 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Real-Time High-Resolution Background Matting
Dec 14, 2020
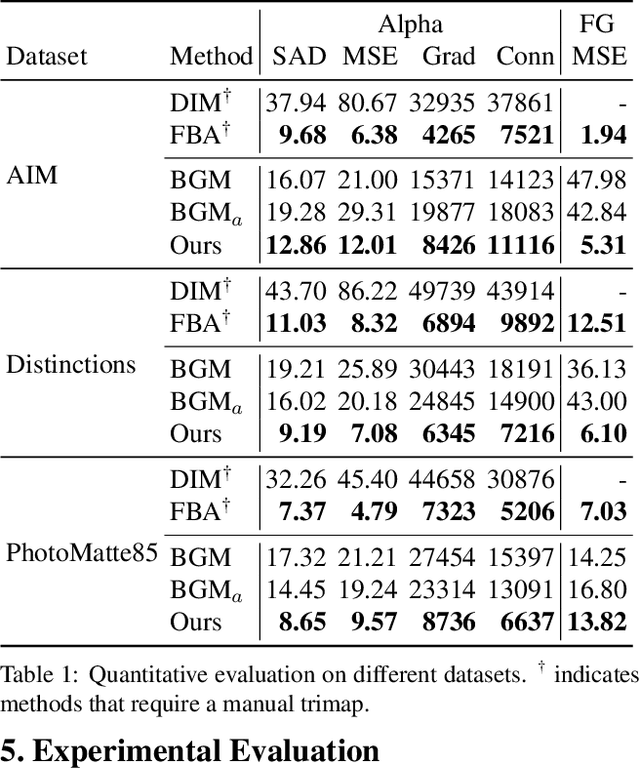

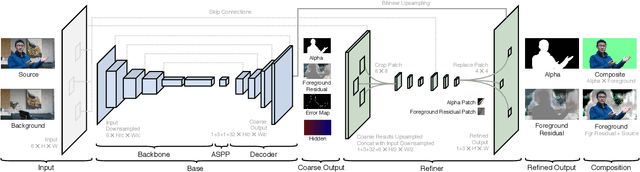
We introduce a real-time, high-resolution background replacement technique which operates at 30fps in 4K resolution, and 60fps for HD on a modern GPU. Our technique is based on background matting, where an additional frame of the background is captured and used in recovering the alpha matte and the foreground layer. The main challenge is to compute a high-quality alpha matte, preserving strand-level hair details, while processing high-resolution images in real-time. To achieve this goal, we employ two neural networks; a base network computes a low-resolution result which is refined by a second network operating at high-resolution on selective patches. We introduce two largescale video and image matting datasets: VideoMatte240K and PhotoMatte13K/85. Our approach yields higher quality results compared to the previous state-of-the-art in background matting, while simultaneously yielding a dramatic boost in both speed and resolution.
Mixup Without Hesitation
Jan 12, 2021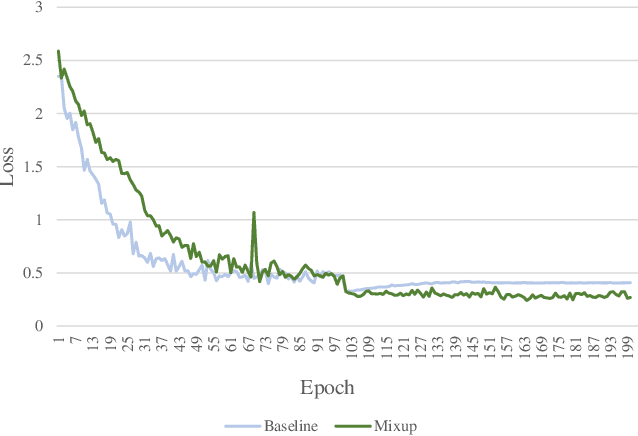
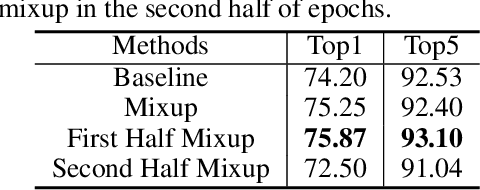


Mixup linearly interpolates pairs of examples to form new samples, which is easy to implement and has been shown to be effective in image classification tasks. However, there are two drawbacks in mixup: one is that more training epochs are needed to obtain a well-trained model; the other is that mixup requires tuning a hyper-parameter to gain appropriate capacity but that is a difficult task. In this paper, we find that mixup constantly explores the representation space, and inspired by the exploration-exploitation dilemma in reinforcement learning, we propose mixup Without hesitation (mWh), a concise, effective, and easy-to-use training algorithm. We show that mWh strikes a good balance between exploration and exploitation by gradually replacing mixup with basic data augmentation. It can achieve a strong baseline with less training time than original mixup and without searching for optimal hyper-parameter, i.e., mWh acts as mixup without hesitation. mWh can also transfer to CutMix, and gain consistent improvement on other machine learning and computer vision tasks such as object detection. Our code is open-source and available at https://github.com/yuhao318/mwh
