 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
End-to-End Text Classification via Image-based Embedding using Character-level Networks
Oct 10, 2018
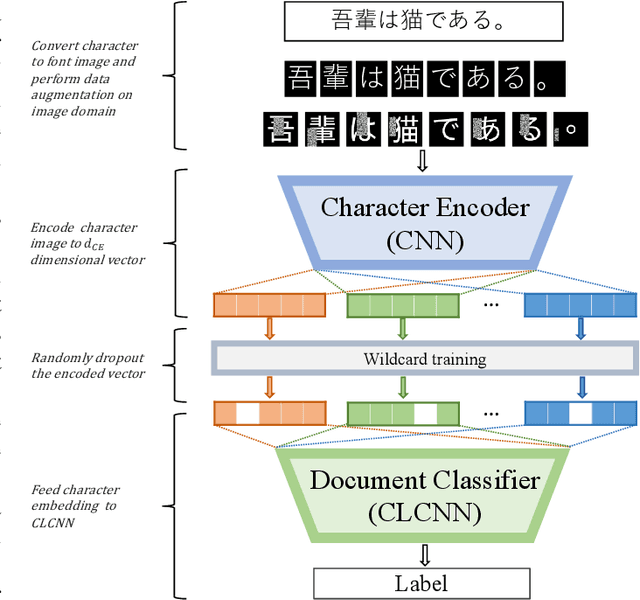


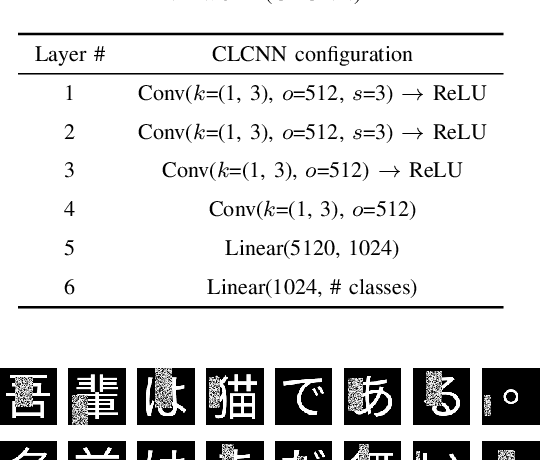
For analysing and/or understanding languages having no word boundaries based on morphological analysis such as Japanese, Chinese, and Thai, it is desirable to perform appropriate word segmentation before word embeddings. But it is inherently difficult in these languages. In recent years, various language models based on deep learning have made remarkable progress, and some of these methodologies utilizing character-level features have successfully avoided such a difficult problem. However, when a model is fed character-level features of the above languages, it often causes overfitting due to a large number of character types. In this paper, we propose a CE-CLCNN, character-level convolutional neural networks using a character encoder to tackle these problems. The proposed CE-CLCNN is an end-to-end learning model and has an image-based character encoder, i.e. the CE-CLCNN handles each character in the target document as an image. Through various experiments, we found and confirmed that our CE-CLCNN captured closely embedded features for visually and semantically similar characters and achieves state-of-the-art results on several open document classification tasks. In this paper we report the performance of our CE-CLCNN with the Wikipedia title estimation task and analyse the internal behaviour.
