 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dual Convolutional Neural Networks for Breast Mass Segmentation and Diagnosis in Mammography
Aug 11, 2020
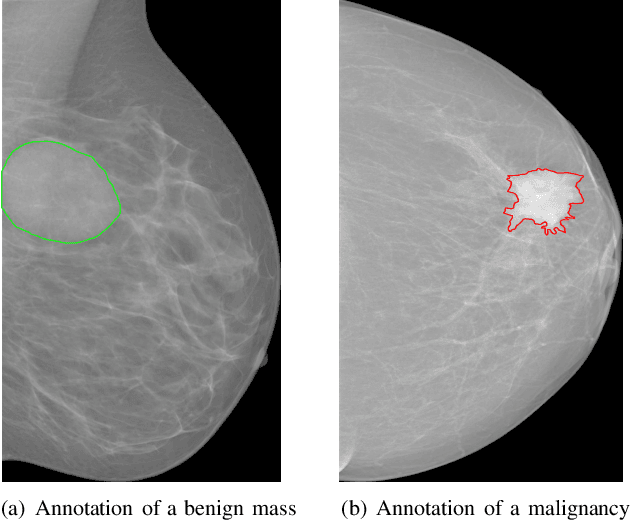
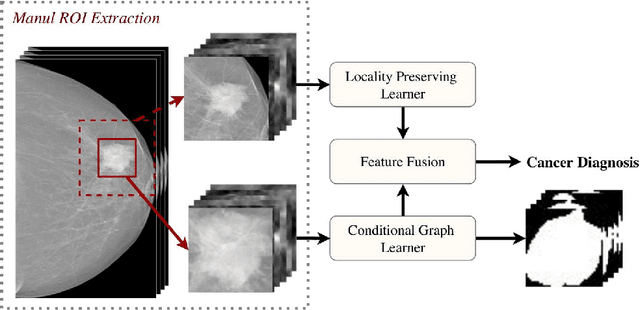
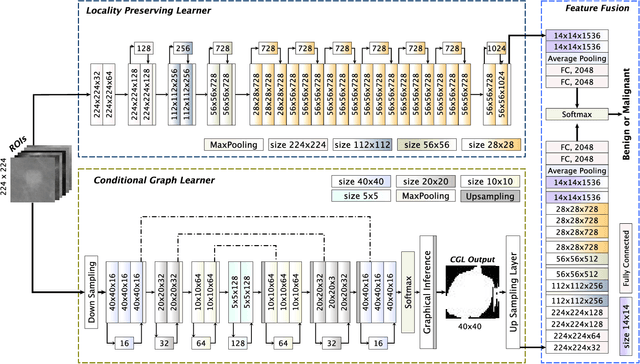
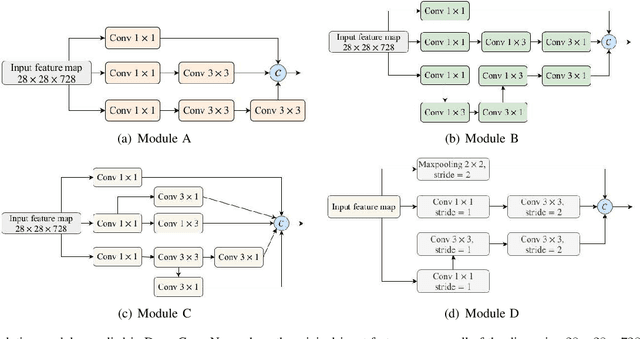
Deep convolutional neural networks (CNNs) have emerged as a new paradigm for Mammogram diagnosis. Contemporary CNN-based computer-aided-diagnosis (CAD) for breast cancer directly extract latent features from input mammogram image and ignore the importance of morphological features. In this paper, we introduce a novel deep learning framework for mammogram image processing, which computes mass segmentation and simultaneously predict diagnosis results. Specifically, our method is constructed in a dual-path architecture that solves the mapping in a dual-problem manner, with an additional consideration of important shape and boundary knowledge. One path called the Locality Preserving Learner (LPL), is devoted to hierarchically extracting and exploiting intrinsic features of the input. Whereas the other path, called the Conditional Graph Learner (CGL) focuses on generating geometrical features via modeling pixel-wise image to mask correlations. By integrating the two learners, both the semantics and structure are well preserved and the component learning paths in return complement each other, contributing an improvement to the mass segmentation and cancer classification problem at the same time. We evaluated our method on two most used public mammography datasets, DDSM and INbreast. Experimental results show that DualCoreNet achieves the best mammography segmentation and classification simultaneously, outperforming recent state-of-the-art models.
