 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Recurrent Neural Networks to Correct Satellite Image Classification Maps
Apr 21, 2017
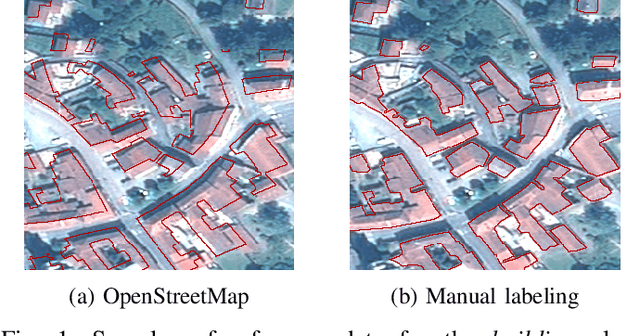

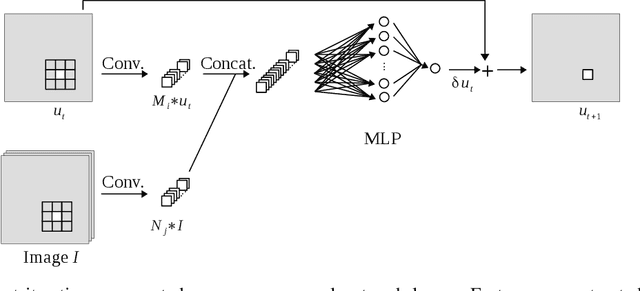

While initially devised for image categorization, convolutional neural networks (CNNs) are being increasingly used for the pixelwise semantic labeling of images. However, the proper nature of the most common CNN architectures makes them good at recognizing but poor at localizing objects precisely. This problem is magnified in the context of aerial and satellite image labeling, where a spatially fine object outlining is of paramount importance. Different iterative enhancement algorithms have been presented in the literature to progressively improve the coarse CNN outputs, seeking to sharpen object boundaries around real image edges. However, one must carefully design, choose and tune such algorithms. Instead, our goal is to directly learn the iterative process itself. For this, we formulate a generic iterative enhancement process inspired from partial differential equations, and observe that it can be expressed as a recurrent neural network (RNN). Consequently, we train such a network from manually labeled data for our enhancement task. In a series of experiments we show that our RNN effectively learns an iterative process that significantly improves the quality of satellite image classification maps.
Learning to Drop Points for LiDAR Scan Synthesis
Feb 23, 2021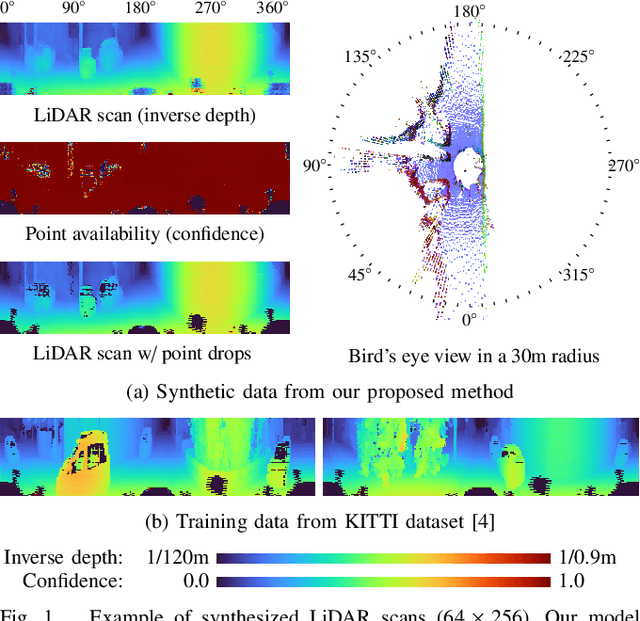

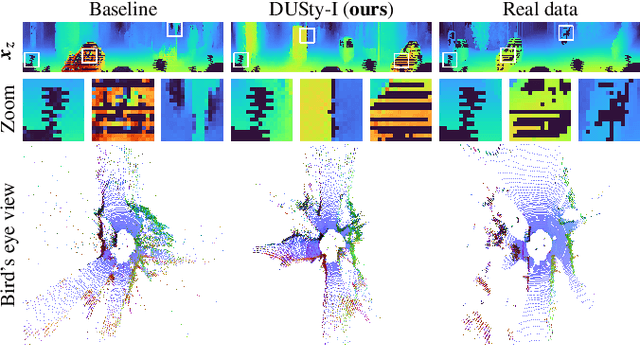

Generative modeling of 3D scenes is a crucial topic for aiding mobile robots to improve unreliable observations. However, despite the rapid progress in the natural image domain, building generative models is still challenging for 3D data, such as point clouds. Most existing studies on point clouds have focused on small and uniform-density data. In contrast, 3D LiDAR point clouds widely used in mobile robots are non-trivial to be handled because of the large number of points and varying-density. To circumvent this issue, 3D-to-2D projected representation such as a cylindrical depth map has been studied in existing LiDAR processing tasks but susceptible to discrete lossy pixels caused by failures of laser reflection. This paper proposes a novel framework based on generative adversarial networks to synthesize realistic LiDAR data as an improved 2D representation. Our generative architectures are designed to learn a distribution of inverse depth maps and simultaneously simulate the lossy pixels, which enables us to decompose an underlying smooth geometry and the corresponding uncertainty of laser reflection. To simulate the lossy pixels, we propose a differentiable framework to learn to produce sample-dependent binary masks using the Gumbel-Sigmoid reparametrization trick. We demonstrate the effectiveness of our approach in synthesis and reconstruction tasks on two LiDAR datasets. We further showcase potential applications by recovering various corruptions in LiDAR data.
