 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The DongNiao International Birds 10000 Dataset
Sep 21, 2020
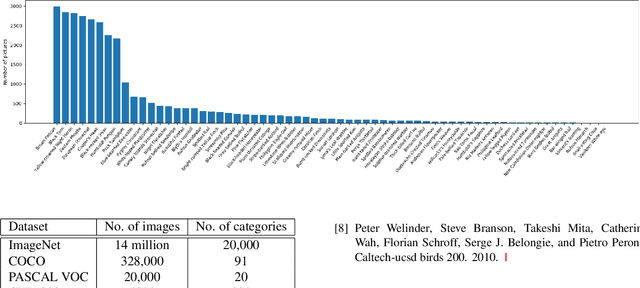

DongNiao International Birds 10000 (DIB-10K) is a challenging image dataset which has more than 10 thousand different types of birds. It was created to enable the study of machine learning and also ornithology research. DIB-10K does not own the copyright of these images. It only provides thumbnails of images, in a way similar to ImageNet.
StoRIR: Stochastic Room Impulse Response Generation for Audio Data Augmentation
Aug 17, 2020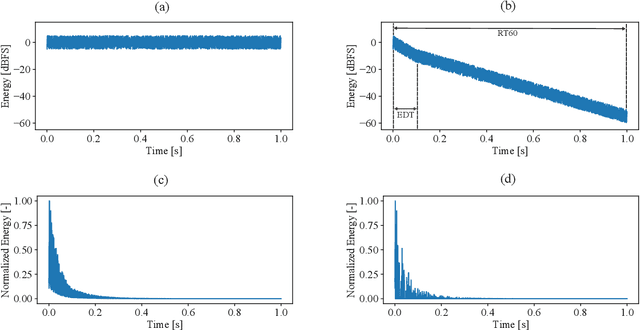
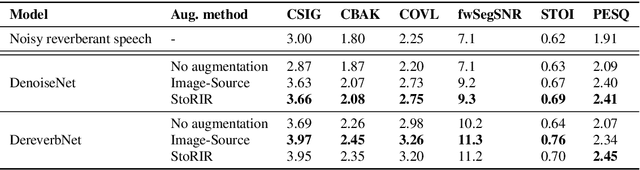
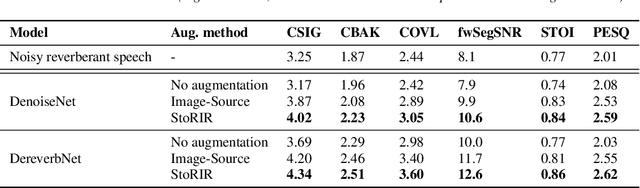
In this paper we introduce StoRIR - a stochastic room impulse response generation method dedicated to audio data augmentation in machine learning applications. This technique, in contrary to geometrical methods like image-source or ray tracing, does not require prior definition of room geometry, absorption coefficients or microphone and source placement and is dependent solely on the acoustic parameters of the room. The method is intuitive, easy to implement and allows to generate RIRs of very complicated enclosures. We show that StoRIR, when used for audio data augmentation in a speech enhancement task, allows