Regularization-Agnostic Compressed Sensing MRI Reconstruction with Hypernetworks
Jan 06, 2021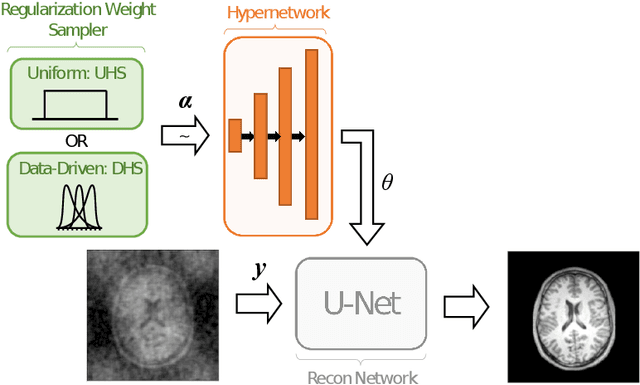


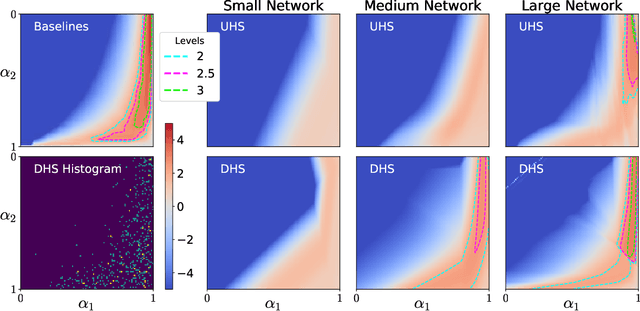
Reconstructing under-sampled k-space measurements in Compressed Sensing MRI (CS-MRI) is classically solved with regularized least-squares. Recently, deep learning has been used to amortize this optimization by training reconstruction networks on a dataset of under-sampled measurements. Here, a crucial design choice is the regularization function(s) and corresponding weight(s). In this paper, we explore a novel strategy of using a hypernetwork to generate the parameters of a separate reconstruction network as a function of the regularization weight(s), resulting in a regularization-agnostic reconstruction model. At test time, for a given under-sampled image, our model can rapidly compute reconstructions with different amounts of regularization. We analyze the variability of these reconstructions, especially in situations when the overall quality is similar. Finally, we propose and empirically demonstrate an efficient and data-driven way of maximizing reconstruction performance given limited hypernetwork capacity. Our code is publicly available at https://github.com/alanqrwang/RegAgnosticCSMRI.
Classification of Noncoding RNA Elements Using Deep Convolutional Neural Networks
Aug 24, 2020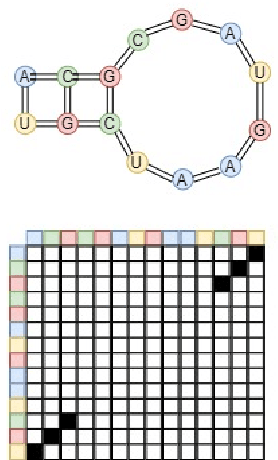

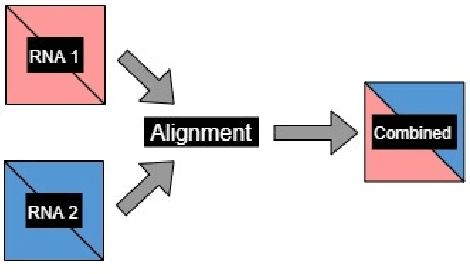

The paper proposes to employ deep convolutional neural networks (CNNs) to classify noncoding RNA (ncRNA) sequences. To this end, we first propose an efficient approach to convert the RNA sequences into images characterizing their base-pairing probability. As a result, classifying RNA sequences is converted to an image classification problem that can be efficiently solved by available CNN-based classification models. The paper also considers the folding potential of the ncRNAs in addition to their primary sequence. Based on the proposed approach, a benchmark image classification dataset is generated from the RFAM database of ncRNA sequences. In addition, three classical CNN models have been implemented and compared to demonstrate the superior performance and efficiency of the proposed approach. Extensive experimental results show the great potential of using deep learning approaches for RNA classification.