DISCO: Dynamic and Invariant Sensitive Channel Obfuscation for deep neural networks
Dec 20, 2020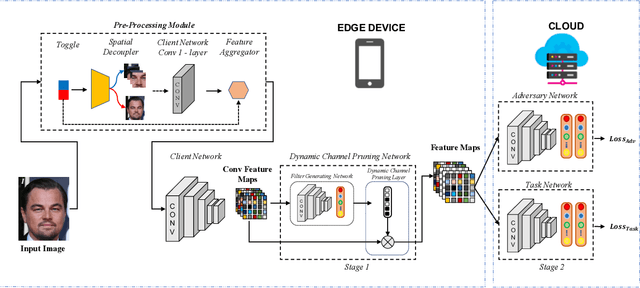
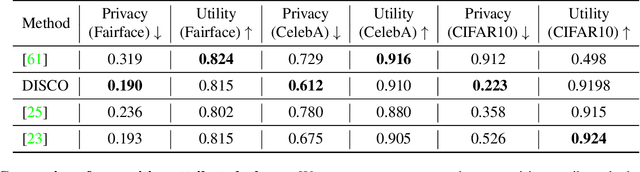

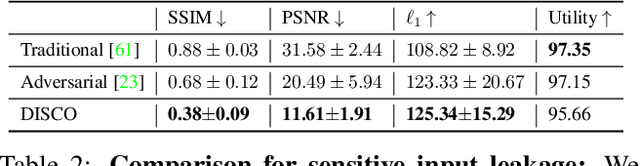
Recent deep learning models have shown remarkable performance in image classification. While these deep learning systems are getting closer to practical deployment, the common assumption made about data is that it does not carry any sensitive information. This assumption may not hold for many practical cases, especially in the domain where an individual's personal information is involved, like healthcare and facial recognition systems. We posit that selectively removing features in this latent space can protect the sensitive information and provide a better privacy-utility trade-off. Consequently, we propose DISCO which learns a dynamic and data driven pruning filter to selectively obfuscate sensitive information in the feature space. We propose diverse attack schemes for sensitive inputs \& attributes and demonstrate the effectiveness of DISCO against state-of-the-art methods through quantitative and qualitative evaluation. Finally, we also release an evaluation benchmark dataset of 1 million sensitive representations to encourage rigorous exploration of novel attack schemes.
Improving Video Instance Segmentation by Light-weight Temporal Uncertainty Estimates
Dec 14, 2020

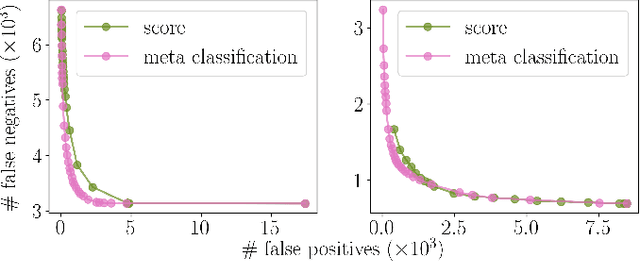

Instance segmentation with neural networks is an essential task in environment perception. However, the networks can predict false positive instances with high confidence values and true positives with low ones. Hence, it is important to accurately model the uncertainties of neural networks to prevent safety issues and foster interpretability. In applications such as automated driving the detection of road users like vehicles and pedestrians is of highest interest. We present a temporal approach to detect false positives and investigate uncertainties of instance segmentation networks. Since image sequences are available for online applications, we track instances over multiple frames and create temporal instance-wise aggregated metrics of uncertainty. The prediction quality is estimated by predicting the intersection over union as performance measure. Furthermore, we show how to use uncertainty information to replace the traditional score value from object detection and improve the overall performance of instance segmentation networks.