MS-GWNN:multi-scale graph wavelet neural network for breast cancer diagnosis
Dec 29, 2020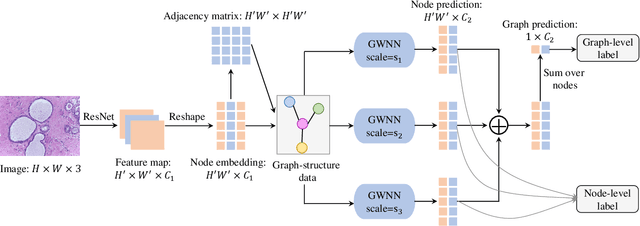
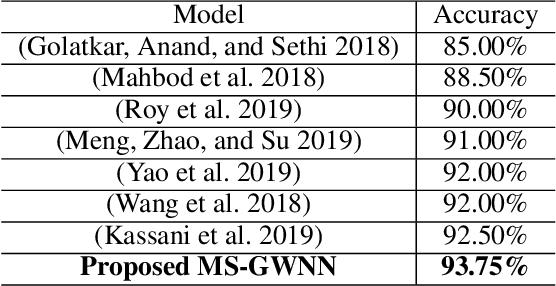
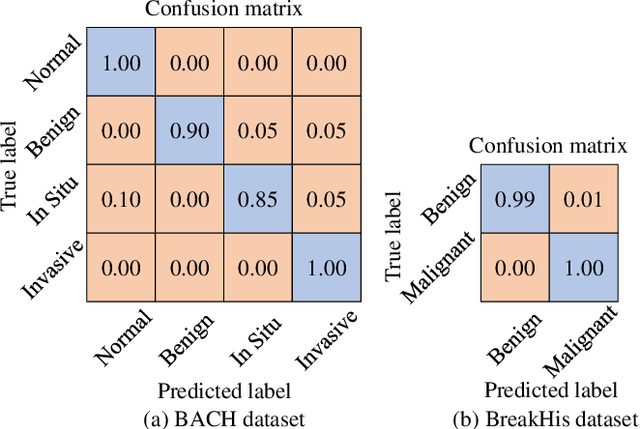
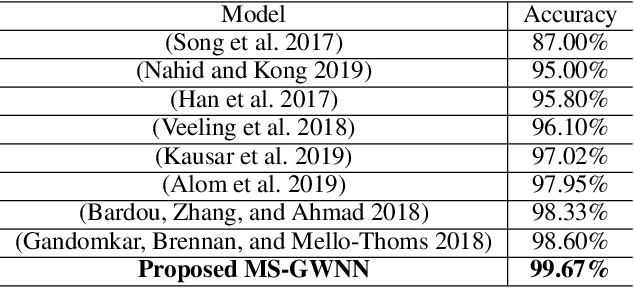
Breast cancer is one of the most common cancers in women worldwide, and early detection can significantly reduce the mortality rate of breast cancer. It is crucial to take multi-scale information of tissue structure into account in the detection of breast cancer. And thus, it is the key to design an accurate computer-aided detection (CAD) system to capture multi-scale contextual features in a cancerous tissue. In this work, we present a novel graph convolutional neural network for histopathological image classification of breast cancer. The new method, named multi-scale graph wavelet neural network (MS-GWNN), leverages the localization property of spectral graph wavelet to perform multi-scale analysis. By aggregating features at different scales, MS-GWNN can encode the multi-scale contextual interactions in the whole pathological slide. Experimental results on two public datasets demonstrate the superiority of the proposed method. Moreover, through ablation studies, we find that multi-scale analysis has a significant impact on the accuracy of cancer diagnosis.
Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
Apr 15, 2020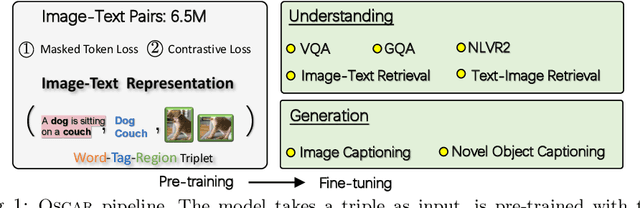

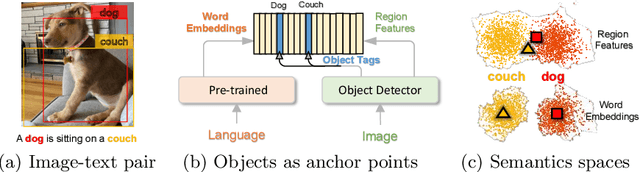
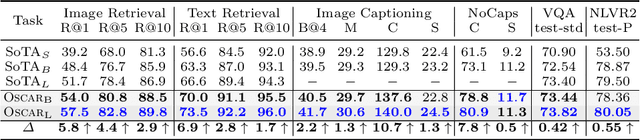
Large-scale pre-training methods of learning cross-modal representations on image-text pairs are becoming popular for vision-language tasks. While existing methods simply concatenate image region features and text features as input to the model to be pre-trained and use self-attention to learn image-text semantic alignments in a brute force manner, in this paper, we propose a new learning method Oscar (Object-Semantics Aligned Pre-training), which uses object tags detected in images as anchor points to significantly ease the learning of alignments. Our method is motivated by the observation that the salient objects in an image can be accurately detected, and are often mentioned in the paired text. We pre-train an Oscar model on the public corpus of 6.5 million text-image pairs, and fine-tune it on downstream tasks, creating new state-of-the-arts on six well-established vision-language understanding and generation tasks.
