 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RandomForestMLP: An Ensemble-Based Multi-Layer Perceptron Against Curse of Dimensionality
Nov 02, 2020
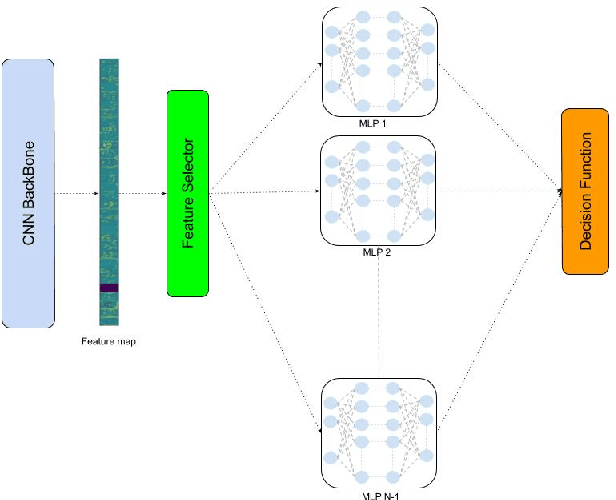
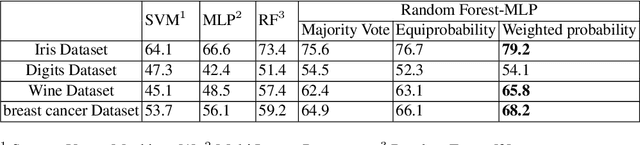
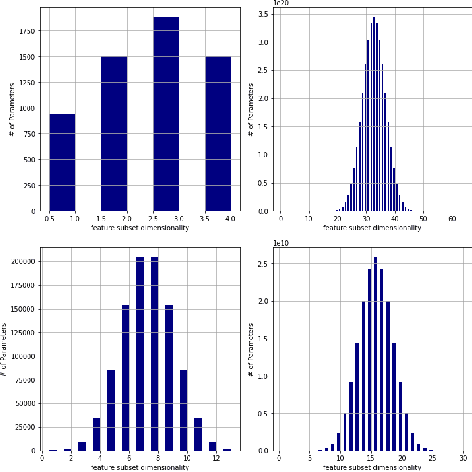
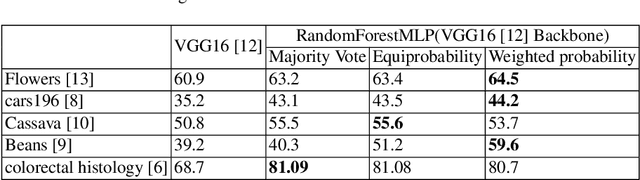
We present a novel and practical deep learning pipeline termed RandomForestMLP. This core trainable classification engine consists of a convolutional neural network backbone followed by an ensemble-based multi-layer perceptrons core for the classification task. It is designed in the context of self and semi-supervised learning tasks to avoid overfitting while training on very small datasets. The paper details the architecture of the RandomForestMLP and present different strategies for neural network decision aggregation. Then, it assesses its robustness to overfitting when trained on realistic image datasets and compares its classification performance with existing regular classifiers.
