 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving Object Detection with Selective Self-supervised Self-training
Jul 17, 2020

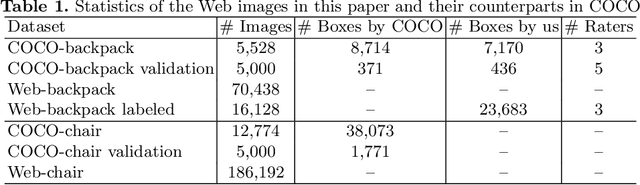

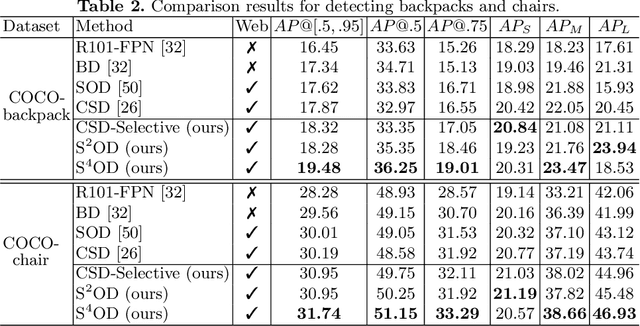
We study how to leverage Web images to augment human-curated object detection datasets. Our approach is two-pronged. On the one hand, we retrieve Web images by image-to-image search, which incurs less domain shift from the curated data than other search methods. The Web images are diverse, supplying a wide variety of object poses, appearances, their interactions with the context, etc. On the other hand, we propose a novel learning method motivated by two parallel lines of work that explore unlabeled data for image classification: self-training and self-supervised learning. They fail to improve object detectors in their vanilla forms due to the domain gap between the Web images and curated datasets. To tackle this challenge, we propose a selective net to rectify the supervision signals in Web images. It not only identifies positive bounding boxes but also creates a safe zone for mining hard negative boxes. We report state-of-the-art results on detecting backpacks and chairs from everyday scenes, along with other challenging object classes.
Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding
Nov 04, 2020
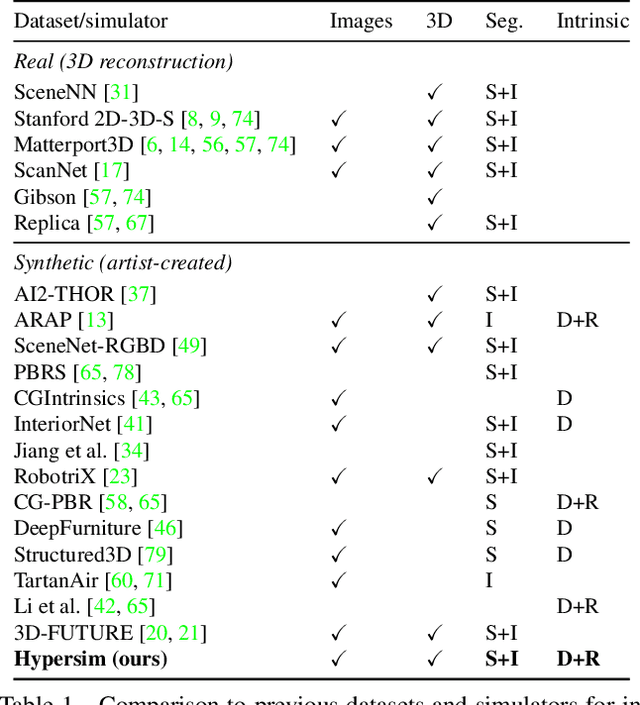
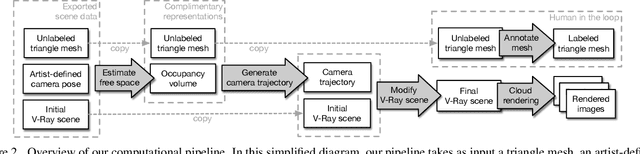

For many fundamental scene understanding tasks, it is difficult or impossible to obtain per-pixel ground truth labels from real images. We address this challenge by introducing Hypersim, a photorealistic synthetic dataset for holistic indoor scene understanding. To create our dataset, we leverage a large repository of synthetic scenes created by professional artists, and we generate 77,400 images of 461 indoor scenes with detailed per-pixel labels and corresponding ground truth geometry. Our dataset: (1) relies exclusively on publicly available 3D assets; (2) includes complete scene geometry, material information, and lighting information for every scene; (3) includes dense per-pixel semantic instance segmentations for every image; and (4) factors every image into diffuse reflectance, diffuse illumination, and a non-diffuse residual term that captures view-dependent lighting effects. Together, these features make our dataset well-suited for geometric learning problems that require direct 3D supervision, multi-task learning problems that require reasoning jointly over multiple input and output modalities, and inverse rendering problems. We analyze our dataset at the level of scenes, objects, and pixels, and we analyze costs in terms of money, annotation effort, and computation time. Remarkably, we find that it is possible to generate our entire dataset from scratch, for roughly half the cost of training a state-of-the-art natural language processing model. All the code we used to generate our dataset will be made available online.
