 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Layer-Wise Information Reinforcement Approach to Improve Learning in Deep Belief Networks
Jan 17, 2021
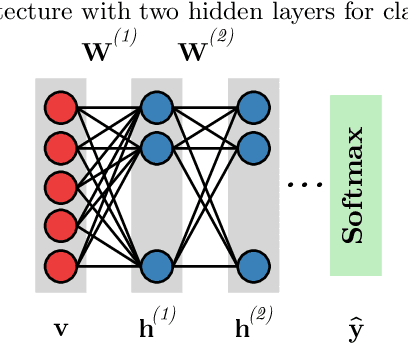

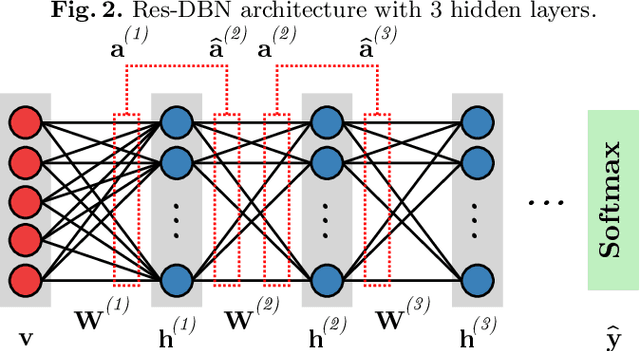
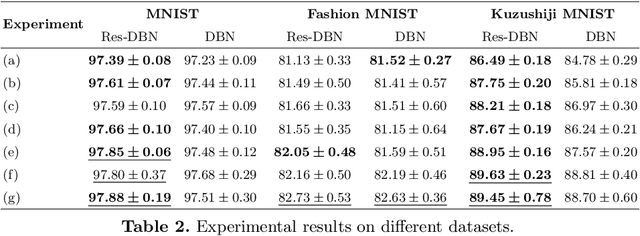
With the advent of deep learning, the number of works proposing new methods or improving existent ones has grown exponentially in the last years. In this scenario, "very deep" models were emerging, once they were expected to extract more intrinsic and abstract features while supporting a better performance. However, such models suffer from the gradient vanishing problem, i.e., backpropagation values become too close to zero in their shallower layers, ultimately causing learning to stagnate. Such an issue was overcome in the context of convolution neural networks by creating "shortcut connections" between layers, in a so-called deep residual learning framework. Nonetheless, a very popular deep learning technique called Deep Belief Network still suffers from gradient vanishing when dealing with discriminative tasks. Therefore, this paper proposes the Residual Deep Belief Network, which considers the information reinforcement layer-by-layer to improve the feature extraction and knowledge retaining, that support better discriminative performance. Experiments conducted over three public datasets demonstrate its robustness concerning the task of binary image classification.
How Faithful is your Synthetic Data? Sample-level Metrics for Evaluating and Auditing Generative Models
Feb 17, 2021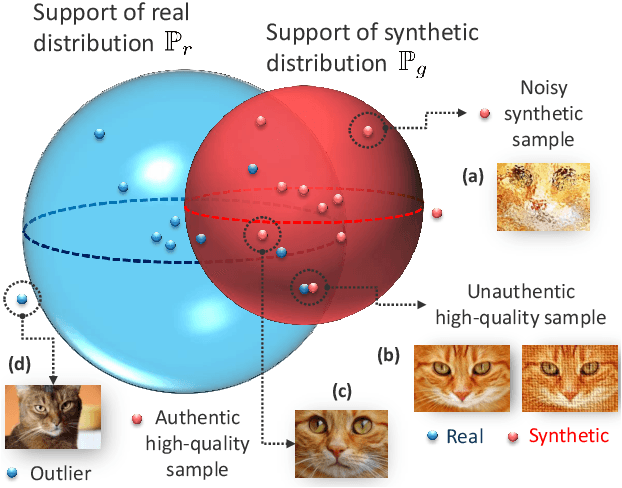

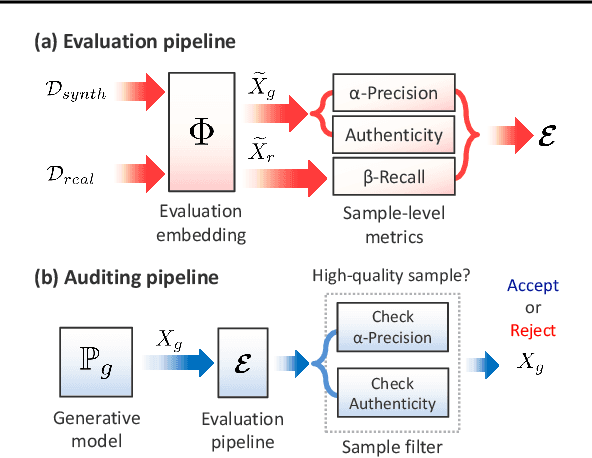
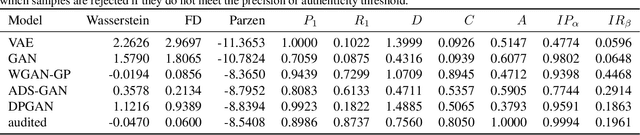
Devising domain- and model-agnostic evaluation metrics for generative models is an important and as yet unresolved problem. Most existing metrics, which were tailored solely to the image synthesis setup, exhibit a limited capacity for diagnosing the different modes of failure of generative models across broader application domains. In this paper, we introduce a 3-dimensional evaluation metric, ($\alpha$-Precision, $\beta$-Recall, Authenticity), that characterizes the fidelity, diversity and generalization performance of any generative model in a domain-agnostic fashion. Our metric unifies statistical divergence measures with precision-recall analysis, enabling sample- and distribution-level diagnoses of model fidelity and diversity. We introduce generalization as an additional, independent dimension (to the fidelity-diversity trade-off) that quantifies the extent to which a model copies training data -- a crucial performance indicator when modeling sensitive data with requirements on privacy. The three metric components correspond to (interpretable) probabilistic quantities, and are estimated via sample-level binary classification. The sample-level nature of our metric inspires a novel use case which we call model auditing, wherein we judge the quality of individual samples generated by a (black-box) model, discarding low-quality samples and hence improving the overall model performance in a post-hoc manner.
Generative Visual Manipulation on the Natural Image Manifold
Sep 25, 2016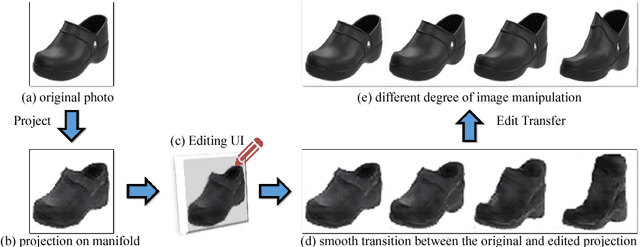



Realistic image manipulation is challenging because it requires modifying the image appearance in a user-controlled way, while preserving the realism of the result. Unless the user has considerable artistic skill, it is easy to "fall off" the manifold of natural images while editing. In this paper, we propose to learn the natural image manifold directly from data using a generative adversarial neural network. We then define a class of image editing operations, and constrain their output to lie on that learned manifold at all times. The model automatically adjusts the output keeping all edits as realistic as possible. All our manipulations are expressed in terms of constrained optimization and are applied in near-real time. We evaluate our algorithm on the task of realistic photo manipulation of shape and color. The presented method can further be used for changing one image to look like the other, as well as generating novel imagery from scratch based on user's scribbles.
Deep learning for scene recognition from visual data: a survey
Jul 03, 2020
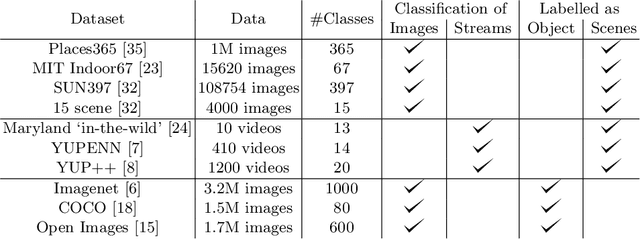
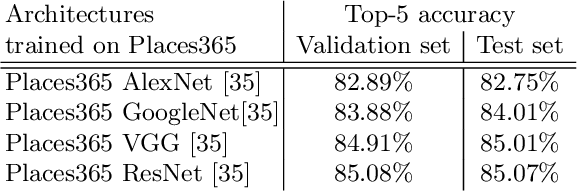
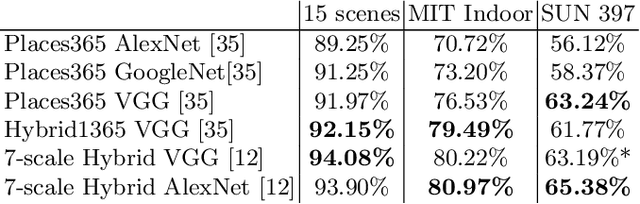
The use of deep learning techniques has exploded during the last few years, resulting in a direct contribution to the field of artificial intelligence. This work aims to be a review of the state-of-the-art in scene recognition with deep learning models from visual data. Scene recognition is still an emerging field in computer vision, which has been addressed from a single image and dynamic image perspective. We first give an overview of available datasets for image and video scene recognition. Later, we describe ensemble techniques introduced by research papers in the field. Finally, we give some remarks on our findings and discuss what we consider challenges in the field and future lines of research. This paper aims to be a future guide for model selection for the task of scene recognition.
