 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Structured Scene Parsing by Learning with Image Descriptions
Feb 28, 2018
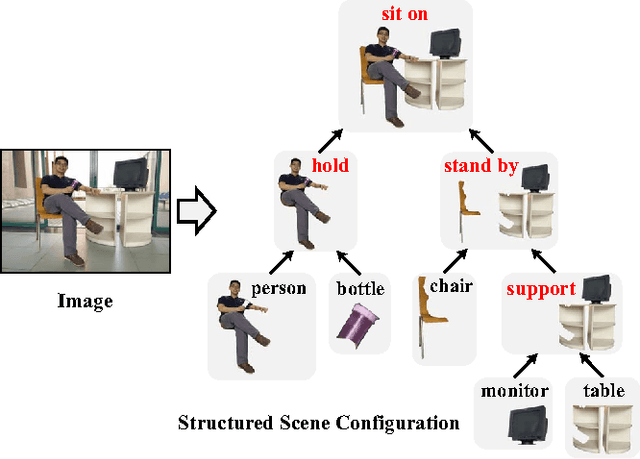
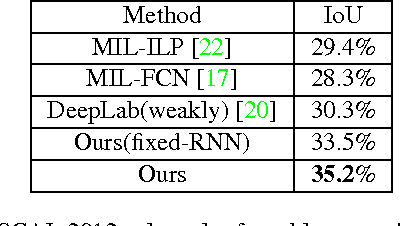
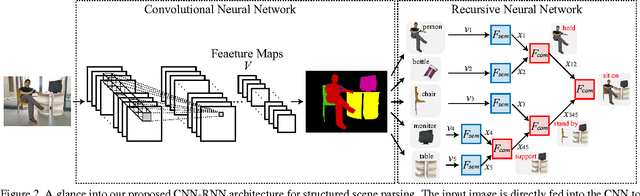
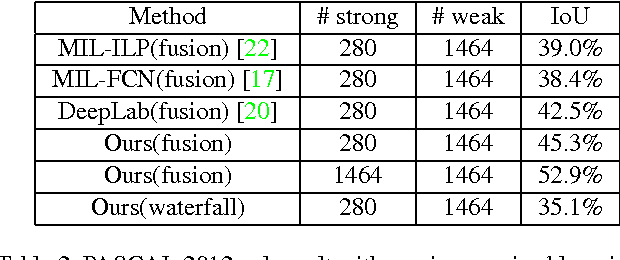
This paper addresses a fundamental problem of scene understanding: How to parse the scene image into a structured configuration (i.e., a semantic object hierarchy with object interaction relations) that finely accords with human perception. We propose a deep architecture consisting of two networks: i) a convolutional neural network (CNN) extracting the image representation for pixelwise object labeling and ii) a recursive neural network (RNN) discovering the hierarchical object structure and the inter-object relations. Rather than relying on elaborative user annotations (e.g., manually labeling semantic maps and relations), we train our deep model in a weakly-supervised manner by leveraging the descriptive sentences of the training images. Specifically, we decompose each sentence into a semantic tree consisting of nouns and verb phrases, and facilitate these trees discovering the configurations of the training images. Once these scene configurations are determined, then the parameters of both the CNN and RNN are updated accordingly by back propagation. The entire model training is accomplished through an Expectation-Maximization method. Extensive experiments suggest that our model is capable of producing meaningful and structured scene configurations and achieving more favorable scene labeling performance on PASCAL VOC 2012 over other state-of-the-art weakly-supervised methods.
