 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GAP++: Learning to generate target-conditioned adversarial examples
Jun 09, 2020
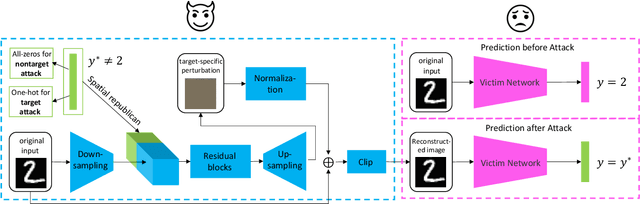
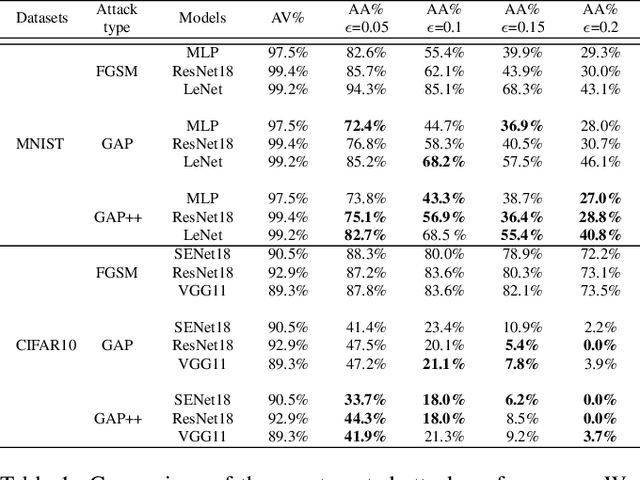
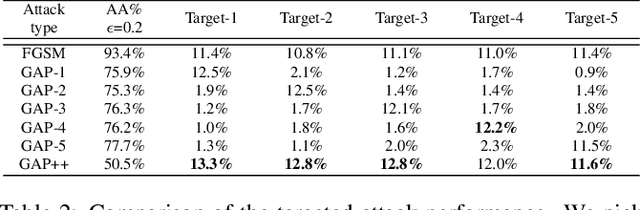
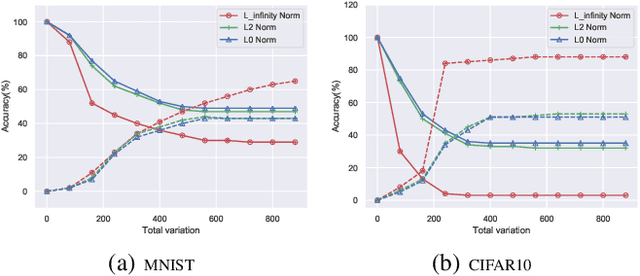
Adversarial examples are perturbed inputs which can cause a serious threat for machine learning models. Finding these perturbations is such a hard task that we can only use the iterative methods to traverse. For computational efficiency, recent works use adversarial generative networks to model the distribution of both the universal or image-dependent perturbations directly. However, these methods generate perturbations only rely on input images. In this work, we propose a more general-purpose framework which infers target-conditioned perturbations dependent on both input image and target label. Different from previous single-target attack models, our model can conduct target-conditioned attacks by learning the relations of attack target and the semantics in image. Using extensive experiments on the datasets of MNIST and CIFAR10, we show that our method achieves superior performance with single target attack models and obtains high fooling rates with small perturbation norms.