PCB Defect Detection Using Denoising Convolutional Autoencoders
Aug 28, 2020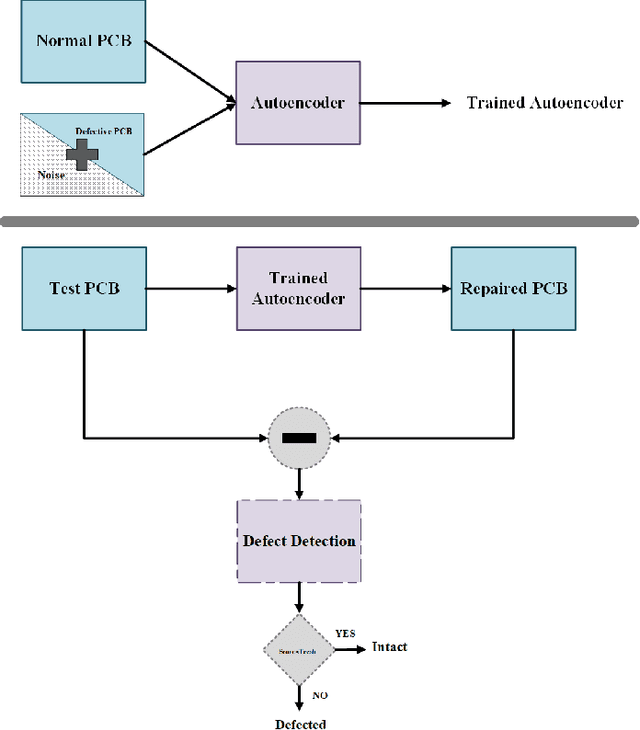
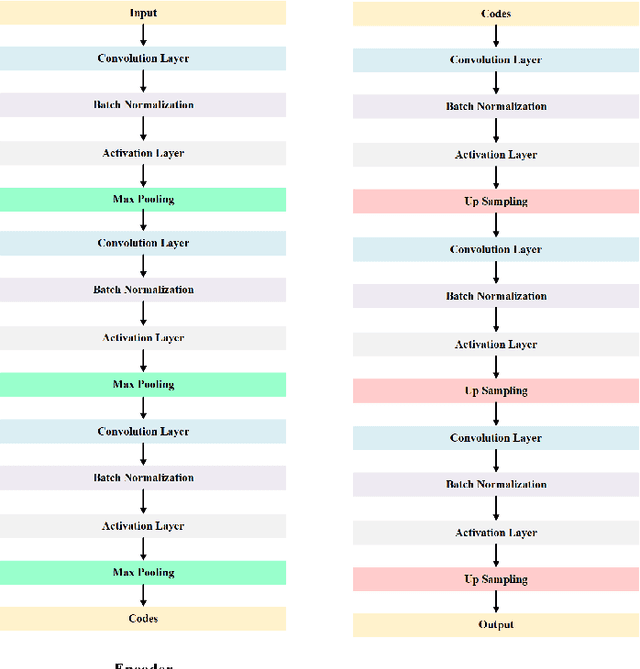

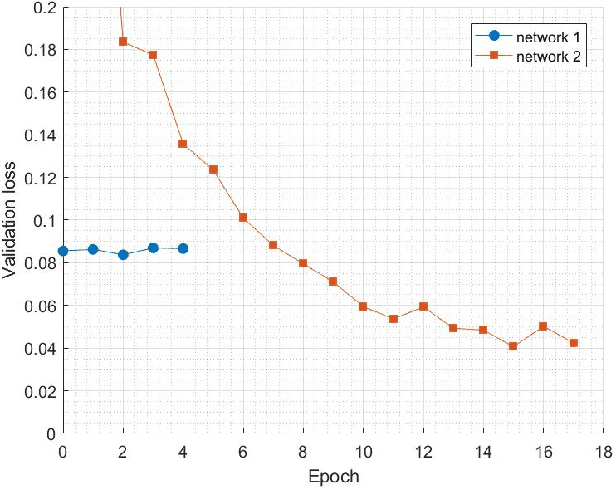
Printed Circuit boards (PCBs) are one of the most important stages in making electronic products. A small defect in PCBs can cause significant flaws in the final product. Hence, detecting all defects in PCBs and locating them is essential. In this paper, we propose an approach based on denoising convolutional autoencoders for detecting defective PCBs and to locate the defects. Denoising autoencoders take a corrupted image and try to recover the intact image. We trained our model with defective PCBs and forced it to repair the defective parts. Our model not only detects all kinds of defects and locates them, but it can also repair them as well. By subtracting the repaired output from the input, the defective parts are located. The experimental results indicate that our model detects the defective PCBs with high accuracy (97.5%) compare to state of the art works.
Post-hoc Overall Survival Time Prediction from Brain MRI
Feb 22, 2021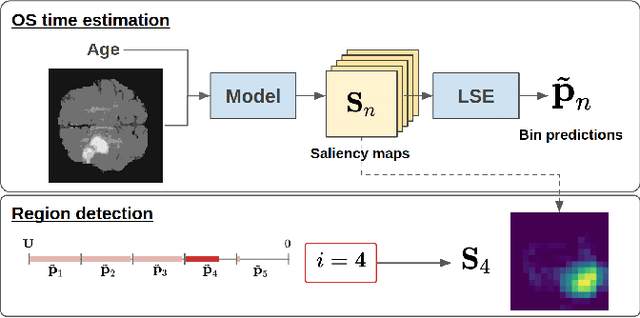
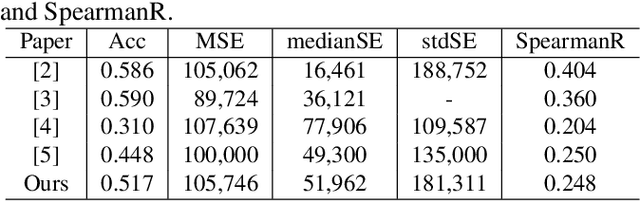
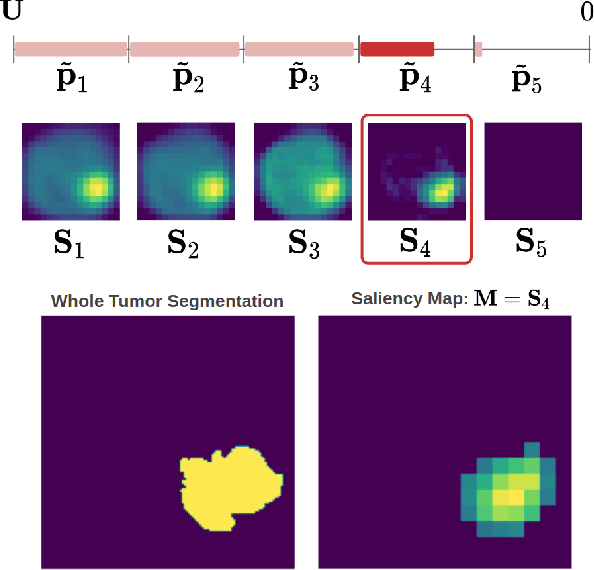
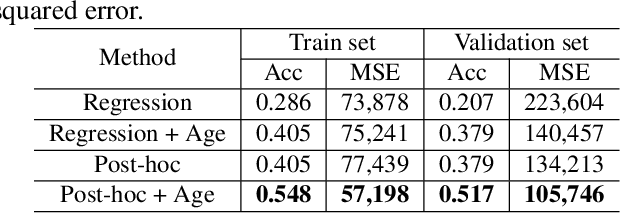
