 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Survey on Deep Learning in Medical Image Analysis
Jun 04, 2017
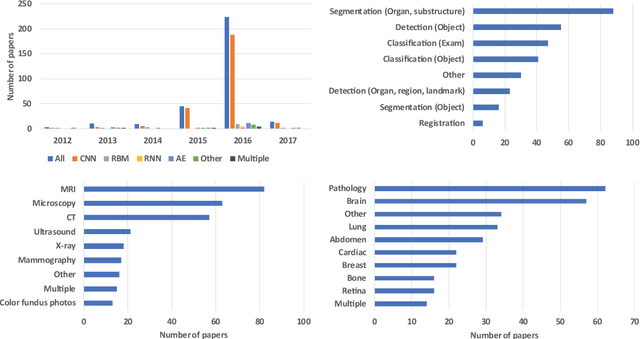
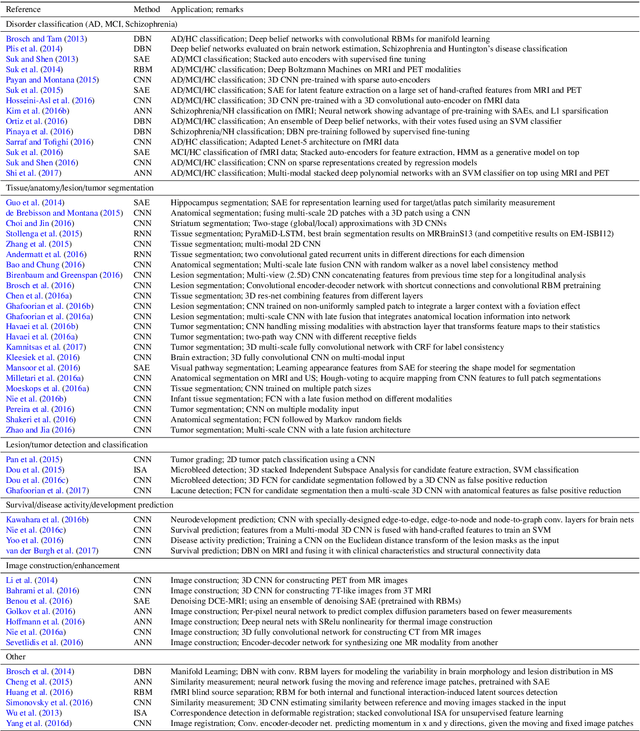
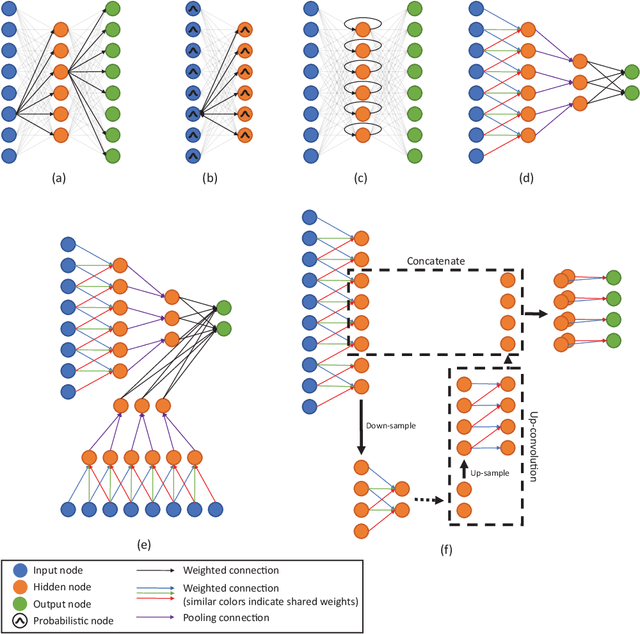

Deep learning algorithms, in particular convolutional networks, have rapidly become a methodology of choice for analyzing medical images. This paper reviews the major deep learning concepts pertinent to medical image analysis and summarizes over 300 contributions to the field, most of which appeared in the last year. We survey the use of deep learning for image classification, object detection, segmentation, registration, and other tasks and provide concise overviews of studies per application area. Open challenges and directions for future research are discussed.