TEC: Tensor Ensemble Classifier for Big Data
Feb 26, 2021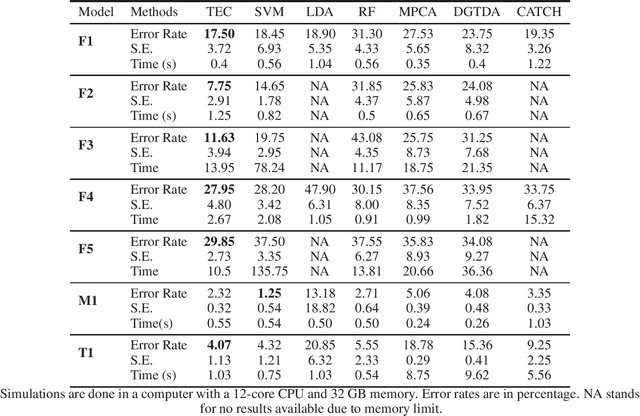
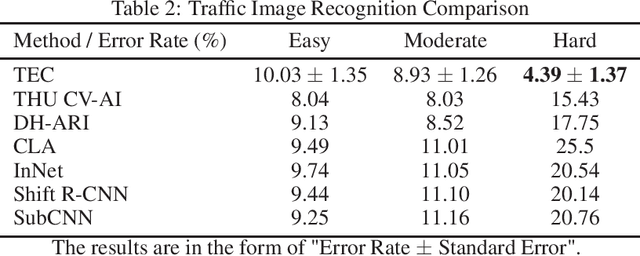
Tensor (multidimensional array) classification problem has become very popular in modern applications such as image recognition and high dimensional spatio-temporal data analysis. Support Tensor Machine (STM) classifier, which is extended from the support vector machine, takes CANDECOMP / Parafac (CP) form of tensor data as input and predicts the data labels. The distribution-free and statistically consistent properties of STM highlight its potential in successfully handling wide varieties of data applications. Training a STM can be computationally expensive with high-dimensional tensors. However, reducing the size of tensor with a random projection technique can reduce the computational time and cost, making it feasible to handle large size tensors on regular machines. We name an STM estimated with randomly projected tensor as Random Projection-based Support Tensor Machine (RPSTM). In this work, we propose a Tensor Ensemble Classifier (TEC), which aggregates multiple RPSTMs for big tensor classification. TEC utilizes the ensemble idea to minimize the excessive classification risk brought by random projection, providing statistically consistent predictions while taking the computational advantage of RPSTM. Since each RPSTM can be estimated independently, TEC can further take advantage of parallel computing techniques and be more computationally efficient. The theoretical and numerical results demonstrate the decent performance of TEC model in high-dimensional tensor classification problems. The model prediction is statistically consistent as its risk is shown to converge to the optimal Bayes risk. Besides, we highlight the trade-off between the computational cost and the prediction risk for TEC model. The method is validated by extensive simulation and a real data example. We prepare a python package for applying TEC, which is available at our GitHub.
A Multi-Modal Approach to Infer Image Affect
Mar 13, 2018
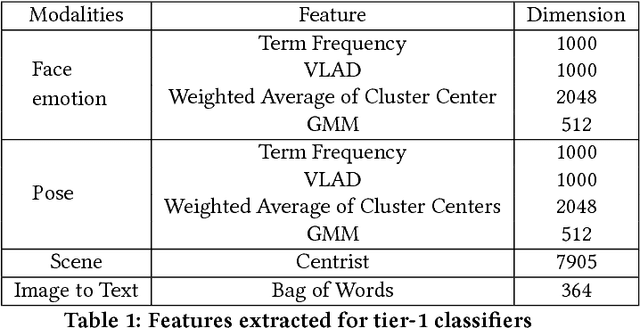

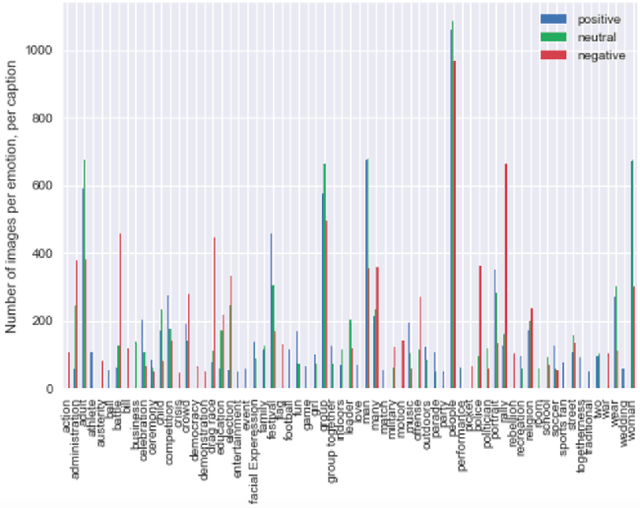
The group affect or emotion in an image of people can be inferred by extracting features about both the people in the picture and the overall makeup of the scene. The state-of-the-art on this problem investigates a combination of facial features, scene extraction and even audio tonality. This paper combines three additional modalities, namely, human pose, text-based tagging and CNN extracted features / predictions. To the best of our knowledge, this is the first time all of the modalities were extracted using deep neural networks. We evaluate the performance of our approach against baselines and identify insights throughout this paper.