ASL to PET Translation by a Semi-supervised Residual-based Attention-guided Convolutional Neural Network
Mar 08, 2021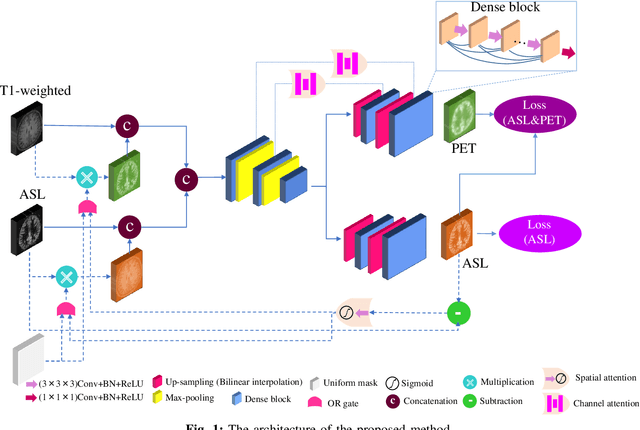
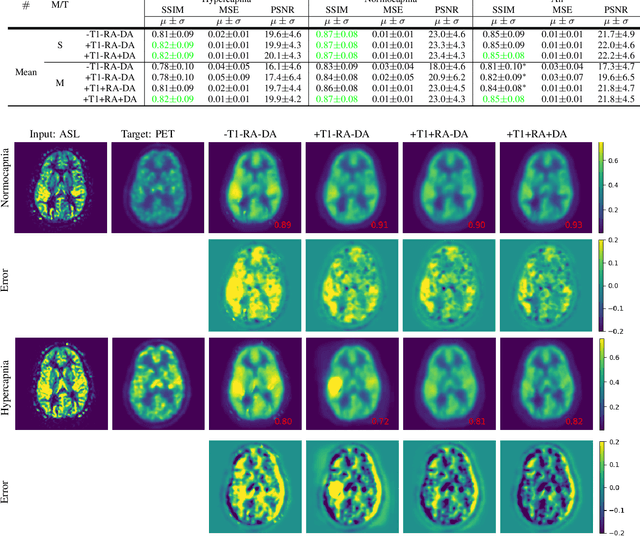
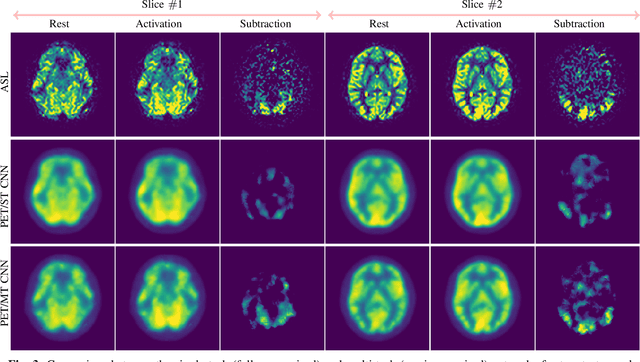
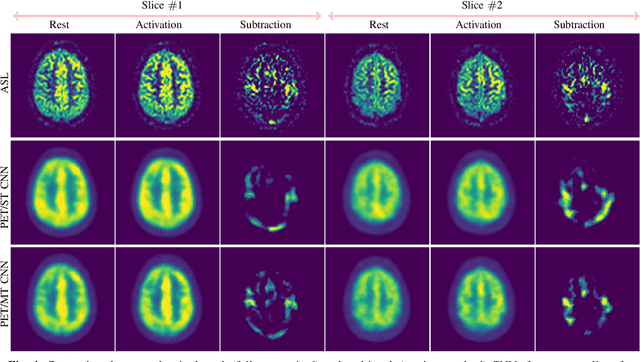
Positron Emission Tomography (PET) is an imaging method that can assess physiological function rather than structural disturbances by measuring cerebral perfusion or glucose consumption. However, this imaging technique relies on injection of radioactive tracers and is expensive. On the contrary, Arterial Spin Labeling (ASL) MRI is a non-invasive, non-radioactive, and relatively cheap imaging technique for brain hemodynamic measurements, which allows quantification to some extent. In this paper we propose a convolutional neural network (CNN) based model for translating ASL to PET images, which could benefit patients as well as the healthcare system in terms of expenses and adverse side effects. However, acquiring a sufficient number of paired ASL-PET scans for training a CNN is prohibitive for many reasons. To tackle this problem, we present a new semi-supervised multitask CNN which is trained on both paired data, i.e. ASL and PET scans, and unpaired data, i.e. only ASL scans, which alleviates the problem of training a network on limited paired data. Moreover, we present a new residual-based-attention guided mechanism to improve the contextual features during the training process. Also, we show that incorporating T1-weighted scans as an input, due to its high resolution and availability of anatomical information, improves the results. We performed a two-stage evaluation based on quantitative image metrics by conducting a 7-fold cross validation followed by a double-blind observer study. The proposed network achieved structural similarity index measure (SSIM), mean squared error (MSE) and peak signal-to-noise ratio (PSNR) values of $0.85\pm0.08$, $0.01\pm0.01$, and $21.8\pm4.5$ respectively, for translating from 2D ASL and T1-weighted images to PET data. The proposed model is publicly available via https://github.com/yousefis/ASL2PET.