Scene Graph Reasoning for Visual Question Answering
Jul 02, 2020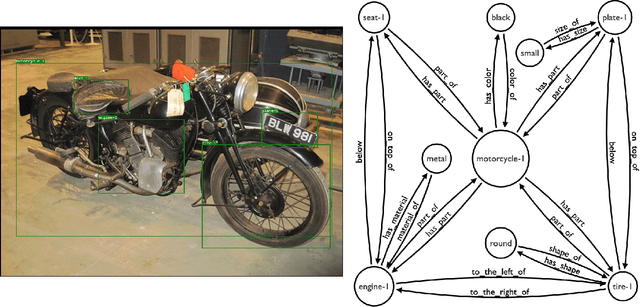
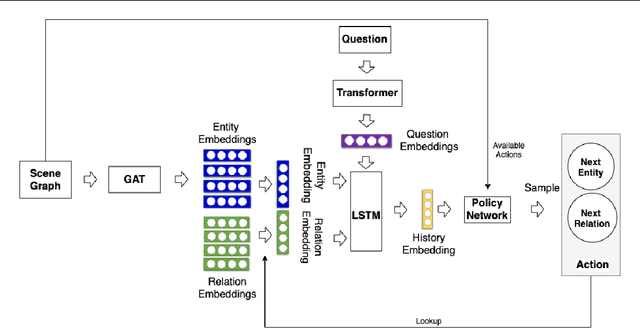

Visual question answering is concerned with answering free-form questions about an image. Since it requires a deep linguistic understanding of the question and the ability to associate it with various objects that are present in the image, it is an ambitious task and requires techniques from both computer vision and natural language processing. We propose a novel method that approaches the task by performing context-driven, sequential reasoning based on the objects and their semantic and spatial relationships present in the scene. As a first step, we derive a scene graph which describes the objects in the image, as well as their attributes and their mutual relationships. A reinforcement agent then learns to autonomously navigate over the extracted scene graph to generate paths, which are then the basis for deriving answers. We conduct a first experimental study on the challenging GQA dataset with manually curated scene graphs, where our method almost reaches the level of human performance.
Simultaneous Semantic Alignment Network for Heterogeneous Domain Adaptation
Aug 05, 2020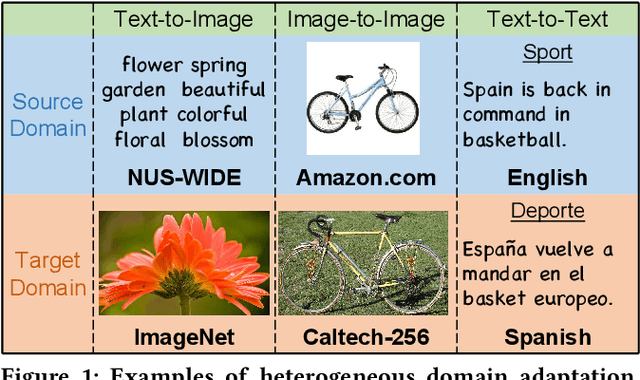
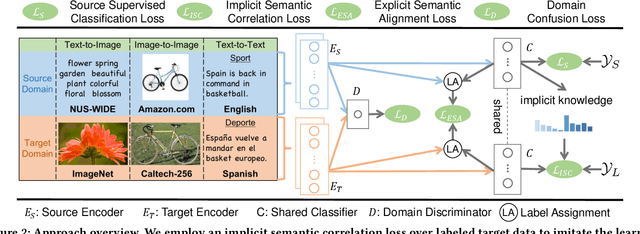
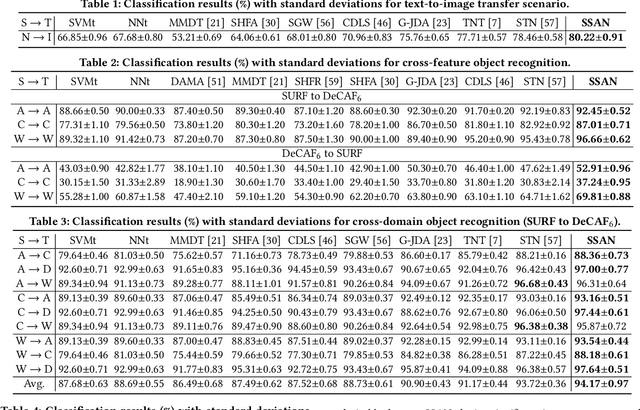
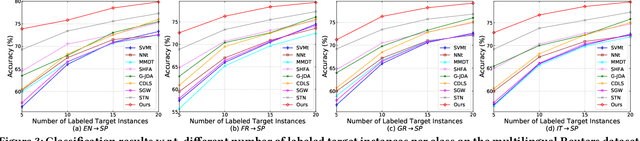
Heterogeneous domain adaptation (HDA) transfers knowledge across source and target domains that present heterogeneities e.g., distinct domain distributions and difference in feature type or dimension. Most previous HDA methods tackle this problem through learning a domain-invariant feature subspace to reduce the discrepancy between domains. However, the intrinsic semantic properties contained in data are under-explored in such alignment strategy, which is also indispensable to achieve promising adaptability. In this paper, we propose a Simultaneous Semantic Alignment Network (SSAN) to simultaneously exploit correlations among categories and align