CVAE-GAN: Fine-Grained Image Generation through Asymmetric Training
Oct 12, 2017
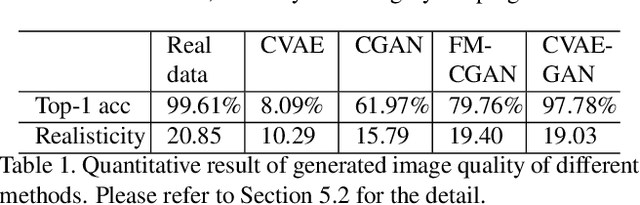
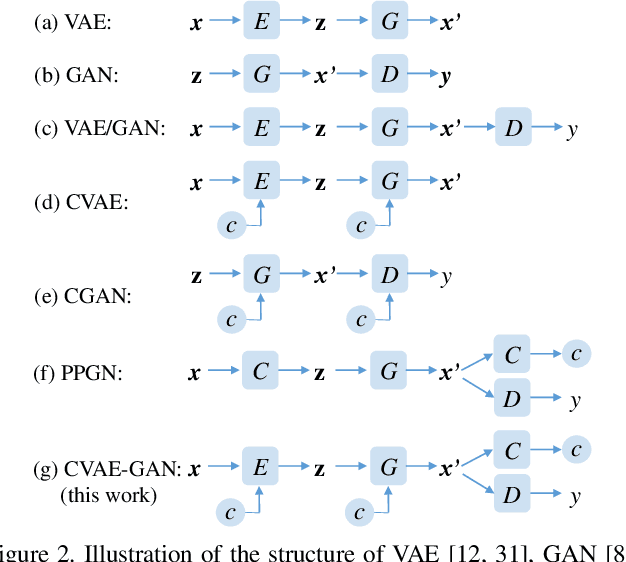
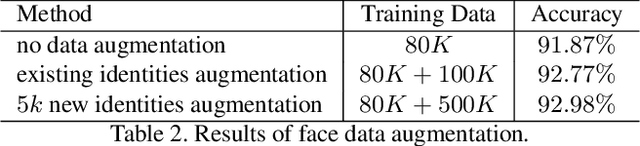
We present variational generative adversarial networks, a general learning framework that combines a variational auto-encoder with a generative adversarial network, for synthesizing images in fine-grained categories, such as faces of a specific person or objects in a category. Our approach models an image as a composition of label and latent attributes in a probabilistic model. By varying the fine-grained category label fed into the resulting generative model, we can generate images in a specific category with randomly drawn values on a latent attribute vector. Our approach has two novel aspects. First, we adopt a cross entropy loss for the discriminative and classifier network, but a mean discrepancy objective for the generative network. This kind of asymmetric loss function makes the GAN training more stable. Second, we adopt an encoder network to learn the relationship between the latent space and the real image space, and use pairwise feature matching to keep the structure of generated images. We experiment with natural images of faces, flowers, and birds, and demonstrate that the proposed models are capable of generating realistic and diverse samples with fine-grained category labels. We further show that our models can be applied to other tasks, such as image inpainting, super-resolution, and data augmentation for training better face recognition models.
