 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Infrared and Visible Image Fusion with ResNet and zero-phase component analysis
Jul 31, 2018
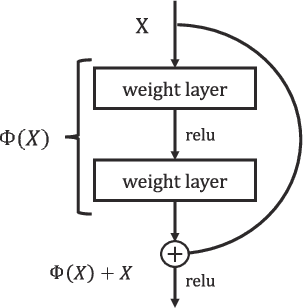
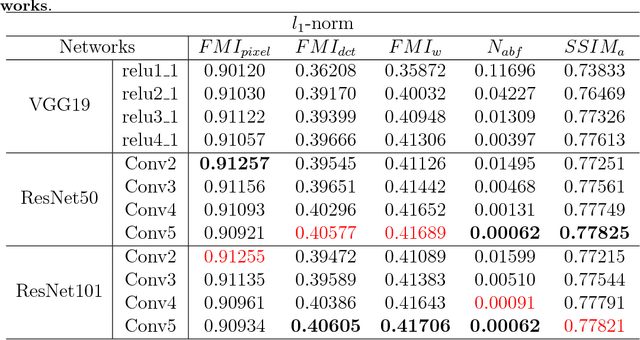
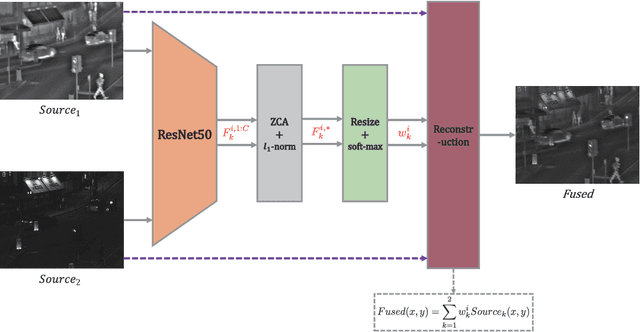
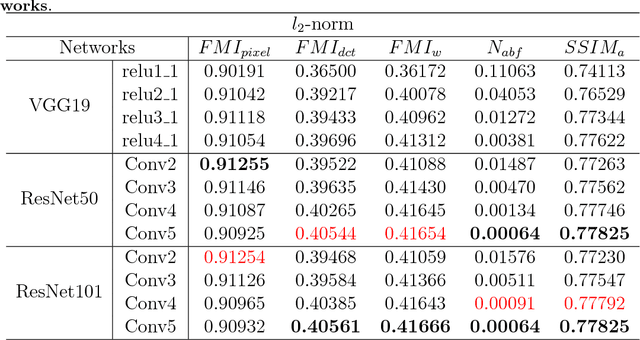
Feature extraction and processing are key tasks in the Image fusion algorithm, while most of deep learning-based methods use deep features directly without feature processing. This leads to the fusion performance degradation in some cases. To solve this drawback, in this paper, a novel fusion framework based on deep features and zero-phase component analysis (ZCA) is proposed. Firstly, the residual network (ResNet) is used to extract deep features from source images. Then ZCA and l_1-norm are utilized to normalize the deep features and obtain initial weight maps. The final weight maps are obtained by employing a soft-max operation in association with the initial weight maps. Finally, the fused image is reconstructed using a weighted-averaging strategy. Compared with the existing fusion methods, experimental results demonstrate that the proposed algorithm achieves better performance in both objective assessment and visual quality. The code of our fusion algorithm is available at https://github.com/exceptionLi/imagefusion_resnet50
Fine-graind Image Classification via Combining Vision and Language
May 03, 2017
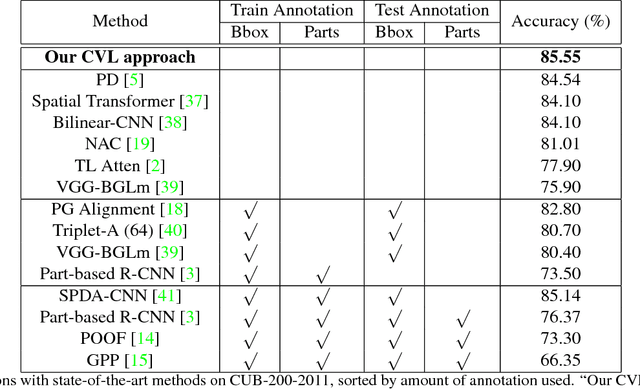
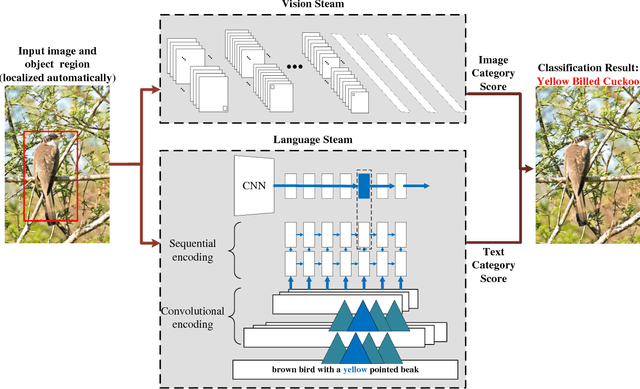

Fine-grained image classification is a challenging task due to the large intra-class variance and small inter-class variance, aiming at recognizing hundreds of sub-categories belonging to the same basic-level category. Most existing fine-grained image classification methods generally learn part detection models to obtain the semantic parts for better classification accuracy. Despite achieving promising results, these methods mainly have two limitations: (1) not all the parts which obtained through the part detection models are beneficial and indispensable for classification, and (2) fine-grained image classification requires more detailed visual descriptions which could not be provided by the part locations or attribute annotations. For addressing the above two limitations, this paper proposes the two-stream model combining vision and language (CVL) for learning latent semantic representations. The vision stream learns deep representations from the original