Mapping Low-Resolution Images To Multiple High-Resolution Images Using Non-Adversarial Mapping
Jun 21, 2020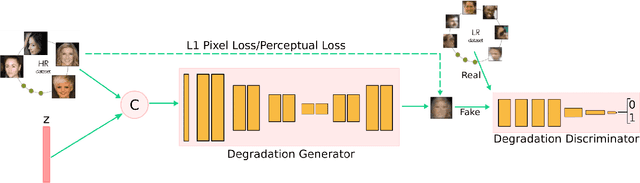
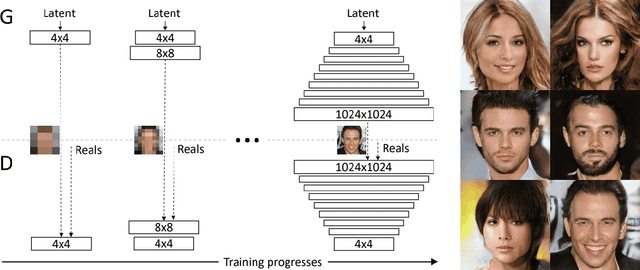
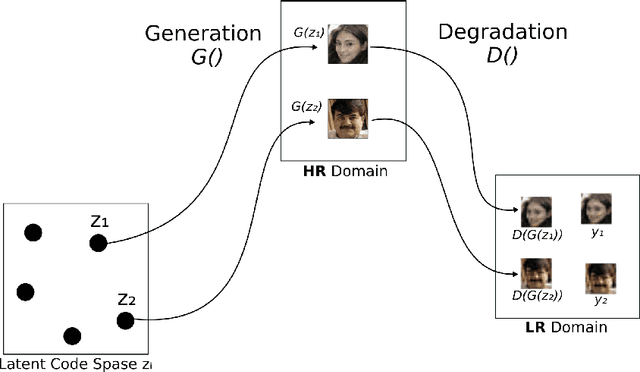

Several methods have recently been proposed for the Single Image Super-Resolution (SISR) problem. The current methods assume that a single low-resolution image can only yield a single high-resolution image. In addition, all of these methods use low-resolution images that were artificially generated through simple bilinear down-sampling. We argue that, first and foremost, the problem of SISR is an one-to-many mapping problem between the low resolution and all possible candidate high-resolution images and we address the challenging task of learning how to realistically degrade and down-sample high-resolution images. To circumvent this problem, we propose SR-NAM which utilizes the Non-Adversarial Mapping (NAM) technique. Furthermore, we propose a degradation model that learns how to transform high-resolution images to low-resolution images that resemble realistically taken low-resolution photos. Finally, some qualitative results for the proposed method along with the weaknesses of SR-NAM are included.
Compressive sensing with un-trained neural networks: Gradient descent finds the smoothest approximation
May 07, 2020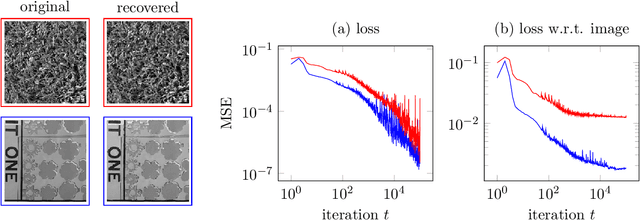
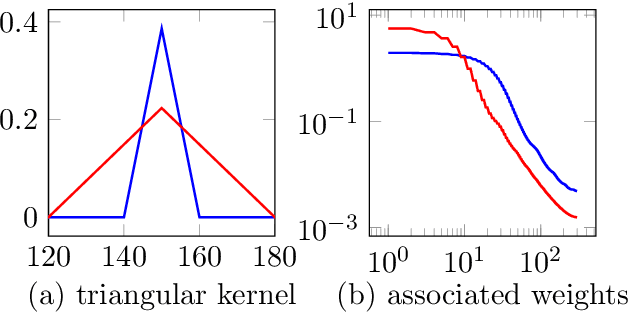
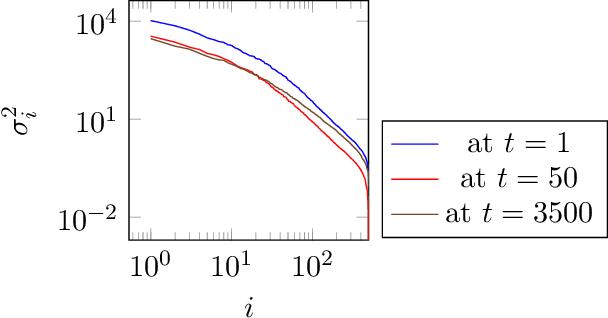
Un-trained convolutional neural networks have emerged as highly successful tools for image recovery and restoration. They are capable of solving standard inverse problems such as denoising and compressive sensing with excellent results by simply fitting a neural network model to measurements from a single image or signal without the need for any additional training data. For some applications, this critically requires additional regularization in the form of early stopping the optimization. For signal recovery from a few measurements, however, un-trained convolutional networks have an intriguing self-regularizing property: Even though the network can perfectly fit any image, the network recovers a natural image from few measurements when trained with gradient descent until convergence. In this paper, we provide numerical evidence for this property and study it theoretically. We show that---without any further regularization---an un-trained convolutional neural network can approximately reconstruct signals and images that are sufficiently structured, from a near minimal number of random measurements.