Evaluation, Tuning and Interpretation of Neural Networks for Meteorological Applications
May 06, 2020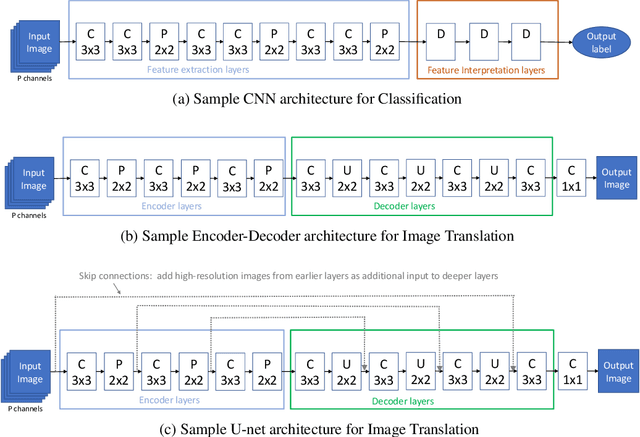
Neural networks have opened up many new opportunities to utilize remotely sensed images in meteorology. Common applications include image classification, e.g., to determine whether an image contains a tropical cyclone, and image translation, e.g., to emulate radar imagery for satellites that only have passive channels. However, there are yet many open questions regarding the use of neural networks in meteorology, such as best practices for evaluation, tuning and interpretation. This article highlights several strategies and practical considerations for neural network development that have not yet received much attention in the meteorological community, such as the concept of effective receptive fields, underutilized meteorological performance measures, and methods for NN interpretation, such as synthetic experiments and layer-wise relevance propagation. We also consider the process of neural network interpretation as a whole, recognizing it as an iterative scientist-driven discovery process, and breaking it down into individual steps that researchers can take. Finally, while most work on neural network interpretation in meteorology has so far focused on networks for image classification tasks, we expand the focus to also include networks for image translation.
COMPAS: Representation Learning with Compositional Part Sharing for Few-Shot Classification
Jan 28, 2021
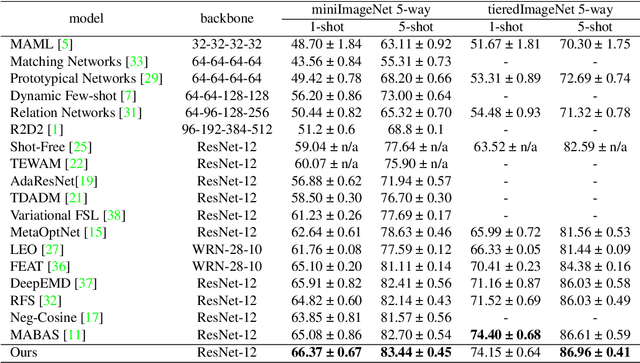
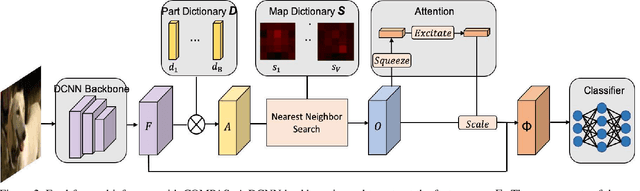
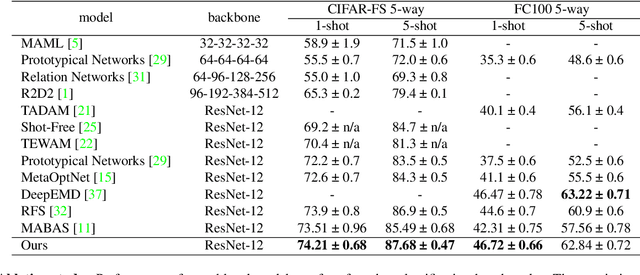
Few-shot image classification consists of two consecutive learning processes: 1) In the meta-learning stage, the model acquires a knowledge base from a set of training classes. 2) During meta-testing, the acquired knowledge is used to recognize unseen classes from very few examples. Inspired by the compositional representation of objects in humans, we train a neural network architecture that explicitly represents objects as a set of parts and their spatial composition. In particular, during meta-learning, we train a knowledge base that consists of a dictionary of part representations and a dictionary of part activation maps that encode frequent spatial activation patterns of parts. The elements of both dictionaries are shared among the training classes. During meta-testing, the representation of unseen classes is learned using the part representations and the part activation maps from the knowledge base. Finally, an attention mechanism is used to strengthen those parts that are most important for each category. We demonstrate the value of our compositional learning framework for a few-shot classification using miniImageNet, tieredImageNet, CIFAR-FS, and FC100, where we achieve state-of-the-art performance.
