 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Quasi-homography warps in image stitching
Mar 18, 2018
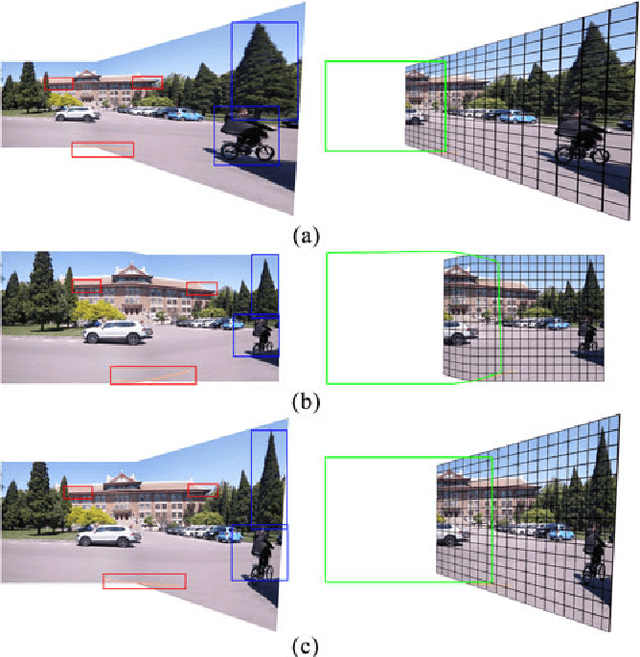
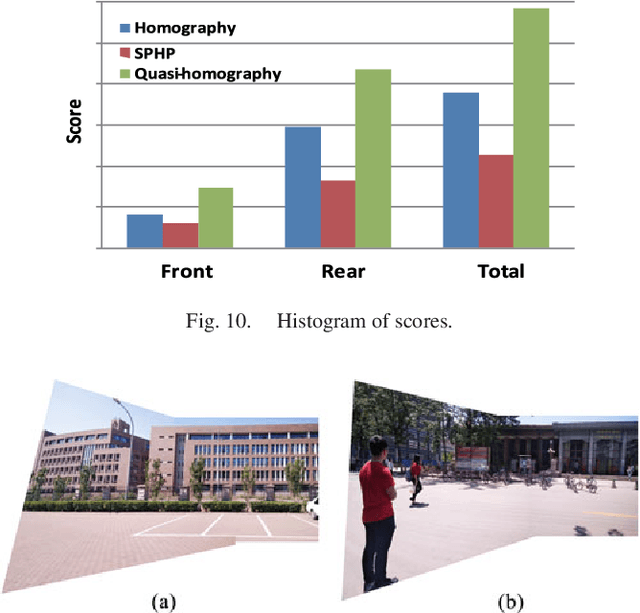

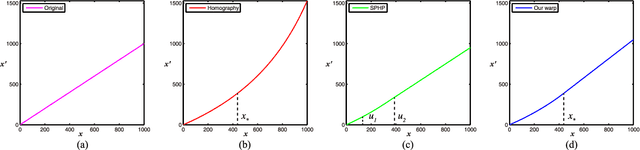
The naturalness of warps is gaining extensive attentions in image stitching. Recent warps such as SPHP and AANAP, use global similarity warps to mitigate projective distortion (which enlarges regions), however, they necessarily bring in perspective distortion (which generates inconsistencies). In this paper, we propose a novel quasi-homography warp, which effectively balances the perspective distortion against the projective distortion in the non-overlapping region to create a more natural-looking panorama. Our approach formulates the warp as the solution of a bivariate system, where perspective distortion and projective distortion are characterized as slope preservation and scale linearization respectively. Because our proposed warp only relies on a global homography, thus it is totally parameter-free. A comprehensive experiment shows that a quasi-homography warp outperforms some state-of-the-art warps in urban scenes, including homography, AutoStitch and SPHP. A user study demonstrates that it wins most users' favor, comparing to homography and SPHP.