Universal Adversarial Perturbations Against Semantic Image Segmentation
Jul 31, 2017



While deep learning is remarkably successful on perceptual tasks, it was also shown to be vulnerable to adversarial perturbations of the input. These perturbations denote noise added to the input that was generated specifically to fool the system while being quasi-imperceptible for humans. More severely, there even exist universal perturbations that are input-agnostic but fool the network on the majority of inputs. While recent work has focused on image classification, this work proposes attacks against semantic image segmentation: we present an approach for generating (universal) adversarial perturbations that make the network yield a desired target segmentation as output. We show empirically that there exist barely perceptible universal noise patterns which result in nearly the same predicted segmentation for arbitrary inputs. Furthermore, we also show the existence of universal noise which removes a target class (e.g., all pedestrians) from the segmentation while leaving the segmentation mostly unchanged otherwise.
Multi-Feature Multi-Scale CNN-Derived COVID-19 Classification from Lung Ultrasound Data
Feb 23, 2021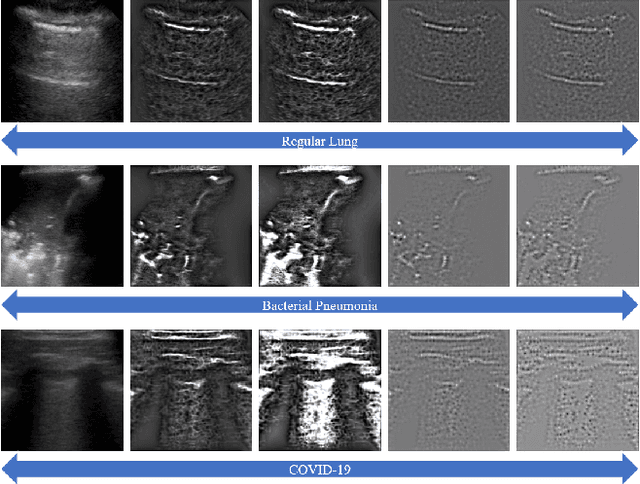
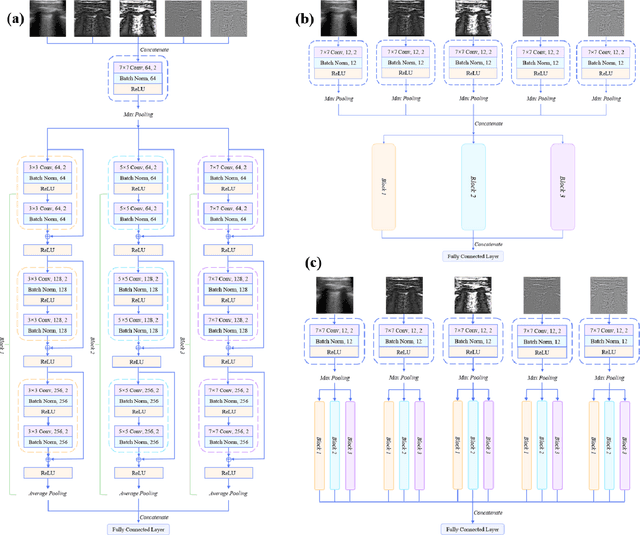
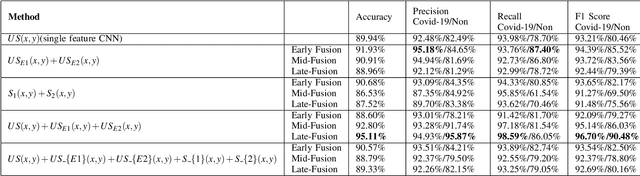
The global pandemic of the novel coronavirus disease 2019 (COVID-19) has put tremendous pressure on the medical system. Imaging plays a complementary role in the management of patients with COVID-19. Computed tomography (CT) and chest X-ray (CXR) are the two dominant screening tools. However, difficulty in eliminating the risk of disease transmission, radiation exposure and not being costeffective are some of the challenges for CT and CXR imaging. This fact induces the implementation of lung ultrasound (LUS) for evaluating COVID-19 due to its practical advantages of noninvasiveness, repeatability, and sensitive bedside property. In this paper, we utilize a deep learning model to perform the classification of COVID-19 from LUS data, which