Learning to do multiframe blind deconvolution unsupervisedly
Jun 02, 2020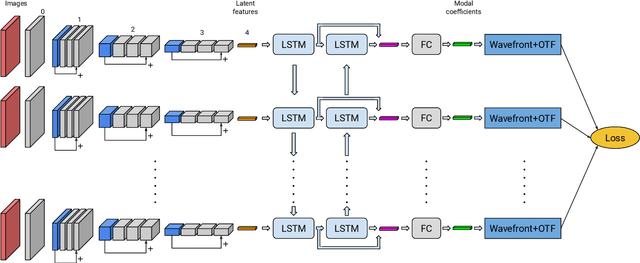

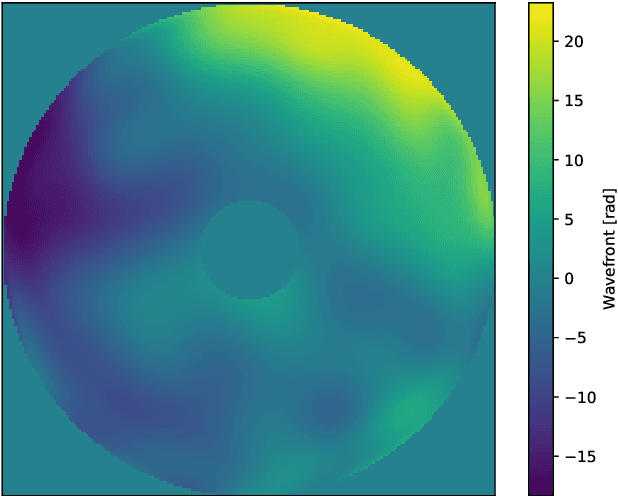

Observation from ground based telescopes are affected by the presence of the Earth atmosphere, which severely perturbs them. The use of adaptive optics techniques has allowed us to partly beat this limitation. However, image selection or post-facto image reconstruction methods are routinely needed to reach the diffraction limit of telescopes. Deep learning has been recently used to accelerate these image reconstructions. Currently, these deep neural networks are trained with supervision, so that standard deconvolution algorithms need to be applied a-priori to generate the training sets. Our aim is to propose an unsupervised method which can then be trained simply with observations and check it with data from the FastCam instrument. We use a neural model composed of three neural networks that are trained end-to-end by leveraging the linear image formation theory to construct a physically-motivated loss function. The analysis of the trained neural model shows that multiframe blind deconvolution can be trained self-supervisedly, i.e., using only observations. The output of the network are the corrected images and also estimations of the instantaneous wavefronts. The network model is of the order of 1000 times faster than applying standard deconvolution based on optimization. With some work, the model can bed used on real-time at the telescope.
Visual Relationship Detection using Scene Graphs: A Survey
May 16, 2020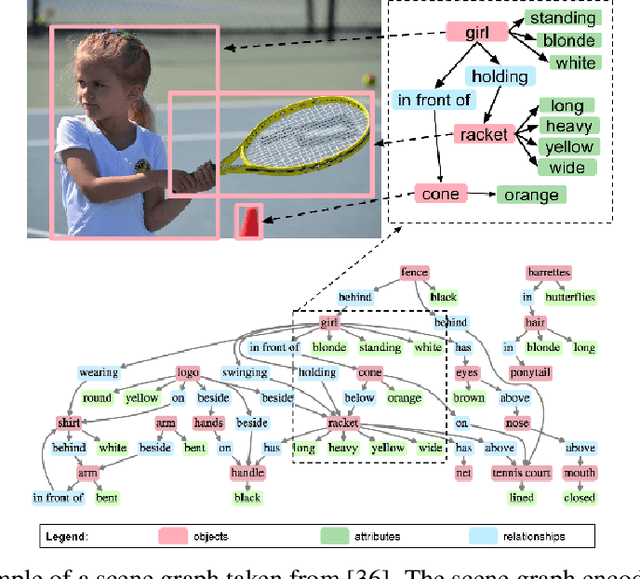
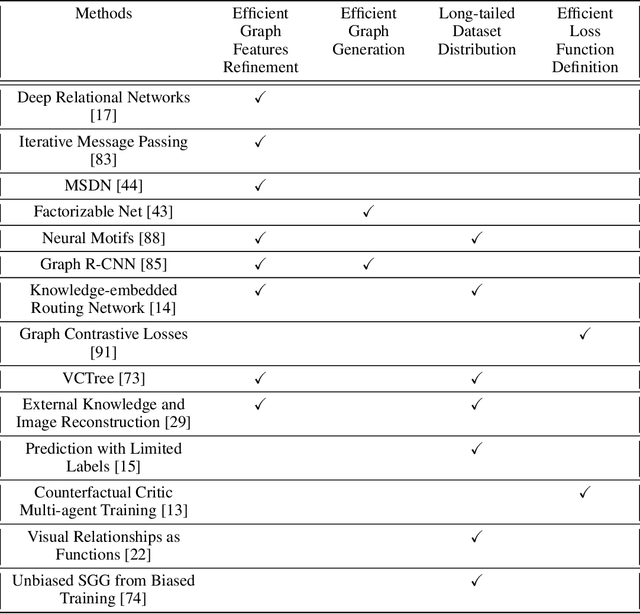
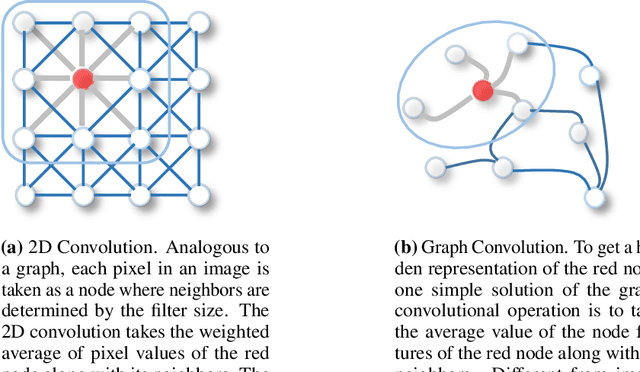
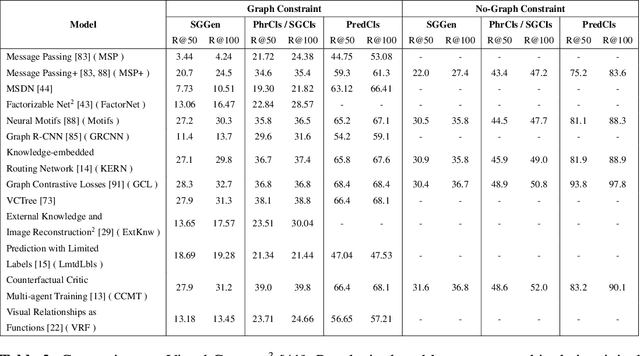
Understanding a scene by decoding the visual relationships depicted in an image has been a long studied problem. While the recent advances in deep learning and the usage of deep neural networks have achieved near human accuracy on many tasks, there still exists a pretty big gap between human and machine level