GRCNN: Graph Recognition Convolutional Neural Network for Synthesizing Programs from Flow Charts
Nov 11, 2020
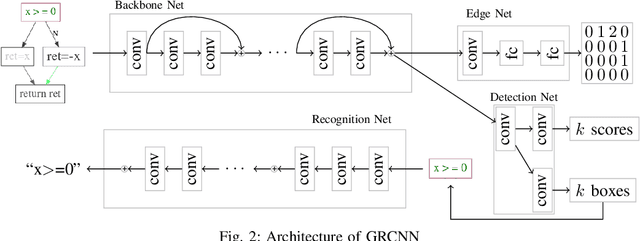

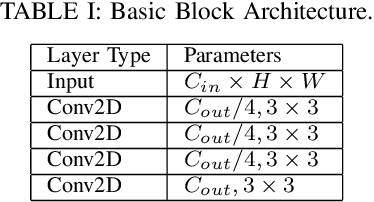
Program synthesis is the task to automatically generate programs based on user specification. In this paper, we present a framework that synthesizes programs from flow charts that serve as accurate and intuitive specifications. In order doing so, we propose a deep neural network called GRCNN that recognizes graph structure from its image. GRCNN is trained end-to-end, which can predict edge and node information of the flow chart simultaneously. Experiments show that the accuracy rate to synthesize a program is 66.4%, and the accuracy rates to recognize edge and nodes are 94.1% and 67.9%, respectively. On average, it takes about 60 milliseconds to synthesize a program.
One-Shot learning based classification for segregation of plastic waste
Sep 29, 2020
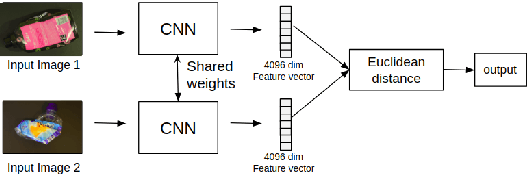
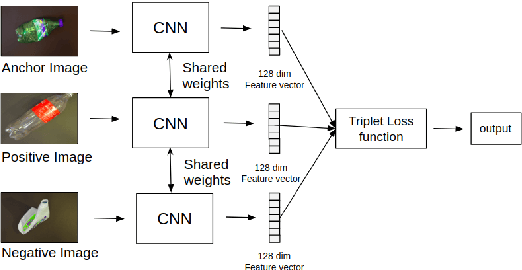
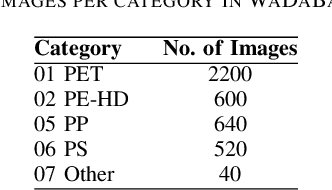
The problem of segregating recyclable waste is fairly daunting for many countries. This article presents an approach for image based classification of plastic waste using one-shot learning techniques. The proposed approach exploits discriminative features generated via the siamese and triplet loss convolutional neural networks to help differentiate between 5 types of plastic waste based on their resin codes. The approach achieves an accuracy of 99.74% on the WaDaBa Database
Analyzing and Improving Generative Adversarial Training for Generative Modeling and Out-of-Distribution Detection
Dec 11, 2020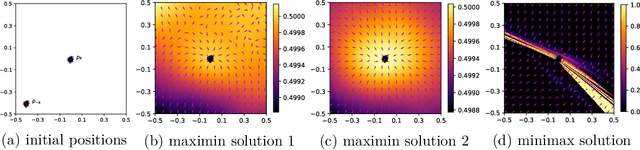
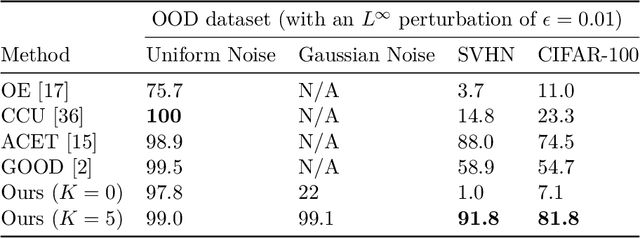