the centroids for each category across domains. In particular, we propose an implicit semantic correlation loss to transfer the correlation knowledge of source categorical prediction distributions to target domain. Meanwhile, by leveraging target pseudo-labels, a robust triplet-centroid alignment mechanism is explicitly applied to align feature representations for each category. Notably, a pseudo-label refinement procedure with geometric similarity involved is introduced to enhance the target pseudo-label assignment accuracy. Comprehensive experiments on various HDA tasks across text-to-image, image-to-image and text-to-text successfully validate the superiority of our SSAN against state-of-the-art HDA methods. The code is publicly available at https://github.com/BIT-DA/SSAN.
Joint Unsupervised Learning of Deep Representations and Image Clusters
Jun 20, 2016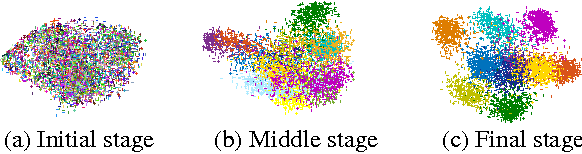

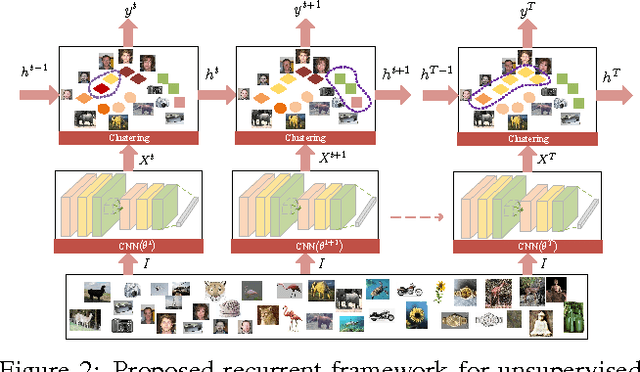
In this paper, we propose a recurrent framework for Joint Unsupervised LEarning (JULE) of deep representations and image clusters. In our framework, successive operations in a clustering algorithm are expressed as steps in a recurrent process, stacked on top of representations output by a Convolutional Neural Network (CNN). During training, image clusters and representations are updated jointly: image clustering is conducted in the forward pass, while representation learning in the backward pass. Our key idea behind this framework is that good representations are beneficial to image clustering and clustering results provide supervisory signals to representation learning. By integrating two processes into a single model with a unified weighted triplet loss and optimizing it end-to-end, we can obtain not only more powerful representations, but also more precise image clusters. Extensive experiments show that our method outperforms the state-of-the-art on image clustering across a variety of image datasets. Moreover, the learned representations generalize well when transferred to other tasks.