performance when it comes to various visual relationship detection tasks. Developing on earlier tasks like object recognition, segmentation and captioning which focused on a relatively coarser image understanding, newer tasks have been introduced recently to deal with a finer level of image understanding. A Scene Graph is one such technique to better represent a scene and the various relationships present in it. With its wide number of applications in various tasks like Visual Question Answering, Semantic Image Retrieval, Image Generation, among many others, it has proved to be a useful tool for deeper and better visual relationship understanding. In this paper, we present a detailed survey on the various techniques for scene graph generation, their efficacy to represent visual relationships and how it has been used to solve various downstream tasks. We also attempt to analyze the various future directions in which the field might advance in the future. Being one of the first papers to give a detailed survey on this topic, we also hope to give a succinct introduction to scene graphs, and guide practitioners while developing approaches for their applications.
An Adaptive Parameter Estimation for Guided Filter based Image Deconvolution
Sep 06, 2016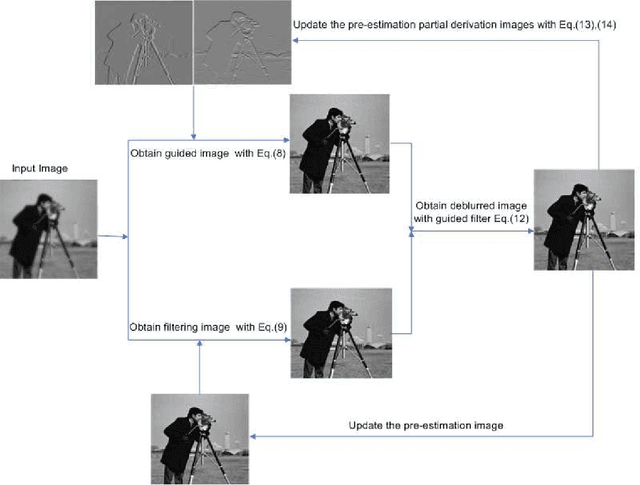

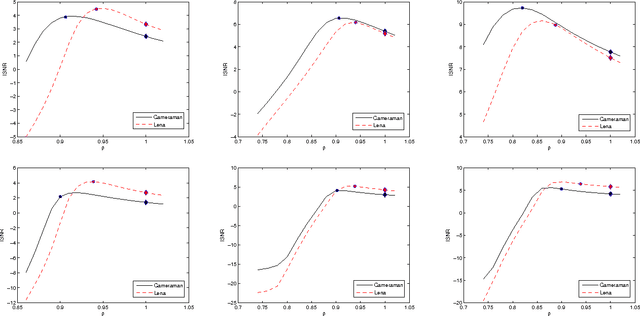

Image deconvolution is still to be a challenging ill-posed problem for recovering a clear image from a given blurry image, when the point spread function is known. Although competitive deconvolution methods are numerically impressive and approach theoretical limits, they are becoming more complex, making analysis, and implementation difficult. Furthermore, accurate estimation of the regularization parameter is not easy for successfully solving image deconvolution problems. In this paper, we develop an effective approach for image restoration based on one explicit image filter - guided filter. By applying the decouple of denoising and deblurring techniques to the deconvolution model, we reduce the optimization