Efficient Subsampling for Generating High-Quality Images from Conditional Generative Adversarial Networks
Mar 20, 2021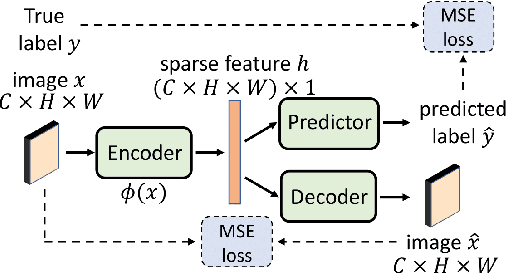
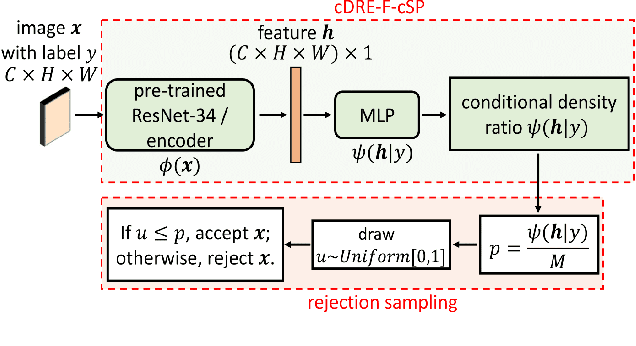
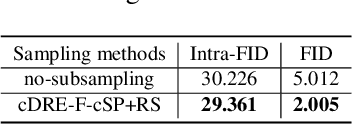
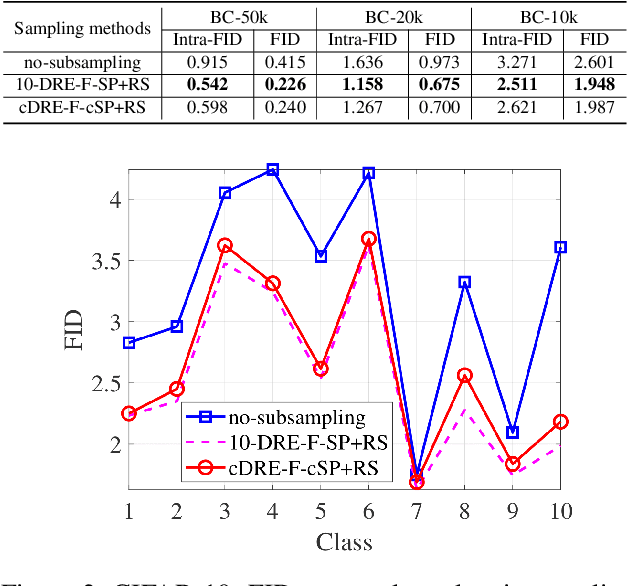
Subsampling unconditional generative adversarial networks (GANs) to improve the overall image quality has been studied recently. However, these methods often require high training costs (e.g., storage space, parameter tuning) and may be inefficient or even inapplicable for subsampling conditional GANs, such as class-conditional GANs and continuous conditional GANs (CcGANs), when the condition has many distinct values. In this paper, we propose an efficient method called conditional density ratio estimation in feature space with conditional Softplus loss (cDRE-F-cSP). With cDRE-F-cSP, we estimate an image's conditional density ratio based on a novel conditional Softplus (cSP) loss in the feature space learned by a specially designed ResNet-34 or sparse autoencoder. We then derive the error bound of a conditional density ratio model trained with the proposed cSP loss. Finally, we propose a rejection sampling scheme, termed cDRE-F-cSP+RS, which can subsample both class-conditional GANs and CcGANs efficiently. An extra filtering scheme is also developed for CcGANs to increase the label consistency. Experiments on CIFAR-10 and Tiny-ImageNet datasets show that cDRE-F-cSP+RS can substantially improve the Intra-FID and FID scores of BigGAN. Experiments on RC-49 and UTKFace datasets demonstrate that cDRE-F-cSP+RS also improves Intra-FID, Diversity, and Label Score of CcGANs. Moreover, to show the high efficiency of cDRE-F-cSP+RS, we compare it with the state-of-the-art unconditional subsampling method (i.e., DRE-F-SP+RS). With comparable or even better performance, cDRE-F-cSP+RS only requires about \textbf{10}\% and \textbf{1.7}\% of the training costs spent respectively on CIFAR-10 and UTKFace by DRE-F-SP+RS.
