 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Randomized eigen-spectrograms extraction for an effective fault diagnosis of bearings
Mar 05, 2021
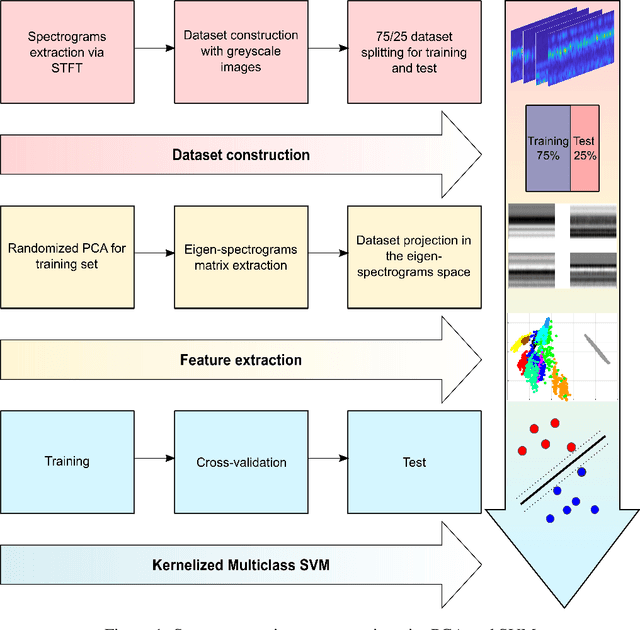

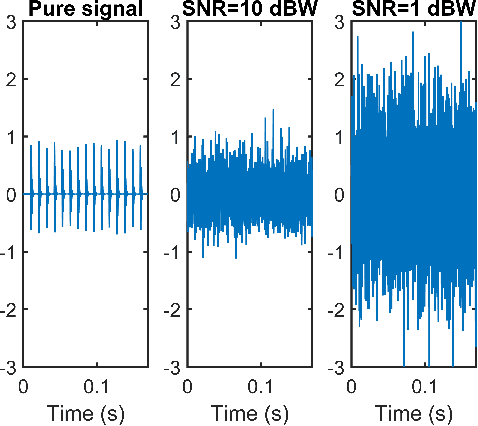

The Intelligent Fault Diagnosis of rotating machinery proposes some captivating challenges in light of the imminent big data era. Large amounts of data are expected to populate the Internet of Things (IoT) diagnostic services. Consequently, todays deep learning strategies are evolving towards effective approaches such as transfer learning to uncover hidden paths in extensive vibration data. However, this field is characterized by several open issues. Models interpretation is still buried under the foundations of data driven science, thus requiring attention to the development of new opportunities also for machine learning theories. This study proposes a diagnosis model, based on intelligent spectrogram recognition, via image processing. The novel approach is embodied by the introduction of the eigen-spectrograms and randomized linear algebra in fault diagnosis. The eigen-spectrograms hierarchically display inherent structures underlying spectrogram images. Also, different combinations of eigen-spectrograms are expected to describe multiple machine health states. Randomized algebra and eigen-spectrograms enable the construction of a significant feature space, which nonetheless emerges as a viable device to explore models interpretations. The computational efficiency of randomized approaches further collocates this methodology in the big data perspective and provides new reading keys of well-established statistical learning theories, such as the Support Vector Machine (SVM). The conjunction of randomized algebra and Support Vector Machine for spectrogram recognition shows to be extremely accurate and efficient as compared to state of the art results and transfer learning strategies.