Seeing with Humans: Gaze-Assisted Neural Image Captioning
Aug 18, 2016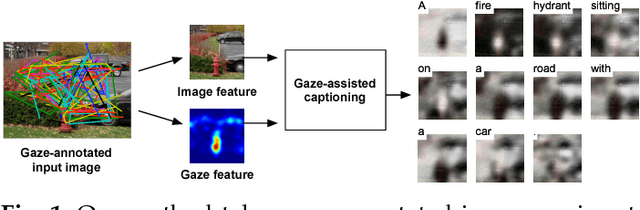
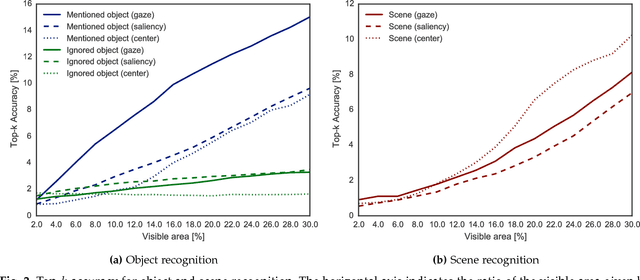
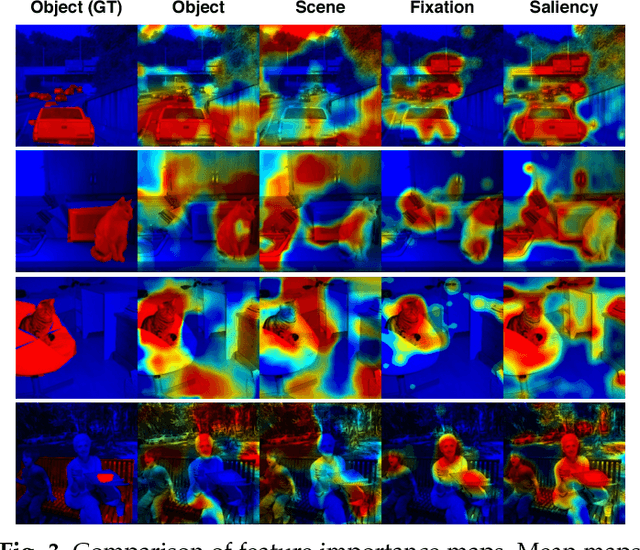
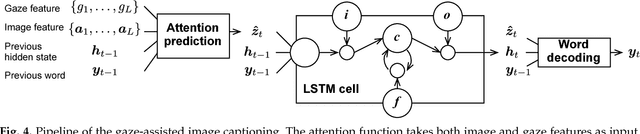
Gaze reflects how humans process visual scenes and is therefore increasingly used in computer vision systems. Previous works demonstrated the potential of gaze for object-centric tasks, such as object localization and recognition, but it remains unclear if gaze can also be beneficial for scene-centric tasks, such as image captioning. We present a new perspective on gaze-assisted image captioning by studying the interplay between human gaze and the attention mechanism of deep neural networks. Using a public large-scale gaze dataset, we first assess the relationship between state-of-the-art object and scene recognition models, bottom-up visual saliency, and human gaze. We then propose a novel split attention model for image captioning. Our model integrates human gaze information into an attention-based long short-term memory architecture, and allows the algorithm to allocate attention selectively to both fixated and non-fixated image regions. Through evaluation on the COCO/SALICON datasets we show that our method improves image captioning performance and that gaze can complement machine attention for semantic scene understanding tasks.