visual information via deep convolutional neural network. The language stream utilizes the natural language descriptions which could point out the discriminative parts or characteristics for each image, and provides a flexible and compact way of encoding the salient visual aspects for distinguishing sub-categories. Since the two streams are complementary, combining the two streams can further achieves better classification accuracy. Comparing with 12 state-of-the-art methods on the widely used CUB-200-2011 dataset for fine-grained image classification, the experimental results demonstrate our CVL approach achieves the best performance.
Deep Learning for Android Malware Defenses: a Systematic Literature Review
Mar 09, 2021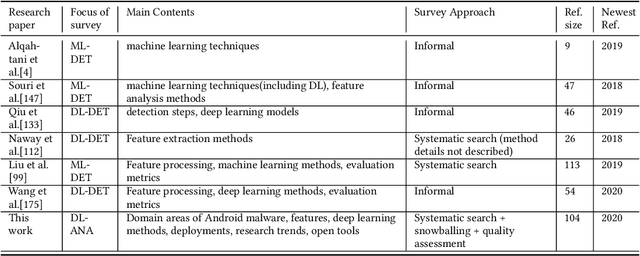
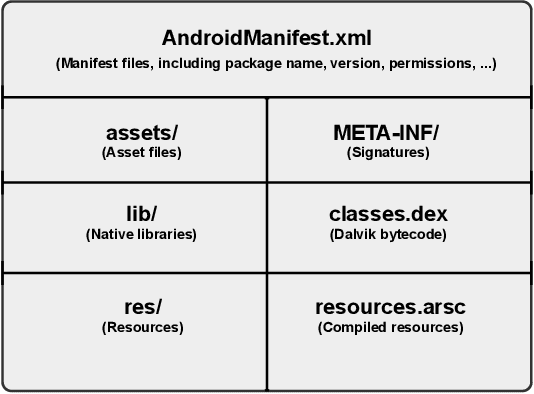
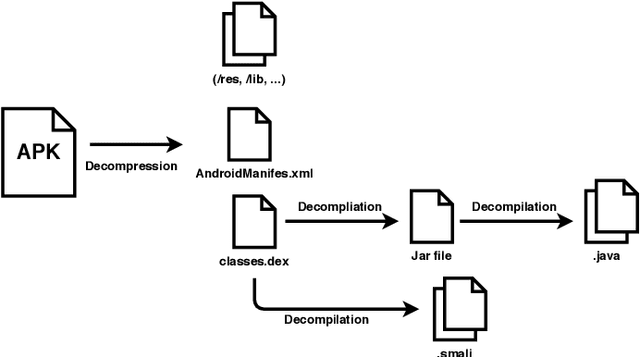

Malicious applications (especially in the Android platform) are a serious threat to developers and end-users. Many research efforts have hence been devoted to developing effective approaches to defend Android malware. However, with the explosive growth of Android malware and the continuous advancement of malicious evasion technologies like obfuscation and reflection, android malware defenses based on manual rules or traditional machine learning may not be effective due to limited apriori knowledge. In recent years, a dominant research field of deep learning (DL) with the powerful feature abstraction ability has demonstrated a compelling and promising performance in various fields, like Nature Language processing and image processing. To this end, employing deep learning techniques to thwart the attack of Android malware has recently gained considerable research attention. Yet, there exists no systematic literature review that focuses on deep learning approaches for Android Malware defenses. In this paper, we conducted a systematic literature review to search and analyze how deep learning approaches have been applied in the context of malware defenses in the Android environment. As a result, a total of 104 studies were identified over the period 2014-2020. The results of our investigation show that even though most of these studies still mainly consider DL-based on Android malware detection, 35 primary studies (33.7\%) design the defenses approaches based on other scenarios. This review also describes research trends, research focuses, challenges, and future research directions in DL-based Android malware defenses.
