 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Single Image Dehazing Using Dark Channel Prior Loss
Dec 06, 2018




Single image dehazing is a critical stage in many modern-day autonomous vision applications. Early prior-based methods often involved a time-consuming minimization of a hand-crafted energy function. Recent learning-based approaches utilize the representational power of deep neural networks (DNNs) to learn the underlying transformation between hazy and clear images. Due to inherent limitations in collecting matching clear and hazy images, these methods resort to training on synthetic data; constructed from indoor images and corresponding depth information. This may result in a possible domain shift when treating outdoor scenes. We propose a completely unsupervised method of training via minimization of the well-known, Dark Channel Prior (DCP) energy function. Instead of feeding the network with synthetic data, we solely use real-world outdoor images and tune the network's parameters by directly minimizing the DCP. Although our `Deep DCP' technique can be regarded as a fast approximator of DCP, it actually improves its results significantly. This suggests an additional regularization obtained via the network and learning process. Experiments show that our method performs on par with other large-scale, supervised methods.
Deep Learning Based Traffic Surveillance System For Missing and Suspicious Car Detection
Jul 17, 2020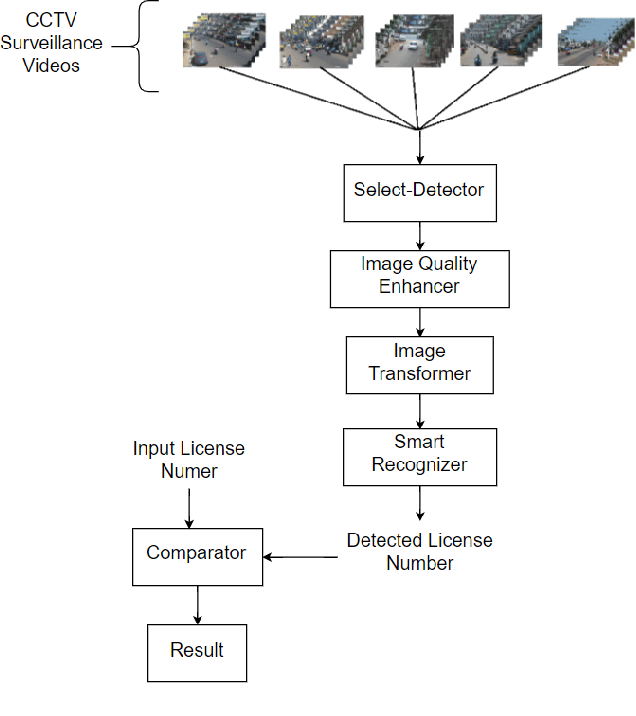


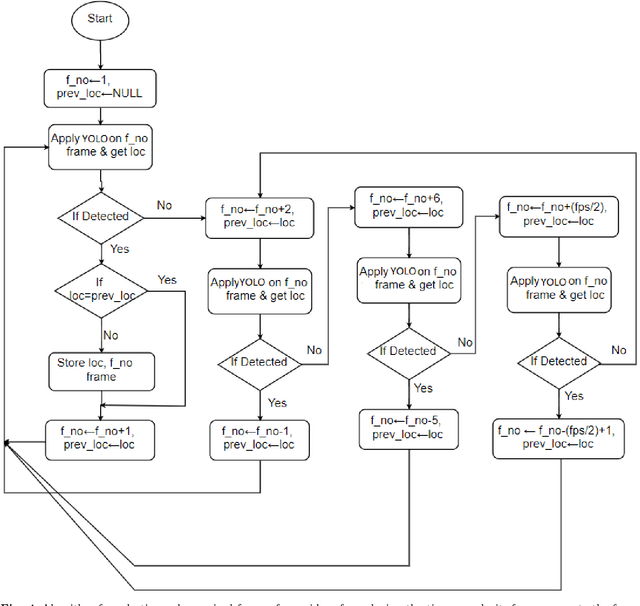
Vehicle theft is arguably one of the fastest-growing types of crime in India. In some of the urban areas, vehicle theft cases are believed to be around 100 each day. Identification of stolen vehicles in such precarious scenarios is not possible using traditional methods like manual checking and radio frequency identification(RFID) based technologies. This paper presents a deep learning based automatic traffic surveillance system for the detection of stolen/suspicious cars from the closed circuit television(CCTV) camera footage. It mainly comprises of four parts: Select-Detector, Image Quality Enhancer, Image Transformer, and Smart Recognizer. The Select-Detector is used for extracting the frames containing vehicles and to detect the license plates much efficiently with minimum time complexity. The quality of the license plates is then enhanced using Image Quality Enhancer which uses pix2pix generative adversarial network(GAN) for enhancing the license plates that are affected by temporal changes like low light, shadow, etc. Image Transformer is used to tackle the problem of inefficient recognition of license plates which are not horizontal(which are at an angle) by transforming the license plate to different levels of rotation and cropping. Smart Recognizer recognizes the license plate number using Tesseract optical character recognition(OCR) and corrects the wrongly recognized characters using Error-Detector. The effectiveness of the proposed approach is tested on the government's CCTV camera footage, which resulted in identifying the stolen/suspicious cars with an accuracy of 87%.