Ray-based framework for state identification in quantum dot devices
Feb 23, 2021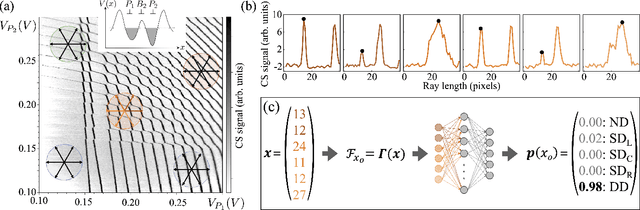
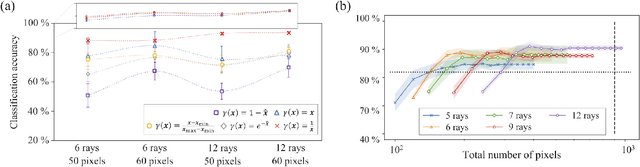
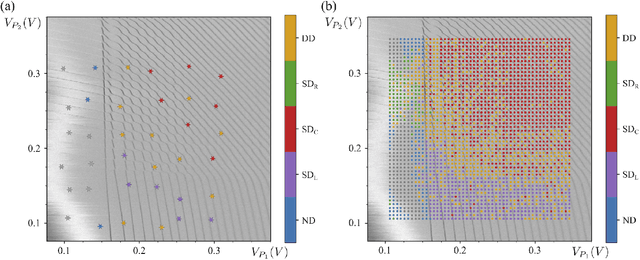
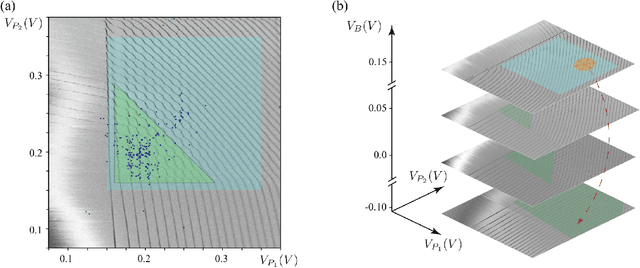
Quantum dots (QDs) defined with electrostatic gates are a leading platform for a scalable quantum computing implementation. However, with increasing numbers of qubits, the complexity of the control parameter space also grows. Traditional measurement techniques, relying on complete or near-complete exploration via two-parameter scans (images) of the device response, quickly become impractical with increasing numbers of gates. Here, we propose to circumvent this challenge by introducing a measurement technique relying on one-dimensional projections of the device response in the multi-dimensional parameter space. Dubbed as the ray-based classification (RBC) framework, we use this machine learning (ML) approach to implement a classifier for QD states, enabling automated recognition of qubit-relevant parameter regimes. We show that RBC surpasses the 82 % accuracy benchmark from the experimental implementation of image-based classification techniques from prior work while cutting down the number of measurement points needed by up to 70 %. The reduction in measurement cost is a significant gain for time-intensive QD measurements and is a step forward towards the scalability of these devices. We also discuss how the RBC-based optimizer, which tunes the device to a multi-qubit regime, performs when tuning in the two- and three-dimensional parameter spaces defined by plunger and barrier gates that control the dots. This work provides experimental validation of both efficient state identification and optimization with ML techniques for non-traditional measurements in quantum systems with high-dimensional parameter spaces and time-intensive measurements.
