 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Intrinsic Decomposition of Document Images In-the-Wild
Nov 29, 2020

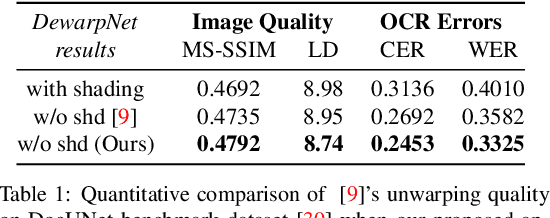

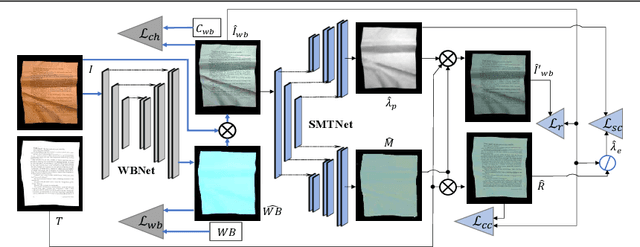
Automatic document content processing is affected by artifacts caused by the shape of the paper, non-uniform and diverse color of lighting conditions. Fully-supervised methods on real data are impossible due to the large amount of data needed. Hence, the current state of the art deep learning models are trained on fully or partially synthetic images. However, document shadow or shading removal results still suffer because: (a) prior methods rely on uniformity of local color statistics, which limit their application on real-scenarios with complex document shapes and textures and; (b) synthetic or hybrid datasets with non-realistic, simulated lighting conditions are used to train the models. In this paper we tackle these problems with our two main contributions. First, a physically constrained learning-based method that directly estimates document reflectance based on intrinsic image formation which generalizes to challenging illumination conditions. Second, a new dataset that clearly improves previous synthetic ones, by adding a large range of realistic shading and diverse multi-illuminant conditions, uniquely customized to deal with documents in-the-wild. The proposed architecture works in a self-supervised manner where only the synthetic texture is used as a weak training signal (obviating the need for very costly ground truth with disentangled versions of shading and reflectance). The proposed approach leads to a significant generalization of document reflectance estimation in real scenes with challenging illumination. We extensively evaluate on the real benchmark datasets available for intrinsic image decomposition and document shadow removal tasks. Our reflectance estimation scheme, when used as a pre-processing step of an OCR pipeline, shows a 26% improvement of character error rate (CER), thus, proving the practical applicability.
Reflectance Adaptive Filtering Improves Intrinsic Image Estimation
Jun 12, 2017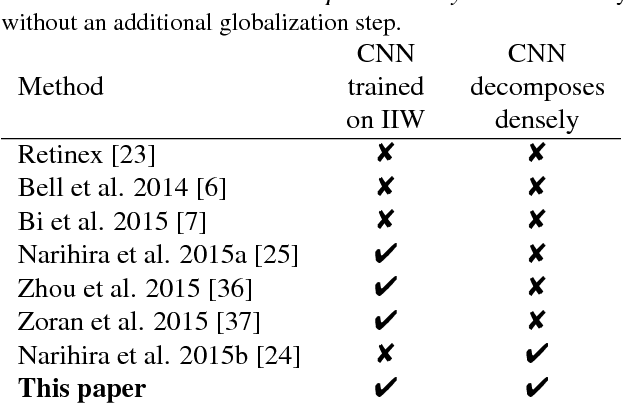
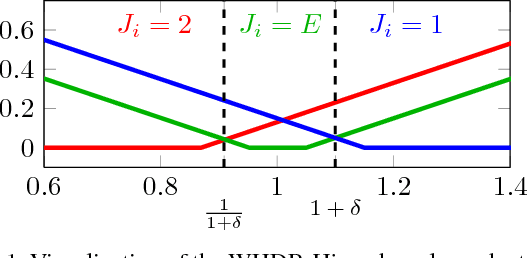
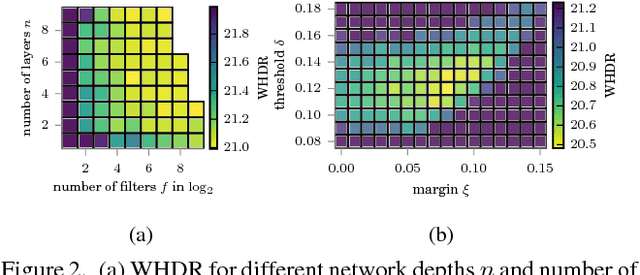

Separating an image into reflectance and shading layers poses a challenge for learning approaches because no large corpus of precise and realistic ground truth decompositions exists. The Intrinsic Images in the Wild~(IIW) dataset provides a sparse set of relative human reflectance judgments, which serves as a standard benchmark for intrinsic images. A number of methods use IIW to learn statistical dependencies between the images and their reflectance layer. Although learning plays an important role for high performance, we show that a standard signal processing technique achieves performance on par with current state-of-the-art. We propose a loss function for CNN learning of dense reflectance predictions. Our results show a simple pixel-wise decision, without any context or prior knowledge, is sufficient to provide a strong baseline on IIW. This sets a competitive baseline which only two other approaches surpass. We then develop a joint bilateral filtering method that implements strong prior knowledge about reflectance constancy. This filtering operation can be applied to any intrinsic image algorithm and we improve several previous results achieving a new state-of-the-art on IIW. Our findings suggest that the effect of learning-based approaches may have been over-estimated so far. Explicit prior knowledge is still at least as important to obtain high performance in intrinsic image decompositions.