Adversarial Learning of Semantic Relevance in Text to Image Synthesis
Dec 12, 2018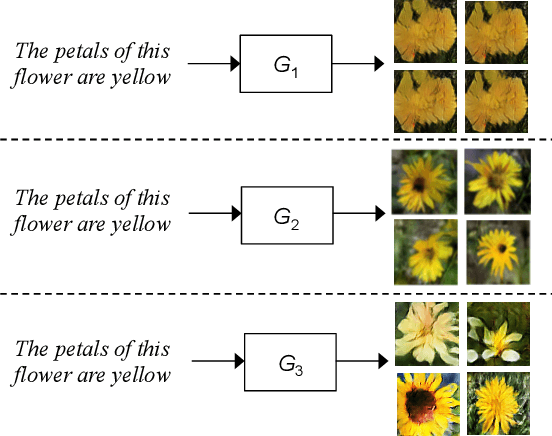
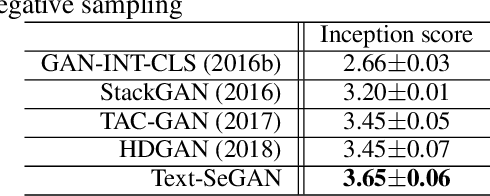
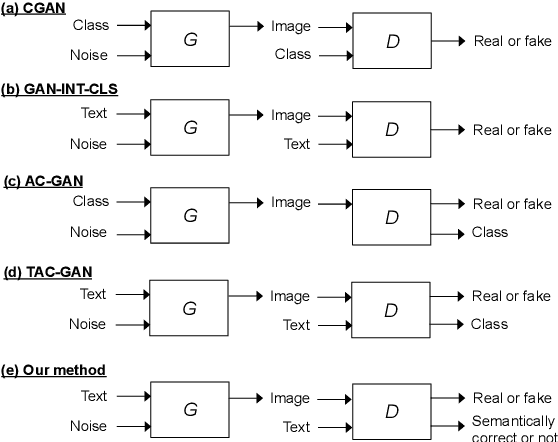
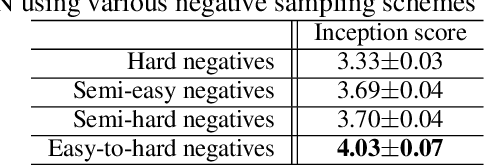
We describe a new approach that improves the training of generative adversarial nets (GANs) for synthesizing diverse images from a text input. Our approach is based on the conditional version of GANs and expands on previous work leveraging an auxiliary task in the discriminator. Our generated images are not limited to certain classes and do not suffer from mode collapse while semantically matching the text input. A key to our training methods is how to form positive and negative training examples with respect to the class label of a given image. Instead of selecting random training examples, we perform negative sampling based on the semantic distance from a positive example in the class. We evaluate our approach using the Oxford-102 flower dataset, adopting the inception score and multi-scale structural similarity index (MS-SSIM) metrics to assess discriminability and diversity of the generated images. The empirical results indicate greater diversity in the generated images, especially when we gradually select more negative training examples closer to a positive example in the semantic space.