could produce objective diagnostic information for clinicians. Specifically, all LUS images are processed to obtain their corresponding local phase filtered images and radial symmetry transformed images before fed into the multi-scale residual convolutional neural network (CNN). Secondly, image combination as the input of the network is used to explore rich and reliable features. Feature fusion strategy at different levels is adopted to investigate the relationship between the depth of feature aggregation and the classification accuracy. Our proposed method is evaluated on the point-of-care US (POCUS) dataset together with the Italian COVID-19 Lung US database (ICLUS-DB) and shows promising performance for COVID-19 prediction.
Deep Selective Combinatorial Embedding and Consistency Regularization for Light Field Super-resolution
Sep 26, 2020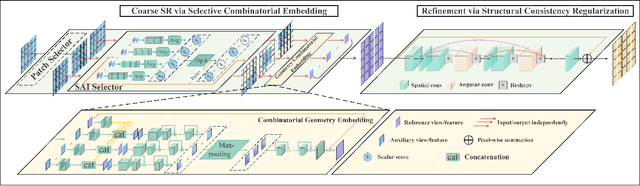
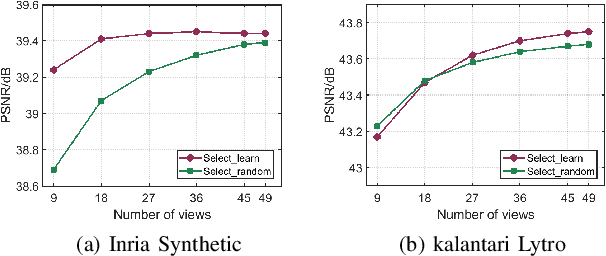
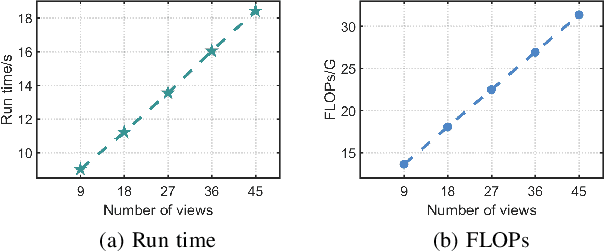
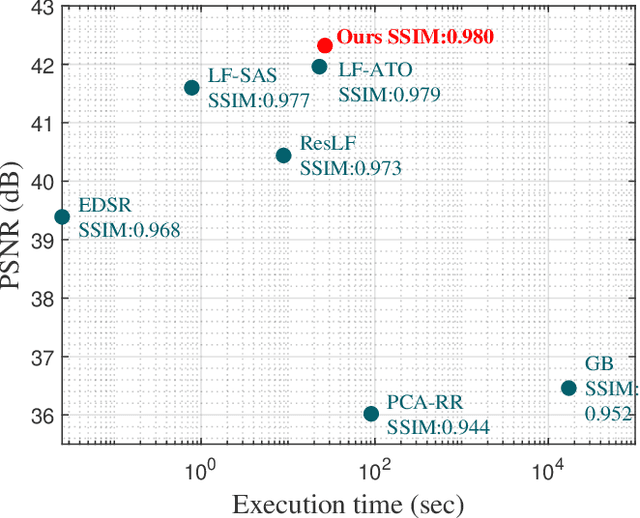
Light field (LF) images acquired by hand-held devices usually suffer from low spatial resolution as the limited detector resolution has to be shared with the angular dimension. LF spatial super-resolution (SR) thus becomes an indispensable part of the LF camera processing pipeline. The high-dimensionality characteristic and complex geometrical structure of LF images make the problem more challenging than traditional single-image SR. The performance of existing methods is still limited as they fail to thoroughly explore the coherence among LF sub-aperture images (SAIs) and are insufficient in accurately preserving the scene's parallax structure. To tackle this challenge, we propose a novel learning-based LF spatial SR framework. Specifically, each SAI of an LF image is first coarsely and individually super-resolved by exploring the complementary information among SAIs with selective combinatorial geometry embedding. To achieve efficient and effective selection of the complementary information, we propose two novel sub-modules conducted hierarchically: the patch