 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Boosting Few-Shot Segmentation via Instance-Aware Data Augmentation and Local Consensus Guided Cross Attention
Jan 18, 2024
Few-shot segmentation aims to train a segmentation model that can fast adapt to a novel task for which only a few annotated images are provided. Most recent models have adopted a prototype-based paradigm for few-shot inference. These approaches may have limited generalization capacity beyond the standard 1- or 5-shot settings. In this paper, we closely examine and reevaluate the fine-tuning based learning scheme that fine-tunes the classification layer of a deep segmentation network pre-trained on diverse base classes. To improve the generalizability of the classification layer optimized with sparsely annotated samples, we introduce an instance-aware data augmentation (IDA) strategy that augments the support images based on the relative sizes of the target objects. The proposed IDA effectively increases the support set's diversity and promotes the distribution consistency between support and query images. On the other hand, the large visual difference between query and support images may hinder knowledge transfer and cripple the segmentation performance. To cope with this challenge, we introduce the local consensus guided cross attention (LCCA) to align the query feature with support features based on their dense correlation, further improving the model's generalizability to the query image. The significant performance improvements on the standard few-shot segmentation benchmarks PASCAL-$5^i$ and COCO-$20^i$ verify the efficacy of our proposed method.
Multimodal Learning for detecting urban functional zones using remote sensing image and multi-semantic information
Jan 12, 2024Urban area-of-interest (AOI) refers to an integrated urban functional zone with defined boundaries. The rapid development of urban commerce has resulted in an increased demand for more precise requirements in defining AOIs. However, existing research primarily concentrates on broad AOI mining for urban planning or regional economic analysis, failing to cater to the precise requirements of mobile Internet online-to-offline businesses. These businesses necessitate accuracy down to a specific community, school, or hospital. In this paper, we propose an end-to-end multimodal deep learning algorithm for detecting AOI fence polygon using remote sensing images and multi-semantics reference information. We then evaluate its timeliness through a cascaded module that incorporates dynamic human mobility and logistics address information. Specifically, we begin by selecting a point-of-interest (POI) of specific category, and use it to recall corresponding remote sensing images, nearby POIs, road nodes, human mobility, and logistics addresses to build a multimodal detection model based on transformer encoder-decoder architecture, titled AOITR. In the model, in addition to the remote sensing images, multi-semantic information including core POI and road nodes is embedded and reorganized as the query content part for the transformer decoder to generate the AOI polygon. Meanwhile, relatively dynamic distribution features of human mobility, nearby POIs, and logistics addresses are used for AOI reliability evaluation through a cascaded feedforward network. The experimental results demonstrate that our algorithm significantly outperforms two existing methods.
Local Conditional Controlling for Text-to-Image Diffusion Models
Dec 14, 2023Diffusion models have exhibited impressive prowess in the text-to-image task. Recent methods add image-level controls, e.g., edge and depth maps, to manipulate the generation process together with text prompts to obtain desired images. This controlling process is globally operated on the entire image, which limits the flexibility of control regions. In this paper, we introduce a new simple yet practical task setting: local control. It focuses on controlling specific local areas according to user-defined image conditions, where the rest areas are only conditioned by the original text prompt. This manner allows the users to flexibly control the image generation in a fine-grained way. However, it is non-trivial to achieve this goal. The naive manner of directly adding local conditions may lead to the local control dominance problem. To mitigate this problem, we propose a training-free method that leverages the updates of noised latents and parameters in the cross-attention map during the denosing process to promote concept generation in non-control areas. Moreover, we use feature mask constraints to mitigate the degradation of synthesized image quality caused by information differences inside and outside the local control area. Extensive experiments demonstrate that our method can synthesize high-quality images to the prompt under local control conditions. Code is available at https://github.com/YibooZhao/Local-Control.
Prompting Hard or Hardly Prompting: Prompt Inversion for Text-to-Image Diffusion Models
Dec 19, 2023The quality of the prompts provided to text-to-image diffusion models determines how faithful the generated content is to the user's intent, often requiring `prompt engineering'. To harness visual concepts from target images without prompt engineering, current approaches largely rely on embedding inversion by optimizing and then mapping them to pseudo-tokens. However, working with such high-dimensional vector representations is challenging because they lack semantics and interpretability, and only allow simple vector operations when using them. Instead, this work focuses on inverting the diffusion model to obtain interpretable language prompts directly. The challenge of doing this lies in the fact that the resulting optimization problem is fundamentally discrete and the space of prompts is exponentially large; this makes using standard optimization techniques, such as stochastic gradient descent, difficult. To this end, we utilize a delayed projection scheme to optimize for prompts representative of the vocabulary space in the model. Further, we leverage the findings that different timesteps of the diffusion process cater to different levels of detail in an image. The later, noisy, timesteps of the forward diffusion process correspond to the semantic information, and therefore, prompt inversion in this range provides tokens representative of the image semantics. We show that our approach can identify semantically interpretable and meaningful prompts for a target image which can be used to synthesize diverse images with similar content. We further illustrate the application of the optimized prompts in evolutionary image generation and concept removal.
