 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Non-Convex Structured Phase Retrieval
Jun 23, 2020
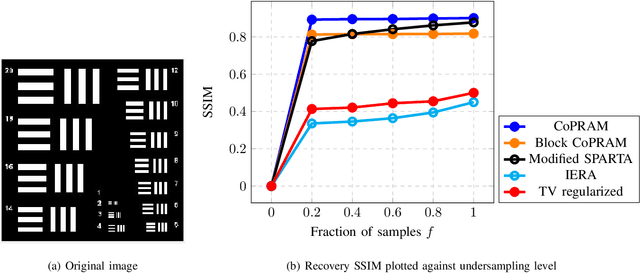
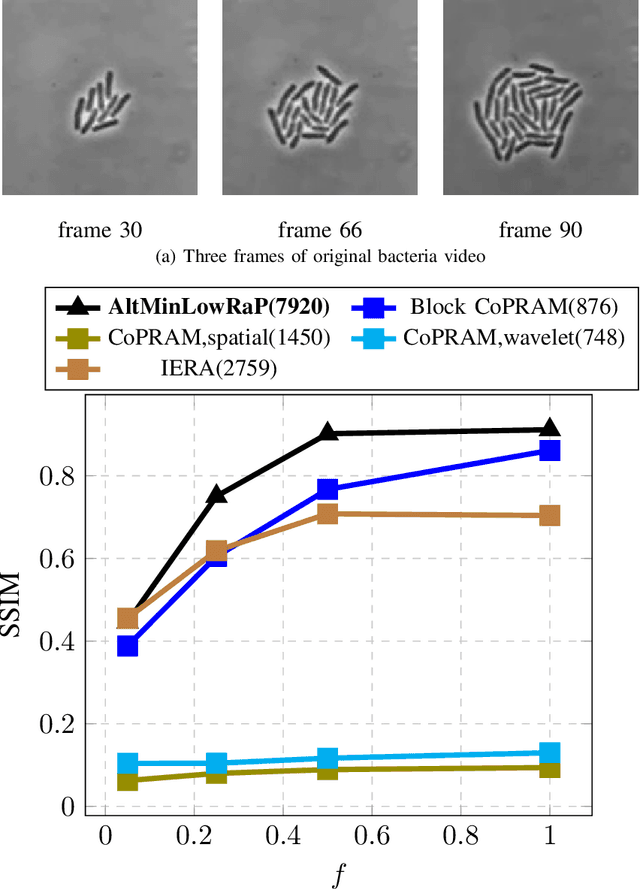
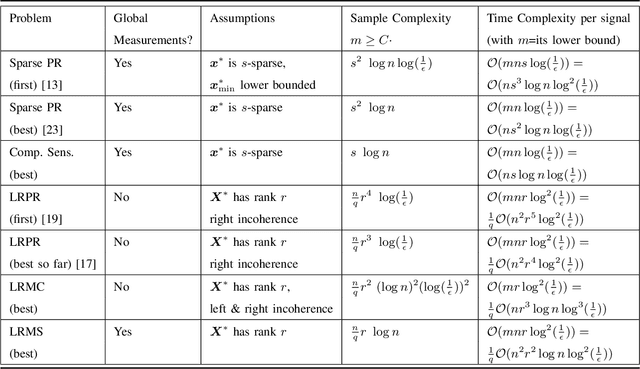
Phase retrieval (PR), also sometimes referred to as quadratic sensing, is a problem that occurs in numerous signal and image acquisition domains ranging from optics, X-ray crystallography, Fourier ptychography, sub-diffraction imaging, and astronomy. In each of these domains, the physics of the acquisition system dictates that only the magnitude (intensity) of certain linear projections of the signal or image can be measured. Without any assumptions on the unknown signal, accurate recovery necessarily requires an over-complete set of measurements. The only way to reduce the measurements/sample complexity is to place extra assumptions on the unknown signal/image. A simple and practically valid set of assumptions is obtained by exploiting the structure inherently present in many natural signals or sequences of signals. Two commonly used structural assumptions are (i) sparsity of a given signal/image or (ii) a low rank model on the matrix formed by a set, e.g., a time sequence, of signals/images. Both have been explored for solving the PR problem in a sample-efficient fashion. This article describes this work, with a focus on non-convex approaches that come with sample complexity guarantees under simple assumptions. We also briefly describe other different types of structural assumptions that have been used in recent literature.
