 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Leveraging Disease Progression Learning for Medical Image Recognition
Sep 01, 2018
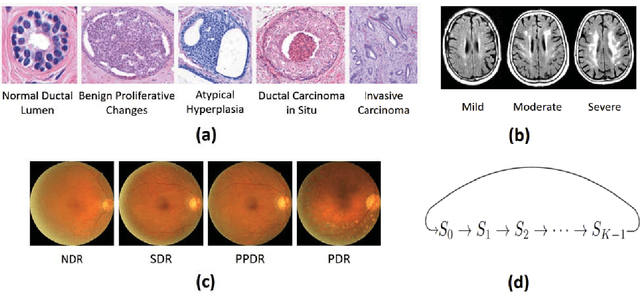
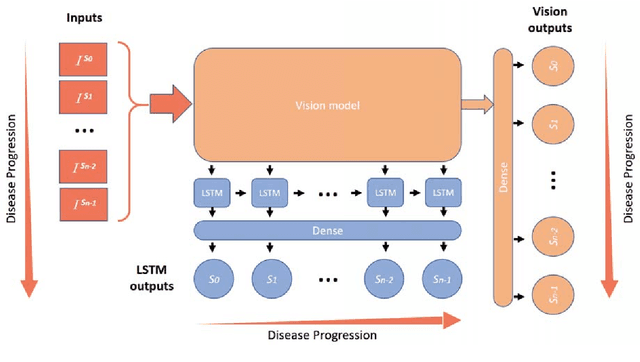
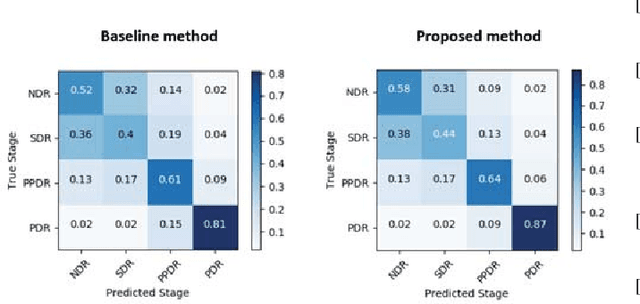

Unlike natural images, medical images often have intrinsic characteristics that can be leveraged for neural network learning. For example, images that belong to different stages of a disease may continuously follow a certain progression pattern. In this paper, we propose a novel method that leverages disease progression learning for medical image recognition. In our method, sequences of images ordered by disease stages are learned by a neural network that consists of a shared vision model for feature extraction and a long short-term memory network for the learning of stage sequences. Auxiliary vision outputs are also included to capture stage features that tend to be discrete along the disease progression. Our proposed method is evaluated on a public diabetic retinopathy dataset, and achieves about 3.3% improvement in disease staging accuracy, compared to the baseline method that does not use disease progression learning.
Nonlinear Prediction of Multidimensional Signals via Deep Regression with Applications to Image Coding
Oct 30, 2018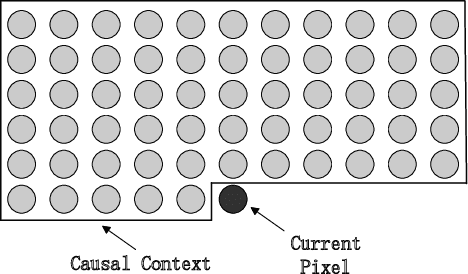
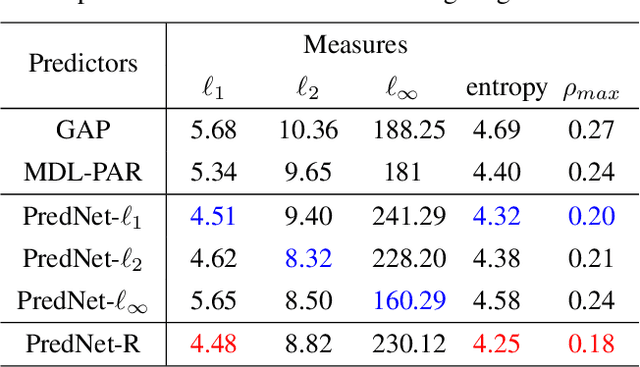
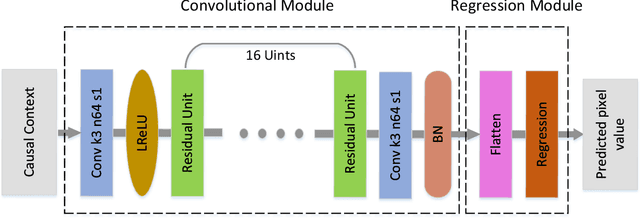
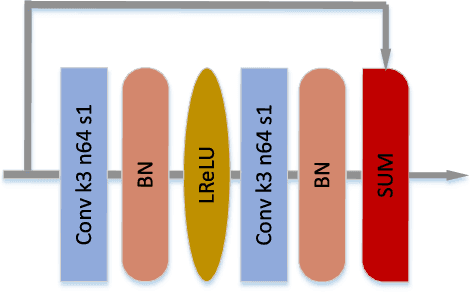
Deep convolutional neural networks (DCNN) have enjoyed great successes in many signal processing applications because they can learn complex, non-linear causal relationships from input to output. In this light, DCNNs are well suited for the task of sequential prediction of multidimensional signals, such as images, and have the potential of improving the