deep learning models to achieve better results on a wide range of metrics than when using the conventional image-source method, effectively improving many of them by more than 5 %. We publish a Python implementation of StoRIR online
Low Dose CT Image Denoising Using a Generative Adversarial Network with Wasserstein Distance and Perceptual Loss
Apr 24, 2018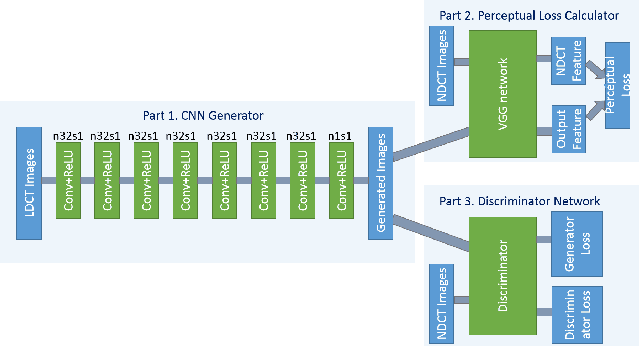
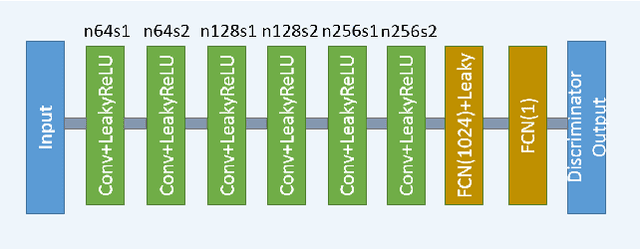
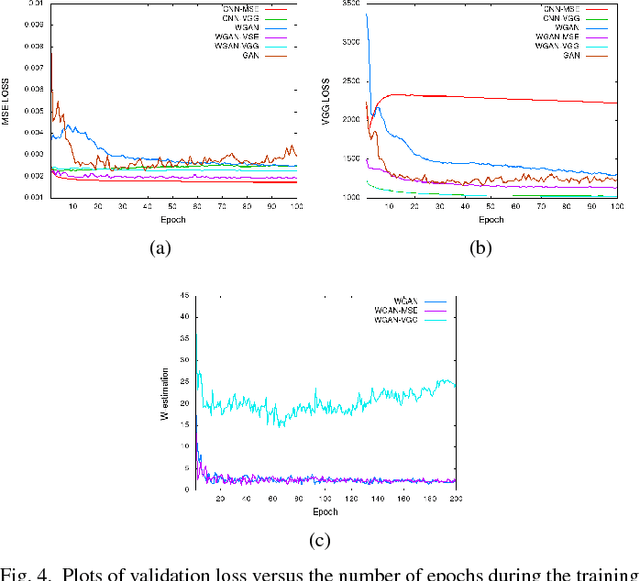
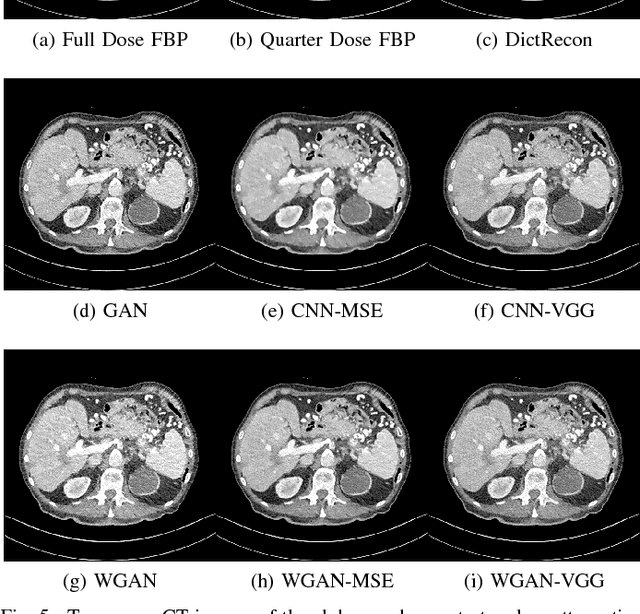
In this paper, we introduce a new CT image denoising method based on the generative adversarial network (GAN) with Wasserstein distance and perceptual similarity. The Wasserstein distance is a key concept of the optimal transform theory, and promises to improve the performance of the GAN. The perceptual loss compares the perceptual features of a denoised output against those of the ground truth in an established feature space, while the GAN helps migrate the data noise distribution from strong to weak. Therefore, our proposed method transfers our knowledge of visual perception to the image denoising task, is capable of not only reducing the image noise level but also keeping the critical information at the same time. Promising results have been obtained in our experiments with clinical CT images.