Density Weighted Connectivity of Grass Pixels in Image Frames for Biomass Estimation
Feb 21, 2018
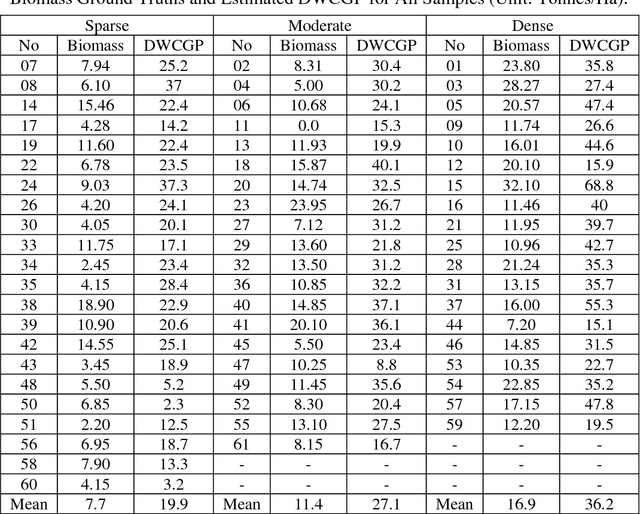
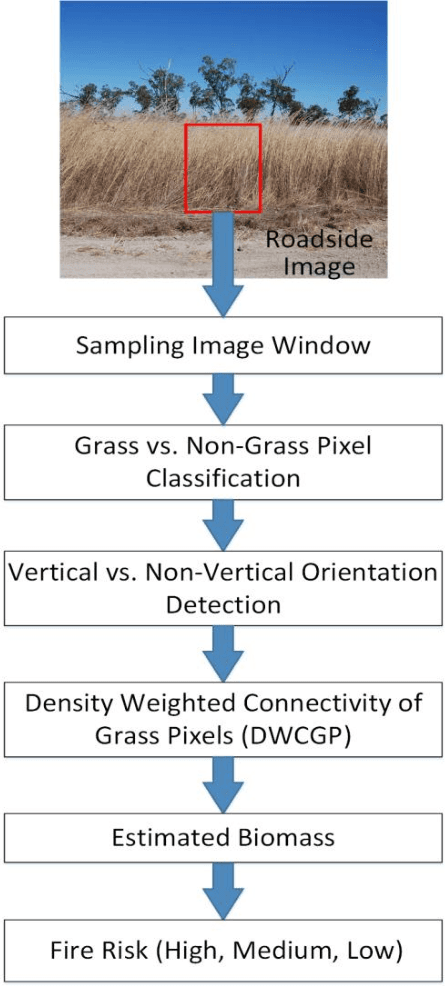

Accurate estimation of the biomass of roadside grasses plays a significant role in applications such as fire-prone region identification. Current solutions heavily depend on field surveys, remote sensing measurements and image processing using reference markers, which often demand big investments of time, effort and cost. This paper proposes Density Weighted Connectivity of Grass Pixels (DWCGP) to automatically estimate grass biomass from roadside image data. The DWCGP calculates the length of continuously connected grass pixels along a vertical orientation in each image column, and then weights the length by the grass density in a surrounding region of the column. Grass pixels are classified using feedforward artificial neural networks and the dominant texture orientation at every pixel is computed using multi-orientation Gabor wavelet filter vote. Evaluations on a field survey dataset show that the DWCGP reduces Root-Mean-Square Error from 5.84 to 5.52 by additionally considering grass density on top of grass height. The DWCGP shows robustness to non-vertical grass stems and to changes of both Gabor filter parameters and surrounding region widths. It also has performance close to human observation and higher than eight baseline approaches, as well as promising results for classifying low vs. high fire risk and identifying fire-prone road regions.