CNN Denoisers as Non-Local Filters: The Neural Tangent Denoiser
Jun 04, 2020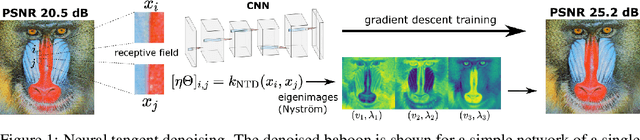
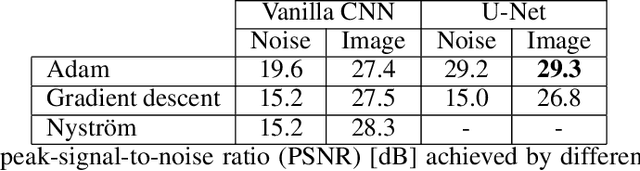

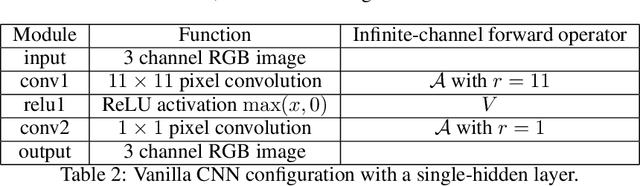
Convolutional Neural Networks (CNNs) are now a well-established tool for solving computational imaging problems. Modern CNN-based algorithms obtain state-of-the-art performance in diverse image restoration problems. Furthermore, it has been recently shown that, despite being highly overparametrized, networks trained with a single corrupted image can still perform as well as fully trained networks, a phenomenon encapsulated in the deep image prior. We introduce a novel interpretation of denoising networks with no clean training data in the context of the neural tangent kernel (NTK), elucidating the strong links with well-known non-local filtering techniques, such as non-local means or BM3D. The filtering function associated with a given network architecture can be obtained in closed form without need to train the network, being fully characterized by the random initialization of the network weights. While the NTK theory accurately predicts the filter associated with networks trained using standard gradient descent, our analysis shows that it falls short to explain the behaviour of networks trained using the popular Adam optimizer. The latter achieves a larger change of weights in hidden layers, adapting the non-local filtering function during training. We evaluate our findings via extensive image denoising experiments.
MSDU-net: A Multi-Scale Dilated U-net for Blur Detection
Jun 05, 2020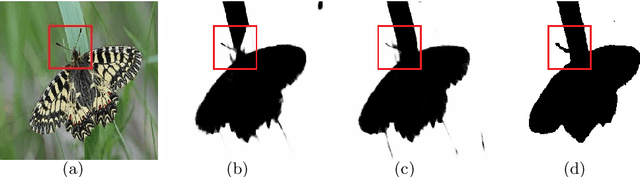
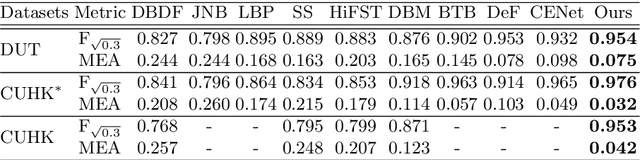
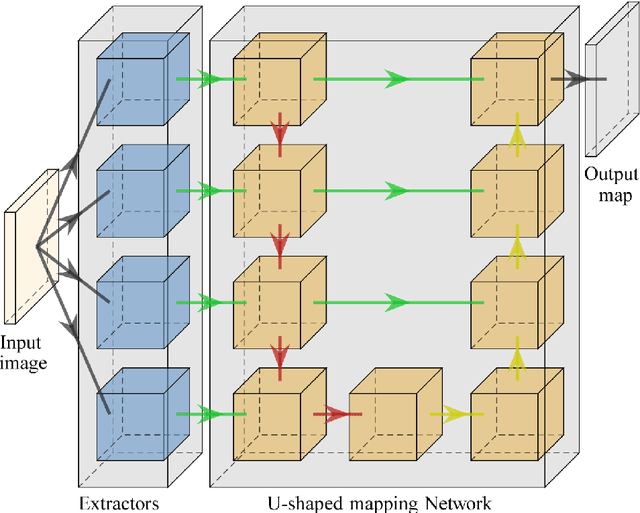
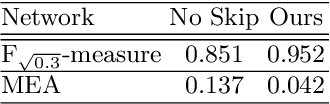
Blur detection is the separation of blurred and clear regions of an image, which is an important and challenging task in computer vision. In this work, we regard blur detection as an image segmentation problem. Inspired by the success of the U-net architecture for image segmentation, we design a Multi-Scale Dilated convolutional neural network based on U-net, which we call MSDU-net. The MSDU-net uses a group of multi-scale feature extractors with dilated convolutions to extract texture information at different scales. The U-shape architecture of the MSDU-net fuses the different-scale texture features and generates a semantic feature which allows us to achieve better results on the blur detection task. We show that using the MSDU-net we are able to outperform other state of the art blur detection methods on two publicly available benchmarks.