selector provides an option of retrieving similar image patches based on offline disparity estimation to handle large-disparity correlations; and the SAI selector adaptively and flexibly selects the most informative SAIs to improve the embedding efficiency. To preserve the parallax structure among the reconstructed SAIs, we subsequently append a consistency regularization network trained over a structure-aware loss function to refine the parallax relationships over the coarse estimation. In addition, we extend the proposed method to irregular LF data. To the best of our knowledge, this is the first learning-based SR method for irregular LF data. Experimental results over both synthetic and real-world LF datasets demonstrate the significant advantage of our approach over state-of-the-art methods.
Surgical Video Motion Magnification with Suppression of Instrument Artefacts
Sep 16, 2020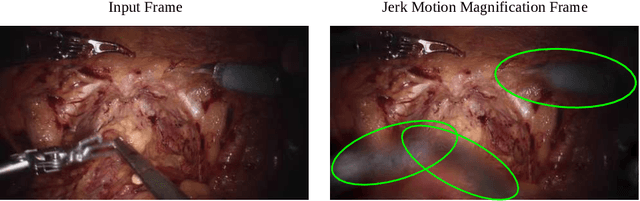
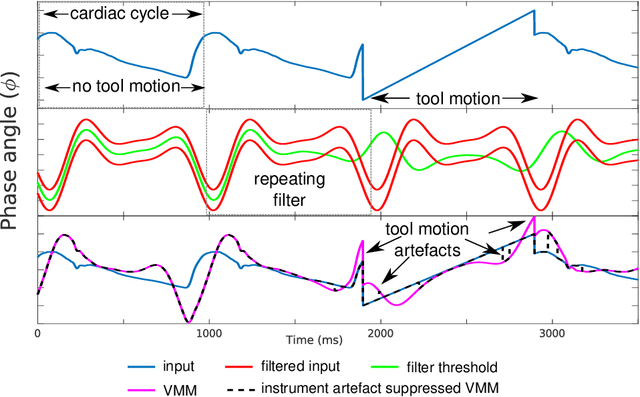
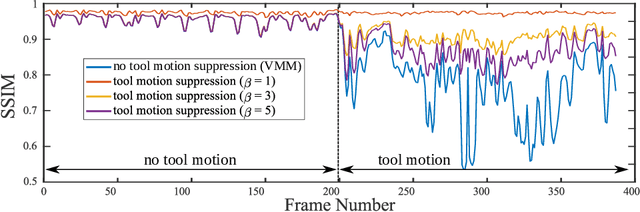
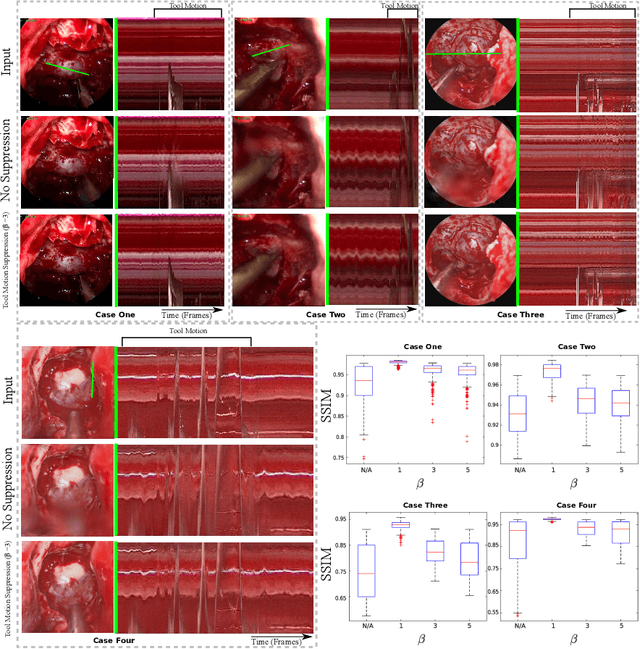
Video motion magnification could directly highlight subsurface blood vessels in endoscopic video in order to prevent inadvertent damage and bleeding. Applying motion filters to the full surgical image is however sensitive to residual motion from the surgical instruments and can impede practical application due to aberration motion artefacts. By storing the temporal filter response from local spatial frequency information for a single cardiovascular cycle prior to tool introduction to the scene, a filter can be used to determine if motion magnification should be active for a spatial region of the surgical image. In this paper, we propose a strategy to reduce aberration due to non-physiological motion for surgical video motion magnification. We present promising results on endoscopic transnasal transsphenoidal pituitary surgery with a quantitative comparison to recent methods using Structural Similarity (SSIM), as well as qualitative analysis by comparing spatio-temporal cross sections of the videos and individual frames.