EDN: Salient Object Detection via Extremely-Downsampled Network
Dec 24, 2020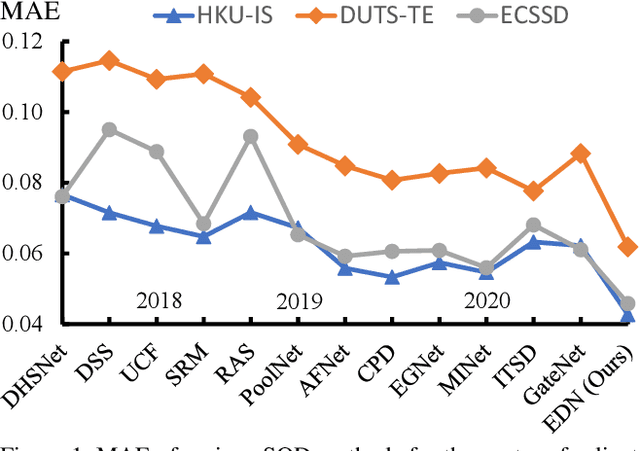
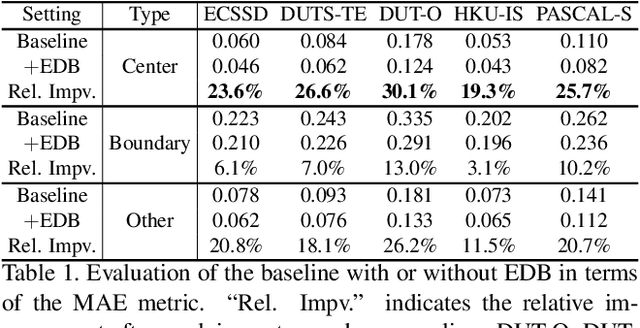
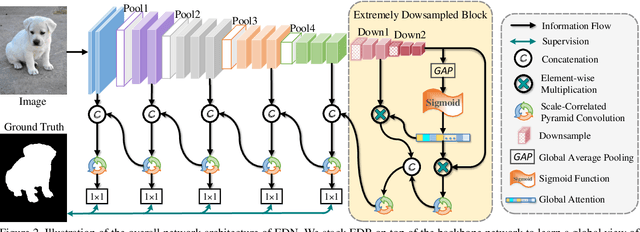
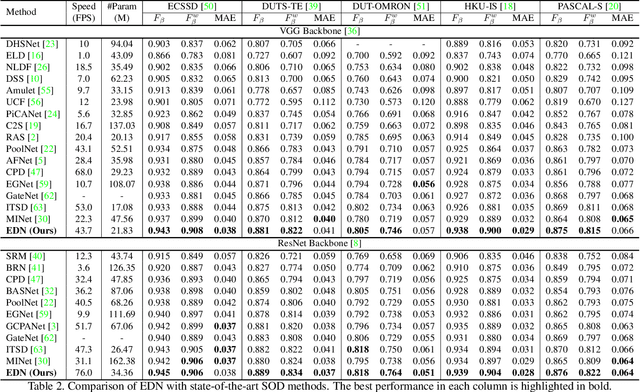
Recent progress on salient object detection (SOD) mainly benefits from multi-scale learning, where the high-level and low-level features work collaboratively in locating salient objects and discovering fine details, respectively. However, most efforts are devoted to low-level feature learning by fusing multi-scale features or enhancing boundary representations. In this paper, we show another direction that improving high-level feature learning is essential for SOD as well. To verify this, we introduce an Extremely-Downsampled Network (EDN), which employs an extreme downsampling technique to effectively learn a global view of the whole image, leading to accurate salient object localization. A novel Scale-Correlated Pyramid Convolution (SCPC) is also designed to build an elegant decoder for recovering object details from the above extreme downsampling. Extensive experiments demonstrate that EDN achieves \sArt performance with real-time speed. Hence, this work is expected to spark some new thinking in SOD. The code will be released.