Leveraging Implicit Spatial Information in Global Features for Image Retrieval
Jun 23, 2018
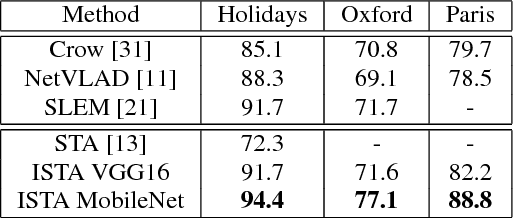

Most image retrieval methods use global features that aggregate local distinctive patterns into a single representation. However, the aggregation process destroys the relative spatial information by considering orderless sets of local descriptors. We propose to integrate relative spatial information into the aggregation process by taking into account co-occurrences of local patterns in a tensor framework. The resulting signature called Improved Spatial Tensor Aggregation (ISTA) is able to reach state of the art performances on well known datasets such as Holidays, Oxford5k and Paris6k.
Mesh Guided One-shot Face Reenactment using Graph Convolutional Networks
Aug 18, 2020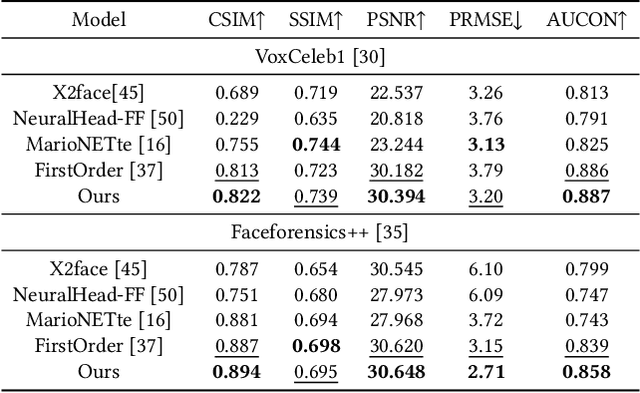
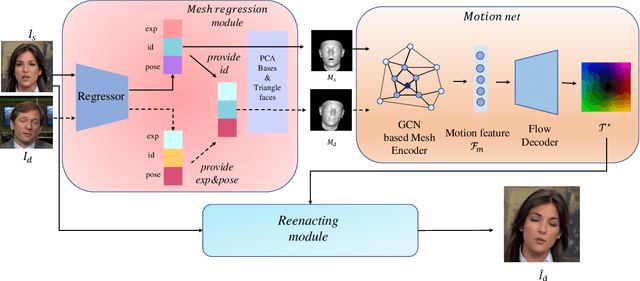
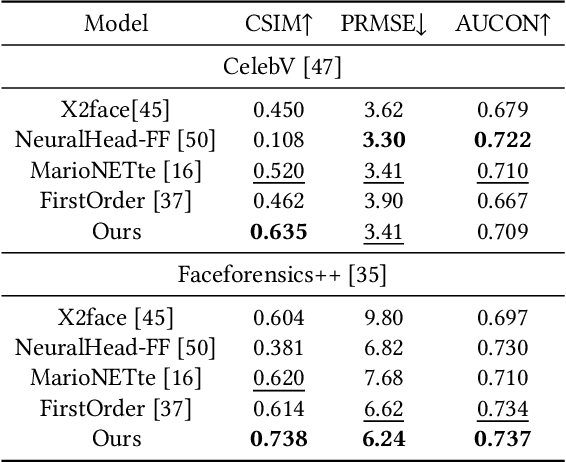
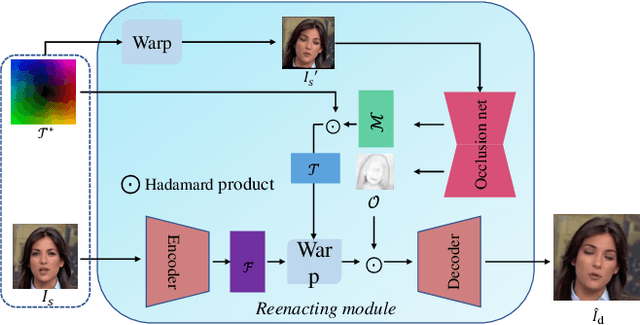
Face reenactment aims to animate a source face image to a different pose and expression provided by a driving image. Existing approaches are either designed for a specific identity, or suffer from the identity preservation problem in the one-shot or few-shot scenarios. In this paper, we introduce a method for one-shot face reenactment, which uses the reconstructed 3D meshes (i.e., the source mesh and driving mesh) as guidance to learn the optical flow needed for the reenacted face synthesis. Technically, we explicitly exclude the driving face's identity information in the reconstructed driving mesh. In this way, our network can focus on the motion estimation for the source face without the interference of driving face shape. We propose a motion net to learn the face motion, which is an asymmetric autoencoder. The encoder is a graph convolutional network (GCN) that learns a latent motion vector from the meshes, and the decoder serves to produce an optical flow image from the