 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Real-time and Autonomous Detection of Helipad for Landing Quad-Rotors by Visual Servoing
Aug 05, 2020


In this paper, we first present a method to autonomously detect helipads in real time. Our method does not rely on any machine-learning methods and as such is applicable in real-time on the computational capabilities of an average quad-rotor. After initial detection, we use image tracking methods to reduce the computational resource requirement further. Once the tracking starts our modified IBVS(Image-Based Visual Servoing) method starts publishing velocity to guide the quad-rotor onto the helipad. The modified IBVS scheme is designed for the four degrees-of-freedom of a quad-rotor and can land the quad-rotor in a specific orientation.
A Type II Fuzzy Entropy Based Multi-Level Image Thresholding Using Adaptive Plant Propagation Algorithm
Aug 23, 2017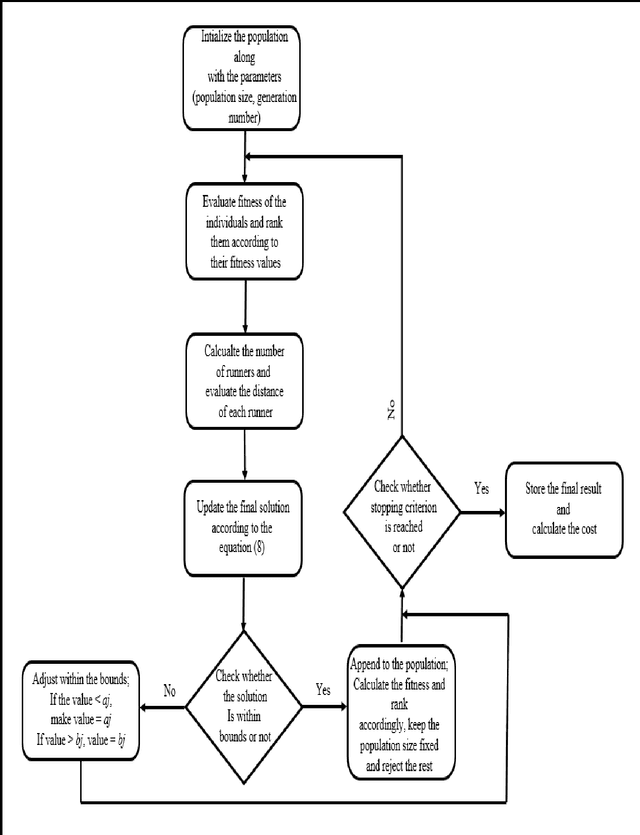
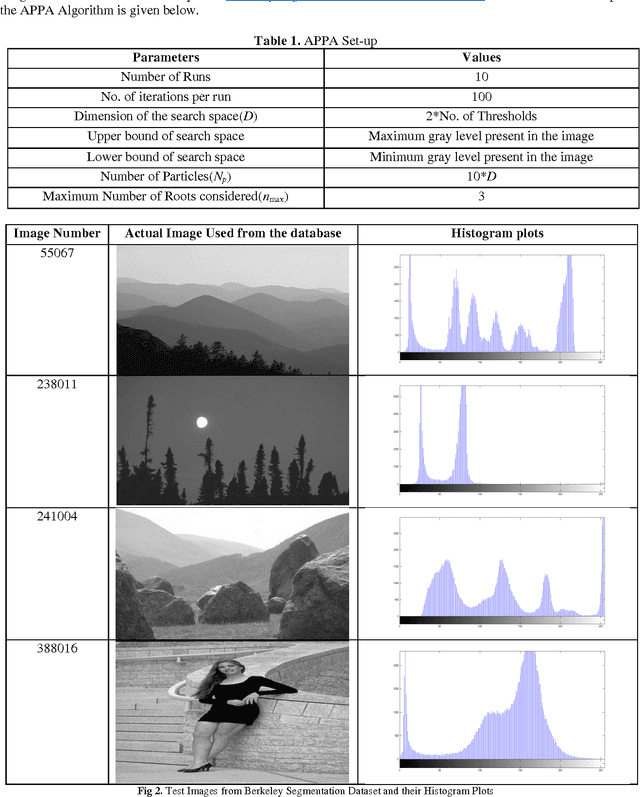

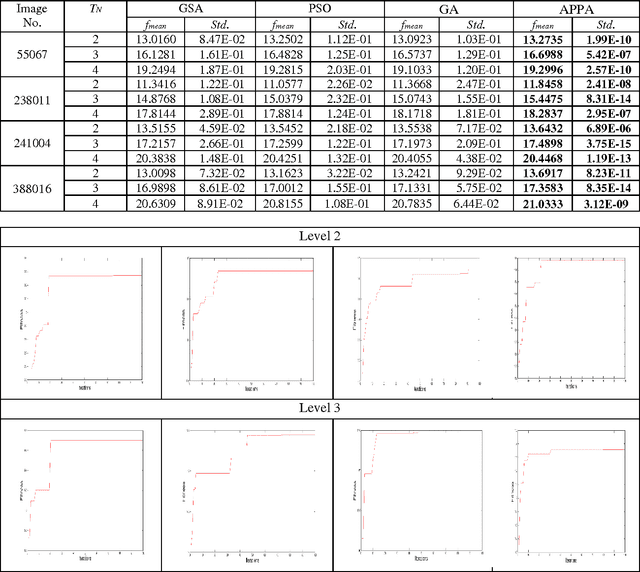
One of the most straightforward, direct and efficient approaches to Image Segmentation is Image Thresholding. Multi-level Image Thresholding is an essential viewpoint in many image processing and Pattern Recognition based real-time applications which can effectively and efficiently classify the pixels into various groups denoting multiple regions in an Image. Thresholding based Image Segmentation using fuzzy entropy combined with intelligent optimization approaches are commonly used direct methods to properly identify the thresholds so that they can be used to segment an Image accurately. In this paper a novel approach for multi-level image thresholding is proposed using Type II Fuzzy sets combined with Adaptive Plant Propagation Algorithm (APPA). Obtaining the optimal thresholds for an image by maximizing the entropy is extremely tedious and time consuming with increase in the number of thresholds. Hence, Adaptive Plant Propagation Algorithm (APPA), a memetic algorithm based on plant intelligence, is used for fast and efficient selection of optimal thresholds. This fact is reasonably justified by comparing the accuracy of the outcomes and computational time consumed by other modern state-of-the-art algorithms such as Particle Swarm Optimization (PSO), Gravitational Search Algorithm (GSA) and Genetic Algorithm (GA).