Scale Optimization for Full-Image-CNN Vehicle Detection
Feb 20, 2018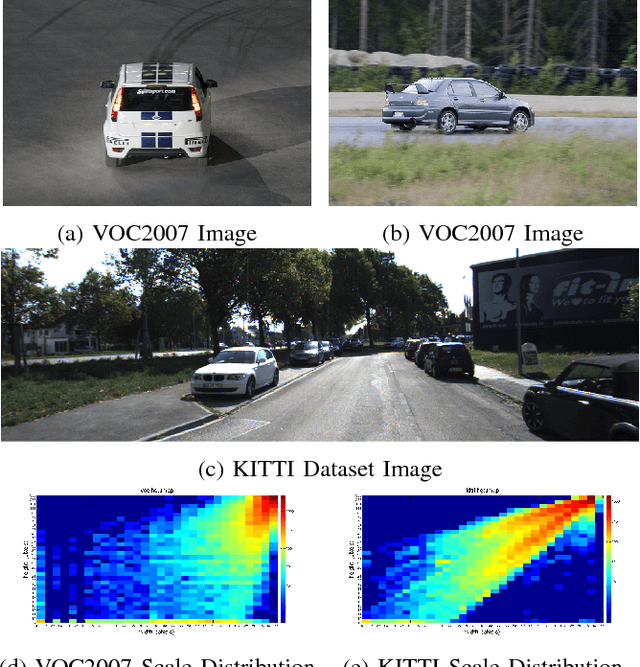
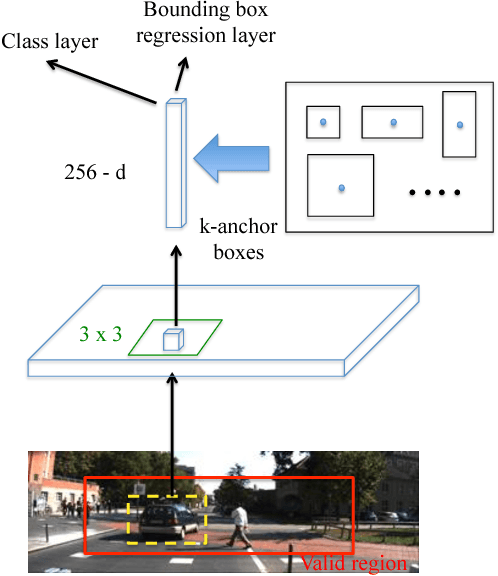
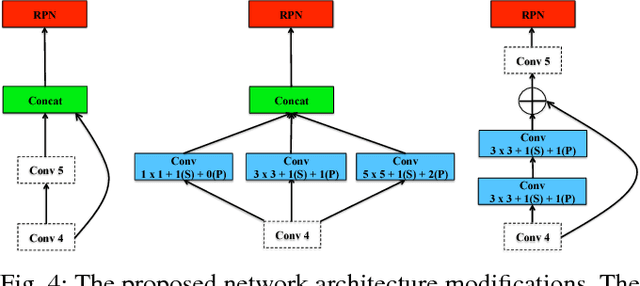
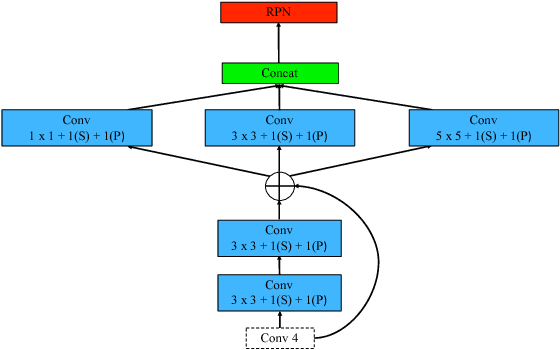
Many state-of-the-art general object detection methods make use of shared full-image convolutional features (as in Faster R-CNN). This achieves a reasonable test-phase computation time while enjoys the discriminative power provided by large Convolutional Neural Network (CNN) models. Such designs excel on benchmarks which contain natural images but which have very unnatural distributions, i.e. they have an unnaturally high-frequency of the target classes and a bias towards a "friendly" or "dominant" object scale. In this paper we present further study of the use and adaptation of the Faster R-CNN object detection method for datasets presenting natural scale distribution and unbiased real-world object frequency. In particular, we show that better alignment of the detector scale sensitivity to the extant distribution improves vehicle detection performance. We do this by modifying both the selection of Region Proposals, and through using more scale-appropriate full-image convolution features within the CNN model. By selecting better scales in the region proposal input and by combining feature maps through careful design of the convolutional neural network, we improve performance on smaller objects. We significantly increase detection AP for the KITTI dataset car class from 76.3% on our baseline Faster R-CNN detector to 83.6% in our improved detector.