Hashed Binary Search Sampling for Convolutional Network Training with Large Overhead Image Patches
Jul 18, 2017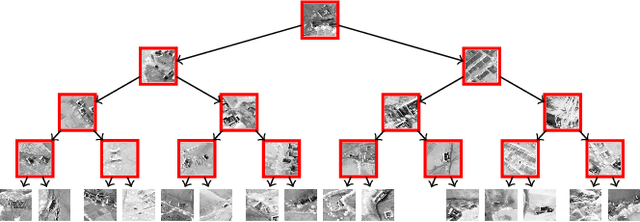
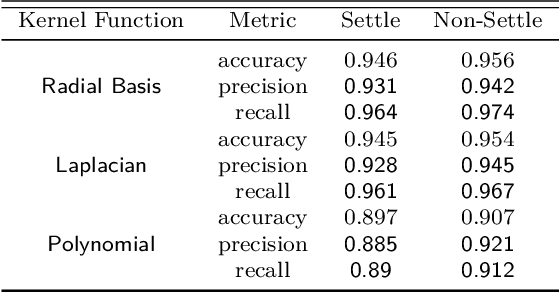
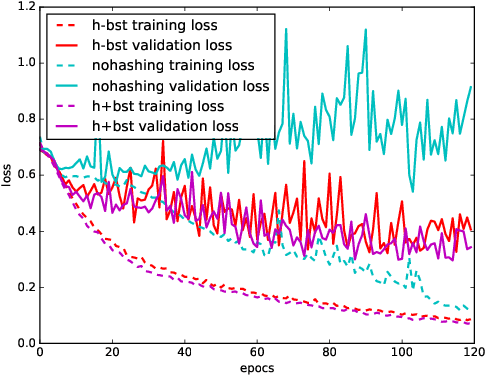

Very large overhead imagery associated with ground truth maps has the potential to generate billions of training image patches for machine learning algorithms. However, random sampling selection criteria often leads to redundant and noisy-image patches for model training. With minimal research efforts behind this challenge, the current status spells missed opportunities to develop supervised learning algorithms that generalize over wide geographical scenes. In addition, much of the computational cycles for large scale machine learning are poorly spent crunching through noisy and redundant image patches. We demonstrate a potential framework to address these challenges specifically, while evaluating a human settlement detection task. A novel binary search tree sampling scheme is fused with a kernel based hashing procedure that maps image patches into hash-buckets using binary codes generated from image content. The framework exploits inherent redundancy within billions of image patches to promote mostly high variance preserving samples for accelerating algorithmic training and increasing model generalization.
Learning Spatial Attention for Face Super-Resolution
Dec 02, 2020
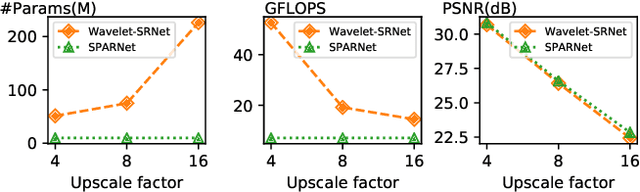
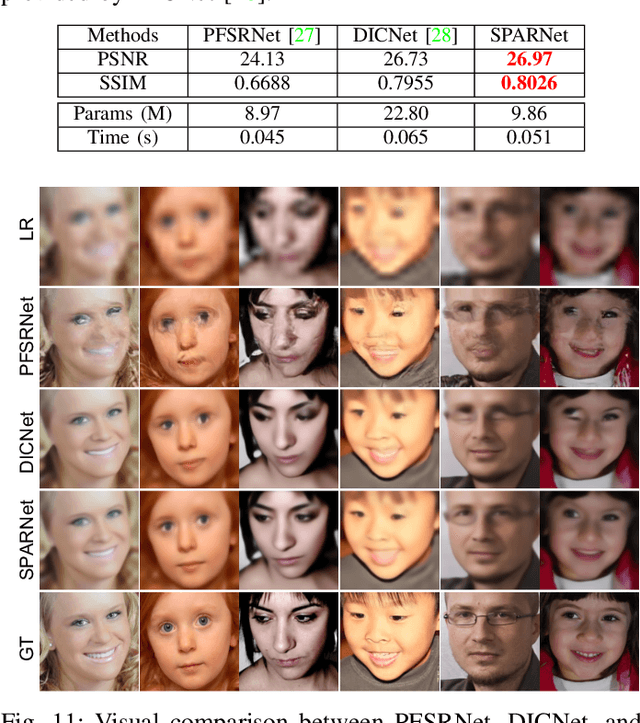

General image super-resolution techniques have difficulties in recovering detailed face structures when applying to low resolution face images. Recent deep learning based methods tailored for face images have achieved improved performance by jointly trained with additional task such as face parsing and landmark prediction. However, multi-task learning requires extra manually labeled data. Besides, most of the existing works can only generate relatively low resolution face images (e.g., $128\times128$), and their applications are therefore limited. In this paper, we introduce a novel SPatial Attention Residual Network (SPARNet) built on our newly proposed Face Attention Units (FAUs) for face super-resolution. Specifically, we introduce a spatial attention mechanism to the vanilla residual blocks. This enables the convolutional layers to adaptively bootstrap features related to the key face structures and pay less attention to those less feature-rich regions. This makes the training more effective and efficient as the key face structures only account for a very small portion of the face image. Visualization of the attention maps shows that our spatial attention network can capture the key face structures well even for very low resolution faces (e.g., $16\times16$). Quantitative comparisons on various kinds of metrics (including PSNR, SSIM, identity similarity, and landmark detection) demonstrate the superiority of our method over current state-of-the-arts. We further extend SPARNet with multi-scale discriminators, named as SPARNetHD, to produce high resolution results (i.e., $512\times512$). We show that SPARNetHD trained with synthetic data cannot only produce high quality and high resolution outputs for synthetically degraded face images, but also show good generalization ability to real world low quality face images. Codes are available at \url{https://github.com/chaofengc/Face-SPARNet}.
