 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Holographic Visualisation of Radiology Data and Automated Machine Learning-based Medical Image Segmentation
Aug 15, 2018

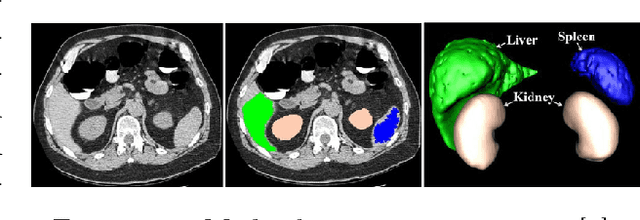
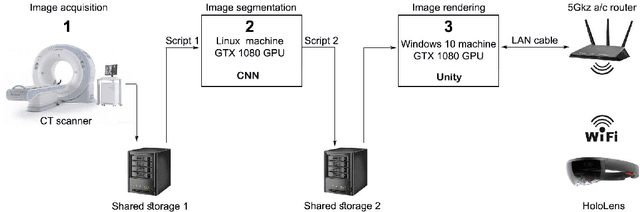
Within this thesis we propose a platform for combining Augmented Reality (AR) hardware with machine learning in a user-oriented pipeline, offering to the medical staff an intuitive 3D visualization of volumetric Computed Tomography (CT) and Magnetic Resonance Imaging (MRI) medical image segmentations inside the AR headset, that does not need human intervention for loading, processing and segmentation of medical images. The AR visualization, based on Microsoft HoloLens, employs a modular and thus scalable frontend-backend architecture for real-time visualizations on multiple AR headsets. As Convolutional Neural Networks (CNNs) have lastly demonstrated superior performance for the machine learning task of image semantic segmentation, the pipeline also includes a fully automated CNN algorithm for the segmentation of the liver from CT scans. The model is based on the Deep Retinal Image Understanding (DRIU) model which is a Fully Convolutional Network with side outputs from feature maps with different resolution, extracted at different stages of the network. The algorithm is 2.5D which means that the input is a set of consecutive scan slices. The experiments have been performed on the Liver Tumor Segmentation Challenge (LiTS) dataset for liver segmentation and demonstrated good results and flexibility. While multiple approaches exist in the domain, only few of them have focused on overcoming the practical aspects which still largely hold this technology away from the operating rooms. In line with this, we also are next planning an evaluation from medical doctors and radiologists in a real-world environment.
Deep Momentum Uncertainty Hashing
Sep 17, 2020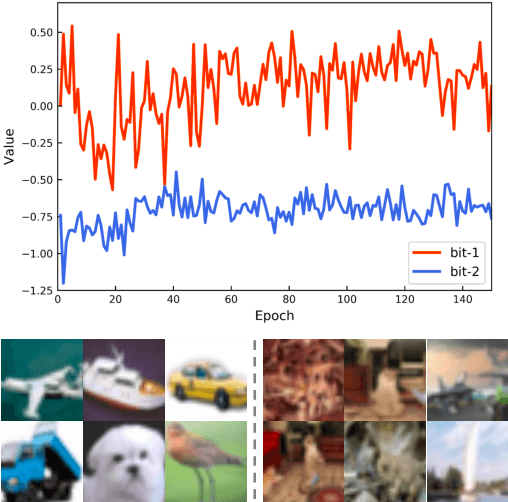
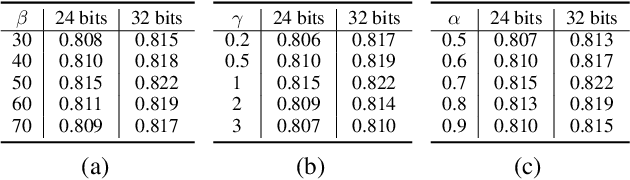
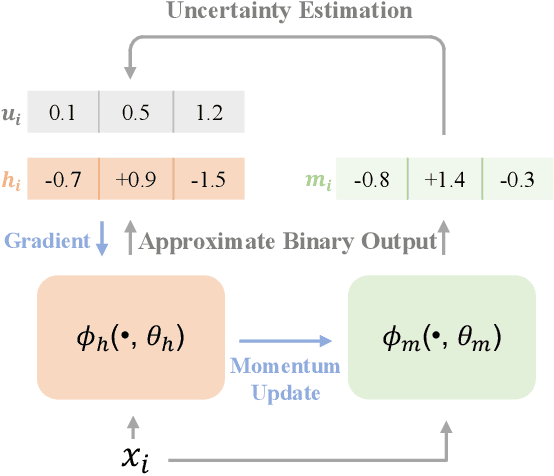
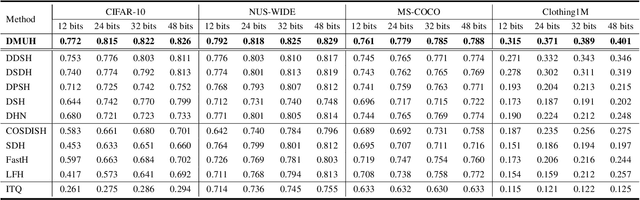
Discrete optimization is one of the most intractable problems in deep hashing. Previous methods usually mitigate this problem by binary approximation, substituting binary codes for real-values via activation functions or regularizations. However, such approximation leads to uncertainty between real-values and binary ones, degrading retrieval performance. In this paper, we propose a novel Deep Momentum Uncertainty Hashing (DMUH). It explicitly estimates the uncertainty during training