ClassSR: A General Framework to Accelerate Super-Resolution Networks by Data Characteristic
Mar 06, 2021
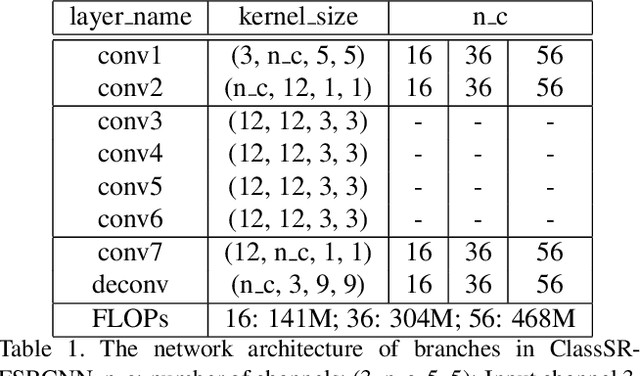
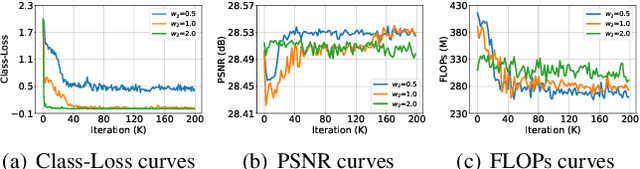
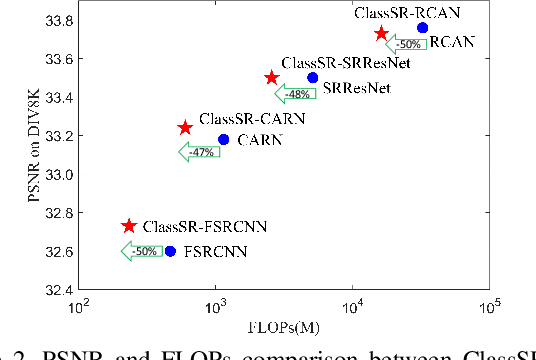
We aim at accelerating super-resolution (SR) networks on large images (2K-8K). The large images are usually decomposed into small sub-images in practical usages. Based on this processing, we found that different image regions have different restoration difficulties and can be processed by networks with different capacities. Intuitively, smooth areas are easier to super-solve than complex textures. To utilize this property, we can adopt appropriate SR networks to process different sub-images after the decomposition. On this basis, we propose a new solution pipeline -- ClassSR that combines classification and SR in a unified framework. In particular, it first uses a Class-Module to classify the sub-images into different classes according to restoration difficulties, then applies an SR-Module to perform SR for different classes. The Class-Module is a conventional classification network, while the SR-Module is a network container that consists of the to-be-accelerated SR network and its simplified versions. We further introduce a new classification method with two losses -- Class-Loss and Average-Loss to produce the classification results. After joint training, a majority of sub-images will pass through smaller networks, thus the computational cost can be significantly reduced. Experiments show that our ClassSR can help most existing methods (e.g., FSRCNN, CARN, SRResNet, RCAN) save up to 50% FLOPs on DIV8K datasets. This general framework can also be applied in other low-level vision tasks.
Robust and Natural Physical Adversarial Examples for Object Detectors
Nov 27, 2020Recently, many studies show that deep neural networks (DNNs) are susceptible to adversarial examples. However, in order to convince that adversarial examples are real threats in real physical world, it is necessary to study and evaluate the adversarial examples in real-world scenarios. In this paper, we propose a robust and natural physical adversarial example attack method targeting object detectors under real-world conditions, which is more challenging than targeting image classifiers. The generated adversarial examples are robust to various physical constraints and visually look similar to the original images, thus these adversarial examples are natural to humans and will not cause any suspicions. First, to ensure the robustness of the adversarial examples in real-world conditions, the proposed method exploits different image transformation functions (Distance, Angle, Illumination, Printing and Photographing), to simulate various physical changes during the iterative optimization of the adversarial examples generation. Second, to construct natural adversarial examples, the proposed method uses an adaptive mask to constrain the area and intensities of added perturbations, and utilizes the real-world perturbation score (RPS) to make the perturbations be similar to those real noises in physical world. Compared with existing studies, our generated adversarial examples can achieve a high success rate with less conspicuous perturbations. Experimental results demonstrate that, the generated adversarial examples are robust under various indoor and outdoor physical conditions. Finally, the proposed physical adversarial attack method is universal and can work in black-box scenarios. The generated adversarial examples generalize well between different models.