2D histology meets 3D topology: Cytoarchitectonic brain mapping with Graph Neural Networks
Mar 09, 2021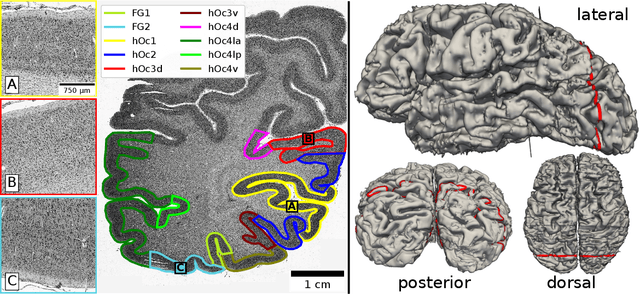
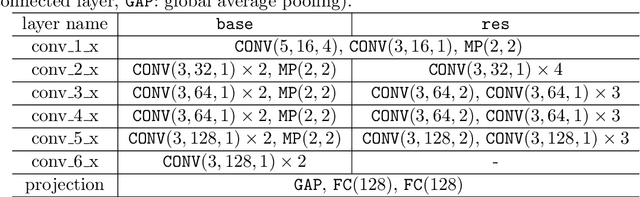
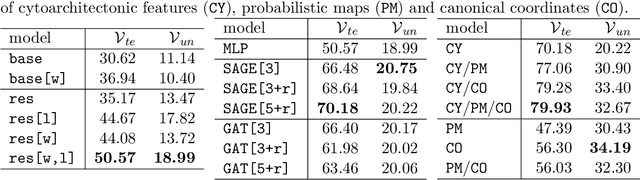
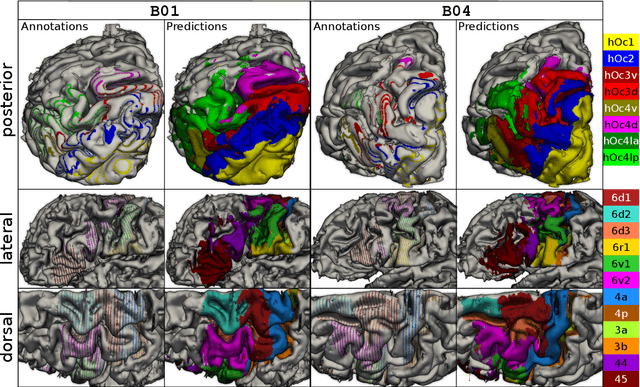
Cytoarchitecture describes the spatial organization of neuronal cells in the brain, including their arrangement into layers and columns with respect to cell density, orientation, or presence of certain cell types. It allows to segregate the brain into cortical areas and subcortical nuclei, links structure with connectivity and function, and provides a microstructural reference for human brain atlases. Mapping boundaries between areas requires to scan histological sections at microscopic resolution. While recent high-throughput scanners allow to scan a complete human brain in the order of a year, it is practically impossible to delineate regions at the same pace using the established gold standard method. Researchers have recently addressed cytoarchitectonic mapping of cortical regions with deep neural networks, relying on image patches from individual 2D sections for classification. However, the 3D context, which is needed to disambiguate complex or obliquely cut brain regions, is not taken into account. In this work, we combine 2D histology with 3D topology by reformulating the mapping task as a node classification problem on an approximate 3D midsurface mesh through the isocortex. We extract deep features from cortical patches in 2D histological sections which are descriptive of cytoarchitecture, and assign them to the corresponding nodes on the 3D mesh to construct a large attributed graph. By solving the brain mapping problem on this graph using graph neural networks, we obtain significantly improved classification results. The proposed framework lends itself nicely to integration of additional neuroanatomical priors for mapping.
