 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Surface Scattering Parameters From SAR Images Using Differentiable Ray Tracing
Jan 02, 2024
Simulating high-resolution Synthetic Aperture Radar (SAR) images in complex scenes has consistently presented a significant research challenge. The development of a microwave-domain surface scattering model and its reversibility are poised to play a pivotal role in enhancing the authenticity of SAR image simulations and facilitating the reconstruction of target parameters. Drawing inspiration from the field of computer graphics, this paper proposes a surface microwave rendering model that comprehensively considers both Specular and Diffuse contributions. The model is analytically represented by the coherent spatially varying bidirectional scattering distribution function (CSVBSDF) based on the Kirchhoff approximation (KA) and the perturbation method (SPM). And SAR imaging is achieved through the synergistic combination of ray tracing and fast mapping projection techniques. Furthermore, a differentiable ray tracing (DRT) engine based on SAR images was constructed for CSVBSDF surface scattering parameter learning. Within this SAR image simulation engine, the use of differentiable reverse ray tracing enables the rapid estimation of parameter gradients from SAR images. The effectiveness of this approach has been validated through simulations and comparisons with real SAR images. By learning the surface scattering parameters, substantial enhancements in SAR image simulation performance under various observation conditions have been demonstrated.
VoxelNextFusion: A Simple, Unified and Effective Voxel Fusion Framework for Multi-Modal 3D Object Detection
Jan 05, 2024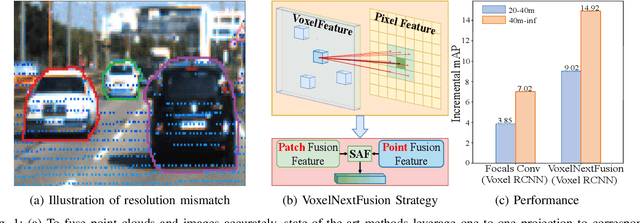
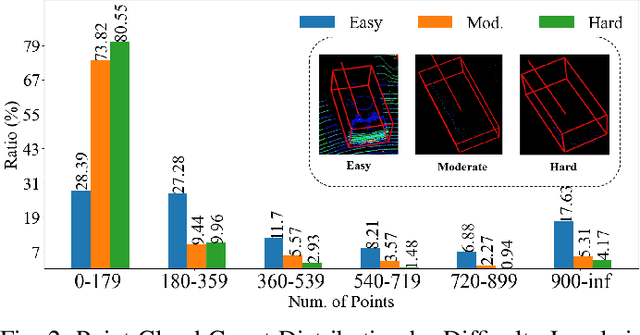
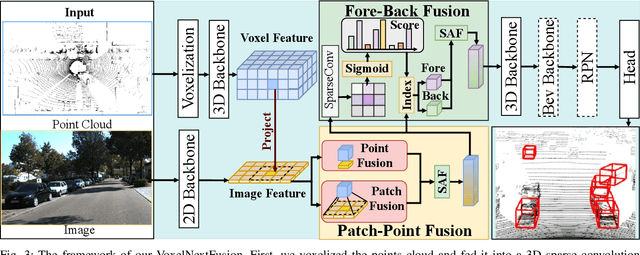
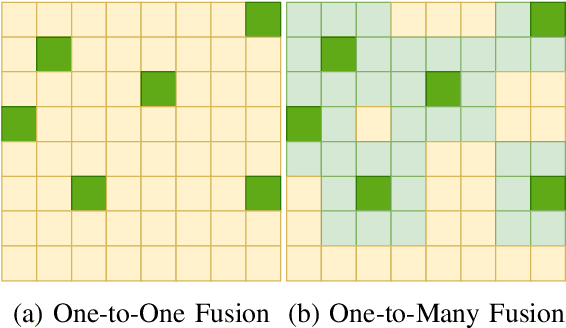
LiDAR-camera fusion can enhance the performance of 3D object detection by utilizing complementary information between depth-aware LiDAR points and semantically rich images. Existing voxel-based methods face significant challenges when fusing sparse voxel features with dense image features in a one-to-one manner, resulting in the loss of the advantages of images, including semantic and continuity information, leading to sub-optimal detection performance, especially at long distances. In this paper, we present VoxelNextFusion, a multi-modal 3D object detection framework specifically designed for voxel-based methods, which effectively bridges the gap between sparse point clouds and dense images. In particular, we propose a voxel-based image pipeline that involves projecting point clouds onto images to obtain both pixel- and patch-level features. These features are then fused using a self-attention to obtain a combined representation. Moreover, to address the issue of background features present in patches, we propose a feature importance module that effectively distinguishes between foreground and background features, thus minimizing the impact of the background features. Extensive experiments were conducted on the widely used KITTI and nuScenes 3D object detection benchmarks. Notably, our VoxelNextFusion achieved around +3.20% in AP@0.7 improvement for car detection in hard level compared to the Voxel R-CNN baseline on the KITTI test dataset