Keep it Simple: Data-efficient Learning for Controlling Complex Systems with Simple Models
Feb 17, 2021
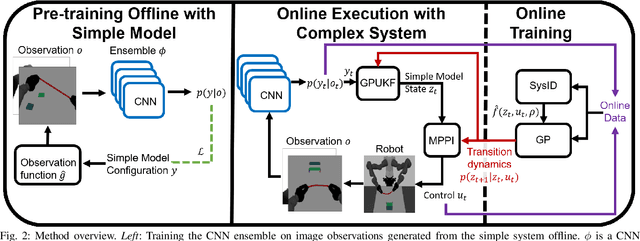


When manipulating a novel object with complex dynamics, a state representation is not always available, for example for deformable objects. Learning both a representation and dynamics from observations requires large amounts of data. We propose Learned Visual Similarity Predictive Control (LVSPC), a novel method for data-efficient learning to control systems with complex dynamics and high-dimensional state spaces from images. LVSPC leverages a given simple model approximation from which image observations can be generated. We use these images to train a perception model that estimates the simple model state from observations of the complex system online. We then use data from the complex system to fit the parameters of the simple model and learn where this model is inaccurate, also online. Finally, we use Model Predictive Control and bias the controller away from regions where the simple model is inaccurate and thus where the controller is less reliable. We evaluate LVSPC on two tasks; manipulating a tethered mass and a rope. We find that our method performs comparably to state-of-the-art reinforcement learning methods with an order of magnitude less data. LVSPC also completes the rope manipulation task on a real robot with 80% success rate after only 10 trials, despite using a perception system trained only on images from simulation.
Locally orderless tensor networks for classifying two- and three-dimensional medical images
Sep 25, 2020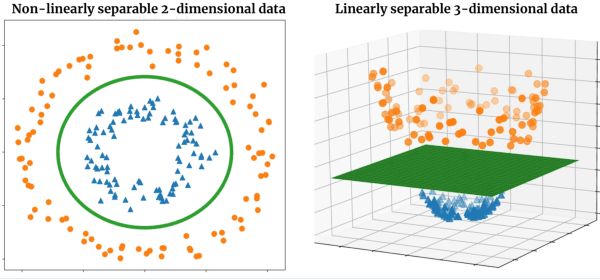

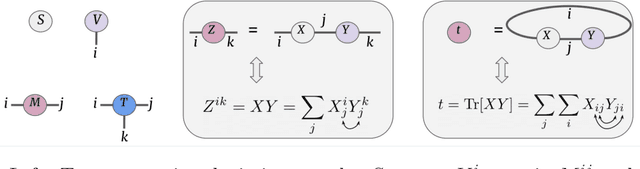
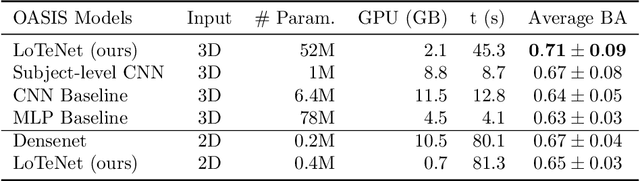
Tensor networks are factorisations of high rank tensors into networks of lower rank tensors and have primarily been used to analyse quantum many-body problems. Tensor networks have seen a recent surge of interest in relation to supervised learning tasks with a focus on image classification. In this work, we improve upon the matrix product state (MPS) tensor networks that can operate on one-dimensional vectors to be useful for working with 2D and 3D medical images. We treat small image regions as orderless, squeeze their spatial information into feature dimensions and then perform MPS operations on these locally orderless regions. These local representations are then aggregated in a hierarchical manner to retain global structure. The proposed locally orderless tensor network (LoTeNet) is compared with relevant methods on three datasets. The architecture of LoTeNet is fixed in all experiments and we show it requires lesser computational resources to attain performance on par or superior to the compared methods.