Fast and Robust Symmetric Image Registration Based on Intensity and Spatial Information
Jul 30, 2018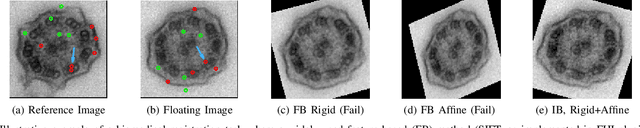
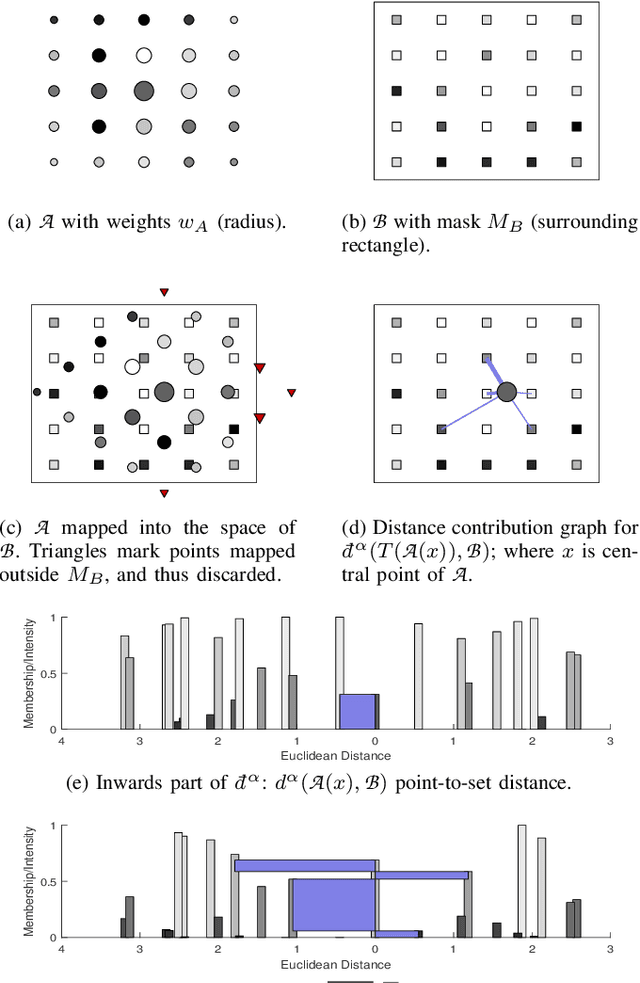
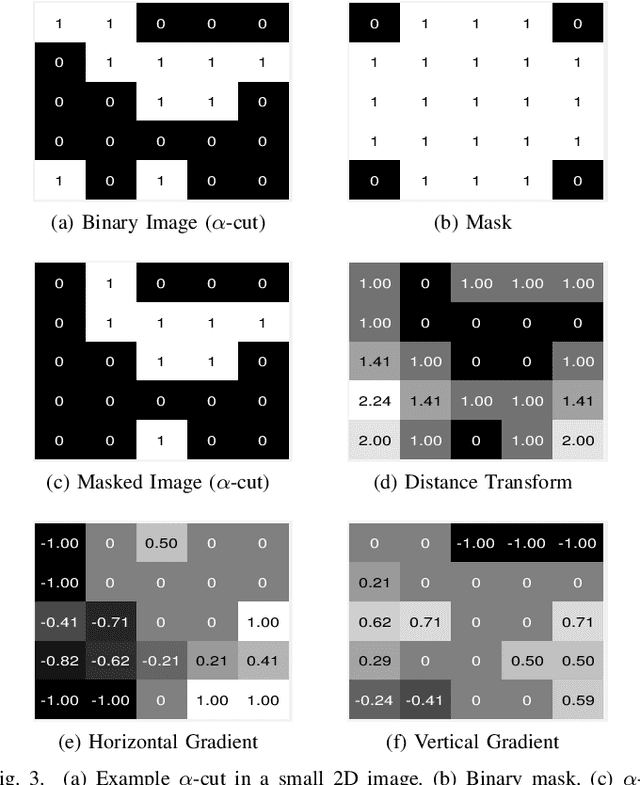
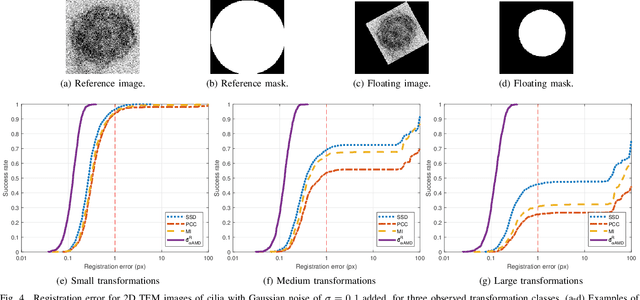
Intensity-based image registration approaches rely on similarity measures to guide the search for geometric correspondences with high affinity between images. The properties of the used measure are vital for the robustness and accuracy of the registration. In this study a symmetric, intensity interpolation-free, affine registration framework based on a combination of intensity and spatial information is proposed. The excellent performance of the framework is demonstrated on a combination of synthetic tests, recovering known transformations in the presence of noise, and real applications in biomedical and medical image registration, for both 2D and 3D images. The method exhibits greater robustness and higher accuracy than similarity measures in common use, when inserted into a standard gradient-based registration framework available as part of the open source Insight Segmentation and Registration Toolkit (ITK). The method is also empirically shown to have a low computational cost, making it practical for real applications. Source code is available.