CrossDiff: Exploring Self-Supervised Representation of Pansharpening via Cross-Predictive Diffusion Model
Jan 13, 2024Fusion of a panchromatic (PAN) image and corresponding multispectral (MS) image is also known as pansharpening, which aims to combine abundant spatial details of PAN and spectral information of MS. Due to the absence of high-resolution MS images, available deep-learning-based methods usually follow the paradigm of training at reduced resolution and testing at both reduced and full resolution. When taking original MS and PAN images as inputs, they always obtain sub-optimal results due to the scale variation. In this paper, we propose to explore the self-supervised representation of pansharpening by designing a cross-predictive diffusion model, named CrossDiff. It has two-stage training. In the first stage, we introduce a cross-predictive pretext task to pre-train the UNet structure based on conditional DDPM, while in the second stage, the encoders of the UNets are frozen to directly extract spatial and spectral features from PAN and MS, and only the fusion head is trained to adapt for pansharpening task. Extensive experiments show the effectiveness and superiority of the proposed model compared with state-of-the-art supervised and unsupervised methods. Besides, the cross-sensor experiments also verify the generalization ability of proposed self-supervised representation learners for other satellite's datasets. We will release our code for reproducibility.
Exploiting GPT-4 Vision for Zero-shot Point Cloud Understanding
Jan 15, 2024In this study, we tackle the challenge of classifying the object category in point clouds, which previous works like PointCLIP struggle to address due to the inherent limitations of the CLIP architecture. Our approach leverages GPT-4 Vision (GPT-4V) to overcome these challenges by employing its advanced generative abilities, enabling a more adaptive and robust classification process. We adapt the application of GPT-4V to process complex 3D data, enabling it to achieve zero-shot recognition capabilities without altering the underlying model architecture. Our methodology also includes a systematic strategy for point cloud image visualization, mitigating domain gap and enhancing GPT-4V's efficiency. Experimental validation demonstrates our approach's superiority in diverse scenarios, setting a new benchmark in zero-shot point cloud classification.
MISS: A Generative Pretraining and Finetuning Approach for Med-VQA
Jan 10, 2024Medical visual question answering (VQA) is a challenging multimodal task, where Vision-Language Pre-training (VLP) models can effectively improve the generalization performance. However, most methods in the medical field treat VQA as an answer classification task which is difficult to transfer to practical application scenarios. Additionally, due to the privacy of medical images and the expensive annotation process, large-scale medical image-text pairs datasets for pretraining are severely lacking. In this paper, we propose a large-scale MultI-task Self-Supervised learning based framework (MISS) for medical VQA tasks. Unlike existing methods, we treat medical VQA as a generative task. We unify the text encoder and multimodal encoder and align image-text features through multi-task learning. Furthermore, we propose a Transfer-and-Caption method that extends the feature space of single-modal image datasets using large language models (LLMs), enabling those traditional medical vision field task data to be applied to VLP. Experiments show that our method achieves excellent results with fewer multimodal datasets and demonstrates the advantages of generative VQA models. The code and model weights will be released upon the paper's acceptance.