Data augmentation with Symbolic-to-Real Image Translation GANs for Traffic Sign Recognition
Jul 17, 2019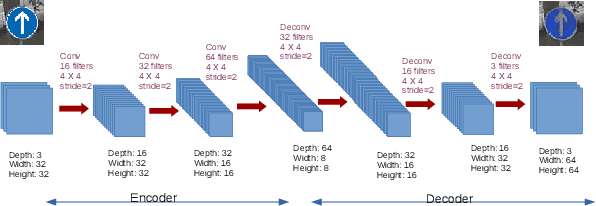

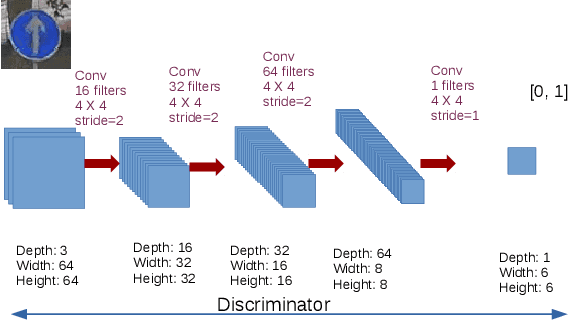
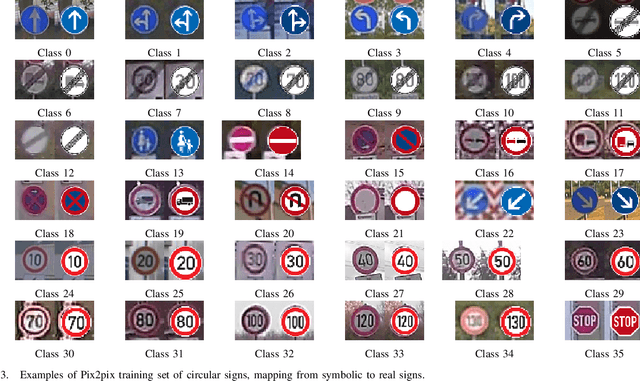
Traffic sign recognition is an important component of many advanced driving assistance systems, and it is required for full autonomous driving. Computational performance is usually the bottleneck in using large scale neural networks for this purpose. SqueezeNet is a good candidate for efficient image classification of traffic signs, but in our experiments it does not reach high accuracy, and we believe this is due to lack of data, requiring data augmentation. Generative adversarial networks can learn the high dimensional distribution of empirical data, allowing the generation of new data points. In this paper we apply pix2pix GANs architecture to generate new traffic sign images and evaluate the use of these images in data augmentation. We were motivated to use pix2pix to translate symbolic sign images to real ones due to the mode collapse in Conditional GANs. Through our experiments we found that data augmentation using GAN can increase classification accuracy for circular traffic signs from 92.1% to 94.0%, and for triangular traffic signs from 93.8% to 95.3%, producing an overall improvement of 2%. However some traditional augmentation techniques can outperform GAN data augmentation, for example contrast variation in circular traffic signs (95.5%) and displacement on triangular traffic signs (96.7 %). Our negative results shows that while GANs can be naively used for data augmentation, they are not always the best choice, depending on the problem and variability in the data.
Modality-Agnostic Attention Fusion for visual search with text feedback
Jun 30, 2020

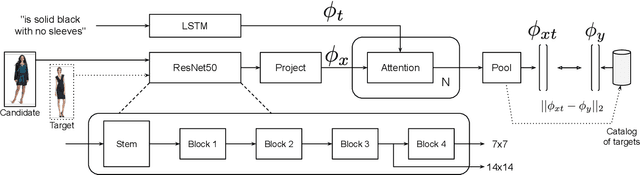
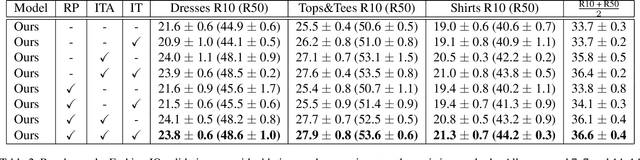