latent vector with CNNs. Compared to previous methods using sparse keypoints to guide the optical flow learning, our motion net learns the optical flow directly from 3D dense meshes, which provide the detailed shape and pose information for the optical flow, so it can achieve more accurate expression and pose on the reenacted face. Extensive experiments show that our method can generate high-quality results and outperforms state-of-the-art methods in both qualitative and quantitative comparisons.
iSeeBetter: Spatio-temporal video super-resolution using recurrent generative back-projection networks
Jun 22, 2020
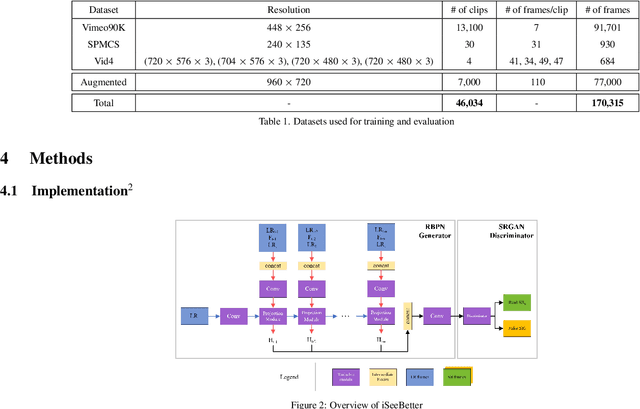
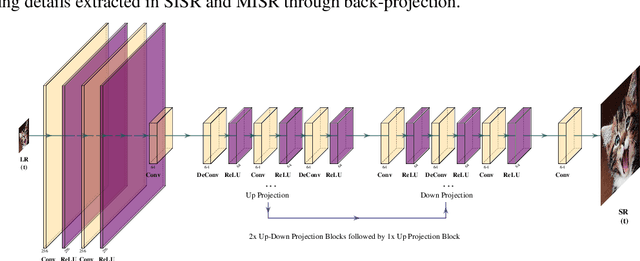
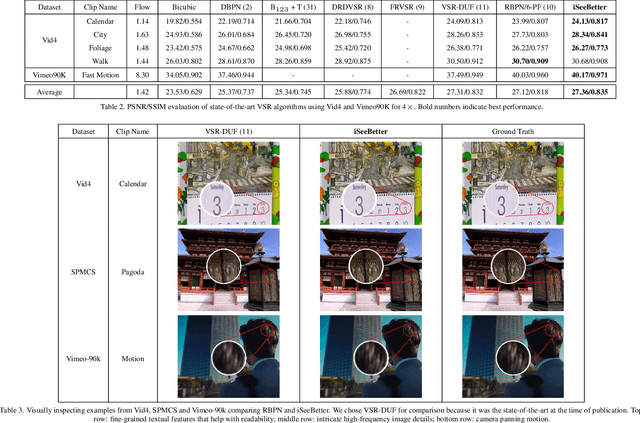
Recently, learning-based models have enhanced the performance of single-image super-resolution (SISR). However, applying SISR successively to each video frame leads to a lack of temporal coherency. Convolutional neural networks (CNNs) outperform traditional approaches in terms of image quality metrics such as peak signal to noise ratio (PSNR) and structural similarity (SSIM). However, generative adversarial networks (GANs) offer a competitive advantage by being able to mitigate the issue of a lack of finer texture details, usually seen with CNNs when super-resolving at large upscaling factors. We present iSeeBetter, a novel GAN-based spatio-temporal approach to video super-resolution (VSR) that renders temporally consistent super-resolution videos. iSeeBetter extracts spatial and temporal information from the current and neighboring frames using the concept of recurrent back-projection networks as its generator. Furthermore, to improve the "naturality" of the super-resolved image while eliminating artifacts seen with traditional algorithms, we utilize the discriminator from super-resolution generative adversarial network (SRGAN). Although mean squared error (MSE) as a primary loss-minimization objective