EVP: Enhanced Visual Perception using Inverse Multi-Attentive Feature Refinement and Regularized Image-Text Alignment
Dec 13, 2023This work presents the network architecture EVP (Enhanced Visual Perception). EVP builds on the previous work VPD which paved the way to use the Stable Diffusion network for computer vision tasks. We propose two major enhancements. First, we develop the Inverse Multi-Attentive Feature Refinement (IMAFR) module which enhances feature learning capabilities by aggregating spatial information from higher pyramid levels. Second, we propose a novel image-text alignment module for improved feature extraction of the Stable Diffusion backbone. The resulting architecture is suitable for a wide variety of tasks and we demonstrate its performance in the context of single-image depth estimation with a specialized decoder using classification-based bins and referring segmentation with an off-the-shelf decoder. Comprehensive experiments conducted on established datasets show that EVP achieves state-of-the-art results in single-image depth estimation for indoor (NYU Depth v2, 11.8% RMSE improvement over VPD) and outdoor (KITTI) environments, as well as referring segmentation (RefCOCO, 2.53 IoU improvement over ReLA). The code and pre-trained models are publicly available at https://github.com/Lavreniuk/EVP.
MsDC-DEQ-Net: Deep Equilibrium Model (DEQ) with Multi-scale Dilated Convolution for Image Compressive Sensing (CS)
Jan 05, 2024Compressive sensing (CS) is a technique that enables the recovery of sparse signals using fewer measurements than traditional sampling methods. To address the computational challenges of CS reconstruction, our objective is to develop an interpretable and concise neural network model for reconstructing natural images using CS. We achieve this by mapping one step of the iterative shrinkage thresholding algorithm (ISTA) to a deep network block, representing one iteration of ISTA. To enhance learning ability and incorporate structural diversity, we integrate aggregated residual transformations (ResNeXt) and squeeze-and-excitation (SE) mechanisms into the ISTA block. This block serves as a deep equilibrium layer, connected to a semi-tensor product network (STP-Net) for convenient sampling and providing an initial reconstruction. The resulting model, called MsDC-DEQ-Net, exhibits competitive performance compared to state-of-the-art network-based methods. It significantly reduces storage requirements compared to deep unrolling methods, using only one iteration block instead of multiple iterations. Unlike deep unrolling models, MsDC-DEQ-Net can be iteratively used, gradually improving reconstruction accuracy while considering computation trade-offs. Additionally, the model benefits from multi-scale dilated convolutions, further enhancing performance.
