 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FedDis: Disentangled Federated Learning for Unsupervised Brain Pathology Segmentation
Mar 05, 2021
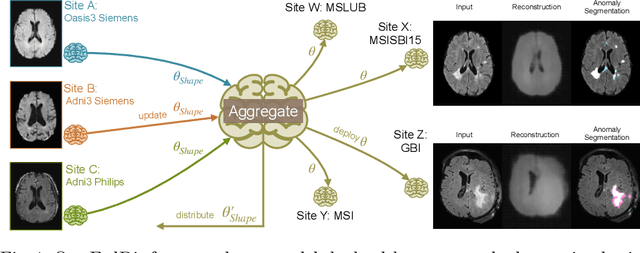

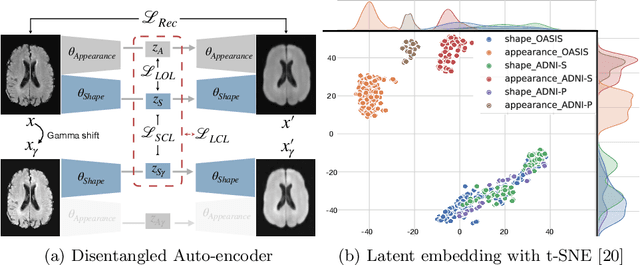
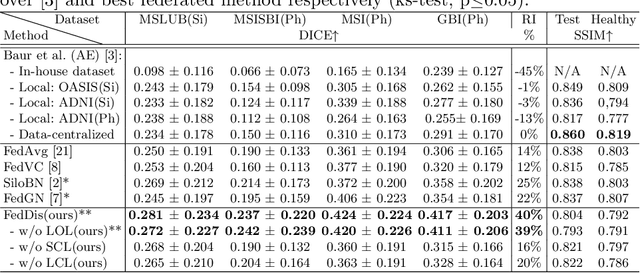
In recent years, data-driven machine learning (ML) methods have revolutionized the computer vision community by providing novel efficient solutions to many unsolved (medical) image analysis problems. However, due to the increasing privacy concerns and data fragmentation on many different sites, existing medical data are not fully utilized, thus limiting the potential of ML. Federated learning (FL) enables multiple parties to collaboratively train a ML model without exchanging local data. However, data heterogeneity (non-IID) among the distributed clients is yet a challenge. To this end, we propose a novel federated method, denoted Federated Disentanglement (FedDis), to disentangle the parameter space into shape and appearance, and only share the shape parameter with the clients. FedDis is based on the assumption that the anatomical structure in brain MRI images is similar across multiple institutions, and sharing the shape knowledge would be beneficial in anomaly detection. In this paper, we leverage healthy brain scans of 623 subjects from multiple sites with real data (OASIS, ADNI) in a privacy-preserving fashion to learn a model of normal anatomy, that allows to segment abnormal structures. We demonstrate a superior performance of FedDis on real pathological databases containing 109 subjects; two publicly available MS Lesions (MSLUB, MSISBI), and an in-house database with MS and Glioblastoma (MSI and GBI). FedDis achieved an average dice performance of 0.38, outperforming the state-of-the-art (SOTA) auto-encoder by 42% and the SOTA federated method by 11%. Further, we illustrate that FedDis learns a shape embedding that is orthogonal to the appearance and consistent under different intensity augmentations.