improves PSNR/SSIM, these metrics may not capture fine details in the image resulting in misrepresentation of perceptual quality. To address this, we use a four-fold (MSE, perceptual, adversarial, and total-variation (TV)) loss function. Our results demonstrate that iSeeBetter offers superior VSR fidelity and surpasses state-of-the-art performance.
* 11 pages, 6 figures, 4 tables
Context-aware Attentional Pooling (CAP) for Fine-grained Visual Classification
Jan 17, 2021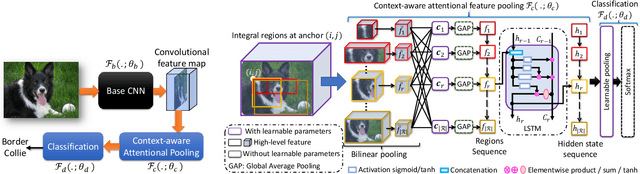
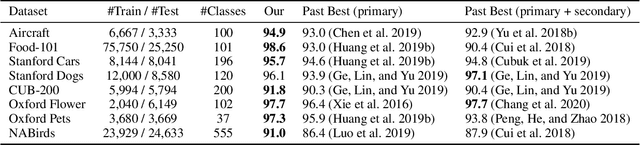

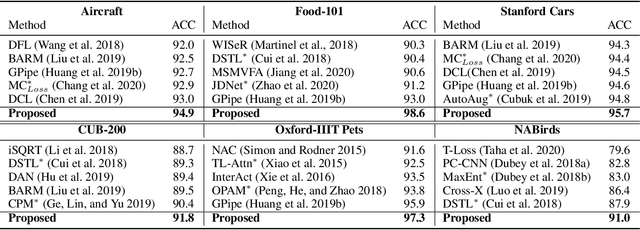
Deep convolutional neural networks (CNNs) have shown a strong ability in mining discriminative object pose and parts information for image recognition. For fine-grained recognition, context-aware rich feature representation of object/scene plays a key role since it exhibits a significant variance in the same subcategory and subtle variance among different subcategories. Finding the subtle variance that fully characterizes the object/scene is not straightforward. To address this, we propose a novel context-aware attentional pooling (CAP) that effectively captures subtle changes via sub-pixel gradients, and learns to attend informative integral regions and their importance in discriminating different subcategories without requiring the bounding-box and/or distinguishable part annotations. We also introduce a novel feature encoding by considering the intrinsic consistency between the informativeness of the integral regions and their spatial structures to capture the semantic correlation among them. Our approach is simple yet extremely effective and can be easily applied on top of a standard classification backbone network. We evaluate our approach using six state-of-the-art (SotA) backbone networks and eight benchmark datasets. Our method significantly outperforms the SotA approaches on six datasets and is very competitive with the remaining two.