complexity and achieve a simple but effective algorithm to automatically compute the parameter in each iteration, which is based on Morozov's discrepancy principle. Experimental results demonstrate that the proposed algorithm outperforms many state-of-the-art deconvolution methods in terms of both ISNR and visual quality.
Adaptive convolutional neural networks for k-space data interpolation in fast magnetic resonance imaging
Jun 02, 2020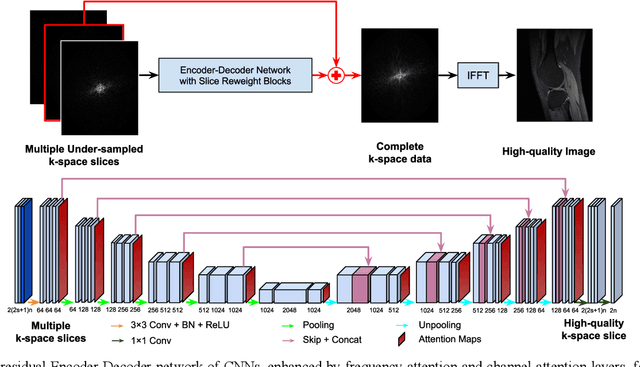
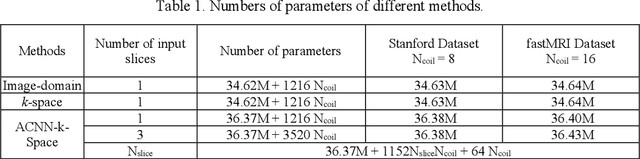
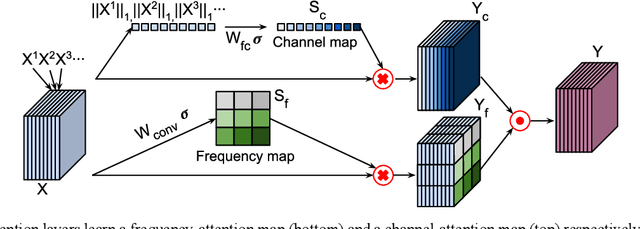
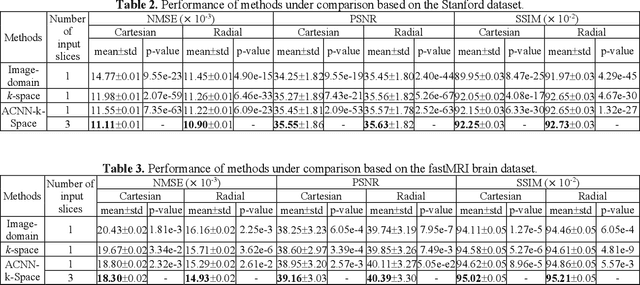
Deep learning in k-space has demonstrated great potential for image reconstruction from undersampled k-space data in fast magnetic resonance imaging (MRI). However, existing deep learning-based image reconstruction methods typically apply weight-sharing convolutional neural networks (CNNs) to k-space data without taking into consideration the k-space data's spatial frequency properties, leading to ineffective learning of the image reconstruction models. Moreover, complementary information of spatially adjacent slices is often ignored in existing deep learning methods. To overcome such limitations, we develop a deep learning algorithm, referred to as adaptive convolutional neural networks for k-space data interpolation (ACNN-k-Space), which adopts a residual Encoder-Decoder network architecture to interpolate the undersampled k-space data by integrating spatially contiguous slices as multi-channel input, along with k-space data from multiple coils if available. The network is enhanced by self-attention layers to adaptively focus on k-space data at different spatial frequencies and channels. We have evaluated our method on two public datasets and compared it with state-of-the-art existing methods. Ablation studies and experimental results demonstrate that our method effectively reconstructs images from undersampled k-space data and achieves significantly better image reconstruction performance than current state-of-the-art techniques.