Generative adversarial training (GAT) is a recently introduced adversarial defense method. Previous works have focused on empirical evaluations of its application to training robust predictive models. In this paper we focus on theoretical understanding of the GAT method and extending its application to generative modeling and out-of-distribution detection. We analyze the optimal solutions of the maximin formulation employed by the GAT objective, and make a comparative analysis of the minimax formulation employed by GANs. We use theoretical analysis and 2D simulations to understand the convergence property of the training algorithm. Based on these results, we develop an incremental generative training algorithm, and conduct comprehensive evaluations of the algorithm's application to image generation and adversarial out-of-distribution detection. Our results suggest that generative adversarial training is a promising new direction for the above applications.
Deinterlacing Network for Early Interlaced Videos
Nov 27, 2020

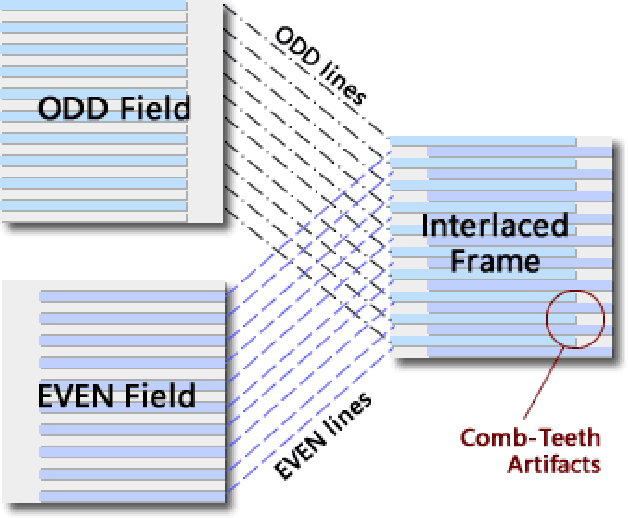
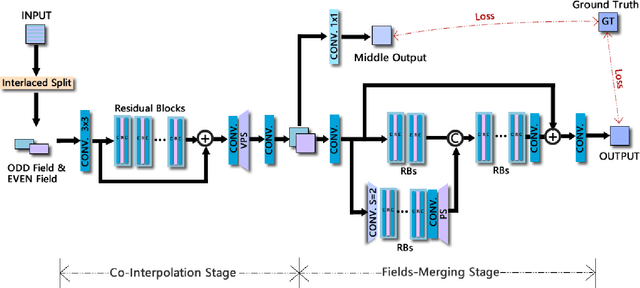
With the rapid development of image restoration techniques, high-definition reconstruction of early videos has achieved impressive results. However, there are few studies about the interlacing artifacts that often appear in early videos and significantly affect visual perception. Traditional deinterlacing approaches are mainly focused on early interlacing scanning systems and thus cannot handle the complex and complicated artifacts in real-world early interlaced videos. Hence, this paper proposes a specific deinterlacing network (DIN), which is motivated by the traditional deinterlacing strategy. The proposed DIN consists of two stages, i.e., a cooperative vertical interpolation stage for split fields, and a merging stage that is applied to perceive movements and remove ghost artifacts. Experimental results demonstrate that the proposed method can effectively remove complex artifacts in early interlaced videos.
