 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fus-MAE: A cross-attention-based data fusion approach for Masked Autoencoders in remote sensing
Jan 05, 2024
Self-supervised frameworks for representation learning have recently stirred up interest among the remote sensing community, given their potential to mitigate the high labeling costs associated with curating large satellite image datasets. In the realm of multimodal data fusion, while the often used contrastive learning methods can help bridging the domain gap between different sensor types, they rely on data augmentations techniques that require expertise and careful design, especially for multispectral remote sensing data. A possible but rather scarcely studied way to circumvent these limitations is to use a masked image modelling based pretraining strategy. In this paper, we introduce Fus-MAE, a self-supervised learning framework based on masked autoencoders that uses cross-attention to perform early and feature-level data fusion between synthetic aperture radar and multispectral optical data - two modalities with a significant domain gap. Our empirical findings demonstrate that Fus-MAE can effectively compete with contrastive learning strategies tailored for SAR-optical data fusion and outperforms other masked-autoencoders frameworks trained on a larger corpus.
Progressive Knowledge Distillation Of Stable Diffusion XL Using Layer Level Loss
Jan 05, 2024Stable Diffusion XL (SDXL) has become the best open source text-to-image model (T2I) for its versatility and top-notch image quality. Efficiently addressing the computational demands of SDXL models is crucial for wider reach and applicability. In this work, we introduce two scaled-down variants, Segmind Stable Diffusion (SSD-1B) and Segmind-Vega, with 1.3B and 0.74B parameter UNets, respectively, achieved through progressive removal using layer-level losses focusing on reducing the model size while preserving generative quality. We release these models weights at https://hf.co/Segmind. Our methodology involves the elimination of residual networks and transformer blocks from the U-Net structure of SDXL, resulting in significant reductions in parameters, and latency. Our compact models effectively emulate the original SDXL by capitalizing on transferred knowledge, achieving competitive results against larger multi-billion parameter SDXL. Our work underscores the efficacy of knowledge distillation coupled with layer-level losses in reducing model size while preserving the high-quality generative capabilities of SDXL, thus facilitating more accessible deployment in resource-constrained environments.
Derm-T2IM: Harnessing Synthetic Skin Lesion Data via Stable Diffusion Models for Enhanced Skin Disease Classification using ViT and CNN
Jan 10, 2024This study explores the utilization of Dermatoscopic synthetic data generated through stable diffusion models as a strategy for enhancing the robustness of machine learning model training. Synthetic data generation plays a pivotal role in mitigating challenges associated with limited labeled datasets, thereby facilitating more effective model training. In this context, we aim to incorporate enhanced data transformation techniques by extending the recent success of few-shot learning and a small amount of data representation in text-to-image latent diffusion models. The optimally tuned model is further used for rendering high-quality skin lesion synthetic data with diverse and realistic characteristics, providing a valuable supplement and diversity to the existing training data. We investigate the impact of incorporating newly generated synthetic data into the training pipeline of state-of-art machine learning models, assessing its effectiveness in enhancing model performance and generalization to unseen real-world data. Our experimental results demonstrate the efficacy of the synthetic data generated through stable diffusion models helps in improving the robustness and adaptability of end-to-end CNN and vision transformer models on two different real-world skin lesion datasets.
Improved Zero-Shot Classification by Adapting VLMs with Text Descriptions
Jan 04, 2024The zero-shot performance of existing vision-language models (VLMs) such as CLIP is limited by the availability of large-scale, aligned image and text datasets in specific domains. In this work, we leverage two complementary sources of information -- descriptions of categories generated by large language models (LLMs) and abundant, fine-grained image classification datasets -- to improve the zero-shot classification performance of VLMs across fine-grained domains. On the technical side, we develop methods to train VLMs with this "bag-level" image-text supervision. We find that simply using these attributes at test-time does not improve performance, but our training strategy, for example, on the iNaturalist dataset, leads to an average improvement of 4-5% in zero-shot classification accuracy for novel categories of birds and flowers. Similar improvements are observed in domains where a subset of the categories was used to fine-tune the model. By prompting LLMs in various ways, we generate descriptions that capture visual appearance, habitat, and geographic regions and pair them with existing attributes such as the taxonomic structure of the categories. We systematically evaluate their ability to improve zero-shot categorization in natural domains. Our findings suggest that geographic priors can be just as effective and are complementary to visual appearance. Our method also outperforms prior work on prompt-based tuning of VLMs. We plan to release the benchmark, consisting of 7 datasets, which will contribute to future research in zero-shot recognition.