Guided Fine-Tuning for Large-Scale Material Transfer
Jul 08, 2020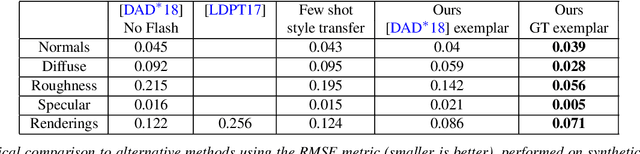
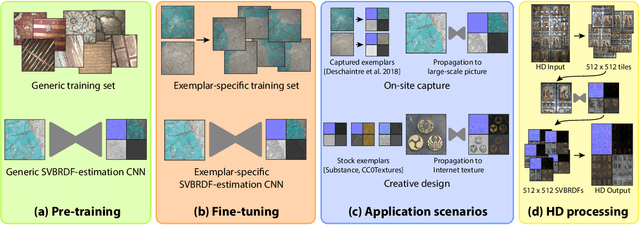
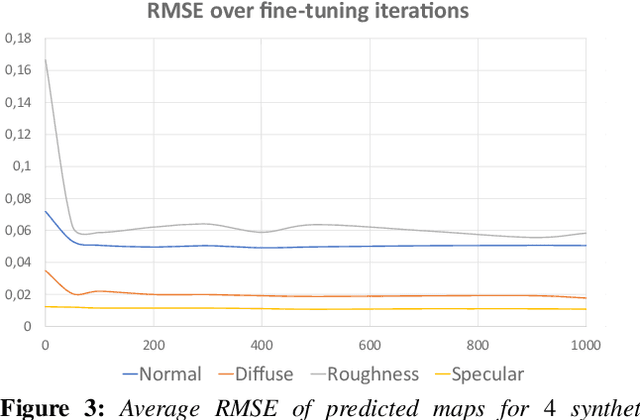

We present a method to transfer the appearance of one or a few exemplar SVBRDFs to a target image representing similar materials. Our solution is extremely simple: we fine-tune a deep appearance-capture network on the provided exemplars, such that it learns to extract similar SVBRDF values from the target image. We introduce two novel material capture and design workflows that demonstrate the strength of this simple approach. Our first workflow allows to produce plausible SVBRDFs of large-scale objects from only a few pictures. Specifically, users only need take a single picture of a large surface and a few close-up flash pictures of some of its details. We use existing methods to extract SVBRDF parameters from the close-ups, and our method to transfer these parameters to the entire surface, enabling the lightweight capture of surfaces several meters wide such as murals, floors and furniture. In our second workflow, we provide a powerful way for users to create large SVBRDFs from internet pictures by transferring the appearance of existing, pre-designed SVBRDFs. By selecting different exemplars, users can control the materials assigned to the target image, greatly enhancing the creative possibilities offered by deep appearance capture.