Prediction of low-keV monochromatic images from polyenergetic CT scans for improved automatic detection of pulmonary embolism
Feb 02, 2021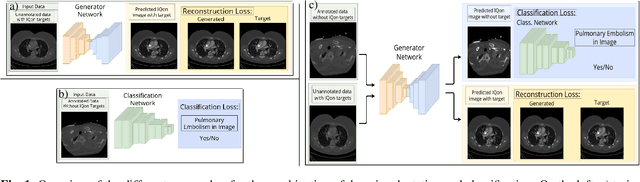
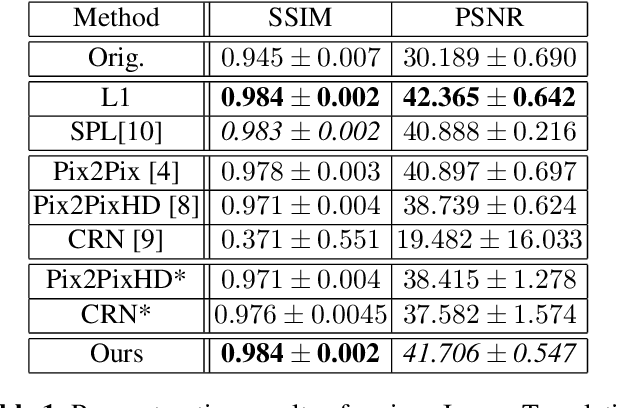
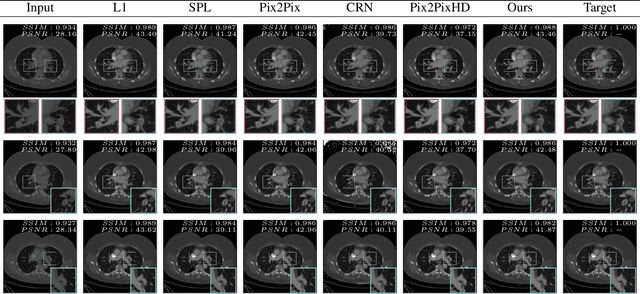

Detector-based spectral computed tomography is a recent dual-energy CT (DECT) technology that offers the possibility of obtaining spectral information. From this spectral data, different types of images can be derived, amongst others virtual monoenergetic (monoE) images. MonoE images potentially exhibit decreased artifacts, improve contrast, and overall contain lower noise values, making them ideal candidates for better delineation and thus improved diagnostic accuracy of vascular abnormalities. In this paper, we are training convolutional neural networks~(CNN) that can emulate the generation of monoE images from conventional single energy CT acquisitions. For this task, we investigate several commonly used image-translation methods. We demonstrate that these methods while creating visually similar outputs, lead to a poorer performance when used for automatic classification of pulmonary embolism (PE). We expand on these methods through the use of a multi-task optimization approach, under which the networks achieve improved classification as well as generation results, as reflected by PSNR and SSIM scores. Further, evaluating our proposed framework on a subset of the RSNA-PE challenge data set shows that we are able to improve the Area under the Receiver Operating Characteristic curve (AuROC) in comparison to a na\"ive classification approach from 0.8142 to 0.8420.
End-to-End Text Classification via Image-based Embedding using Character-level Networks
Oct 10, 2018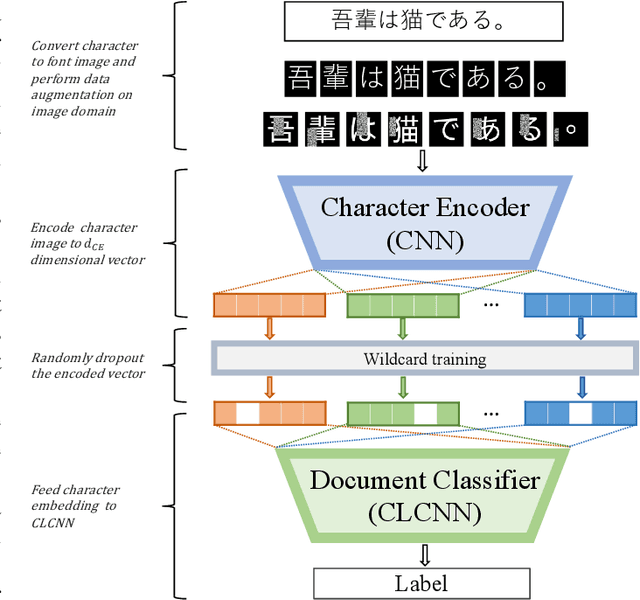


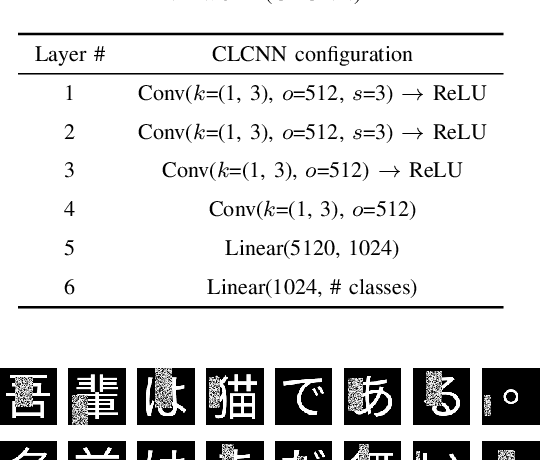
For analysing and/or understanding languages having no word boundaries based on morphological analysis such as Japanese, Chinese, and Thai, it is desirable to perform appropriate word segmentation before word embeddings. But it is inherently difficult in these languages. In recent years, various language models based on deep learning have made remarkable progress, and some of these methodologies utilizing character-level features have successfully avoided such a difficult problem. However, when a model is fed character-level features of the above languages, it often causes overfitting due to a large number of character types. In this paper, we propose a CE-CLCNN, character-level convolutional neural networks using a character encoder to tackle these problems. The proposed CE-CLCNN is an end-to-end learning model and has an image-based character encoder, i.e. the CE-CLCNN handles each character in the target document as an image. Through various experiments, we found and confirmed that our CE-CLCNN captured closely embedded features for visually and semantically similar characters and achieves state-of-the-art results on several open document classification tasks. In this paper we report the performance of our CE-CLCNN with the Wikipedia title estimation task and analyse the internal behaviour.