and leverages the uncertainty information to guide the approximation process. Specifically, we model \emph{bit-level uncertainty} via measuring the discrepancy between the output of a hashing network and that of a momentum-updated network. The discrepancy of each bit indicates the uncertainty of the hashing network to the approximate output of that bit. Meanwhile, the mean discrepancy of all bits in a hashing code can be regarded as \emph{image-level uncertainty}. It embodies the uncertainty of the hashing network to the corresponding input image. The hashing bit and the image with higher uncertainty are paid more attention during optimization. To the best of our knowledge, this is the first work to study the uncertainty in hashing bits. Extensive experiments are conducted on four datasets to verify the superiority of our method, including CIFAR-10, NUS-WIDE, MS-COCO, and a million-scale dataset Clothing1M. Our method achieves best performance on all datasets and surpasses existing state-of-the-arts by a large margin, especially on Clothing1M.
Detailed Human Shape Estimation from a Single Image by Hierarchical Mesh Deformation
May 08, 2019
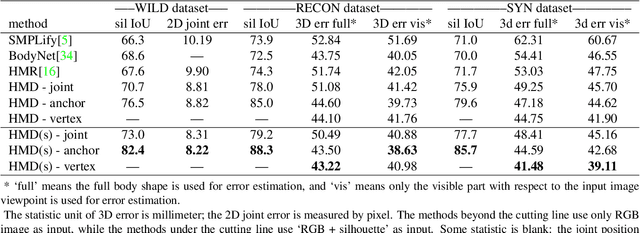

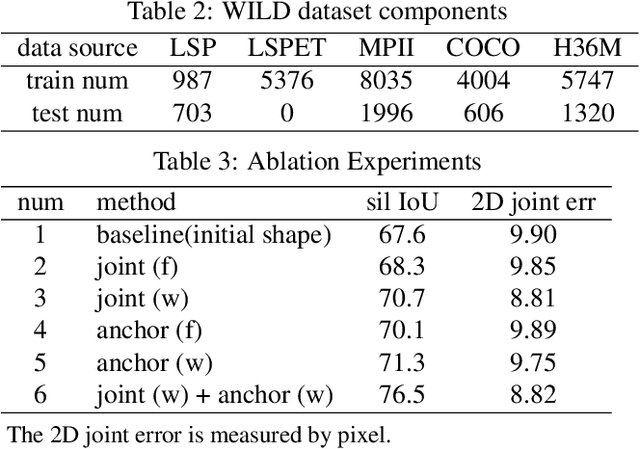
This paper presents a novel framework to recover detailed human body shapes from a single image. It is a challenging task due to factors such as variations in human shapes, body poses, and viewpoints. Prior methods typically attempt to recover the human body shape using a parametric based template that lacks the surface details. As such the resulting body shape appears to be without clothing. In this paper, we propose a novel learning-based framework that combines the robustness of parametric model with the flexibility of free-form 3D deformation. We use the deep neural networks to refine the 3D shape in a Hierarchical Mesh Deformation (HMD) framework, utilizing the constraints from body joints, silhouettes, and per-pixel shading information. We are able to restore detailed human body shapes beyond skinned models. Experiments demonstrate that our method has outperformed previous state-of-the-art approaches, achieving better accuracy in terms of both 2D IoU number and 3D metric distance. The code is available in https://github.com/zhuhao-nju/hmd.git
BIKED: A Dataset and Machine Learning Benchmarks for Data-Driven Bicycle Design
Mar 10, 2021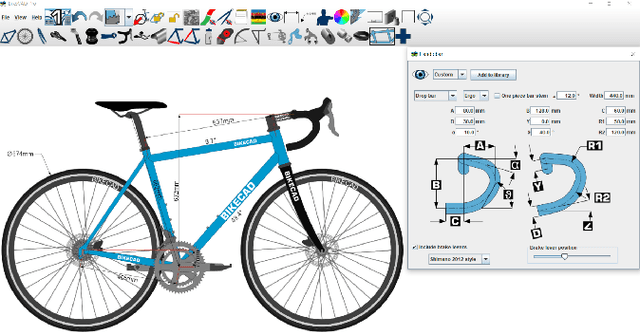
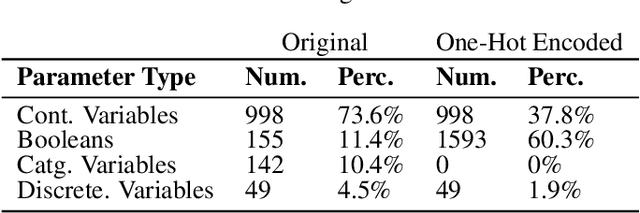

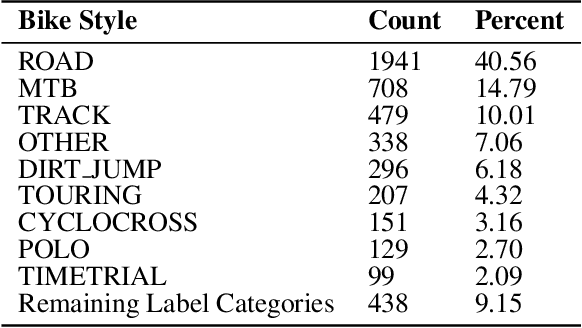