Event Camera Calibration of Per-pixel Biased Contrast Threshold
Dec 17, 2020
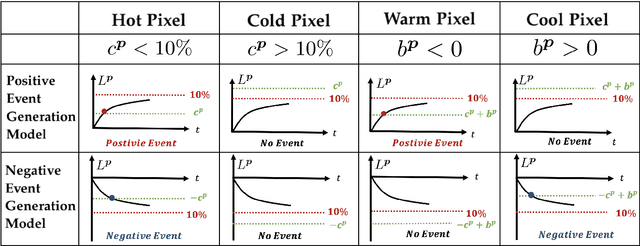
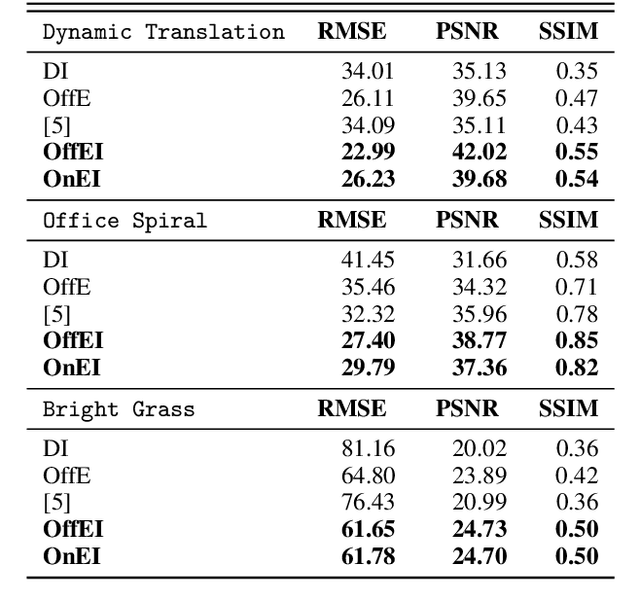
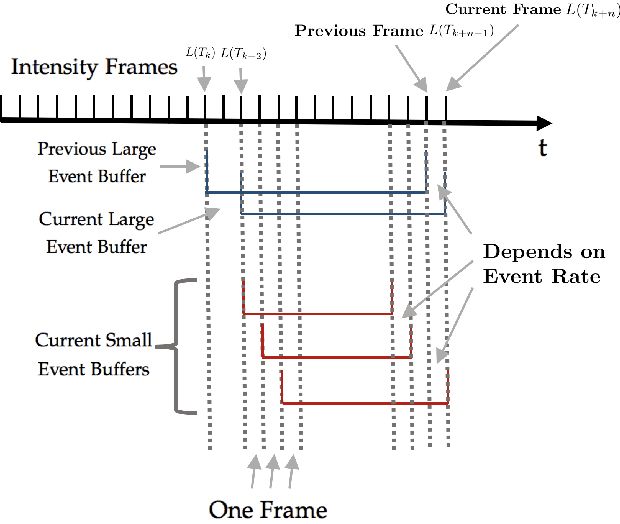
Event cameras output asynchronous events to represent intensity changes with a high temporal resolution, even under extreme lighting conditions. Currently, most of the existing works use a single contrast threshold to estimate the intensity change of all pixels. However, complex circuit bias and manufacturing imperfections cause biased pixels and mismatch contrast threshold among pixels, which may lead to undesirable outputs. In this paper, we propose a new event camera model and two calibration approaches which cover event-only cameras and hybrid image-event cameras. When intensity images are simultaneously provided along with events, we also propose an efficient online method to calibrate event cameras that adapts to time-varying event rates. We demonstrate the advantages of our proposed methods compared to the state-of-the-art on several different event camera datasets.