Self-Supervised Representation Learning for Astronomical Images
Dec 24, 2020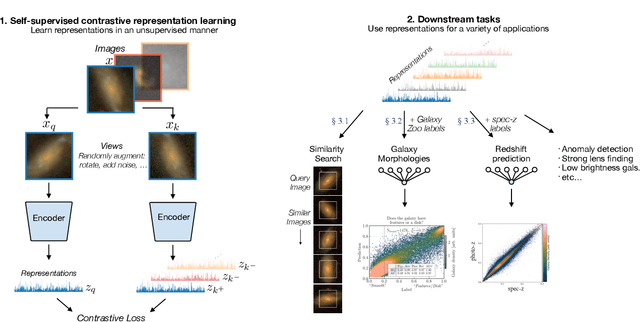

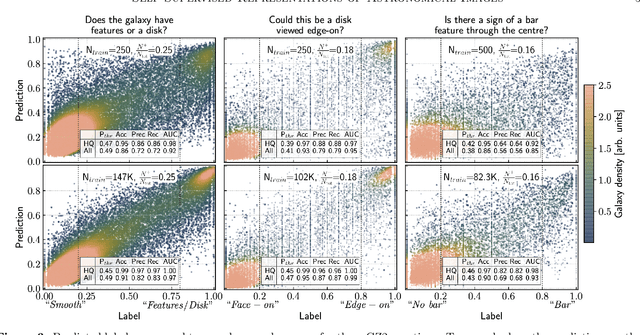
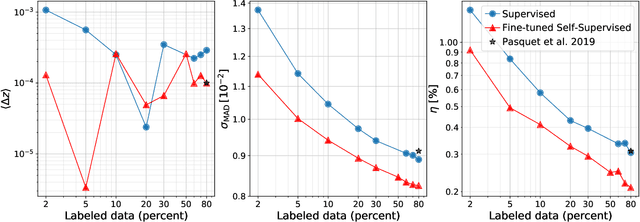
Sky surveys are the largest data generators in astronomy, making automated tools for extracting meaningful scientific information an absolute necessity. We show that, without the need for labels, self-supervised learning recovers representations of sky survey images that are semantically useful for a variety of scientific tasks. These representations can be directly used as features, or fine-tuned, to outperform supervised methods trained only on labeled data. We apply a contrastive learning framework on multi-band galaxy photometry from the Sloan Digital Sky Survey (SDSS) to learn image representations. We then use them for galaxy morphology classification, and fine-tune them for photometric redshift estimation, using labels from the Galaxy Zoo 2 dataset and SDSS spectroscopy. In both downstream tasks, using the same learned representations, we outperform the supervised state-of-the-art results, and we show that our approach can achieve the accuracy of supervised models while using 2-4 times fewer labels for training.
Transformer Interpretability Beyond Attention Visualization
Dec 17, 2020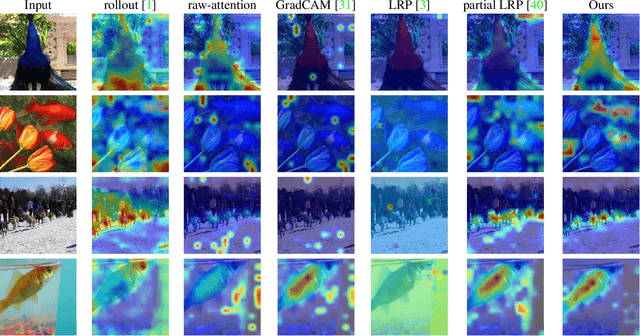


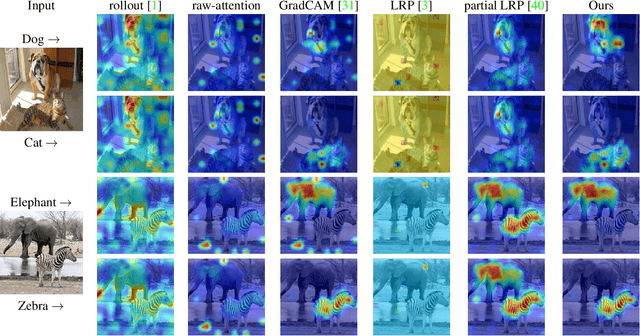
Self-attention techniques, and specifically Transformers, are dominating the field of text processing and are becoming increasingly popular in computer vision classification tasks. In order to visualize the parts of the image that led to a certain classification, existing methods either rely on the obtained attention maps, or employ heuristic propagation along the attention graph. In this work, we propose a novel way to compute relevancy for Transformer networks. The method assigns local relevance based on the deep Taylor decomposition principle and then propagates these relevancy scores through the layers. This propagation involves attention layers and skip connections, which challenge existing methods. Our solution is based on a specific formulation that is shown to maintain the total relevancy across layers. We benchmark our method on very recent visual Transformer networks, as well as on a text classification problem, and demonstrate a clear advantage over the existing explainability methods.