Semantic Regularisation for Recurrent Image Annotation
Nov 16, 2016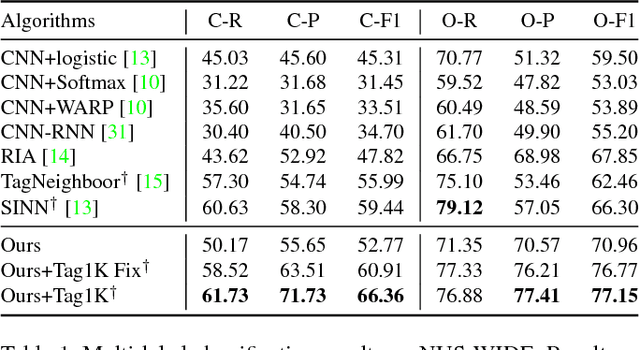

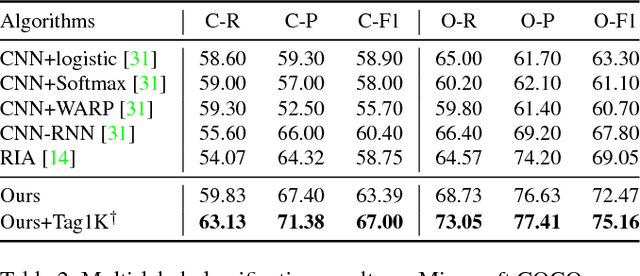

The "CNN-RNN" design pattern is increasingly widely applied in a variety of image annotation tasks including multi-label classification and captioning. Existing models use the weakly semantic CNN hidden layer or its transform as the image embedding that provides the interface between the CNN and RNN. This leaves the RNN overstretched with two jobs: predicting the visual concepts and modelling their correlations for generating structured annotation output. Importantly this makes the end-to-end training of the CNN and RNN slow and ineffective due to the difficulty of back propagating gradients through the RNN to train the CNN. We propose a simple modification to the design pattern that makes learning more effective and efficient. Specifically, we propose to use a semantically regularised embedding layer as the interface between the CNN and RNN. Regularising the interface can partially or completely decouple the learning problems, allowing each to be more effectively trained and jointly training much more efficient. Extensive experiments show that state-of-the art performance is achieved on multi-label classification as well as image captioning.
Generating Natural Questions from Images for Multimodal Assistants
Nov 17, 2020
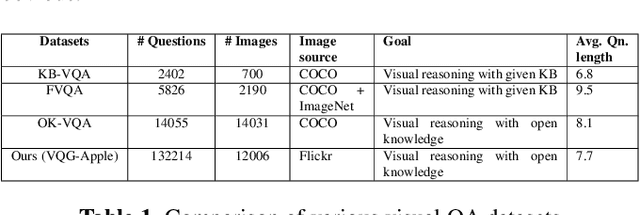

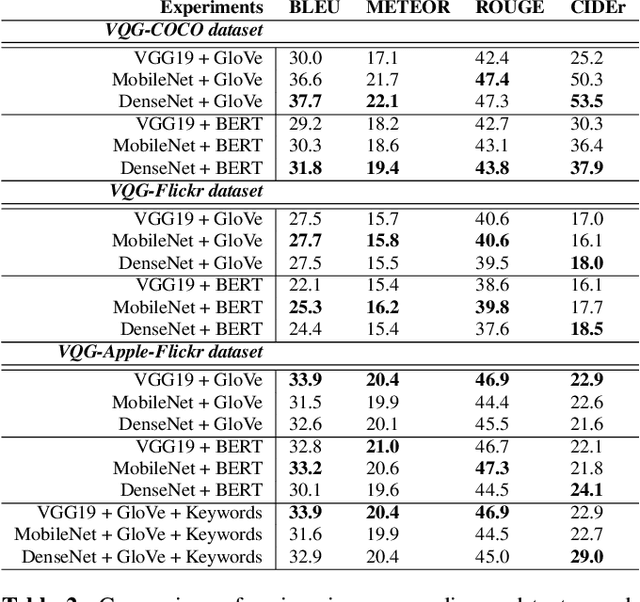
Generating natural, diverse, and meaningful questions from images is an essential task for multimodal assistants as it confirms whether they have understood the object and scene in the images properly. The research in visual question answering (VQA) and visual question generation (VQG) is a great step. However, this research does not capture questions that a visually-abled person would ask multimodal assistants. Recently published datasets such as KB-VQA, FVQA, and OK-VQA try to collect questions that look for external knowledge which makes them appropriate for multimodal assistants. However, they still contain many obvious and common-sense questions that humans would not usually ask a digital assistant. In this paper, we provide a new benchmark dataset that contains questions generated by human annotators keeping in mind what they would ask multimodal digital assistants. Large scale annotations for several hundred thousand images are expensive and time-consuming, so we also present an effective way of automatically generating questions from unseen images. In this paper, we present an approach for generating diverse and meaningful questions that consider image content and metadata of image (e.g., location, associated keyword). We evaluate our approach using standard evaluation metrics such as BLEU, METEOR, ROUGE, and CIDEr to show the relevance of generated questions with human-provided questions. We also measure the diversity of generated questions using generative strength and inventiveness metrics. We report new state-of-the-art results on the public and our datasets.