Overall survival (OS) time prediction is one of the most common estimates of the prognosis of gliomas and is used to design an appropriate treatment planning. State-of-the-art (SOTA) methods for OS time prediction follow a pre-hoc approach that require computing the segmentation map of the glioma tumor sub-regions (necrotic, edema tumor, enhancing tumor) for estimating OS time. However, the training of the segmentation methods require ground truth segmentation labels which are tedious and expensive to obtain. Given that most of the large-scale data sets available from hospitals are unlikely to contain such precise segmentation, those SOTA methods have limited applicability. In this paper, we introduce a new post-hoc method for OS time prediction that does not require segmentation map annotation for training. Our model uses medical image and patient demographics (represented by age) as inputs to estimate the OS time and to estimate a saliency map that localizes the tumor as a way to explain the OS time prediction in a post-hoc manner. It is worth emphasizing that although our model can localize tumors, it uses only the ground truth OS time as training signal, i.e., no segmentation labels are needed. We evaluate our post-hoc method on the Multimodal Brain Tumor Segmentation Challenge (BraTS) 2019 data set and show that it achieves competitive results compared to pre-hoc methods with the advantage of not requiring segmentation labels for training.
Patch-based Texture Synthesis for Image Inpainting
May 05, 2016
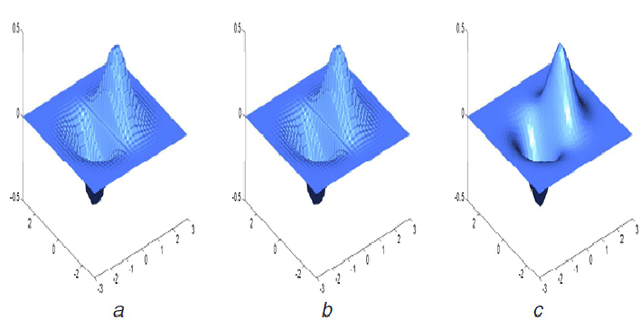

Image inpaiting is an important task in image processing and vision. In this paper, we develop a general method for patch-based image inpainting by synthesizing new textures from existing one. A novel framework is introduced to find several optimal candidate patches and generate a new texture patch in the process. We form it as an optimization problem that identifies the potential patches for synthesis from an coarse-to-fine manner. We use the texture descriptor as a clue in searching for matching patches from the known region. To ensure the structure faithful to the original image, a geometric constraint metric is formally defined that is applied directly to the patch synthesis procedure. We extensively conducted our experiments on a wide range of testing images on various scenarios and contents by arbitrarily specifying the target the regions for inference followed by using existing evaluation metrics to verify its texture coherency and structural consistency. Our results demonstrate the high accuracy and desirable output that can be potentially used for numerous applications: object removal, background subtraction, and image retrieval.