Comparison of Update and Genetic Training Algorithms in a Memristor Crossbar Perceptron
Dec 10, 2020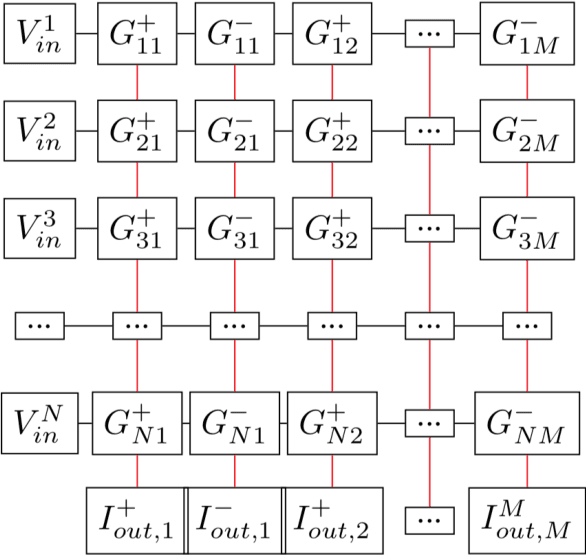
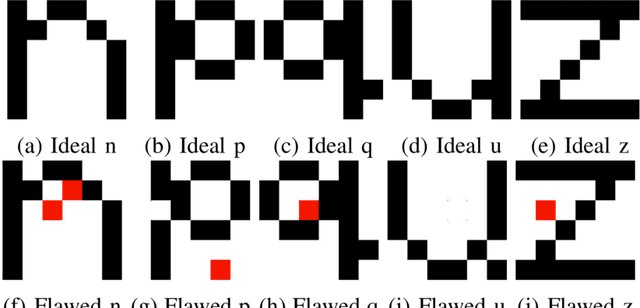
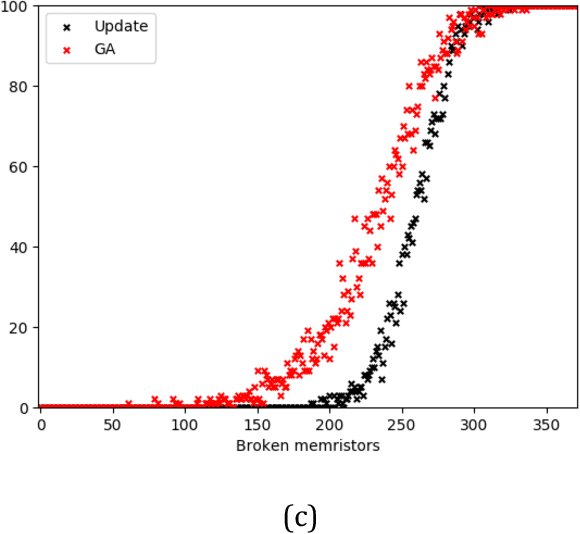
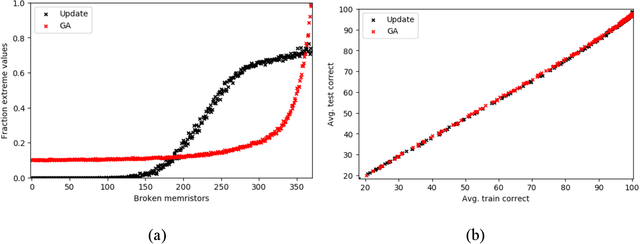
Memristor-based computer architectures are becoming more attractive as a possible choice of hardware for the implementation of neural networks. However, at present, memristor technologies are susceptible to a variety of failure modes, a serious concern in any application where regular access to the hardware may not be expected or even possible. In this study, we investigate whether certain training algorithms may be more resilient to particular hardware failure modes, and therefore more suitable for use in those applications. We implement two training algorithms -- a local update scheme and a genetic algorithm -- in a simulated memristor crossbar, and compare their ability to train for a simple image classification task as an increasing number of memristors fail to adjust their conductance. We demonstrate that there is a clear distinction between the two algorithms in several measures of the rate of failure to train.