Image retrieval with natural language feedback offers the promise of catalog search based on fine-grained visual features that go beyond objects and binary attributes, facilitating real-world applications such as e-commerce. Our Modality-Agnostic Attention Fusion (MAAF) model combines image and text features and outperforms existing approaches on two visual search with modifying phrase datasets, Fashion IQ and CSS, and performs competitively on a dataset with only single-word modifications, Fashion200k. We also introduce two new challenging benchmarks adapted from Birds-to-Words and Spot-the-Diff, which provide new settings with rich language inputs, and we show that our approach without modification outperforms strong baselines. To better understand our model, we conduct detailed ablations on Fashion IQ and provide visualizations of the surprising phenomenon of words avoiding "attending" to the image region they refer to.
Unsupervised Single Image Dehazing Using Dark Channel Prior Loss
Dec 06, 2018



Single image dehazing is a critical stage in many modern-day autonomous vision applications. Early prior-based methods often involved a time-consuming minimization of a hand-crafted energy function. Recent learning-based approaches utilize the representational power of deep neural networks (DNNs) to learn the underlying transformation between hazy and clear images. Due to inherent limitations in collecting matching clear and hazy images, these methods resort to training on synthetic data; constructed from indoor images and corresponding depth information. This may result in a possible domain shift when treating outdoor scenes. We propose a completely unsupervised method of training via minimization of the well-known, Dark Channel Prior (DCP) energy function. Instead of feeding the network with synthetic data, we solely use real-world outdoor images and tune the network's parameters by directly minimizing the DCP. Although our `Deep DCP' technique can be regarded as a fast approximator of DCP, it actually improves its results significantly. This suggests an additional regularization obtained via the network and learning process. Experiments show that our method performs on par with other large-scale, supervised methods.
