 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Probabilistic 3D surface reconstruction from sparse MRI information
Oct 05, 2020
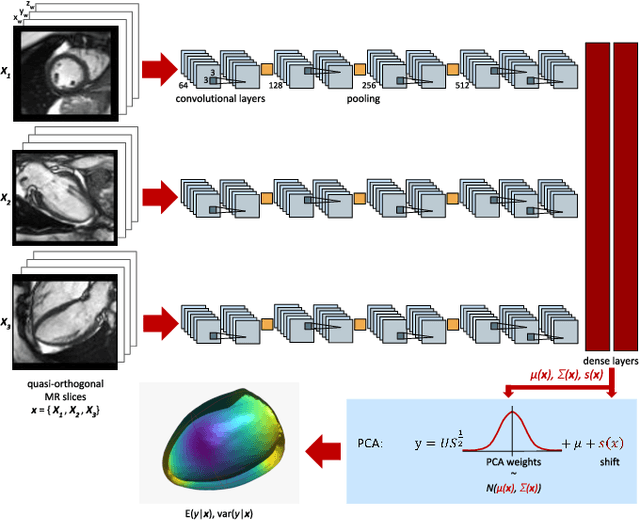
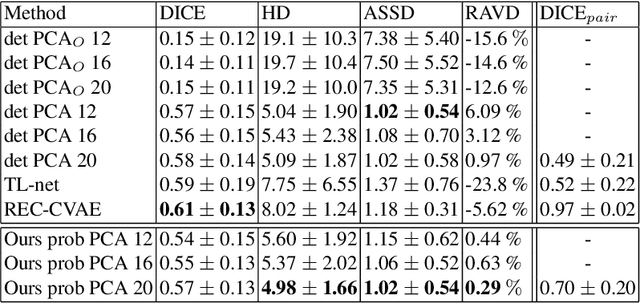

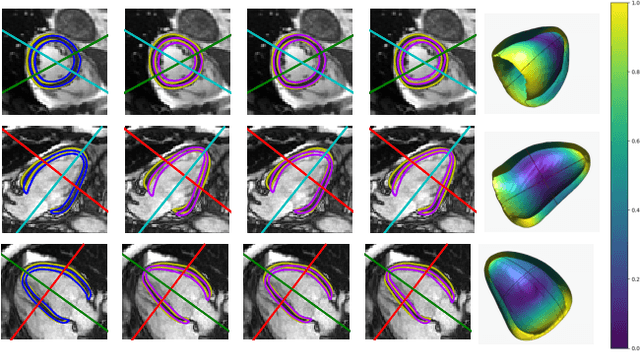
Surface reconstruction from magnetic resonance (MR) imaging data is indispensable in medical image analysis and clinical research. A reliable and effective reconstruction tool should: be fast in prediction of accurate well localised and high resolution models, evaluate prediction uncertainty, work with as little input data as possible. Current deep learning state of the art (SOTA) 3D reconstruction methods, however, often only produce shapes of limited variability positioned in a canonical position or lack uncertainty evaluation. In this paper, we present a novel probabilistic deep learning approach for concurrent 3D surface reconstruction from sparse 2D MR image data and aleatoric uncertainty prediction. Our method is capable of reconstructing large surface meshes from three quasi-orthogonal MR imaging slices from limited training sets whilst modelling the location of each mesh vertex through a Gaussian distribution. Prior shape information is encoded using a built-in linear principal component analysis (PCA) model. Extensive experiments on cardiac MR data show that our probabilistic approach successfully assesses prediction uncertainty while at the same time qualitatively and quantitatively outperforms SOTA methods in shape prediction. Compared to SOTA, we are capable of properly localising and orientating the prediction via the use of a spatially aware neural network.