ROAD: The ROad event Awareness Dataset for Autonomous Driving
Feb 25, 2021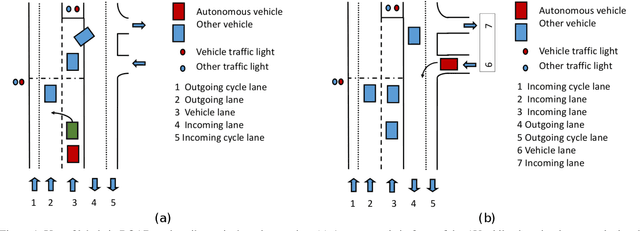

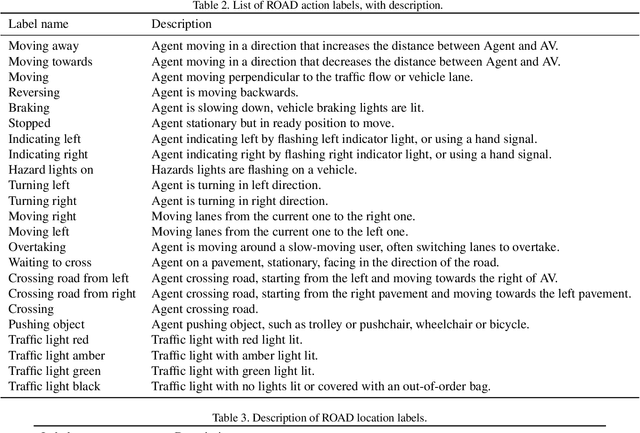

Humans approach driving in a holistic fashion which entails, in particular, understanding road events and their evolution. Injecting these capabilities in an autonomous vehicle has thus the potential to take situational awareness and decision making closer to human-level performance. To this purpose, we introduce the ROad event Awareness Dataset (ROAD) for Autonomous Driving, to our knowledge the first of its kind. ROAD is designed to test an autonomous vehicle's ability to detect road events, defined as triplets composed by a moving agent, the action(s) it performs and the corresponding scene locations. ROAD comprises 22 videos, originally from the Oxford RobotCar Dataset, annotated with bounding boxes showing the location in the image plane of each road event. We also provide as baseline a new incremental algorithm for online road event awareness, based on inflating RetinaNet along time, which achieves a mean average precision of 16.8% and 6.1% for frame-level and video-level event detection, respectively, at 50% overlap. Though promising, these figures highlight the challenges faced by situation awareness in autonomous driving. Finally, ROAD allows scholars to investigate exciting tasks such as complex (road) activity detection, future road event anticipation and the modelling of sentient road agents in terms of mental states. Dataset can be obtained from https://github.com/gurkirt/road-dataset and baseline code from https://github.com/gurkirt/3D-RetinaNet.
Probabilistic Visual Navigation with Bidirectional Image Prediction
Mar 20, 2020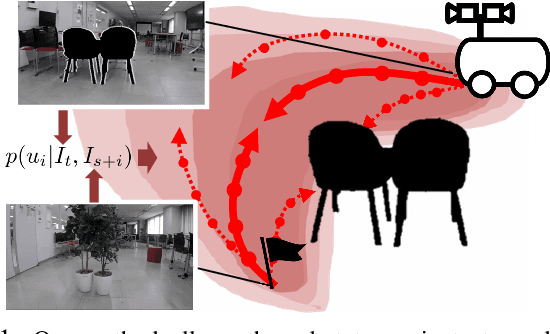
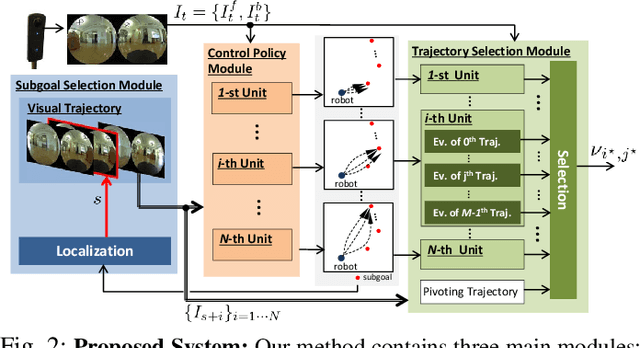
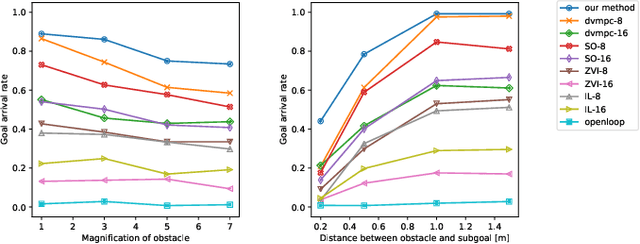
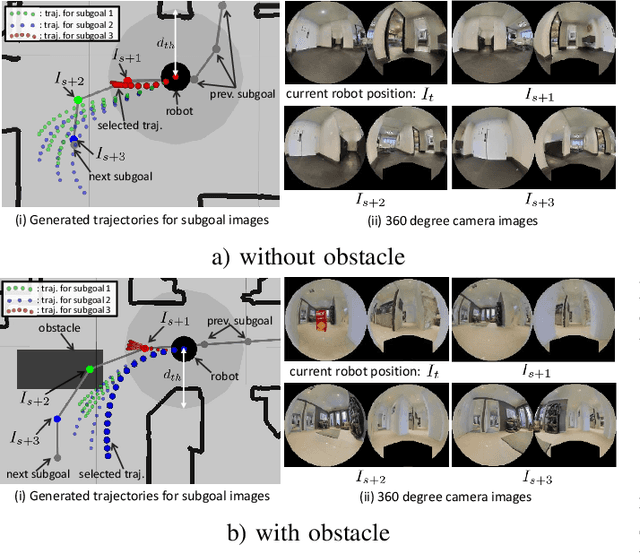
