 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ChineseFoodNet: A large-scale Image Dataset for Chinese Food Recognition
Oct 15, 2017


In this paper, we introduce a new and challenging large-scale food image dataset called "ChineseFoodNet", which aims to automatically recognizing pictured Chinese dishes. Most of the existing food image datasets collected food images either from recipe pictures or selfie. In our dataset, images of each food category of our dataset consists of not only web recipe and menu pictures but photos taken from real dishes, recipe and menu as well. ChineseFoodNet contains over 180,000 food photos of 208 categories, with each category covering a large variations in presentations of same Chinese food. We present our efforts to build this large-scale image dataset, including food category selection, data collection, and data clean and label, in particular how to use machine learning methods to reduce manual labeling work that is an expensive process. We share a detailed benchmark of several state-of-the-art deep convolutional neural networks (CNNs) on ChineseFoodNet. We further propose a novel two-step data fusion approach referred as "TastyNet", which combines prediction results from different CNNs with voting method. Our proposed approach achieves top-1 accuracies of 81.43% on the validation set and 81.55% on the test set, respectively. The latest dataset is public available for research and can be achieved at https://sites.google.com/view/chinesefoodnet.
Learning Representations For Images With Hierarchical Labels
Apr 11, 2020

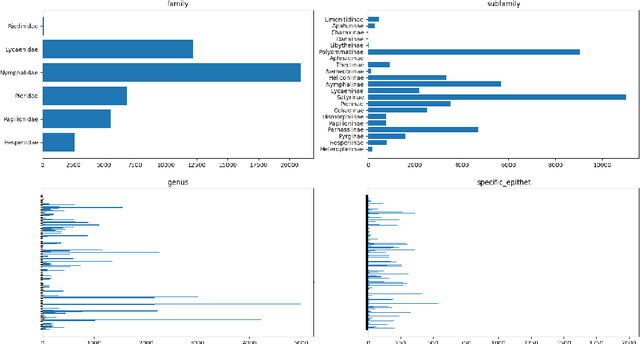

Image classification has been studied extensively but there has been limited work in the direction of using non-conventional, external guidance other than traditional image-label pairs to train such models. In this thesis we present a set of methods to leverage information about the semantic hierarchy induced by class labels. In the first part of the thesis, we inject label-hierarchy knowledge to an arbitrary classifier and empirically show that availability of such external semantic information in conjunction with the visual semantics from images boosts overall performance. Taking a step further in this direction, we model more explicitly the label-label and label-image interactions by using order-preserving embedding-based models, prevalent in natural language, and tailor them to the domain of computer vision to perform image classification. Although, contrasting in nature, both the CNN-classifiers injected with hierarchical information, and the embedding-based models outperform a hierarchy-agnostic model on the newly presented, real-world ETH Entomological Collection image dataset https://www.research-collection.ethz.ch/handle/20.500.11850/365379.
Fine-Grained Visual Classification via Simultaneously Learning of Multi-regional Multi-grained Features
Jan 31, 2021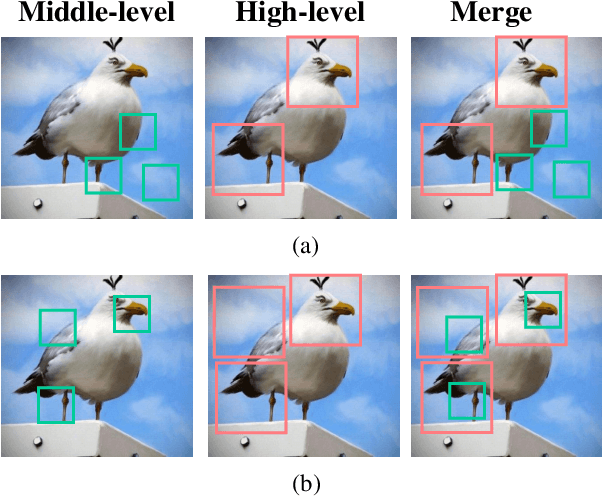
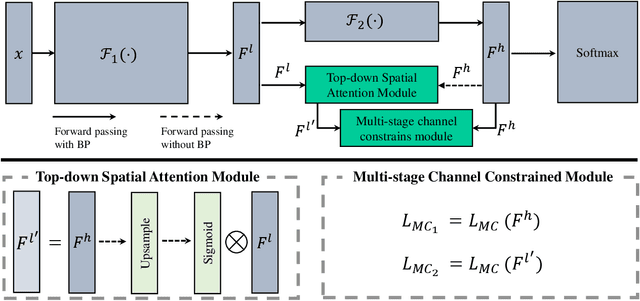
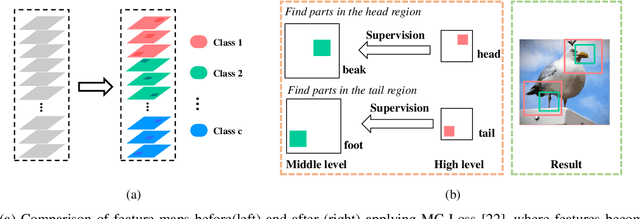