Deep Generative Adversarial Residual Convolutional Networks for Real-World Super-Resolution
May 03, 2020
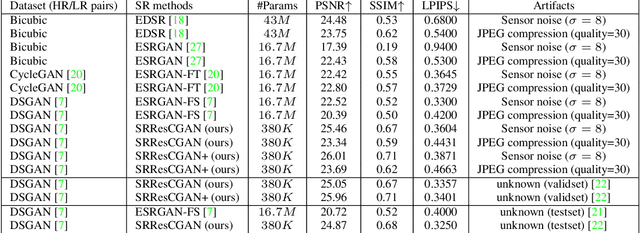
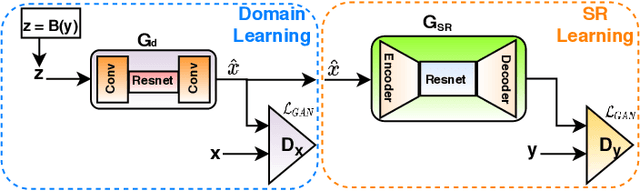
Most current deep learning based single image super-resolution (SISR) methods focus on designing deeper / wider models to learn the non-linear mapping between low-resolution (LR) inputs and the high-resolution (HR) outputs from a large number of paired (LR/HR) training data. They usually take as assumption that the LR image is a bicubic down-sampled version of the HR image. However, such degradation process is not available in real-world settings i.e. inherent sensor noise, stochastic noise, compression artifacts, possible mismatch between image degradation process and camera device. It reduces significantly the performance of current SISR methods due to real-world image corruptions. To address these problems, we propose a deep Super-Resolution Residual Convolutional Generative Adversarial Network (SRResCGAN) to follow the real-world degradation settings by adversarial training the model with pixel-wise supervision in the HR domain from its generated LR counterpart. The proposed network exploits the residual learning by minimizing the energy-based objective function with powerful image regularization and convex optimization techniques. We demonstrate our proposed approach in quantitative and qualitative experiments that generalize robustly to real input and it is easy to deploy for other down-scaling operators and mobile/embedded devices.
Autonomous Removal of Perspective Distortion based on Detection Results of Robotic Elevator Button Corner
Jul 23, 2020
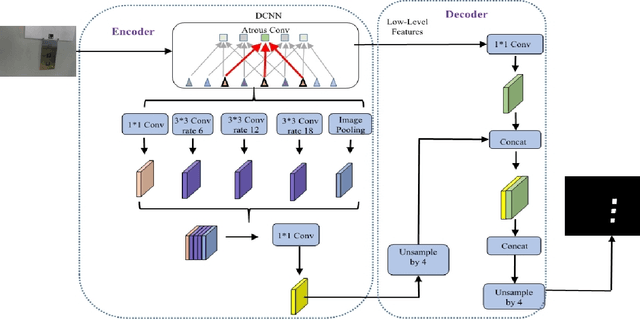
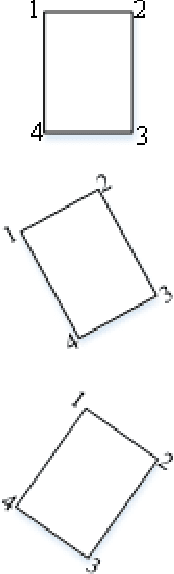
Elevator button recognition is an important function to realize the autonomous operation of elevators. However, challenging image conditions and various image distortions make it difficult to accurately recognize buttons. In this work, We propose a novel algorithm that can automatically correct perspective distortions of elevator panel images based on button corner detection results. The algorithm first leverages DeepLabv3+ model and Hough Transform method to obtain button segmentation results and button corner detection results, then utilizes pixel coordinates of standard button corners as reference features to estimate camera motions for correcting perspective distortions. The algorithm is much more robust to outliers and noise on the removal of perspective distortion than traditional geometric approaches as it only performs on a single image autonomously. 15 elevator panel images are captured from different angles of view as the dataset. The experimental results show that our approach significantly outperforms traditional geometric techniques in accuracy and robustness. Rectification results of the proposed algorithm is 77.4% better than the results of traditional geometric algorithm in average.