* 11 pages, 7 figures, the paper has been accepted for publication at the Australian Conference on Robotics and Automation, 2019
Oriole: Thwarting Privacy against Trustworthy Deep Learning Models
Feb 23, 2021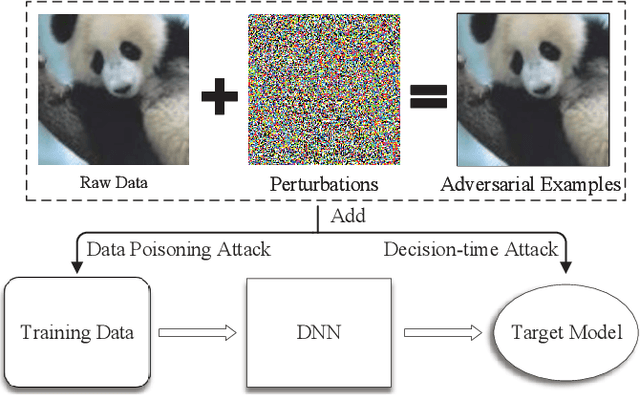
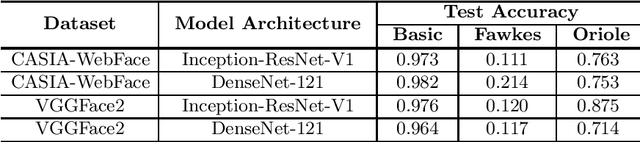
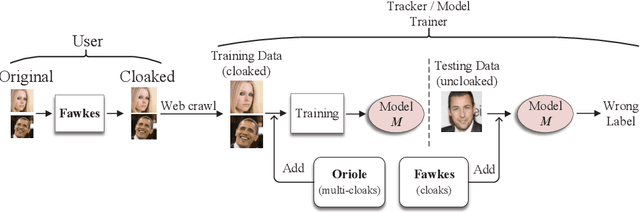
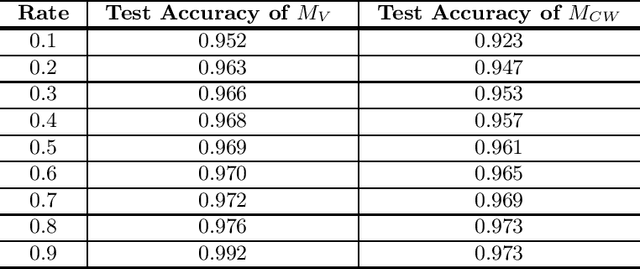
Deep Neural Networks have achieved unprecedented success in the field of face recognition such that any individual can crawl the data of others from the Internet without their explicit permission for the purpose of training high-precision face recognition models, creating a serious violation of privacy. Recently, a well-known system named Fawkes (published in USENIX Security 2020) claimed this privacy threat can be neutralized by uploading cloaked user images instead of their original images. In this paper, we present Oriole, a system that combines the advantages of data poisoning attacks and evasion attacks, to thwart the protection offered by Fawkes, by training the attacker face recognition model with multi-cloaked images generated by Oriole. Consequently, the face recognition accuracy of the attack model is maintained and the weaknesses of Fawkes are revealed. Experimental results show that our proposed Oriole system is able to effectively interfere with the performance of the Fawkes system to achieve promising attacking results. Our ablation study highlights multiple principal factors that affect the performance of the Oriole system, including the DSSIM perturbation budget, the ratio of leaked clean user images, and the numbers of multi-cloaks for each uncloaked image. We also identify and discuss at length the vulnerabilities of Fawkes. We hope that the new methodology presented in this paper will inform the security community of a need to design more robust privacy-preserving deep learning models.
Utilizing Uncertainty Estimation in Deep Learning Segmentation of Fluorescence Microscopy Images with Missing Markers
Jan 27, 2021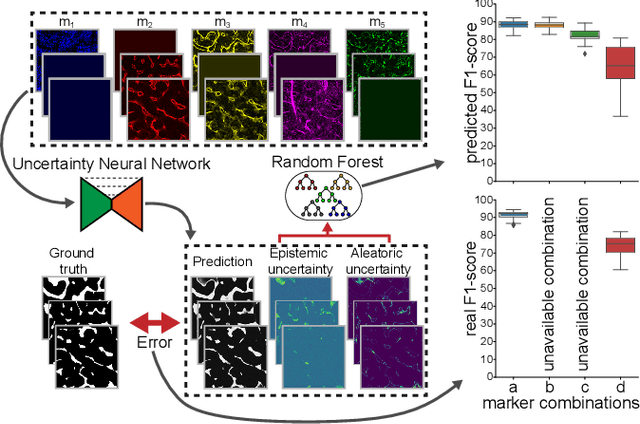
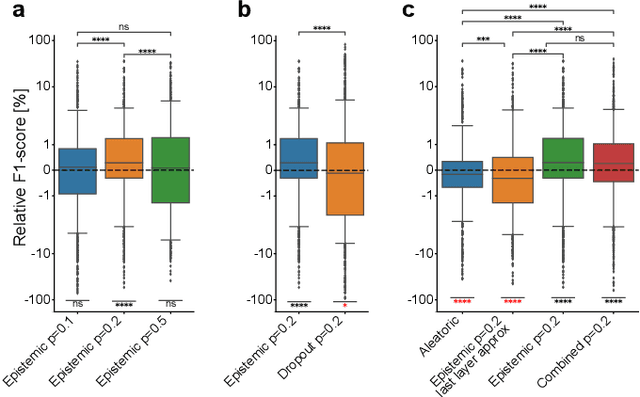
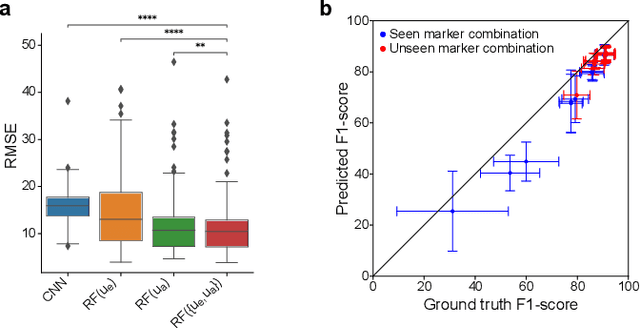
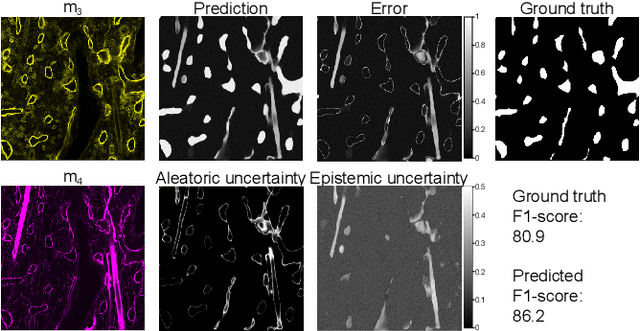