Fine-grained visual classification is a challenging task that recognizes the sub-classes belonging to the same meta-class. Large inter-class similarity and intra-class variance is the main challenge of this task. Most exiting methods try to solve this problem by designing complex model structures to explore more minute and discriminative regions. In this paper, we argue that mining multi-regional multi-grained features is precisely the key to this task. Specifically, we introduce a new loss function, termed top-down spatial attention loss (TDSA-Loss), which contains a multi-stage channel constrained module and a top-down spatial attention module. The multi-stage channel constrained module aims to make the feature channels in different stages category-aligned. Meanwhile, the top-down spatial attention module uses the attention map generated by high-level aligned feature channels to make middle-level aligned feature channels to focus on particular regions. Finally, we can obtain multiple discriminative regions on high-level feature channels and obtain multiple more minute regions within these discriminative regions on middle-level feature channels. In summary, we obtain multi-regional multi-grained features. Experimental results over four widely used fine-grained image classification datasets demonstrate the effectiveness of the proposed method. Ablative studies further show the superiority of two modules in the proposed method. Codes are available at: https://github.com/dongliangchang/Top-Down-Spatial-Attention-Loss.
Double Sparse Multi-Frame Image Super Resolution
Dec 02, 2015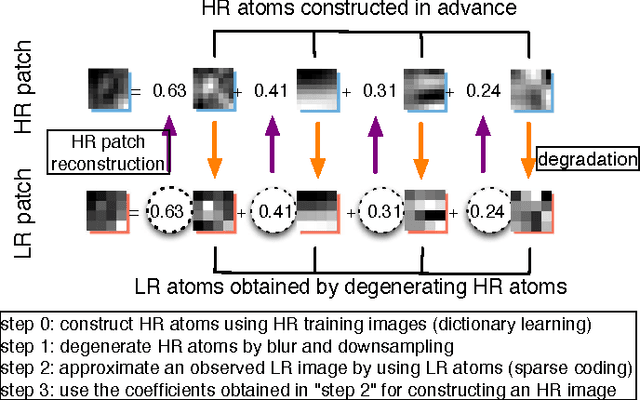