In this paper, we present "BIKED," a dataset comprised of 4500 individually designed bicycle models sourced from hundreds of designers. We expect BIKED to enable a variety of data-driven design applications for bicycles and generally support the development of data-driven design methods. The dataset is comprised of a variety of design information including assembly images, component images, numerical design parameters, and class labels. In this paper, we first discuss the processing of the dataset and present the various features provided. We then illustrate the scale, variety, and structure of the data using several unsupervised clustering studies. Next, we explore a variety of data-driven applications. We provide baseline classification performance for 10 algorithms trained on differing amounts of training data. We then contrast classification performance of three deep neural networks using parametric data, image data, and a combination of the two. Using one of the trained classification models, we conduct a Shapley Additive Explanations Analysis to better understand the extent to which certain design parameters impact classification predictions. Next, we test bike reconstruction and design synthesis using two Variational Autoencoders (VAEs) trained on images and parametric data. We furthermore contrast the performance of interpolation and extrapolation tasks in the original parameter space and the latent space of a VAE. Finally, we discuss some exciting possibilities for other applications beyond the few actively explored in this paper and summarize overall strengths and weaknesses of the dataset.
Learning Visual Context by Comparison
Jul 15, 2020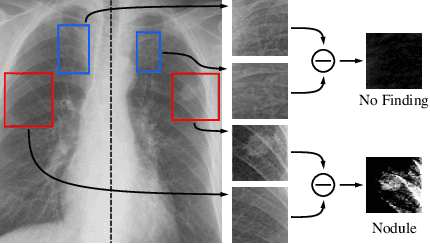

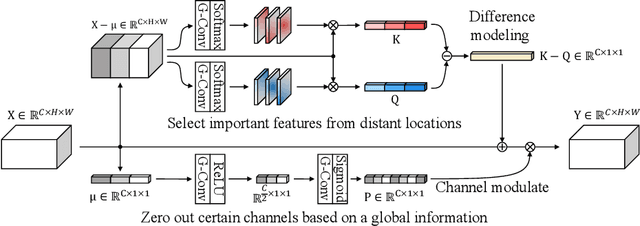
Finding diseases from an X-ray image is an important yet highly challenging task. Current methods for solving this task exploit various characteristics of the chest X-ray image, but one of the most important characteristics is still missing: the necessity of comparison between related regions in an image. In this paper, we present Attend-and-Compare Module (ACM) for capturing the difference between an object of interest and its corresponding context. We show that explicit difference modeling can be very helpful in tasks that require direct comparison between locations from afar. This module can be plugged into existing deep learning models. For evaluation, we apply our module to three chest X-ray recognition tasks and COCO object detection & segmentation tasks and observe consistent improvements across tasks. The code is available at https://github.com/mk-minchul/attend-and-compare.