Introducing and Applying Newtonian Blurring: An Augmented Dataset of 126,000 Human Connectomes at braingraph.org
Oct 20, 2020
Gaussian blurring is a well-established method for image data augmentation: it may generate a large set of images from a small set of pictures for training and testing purposes for Artificial Intelligence (AI) applications. When we apply AI for non-imagelike biological data, hardly any related method exists. Here we introduce the "Newtonian blurring" in human braingraph (or connectome) augmentation: Started from a dataset of 1053 subjects, we first repeat a probabilistic weighted braingraph construction algorithm 10 times for describing the connections of distinct cerebral areas, then take 7 repetitions in every possible way, delete the lower and upper extremes, and average the remaining 7-2=5 edge-weights for the data of each subject. This way we augment the 1053 graph-set to 120 x 1053 = 126,360 graphs. In augmentation techniques, it is an important requirement that no artificial additions should be introduced into the dataset. Gaussian blurring and also this Newtonian blurring satisfy this goal. The resulting dataset of 126,360 graphs, each in 5 resolutions (i.e., 631,800 graphs in total), is freely available at the site https://braingraph.org/cms/download-pit-group-connectomes/. Augmenting with Newtonian blurring may also be applicable in other non-image related fields, where probabilistic processing and data averaging are implemented.
Fully automated analysis of muscle architecture from B-mode ultrasound images with deep learning
Sep 10, 2020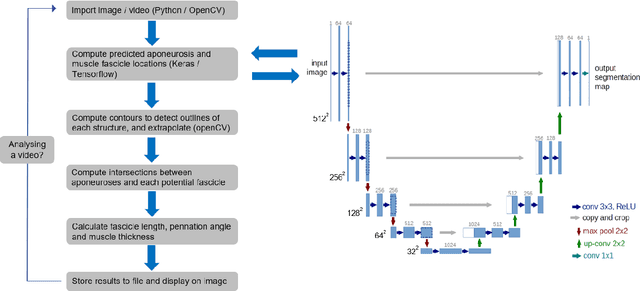
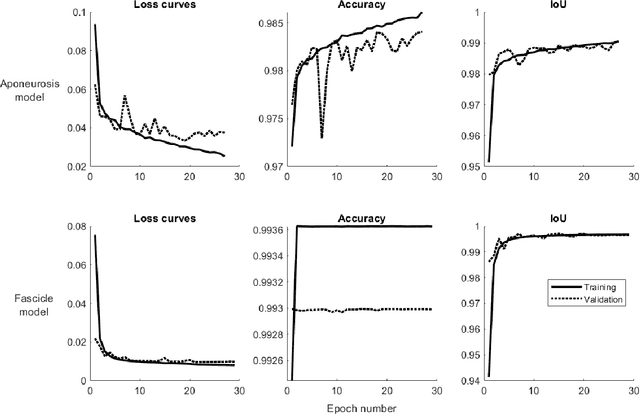

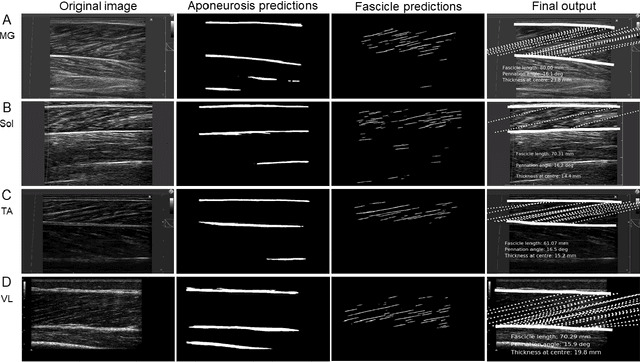
B-mode ultrasound is commonly used to image musculoskeletal tissues, but one major bottleneck is data interpretation, and analyses of muscle thickness, pennation angle and fascicle length are often still performed manually. In this study we trained deep neural networks (based on U-net) to detect muscle fascicles and aponeuroses using a set of labelled musculoskeletal ultrasound images. We then compared neural network predictions on new, unseen images to those obtained via manual analysis and two existing semi/automated analysis approaches (SMA and Ultratrack). With a GPU, inference time for a single image with the new approach was around 0.7s, compared to 4.6s with a CPU. Our method detects the locations of the superficial and deep aponeuroses, as well as multiple fascicle fragments per image. For single images, the method gave similar results to those produced by a non-trainable automated method (SMA; mean difference in fascicle length: 1.1 mm) or human manual analysis (mean difference: 2.1 mm). Between-method differences in pennation angle were within 1$^\circ$, and mean differences in muscle thickness were less than 0.2 mm. Similarly, for videos, there was strong overlap between the results produced with Ultratrack and our method, with a mean ICC of 0.73, despite the fact that the analysed trials included hundreds of frames. Our method is fully automated and open source, and can estimate fascicle length, pennation angle and muscle thickness from single images or videos, as well as from multiple superficial muscles. We also provide all necessary code and training data for custom model development.