A Global to Local Double Embedding Method for Multi-person Pose Estimation
Feb 16, 2021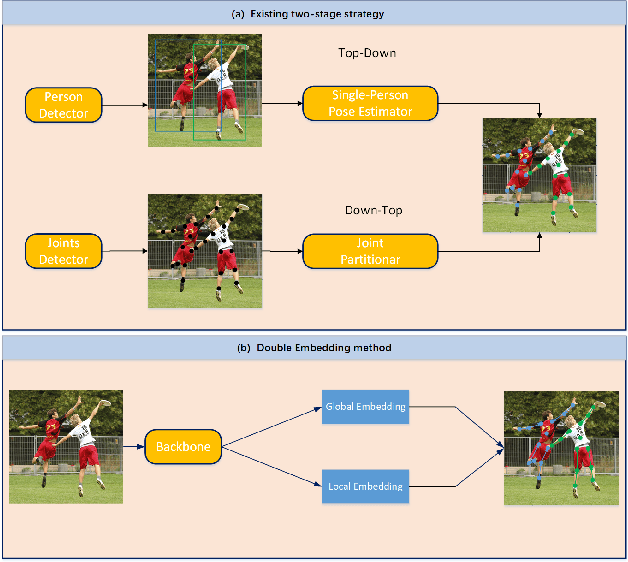
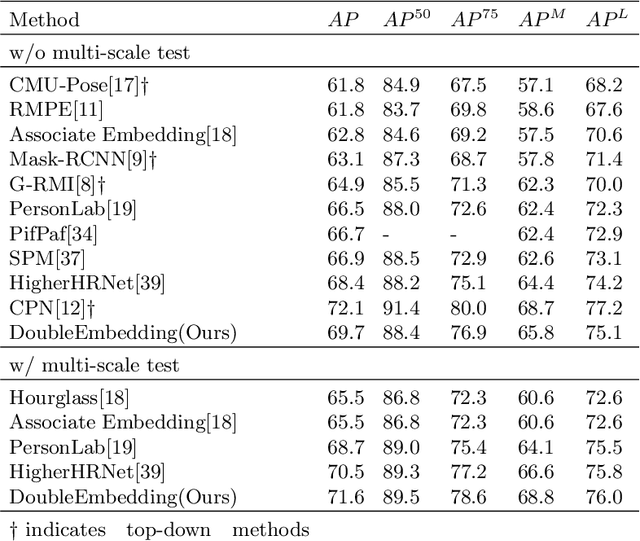
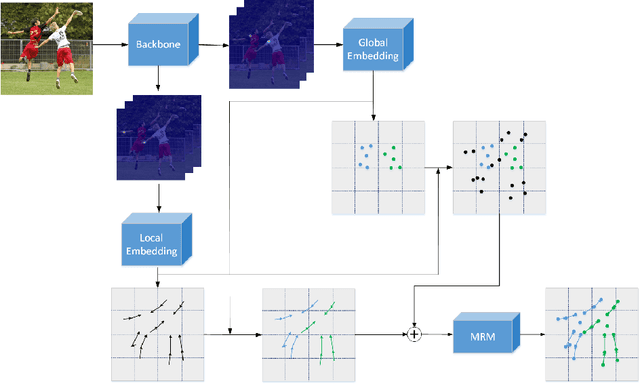
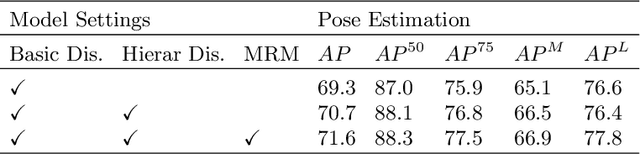
Multi-person pose estimation is a fundamental and challenging problem to many computer vision tasks. Most existing methods can be broadly categorized into two classes: top-down and bottom-up methods. Both of the two types of methods involve two stages, namely, person detection and joints detection. Conventionally, the two stages are implemented separately without considering their interactions between them, and this may inevitably cause some issue intrinsically. In this paper, we present a novel method to simplify the pipeline by implementing person detection and joints detection simultaneously. We propose a Double Embedding (DE) method to complete the multi-person pose estimation task in a global-to-local way. DE consists of Global Embedding (GE) and Local Embedding (LE). GE encodes different person instances and processes information covering the whole image and LE encodes the local limbs information. GE functions for the person detection in top-down strategy while LE connects the rest joints sequentially which functions for joint grouping and information processing in A bottom-up strategy. Based on LE, we design the Mutual Refine Machine (MRM) to reduce the prediction difficulty in complex scenarios. MRM can effectively realize the information communicating between keypoints and further improve the accuracy. We achieve the competitive results on benchmarks MSCOCO, MPII and CrowdPose, demonstrating the effectiveness and generalization ability of our method.