Transfer Learning Based Automatic Model Creation Tool For Resource Constraint Devices
Dec 18, 2020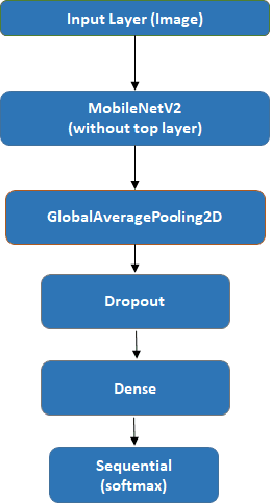
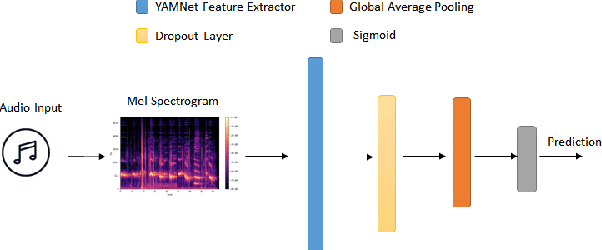
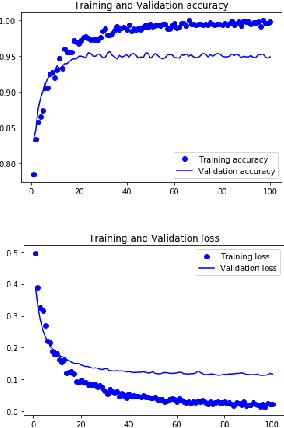
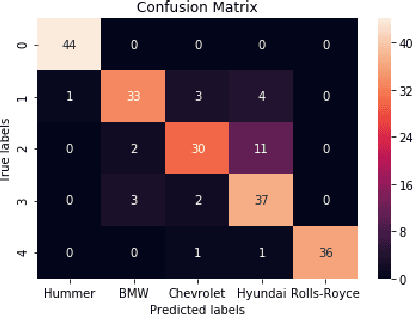
With the enhancement of Machine Learning, many tools are being designed to assist developers to easily create their Machine Learning models. In this paper, we propose a novel method for auto creation of such custom models for constraint devices using transfer learning without the need to write any machine learning code. We share the architecture of our automatic model creation tool and the CNN Model created by it using pretrained models such as YAMNet and MobileNetV2 as feature extractors. Finally, we demonstrate accuracy and memory footprint of the model created from the tool by creating an Automatic Image and Audio classifier and report the results of our experiments using Stanford Cars and ESC-50 dataset.