Learning Spatial-Spectral Prior for Super-Resolution of Hyperspectral Imagery
May 24, 2020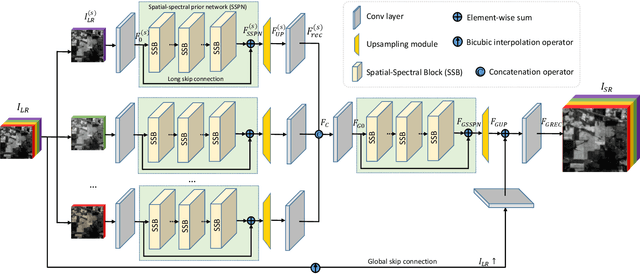
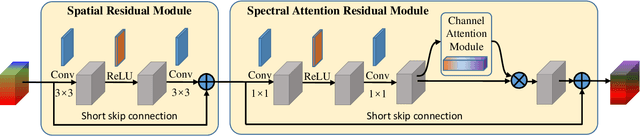


Recently, single gray/RGB image super-resolution reconstruction task has been extensively studied and made significant progress by leveraging the advanced machine learning techniques based on deep convolutional neural networks (DCNNs). However, there has been limited technical development focusing on single hyperspectral image super-resolution due to the high-dimensional and complex spectral patterns in hyperspectral image. In this paper, we make a step forward by investigating how to adapt state-of-the-art residual learning based single gray/RGB image super-resolution approaches for computationally efficient single hyperspectral image super-resolution, referred as SSPSR. Specifically, we introduce a spatial-spectral prior network (SSPN) to fully exploit the spatial information and the correlation between the spectra of the hyperspectral data. Considering that the hyperspectral training samples are scarce and the spectral dimension of hyperspectral image data is very high, it is nontrivial to train a stable and effective deep network. Therefore, a group convolution (with shared network parameters) and progressive upsampling framework is proposed. This will not only alleviate the difficulty in feature extraction due to high-dimension of the hyperspectral data, but also make the training process more stable. To exploit the spatial and spectral prior, we design a spatial-spectral block (SSB), which consists of a spatial residual module and a spectral attention residual module. Experimental results on some hyperspectral images demonstrate that the proposed SSPSR method enhances the details of the recovered high-resolution hyperspectral images, and outperforms state-of-the-arts. The source code is available at \url{https://github.com/junjun-jiang/SSPSR
Absolute 3D Pose Estimation and Length Measurement of Severely Deformed Fish from Monocular Videos in Longline Fishing
Feb 09, 2021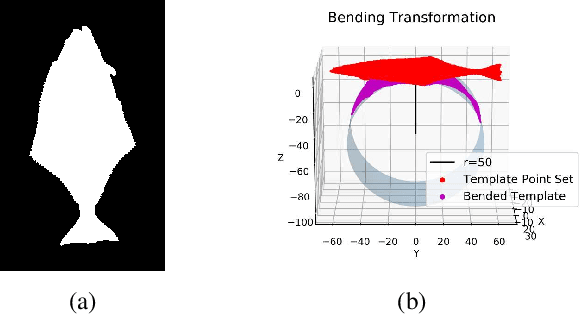
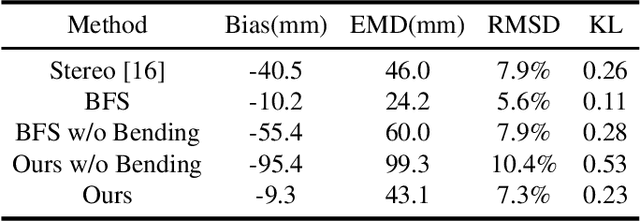
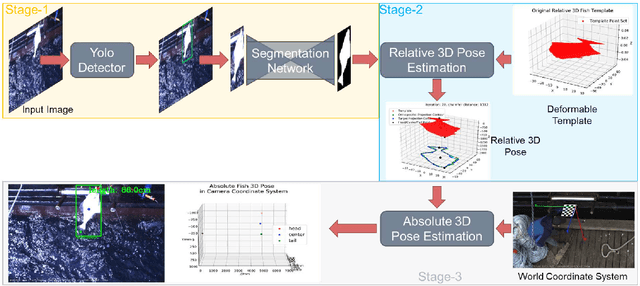
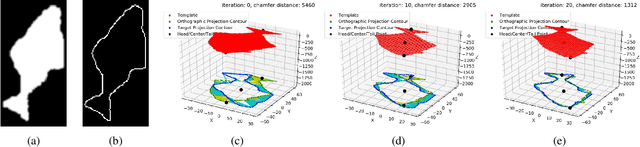