A dynamic interactive learning framework for automated 3D medical image segmentation
Dec 11, 2023Many deep learning based automated medical image segmentation systems, in reality, face difficulties in deployment due to the cost of massive data annotation and high latency in model iteration. We propose a dynamic interactive learning framework that addresses these challenges by integrating interactive segmentation into end-to-end weak supervised learning with streaming tasks. We develop novel replay and label smoothing schemes that overcome catastrophic forgetting and improve online learning robustness. For each image, our multi-round interactive segmentation module simultaneously optimizes both front-end predictions and deep learning segmenter. In each round, a 3D "proxy mask" is propagated from sparse user inputs based on image registration, serving as weak supervision that enable knowledge distillation from the unknown ground truth. In return, the trained segmenter explicitly guides next step's user interventions according to a spatial residual map from consecutive front or back-end predictions. Evaluation on 3D segmentation tasks (NCI-ISBI2013 and BraTS2015) shows that our framework generates online learning performances that match offline training benchmark. In addition, with a 62% reduction in total annotation efforts, our framework produces competitive dice scores comparing to online and offline learning which equipped with full ground truth. Furthermore, such a framework, with its flexibility and responsiveness, could be deployed behind hospital firewall that guarantees data security and easy maintenance.
Identifying Important Group of Pixels using Interactions
Jan 08, 2024To better understand the behavior of image classifiers, it is useful to visualize the contribution of individual pixels to the model prediction. In this study, we propose a method, MoXI~($\textbf{Mo}$del e$\textbf{X}$planation by $\textbf{I}$nteractions), that efficiently and accurately identifies a group of pixels with high prediction confidence. The proposed method employs game-theoretic concepts, Shapley values and interactions, taking into account the effects of individual pixels and the cooperative influence of pixels on model confidence. Theoretical analysis and experiments demonstrate that our method better identifies the pixels that are highly contributing to the model outputs than widely-used visualization methods using Grad-CAM, Attention rollout, and Shapley value. While prior studies have suffered from the exponential computational cost in the computation of Shapley value and interactions, we show that this can be reduced to linear cost for our task.
AUPIMO: Redefining Visual Anomaly Detection Benchmarks with High Speed and Low Tolerance
Jan 03, 2024Recent advances in visual anomaly detection research have seen AUROC and AUPRO scores on public benchmark datasets such as MVTec and VisA converge towards perfect recall, giving the impression that these benchmarks are near-solved. However, high AUROC and AUPRO scores do not always reflect qualitative performance, which limits the validity of these metrics in real-world applications. We argue that the artificial ceiling imposed by the lack of an adequate evaluation metric restrains progression of the field, and it is crucial that we revisit the evaluation metrics used to rate our algorithms. In response, we introduce Per-IMage Overlap (PIMO), a novel metric that addresses the shortcomings of AUROC and AUPRO. PIMO retains the recall-based nature of the existing metrics but introduces two distinctions: the assignment of curves (and respective area under the curve) is per-image, and its X-axis relies solely on normal images. Measuring recall per image simplifies instance score indexing and is more robust to noisy annotations. As we show, it also accelerates computation and enables the usage of statistical tests to compare models. By imposing low tolerance for false positives on normal images, PIMO provides an enhanced model validation procedure and highlights performance variations across datasets. Our experiments demonstrate that PIMO offers practical advantages and nuanced performance insights that redefine anomaly detection benchmarks -- notably challenging the perception that MVTec AD and VisA datasets have been solved by contemporary models. Available on GitHub: https://github.com/jpcbertoldo/aupimo.