Learning Better Lossless Compression Using Lossy Compression
Mar 23, 2020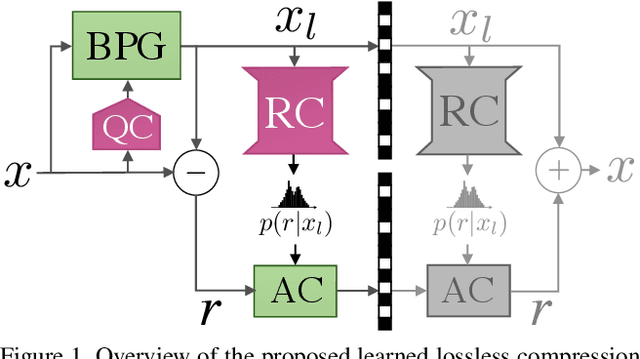
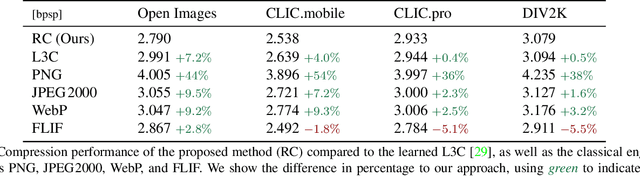
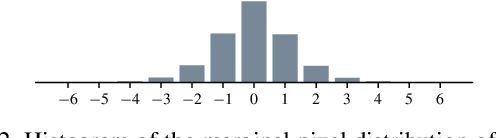
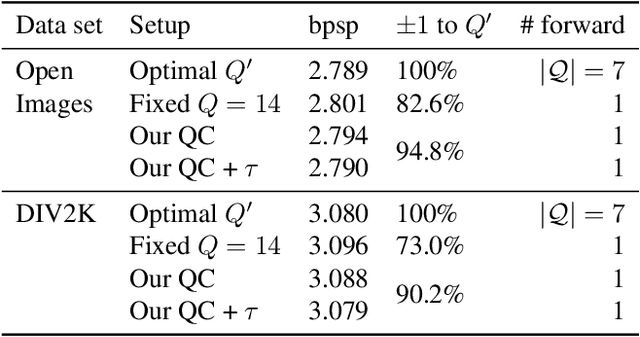
We leverage the powerful lossy image compression algorithm BPG to build a lossless image compression system. Specifically, the original image is first decomposed into the lossy reconstruction obtained after compressing it with BPG and the corresponding residual. We then model the distribution of the residual with a convolutional neural network-based probabilistic model that is conditioned on the BPG reconstruction, and combine it with entropy coding to losslessly encode the residual. Finally, the image is stored using the concatenation of the bitstreams produced by BPG and the learned residual coder. The resulting compression system achieves state-of-the-art performance in learned lossless full-resolution image compression, outperforming previous learned approaches as well as PNG, WebP, and JPEG2000.
Geometric Scene Refocusing
Dec 20, 2020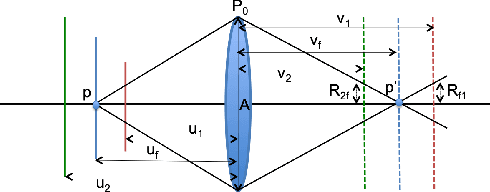
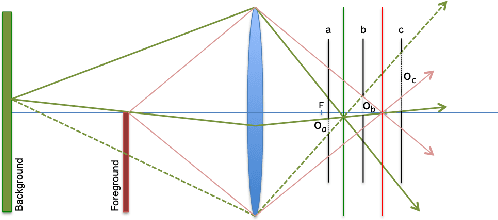

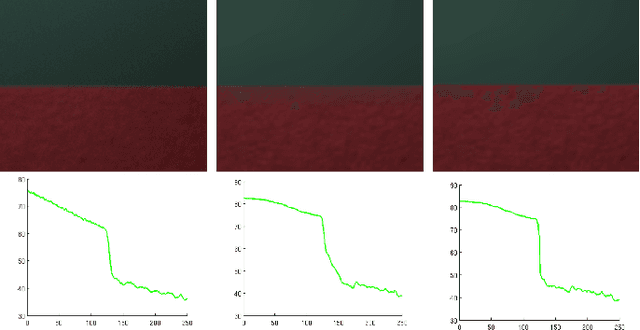
An image captured with a wide-aperture camera exhibits a finite depth-of-field, with focused and defocused pixels. A compact and robust representation of focus and defocus helps analyze and manipulate such images. In this work, we study the fine characteristics of images with a shallow depth-of-field in the context of focal stacks. We present a composite measure for focus that is a combination of existing measures. We identify in-focus pixels, dual-focus pixels, pixels that exhibit bokeh and spatially-varying blur kernels between focal slices. We use these to build a novel representation that facilitates easy manipulation of focal stacks. We present a comprehensive algorithm for post-capture refocusing in a geometrically correct manner. Our approach can refocus the scene at high fidelity while preserving fine aspects of focus and defocus blur.