Union is strength in lossy image compression
Jul 31, 2016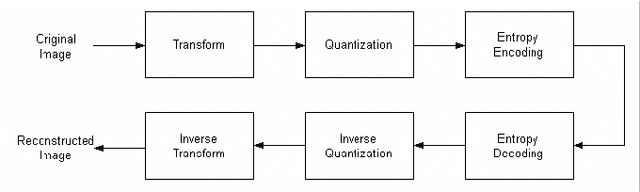
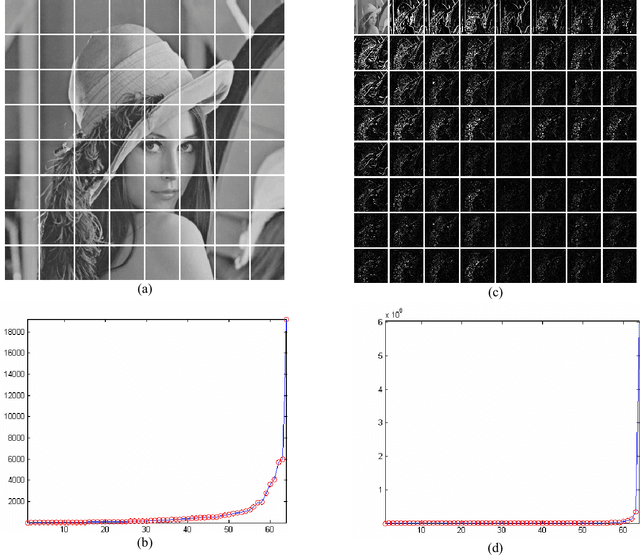
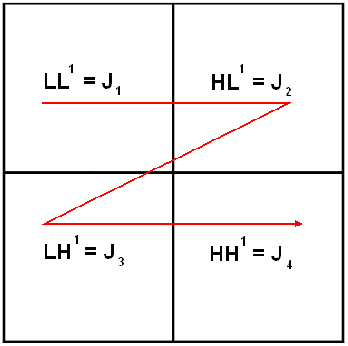
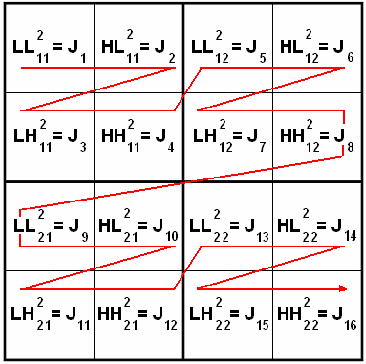
In this work, we present a comparison between different techniques of image compression. First, the image is divided in blocks which are organized according to a certain scan. Later, several compression techniques are applied, combined or alone. Such techniques are: wavelets (Haar's basis), Karhunen-Loeve Transform, etc. Simulations show that the combined versions are the best, with minor Mean Squared Error (MSE), and higher Peak Signal to Noise Ratio (PSNR) and better image quality, even in the presence of noise.