Monge's Optimal Transport Distance for Image Classification
Apr 08, 2018
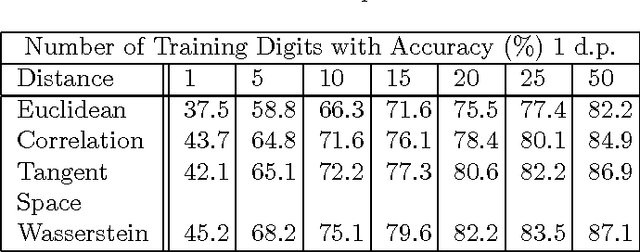
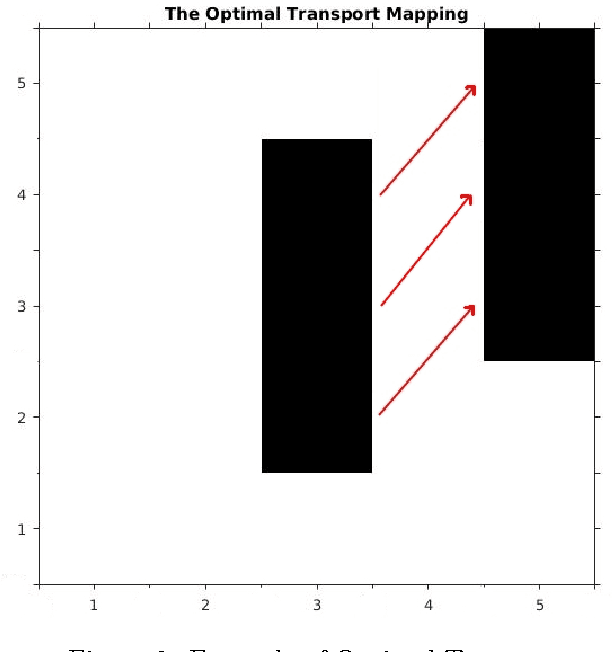
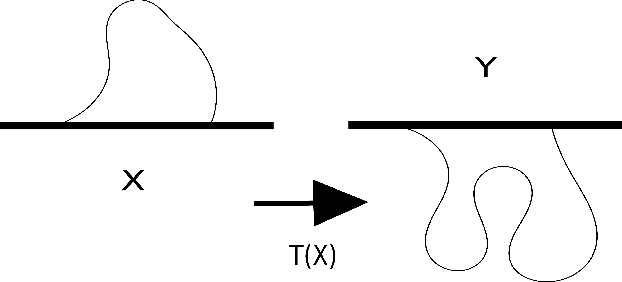
This paper focuses on a similarity measure, known as the Wasserstein distance, with which to compare images. The Wasserstein distance results from a partial differential equation (PDE) formulation of Monge's optimal transport problem. We present an efficient numerical solution method for solving Monge's problem. To demonstrate the measure's discriminatory power when comparing images, we use a $1$-Nearest Neighbour ($1$-NN) machine learning algorithm to illustrate the measure's potential benefits over other more traditional distance metrics and also the Tangent Space distance, designed to perform excellently on the well-known MNIST dataset. To our knowledge, the PDE formulation of the Wasserstein metric has not been presented for dealing with image comparison, nor has the Wasserstein distance been used within the $1$-nearest neighbour architecture.
Focal Frequency Loss for Generative Models
Dec 23, 2020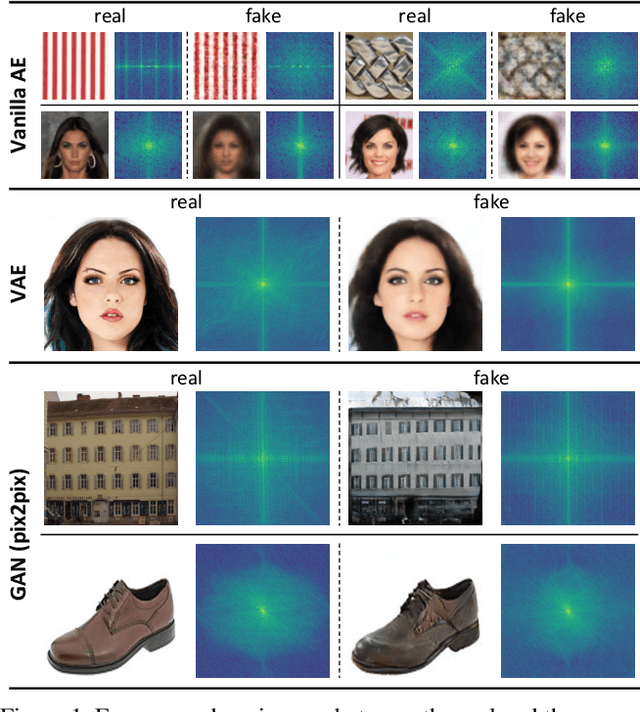
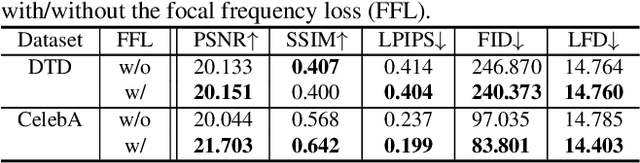

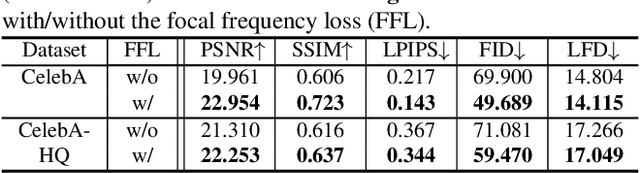
Despite the remarkable success of generative models in creating photorealistic images using deep neural networks, gaps could still exist between the real and generated images, especially in the frequency domain. In this study, we find that narrowing the frequency domain gap can ameliorate the image synthesis quality further. To this end, we propose the focal frequency loss, a novel objective function that brings optimization of generative models into the frequency domain. The proposed loss allows the model to dynamically focus on the frequency components that are hard to synthesize by down-weighting the easy frequencies. This