Fluorescence microscopy images contain several channels, each indicating a marker staining the sample. Since many different marker combinations are utilized in practice, it has been challenging to apply deep learning based segmentation models, which expect a predefined channel combination for all training samples as well as at inference for future application. Recent work circumvents this problem using a modality attention approach to be effective across any possible marker combination. However, for combinations that do not exist in a labeled training dataset, one cannot have any estimation of potential segmentation quality if that combination is encountered during inference. Without this, not only one lacks quality assurance but one also does not know where to put any additional imaging and labeling effort. We herein propose a method to estimate segmentation quality on unlabeled images by (i) estimating both aleatoric and epistemic uncertainties of convolutional neural networks for image segmentation, and (ii) training a Random Forest model for the interpretation of uncertainty features via regression to their corresponding segmentation metrics. Additionally, we demonstrate that including these uncertainty measures during training can provide an improvement on segmentation performance.
What Do Deep Nets Learn? Class-wise Patterns Revealed in the Input Space
Feb 06, 2021
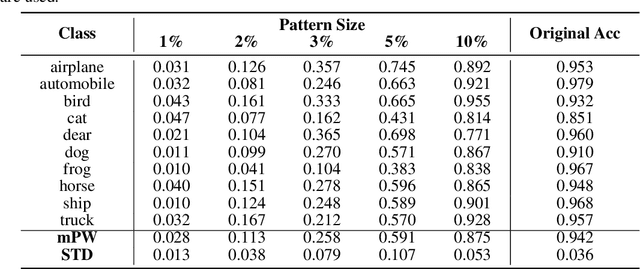

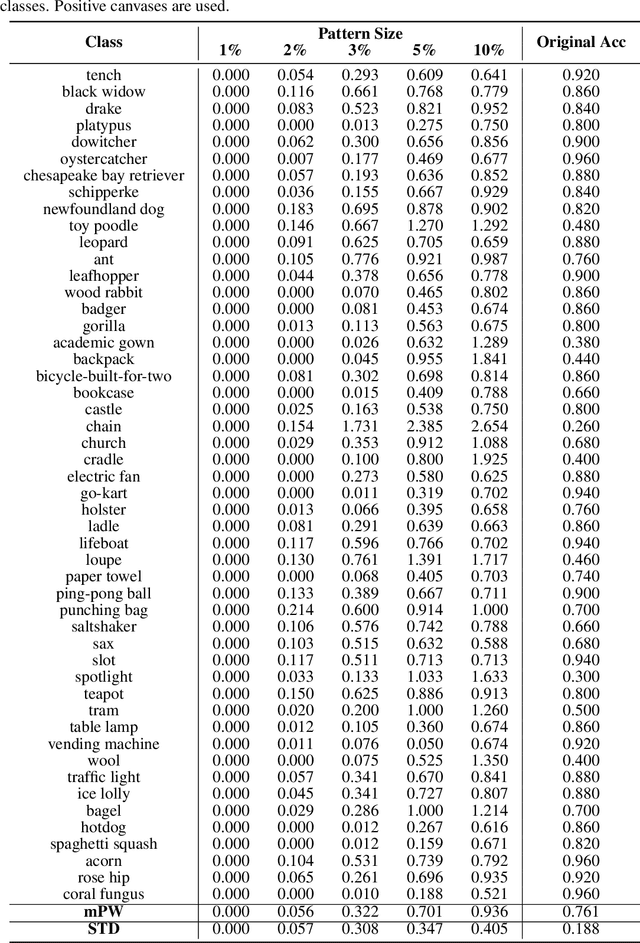
Deep neural networks (DNNs) are increasingly deployed in different applications to achieve state-of-the-art performance. However, they are often applied as a black box with limited understanding of what knowledge the model has learned from the data. In this paper, we focus on image classification and propose a method to visualize and understand the class-wise knowledge (patterns) learned by DNNs under three different settings including natural, backdoor and adversarial. Different to existing visualization methods, our method searches for a single predictive pattern in the pixel space to represent the knowledge learned by the model for each class. Based on the proposed method, we show that DNNs trained on natural (clean) data learn abstract shapes along with some texture, and backdoored models learn a suspicious pattern for the backdoored class. Interestingly, the phenomenon that DNNs can learn a single