STEREOFOG -- Computational DeFogging via Image-to-Image Translation on a real-world Dataset
Dec 04, 2023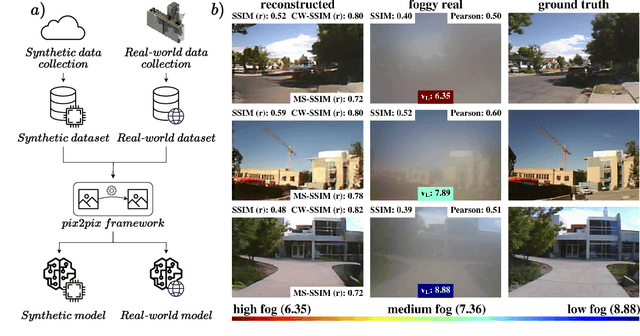

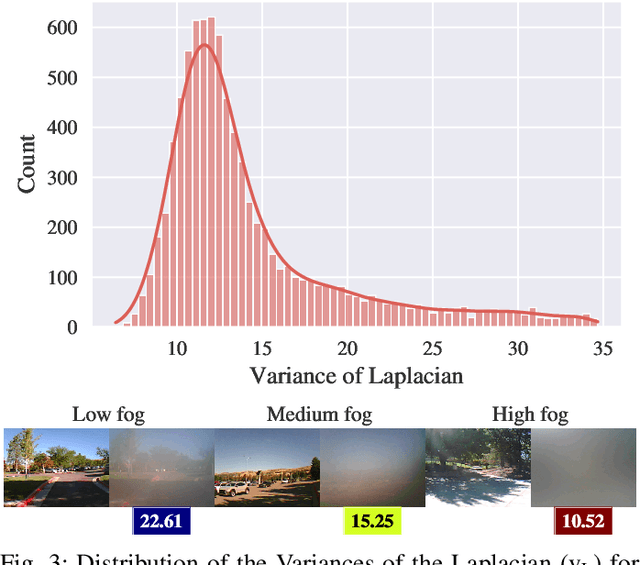

Image-to-Image translation (I2I) is a subtype of Machine Learning (ML) that has tremendous potential in applications where two domains of images and the need for translation between the two exist, such as the removal of fog. For example, this could be useful for autonomous vehicles, which currently struggle with adverse weather conditions like fog. However, datasets for I2I tasks are not abundant and typically hard to acquire. Here, we introduce STEREOFOG, a dataset comprised of $10,067$ paired fogged and clear images, captured using a custom-built device, with the purpose of exploring I2I's potential in this domain. It is the only real-world dataset of this kind to the best of our knowledge. Furthermore, we apply and optimize the pix2pix I2I ML framework to this dataset. With the final model achieving an average Complex Wavelet-Structural Similarity (CW-SSIM) score of $0.76$, we prove the technique's suitability for the problem.
Frequency Domain Modality-invariant Feature Learning for Visible-infrared Person Re-Identification
Jan 04, 2024Visible-infrared person re-identification (VI-ReID) is challenging due to the significant cross-modality discrepancies between visible and infrared images. While existing methods have focused on designing complex network architectures or using metric learning constraints to learn modality-invariant features, they often overlook which specific component of the image causes the modality discrepancy problem. In this paper, we first reveal that the difference in the amplitude component of visible and infrared images is the primary factor that causes the modality discrepancy and further propose a novel Frequency Domain modality-invariant feature learning framework (FDMNet) to reduce modality discrepancy from the frequency domain perspective. Our framework introduces two novel modules, namely the Instance-Adaptive Amplitude Filter (IAF) module and the Phrase-Preserving Normalization (PPNorm) module, to enhance the modality-invariant amplitude component and suppress the modality-specific component at both the image- and feature-levels. Extensive experimental results on two standard benchmarks, SYSU-MM01 and RegDB, demonstrate the superior performance of our FDMNet against state-of-the-art methods.
Slot-guided Volumetric Object Radiance Fields
Jan 04, 2024We present a novel framework for 3D object-centric representation learning. Our approach effectively decomposes complex scenes into individual objects from a single image in an unsupervised fashion. This method, called slot-guided Volumetric Object Radiance Fields (sVORF), composes volumetric object radiance fields with object slots as a guidance to implement unsupervised 3D scene decomposition. Specifically, sVORF obtains object slots from a single image via a transformer module, maps these slots to volumetric object radiance fields with a hypernetwork and composes object radiance fields with the guidance of object slots at a 3D location. Moreover, sVORF significantly reduces memory requirement due to small-sized pixel rendering during training. We demonstrate the effectiveness of our approach by showing top results in scene decomposition and generation tasks of complex synthetic datasets (e.g., Room-Diverse). Furthermore, we also confirm the potential of sVORF to segment objects in real-world scenes (e.g., the LLFF dataset). We hope our approach can provide preliminary understanding of the physical world and help ease future research in 3D object-centric representation learning.