objective function is complementary to existing spatial losses, offering great impedance against the loss of important frequency information due to the inherent crux of neural networks. We demonstrate the versatility and effectiveness of focal frequency loss to improve various baselines in both perceptual quality and quantitative performance.
A Hierarchical Distributed Processing Framework for Big Image Data
Jul 03, 2016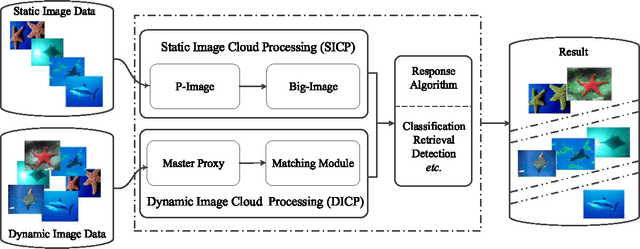

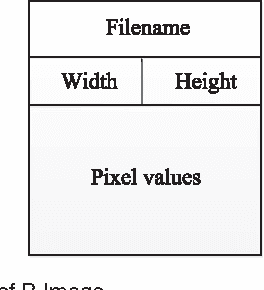

This paper introduces an effective processing framework nominated ICP (Image Cloud Processing) to powerfully cope with the data explosion in image processing field. While most previous researches focus on optimizing the image processing algorithms to gain higher efficiency, our work dedicates to providing a general framework for those image processing algorithms, which can be implemented in parallel so as to achieve a boost in time efficiency without compromising the results performance along with the increasing image scale. The proposed ICP framework consists of two mechanisms, i.e. SICP (Static ICP) and DICP (Dynamic ICP). Specifically, SICP is aimed at processing the big image data pre-stored in the distributed system, while DICP is proposed for dynamic input. To accomplish SICP, two novel data representations named P-Image and Big-Image are designed to cooperate with MapReduce to achieve more optimized configuration and higher efficiency. DICP is implemented through a parallel processing procedure working with the traditional processing mechanism of the distributed system. Representative results of comprehensive experiments on the challenging ImageNet dataset are selected to validate the capacity of our proposed ICP framework over the traditional state-of-the-art methods, both in time efficiency and quality of results.