Learning Disentangled Representations with Latent Variation Predictability
Jul 25, 2020
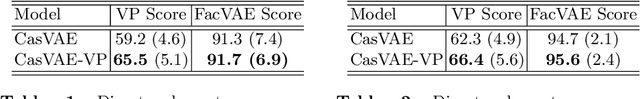
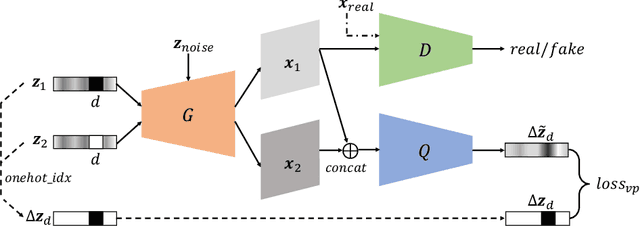
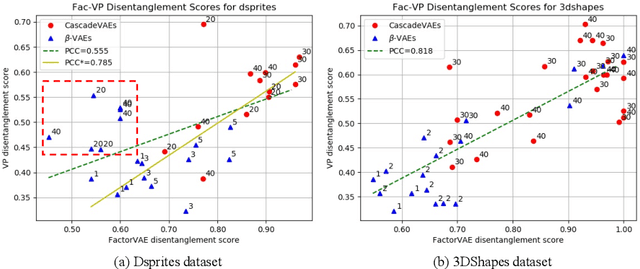
Latent traversal is a popular approach to visualize the disentangled latent representations. Given a bunch of variations in a single unit of the latent representation, it is expected that there is a change in a single factor of variation of the data while others are fixed. However, this impressive experimental observation is rarely explicitly encoded in the objective function of learning disentangled representations. This paper defines the variation predictability of latent disentangled representations. Given image pairs generated by latent codes varying in a single dimension, this varied dimension could be closely correlated with these image pairs if the representation is well disentangled. Within an adversarial generation process, we encourage variation predictability by maximizing the mutual information between latent variations and corresponding image pairs. We further develop an evaluation metric that does not rely on the ground-truth generative factors to measure the disentanglement of latent representations. The proposed variation predictability is a general constraint that is applicable to the VAE and GAN frameworks for boosting disentanglement of latent representations. Experiments show that the proposed variation predictability correlates well with existing ground-truth-required metrics and the proposed algorithm is effective for disentanglement learning.
Weakly Supervised Semantic Image Segmentation with Self-correcting Networks
Nov 17, 2018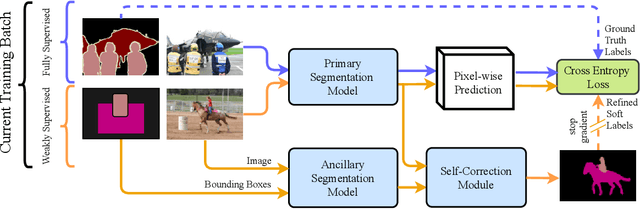
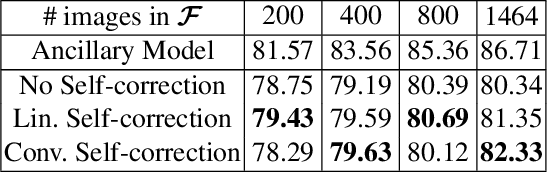
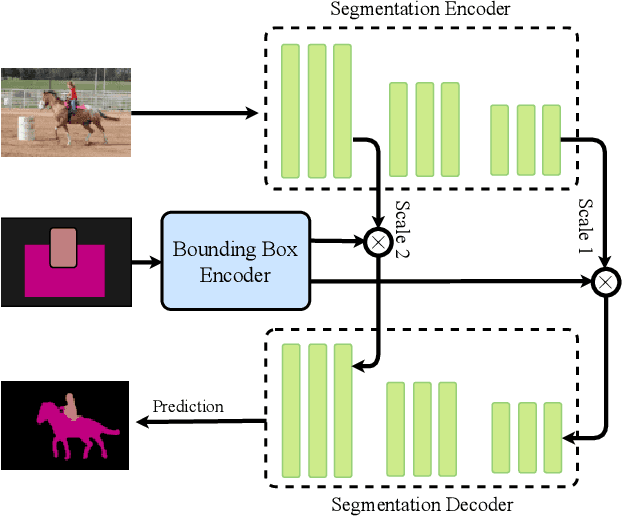
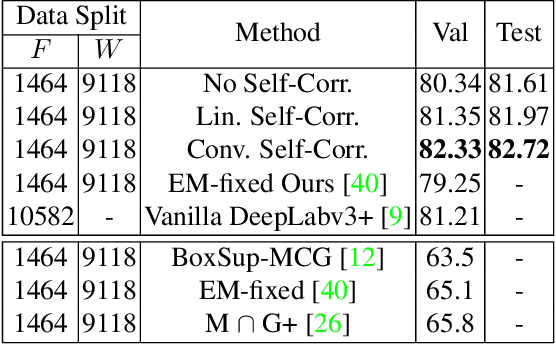
Building a large image dataset with high-quality object masks for semantic segmentation is costly and time consuming. In this paper, we reduce the data preparation cost by leveraging weak supervision in the form of object bounding boxes. To accomplish this, we propose a principled framework that trains a deep convolutional segmentation model that combines a large set of weakly supervised images (having only object bounding box labels) with a small set of fully supervised images (having semantic segmentation labels and box labels). Our framework trains the primary segmentation model with the aid of an ancillary model that generates initial segmentation labels for the