Generative Adversarial Networks for Synthesizing InSAR Patches
Aug 03, 2020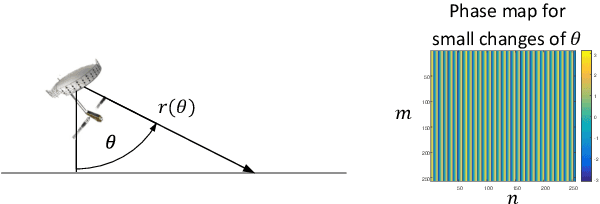
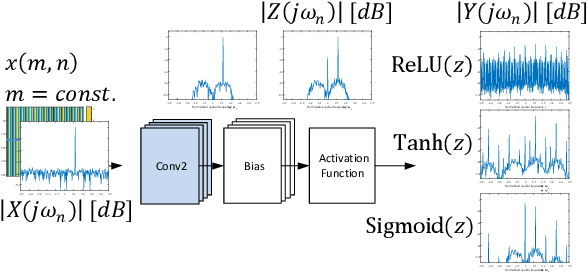
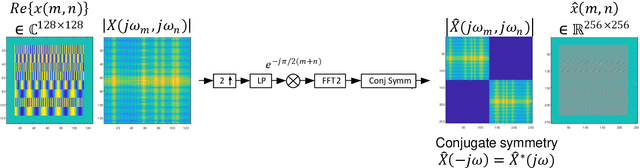
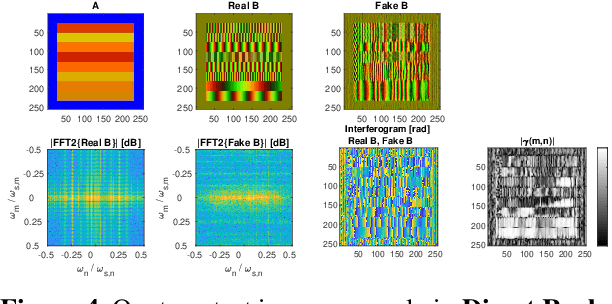
Generative Adversarial Networks (GANs) have been employed with certain success for image translation tasks between optical and real-valued SAR intensity imagery. Applications include aiding interpretability of SAR scenes with their optical counterparts by artificial patch generation and automatic SAR-optical scene matching. The synthesis of artificial complex-valued InSAR image stacks asks for, besides good perceptual quality, more stringent quality metrics like phase noise and phase coherence. This paper provides a signal processing model of generative CNN structures, describes effects influencing those quality metrics and presents a mapping scheme of complex-valued data to given CNN structures based on popular Deep Learning frameworks.
NUAA-QMUL at SemEval-2020 Task 8: Utilizing BERT and DenseNet for Internet Meme Emotion Analysis
Nov 09, 2020
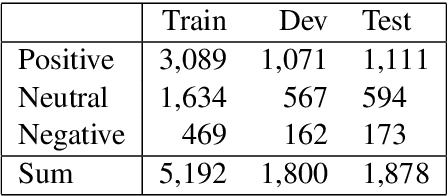


This paper describes our contribution to SemEval 2020 Task 8: Memotion Analysis. Our system learns multi-modal embeddings from text and images in order to classify Internet memes by sentiment. Our model learns text embeddings using BERT and extracts features from images with DenseNet, subsequently combining both features through concatenation. We also compare our results with those produced by DenseNet, ResNet, BERT, and BERT-ResNet. Our results show that image classification models have the potential to help classifying memes, with DenseNet outperforming ResNet. Adding text features is however not always helpful for Memotion Analysis.