Monocular absolute 3D fish pose estimation allows for efficient fish length measurement in the longline fisheries, where fishes are under severe deformation during the catching process. This task is challenging since it requires locating absolute 3D fish keypoints based on a short monocular video clip. Unlike related works, which either require expensive 3D ground-truth data and/or multiple-view images to provide depth information, or are limited to rigid objects, we propose a novel frame-based method to estimate the absolute 3D fish pose and fish length from a single-view 2D segmentation mask. We first introduce a relative 3D fish template. By minimizing an objective function, our method systematically estimates the relative 3D pose of the target fish and fish 2D keypoints in the image. Finally, with a closed-form solution, the relative 3D fish pose can help locate absolute 3D keypoints, resulting in the frame-based absolute fish length measurement, which is further refined based on the statistical temporal inference for the optimal fish length measurement from the video clip. Our experiments show that this method can accurately estimate the absolute 3D fish pose and further measure the absolute length, even outperforming the state-of-the-art multi-view method.
Photographic Image Synthesis with Cascaded Refinement Networks
Jul 28, 2017

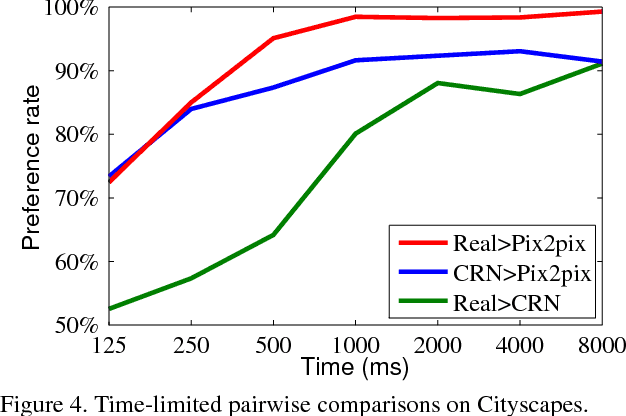
We present an approach to synthesizing photographic images conditioned on semantic layouts. Given a semantic label map, our approach produces an image with photographic appearance that conforms to the input layout. The approach thus functions as a rendering engine that takes a two-dimensional semantic specification of the scene and produces a corresponding photographic image. Unlike recent and contemporaneous work, our approach does not rely on adversarial training. We show that photographic images can be synthesized from semantic layouts by a single feedforward network with appropriate structure, trained end-to-end with a direct regression objective. The presented approach scales seamlessly to high resolutions; we demonstrate this by synthesizing photographic images at 2-megapixel resolution, the full resolution of our training data. Extensive perceptual experiments on datasets of outdoor and indoor scenes demonstrate that images synthesized by the presented approach are considerably more realistic than alternative approaches. The results are shown in the supplementary video at https://youtu.be/0fhUJT21-bs
3D Hand Shape and Pose Estimation from a Single RGB Image