Self-Supervised Learning for Monocular Depth Estimation from Aerial Imagery
Aug 17, 2020
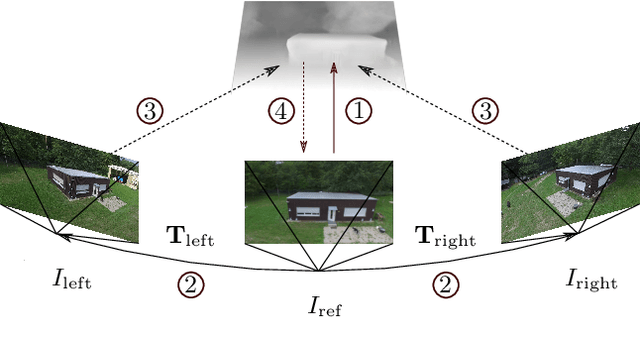
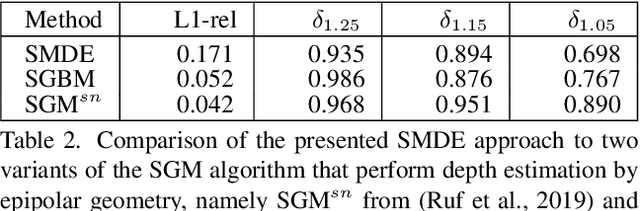
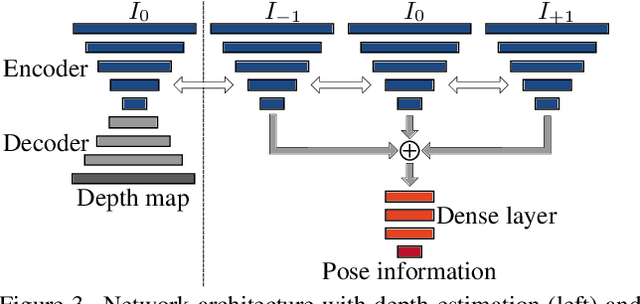
Supervised learning based methods for monocular depth estimation usually require large amounts of extensively annotated training data. In the case of aerial imagery, this ground truth is particularly difficult to acquire. Therefore, in this paper, we present a method for self-supervised learning for monocular depth estimation from aerial imagery that does not require annotated training data. For this, we only use an image sequence from a single moving camera and learn to simultaneously estimate depth and pose information. By sharing the weights between pose and depth estimation, we achieve a relatively small model, which favors real-time application. We evaluate our approach on three diverse datasets and compare the results to conventional methods that estimate depth maps based on multi-view geometry. We achieve an accuracy {\delta}1.25 of up to 93.5 %. In addition, we have paid particular attention to the generalization of a trained model to unknown data and the self-improving capabilities of our approach. We conclude that, even though the results of monocular depth estimation are inferior to those achieved by conventional methods, they are well suited to provide a good initialization for methods that rely on image matching or to provide estimates in regions where image matching fails, e.g. occluded or texture-less regions.