A smartphone based multi input workflow for non-invasive estimation of haemoglobin levels using machine learning techniques
Nov 29, 2020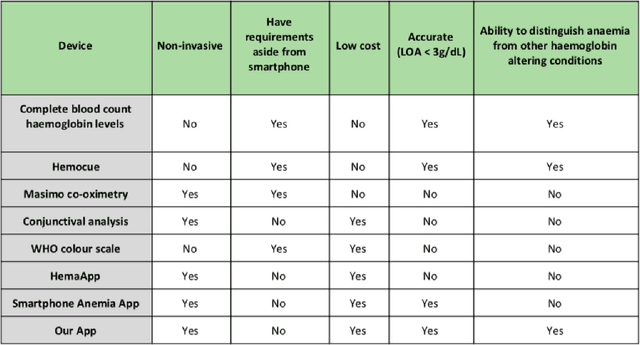
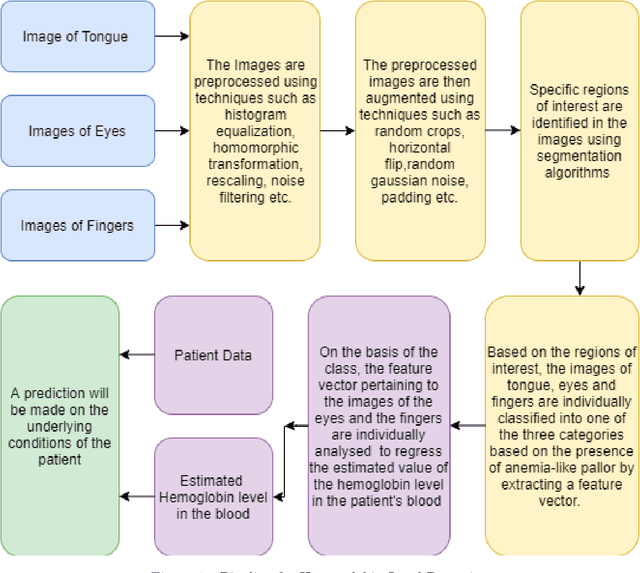
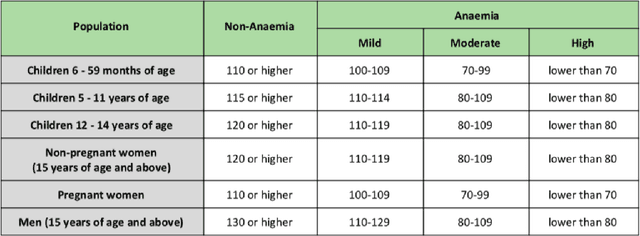
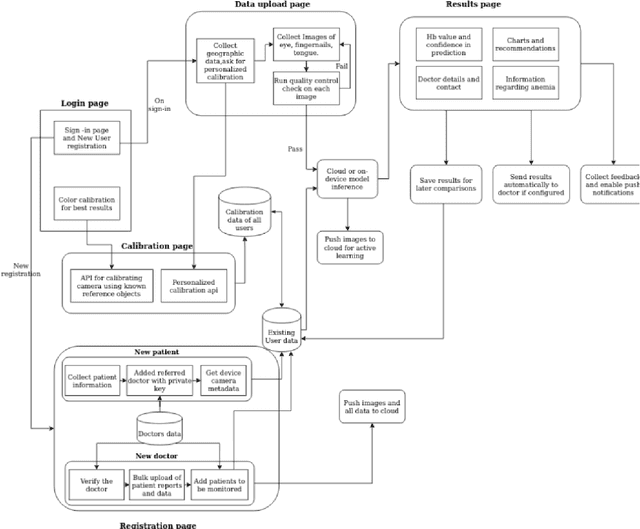
We suggest a low cost, non invasive healthcare system that measures haemoglobin levels in patients and can be used as a preliminary diagnostic test for anaemia. A combination of image processing, machine learning and deep learning techniques are employed to develop predictive models to measure haemoglobin levels. This is achieved through the color analysis of the fingernail beds, palpebral conjunctiva and tongue of the patients. This predictive model is then encapsulated in a healthcare application. This application expedites data collection and facilitates active learning of the model. It also incorporates personalized calibration of the model for each patient, assisting in the continual monitoring of the haemoglobin levels of the patient. Upon validating this framework using data, it can serve as a highly accurate preliminary diagnostic test for anaemia.
Relative Depth Estimation as a Ranking Problem
Oct 14, 2020



We present a formulation of the relative depth estimation from a single image problem, as a ranking problem. By reformulating the problem this way, we were able to utilize literature on the ranking problem, and apply the existing knowledge to achieve better results. To this end, we have introduced a listwise ranking loss borrowed from ranking literature, weighted ListMLE, to the relative depth estimation problem. We have also brought a new metric which considers pixel depth ranking accuracy, on which our method is stronger.