Mar 03, 2019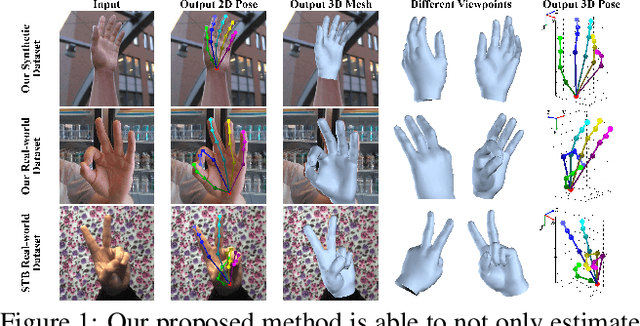



This work addresses a novel and challenging problem of estimating the full 3D hand shape and pose from a single RGB image. Most current methods in 3D hand analysis from monocular RGB images only focus on estimating the 3D locations of hand keypoints, which cannot fully express the 3D shape of hand. In contrast, we propose a Graph Convolutional Neural Network (Graph CNN) based method to reconstruct a full 3D mesh of hand surface that contains richer information of both 3D hand shape and pose. To train networks with full supervision, we create a large-scale synthetic dataset containing both ground truth 3D meshes and 3D poses. When fine-tuning the networks on real-world datasets without 3D ground truth, we propose a weakly-supervised approach by leveraging the depth map as a weak supervision in training. Through extensive evaluations on our proposed new datasets and two public datasets, we show that our proposed method can produce accurate and reasonable 3D hand mesh, and can achieve superior 3D hand pose estimation accuracy when compared with state-of-the-art methods.
Learning Functors using Gradient Descent
Sep 15, 2020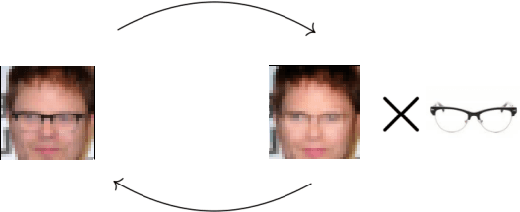
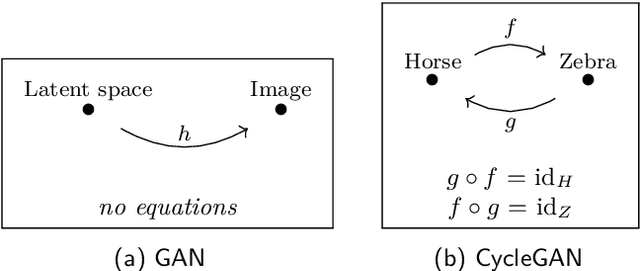
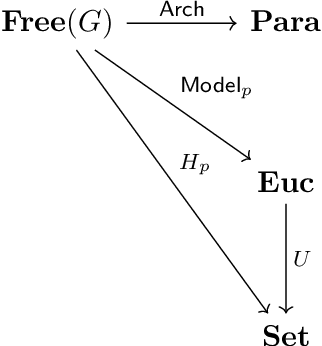
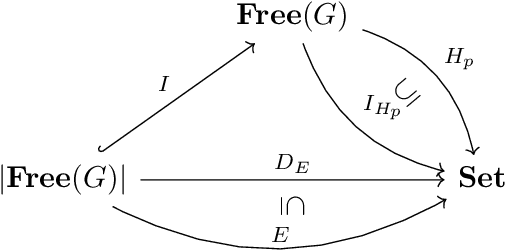
Neural networks are a general framework for differentiable optimization which includes many other machine learning approaches as special cases. In this paper we build a category-theoretic formalism around a neural network system called CycleGAN. CycleGAN is a general approach to unpaired image-to-image translation that has been getting attention in the recent years. Inspired by categorical database systems, we show that CycleGAN is a "schema", i.e. a specific category presented by generators and relations, whose specific parameter instantiations are just set-valued functors on this schema. We show that enforcing cycle-consistencies amounts to enforcing composition invariants in this category. We generalize the learning procedure to arbitrary such categories and show a special class of functors, rather than functions, can be learned using gradient descent. Using this framework we design a novel neural network system capable of learning to insert and delete objects from images without paired data. We qualitatively evaluate the system on the CelebA dataset and obtain promising results.