Humans can robustly follow a visual trajectory defined by a sequence of images (i.e. a video) regardless of substantial changes in the environment or the presence of obstacles. We aim at endowing similar visual navigation capabilities to mobile robots solely equipped with a RGB fisheye camera. We propose a novel probabilistic visual navigation system that learns to follow a sequence of images with bidirectional visual predictions conditioned on possible navigation velocities. By predicting bidirectionally (from start towards goal and vice versa) our method extends its predictive horizon enabling the robot to go around unseen large obstacles that are not visible in the video trajectory. Learning how to react to obstacles and potential risks in the visual field is achieved by imitating human teleoperators. Since the human teleoperation commands are diverse, we propose a probabilistic representation of trajectories that we can sample to find the safest path. Integrated into our navigation system, we present a novel localization approach that infers the current location of the robot based on the virtual predicted trajectories required to reach different images in the visual trajectory. We evaluate our navigation system quantitatively and qualitatively in multiple simulated and real environments and compare to state-of-the-art baselines.Our approach outperforms the most recent visual navigation methods with a large margin with regard to goal arrival rate, subgoal coverage rate, and success weighted by path length (SPL). Our method also generalizes to new robot embodiments never used during training.
Sewer-ML: A Multi-Label Sewer Defect Classification Dataset and Benchmark
Mar 19, 2021
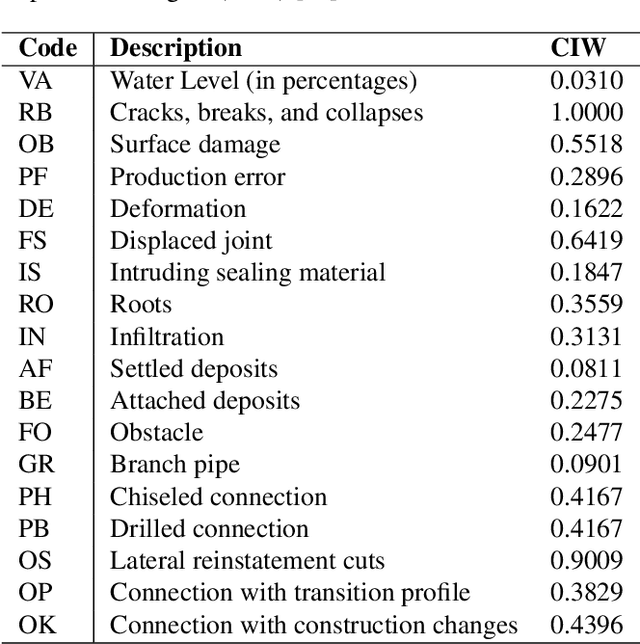
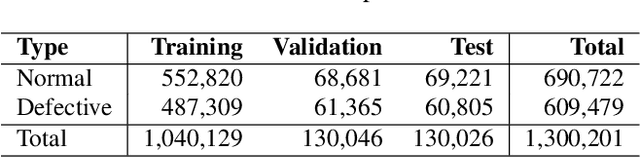
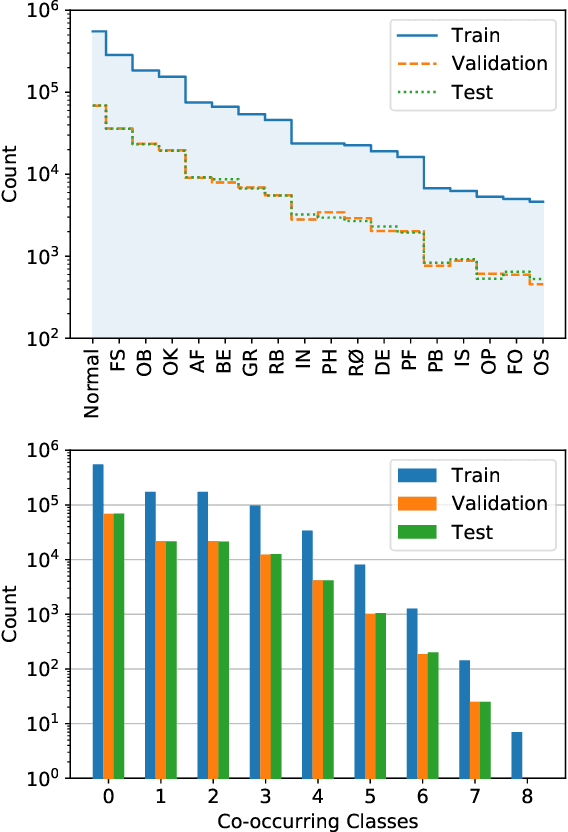