DeepSZ: Identification of Sunyaev-Zel'dovich Galaxy Clusters using Deep Learning
Mar 08, 2021
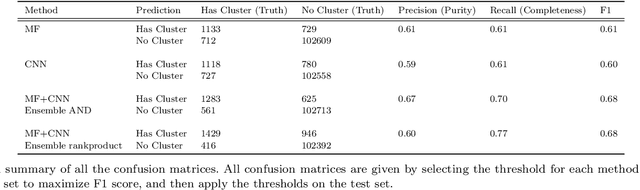


Galaxy clusters identified from the Sunyaev Zel'dovich (SZ) effect are a key ingredient in multi-wavelength cluster-based cosmology. We present a comparison between two methods of cluster identification: the standard Matched Filter (MF) method in SZ cluster finding and a method using Convolutional Neural Networks (CNN). We further implement and show results for a `combined' identifier. We apply the methods to simulated millimeter maps for several observing frequencies for an SPT-3G-like survey. There are some key differences between the methods. The MF method requires image pre-processing to remove point sources and a model for the noise, while the CNN method requires very little pre-processing of images. Additionally, the CNN requires tuning of hyperparameters in the model and takes as input, cutout images of the sky. Specifically, we use the CNN to classify whether or not an 8 arcmin $\times$ 8 arcmin cutout of the sky contains a cluster. We compare differences in purity and completeness. The MF signal-to-noise ratio depends on both mass and redshift. Our CNN, trained for a given mass threshold, captures a different set of clusters than the MF, some of which have SNR below the MF detection threshold. However, the CNN tends to mis-classify cutouts whose clusters are located near the edge of the cutout, which can be mitigated with staggered cutouts. We leverage the complementarity of the two methods, combining the scores from each method for identification. The purity and completeness of the MF alone are both 0.61, assuming a standard detection threshold. The purity and completeness of the CNN alone are 0.59 and 0.61. The combined classification method yields 0.60 and 0.77, a significant increase for completeness with a modest decrease in purity. We advocate for combined methods that increase the confidence of many lower signal-to-noise clusters.