* Extended version of the accepted paper in 35th AAAI Conference on Artificial Intelligence 2021
Boosting Segmentation Performance across datasets using histogram specification with application to pelvic bone segmentation
Jan 26, 2021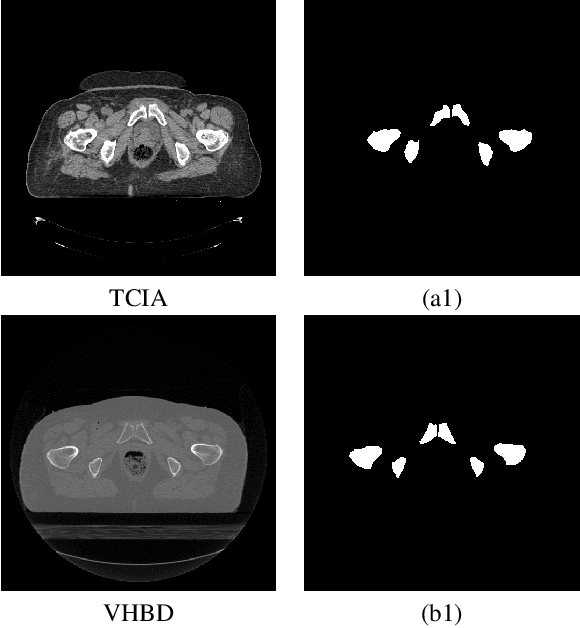
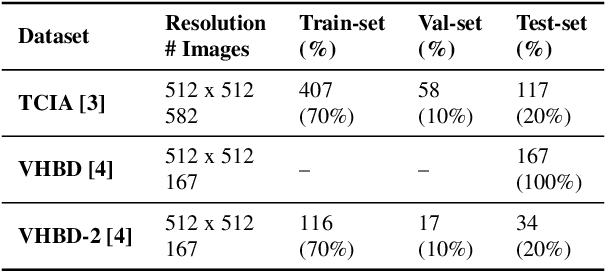
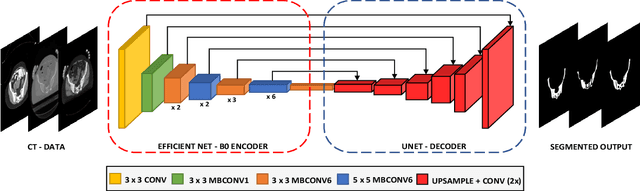
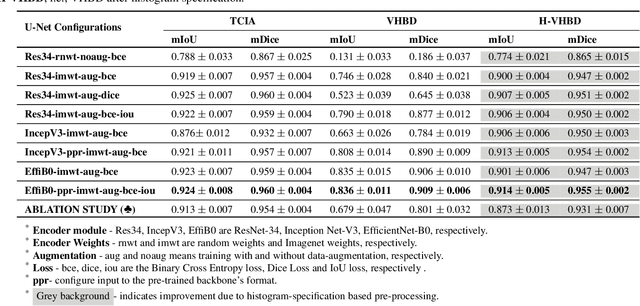
Accurate segmentation of the pelvic CTs is crucial for the clinical diagnosis of pelvic bone diseases and for planning patient-specific hip surgeries. With the emergence and advancements of deep learning for digital healthcare, several methodologies have been proposed for such segmentation tasks. But in a low data scenario, the lack of abundant data needed to train a Deep Neural Network is a significant bottle-neck. In this work, we propose a methodology based on modulation of image tonal distributions and deep learning to boost the performance of networks trained on limited data. The strategy involves pre-processing of test data through histogram specification. This simple yet effective approach can be viewed as a style transfer methodology. The segmentation task uses a U-Net configuration with an EfficientNet-B0 backbone, optimized using an augmented BCE-IoU loss function. This configuration is validated on a total of 284 images taken from two publicly available CT datasets, TCIA (a cancer imaging archive) and the Visible Human Project. The average performance measures for the Dice coefficient and Intersection over Union are 95.7% and 91.9%, respectively, give strong evidence for the effectiveness of the approach, which is highly competitive with state-of-the-art methodologies.