CVAE-GAN: Fine-Grained Image Generation through Asymmetric Training
Oct 12, 2017
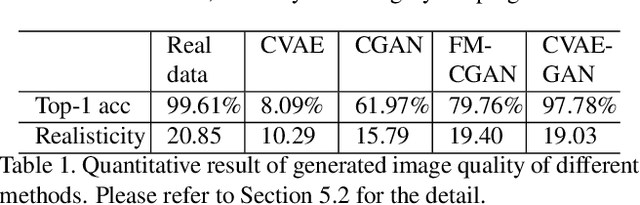
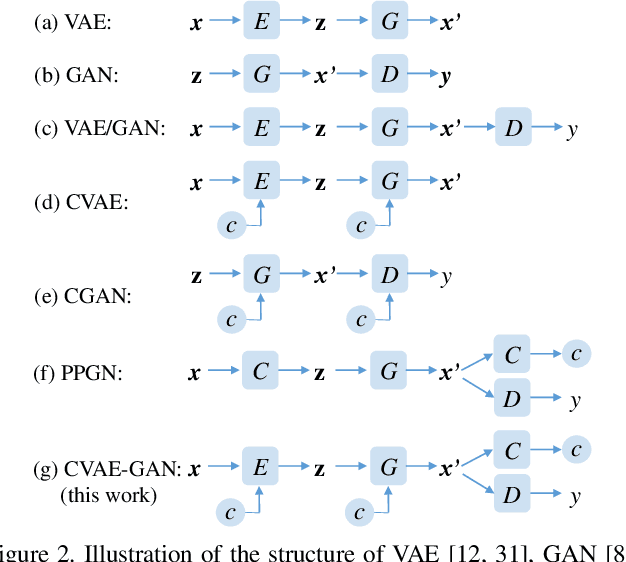
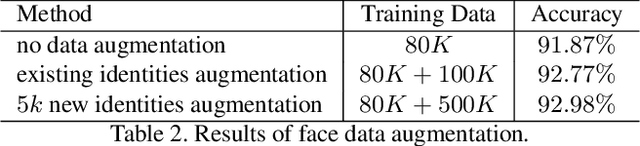
We present variational generative adversarial networks, a general learning framework that combines a variational auto-encoder with a generative adversarial network, for synthesizing images in fine-grained categories, such as faces of a specific person or objects in a category. Our approach models an image as a composition of label and latent attributes in a probabilistic model. By varying the fine-grained category label fed into the resulting generative model, we can generate images in a specific category with randomly drawn values on a latent attribute vector. Our approach has two novel aspects. First, we adopt a cross entropy loss for the discriminative and classifier network, but a mean discrepancy objective for the generative network. This kind of asymmetric loss function makes the GAN training more stable. Second, we adopt an encoder network to learn the relationship between the latent space and the real image space, and use pairwise feature matching to keep the structure of generated images. We experiment with natural images of faces, flowers, and birds, and demonstrate that the proposed models are capable of generating realistic and diverse samples with fine-grained category labels. We further show that our models can be applied to other tasks, such as image inpainting, super-resolution, and data augmentation for training better face recognition models.
Improving Object Detection with Selective Self-supervised Self-training
Jul 24, 2020
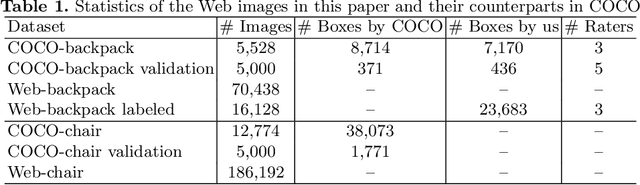

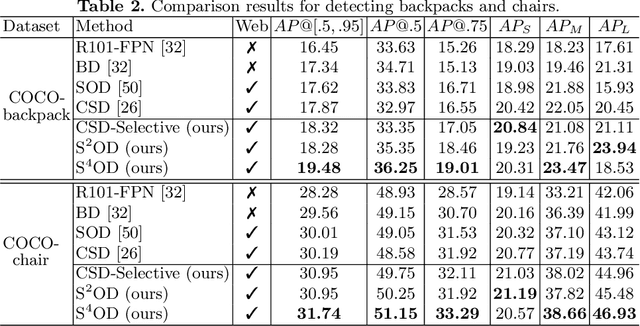
We study how to leverage Web images to augment human-curated object detection datasets. Our approach is two-pronged. On the one hand, we retrieve Web images by image-to-image search, which incurs less domain shift from the curated data than other search methods. The Web images are diverse, supplying a wide variety of object poses, appearances, their interactions with the context, etc. On the other hand, we propose a novel learning method motivated by two parallel lines of work that explore unlabeled data for image classification: self-training and self-supervised learning. They fail to improve object detectors in their vanilla forms due to the domain gap between the Web images and curated datasets. To tackle this challenge, we propose a selective net to rectify the supervision signals in Web images. It not only identifies positive bounding boxes but also creates a safe zone for mining hard negative boxes. We report state-of-the-art results on detecting backpacks and chairs from everyday scenes, along with other challenging object classes.