Shape-Texture Debiased Neural Network Training
Oct 12, 2020

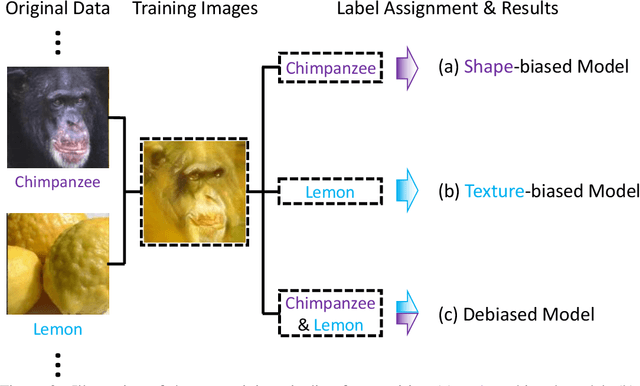
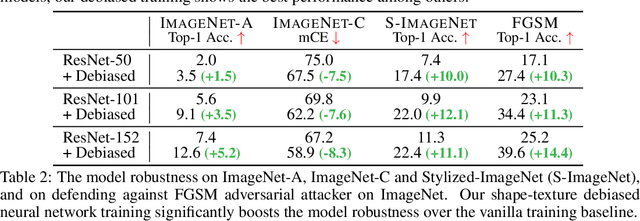
Shape and texture are two prominent and complementary cues for recognizing objects. Nonetheless, Convolutional Neural Networks are often biased towards either texture or shape, depending on the training dataset. Our ablation shows that such bias degenerates model performance. Motivated by this observation, we develop a simple algorithm for shape-texture debiased learning. To prevent models from exclusively attending on a single cue in representation learning, we augment training data with images with conflicting shape and texture information (e.g., an image of chimpanzee shape but with lemon texture) and, most importantly, provide the corresponding supervisions from shape and texture simultaneously. Experiments show that our method successfully improves model performance on several image recognition benchmarks and adversarial robustness. For example, by training on ImageNet, it helps ResNet-152 achieve substantial improvements on ImageNet (+1.2%), ImageNet-A (+5.2%), ImageNet-C (+8.3%) and Stylized-ImageNet (+11.1%), and on defending against FGSM adversarial attacker on ImageNet (+14.4%). Our method also claims to be compatible to other advanced data augmentation strategies, e.g., Mixup and CutMix. The code is available here: https://github.com/LiYingwei/ShapeTextureDebiasedTraining.
Structure-Aware Completion of Photogrammetric Meshes in Urban Road Environment
Nov 23, 2020

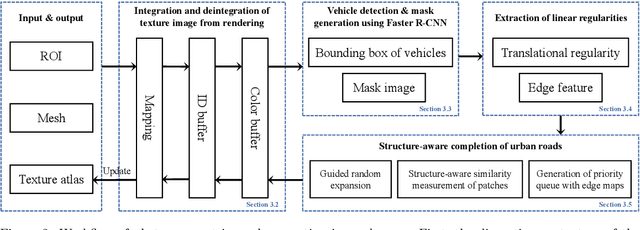

Photogrammetric mesh models obtained from aerial oblique images have been widely used for urban reconstruction. However, the photogrammetric meshes also suffer from severe texture problems, especially on the road areas due to occlusion. This paper proposes a structure-aware completion approach to improve the quality of meshes by removing undesired vehicles on the road seamlessly. Specifically, the discontinuous texture atlas is first integrated to a continuous screen space through rendering by the graphics pipeline; the rendering also records necessary mapping for deintegration to the original texture atlas after editing. Vehicle regions are masked by a standard object detection approach, e.g. Faster RCNN. Then, the masked regions are completed guided by the linear structures and regularities in the road region, which is implemented based on Patch Match. Finally, the completed rendered image is deintegrated to the original texture atlas and the triangles for the vehicles are also flattened for improved meshes. Experimental evaluations and analyses are conducted against three datasets, which are captured with different sensors and ground sample distances. The results reveal that the proposed method can quite realistic meshes after removing the vehicles. The structure-aware completion approach for road regions outperforms popular image completion methods and ablation study further confirms the effectiveness of the linear guidance. It should be noted that the proposed method is also capable to handle tiled mesh models for large-scale scenes. Dataset and code are available at vrlab.org.cn/~hanhu/projects/mesh.