Neural arbitrary style transfer for portrait images using the attention mechanism
Feb 17, 2020Arbitrary style transfer is the task of synthesis of an image that has never been seen before, using two given images: content image and style image. The content image forms the structure, the basic geometric lines and shapes of the resulting image, while the style image sets the color and texture of the result. The word "arbitrary" in this context means the absence of any one pre-learned style. So, for example, convolutional neural networks capable of transferring a new style only after training or retraining on a new amount of data are not con-sidered to solve such a problem, while networks based on the attention mech-anism that are capable of performing such a transformation without retraining - yes. An original image can be, for example, a photograph, and a style image can be a painting of a famous artist. The resulting image in this case will be the scene depicted in the original photograph, made in the stylie of this picture. Recent arbitrary style transfer algorithms make it possible to achieve good re-sults in this task, however, in processing portrait images of people, the result of such algorithms is either unacceptable due to excessive distortion of facial features, or weakly expressed, not bearing the characteristic features of a style image. In this paper, we consider an approach to solving this problem using the combined architecture of deep neural networks with a attention mechanism that transfers style based on the contents of a particular image segment: with a clear predominance of style over the form for the background part of the im-age, and with the prevalence of content over the form in the image part con-taining directly the image of a person.
Automatic Comic Generation with Stylistic Multi-page Layouts and Emotion-driven Text Balloon Generation
Jan 26, 2021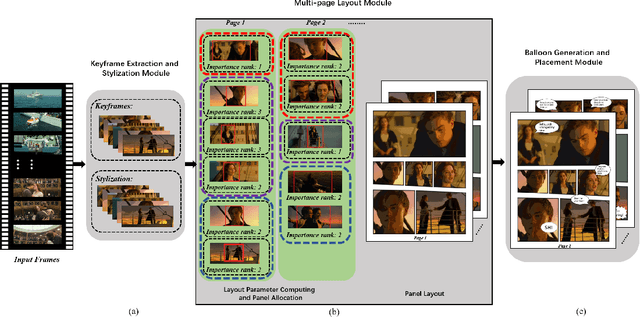
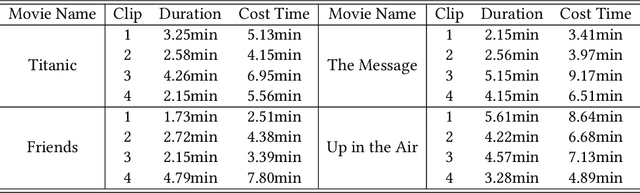
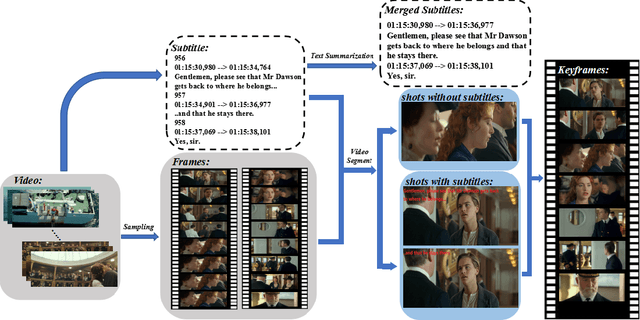
In this paper, we propose a fully automatic system for generating comic books from videos without any human intervention. Given an input video along with its subtitles, our approach first extracts informative keyframes by analyzing the subtitles, and stylizes keyframes into comic-style images. Then, we propose a novel automatic multi-page layout framework, which can allocate the images across multiple pages and synthesize visually interesting layouts based on the rich semantics of the images (e.g., importance and inter-image relation). Finally, as opposed to using the same type of balloon as in previous works, we propose an emotion-aware balloon generation method to create different types of word balloons by analyzing the emotion of subtitles and audios. Our method is able to vary balloon shapes and word sizes in balloons in response to different emotions, leading to more enriched reading experience. Once the balloons are generated, they are placed adjacent to their corresponding speakers via speaker detection. Our results show that our method, without requiring any user inputs, can generate high-quality comic pages with visually rich layouts and balloons. Our user studies also demonstrate that users prefer our generated results over those by state-of-the-art comic generation systems.