performance of traditional linear predictors. In this research we investigate how far DCNNs can push the envelop in terms of prediction precision. We propose, in a case study, a two-stage deep regression DCNN framework for nonlinear prediction of two-dimensional image signals. In the first-stage regression, the proposed deep prediction network (PredNet) takes the causal context as input and emits a prediction of the present pixel. Three PredNets are trained with the regression objectives of minimizing $\ell_1$, $\ell_2$ and $\ell_\infty$ norms of prediction residuals, respectively. The second-stage regression combines the outputs of the three PredNets to generate an even more precise and robust prediction. The proposed deep regression model is applied to lossless predictive image coding, and it outperforms the state-of-the-art linear predictors by appreciable margin.
Trainable Activation Function Supported CNN in Image Classification
Apr 28, 2020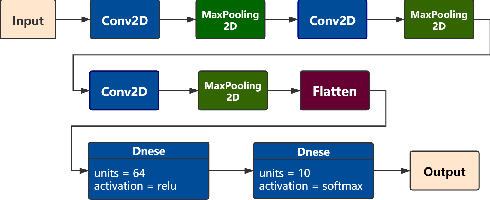
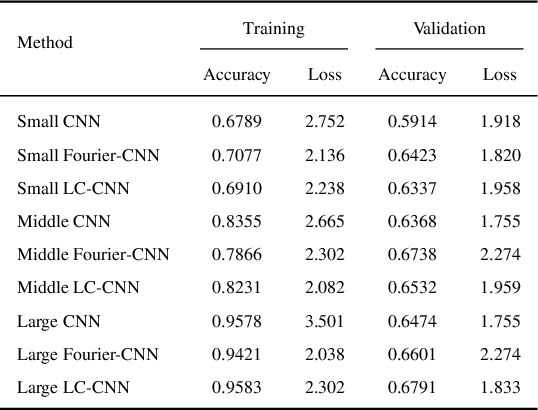
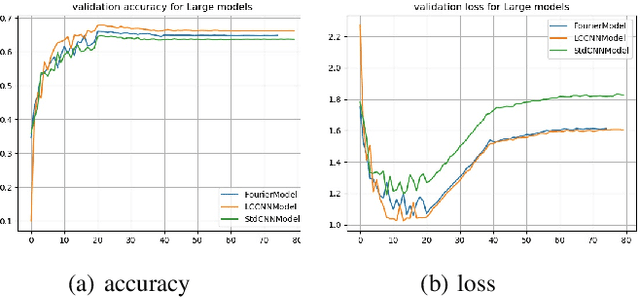
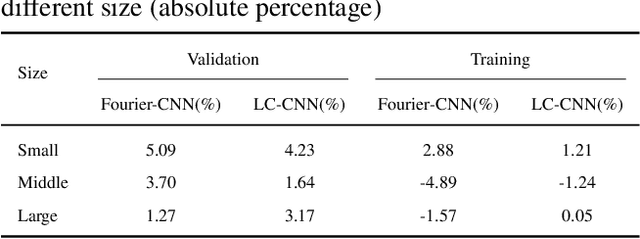
In the current research of neural networks, the activation function is manually specified by human and not able to change themselves during training. This paper focus on how to make the activation function trainable for deep neural networks. We use series and linear combination of different activation functions make activation functions continuously variable. Also, we test the performance of CNNs with Fourier series simulated activation(Fourier-CNN) and CNNs with linear combined activation function (LC-CNN) on Cifar-10 dataset. The result shows our trainable activation function reveals better performance than the most used ReLU activation function. Finally, we improves the performance of Fourier-CNN with Autoencoder, and test the performance of PSO algorithm in optimizing the parameters of networks