Image Registration of Very Large Images via Genetic Programming
Nov 21, 2017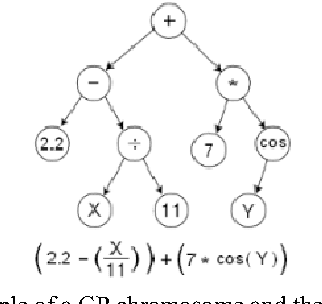

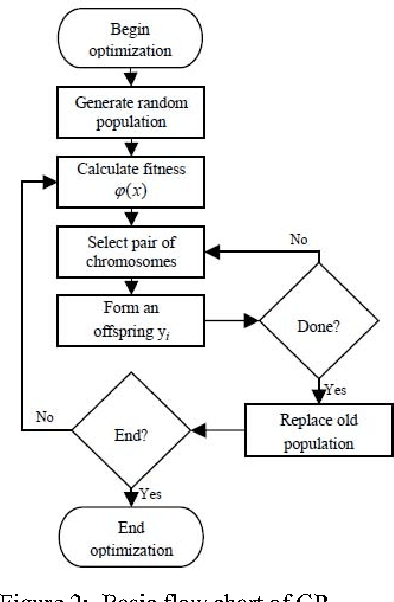
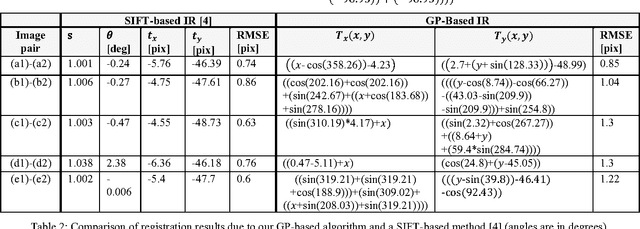
Image registration (IR) is a fundamental task in image processing for matching two or more images of the same scene taken at different times, from different viewpoints and/or by different sensors. Due to the enormous diversity of IR applications, automatic IR remains a challenging problem to this day. A wide range of techniques has been developed for various data types and problems. However, they might not handle effectively very large images, which give rise usually to more complex transformations, e.g., deformations and various other distortions. In this paper we present a genetic programming (GP)-based approach for IR, which could offer a significant advantage in dealing with very large images, as it does not make any prior assumptions about the transformation model. Thus, by incorporating certain generic building blocks into the proposed GP framework, we hope to realize a large set of specialized transformations that should yield accurate registration of very large images.
See Clearer at Night: Towards Robust Nighttime Semantic Segmentation through Day-Night Image Conversion
Aug 16, 2019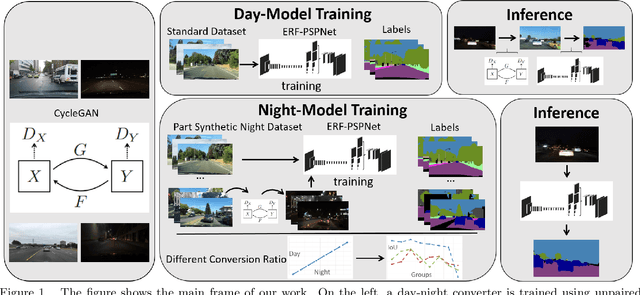


Currently, semantic segmentation shows remarkable efficiency and reliability in standard scenarios such as daytime scenes with favorable illumination conditions. However, in face of adverse conditions such as the nighttime, semantic segmentation loses its accuracy significantly. One of the main causes of the problem is the lack of sufficient annotated segmentation datasets of nighttime scenes. In this paper, we propose a framework to alleviate the accuracy decline when semantic segmentation is taken to adverse conditions by using Generative Adversarial Networks (GANs). To bridge the daytime and nighttime image domains, we made key observation that compared to datasets in adverse conditions, there are considerable amount of segmentation datasets in standard conditions such as BDD and our collected ZJU datasets. Our GAN-based nighttime semantic segmentation framework includes two methods. In the first method, GANs were used to translate nighttime images to the daytime, thus semantic segmentation can be performed using robust models already trained on daytime datasets. In another method, we use GANs to translate different ratio of daytime images in the dataset to the nighttime but still with their labels. In this sense, synthetic nighttime segmentation datasets can be generated to yield models prepared to operate at nighttime conditions robustly. In our experiment, the later method significantly boosts the performance at the nighttime evidenced by quantitative results using Intersection over Union (IoU) and Pixel Accuracy (Acc). We show that the performance varies with respect to the proportion of synthetic nighttime images in the dataset, where the sweet spot corresponds to most robust performance across the day and night.