Adversarial Defense of Image Classification Using a Variational Auto-Encoder
Dec 07, 2018
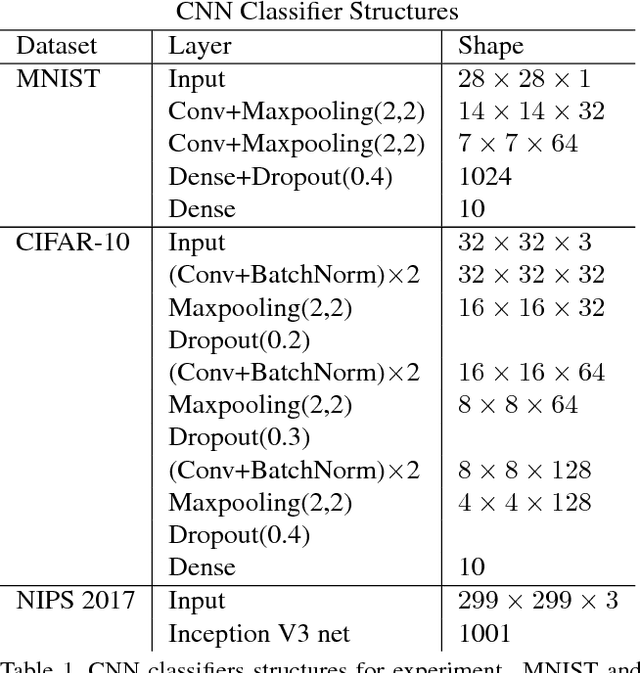
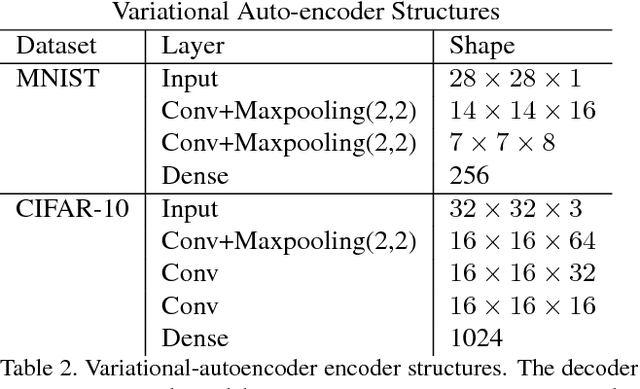
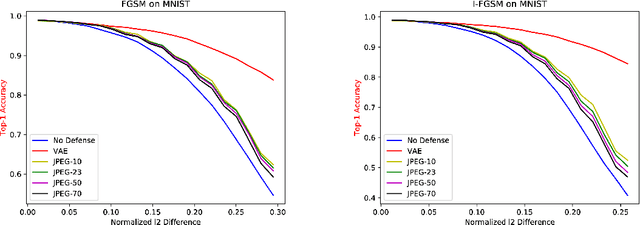
Deep neural networks are known to be vulnerable to adversarial attacks. This exposes them to potential exploits in security-sensitive applications and highlights their lack of robustness. This paper uses a variational auto-encoder (VAE) to defend against adversarial attacks for image classification tasks. This VAE defense has a few nice properties: (1) it is quite flexible and its use of randomness makes it harder to attack; (2) it can learn disentangled representations that prevent blurry reconstruction; and (3) a patch-wise VAE defense strategy is used that does not require retraining for different size images. For moderate to severe attacks, this system outperforms or closely matches the performance of JPEG compression, with the best quality parameter. It also has more flexibility and potential for improvement via training.
Adversarial Examples in Constrained Domains
Nov 02, 2020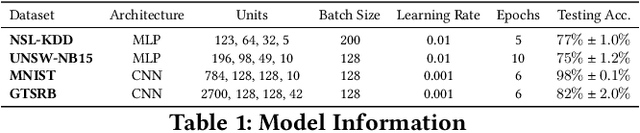
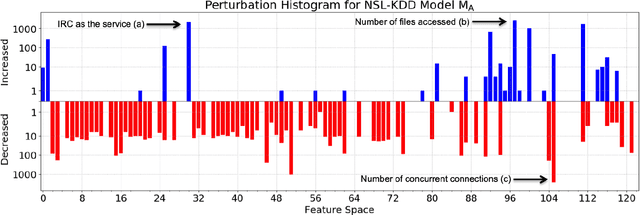
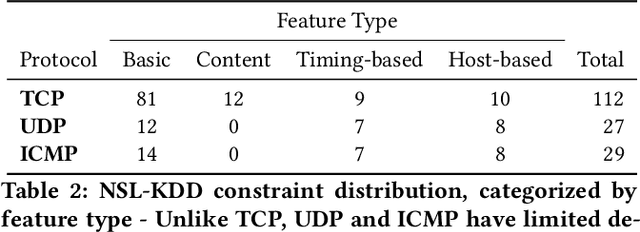
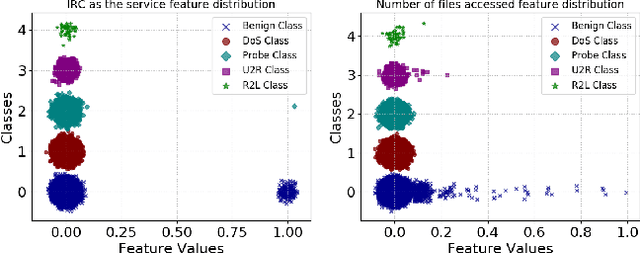
Machine learning algorithms have been shown to be vulnerable to adversarial manipulation through systematic modification of inputs (e.g., adversarial examples) in domains such as image recognition. Under the default threat model, the adversary exploits the unconstrained nature of images; each feature (pixel) is fully under control of the adversary. However, it is not clear how these attacks translate to constrained domains that limit which and how features can be modified by the adversary (e.g., network intrusion detection). In this paper, we explore whether constrained domains are less vulnerable than unconstrained domains to adversarial example generation algorithms. We create an algorithm for generating adversarial sketches: targeted universal perturbation vectors which encode feature saliency within the envelope of domain constraints. To assess how these algorithms perform, we evaluate them in constrained (e.g., network intrusion detection) and unconstrained (e.g., image recognition) domains. The results demonstrate that our approaches generate misclassification rates in constrained domains that were comparable to those of unconstrained domains (greater than 95%). Our investigation shows that the narrow attack surface exposed by constrained domains is still sufficiently large to craft successful adversarial examples; and thus, constraints do not appear to make a domain robust. Indeed, with as little as five randomly selected features, one can still generate adversarial examples.