Unsupervised Rank-Preserving Hashing for Large-Scale Image Retrieval
Mar 04, 2019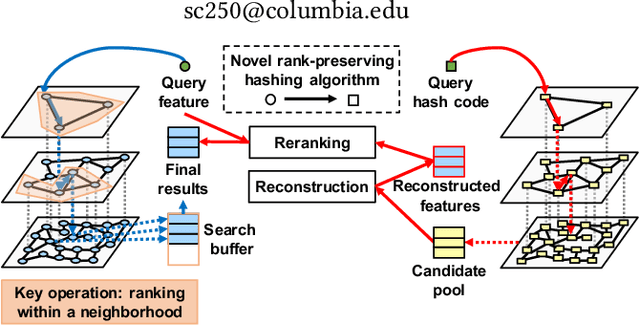
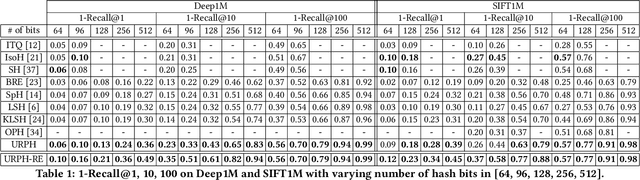
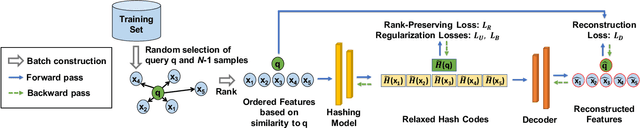
We propose an unsupervised hashing method which aims to produce binary codes that preserve the ranking induced by a real-valued representation. Such compact hash codes enable the complete elimination of real-valued feature storage and allow for significant reduction of the computation complexity and storage cost of large-scale image retrieval applications. Specifically, we learn a neural network-based model, which transforms the input representation into a binary representation. We formalize the training objective of the network in an intuitive and effective way, considering each training sample as a query and aiming to obtain the same retrieval results using the produced hash codes as those obtained with the original features. This training formulation directly optimizes the hashing model for the target usage of the hash codes it produces. We further explore the addition of a decoder trained to obtain an approximated reconstruction of the original features. At test time, we retrieved the most promising database samples with an efficient graph-based search procedure using only our hash codes and perform re-ranking using the reconstructed features, thus without needing to access the original features at all. Experiments conducted on multiple publicly available large-scale datasets show that our method consistently outperforms all compared state-of-the-art unsupervised hashing methods and that the reconstruction procedure can effectively boost the search accuracy with a minimal constant additional cost.