Disentangling Latent Space for Unsupervised Semantic Face Editing
Nov 05, 2020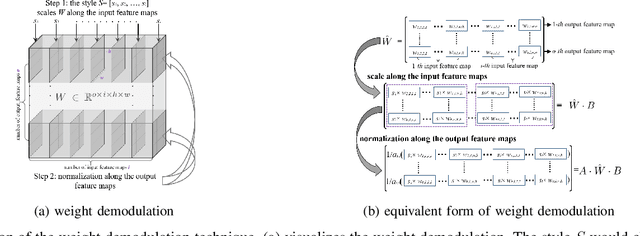
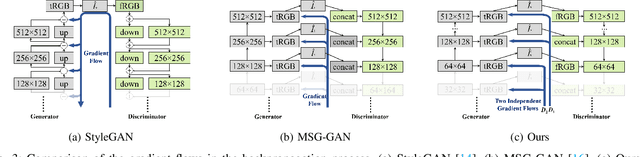

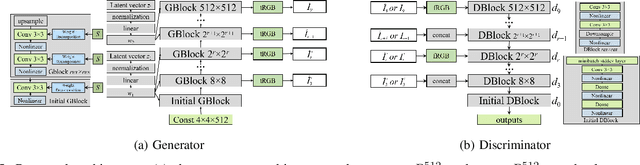
Editing facial images created by StyleGAN is a popular research topic with important applications. Through editing the latent vectors, it is possible to control the facial attributes such as smile, age, \textit{etc}. However, facial attributes are entangled in the latent space and this makes it very difficult to independently control a specific attribute without affecting the others. The key to developing neat semantic control is to completely disentangle the latent space and perform image editing in an unsupervised manner. In this paper, we present a new technique termed Structure-Texture Independent Architecture with Weight Decomposition and Orthogonal Regularization (STIA-WO) to disentangle the latent space. The GAN model, applying STIA-WO, is referred to as STGAN-WO. STGAN-WO performs weight decomposition by utilizing the style vector to construct a fully controllable weight matrix for controlling the image synthesis, and utilizes orthogonal regularization to ensure each entry of the style vector only controls one factor of variation. To further disentangle the facial attributes, STGAN-WO introduces a structure-texture independent architecture which utilizes two independently and identically distributed (i.i.d.) latent vectors to control the synthesis of the texture and structure components in a disentangled way.Unsupervised