Perhaps surprisingly sewerage infrastructure is one of the most costly infrastructures in modern society. Sewer pipes are manually inspected to determine whether the pipes are defective. However, this process is limited by the number of qualified inspectors and the time it takes to inspect a pipe. Automatization of this process is therefore of high interest. So far, the success of computer vision approaches for sewer defect classification has been limited when compared to the success in other fields mainly due to the lack of public datasets. To this end, in this work we present a large novel and publicly available multi-label classification dataset for image-based sewer defect classification called Sewer-ML. The Sewer-ML dataset consists of 1.3 million images annotated by professional sewer inspectors from three different utility companies across nine years. Together with the dataset, we also present a benchmark algorithm and a novel metric for assessing performance. The benchmark algorithm is a result of evaluating 12 state-of-the-art algorithms, six from the sewer defect classification domain and six from the multi-label classification domain, and combining the best performing algorithms. The novel metric is a class-importance weighted F2 score, $\text{F}2_{\text{CIW}}$, reflecting the economic impact of each class, used together with the normal pipe F1 score, $\text{F}1_{\text{Normal}}$. The benchmark algorithm achieves an $\text{F}2_{\text{CIW}}$ score of 55.11% and $\text{F}1_{\text{Normal}}$ score of 90.94%, leaving ample room for improvement on the Sewer-ML dataset. The code, models, and dataset are available at the project page https://vap.aau.dk/sewer-ml/
Novel Object Viewpoint Estimation through Reconstruction Alignment
Jun 05, 2020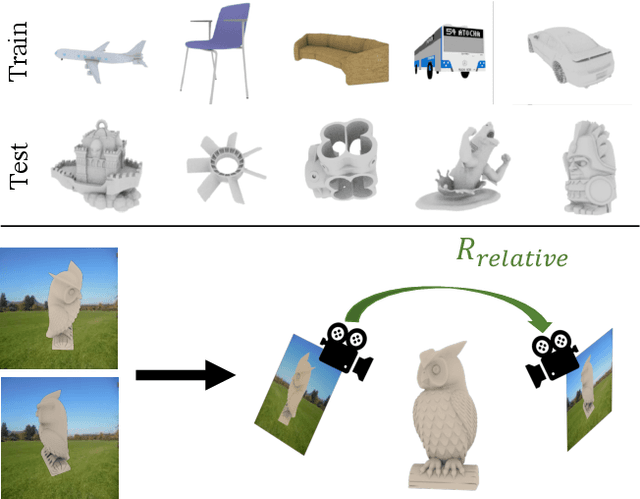

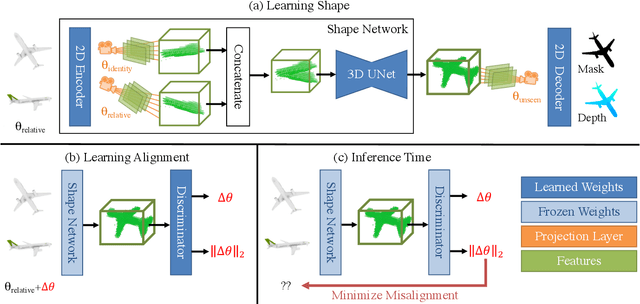

The goal of this paper is to estimate the viewpoint for a novel object. Standard viewpoint estimation approaches generally fail on this task due to their reliance on a 3D model for alignment or large amounts of class-specific training data and their corresponding canonical pose. We overcome those limitations by learning a reconstruct and align approach. Our key insight is that although we do not have an explicit 3D model or a