Textual Prompt Guided Image Restoration
Dec 11, 2023
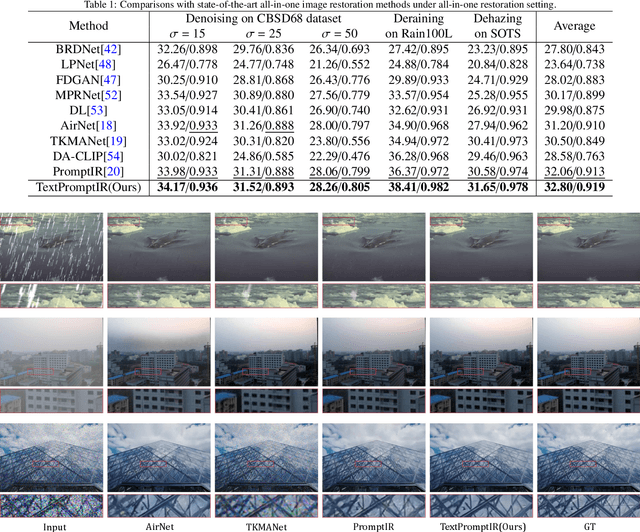
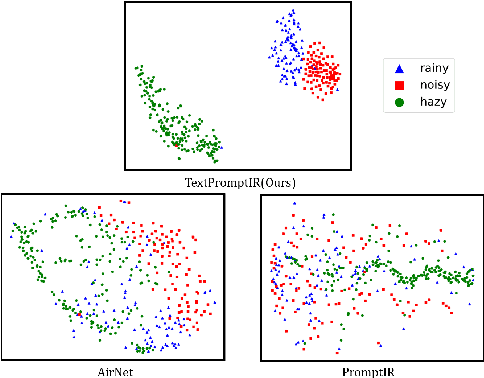
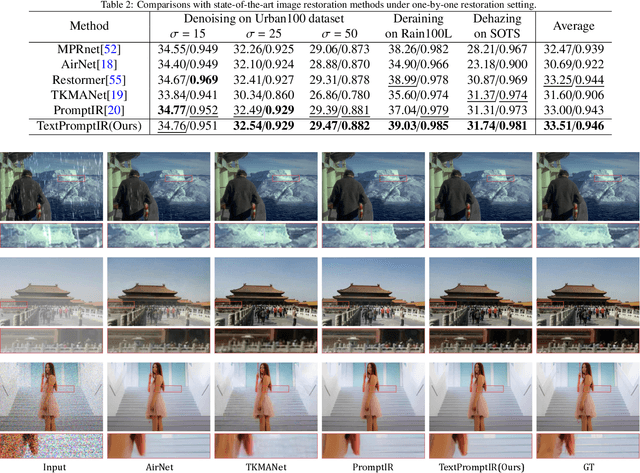
Image restoration has always been a cutting-edge topic in the academic and industrial fields of computer vision. Since degradation signals are often random and diverse, "all-in-one" models that can do blind image restoration have been concerned in recent years. Early works require training specialized headers and tails to handle each degradation of concern, which are manually cumbersome. Recent works focus on learning visual prompts from data distribution to identify degradation type. However, the prompts employed in most of models are non-text, lacking sufficient emphasis on the importance of human-in-the-loop. In this paper, an effective textual prompt guided image restoration model has been proposed. In this model, task-specific BERT is fine-tuned to accurately understand user's instructions and generating textual prompt guidance. Depth-wise multi-head transposed attentions and gated convolution modules are designed to bridge the gap between textual prompts and visual features. The proposed model has innovatively introduced semantic prompts into low-level visual domain. It highlights the potential to provide a natural, precise, and controllable way to perform image restoration tasks. Extensive experiments have been done on public denoising, dehazing and deraining datasets. The experiment results demonstrate that, compared with popular state-of-the-art methods, the proposed model can obtain much more superior performance, achieving accurate recognition and removal of degradation without increasing model's complexity. Related source codes and data will be publicly available on github site https://github.com/MoTong-AI-studio/TextPromptIR.
A Dual Domain Multi-exposure Image Fusion Network based on the Spatial-Frequency Integration
Dec 17, 2023Multi-exposure image fusion aims to generate a single high-dynamic image by integrating images with different exposures. Existing deep learning-based multi-exposure image fusion methods primarily focus on spatial domain fusion, neglecting the global modeling ability of the frequency domain. To effectively leverage the global illumination modeling ability of the frequency domain, we propose a novelty perspective on multi-exposure image fusion via the Spatial-Frequency Integration Framework, named MEF-SFI. Initially, we revisit the properties of the Fourier transform on the 2D image, and verify the feasibility of multi-exposure image fusion on the frequency domain where the amplitude and phase component is able to guide the integration of the illumination information. Subsequently, we present the deep Fourier-based multi-exposure image fusion framework, which consists of a spatial path and frequency path for local and global modeling separately. Specifically, we introduce a Spatial-Frequency Fusion Block to facilitate efficient interaction between dual domains and capture complementary information from input images with different exposures. Finally, we combine a dual domain loss function to ensure the retention of complementary information in both the spatial and frequency domains. Extensive experiments on the PQA-MEF dataset demonstrate that our method achieves visual-appealing fusion results against state-of-the-art multi-exposure image fusion approaches. Our code is available at https://github.com/SSyangguang/MEF-freq.
Generation of Synthetic Images for Pedestrian Detection Using a Sequence of GANs
Jan 14, 2024Creating annotated datasets demands a substantial amount of manual effort. In this proof-of-concept work, we address this issue by proposing a novel image generation pipeline. The pipeline consists of three distinct generative adversarial networks (previously published), combined in a novel way to augment a dataset for pedestrian detection. Despite the fact that the generated images are not always visually pleasant to the human eye, our detection benchmark reveals that the results substantially surpass the baseline. The presented proof-of-concept work was done in 2020 and is now published as a technical report after a three years retention period.