* In Proceedings ACT 2019, arXiv:2009.06334. This paper is a condensed version of the master thesis of the author (arXiv:1907.08292)
Task Driven Generative Modeling for Unsupervised Domain Adaptation: Application to X-ray Image Segmentation
Jun 11, 2018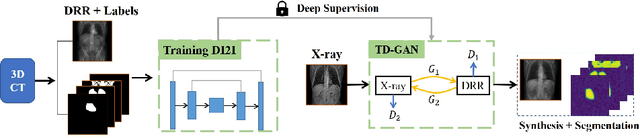
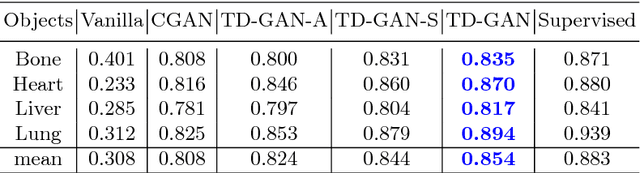
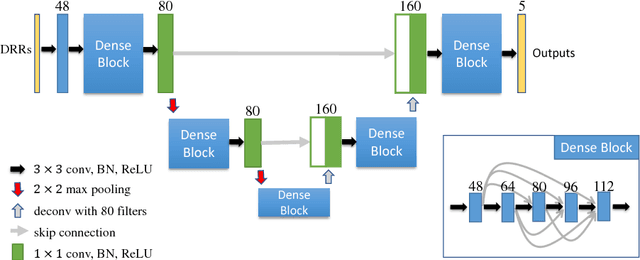
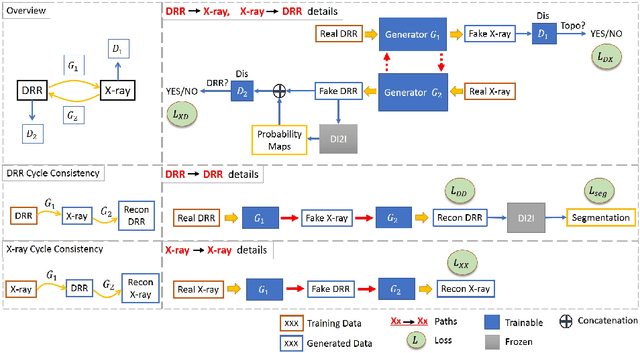
Automatic parsing of anatomical objects in X-ray images is critical to many clinical applications in particular towards image-guided invention and workflow automation. Existing deep network models require a large amount of labeled data. However, obtaining accurate pixel-wise labeling in X-ray images relies heavily on skilled clinicians due to the large overlaps of anatomy and the complex texture patterns. On the other hand, organs in 3D CT scans preserve clearer structures as well as sharper boundaries and thus can be easily delineated. In this paper, we propose a novel model framework for learning automatic X-ray image parsing from labeled CT scans. Specifically, a Dense Image-to-Image network (DI2I) for multi-organ segmentation is first trained on X-ray like Digitally Reconstructed Radiographs (DRRs) rendered from 3D CT volumes. Then we introduce a Task Driven Generative Adversarial Network (TD-GAN) architecture to achieve simultaneous style transfer and parsing for unseen real X-ray images. TD-GAN consists of a modified cycle-GAN substructure for pixel-to-pixel translation between DRRs and X-ray images and an added module leveraging the pre-trained DI2I to enforce segmentation consistency. The TD-GAN framework is general and can be easily adapted to other learning tasks. In the numerical experiments, we validate the proposed model on 815 DRRs and 153 topograms. While the vanilla DI2I without any adaptation fails completely on segmenting the topograms, the proposed model does not require any topogram labels and is able to provide a promising average dice of 85% which achieves the same level accuracy of supervised training (88%).