weakly supervised instances and a self-correction module that improves the generated labels during training using the increasingly accurate primary model. We introduce two variants of the self-correction module using either linear or convolutional functions. Experiments on the PASCAL VOC 2012 and Cityscape datasets show that our models trained with a small fully supervised set perform similar to, or better than, models trained with a large fully supervised set while requiring ~7x less annotation effort.
Animating Through Warping: an Efficient Method for High-Quality Facial Expression Animation
Aug 01, 2020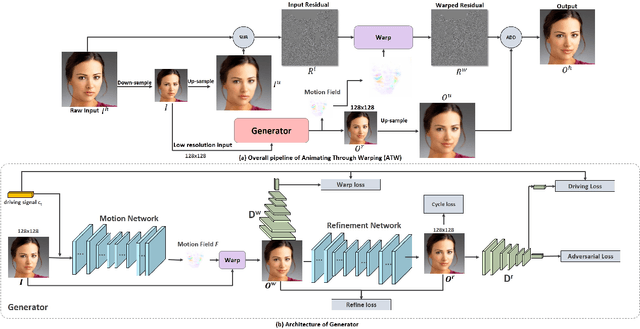
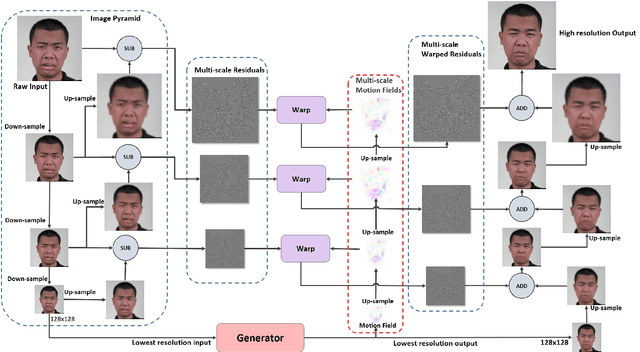


Advances in deep neural networks have considerably improved the art of animating a still image without operating in 3D domain. Whereas, prior arts can only animate small images (typically no larger than 512x512) due to memory limitations, difficulty of training and lack of high-resolution (HD) training datasets, which significantly reduce their potential for applications in movie production and interactive systems. Motivated by the idea that HD images can be generated by adding high-frequency residuals to low-resolution results produced by a neural network, we propose a novel framework known as Animating Through Warping (ATW) to enable efficient animation of HD images. Specifically, the proposed framework consists of two modules, a novel two-stage neural-network generator and a novel post-processing module known as Animating Through Warping (ATW). It only requires the generator to be trained on small images and can do inference on an image of any size. During inference, an HD input image is decomposed into a low-resolution component(128x128) and its corresponding high-frequency residuals. The generator predicts the low-resolution result as well as the motion field that warps the input face to the desired status (e.g., expressions categories or action units). Finally, the ResWarp module warps the residuals based on the motion field and adding the warped residuals to generates the final HD results from the naively up-sampled low-resolution results. Experiments show the effectiveness and efficiency of our method in generating high-resolution animations. Our proposed framework successfully animates a 4K facial image, which has never been achieved by prior neural models. In addition, our method generally guarantee the temporal coherency of the generated animations. Source codes will be made publicly available.