predefined canonical pose, we can still learn to estimate the object's shape in the viewer's frame and then use an image to provide our reference model or canonical pose. In particular, we propose learning two networks: the first maps images to a 3D geometry-aware feature bottleneck and is trained via an image-to-image translation loss; the second learns whether two instances of features are aligned. At test time, our model finds the relative transformation that best aligns the bottleneck features of our test image to a reference image. We evaluate our method on novel object viewpoint estimation by generalizing across different datasets, analyzing the impact of our different modules, and providing a qualitative analysis of the learned features to identify what representations are being learnt for alignment.
Road Surface Translation Under Snow-covered and Semantic Segmentation for Snow Hazard Index
Jan 16, 2021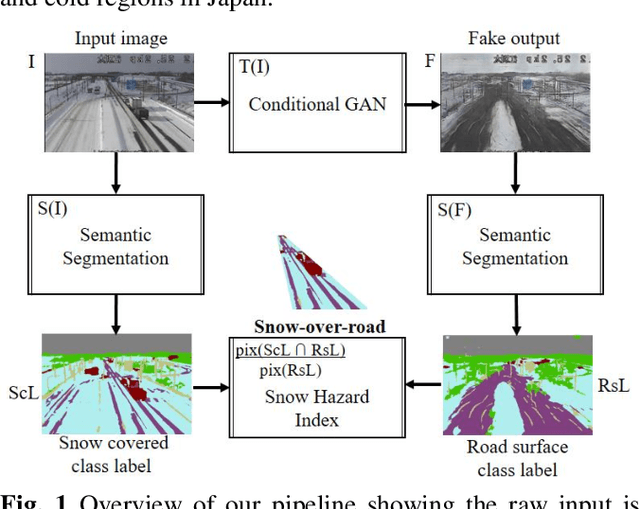



In 2020, record heavy snowfall have been occurred owing to climate change. Actually, 2,000 vehicles on the highway could get stuck for three days. Due to the freezing of the road surface, 10 vehicles could have a billiard accident. Road managers are required to provide them immediately in order to alert drivers to snow cover at hazardous location. This paper proposes a deep learning application with CCTV image post-processing to automatically calculate a snow hazard indicator. First, the road surface of hidden region under snow-covered is translated using generative adversarial network, pix2pix. Second, snow-covered and road surface classes are detected using semantic segmentation, DeepLabv3+ under backbone MobileNet. Based on these trained networks, we enable to automatically compute the road to snow rate hazard index how much snow is covered on the road surface. We demonstrate the applied results to 1,000 CCTV snow images on Hokkaido and North Tohoku area in Japan. We mention the usefulness and the practical robustness.