Implicit Subspace Prior Learning for Dual-Blind Face Restoration
Oct 12, 2020
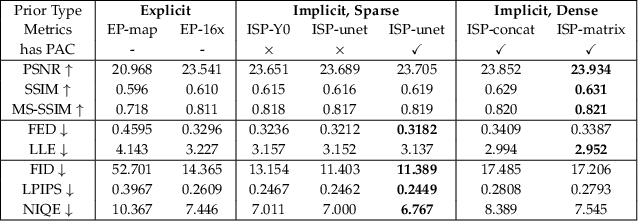


Face restoration is an inherently ill-posed problem, where additional prior constraints are typically considered crucial for mitigating such pathology. However, real-world image prior are often hard to simulate with precise mathematical models, which inevitably limits the performance and generalization ability of existing prior-regularized restoration methods. In this paper, we study the problem of face restoration under a more practical ``dual blind'' setting, i.e., without prior assumptions or hand-crafted regularization terms on the degradation profile or image contents. To this end, a novel implicit subspace prior learning (ISPL) framework is proposed as a generic solution to dual-blind face restoration, with two key elements: 1) an implicit formulation to circumvent the ill-defined restoration mapping and 2) a subspace prior decomposition and fusion mechanism to dynamically handle inputs at varying degradation levels with consistent high-quality restoration results. Experimental results demonstrate significant perception-distortion improvement of ISPL against existing state-of-the-art methods for a variety of restoration subtasks, including a 3.69db PSNR and 45.8% FID gain against ESRGAN, the 2018 NTIRE SR challenge winner. Overall, we prove that it is possible to capture and utilize prior knowledge without explicitly formulating it, which will help inspire new research paradigms towards low-level vision tasks.
Robotized Ultrasound Imaging of the Peripheral Arteries -- a Phantom Study
Jul 13, 2020



The first choice in diagnostic imaging for patients suffering from peripheral arterial disease is 2D ultrasound (US). However, for a proper imaging process, a skilled and experienced sonographer is required. Additionally, it is a highly user-dependent operation. A robotized US system that autonomously scans the peripheral arteries has the potential to overcome these limitations. In this work, we extend a previously proposed system by a hierarchical image analysis pipeline based on convolutional neural networks in order to control the robot. The system was evaluated by checking its feasibility to keep the vessel lumen of a leg phantom within the US image while scanning along the artery. In 100 % of the images acquired during the scan process the whole vessel lumen was visible. While defining an insensitivity margin of 2.74 mm, the mean absolute distance between vessel center and the horizontal image center line was 2.47 mm and 3.90 mm for an easy and complex scenario, respectively. In conclusion, this system presents the basis for fully automatized peripheral artery imaging in humans using a radiation-free approach.