DLBCL-Morph: Morphological features computed using deep learning for an annotated digital DLBCL image set
Sep 17, 2020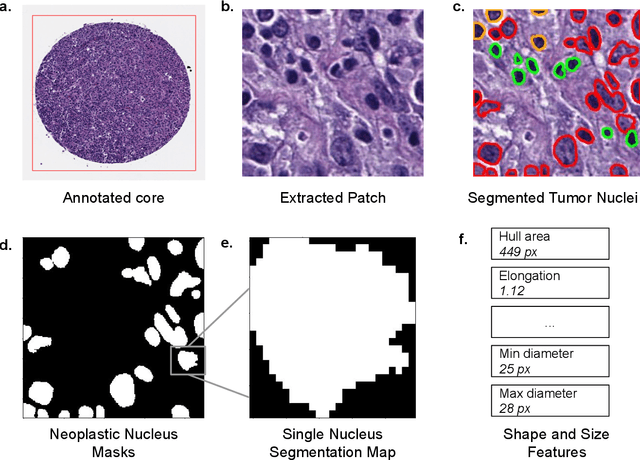
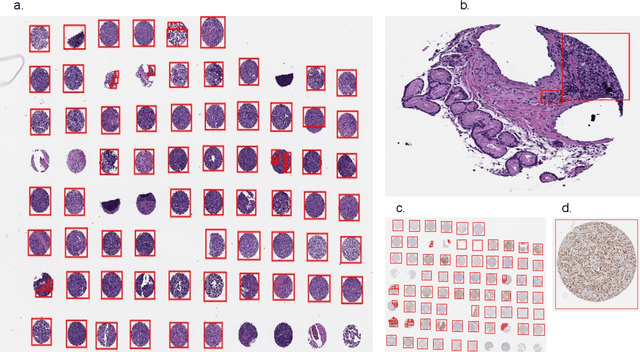
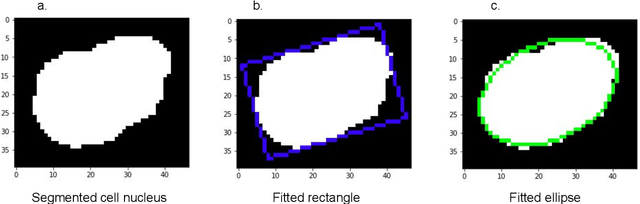
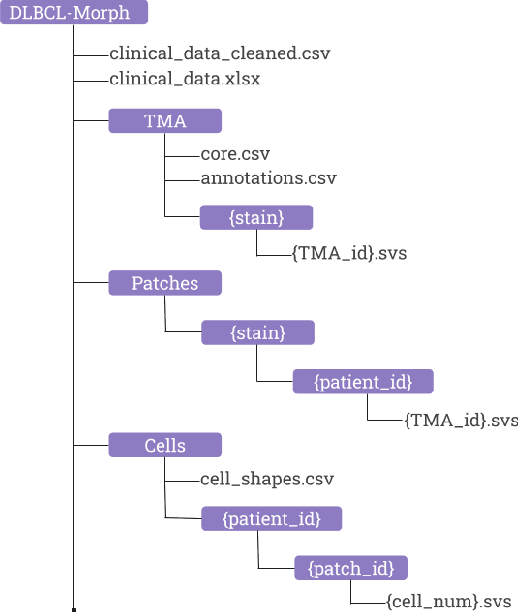
Diffuse Large B-Cell Lymphoma (DLBCL) is the most common non-Hodgkin lymphoma. Though histologically DLBCL shows varying morphologies, no morphologic features have been consistently demonstrated to correlate with prognosis. We present a morphologic analysis of histology sections from 209 DLBCL cases with associated clinical and cytogenetic data. Duplicate tissue core sections were arranged in tissue microarrays (TMAs), and replicate sections were stained with H&E and immunohistochemical stains for CD10, BCL6, MUM1, BCL2, and MYC. The TMAs are accompanied by pathologist-annotated regions-of-interest (ROIs) that identify areas of tissue representative of DLBCL. We used a deep learning model to segment all tumor nuclei in the ROIs, and computed several geometric features for each segmented nucleus. We fit a Cox proportional hazards model to demonstrate the utility of these geometric features in predicting survival outcome, and found that it achieved a C-index (95% CI) of 0.635 (0.574,0.691). Our finding suggests that geometric features computed from tumor nuclei are of prognostic importance, and should be validated in prospective studies.