Collaborative Teacher-Student Learning via Multiple Knowledge Transfer
Jan 27, 2021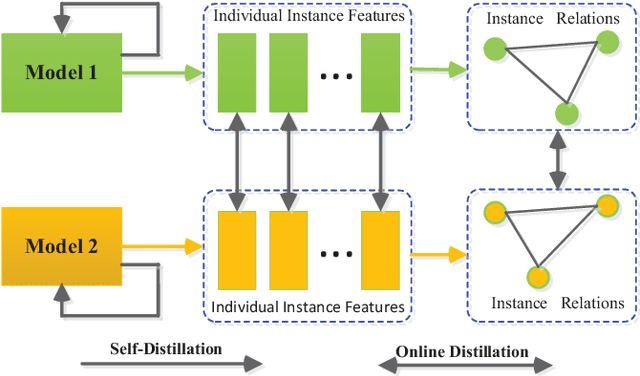

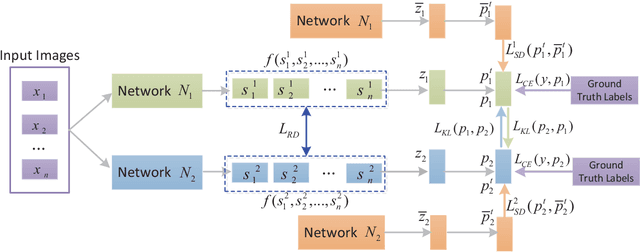
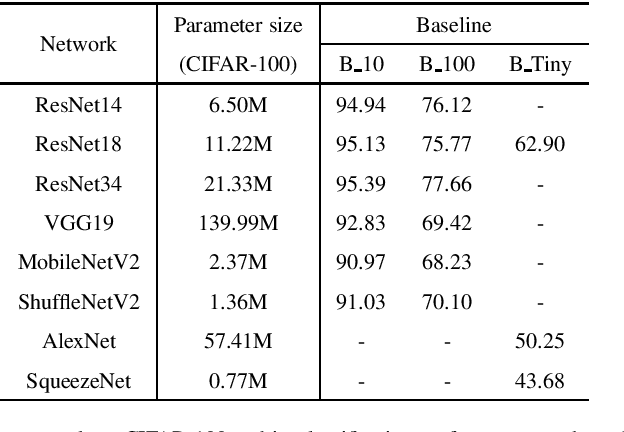
Knowledge distillation (KD), as an efficient and effective model compression technique, has been receiving considerable attention in deep learning. The key to its success is to transfer knowledge from a large teacher network to a small student one. However, most of the existing knowledge distillation methods consider only one type of knowledge learned from either instance features or instance relations via a specific distillation strategy in teacher-student learning. There are few works that explore the idea of transferring different types of knowledge with different distillation strategies in a unified framework. Moreover, the frequently used offline distillation suffers from a limited learning capacity due to the fixed teacher-student architecture. In this paper we propose a collaborative teacher-student learning via multiple knowledge transfer (CTSL-MKT) that prompts both self-learning and collaborative learning. It allows multiple students learn knowledge from both individual instances and instance relations in a collaborative way. While learning from themselves with self-distillation, they can also guide each other via online distillation. The experiments and ablation studies on four image datasets demonstrate that the proposed CTSL-MKT significantly outperforms the state-of-the-art KD methods.
Automatic label correction based on CCESD
Oct 05, 2020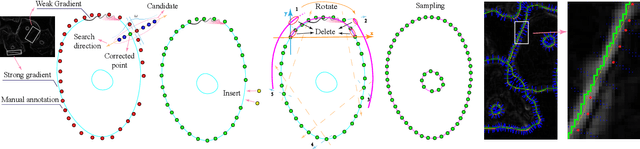
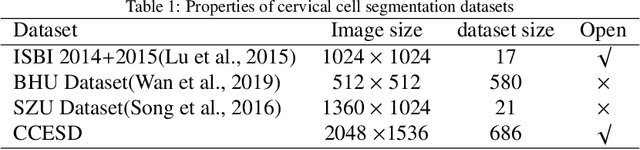
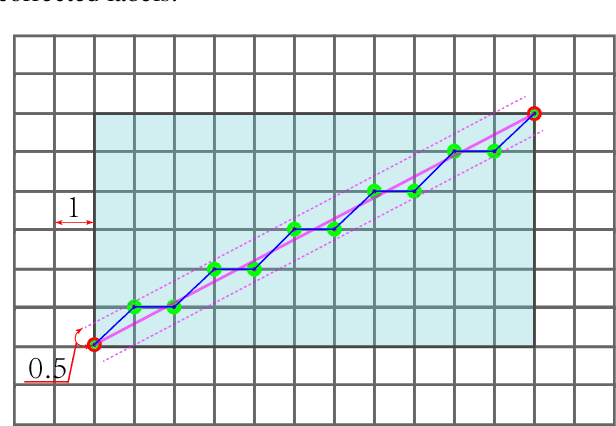
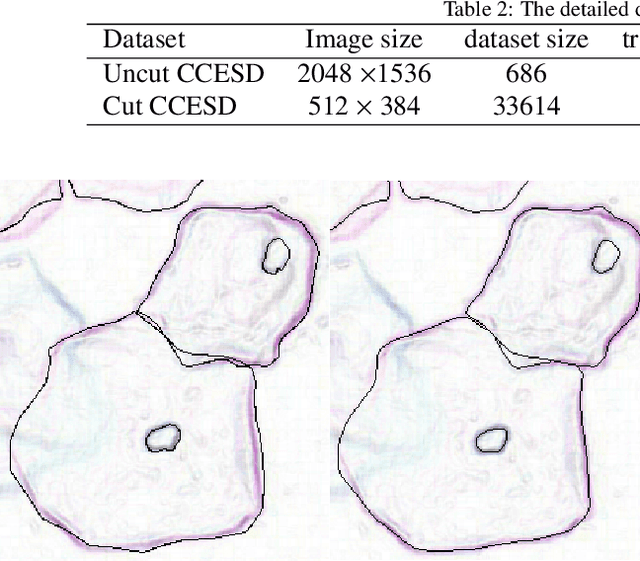
In the computer-aided diagnosis of cervical precancerous lesions, it is essential for accurate cell segmentation. For a cervical cell image with multi-cell overlap (n>3), blurry and noisy background, and low contrast, it is difficult for a professional doctor to obtain an ultra-high-precision labeled image. On the other hand, it is possible for the annotator