A large number of image super resolution algorithms based on the sparse coding are proposed, and some algorithms realize the multi-frame super resolution. In multi-frame super resolution based on the sparse coding, both accurate image registration and sparse coding are required. Previous study on multi-frame super resolution based on sparse coding firstly apply block matching for image registration, followed by sparse coding to enhance the image resolution. In this paper, these two problems are solved by optimizing a single objective function. The results of numerical experiments support the effectiveness of the proposed approch.
Mixup Without Hesitation
Jan 12, 2021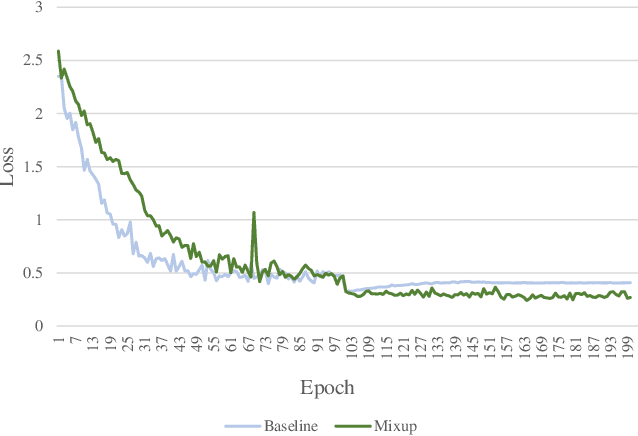
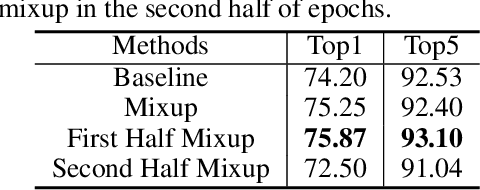


Mixup linearly interpolates pairs of examples to form new samples, which is easy to implement and has been shown to be effective in image classification tasks. However, there are two drawbacks in mixup: one is that more training epochs are needed to obtain a well-trained model; the other is that mixup requires tuning a hyper-parameter to gain appropriate capacity but that is a difficult task. In this paper, we find that mixup constantly explores the representation space, and inspired by the exploration-exploitation dilemma in reinforcement learning, we propose mixup Without hesitation (mWh), a concise, effective, and easy-to-use training algorithm. We show that mWh strikes a good balance between exploration and exploitation by gradually replacing mixup with basic data augmentation. It can achieve a strong baseline with less training time than original mixup and without searching for optimal hyper-parameter, i.e., mWh acts as mixup without hesitation. mWh can also transfer to CutMix, and gain consistent improvement on other machine learning and computer vision tasks such as object detection. Our code is open-source and available at https://github.com/yuhao318/mwh
DISCO: Dynamic and Invariant Sensitive Channel Obfuscation for deep neural networks
Dec 20, 2020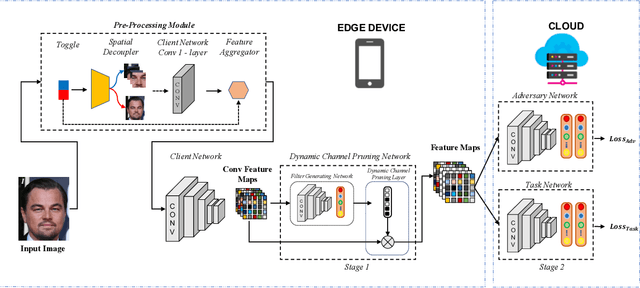
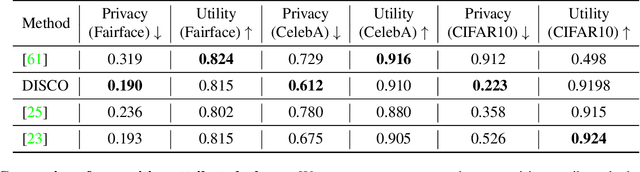