Photo-realistic Image Super-resolution with Fast and Lightweight Cascading Residual Network
Mar 06, 2019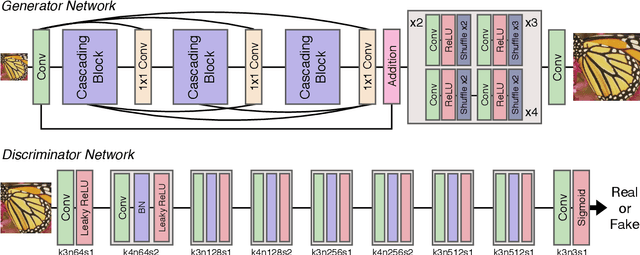
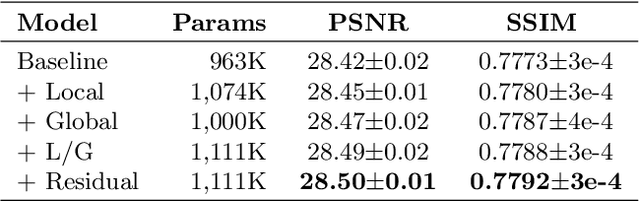
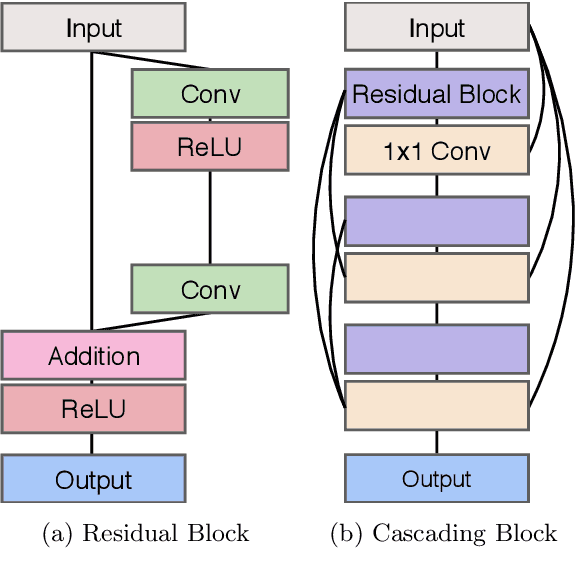

Recent progress in the deep learning-based models has improved single-image super-resolution significantly. However, despite their powerful performance, many models are difficult to apply to the real-world applications because of the heavy computational requirements. To facilitate the use of a deep learning model in such demands, we focus on keeping the model fast and lightweight while maintaining its accuracy. In detail, we design an architecture that implements a cascading mechanism on a residual network to boost the performance with limited resources via multi-level feature fusion. Moreover, we adopt group convolution and weight-tying for our proposed model in order to achieve extreme efficiency. In addition to the traditional super-resolution task, we apply our methods to the photo-realistic super-resolution field using the adversarial learning paradigm and a multi-scale discriminator approach. By doing so, we show that the performances of the proposed models surpass those of the recent methods, which have a complexity similar to ours, for both traditional pixel-based and perception-based tasks.