Randomized RX for target detection
Dec 08, 2020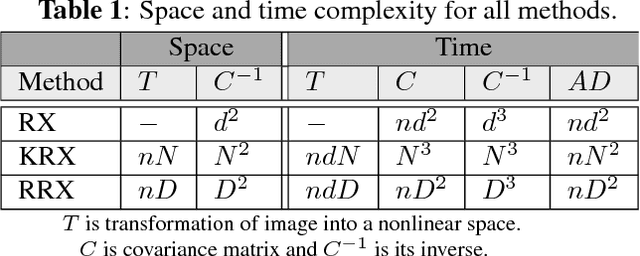
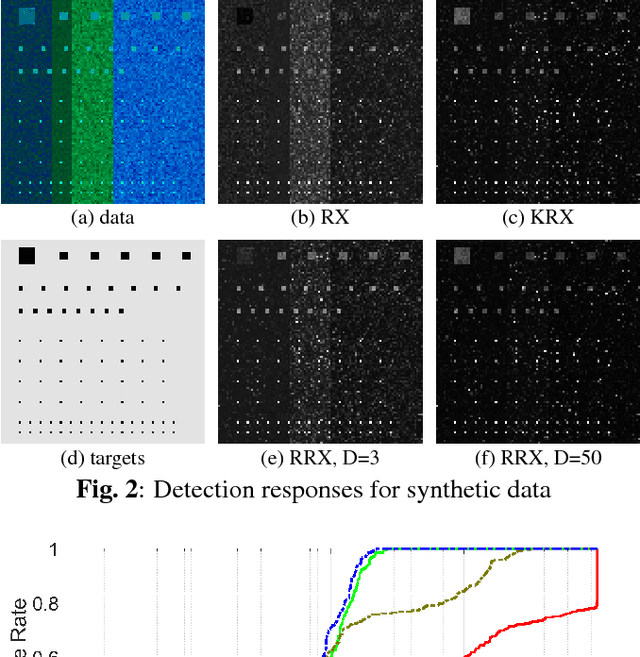
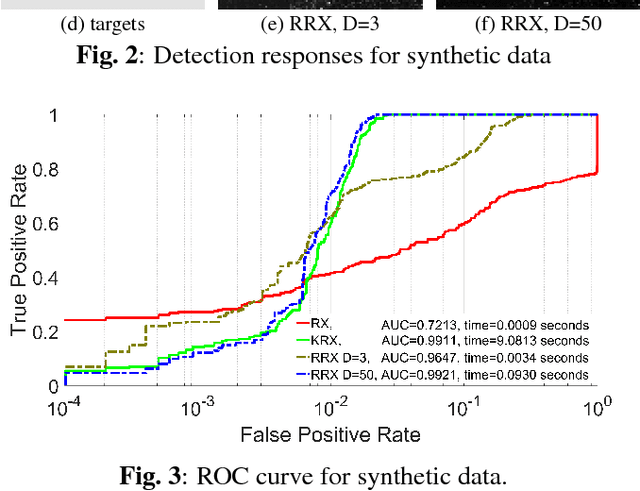
This work tackles the target detection problem through the well-known global RX method. The RX method models the clutter as a multivariate Gaussian distribution, and has been extended to nonlinear distributions using kernel methods. While the kernel RX can cope with complex clutters, it requires a considerable amount of computational resources as the number of clutter pixels gets larger. Here we propose random Fourier features to approximate the Gaussian kernel in kernel RX and consequently our development keep the accuracy of the nonlinearity while reducing the computational cost which is now controlled by an hyperparameter. Results over both synthetic and real-world image target detection problems show space and time efficiency of the proposed method while providing high detection performance.
On Baselines for Local Feature Attributions
Jan 04, 2021
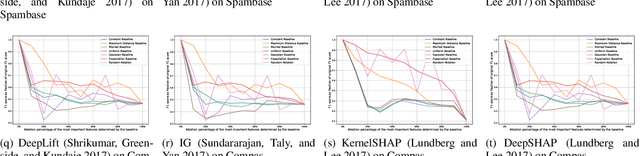

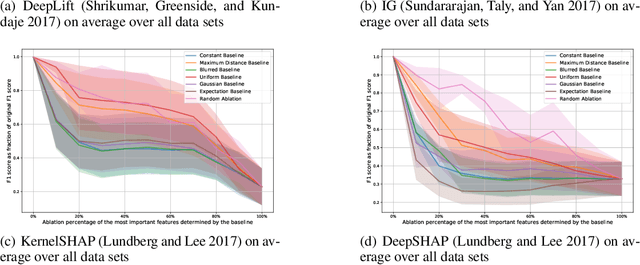
High-performing predictive models, such as neural nets, usually operate as black boxes, which raises serious concerns about their interpretability. Local feature attribution methods help to explain black box models and are therefore a powerful tool for assessing the reliability and fairness of predictions. To this end, most attribution models compare the importance of input features with a reference value, often called baseline. Recent studies show that the baseline can heavily impact the quality of feature attributions. Yet, we frequently find simplistic baselines, such as the zero vector, in practice. In this paper, we show empirically that baselines can significantly alter the discriminative power of feature attributions. We conduct our analysis on tabular data sets, thus complementing recent works on image data. Besides, we propose a new taxonomy of baseline methods. Our experimental study illustrates the sensitivity of popular attribution models to the baseline, thus laying the foundation for a more in-depth discussion on sensible baseline methods for tabular data.