TOM-Net: Learning Transparent Object Matting from a Single Image
Mar 29, 2018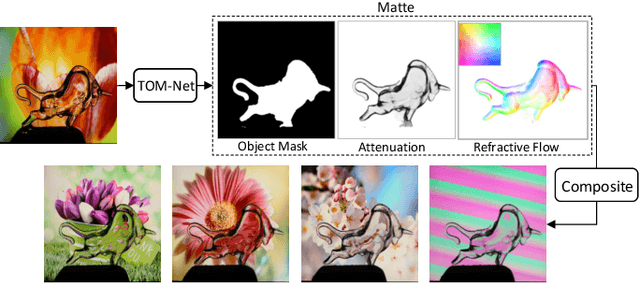
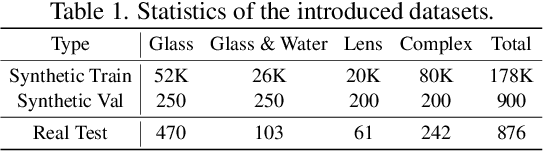
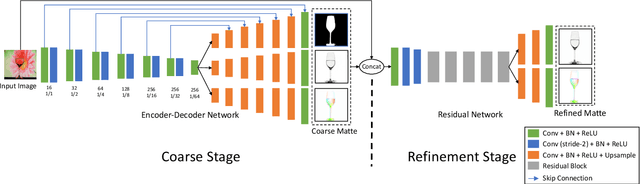
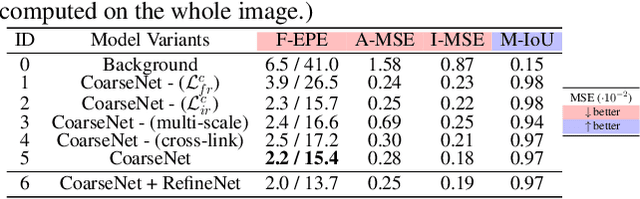
This paper addresses the problem of transparent object matting. Existing image matting approaches for transparent objects often require tedious capturing procedures and long processing time, which limit their practical use. In this paper, we first formulate transparent object matting as a refractive flow estimation problem. We then propose a deep learning framework, called TOM-Net, for learning the refractive flow. Our framework comprises two parts, namely a multi-scale encoder-decoder network for producing a coarse prediction, and a residual network for refinement. At test time, TOM-Net takes a single image as input, and outputs a matte (consisting of an object mask, an attenuation mask and a refractive flow field) in a fast feed-forward pass. As no off-the-shelf dataset is available for transparent object matting, we create a large-scale synthetic dataset consisting of 158K images of transparent objects rendered in front of images sampled from the Microsoft COCO dataset. We also collect a real dataset consisting of 876 samples using 14 transparent objects and 60 background images. Promising experimental results have been achieved on both synthetic and real data, which clearly demonstrate the effectiveness of our approach.
Learning Flow-based Feature Warping for Face Frontalization with Illumination Inconsistent Supervision
Sep 09, 2020
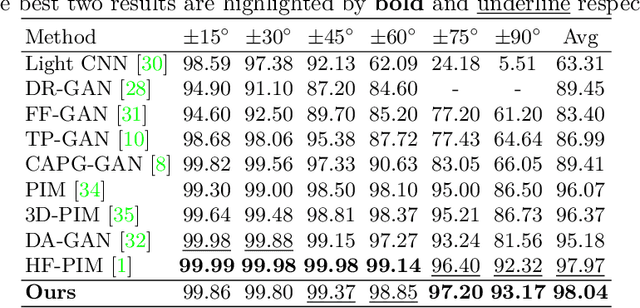
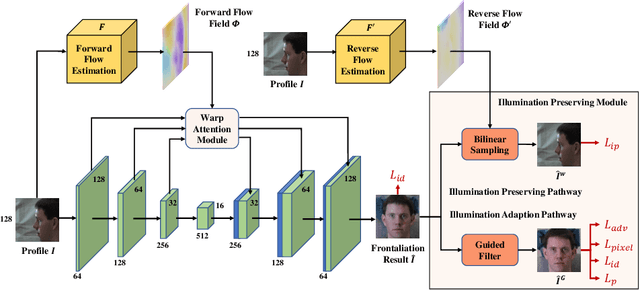

Despite recent advances in deep learning-based face frontalization methods, photo-realistic and illumination preserving frontal face synthesis is still challenging due to large pose and illumination discrepancy during training. We propose a novel Flow-based Feature Warping Model (FFWM) which can learn to synthesize photo-realistic and illumination preserving frontal images with illumination inconsistent supervision. Specifically, an Illumination Preserving Module (IPM) is proposed to learn illumination preserving image synthesis from illumination inconsistent image pairs. IPM includes two pathways which collaborate to ensure the synthesized frontal images are illumination preserving and with fine details. Moreover, a Warp Attention Module (WAM) is introduced to reduce the pose discrepancy in the feature level, and hence to synthesize frontal images more effectively and preserve more details of profile images. The attention mechanism in WAM helps reduce the artifacts caused by the displacements between the profile and the frontal images. Quantitative and qualitative experimental results show that our FFWM can synthesize photo-realistic and illumination preserving frontal images and performs favorably against the state-of-the-art results.