predictive pattern for each class indicates that DNNs can learn a backdoor even from clean data, and the pattern itself is a backdoor trigger. In the adversarial setting, we show that adversarially trained models tend to learn more simplified shape patterns. Our method can serve as a useful tool to better understand the knowledge learned by DNNs on different datasets under different settings.
Multi-scale Attention U-Net (MsAUNet): A Modified U-Net Architecture for Scene Segmentation
Sep 15, 2020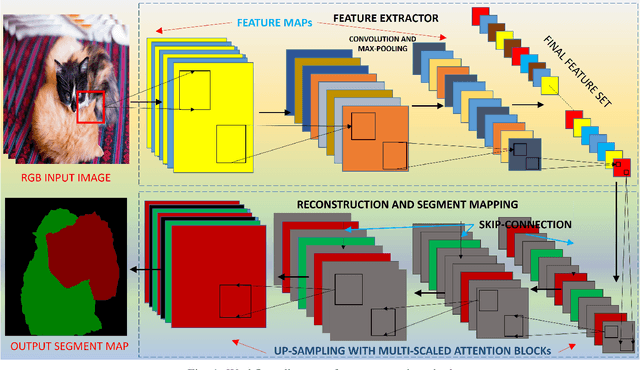
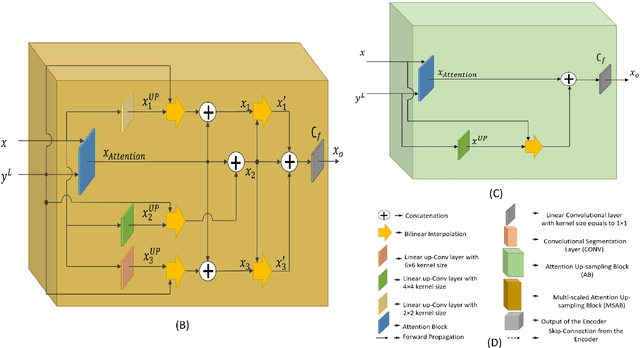
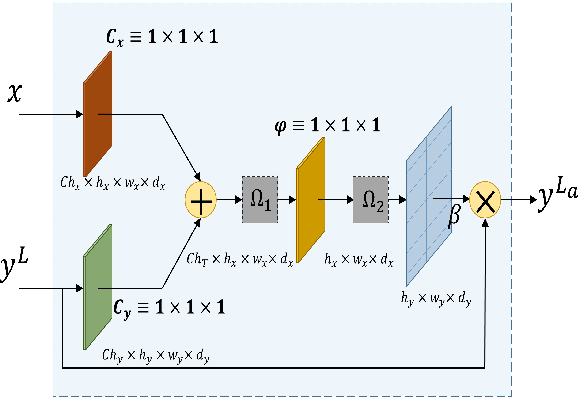

Despite the growing success of Convolution neural networks (CNN) in the recent past in the task of scene segmentation, the standard models lack some of the important features that might result in sub-optimal segmentation outputs. The widely used encoder-decoder architecture extracts and uses several redundant and low-level features at different steps and different scales. Also, these networks fail to map the long-range dependencies of local features, which results in discriminative feature maps corresponding to each semantic class in the resulting segmented image. In this paper, we propose a novel multi-scale attention network for scene segmentation purposes by using the rich contextual information from an image. Different from the original UNet architecture we have used attention gates which take the features from the encoder and the output of the pyramid pool as input and produced out-put is further concatenated with the up-sampled output of the previous pyramid-pool layer and mapped to the next subsequent layer. This network can map local features with their global counterparts with improved accuracy and emphasize on discriminative image regions by focusing on relevant local features only. We also propose a compound loss function by optimizing the IoU loss and fusing Dice Loss and Weighted Cross-entropy loss with it to achieve an optimal solution at a faster convergence rate. We have evaluated our model on two standard datasets named PascalVOC2012 and ADE20k and was able to achieve mean IoU of 79.88% and 44.88% on the two datasets respectively, and compared our result with the widely known models to prove the superiority of our model over them.