Fundamental Limits in Multi-image Alignment
Feb 04, 2016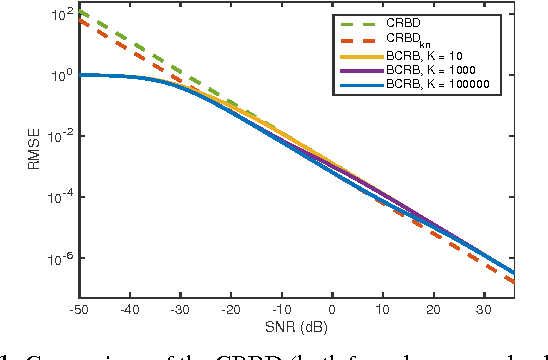
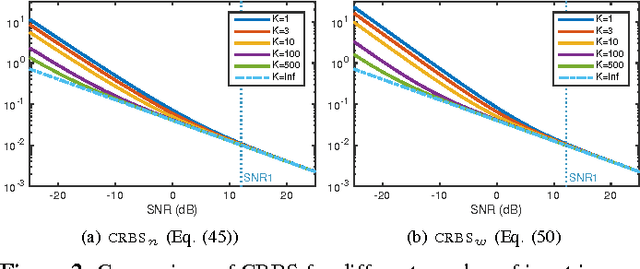
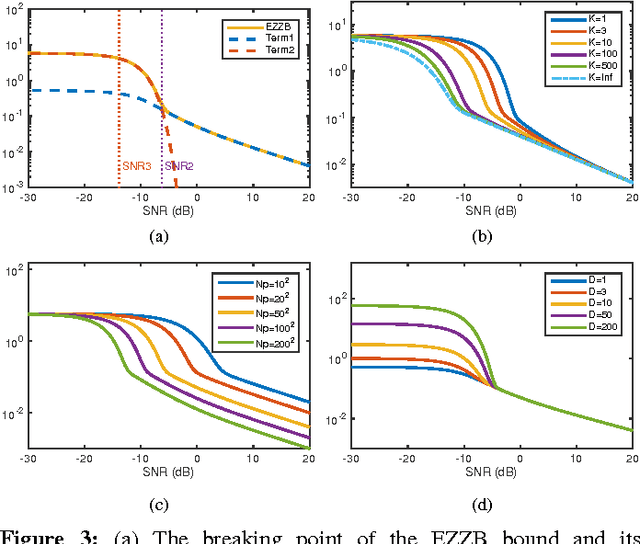
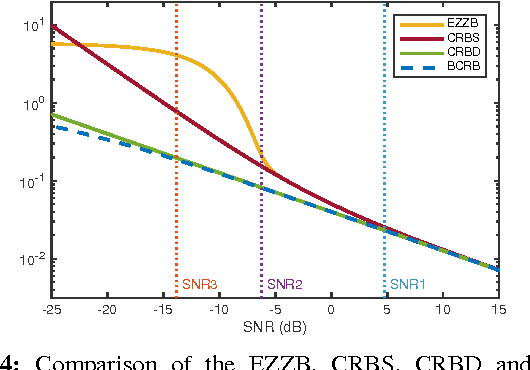
The performance of multi-image alignment, bringing different images into one coordinate system, is critical in many applications with varied signal-to-noise ratio (SNR) conditions. A great amount of effort is being invested into developing methods to solve this problem. Several important questions thus arise, including: Which are the fundamental limits in multi-image alignment performance? Does having access to more images improve the alignment? Theoretical bounds provide a fundamental benchmark to compare methods and can help establish whether improvements can be made. In this work, we tackle the problem of finding the performance limits in image registration when multiple shifted and noisy observations are available. We derive and analyze the Cram\'er-Rao and Ziv-Zakai lower bounds under different statistical models for the underlying image. The accuracy of the derived bounds is experimentally assessed through a comparison to the maximum likelihood estimator. We show the existence of different behavior zones depending on the difficulty level of the problem, given by the SNR conditions of the input images. We find that increasing the number of images is only useful below a certain SNR threshold, above which the pairwise MLE estimation proves to be optimal. The analysis we present here brings further insight into the fundamental limitations of the multi-image alignment problem.