Exercise? I thought you said 'Extra Fries': Leveraging Sentence Demarcations and Multi-hop Attention for Meme Affect Analysis
Mar 23, 2021

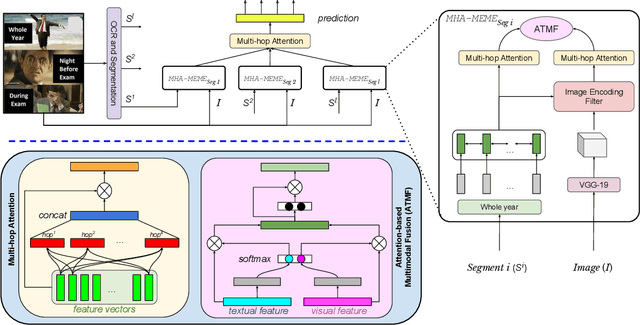
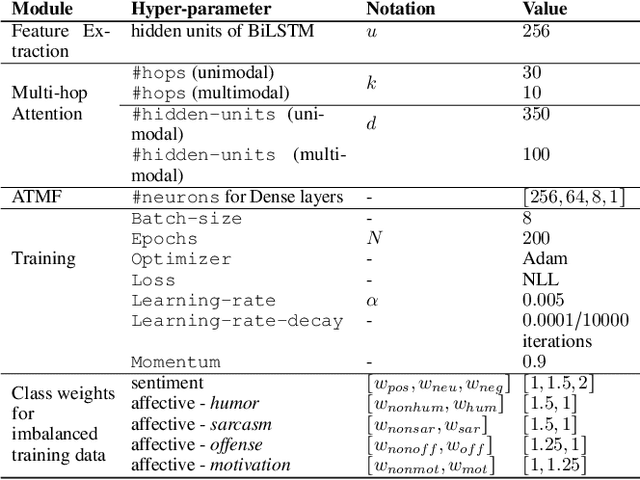
Today's Internet is awash in memes as they are humorous, satirical, or ironic which make people laugh. According to a survey, 33% of social media users in age bracket [13-35] send memes every day, whereas more than 50% send every week. Some of these memes spread rapidly within a very short time-frame, and their virality depends on the novelty of their (textual and visual) content. A few of them convey positive messages, such as funny or motivational quotes; while others are meant to mock/hurt someone's feelings through sarcastic or offensive messages. Despite the appealing nature of memes and their rapid emergence on social media, effective analysis of memes has not been adequately attempted to the extent it deserves. In this paper, we attempt to solve the same set of tasks suggested in the SemEval'20-Memotion Analysis competition. We propose a multi-hop attention-based deep neural network framework, called MHA-MEME, whose prime objective is to leverage the spatial-domain correspondence between the visual modality (an image) and various textual segments to extract fine-grained feature representations for classification. We evaluate MHA-MEME on the 'Memotion Analysis' dataset for all three sub-tasks - sentiment classification, affect classification, and affect class quantification. Our comparative study shows sota performances of MHA-MEME for all three tasks compared to the top systems that participated in the competition. Unlike all the baselines which perform inconsistently across all three tasks, MHA-MEME outperforms baselines in all the tasks on average. Moreover, we validate the generalization of MHA-MEME on another set of manually annotated test samples and observe it to be consistent. Finally, we establish the interpretability of MHA-MEME.