A two-stage data association approach for 3D Multi-object Tracking
Jan 21, 2021
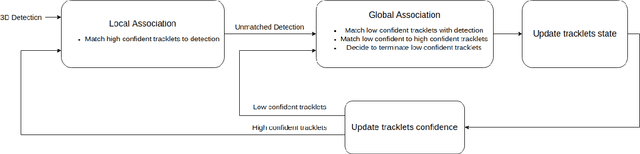
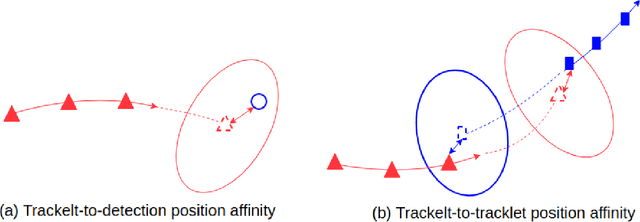
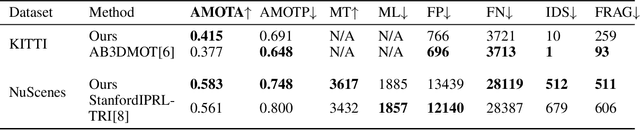
Multi-object tracking (MOT) is an integral part of any autonomous driving pipelines because itproduces trajectories which has been taken by other moving objects in the scene and helps predicttheir future motion. Thanks to the recent advances in 3D object detection enabled by deep learning,track-by-detection has become the dominant paradigm in 3D MOT. In this paradigm, a MOT systemis essentially made of an object detector and a data association algorithm which establishes track-to-detection correspondence. While 3D object detection has been actively researched, associationalgorithms for 3D MOT seem to settle at a bipartie matching formulated as a linear assignmentproblem (LAP) and solved by the Hungarian algorithm. In this paper, we adapt a two-stage dataassociation method which was successful in image-based tracking to the 3D setting, thus providingan alternative for data association for 3D MOT. Our method outperforms the baseline using one-stagebipartie matching for data association by achieving 0.587 AMOTA in NuScenes validation set.
Deep Network Ensemble Learning applied to Image Classification using CNN Trees
Jul 23, 2020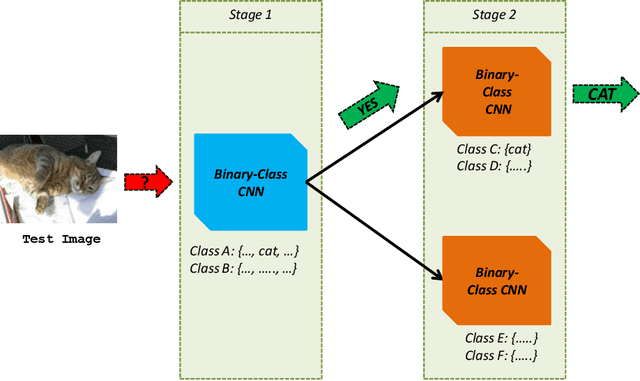

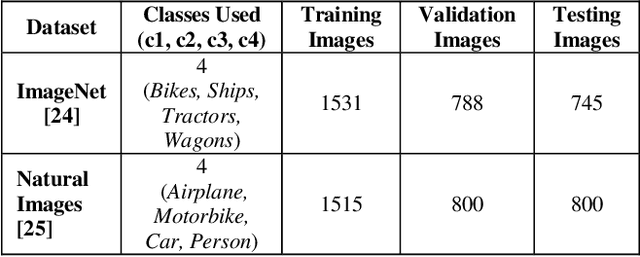
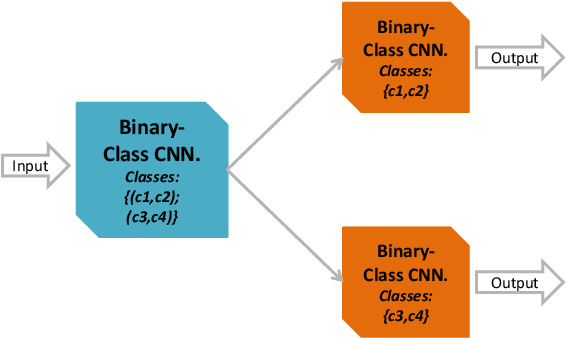
Traditional machine learning approaches may fail to perform satisfactorily when dealing with complex data. In this context, the importance of data mining evolves w.r.t. building an efficient knowledge discovery and mining framework. Ensemble learning is aimed at integration of fusion, modeling and mining of data into a unified model. However, traditional ensemble learning methods are complex and have optimization or tuning problems. In this paper, we propose a simple, sequential, efficient, ensemble learning approach using multiple deep networks. The deep network used in the ensembles is ResNet50. The model draws inspiration from binary decision/classification trees. The proposed approach is compared against the baseline viz. the single classifier approach i.e. using a single multiclass ResNet50 on the ImageNet and Natural Images datasets. Our approach outperforms the baseline on all experiments on the ImageNet dataset. Code is available in https://github.com/mueedhafiz1982/CNNTreeEnsemble.git