Implementation of Artificial Neural Networks for the Nepta-Uranian Interplanetary (NUIP) Mission
Mar 19, 2021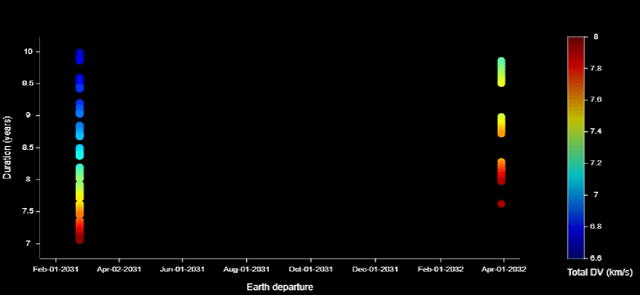

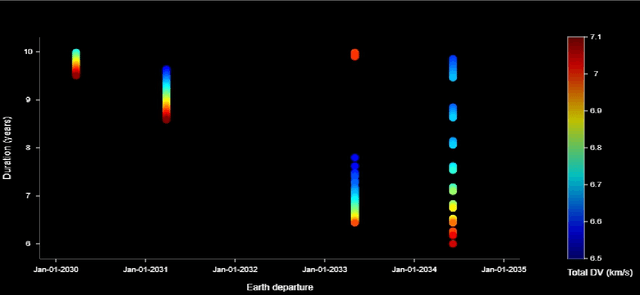
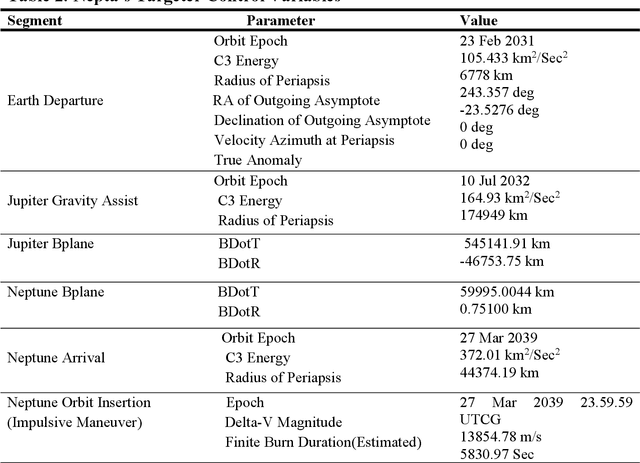
A celestial alignment between Neptune, Uranus, and Jupiter will occur in the early 2030s, allowing a slingshot around Jupiter to gain enough momentum to achieve planetary flyover capability around the two ice giants. The launch of the uranian probe for the departure windows of the NUIP mission is between January 2030 and January 2035, and the duration of the mission is between six and ten years, and the launch of the Nepta probe for the departure windows of the NUIP mission is between February 2031 and April 2032 and the duration of the mission is between seven and ten years. To get the most out of alignment. Deep learning methods are expected to play a critical role in autonomous and intelligent spatial guidance problems. This would reduce travel time, hence mission time, and allow the spacecraft to perform well for the life of its sophisticated instruments and power systems up to fifteen years. This article proposes a design of deep neural networks, namely convolutional neural networks and recurrent neural networks, capable of predicting optimal control actions and image classification during the mission. Nepta-Uranian interplanetary mission, using only raw images taken by optimal onboard cameras. It also describes the unique requirements and constraints of the NUIP mission, which led to the design of the communications system for the Nepta-Uranian spacecraft. The proposed mission is expected to collect telemetry data on Uranus and Neptune while performing the flyovers and transmit the obtained data to Earth for further analysis. The advanced range of spectrometers and particle detectors available would allow better quantification of the ice giant's properties.