Demonstrating the Evolution of GANs through t-SNE
Jan 31, 2021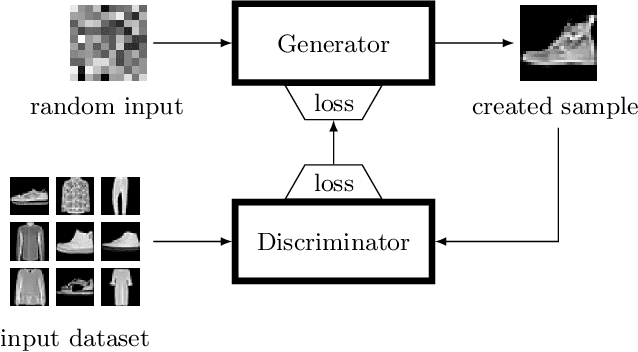
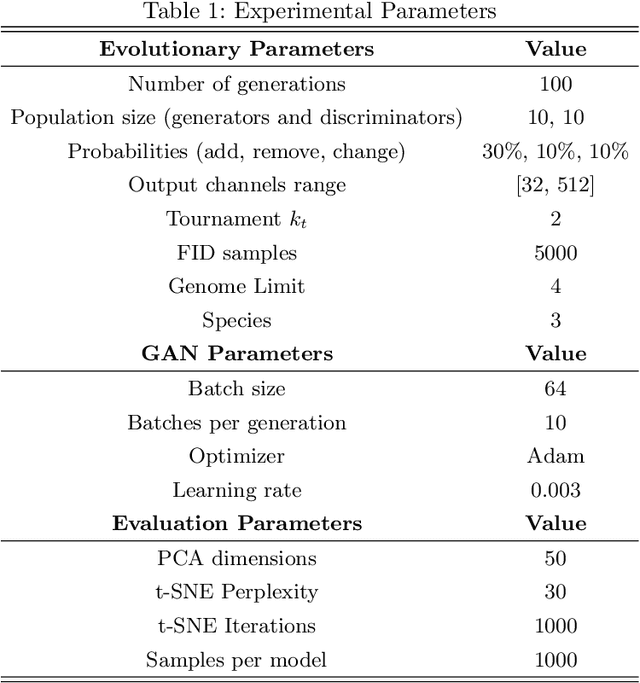
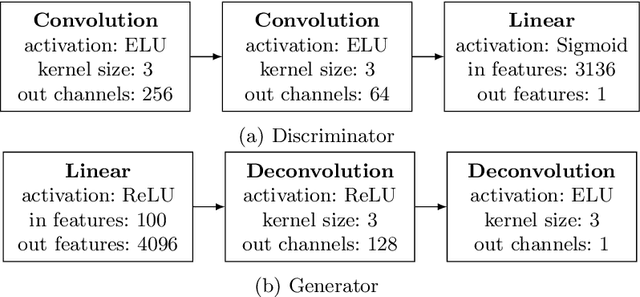
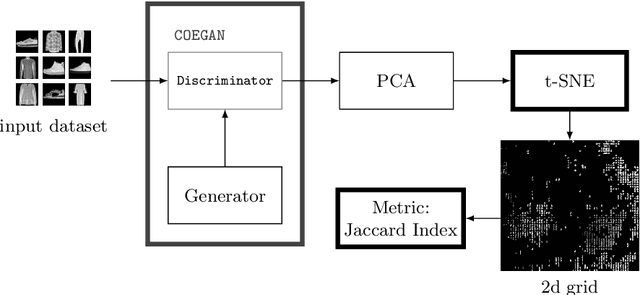
Generative Adversarial Networks (GANs) are powerful generative models that achieved strong results, mainly in the image domain. However, the training of GANs is not trivial, presenting some challenges tackled by different strategies. Evolutionary algorithms, such as COEGAN, were recently proposed as a solution to improve the GAN training, overcoming common problems that affect the model, such as vanishing gradient and mode collapse. In this work, we propose an evaluation method based on t-distributed Stochastic Neighbour Embedding (t-SNE) to assess the progress of GANs and visualize the distribution learned by generators in training. We propose the use of the feature space extracted from trained discriminators to evaluate samples produced by generators and from the input dataset. A metric based on the resulting t-SNE maps and the Jaccard index is proposed to represent the model quality. Experiments were conducted to assess the progress of GANs when trained using COEGAN. The results show both by visual inspection and metrics that the Evolutionary Algorithm gradually improves discriminators and generators through generations, avoiding problems such as mode collapse.