposed mean-space learning strategy could be widely applied to learning-based registration tasks. In addition, this group-wise framework introduces a novel way for learning-based longitudinal studies by direct construction of an unbiased within-subject template and allowing reliable and efficient analysis of spatio-temporal imaging biomarkers.
Diffusion models for Handwriting Generation
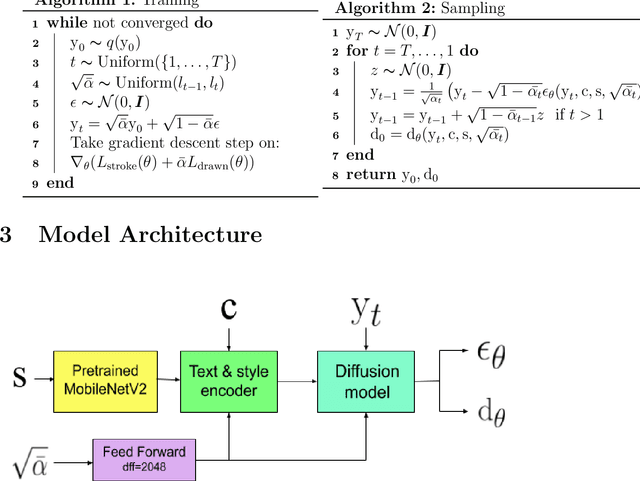
Nov 13, 2020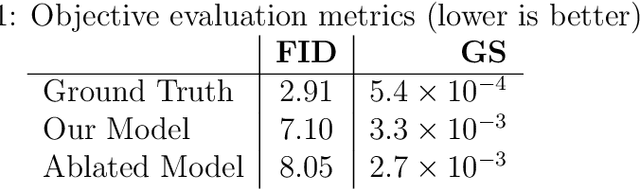

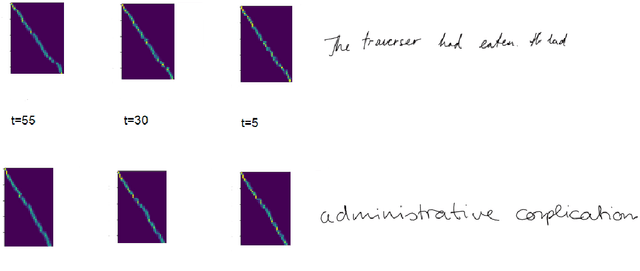
In this paper, we propose a diffusion probabilistic model for handwriting generation. Diffusion models are a class of generative models where samples start from Gaussian noise and are gradually denoised to produce output. Our method of handwriting generation does not require using any text-recognition based, writer-style based, or adversarial loss functions, nor does it require training of auxiliary networks. Our model is able to incorporate writer stylistic features directly from image data, eliminating the need for user interaction during sampling. Experiments reveal that our model is able to generate realistic , high quality images of handwritten text in a similar style to a given writer. Our implementation can be found at https://github.com/tcl9876/Diffusion-Handwriting-Generation