Scalable image coding based on epitomes
Jun 28, 2016
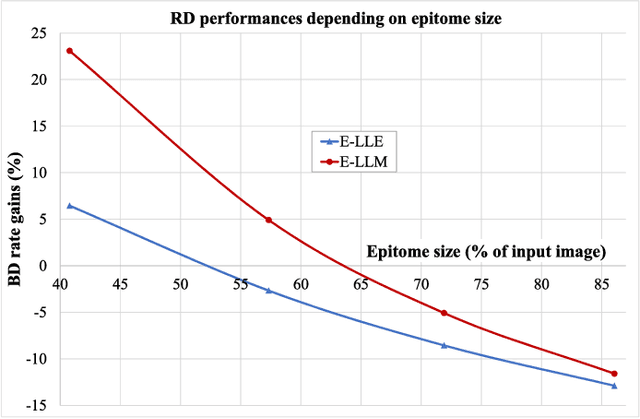
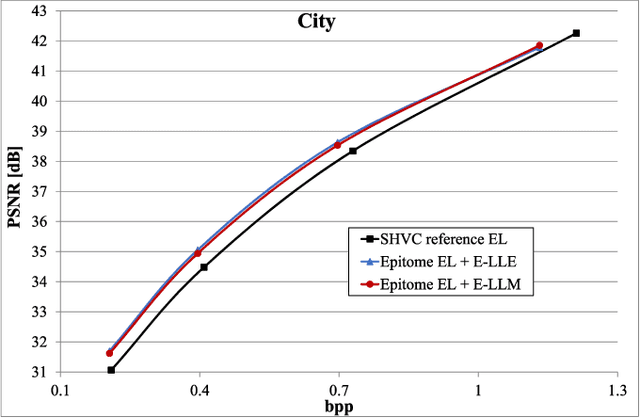
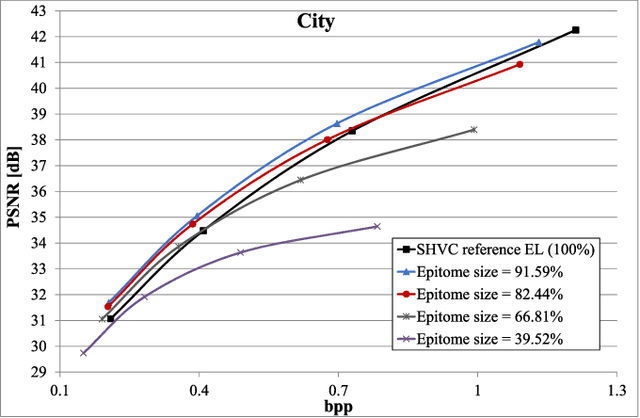
In this paper, we propose a novel scheme for scalable image coding based on the concept of epitome. An epitome can be seen as a factorized representation of an image. Focusing on spatial scalability, the enhancement layer of the proposed scheme contains only the epitome of the input image. The pixels of the enhancement layer not contained in the epitome are then restored using two approaches inspired from local learning-based super-resolution methods. In the first method, a locally linear embedding model is learned on base layer patches and then applied to the corresponding epitome patches to reconstruct the enhancement layer. The second approach learns linear mappings between pairs of co-located base layer and epitome patches. Experiments have shown that significant improvement of the rate-distortion performances can be achieved compared to an SHVC reference.