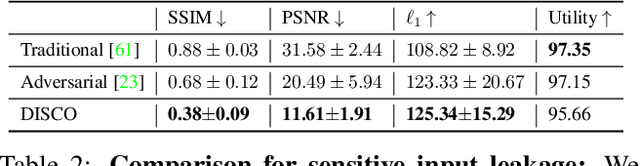
Recent deep learning models have shown remarkable performance in image classification. While these deep learning systems are getting closer to practical deployment, the common assumption made about data is that it does not carry any sensitive information. This assumption may not hold for many practical cases, especially in the domain where an individual's personal information is involved, like healthcare and facial recognition systems. We posit that selectively removing features in this latent space can protect the sensitive information and provide a better privacy-utility trade-off. Consequently, we propose DISCO which learns a dynamic and data driven pruning filter to selectively obfuscate sensitive information in the feature space. We propose diverse attack schemes for sensitive inputs \& attributes and demonstrate the effectiveness of DISCO against state-of-the-art methods through quantitative and qualitative evaluation. Finally, we also release an evaluation benchmark dataset of 1 million sensitive representations to encourage rigorous exploration of novel attack schemes.
Improving Video Instance Segmentation by Light-weight Temporal Uncertainty Estimates
Dec 14, 2020

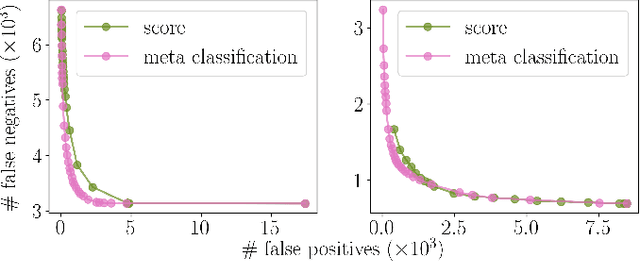

Instance segmentation with neural networks is an essential task in environment perception. However, the networks can predict false positive instances with high confidence values and true positives with low ones. Hence, it is important to accurately model the uncertainties of neural networks to prevent safety issues and foster interpretability. In applications such as automated driving the detection of road users like vehicles and pedestrians is of highest interest. We present a temporal approach to detect false positives and investigate uncertainties of instance segmentation networks. Since image sequences are available for online applications, we track instances over multiple frames and create temporal instance-wise aggregated metrics of uncertainty. The prediction quality is estimated by predicting the intersection over union as performance measure. Furthermore, we show how to use uncertainty information to replace the traditional score value from object detection and improve the overall performance of instance segmentation networks.
Materials for Masses: SVBRDF Acquisition with a Single Mobile Phone Image
Apr 16, 2018
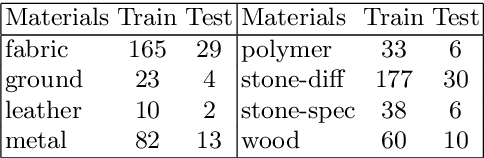