Text-Image Conditioned Diffusion for Consistent Text-to-3D Generation
Dec 19, 2023By lifting the pre-trained 2D diffusion models into Neural Radiance Fields (NeRFs), text-to-3D generation methods have made great progress. Many state-of-the-art approaches usually apply score distillation sampling (SDS) to optimize the NeRF representations, which supervises the NeRF optimization with pre-trained text-conditioned 2D diffusion models such as Imagen. However, the supervision signal provided by such pre-trained diffusion models only depends on text prompts and does not constrain the multi-view consistency. To inject the cross-view consistency into diffusion priors, some recent works finetune the 2D diffusion model with multi-view data, but still lack fine-grained view coherence. To tackle this challenge, we incorporate multi-view image conditions into the supervision signal of NeRF optimization, which explicitly enforces fine-grained view consistency. With such stronger supervision, our proposed text-to-3D method effectively mitigates the generation of floaters (due to excessive densities) and completely empty spaces (due to insufficient densities). Our quantitative evaluations on the T$^3$Bench dataset demonstrate that our method achieves state-of-the-art performance over existing text-to-3D methods. We will make the code publicly available.
Content-Conditioned Generation of Stylized Free hand Sketches
Jan 09, 2024In recent years, the recognition of free-hand sketches has remained a popular task. However, in some special fields such as the military field, free-hand sketches are difficult to sample on a large scale. Common data augmentation and image generation techniques are difficult to produce images with various free-hand sketching styles. Therefore, the recognition and segmentation tasks in related fields are limited. In this paper, we propose a novel adversarial generative network that can accurately generate realistic free-hand sketches with various styles. We explore the performance of the model, including using styles randomly sampled from a prior normal distribution to generate images with various free-hand sketching styles, disentangling the painters' styles from known free-hand sketches to generate images with specific styles, and generating images of unknown classes that are not in the training set. We further demonstrate with qualitative and quantitative evaluations our advantages in visual quality, content accuracy, and style imitation on SketchIME.
Decomposer: Semi-supervised Learning of Image Restoration and Image Decomposition
Nov 28, 2023

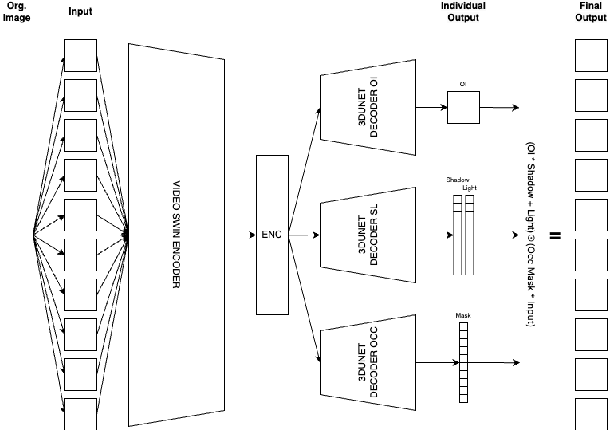

We present Decomposer, a semi-supervised reconstruction model that decomposes distorted image sequences into their fundamental building blocks - the original image and the applied augmentations, i.e., shadow, light, and occlusions. To solve this problem, we use the SIDAR dataset that provides a large number of distorted image sequences: each sequence contains images with shadows, lighting, and occlusions applied to an undistorted version. Each distortion changes the original signal in different ways, e.g., additive or multiplicative noise. We propose a transformer-based model to explicitly learn this decomposition. The sequential model uses 3D Swin-Transformers for spatio-temporal encoding and 3D U-Nets as prediction heads for individual parts of the decomposition. We demonstrate that by separately pre-training our model on weakly supervised pseudo labels, we can steer our model to optimize for our ambiguous problem definition and learn to differentiate between the different image distortions.