PC-U Net: Learning to Jointly Reconstruct and Segment the Cardiac Walls in 3D from CT Data
Aug 18, 2020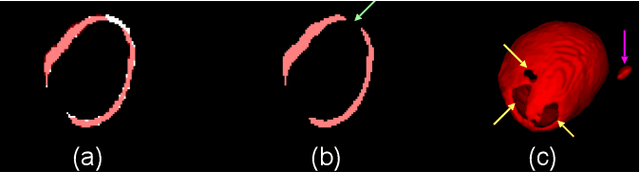
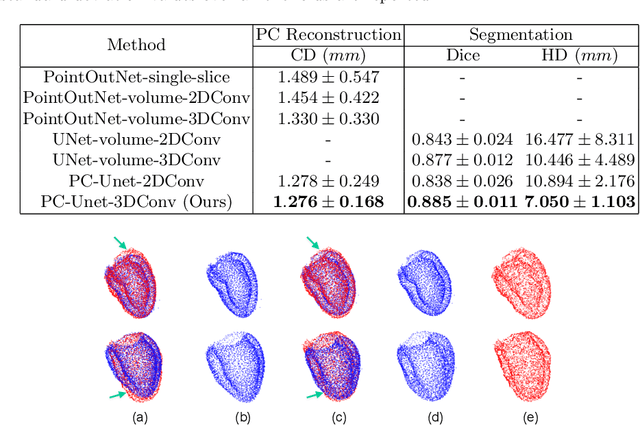
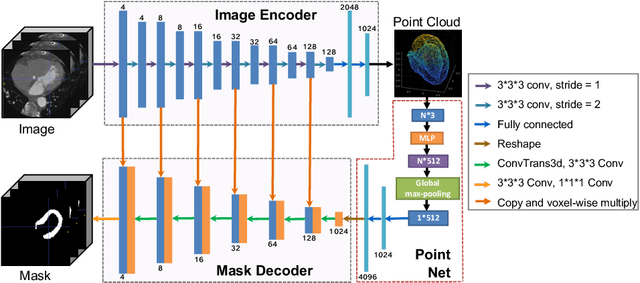

The 3D volumetric shape of the heart's left ventricle (LV) myocardium (MYO) wall provides important information for diagnosis of cardiac disease and invasive procedure navigation. Many cardiac image segmentation methods have relied on detection of region-of-interest as a pre-requisite for shape segmentation and modeling. With segmentation results, a 3D surface mesh and a corresponding point cloud of the segmented cardiac volume can be reconstructed for further analyses. Although state-of-the-art methods (e.g., U-Net) have achieved decent performance on cardiac image segmentation in terms of accuracy, these segmentation results can still suffer from imaging artifacts and noise, which will lead to inaccurate shape modeling results. In this paper, we propose a PC-U net that jointly reconstructs the point cloud of the LV MYO wall directly from volumes of 2D CT slices and generates its segmentation masks from the predicted 3D point cloud. Extensive experimental results show that by incorporating a shape prior from the point cloud, the segmentation masks are more accurate than the state-of-the-art U-Net results in terms of Dice's coefficient and Hausdorff distance.The proposed joint learning framework of our PC-U net is beneficial for automatic cardiac image analysis tasks because it can obtain simultaneously the 3D shape and segmentation of the LV MYO walls.