Comparison of Convolutional neural network training parameters for detecting Alzheimers disease and effect on visualization
Aug 18, 2020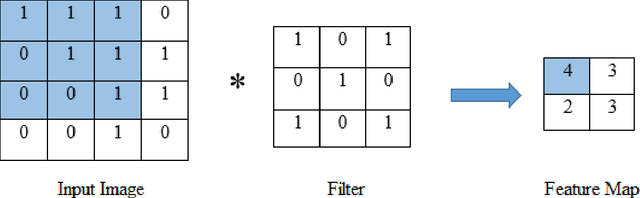
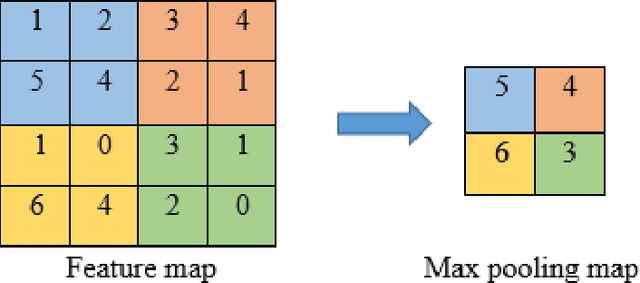
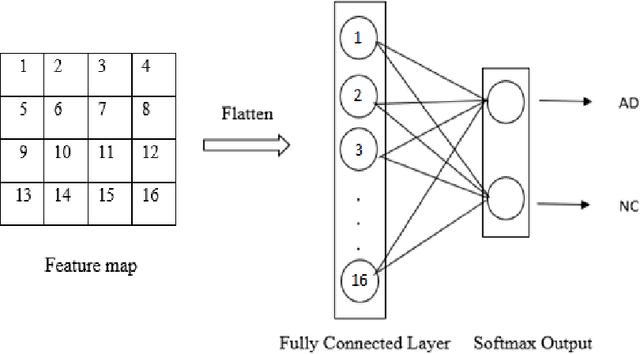
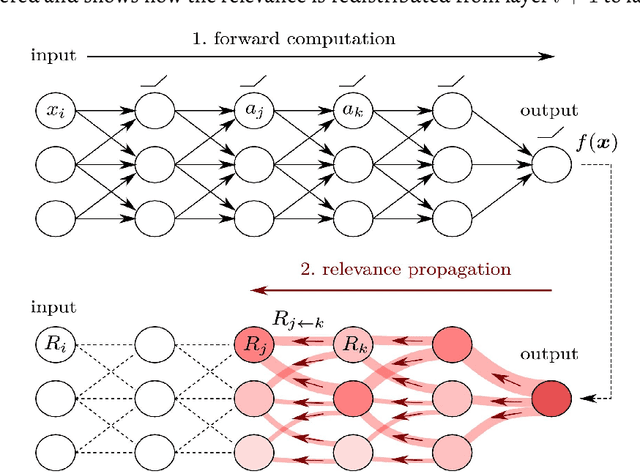
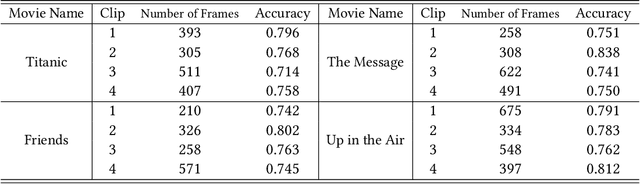
Convolutional neural networks (CNN) have become a powerful tool for detecting patterns in image data. Recent papers report promising results in the domain of disease detection using brain MRI data. Despite the high accuracy obtained from CNN models for MRI data so far, almost no papers provided information on the features or image regions driving this accuracy as adequate methods were missing or challenging to apply. Recently, the toolbox iNNvestigate has become available, implementing various state of the art methods for deep learning visualizations. Currently, there is a great demand for a comparison of visualization algorithms to provide an overview of the practical usefulness and capability of these algorithms. Therefore, this thesis has two goals: 1. To systematically evaluate the influence of CNN hyper-parameters on model accuracy. 2. To compare various visualization methods with respect to the quality (i.e. randomness/focus, soundness).