AFN: Attentional Feedback Network based 3D Terrain Super-Resolution
Oct 04, 2020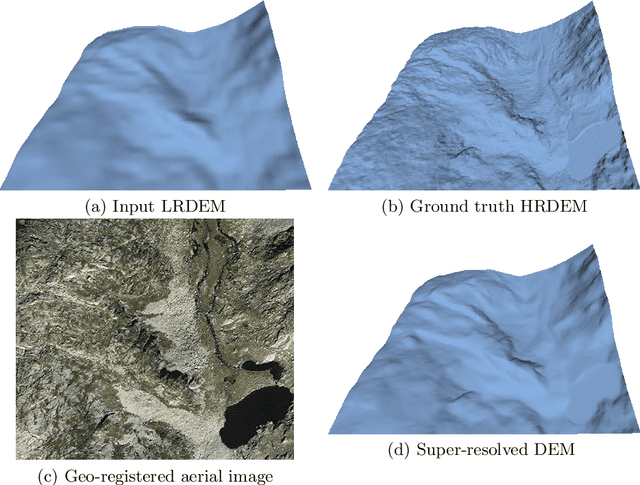
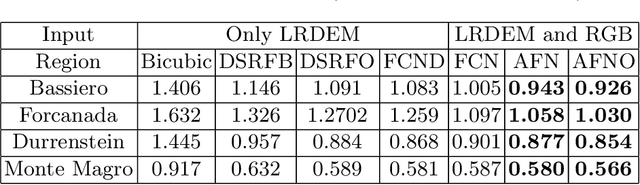
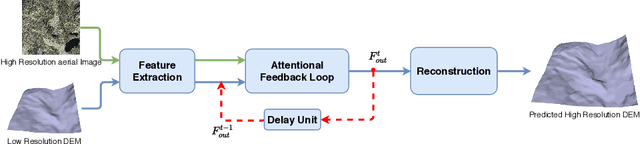
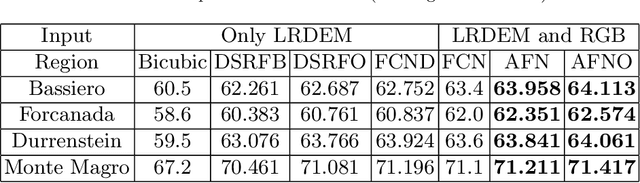
Terrain, representing features of an earth surface, plays a crucial role in many applications such as simulations, route planning, analysis of surface dynamics, computer graphics-based games, entertainment, films, to name a few. With recent advancements in digital technology, these applications demand the presence of high-resolution details in the terrain. In this paper, we propose a novel fully convolutional neural network-based super-resolution architecture to increase the resolution of low-resolution Digital Elevation Model (LRDEM) with the help of information extracted from the corresponding aerial image as a complementary modality. We perform the super-resolution of LRDEM using an attention-based feedback mechanism named 'Attentional Feedback Network' (AFN), which selectively fuses the information from LRDEM and aerial image to enhance and infuse the high-frequency features and to produce the terrain realistically. We compare the proposed architecture with existing state-of-the-art DEM super-resolution methods and show that the proposed architecture outperforms enhancing the resolution of input LRDEM accurately and in a realistic manner.