Using GANs to Synthesise Minimum Training Data for Deepfake Generation
Nov 10, 2020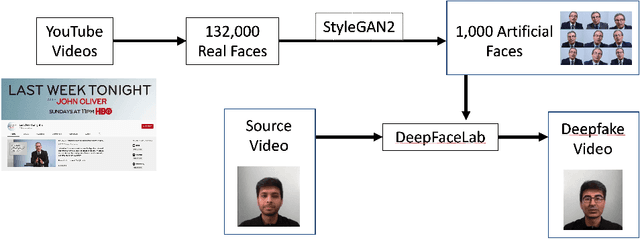
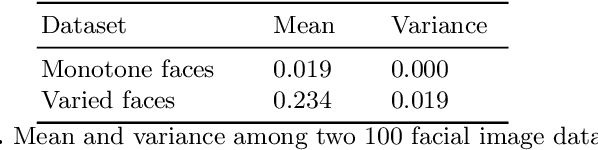
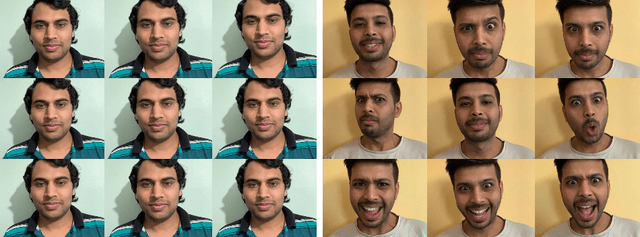
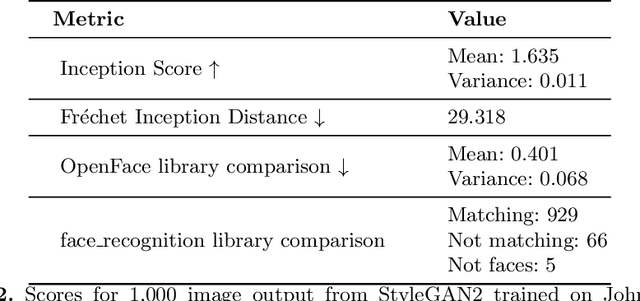
There are many applications of Generative Adversarial Networks (GANs) in fields like computer vision, natural language processing, speech synthesis, and more. Undoubtedly the most notable results have been in the area of image synthesis and in particular in the generation of deepfake videos. While deepfakes have received much negative media coverage, they can be a useful technology in applications like entertainment, customer relations, or even assistive care. One problem with generating deepfakes is the requirement for a lot of image training data of the subject which is not an issue if the subject is a celebrity for whom many images already exist. If there are only a small number of training images then the quality of the deepfake will be poor. Some media reports have indicated that a good deepfake can be produced with as few as 500 images but in practice, quality deepfakes require many thousands of images, one of the reasons why deepfakes of celebrities and politicians have become so popular. In this study, we exploit the property of a GAN to produce images of an individual with variable facial expressions which we then use to generate a deepfake. We observe that with such variability in facial expressions of synthetic GAN-generated training images and a reduced quantity of them, we can produce a near-realistic deepfake videos.
Learning Visual Representations with Caption Annotations
Aug 04, 2020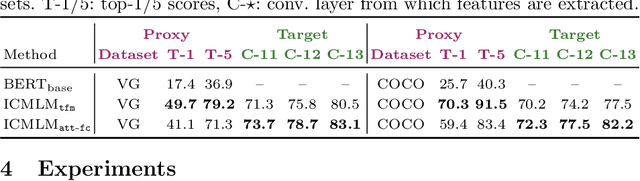
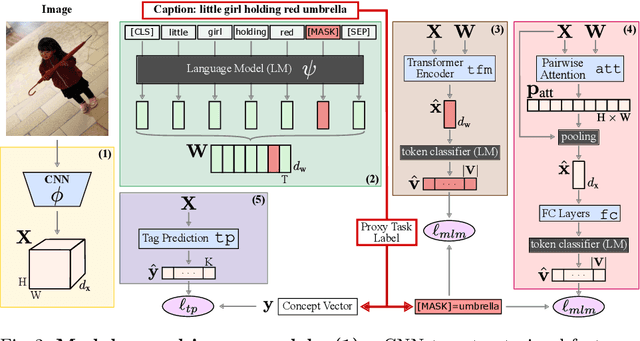
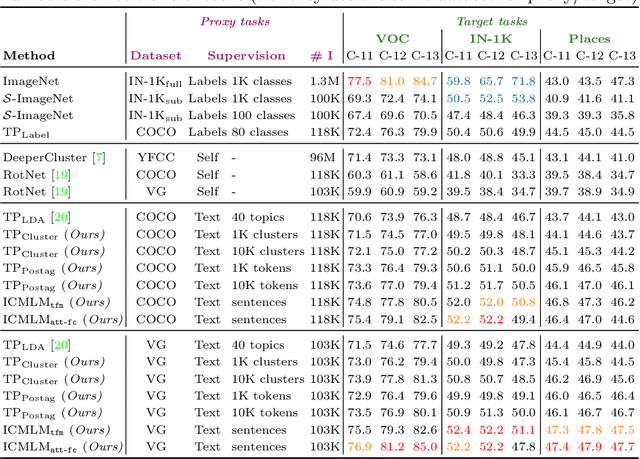

Pretraining general-purpose visual features has become a crucial part of tackling many computer vision tasks. While one can learn such features on the extensively-annotated ImageNet dataset, recent approaches have looked at ways to allow for noisy, fewer, or even no annotations to perform such pretraining. Starting from the observation that captioned images are easily crawlable, we argue that this overlooked source of information can be exploited to supervise the training of visual representations. To do so, motivated by the recent progresses in language models, we introduce {\em image-conditioned masked language modeling} (ICMLM) -- a proxy task to learn visual representations over image-caption pairs. ICMLM consists in predicting masked words in captions by relying on visual cues. To tackle this task, we propose hybrid models, with dedicated visual and textual encoders, and we show that the visual representations learned as a by-product of solving this task transfer well to a variety of target tasks. Our experiments confirm that image captions can be leveraged to inject global and localized semantic information into visual representations. Project website: https://europe.naverlabs.com/icmlm.