Building Emotional Machines: Recognizing Image Emotions through Deep Neural Networks
Jul 03, 2017
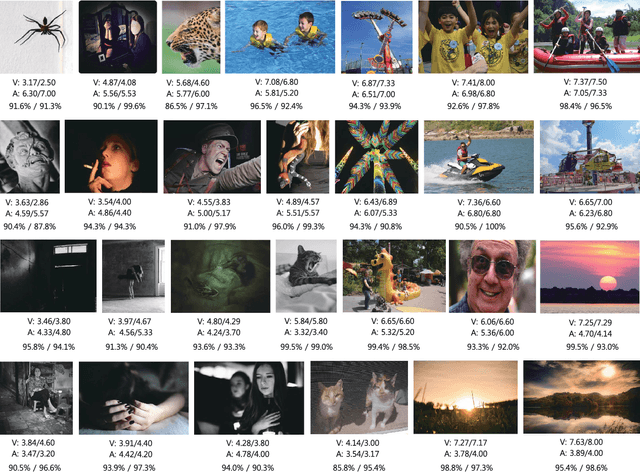


An image is a very effective tool for conveying emotions. Many researchers have investigated in computing the image emotions by using various features extracted from images. In this paper, we focus on two high level features, the object and the background, and assume that the semantic information of images is a good cue for predicting emotion. An object is one of the most important elements that define an image, and we find out through experiments that there is a high correlation between the object and the emotion in images. Even with the same object, there may be slight difference in emotion due to different backgrounds, and we use the semantic information of the background to improve the prediction performance. By combining the different levels of features, we build an emotion based feed forward deep neural network which produces the emotion values of a given image. The output emotion values in our framework are continuous values in the 2-dimensional space (Valence and Arousal), which are more effective than using a few number of emotion categories in describing emotions. Experiments confirm the effectiveness of our network in predicting the emotion of images.
Joint Generative Learning and Super-Resolution For Real-World Camera-Screen Degradation
Sep 14, 2020



In real-world single image super-resolution (SISR) task, the low-resolution image suffers more complicated degradations, not only downsampled by unknown kernels. However, existing SISR methods are generally studied with the synthetic low-resolution generation such as bicubic interpolation (BI), which greatly limits their performance. Recently, some researchers investigate real-world SISR from the perspective of the camera and smartphone. However, except the acquisition equipment, the display device also involves more complicated degradations. In this paper, we focus on the camera-screen degradation and build a real-world dataset (Cam-ScreenSR), where HR images are original ground truths from the previous DIV2K dataset and corresponding LR images are camera-captured versions of HRs displayed on the screen. We conduct extensive experiments to demonstrate that involving more real degradations is positive to improve the generalization of SISR models. Moreover, we propose a joint two-stage model. Firstly, the downsampling degradation GAN(DD-GAN) is trained to model the degradation and produces more various of LR images, which is validated to be efficient for data augmentation. Then the dual residual channel attention network (DuRCAN) learns to recover the SR image. The weighted combination of L1 loss and proposed Laplacian loss are applied to sharpen the high-frequency edges. Extensive experimental results in both typical synthetic and complicated real-world degradations validate the proposed method outperforms than existing SOTA models with less parameters, faster speed and better visual results. Moreover, in real captured photographs, our model also delivers best visual quality with sharper edge, less artifacts, especially appropriate color enhancement, which has not been accomplished by previous methods.