A Convolutional Neural Network with Parallel Multi-Scale Spatial Pooling to Detect Temporal Changes in SAR Images
May 22, 2020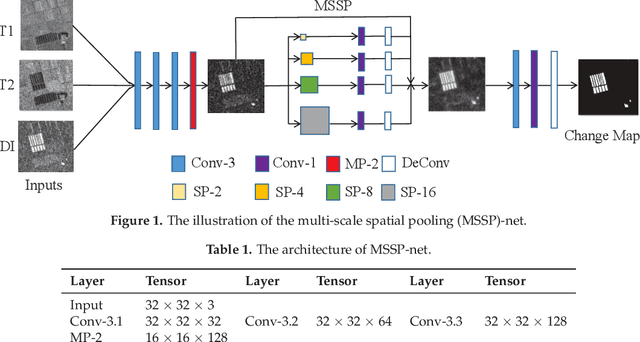


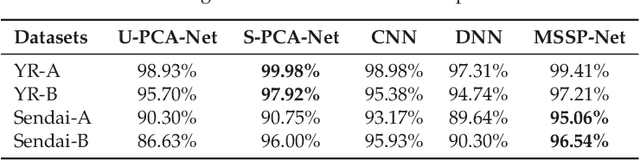
In synthetic aperture radar (SAR) image change detection, it is quite challenging to exploit the changing information from the noisy difference image subject to the speckle. In this paper, we propose a multi-scale spatial pooling (MSSP) network to exploit the changed information from the noisy difference image. Being different from the traditional convolutional network with only mono-scale pooling kernels, in the proposed method, multi-scale pooling kernels are equipped in a convolutional network to exploit the spatial context information on changed regions from the difference image. Furthermore, to verify the generalization of the proposed method, we apply our proposed method to the cross-dataset bitemporal SAR image change detection, where the MSSP network (MSSP-Net) is trained on a dataset and then applied to an unknown testing dataset. We compare the proposed method with other state-of-arts and the comparisons are performed on four challenging datasets of bitemporal SAR images. Experimental results demonstrate that our proposed method obtains comparable results with S-PCA-Net on YR-A and YR-B dataset and outperforms other