Fully automated analysis of muscle architecture from B-mode ultrasound images with deep learning
Sep 10, 2020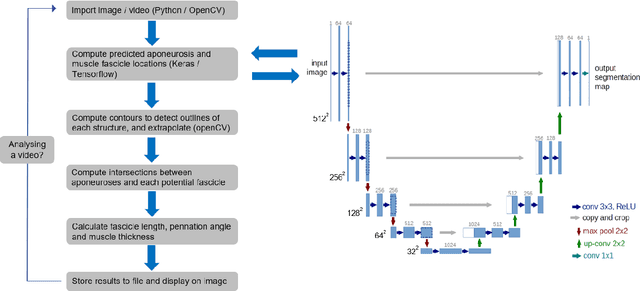
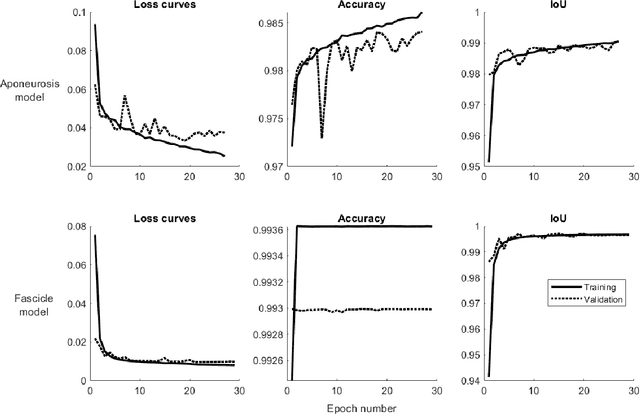

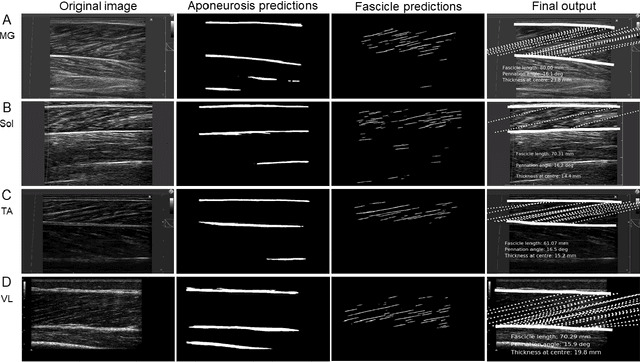
B-mode ultrasound is commonly used to image musculoskeletal tissues, but one major bottleneck is data interpretation, and analyses of muscle thickness, pennation angle and fascicle length are often still performed manually. In this study we trained deep neural networks (based on U-net) to detect muscle fascicles and aponeuroses using a set of labelled musculoskeletal ultrasound images. We then compared neural network predictions on new, unseen images to those obtained via manual analysis and two existing semi/automated analysis approaches (SMA and Ultratrack). With a GPU, inference time for a single image with the new approach was around 0.7s, compared to 4.6s with a CPU. Our method detects the locations of the superficial and deep aponeuroses, as well as multiple fascicle fragments per image. For single images, the method gave similar results to those produced by a non-trainable automated method (SMA; mean difference in fascicle length: 1.1 mm) or human manual analysis (mean difference: 2.1 mm). Between-method differences in pennation angle were within 1$^\circ$, and mean differences in muscle thickness were less than 0.2 mm. Similarly, for videos, there was strong overlap between the results produced with Ultratrack and our method, with a mean ICC of 0.73, despite the fact that the analysed trials included hundreds of frames. Our method is fully automated and open source, and can estimate fascicle length, pennation angle and muscle thickness from single images or videos, as well as from multiple superficial muscles. We also provide all necessary code and training data for custom model development.