to draw the outline of the cell as accurately as possible. However, if the label edge position is inaccurate, the accuracy of the training model will decrease, and it will have a great impact on the accuracy of the model evaluation. We designed an automatic label correction algorithm based on gradient guidance, which can solve the effects of poor edge position accuracy and differences between different annotators during manual labeling. At the same time, an open cervical cell edge segmentation dataset (CCESD) with higher labeling accuracy was constructed. We also use deep learning models to generate the baseline performance on CCESD. Using the modified labeling data to train multiple models compared to the original labeling data can be improved 7% average precision (AP). The implementation is available at https://github.com/nachifur-ljw/label_correction_based_CCESD.
Improving Object Detection with Selective Self-supervised Self-training
Jul 17, 2020
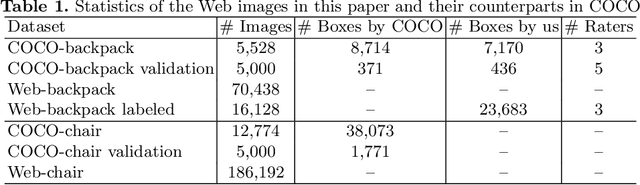

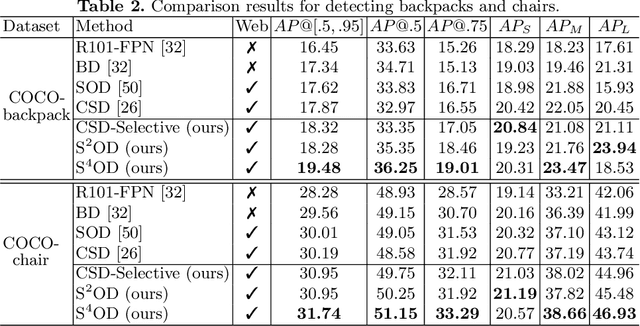
We study how to leverage Web images to augment human-curated object detection datasets. Our approach is two-pronged. On the one hand, we retrieve Web images by image-to-image search, which incurs less domain shift from the curated data than other search methods. The Web images are diverse, supplying a wide variety of object poses, appearances, their interactions with the context, etc. On the other hand, we propose a novel learning method motivated by two parallel lines of work that explore unlabeled data for image classification: self-training and self-supervised learning. They fail to improve object detectors in their vanilla forms due to the domain gap between the Web images and curated datasets. To tackle this challenge, we propose a selective net to rectify the supervision signals in Web images. It not only identifies positive bounding boxes but also creates a safe zone for mining hard negative boxes. We report state-of-the-art results on detecting backpacks and chairs from everyday scenes, along with other challenging object classes.