state-of-art methods, especially on the Sendai-A and Sendai-B datasets with more complex scenes. More important, MSSP-Net is more efficient than S-PCA-Net and convolutional neural networks (CNN) with less executing time in both training and testing phases.
Low Dose CT Image Denoising Using a Generative Adversarial Network with Wasserstein Distance and Perceptual Loss
Apr 24, 2018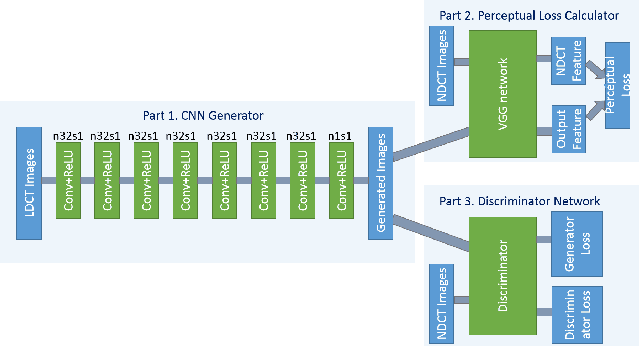
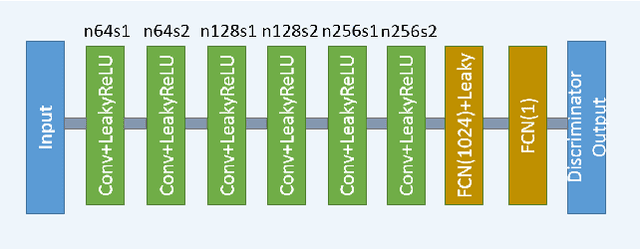
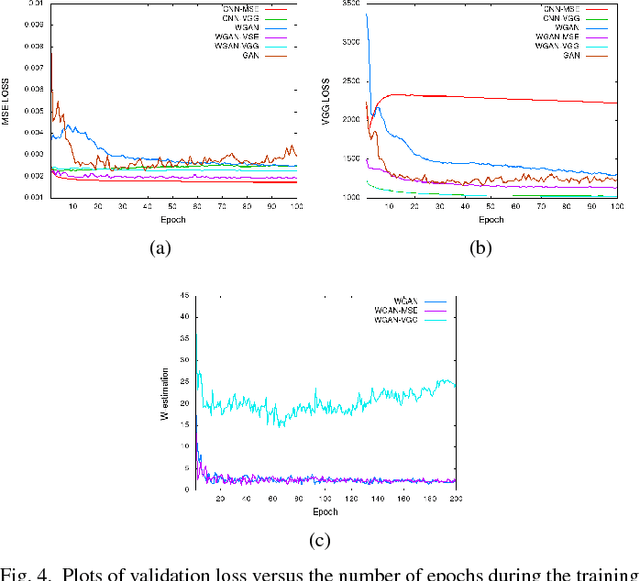
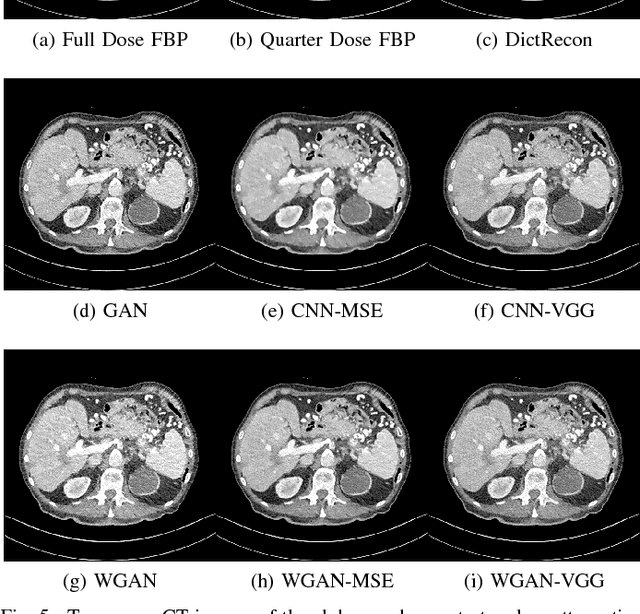
In this paper, we introduce a new CT image denoising method based on the generative adversarial network (GAN) with Wasserstein distance and perceptual similarity. The Wasserstein distance is a key concept of the optimal transform theory, and promises to improve the performance of the GAN. The perceptual loss compares the perceptual features of a denoised output against those of the ground truth in an established feature space, while the GAN helps migrate the data noise distribution from strong to weak. Therefore, our proposed method transfers our knowledge of visual perception to the image denoising task, is capable of not only reducing the image noise level but also keeping the critical information at the same time. Promising results have been obtained in our experiments with clinical CT images.