CrossStack: A 3-D Reconfigurable RRAM Crossbar Inference Engine
Feb 07, 2021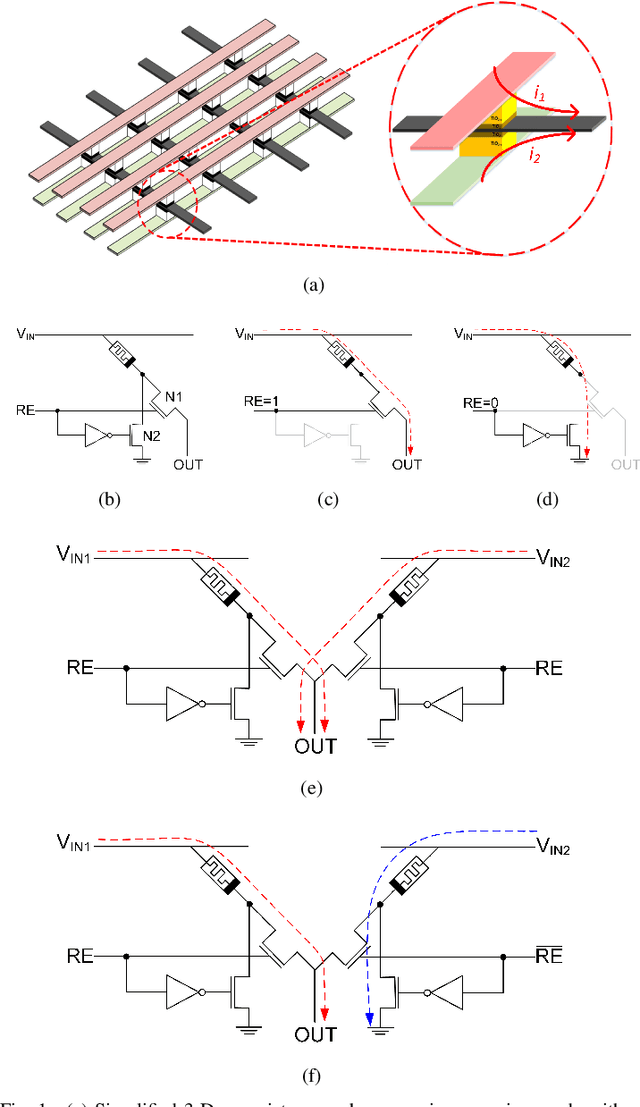

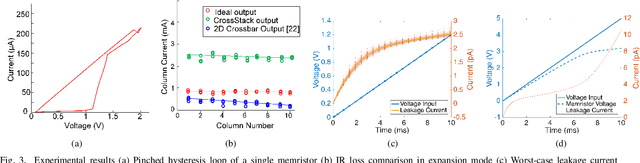
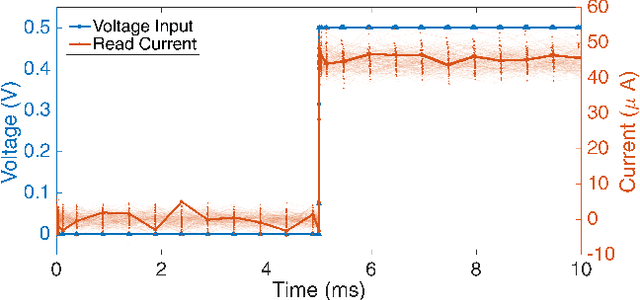
Deep neural network inference accelerators are rapidly growing in importance as we turn to massively parallelized processing beyond GPUs and ASICs. The dominant operation in feedforward inference is the multiply-and-accumlate process, where each column in a crossbar generates the current response of a single neuron. As a result, memristor crossbar arrays parallelize inference and image processing tasks very efficiently. In this brief, we present a 3-D active memristor crossbar array `CrossStack', which adopts stacked pairs of Al/TiO2/TiO2-x/Al devices with common middle electrodes. By designing CMOS-memristor hybrid cells used in the layout of the array, CrossStack can operate in one of two user-configurable modes as a reconfigurable inference engine: 1) expansion mode and 2) deep-net mode. In expansion mode, the resolution of the network is doubled by increasing the number of inputs for a given chip area, reducing IR drop by 22%. In deep-net mode, inference speed per-10-bit convolution is improved by 29\% by simultaneously using one TiO2/TiO2-x layer for read processes, and the other for write processes. We experimentally verify both modes on our $10\times10\times2$ array.