Adversarial Semantic Scene Completion from a Single Depth Image
Oct 25, 2018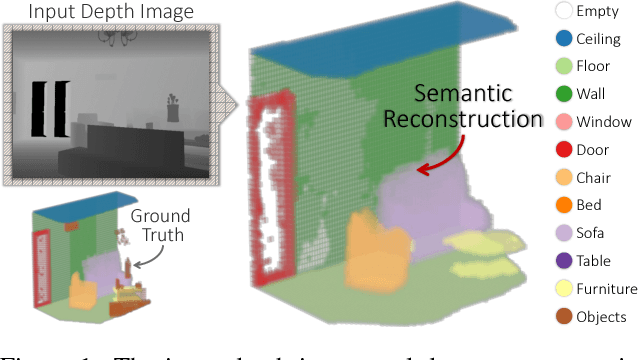
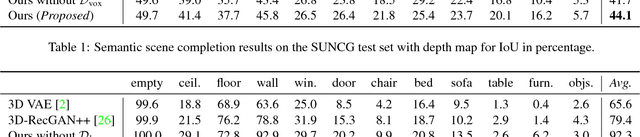
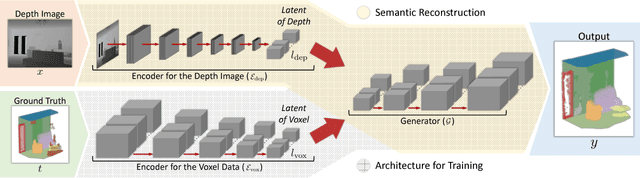

We propose a method to reconstruct, complete and semantically label a 3D scene from a single input depth image. We improve the accuracy of the regressed semantic 3D maps by a novel architecture based on adversarial learning. In particular, we suggest using multiple adversarial loss terms that not only enforce realistic outputs with respect to the ground truth, but also an effective embedding of the internal features. This is done by correlating the latent features of the encoder working on partial 2.5D data with the latent features extracted from a variational 3D auto-encoder trained to reconstruct the complete semantic scene. In addition, differently from other approaches that operate entirely through 3D convolutions, at test time we retain the original 2.5D structure of the input during downsampling to improve the effectiveness of the internal representation of our model. We test our approach on the main benchmark datasets for semantic scene completion to qualitatively and quantitatively assess the effectiveness of our proposal.
* 2018 International Conference on 3D Vision (3DV)
Focal Frequency Loss for Generative Models
Dec 23, 2020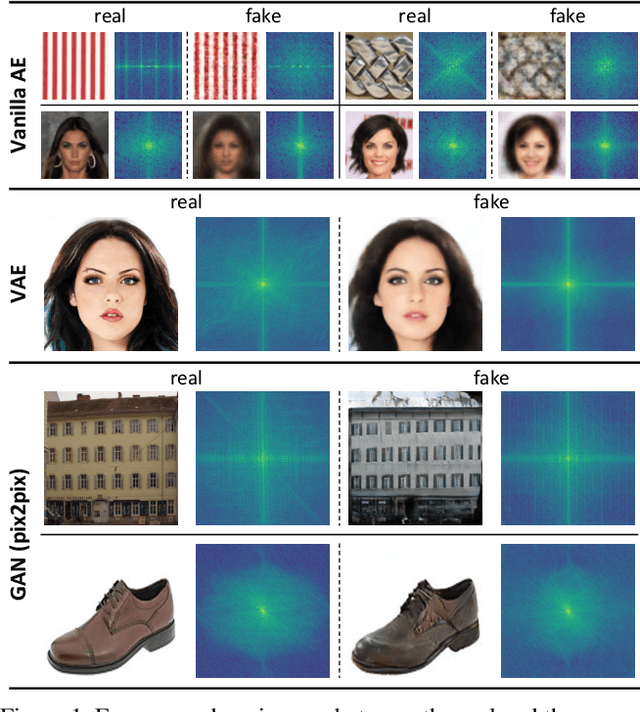
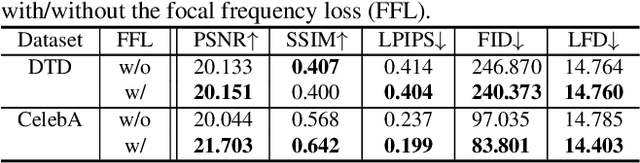

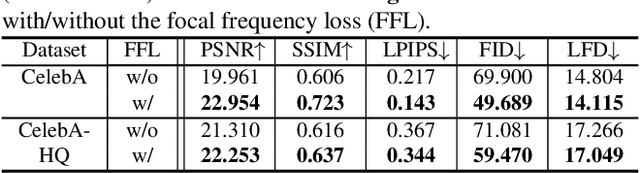
Despite the remarkable success of generative models in creating photorealistic images using deep neural networks, gaps could still exist between the real and generated images, especially in the frequency domain. In this study, we find that narrowing the frequency domain gap can ameliorate the image synthesis quality further. To this end, we propose the focal frequency loss, a novel objective function that brings optimization of generative models into the frequency domain. The proposed loss allows the model to dynamically focus on the frequency components that are hard to synthesize by down-weighting the easy frequencies. This objective function is complementary to existing spatial losses, offering great impedance against the loss of important frequency information due to the inherent crux of neural networks. We demonstrate the versatility and effectiveness of focal frequency loss to improve various baselines in both perceptual quality and quantitative performance.