From Black-box to White-box: Examining Confidence Calibration under different Conditions
Jan 08, 2021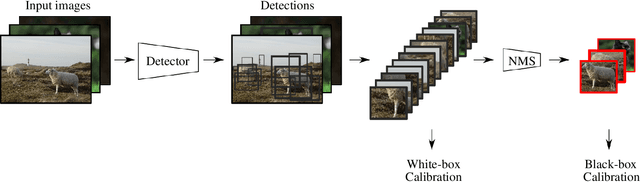
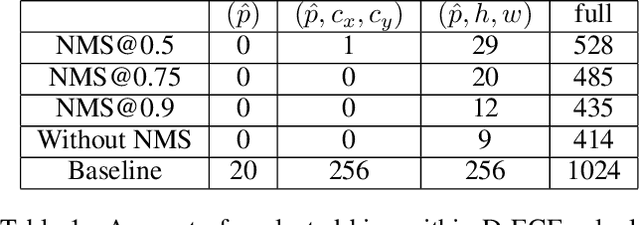
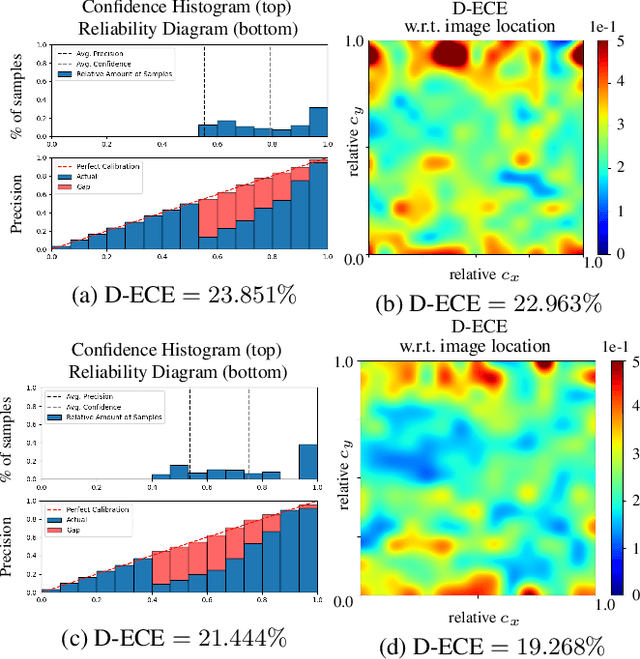
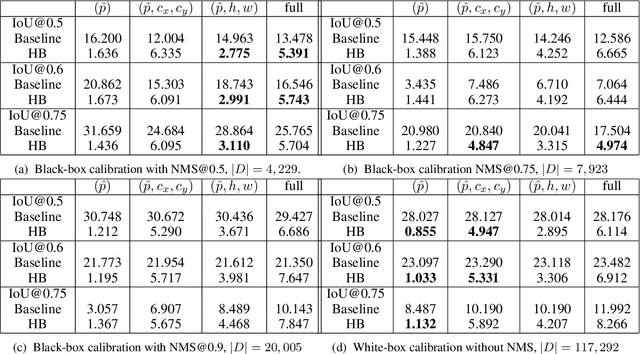
Confidence calibration is a major concern when applying artificial neural networks in safety-critical applications. Since most research in this area has focused on classification in the past, confidence calibration in the scope of object detection has gained more attention only recently. Based on previous work, we study the miscalibration of object detection models with respect to image location and box scale. Our main contribution is to additionally consider the impact of box selection methods like non-maximum suppression to calibration. We investigate the default intrinsic calibration of object detection models and how it is affected by these post-processing techniques. For this purpose, we distinguish between black-box calibration with non-maximum suppression and white-box calibration with raw network outputs. Our experiments reveal that post-processing highly affects confidence calibration. We show that non-maximum suppression has the potential to degrade initially well-calibrated predictions, leading to overconfident and thus miscalibrated models.