TiMix: Text-aware Image Mixing for Effective Vision-Language Pre-training
Dec 14, 2023Self-supervised Multi-modal Contrastive Learning (SMCL) remarkably advances modern Vision-Language Pre-training (VLP) models by aligning visual and linguistic modalities. Due to noises in web-harvested text-image pairs, however, scaling up training data volume in SMCL presents considerable obstacles in terms of computational cost and data inefficiency. To improve data efficiency in VLP, we propose Text-aware Image Mixing (TiMix), which integrates mix-based data augmentation techniques into SMCL, yielding significant performance improvements without significantly increasing computational overhead. We provide a theoretical analysis of TiMixfrom a mutual information (MI) perspective, showing that mixed data samples for cross-modal contrastive learning implicitly serve as a regularizer for the contrastive loss. The experimental results demonstrate that TiMix exhibits a comparable performance on downstream tasks, even with a reduced amount of training data and shorter training time, when benchmarked against existing methods. This work empirically and theoretically demonstrates the potential of data mixing for data-efficient and computationally viable VLP, benefiting broader VLP model adoption in practical scenarios.
What Else Would I Like? A User Simulator using Alternatives for Improved Evaluation of Fashion Conversational Recommendation Systems
Jan 11, 2024In Conversational Recommendation Systems (CRS), a user can provide feedback on recommended items at each interaction turn, leading the CRS towards more desirable recommendations. Currently, different types of CRS offer various possibilities for feedback, i.e., natural language feedback, or answering clarifying questions. In most cases, a user simulator is employed for training as well as evaluating the CRS. Such user simulators typically critique the current retrieved items based on knowledge of a single target item. Still, evaluating systems in offline settings with simulators suffers from problems, such as focusing entirely on a single target item (not addressing the exploratory nature of a recommender system), and exhibiting extreme patience (consistent feedback over a large number of turns). To overcome these limitations, we obtain extra judgements for a selection of alternative items in common CRS datasets, namely Shoes and Fashion IQ Dresses. Going further, we propose improved user simulators that allow simulated users not only to express their preferences about alternative items to their original target, but also to change their mind and level of patience. In our experiments using the relative image captioning CRS setting and different CRS models, we find that using the knowledge of alternatives by the simulator can have a considerable impact on the evaluation of existing CRS models, specifically that the existing single-target evaluation underestimates their effectiveness, and when simulated users are allowed to instead consider alternatives, the system can rapidly respond to more quickly satisfy the user.
AdaptIR: Parameter Efficient Multi-task Adaptation for Pre-trained Image Restoration Models
Dec 12, 2023Pre-training has shown promising results on various image restoration tasks, which is usually followed by full fine-tuning for each specific downstream task (e.g., image denoising). However, such full fine-tuning usually suffers from the problems of heavy computational cost in practice, due to the massive parameters of pre-trained restoration models, thus limiting its real-world applications. Recently, Parameter Efficient Transfer Learning (PETL) offers an efficient alternative solution to full fine-tuning, yet still faces great challenges for pre-trained image restoration models, due to the diversity of different degradations. To address these issues, we propose AdaptIR, a novel parameter efficient transfer learning method for adapting pre-trained restoration models. Specifically, the proposed method consists of a multi-branch inception structure to orthogonally capture local spatial, global spatial, and channel interactions. In this way, it allows powerful representations under a very low parameter budget. Extensive experiments demonstrate that the proposed method can achieve comparable or even better performance than full fine-tuning, while only using 0.6% parameters. Code is available at https://github.com/csguoh/AdaptIR.