Segmentation of Breast Microcalcifications: A Multi-Scale Approach
Feb 01, 2021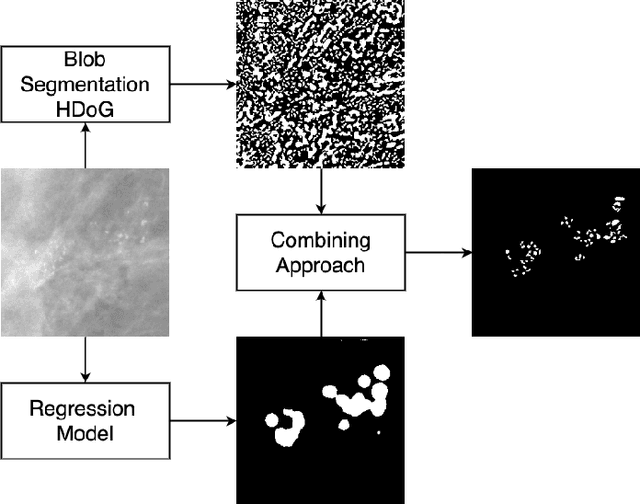
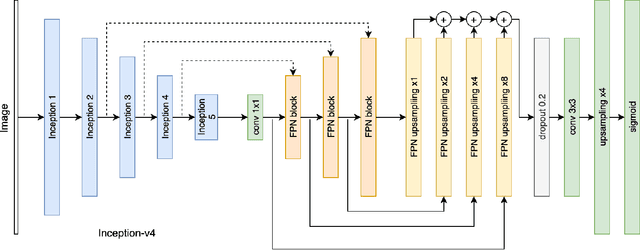


Accurate characterization of microcalcifications (MCs) in 2D full-field digital screening mammography is a necessary step towards reducing diagnostic uncertainty associated with the callback of women with suspicious MCs. Quantitative analysis of MCs has the potential to better identify MCs that have a higher likelihood of corresponding to invasive cancer. However, automated identification and segmentation of MCs remains a challenging task with high false positive rates. We present Hessian Difference of Gaussians Regression (HDoGReg), a two stage multi-scale approach to MC segmentation. Candidate high optical density objects are first delineated using blob detection and Hessian analysis. A regression convolutional network, trained to output a function with higher response near MCs, chooses the objects which constitute actual MCs. The method is trained and validated on 435 mammograms from two separate datasets. HDoGReg achieved a mean intersection over the union of 0.670$\pm$0.121 per image, intersection over the union per MC object of 0.607$\pm$0.250 and true positive rate of 0.744 at 0.4 false positive detections per $cm^2$. The results of HDoGReg perform better when compared to state-of-the-art MC segmentation and detection methods.