Learning Sampling and Model-Based Signal Recovery for Compressed Sensing MRI
Apr 22, 2020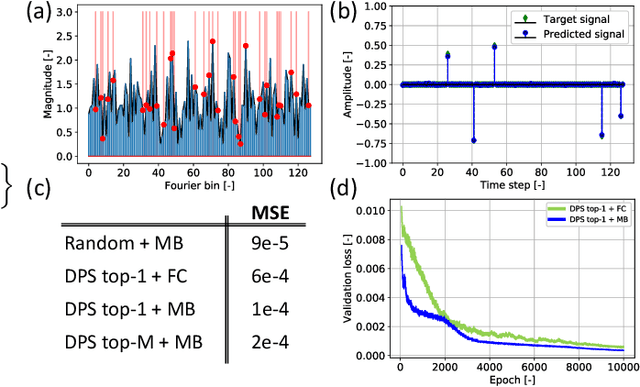
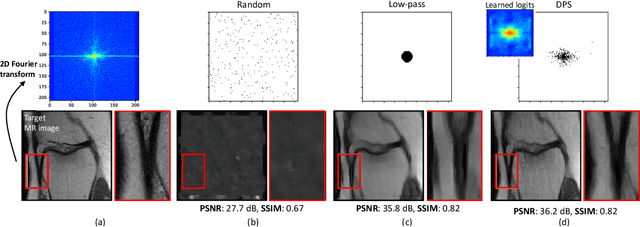
Compressed sensing (CS) MRI relies on adequate undersampling of the k-space to accelerate the acquisition without compromising image quality. Consequently, the design of optimal sampling patterns for these k-space coefficients has received significant attention, with many CS MRI methods exploiting variable-density probability distributions. Realizing that an optimal sampling pattern may depend on the downstream task (e.g. image reconstruction, segmentation, or classification), we here propose joint learning of both task-adaptive k-space sampling and a subsequent model-based proximal-gradient recovery network. The former is enabled through a probabilistic generative model that leverages the Gumbel-softmax relaxation to sample across trainable beliefs while maintaining differentiability. The proposed combination of a highly flexible sampling model and a model-based (sampling-adaptive) image reconstruction network facilitates exploration and efficient training, yielding improved MR image quality compared to other sampling baselines.
Data Processing for Short-Term Solar Irradiance Forecasting using Ground-Based Infrared Images
Jan 21, 2021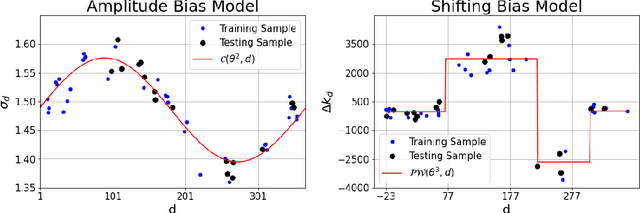
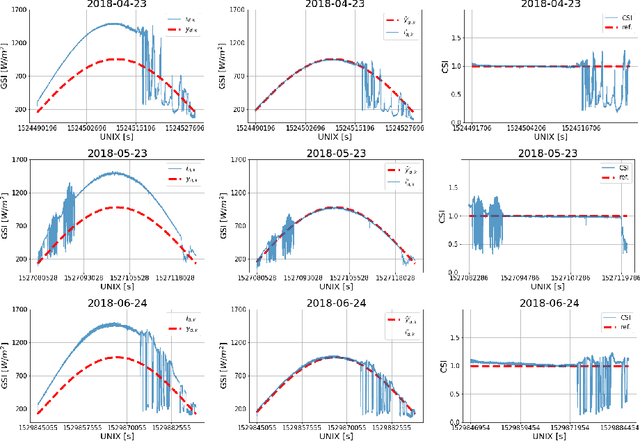
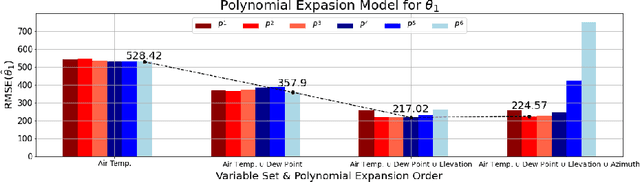
The generation of energy in a power grid which uses Photovoltaic (PV) systems depends on the projection of shadows from moving clouds in the Troposphere. This investigation proposes an efficient method of data processing for the statistical quantification of cloud features using long-wave infrared (IR) images and Global Solar Irradiance (GSI) measurements. The IR images are obtained using a data acquisition system (DAQ) mounted on a solar tracker. We explain how to remove cyclostationary biases in GSI measurements. Seasonal trends are removed from the GSI time series, using the theoretical GSI to obtain the Clear-Sky Index (CSI) time series. We introduce an atmospheric model to remove from IR images both the effect of atmosphere scatter irradiance and the effect of the Sun's direct irradiance. Scattering is produced by water spots and dust particles on the germanium lens of the enclosure. We explain how to remove the scattering effect produced by the germanium lens attached to the DAQ enclosure window of the IR camera. An atmospheric condition model classifies the sky-conditions in four different categories: clear-sky, cumulus, stratus and nimbus. When an IR image is classified in the category of clear-sky, it is used to model the scattering effect of the germanium lens.