Deploying machine learning to assist digital humanitarians: making image annotation in OpenStreetMap more efficient
Sep 17, 2020

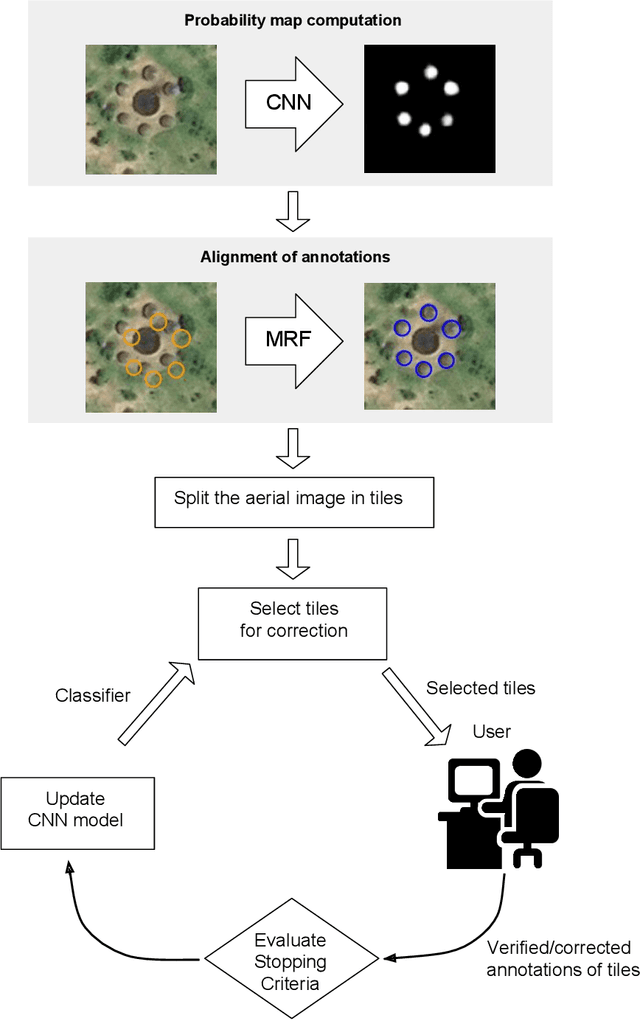
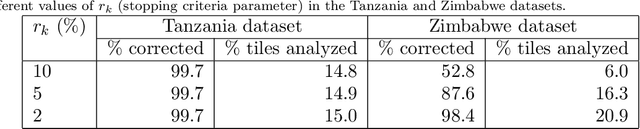
Locating populations in rural areas of developing countries has attracted the attention of humanitarian mapping projects since it is important to plan actions that affect vulnerable areas. Recent efforts have tackled this problem as the detection of buildings in aerial images. However, the quality and the amount of rural building annotated data in open mapping services like OpenStreetMap (OSM) is not sufficient for training accurate models for such detection. Although these methods have the potential of aiding in the update of rural building information, they are not accurate enough to automatically update the rural building maps. In this paper, we explore a human-computer interaction approach and propose an interactive method to support and optimize the work of volunteers in OSM. The user is asked to verify/correct the annotation of selected tiles during several iterations and therefore improving the model with the new annotated data. The experimental results, with simulated and real user annotation corrections, show that the proposed method greatly reduces the amount of data that the volunteers of OSM need to verify/correct. The proposed methodology could benefit humanitarian mapping projects, not only by making more efficient the process of annotation but also by improving the engagement of volunteers.