Unlimited Resolution Image Generation with R2D2-GANs
Mar 02, 2020

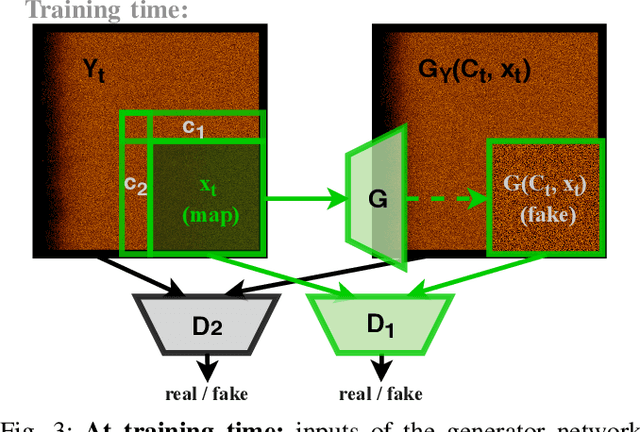
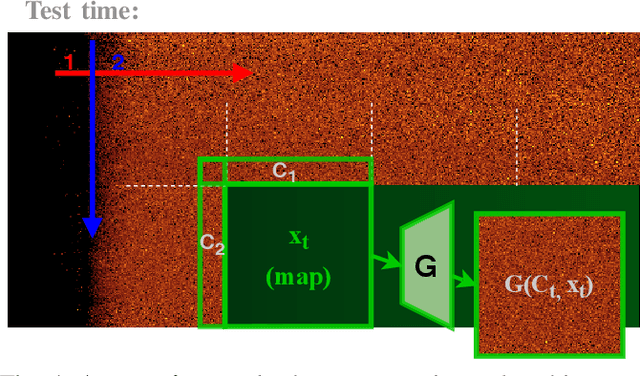
In this paper we present a novel simulation technique for generating high quality images of any predefined resolution. This method can be used to synthesize sonar scans of size equivalent to those collected during a full-length mission, with across track resolutions of any chosen magnitude. In essence, our model extends Generative Adversarial Networks (GANs) based architecture into a conditional recursive setting, that facilitates the continuity of the generated images. The data produced is continuous, realistically-looking, and can also be generated at least two times faster than the real speed of acquisition for the sonars with higher resolutions, such as EdgeTech. The seabed topography can be fully controlled by the user. The visual assessment tests demonstrate that humans cannot distinguish the simulated images from real. Moreover, experimental results suggest that in the absence of real data the autonomous recognition systems can benefit greatly from training with the synthetic data, produced by the R2D2-GANs.
PCB Defect Detection Using Denoising Convolutional Autoencoders
Aug 28, 2020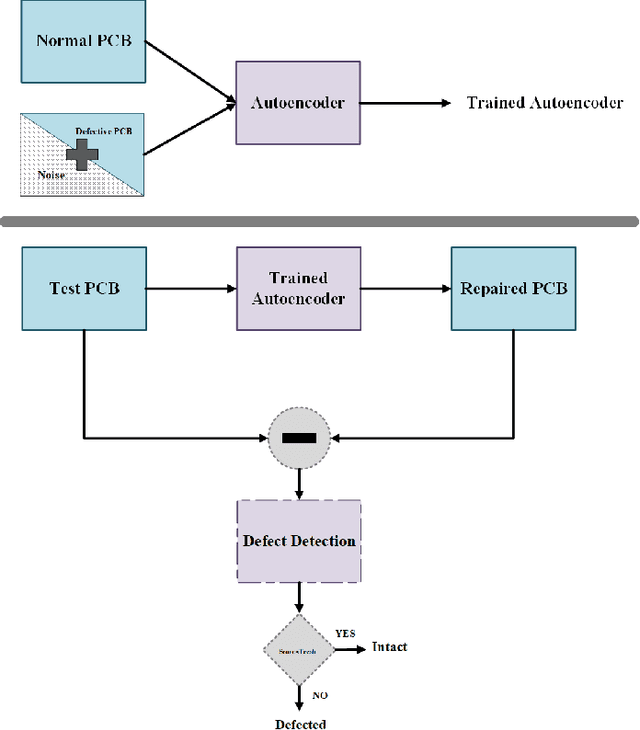
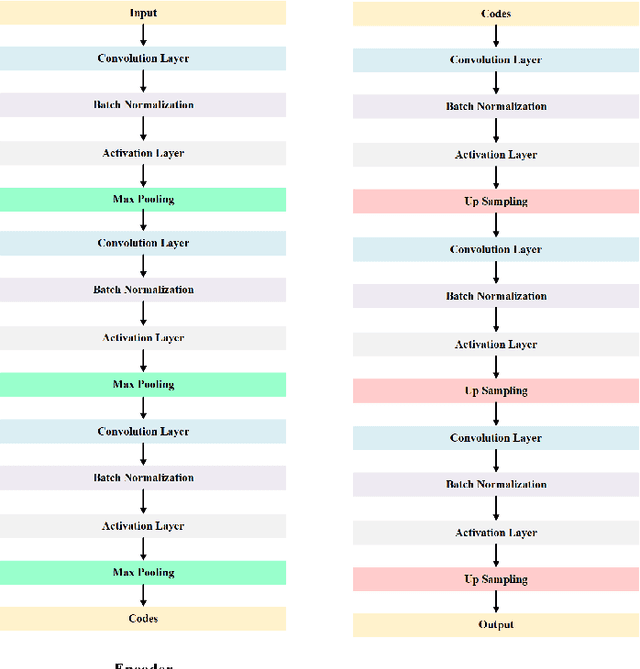

Printed Circuit boards (PCBs) are one of the most important stages in making electronic products. A small defect in PCBs can cause significant flaws in the final product. Hence, detecting all defects in PCBs and locating them is essential. In this paper, we propose an approach based on denoising convolutional autoencoders for detecting defective PCBs and to locate the defects. Denoising autoencoders take a corrupted image and try to recover the intact image. We trained our model with defective PCBs and forced it to repair the defective parts. Our model not only detects all kinds of defects and locates them, but it can also repair them as well. By subtracting the repaired output from the input, the defective parts are located. The experimental results indicate that our model detects the defective PCBs with high accuracy (97.5%) compare to state of the art works.