Adapting JPEG XS gains and priorities to tasks and contents
May 19, 2020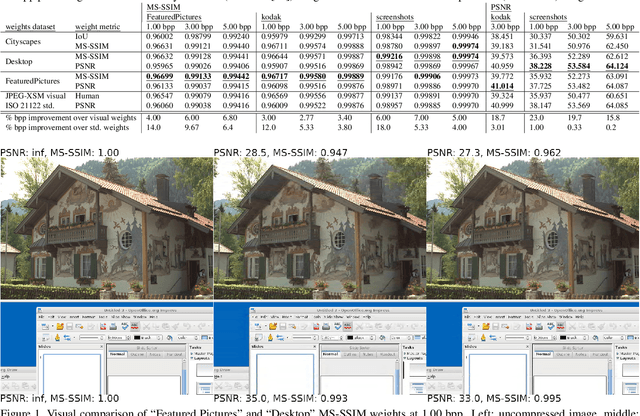
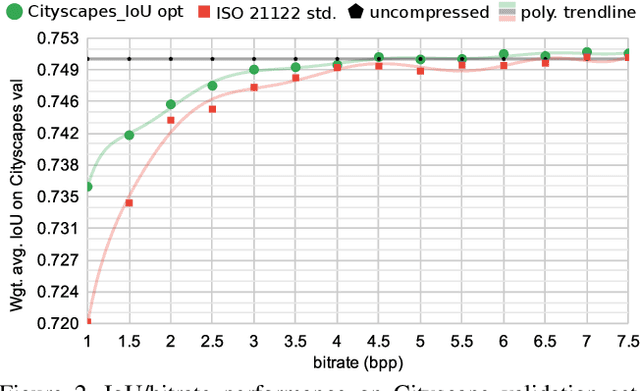
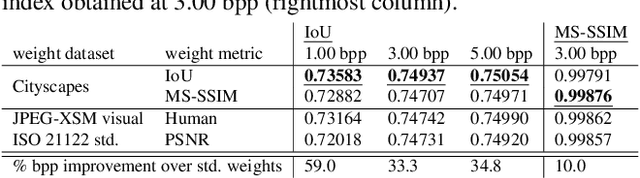
Most current research in the domain of image compression focuses solely on achieving state of the art compression ratio, but that is not always usable in today's workflow due to the constraints on computing resources. Constant market requirements for a low-complexity image codec have led to the recent development and standardization of a lightweight image codec named JPEG XS. In this work we show that JPEG XS compression can be adapted to a specific given task and content, such as preserving visual quality on desktop content or maintaining high accuracy in neural network segmentation tasks, by optimizing its gain and priority parameters using the covariance matrix adaptation evolution strategy.
Federated Learning over Wireless Device-to-Device Networks: Algorithms and Convergence Analysis
Jan 29, 2021
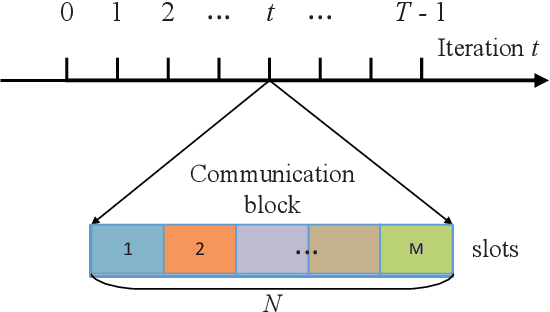
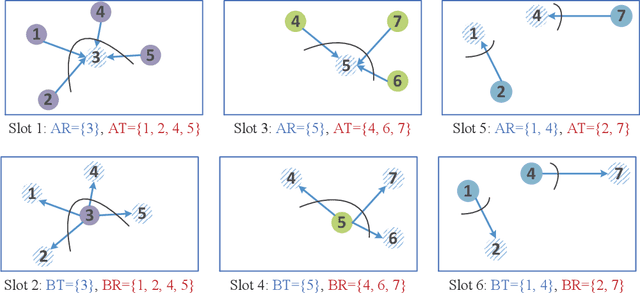
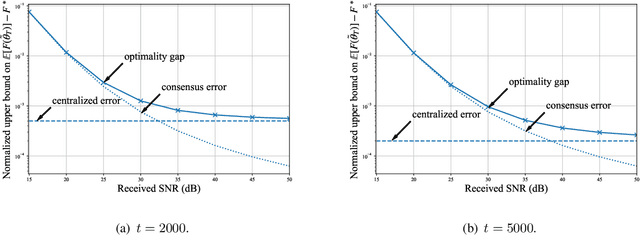
The proliferation of Internet-of-Things (IoT) devices and cloud-computing applications over siloed data centers is motivating renewed interest in the collaborative training of a shared model by multiple individual clients via federated learning (FL). To improve the communication efficiency of FL implementations in wireless systems, recent works have proposed compression and dimension reduction mechanisms, along with digital and analog transmission schemes that account for channel noise, fading, and interference. This prior art has mainly focused on star topologies consisting of distributed clients and a central server. In contrast, this paper studies FL over wireless device-to-device (D2D) networks by providing theoretical insights into the performance of digital and analog implementations of decentralized stochastic gradient descent (DSGD). First, we introduce generic digital and analog wireless implementations of communication-efficient DSGD algorithms, leveraging random linear coding (RLC) for compression and over-the-air computation (AirComp) for simultaneous analog transmissions. Next, under the assumptions of convexity and connectivity, we provide convergence bounds for both implementations. The results demonstrate the dependence of the optimality gap on the connectivity and on the signal-to-noise ratio (SNR) levels in the network. The analysis is corroborated by experiments on an image-classification task.