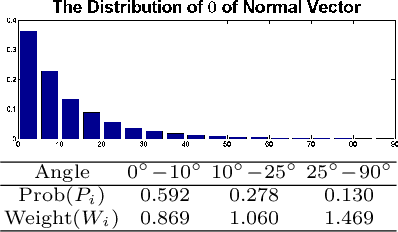
We propose a material acquisition approach to recover the spatially-varying BRDF and normal map of a near-planar surface from a single image captured by a handheld mobile phone camera. Our method images the surface under arbitrary environment lighting with the flash turned on, thereby avoiding shadows while simultaneously capturing high-frequency specular highlights. We train a CNN to regress an SVBRDF and surface normals from this image. Our network is trained using a large-scale SVBRDF dataset and designed to incorporate physical insights for material estimation, including an in-network rendering layer to model appearance and a material classifier to provide additional supervision during training. We refine the results from the network using a dense CRF module whose terms are designed specifically for our task. The framework is trained end-to-end and produces high quality results for a variety of materials. We provide extensive ablation studies to evaluate our network on both synthetic and real data, while demonstrating significant improvements in comparisons with prior works.
Deep Multimodal Transfer-Learned Regression in Data-Poor Domains
Jun 16, 2020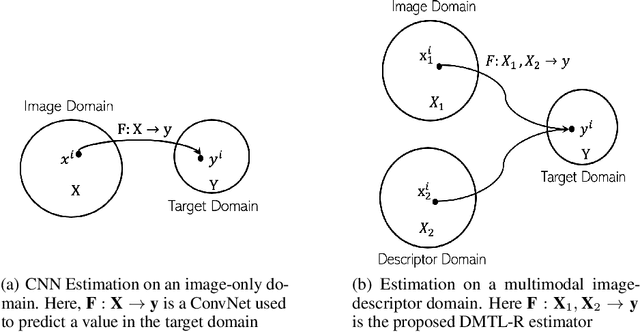
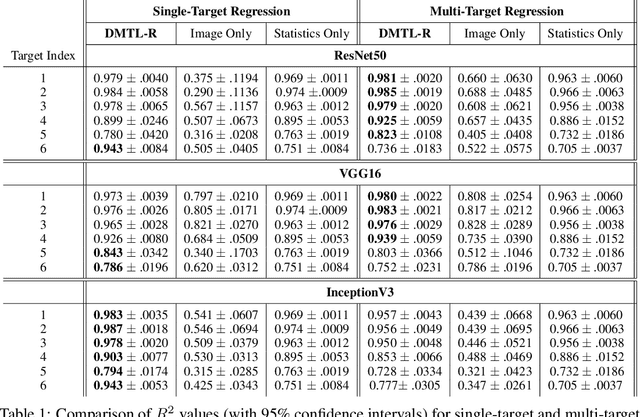
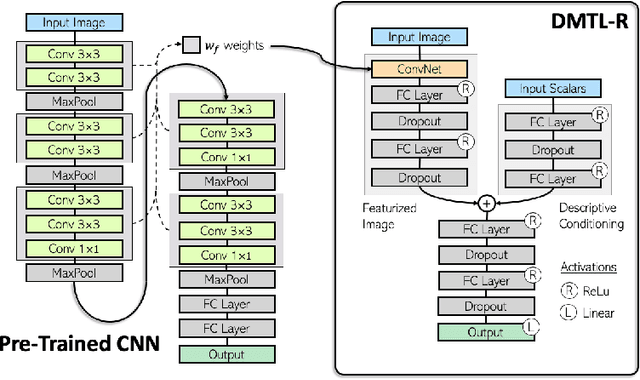