Unsupervised Pathology Image Segmentation Using Representation Learning with Spherical K-means
Apr 11, 2018This paper presents a novel method for unsupervised segmentation of pathology images. Staging of lung cancer is a major factor of prognosis. Measuring the maximum dimensions of the invasive component in a pathology images is an essential task. Therefore, image segmentation methods for visualizing the extent of invasive and noninvasive components on pathology images could support pathological examination. However, it is challenging for most of the recent segmentation methods that rely on supervised learning to cope with unlabeled pathology images. In this paper, we propose a unified approach to unsupervised representation learning and clustering for pathology image segmentation. Our method consists of two phases. In the first phase, we learn feature representations of training patches from a target image using the spherical k-means. The purpose of this phase is to obtain cluster centroids which could be used as filters for feature extraction. In the second phase, we apply conventional k-means to the representations extracted by the centroids and then project cluster labels to the target images. We evaluated our methods on pathology images of lung cancer specimen. Our experiments showed that the proposed method outperforms traditional k-means segmentation and the multithreshold Otsu method both quantitatively and qualitatively with an improved normalized mutual information (NMI) score of 0.626 compared to 0.168 and 0.167, respectively. Furthermore, we found that the centroids can be applied to the segmentation of other slices from the same sample.
* This paper was presented at SPIE Medical Imaging 2018, Houston, TX, USA
Boundary-Aware Geometric Encoding for Semantic Segmentation of Point Clouds
Jan 07, 2021
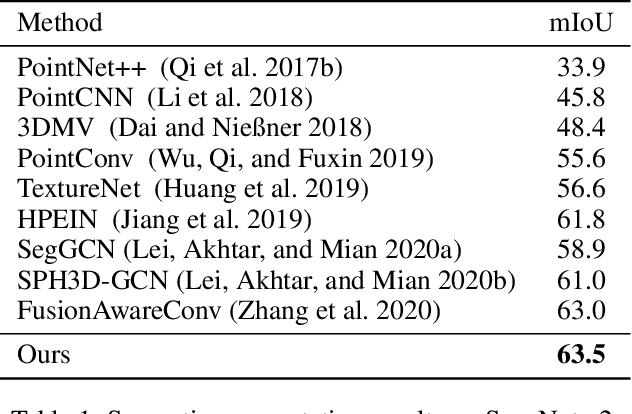
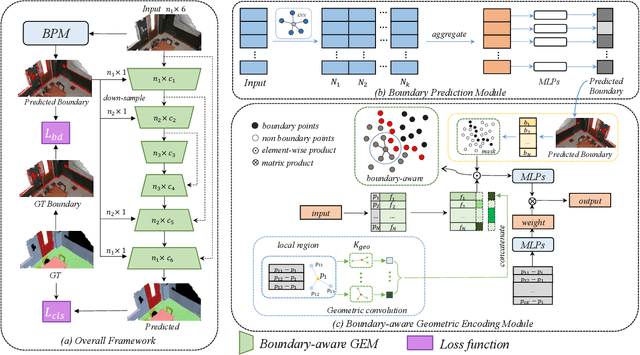
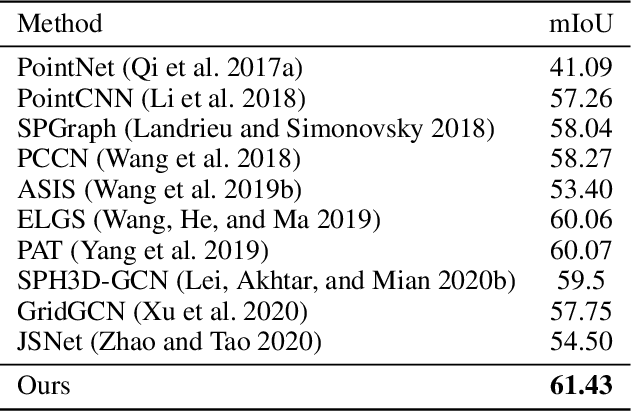
Boundary information plays a significant role in 2D image segmentation, while usually being ignored in 3D point cloud segmentation where ambiguous features might be generated in feature extraction, leading to misclassification in the transition area between two objects. In this paper, firstly, we propose a Boundary Prediction Module (BPM) to predict boundary points. Based on the predicted boundary, a boundary-aware Geometric Encoding Module (GEM) is designed to encode geometric information and aggregate features with discrimination in a neighborhood, so that the local features belonging to different categories will not be polluted by each other. To provide extra geometric information for boundary-aware GEM, we also propose a light-weight Geometric Convolution Operation (GCO), making the extracted features more distinguishing. Built upon the boundary-aware GEM, we build our network and test it on benchmarks like ScanNet v2, S3DIS. Results show our methods can significantly improve the baseline and achieve state-of-the-art performance. Code is available at https://github.com/JchenXu/BoundaryAwareGEM.