Improving Apparel Detection with Category Grouping and Multi-grained Branches
Jan 17, 2021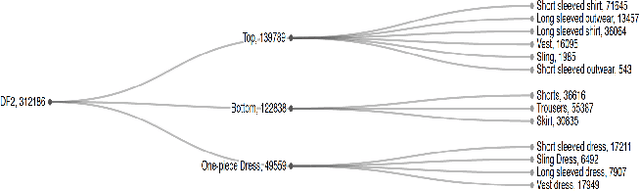
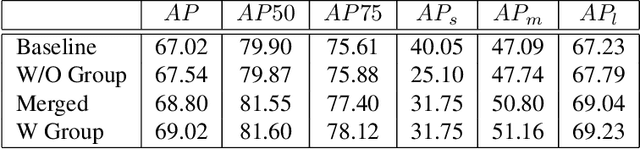
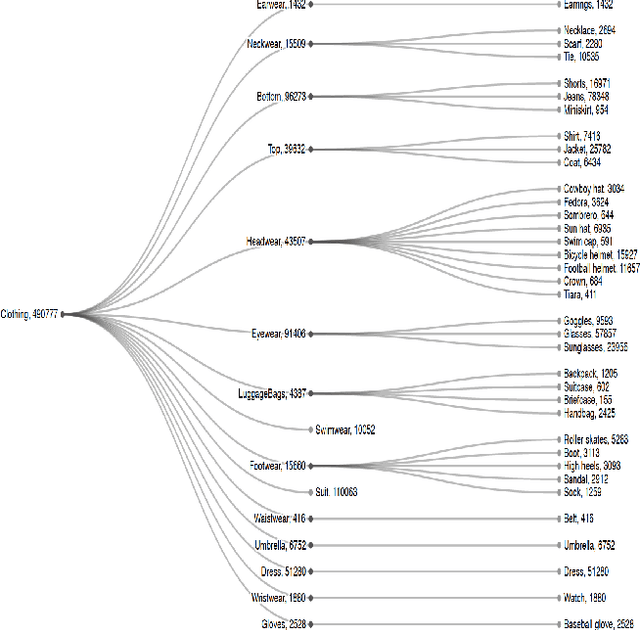
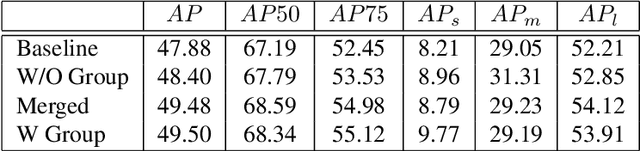
Training an accurate object detector is expensive and time-consuming. One main reason lies in the laborious labeling process, i.e., annotating category and bounding box information for all instances in every image. In this paper, we examine ways to improve performance of deep object detectors without extra labeling. We first explore to group existing categories of high visual and semantic similarities together as one super category (or, a superclass). Then, we study how this knowledge of hierarchical categories can be exploited to better detect object using multi-grained RCNN top branches. Experimental results on DeepFashion2 and OpenImagesV4-Clothing reveal that the proposed detection heads with multi-grained branches can boost the overall performance by 2.3 mAP for DeepFashion2 and 2.5 mAP for OpenImagesV4-Clothing with no additional time-consuming annotations. More importantly, classes that have fewer training samples tend to benefit more from the proposed multi-grained heads with superclass grouping. In particular, we improve the mAP for last 30% categories (in terms of training sample number) by 2.6 and 4.6 for DeepFashion2 and OpenImagesV4-Clothing, respectively.