Reinforcement Learning Based Handwritten Digit Recognition with Two-State Q-Learning
Jun 28, 2020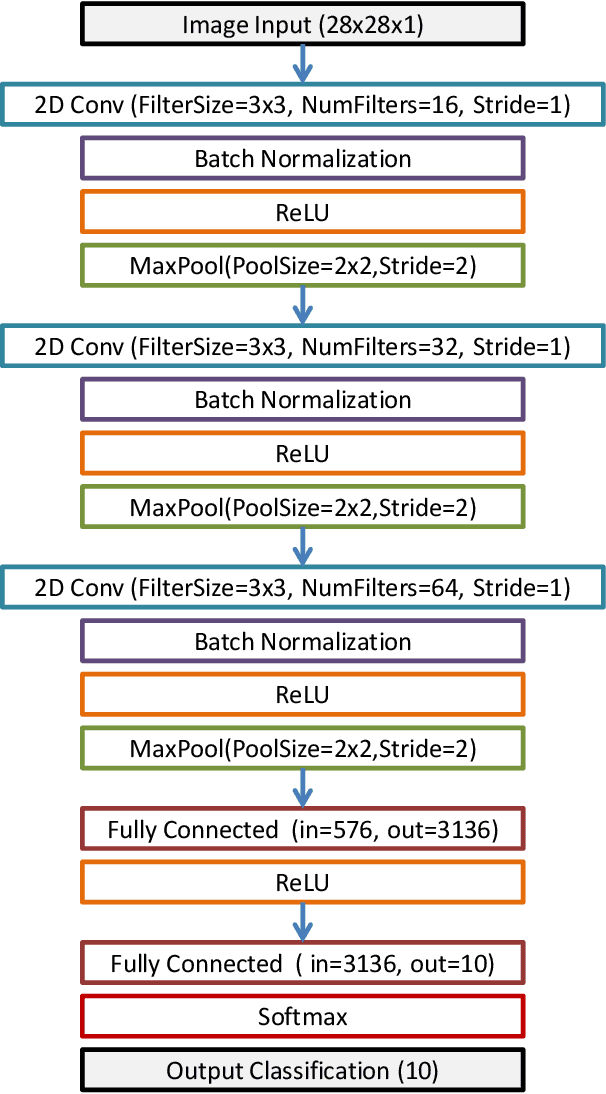
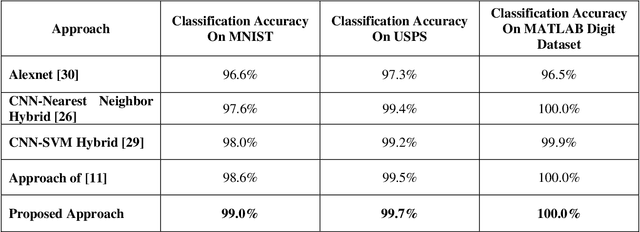
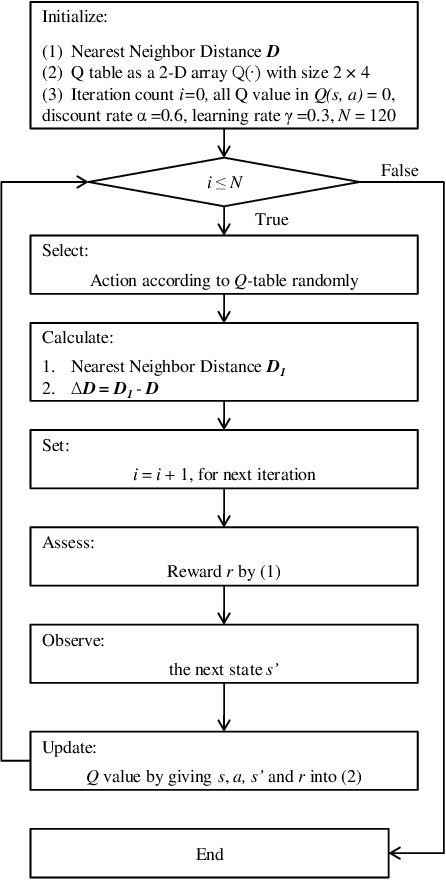
We present a simple yet efficient Hybrid Classifier based on Deep Learning and Reinforcement Learning. Q-Learning is used with two Q-states and four actions. Conventional techniques use feature maps extracted from Convolutional Neural Networks (CNNs) and include them in the Qstates along with past history. This leads to difficulties with these approaches as the number of states is very large number due to high dimensions of the feature maps. Since our method uses only two Q-states it is simple and has much lesser number of parameters to optimize and also thus has a straightforward reward function. Also, the approach uses unexplored actions for image processing vis-a-vis other contemporary techniques. Three datasets have been used for benchmarking of the approach. These are the MNIST Digit Image Dataset, the USPS Digit Image Dataset and the MATLAB Digit Image Dataset. The performance of the proposed hybrid classifier has been compared with other contemporary techniques like a well-established Reinforcement Learning Technique, AlexNet, CNN-Nearest Neighbor Classifier and CNNSupport Vector Machine Classifier. Our approach outperforms these contemporary hybrid classifiers on all the three datasets used.