TRANSPR: Transparency Ray-Accumulating Neural 3D Scene Point Renderer
Sep 06, 2020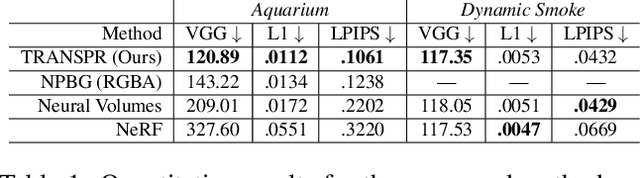
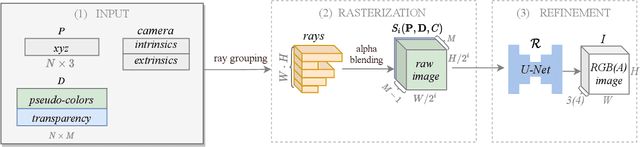
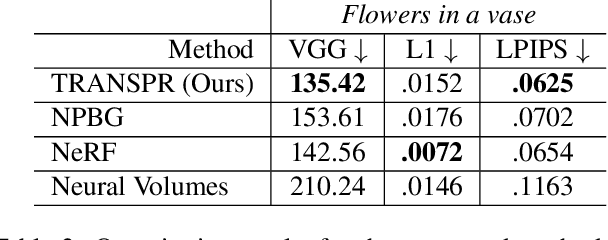
We propose and evaluate a neural point-based graphics method that can model semi-transparent scene parts. Similarly to its predecessor pipeline, ours uses point clouds to model proxy geometry, and augments each point with a neural descriptor. Additionally, a learnable transparency value is introduced in our approach for each point. Our neural rendering procedure consists of two steps. Firstly, the point cloud is rasterized using ray grouping into a multi-channel image. This is followed by the neural rendering step that "translates" the rasterized image into an RGB output using a learnable convolutional network. New scenes can be modeled using gradient-based optimization of neural descriptors and of the rendering network. We show that novel views of semi-transparent point cloud scenes can be generated after training with our approach. Our experiments demonstrate the benefit of introducing semi-transparency into the neural point-based modeling for a range of scenes with semi-transparent parts.
Self-Supervised Visual Representation Learning from Hierarchical Grouping
Dec 05, 2020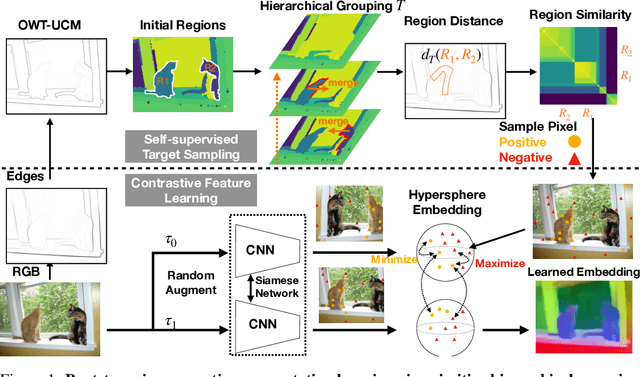
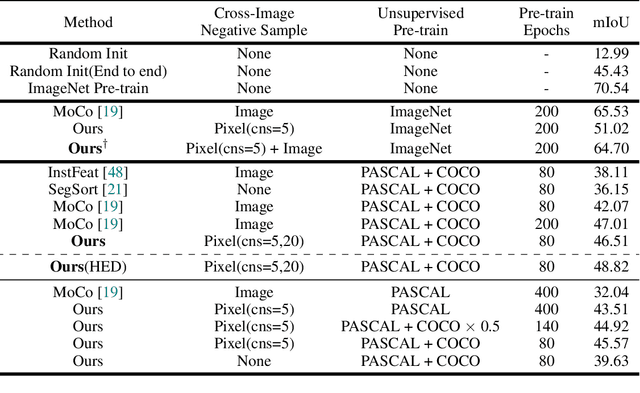


We create a framework for bootstrapping visual representation learning from a primitive visual grouping capability. We operationalize grouping via a contour detector that partitions an image into regions, followed by merging of those regions into a tree hierarchy. A small supervised dataset suffices for training this grouping primitive. Across a large unlabeled dataset, we apply this learned primitive to automatically predict hierarchical region structure. These predictions serve as guidance for self-supervised contrastive feature learning: we task a deep network with producing per-pixel embeddings whose pairwise distances respect the region hierarchy. Experiments demonstrate that our approach can serve as state-of-the-art generic pre-training, benefiting downstream tasks. We additionally explore applications to semantic region search and video-based object instance tracking.