In many real-world applications of deep learning, estimation of a target may rely on various types of input data modes, such as audio-video, image-text, etc. This task can be further complicated by a lack of sufficient data. Here we propose a Deep Multimodal Transfer-Learned Regressor (DMTL-R) for multimodal learning of image and feature data in a deep regression architecture effective at predicting target parameters in data-poor domains. Our model is capable of fine-tuning a given set of pre-trained CNN weights on a small amount of training image data, while simultaneously conditioning on feature information from a complimentary data mode during network training, yielding more accurate single-target or multi-target regression than can be achieved using the images or the features alone. We present results using phase-field simulation microstructure images with an accompanying set of physical features, using pre-trained weights from various well-known CNN architectures, which demonstrate the efficacy of the proposed multimodal approach.
Show, Adapt and Tell: Adversarial Training of Cross-domain Image Captioner
Aug 14, 2017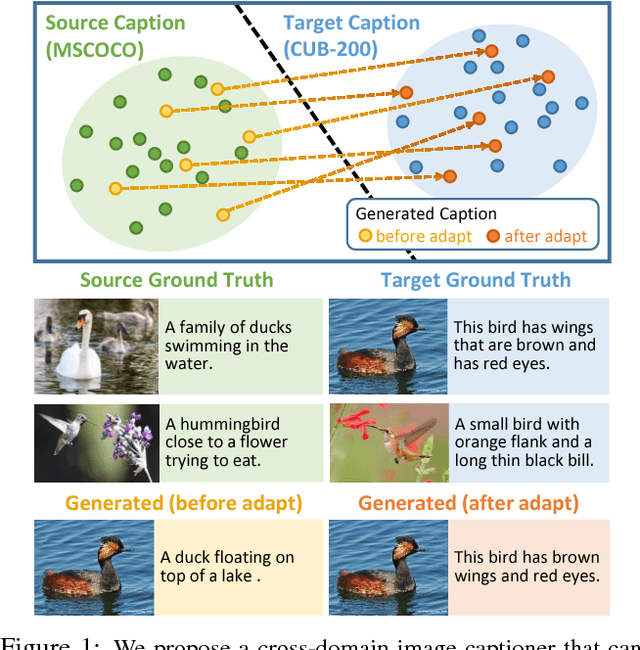
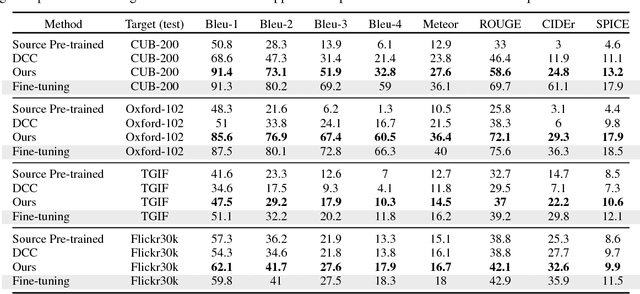
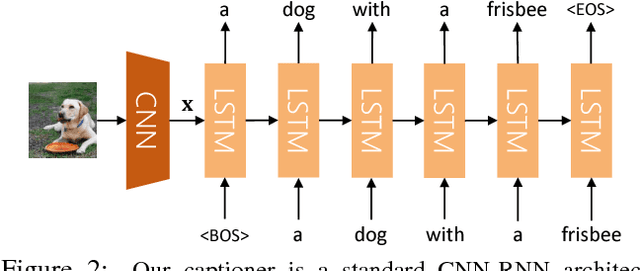
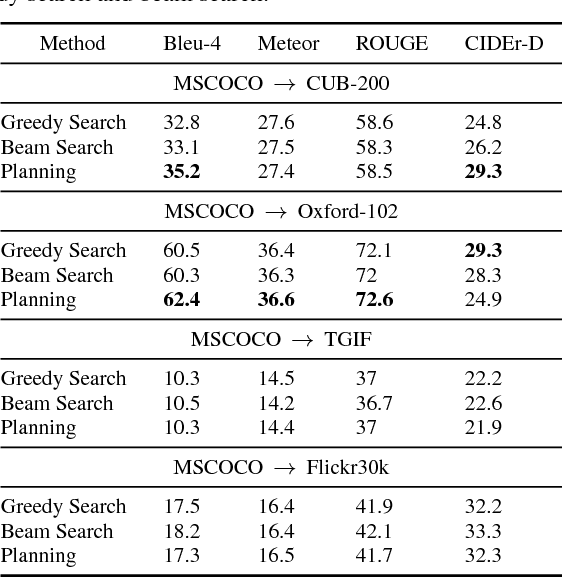
Impressive image captioning results are achieved in domains with plenty of training image and sentence pairs (e.g., MSCOCO). However, transferring to a target domain with significant domain shifts but no paired training data (referred to as cross-domain image captioning) remains largely unexplored. We propose a novel adversarial training procedure to leverage unpaired data in the target domain. Two critic networks are introduced to guide the captioner, namely domain critic and multi-modal critic. The domain critic assesses whether the generated sentences are indistinguishable from sentences in the target domain. The multi-modal critic assesses whether an image and its generated sentence are a valid pair. During training, the critics and captioner act as adversaries -- captioner aims to generate indistinguishable sentences, whereas critics aim at distinguishing them. The assessment improves the captioner through policy gradient updates. During inference, we further propose a novel critic-based planning method to select high-quality sentences without additional supervision (e.g., tags). To evaluate, we use MSCOCO as the source domain and four other datasets (CUB-200-2011, Oxford-102, TGIF, and Flickr30k) as the target domains. Our method consistently performs well on all datasets. In particular, on CUB-200-2011, we achieve 21.8% CIDEr-D improvement after adaptation. Utilizing critics during inference further gives another 4.5% boost.