Hashed Binary Search Sampling for Convolutional Network Training with Large Overhead Image Patches
Jul 18, 2017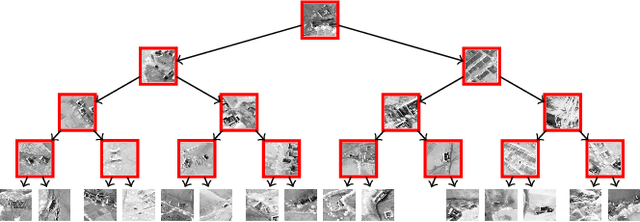
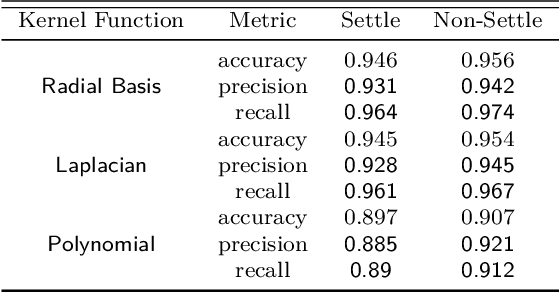
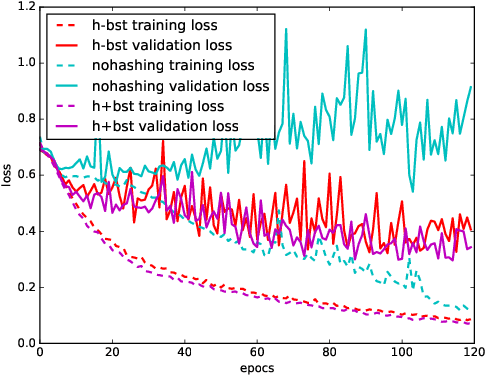

Very large overhead imagery associated with ground truth maps has the potential to generate billions of training image patches for machine learning algorithms. However, random sampling selection criteria often leads to redundant and noisy-image patches for model training. With minimal research efforts behind this challenge, the current status spells missed opportunities to develop supervised learning algorithms that generalize over wide geographical scenes. In addition, much of the computational cycles for large scale machine learning are poorly spent crunching through noisy and redundant image patches. We demonstrate a potential framework to address these challenges specifically, while evaluating a human settlement detection task. A novel binary search tree sampling scheme is fused with a kernel based hashing procedure that maps image patches into hash-buckets using binary codes generated from image content. The framework exploits inherent redundancy within billions of image patches to promote mostly high variance preserving samples for accelerating algorithmic training and increasing model generalization.
Heatmap-based Object Detection and Tracking with a Fully Convolutional Neural Network
Jan 10, 2021
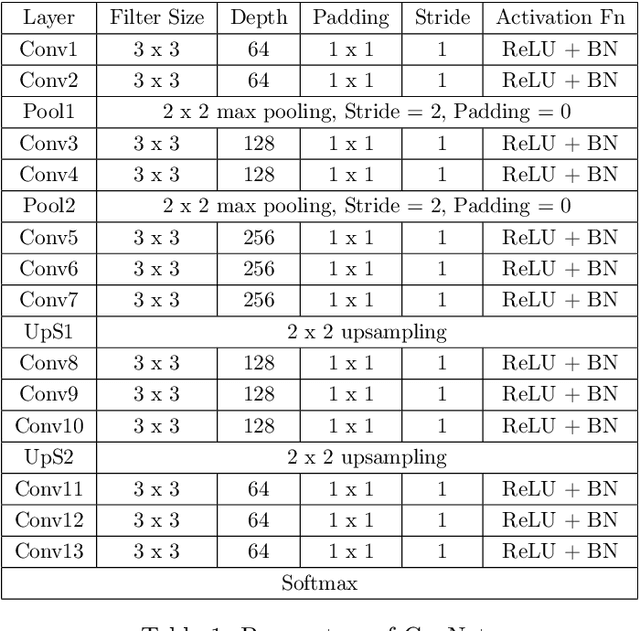

The main topic of this paper is a brief overview of the field of Artificial Intelligence. The core of this paper is a practical implementation of an algorithm for object detection and tracking. The ability to detect and track fast-moving objects is crucial for various applications of Artificial Intelligence like autonomous driving, ball tracking in sports, robotics or object counting. As part of this paper the Fully Convolutional Neural Network "CueNet" was developed. It detects and tracks the cueball on a labyrinth game robustly and reliably. While CueNet V1 has a single input image, the approach with CueNet V2 was to take three consecutive 240 x 180-pixel images as an input and transform them into a probability heatmap for the cueball's location. The network was tested with a separate video that contained all sorts of distractions to test its robustness. When confronted with our testing data, CueNet V1 predicted the correct cueball location in 99.6% of all frames, while CueNet V2 had 99.8% accuracy.