An Efficient Integration of Disentangled Attended Expression and Identity FeaturesFor Facial Expression Transfer andSynthesis
May 01, 2020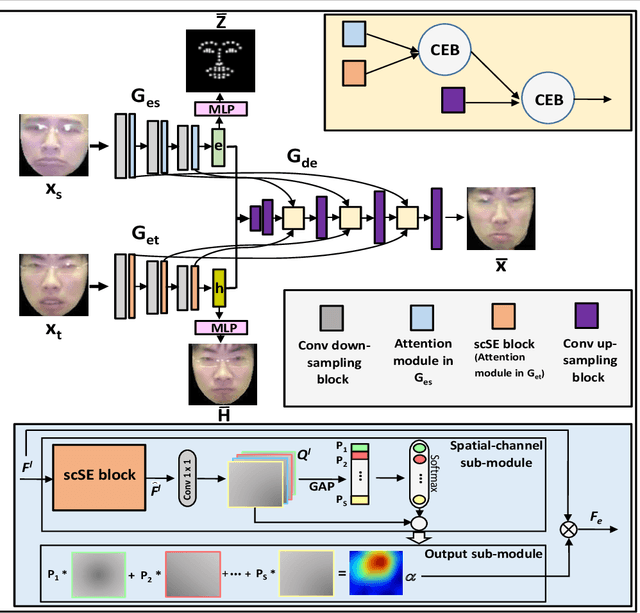
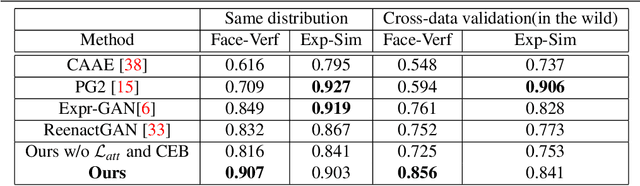

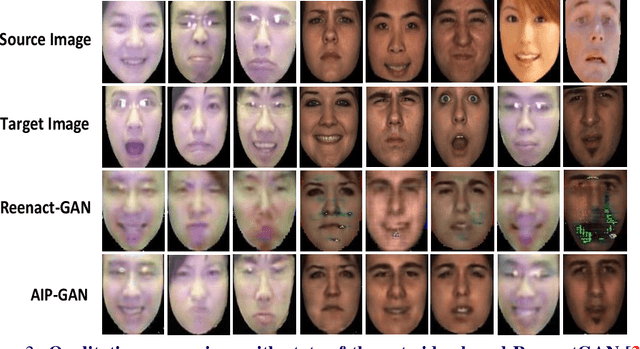
In this paper, we present an Attention-based Identity Preserving Generative Adversarial Network (AIP-GAN) to overcome the identity leakage problem from a source image to a generated face image, an issue that is encountered in a cross-subject facial expression transfer and synthesis process. Our key insight is that the identity preserving network should be able to disentangle and compose shape, appearance, and expression information for efficient facial expression transfer and synthesis. Specifically, the expression encoder of our AIP-GAN disentangles the expression information from the input source image by predicting its facial landmarks using our supervised spatial and channel-wise attention module. Similarly, the disentangled expression-agnostic identity features are extracted from the input target image by inferring its combined intrinsic-shape and appearance image employing our self-supervised spatial and channel-wise attention mod-ule. To leverage the expression and identity information encoded by the intermediate layers of both of our encoders, we combine these features with the features learned by the intermediate layers of our decoder using a cross-encoder bilinear pooling operation. Experimental results show the promising performance of our AIP-GAN based technique.