Filtered Manifold Alignment
Nov 11, 2020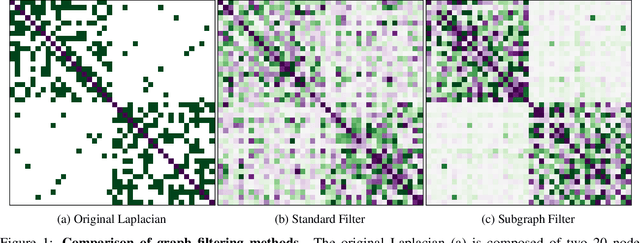
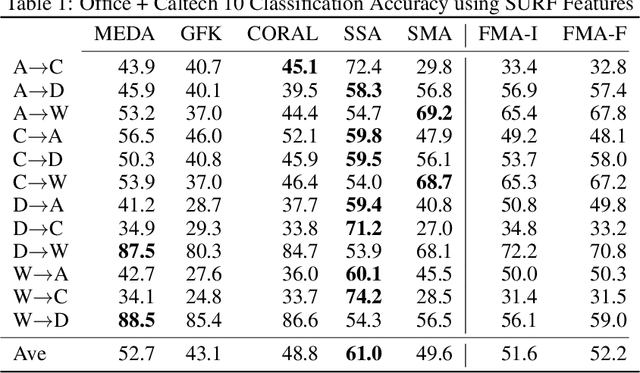
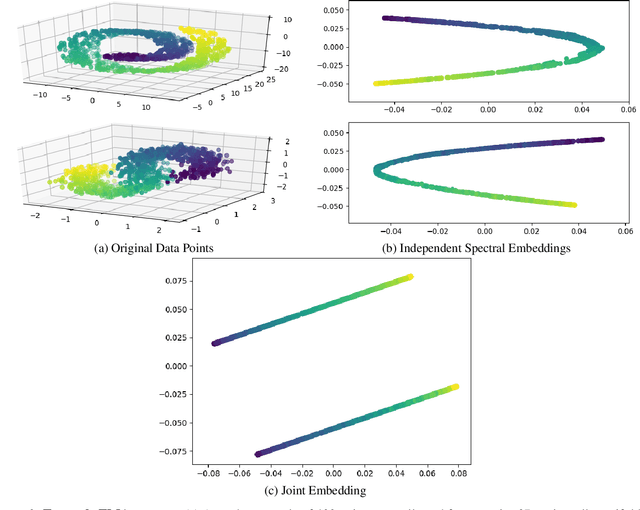
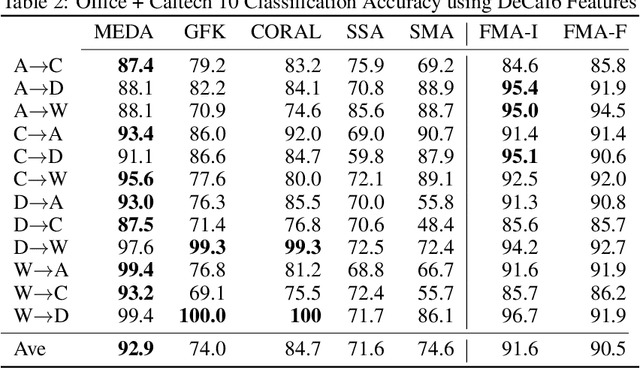
Domain adaptation is an essential task in transfer learning to leverage data in one domain to bolster learning in another domain. In this paper, we present a new semi-supervised manifold alignment technique based on a two-step approach of projecting and filtering the source and target domains to low dimensional spaces followed by joining the two spaces. Our proposed approach, filtered manifold alignment (FMA), reduces the computational complexity of previous manifold alignment techniques, is flexible enough to align domains with completely disparate sets of feature and demonstrates state-of-the-art classification accuracy on multiple benchmark domain adaptation tasks composed of classifying real world image datasets.