RCoNet: Deformable Mutual Information Maximization and High-order Uncertainty-aware Learning for Robust COVID-19 Detection
Feb 22, 2021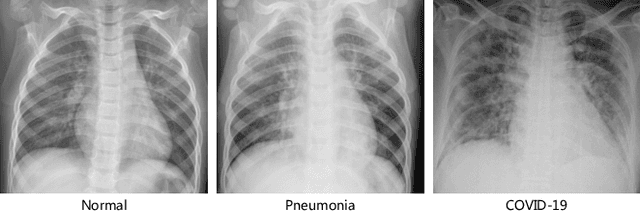
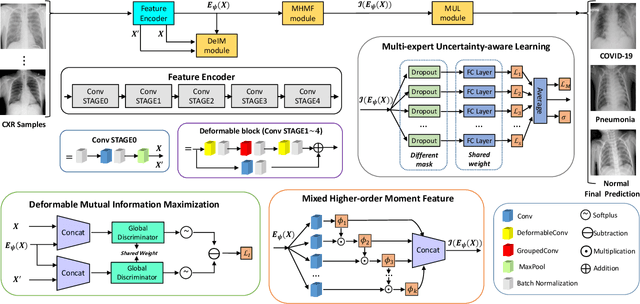
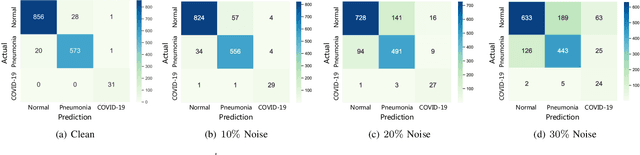
The novel 2019 Coronavirus (COVID-19) infection has spread world widely and is currently a major healthcare challenge around the world. Chest Computed Tomography (CT) and X-ray images have been well recognized to be two effective techniques for clinical COVID-19 disease diagnoses. Due to faster imaging time and considerably lower cost than CT, detecting COVID-19 in chest X-ray (CXR) images is preferred for efficient diagnosis, assessment and treatment. However, considering the similarity between COVID-19 and pneumonia, CXR samples with deep features distributed near category boundaries are easily misclassified by the hyper-planes learned from limited training data. Moreover, most existing approaches for COVID-19 detection focus on the accuracy of prediction and overlook the uncertainty estimation, which is particularly important when dealing with noisy datasets. To alleviate these concerns, we propose a novel deep network named {\em RCoNet$^k_s$} for robust COVID-19 detection which employs {\em Deformable Mutual Information Maximization} (DeIM), {\em Mixed High-order Moment Feature} (MHMF) and {\em Multi-expert Uncertainty-aware Learning} (MUL). With DeIM, the mutual information (MI) between input data and the corresponding latent representations can be well estimated and maximized to capture compact and disentangled representational characteristics. Meanwhile, MHMF can fully explore the benefits of using high-order statistics and extract discriminative features of complex distributions in medical imaging. Finally, MUL creates multiple parallel dropout networks for each CXR image to evaluate uncertainty and thus prevent performance degradation caused by the noise in the data.