Difficulty in estimating visual information from randomly sampled images
Dec 16, 2020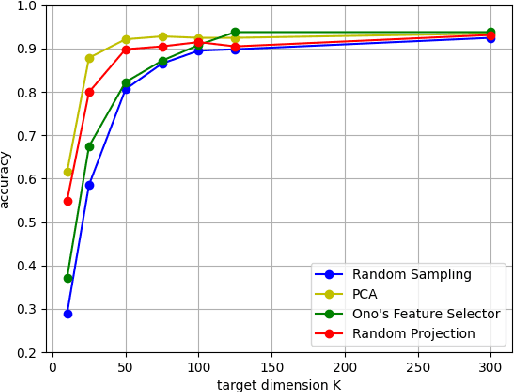
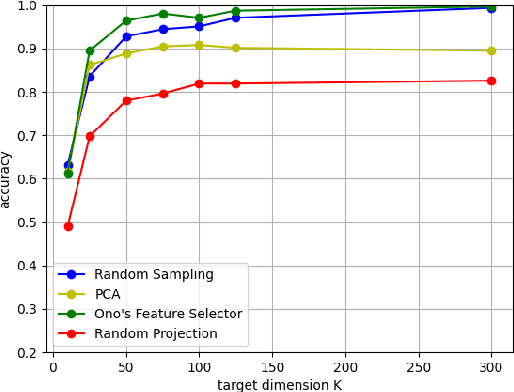
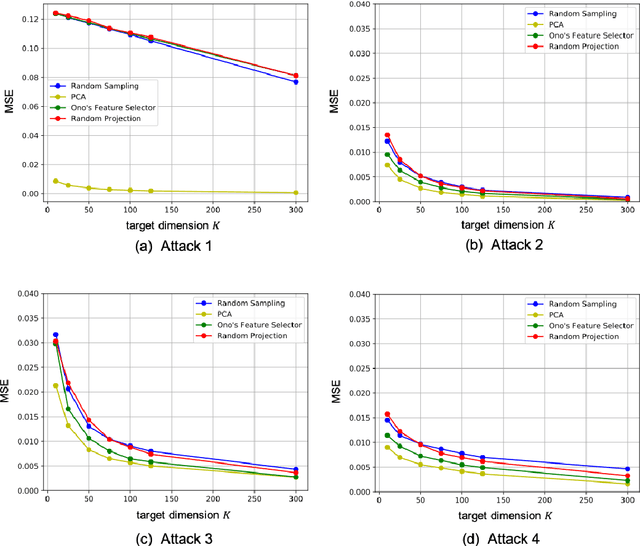
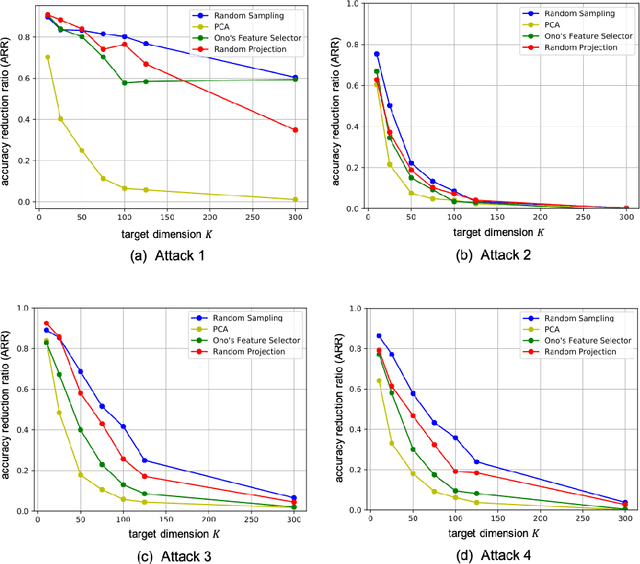
In this paper, we evaluate dimensionality reduction methods in terms of difficulty in estimating visual information on original images from dimensionally reduced ones. Recently, dimensionality reduction has been receiving attention as the process of not only reducing the number of random variables, but also protecting visual information for privacy-preserving machine learning. For such a reason, difficulty in estimating visual information is discussed. In particular, the random sampling method that was proposed for privacy-preserving machine learning, is compared with typical dimensionality reduction methods. In an image classification experiment, the random sampling method is demonstrated not only to have high difficulty, but also to be comparable to other dimensionality reduction methods, while maintaining the property of spatial information invariant.