semantic editing is achieved by moving the latent code in the coarse layers along its orthogonal directions to change texture related attributes or changing the latent code in the fine layers to manipulate structure related ones. We present experimental results which show that our new STGAN-WO can achieve better attribute editing than state of the art methods (The code is available at https://github.com/max-liu-112/STGAN-WO)
Spatiotemporal tomography based on scattered multiangular signals and its application for resolving evolving clouds using moving platforms
Dec 06, 2020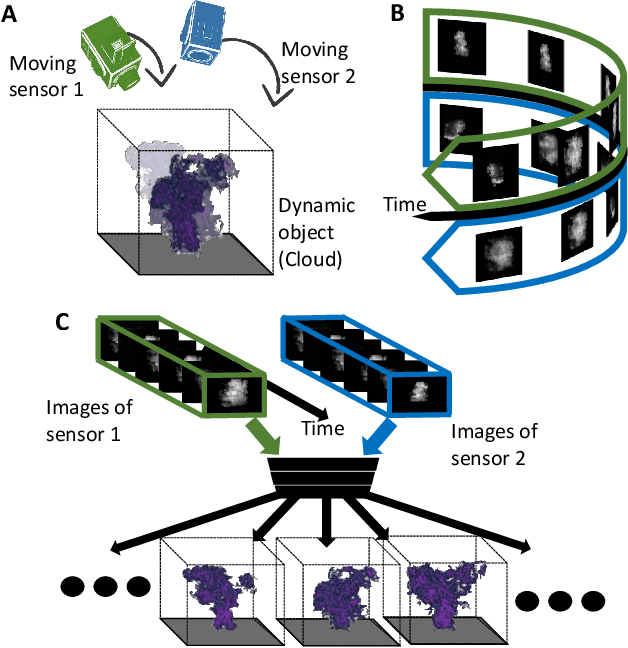
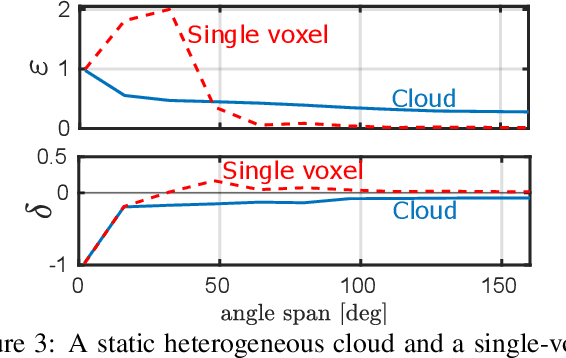
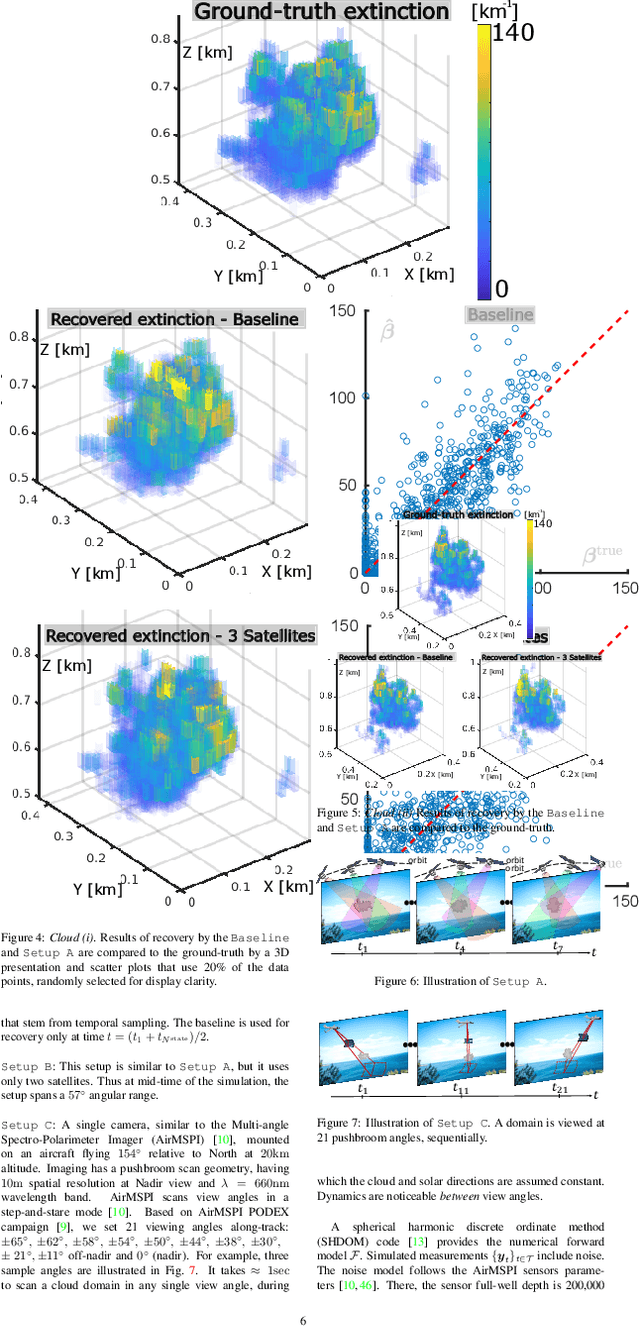
We derive computed tomography (CT) of a time-varying volumetric translucent object, using a small number of moving cameras. We particularly focus on passive scattering tomography, which is a non-linear problem. We demonstrate the approach on dynamic clouds, as clouds have a major effect on Earth's climate. State of the art scattering CT assumes a static object. Existing 4D CT methods rely on a linear image formation model and often on significant priors. In this paper, the angular and temporal sampling rates needed for a proper recovery are discussed. If these rates are used, the paper leads to a representation of the time-varying object, which simplifies 4D CT tomography. The task is achieved using gradient-based optimization. We demonstrate this in physics-based simulations and in an experiment that had yielded real-world data.