DRL-FAS: A Novel Framework Based on Deep Reinforcement Learning for Face Anti-Spoofing
Sep 16, 2020
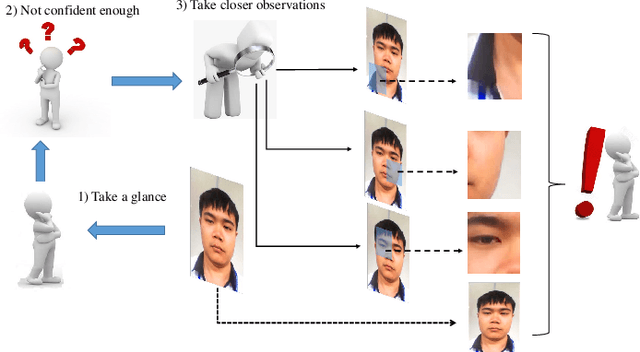
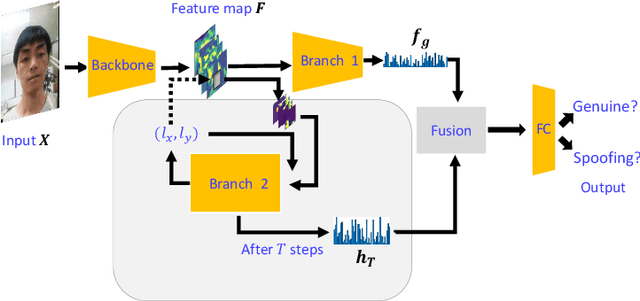
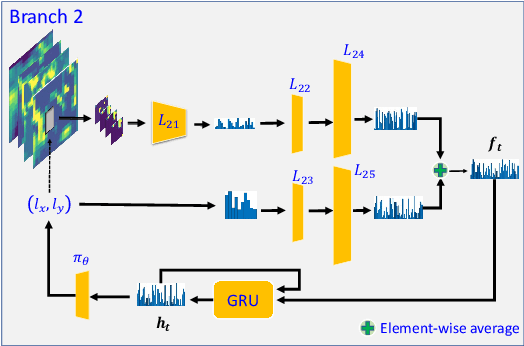
Inspired by the philosophy employed by human beings to determine whether a presented face example is genuine or not, i.e., to glance at the example globally first and then carefully observe the local regions to gain more discriminative information, for the face anti-spoofing problem, we propose a novel framework based on the Convolutional Neural Network (CNN) and the Recurrent Neural Network (RNN). In particular, we model the behavior of exploring face-spoofing-related information from image sub-patches by leveraging deep reinforcement learning. We further introduce a recurrent mechanism to learn representations of local information sequentially from the explored sub-patches with an RNN. Finally, for the classification purpose, we fuse the local information with the global one, which can be learned from the original input image through a CNN. Moreover, we conduct extensive experiments, including ablation study and visualization analysis, to evaluate our proposed framework on various public databases. The experiment results show that our method can generally achieve state-of-the-art performance among all scenarios, demonstrating its effectiveness.