SESAME: Semantic Editing of Scenes by Adding, Manipulating or Erasing Objects
Apr 10, 2020
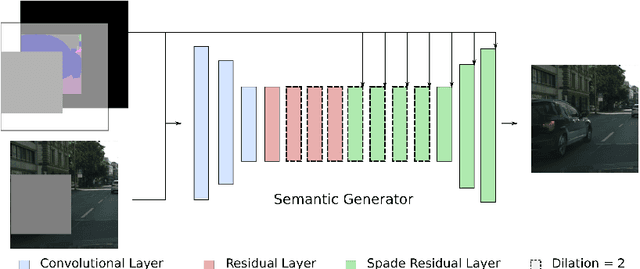

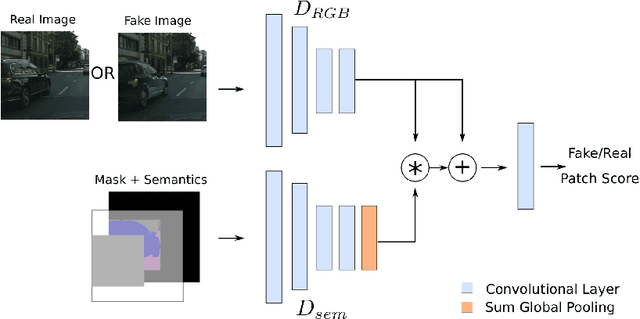
Recent advances in image generation gave rise to powerful tools for semantic image editing. However, existing approaches can either operate on a single image or require an abundance of additional information. They are not capable of handling the complete set of editing operations, that is addition, manipulation or removal of semantic concepts. To address these limitations, we propose SESAME, a novel generator-discriminator pair for Semantic Editing of Scenes by Adding, Manipulating or Erasing objects. In our setup, the user provides the semantic labels of the areas to be edited and the generator synthesizes the corresponding pixels. In contrast to previous methods that employ a discriminator that trivially concatenates semantics and image as an input, the SESAME discriminator is composed of two input streams that independently process the image and its semantics, using the latter to manipulate the results of the former. We evaluate our model on a diverse set of datasets and report state-of-the-art performance on two tasks: (a) image manipulation and (b) image generation conditioned on semantic labels.
AlphaGAN: Generative adversarial networks for natural image matting
Jul 26, 2018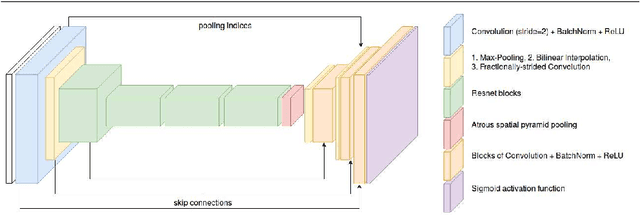
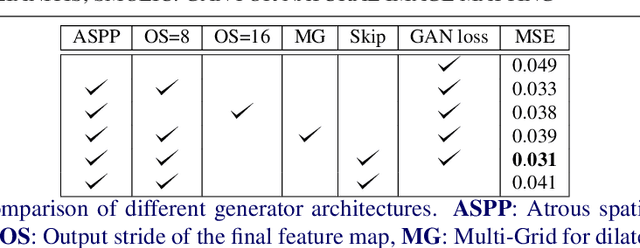
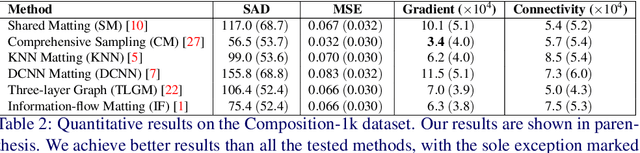

We present the first generative adversarial network (GAN) for natural image matting. Our novel generator network is trained to predict visually appealing alphas with the addition of the adversarial loss from the discriminator that is trained to classify well-composited images. Further, we improve existing encoder-decoder architectures to better deal with the spatial localization issues inherited in convolutional neural networks (CNN) by using dilated convolutions to capture global context information without downscaling feature maps and losing spatial information. We present state-of-the-art results on the alphamatting online benchmark for the gradient error and give comparable results in others. Our method is particularly well suited for fine structures like hair, which is of great importance in practical matting applications, e.g. in film/TV production.