Feature space approximation for kernel-based supervised learning
Nov 25, 2020
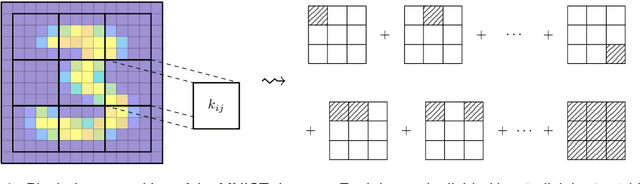
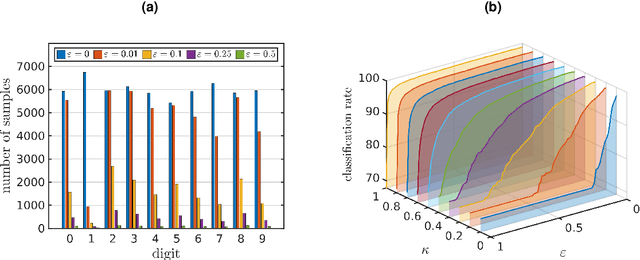
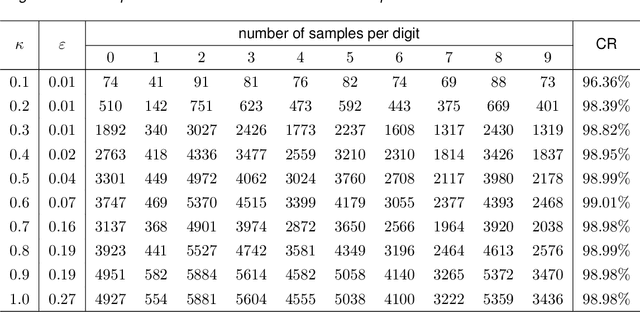
We propose a method for the approximation of high- or even infinite-dimensional feature vectors, which play an important role in supervised learning. The goal is to reduce the size of the training data, resulting in lower storage consumption and computational complexity. Furthermore, the method can be regarded as a regularization technique, which improves the generalizability of learned target functions. We demonstrate significant improvements in comparison to the computation of data-driven predictions involving the full training data set. The method is applied to classification and regression problems from different application areas such as image recognition, system identification, and oceanographic time series analysis.
LULC classification by semantic segmentation of satellite images using FastFCN
Dec 03, 2020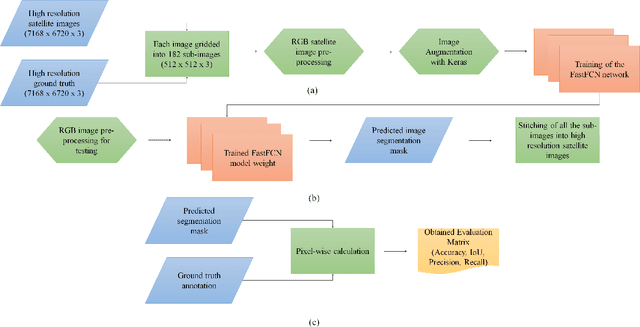
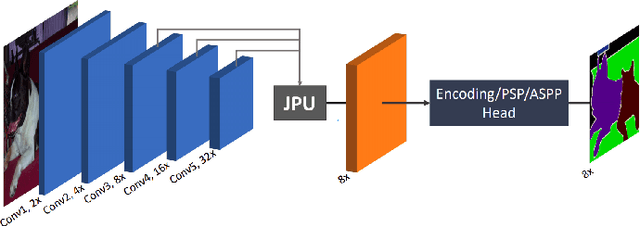

This paper analyses how well a Fast Fully Convolutional Network (FastFCN) semantically segments satellite images and thus classifies Land Use/Land Cover(LULC) classes. Fast-FCN was used on Gaofen-2 Image Dataset (GID-2) to segment them in five different classes: BuiltUp, Meadow, Farmland, Water and Forest. The results showed better accuracy (0.93), precision (0.99), recall (0.98) and mean Intersection over Union (mIoU)(0.97) than other approaches like using FCN-8 or eCognition, a readily available software. We presented a comparison between the results. We propose FastFCN to be both faster and more accurate automated method than other existing methods for LULC classification.