Multilingual Image Description with Neural Sequence Models
Nov 18, 2015
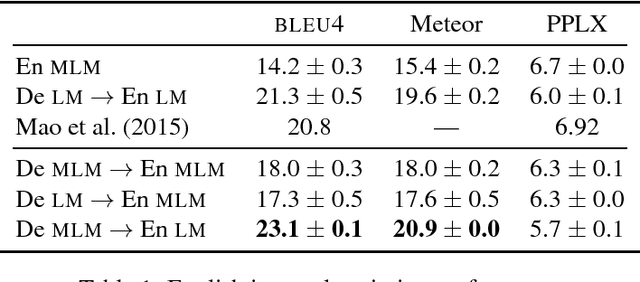
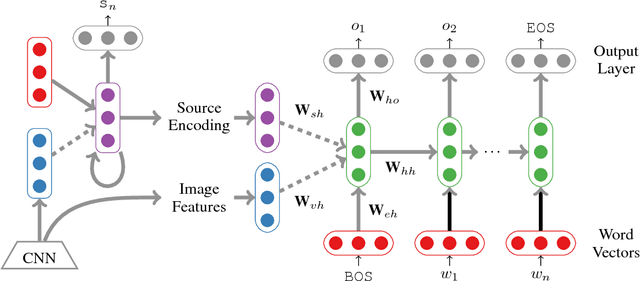
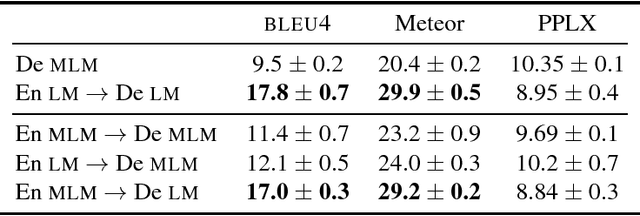
In this paper we present an approach to multi-language image description bringing together insights from neural machine translation and neural image description. To create a description of an image for a given target language, our sequence generation models condition on feature vectors from the image, the description from the source language, and/or a multimodal vector computed over the image and a description in the source language. In image description experiments on the IAPR-TC12 dataset of images aligned with English and German sentences, we find significant and substantial improvements in BLEU4 and Meteor scores for models trained over multiple languages, compared to a monolingual baseline.
X-ray Scatter Estimation Using Deep Splines
Jan 22, 2021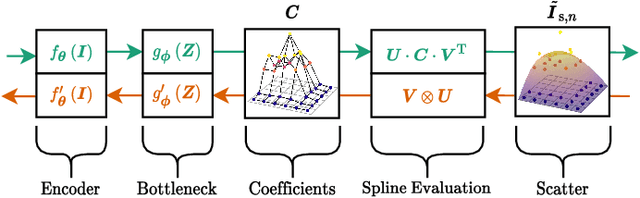
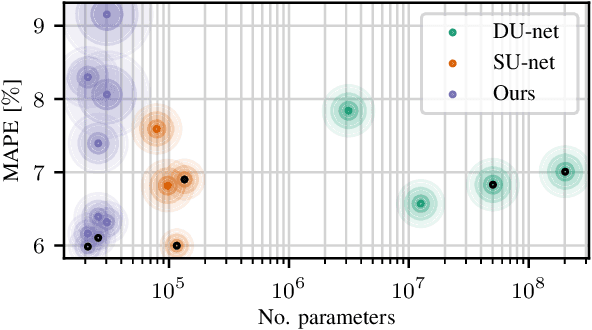
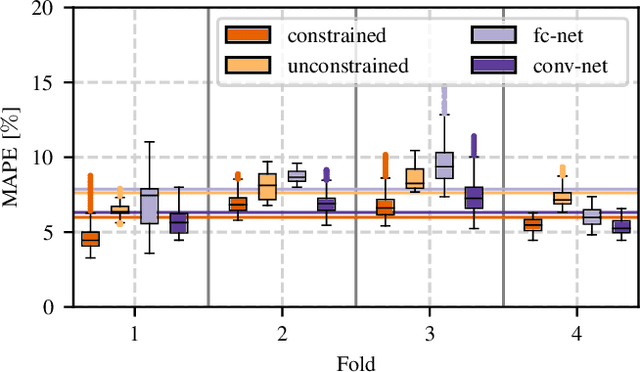
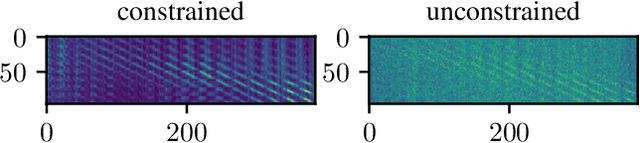
Algorithmic X-ray scatter compensation is a desirable technique in flat-panel X-ray imaging and cone-beam computed tomography. State-of-the-art U-net based image translation approaches yielded promising results. As there are no physics constraints applied to the output of the U-Net, it cannot be ruled out that it yields spurious results. Unfortunately, those may be misleading in the context of medical imaging. To overcome this problem, we propose to embed B-splines as a known operator into neural networks. This inherently limits their predictions to well-behaved and smooth functions. In a study using synthetic head and thorax data as well as real thorax phantom data, we found that our approach performed on par with U-net when comparing both algorithms based on quantitative performance metrics. However, our approach not only reduces runtime and parameter complexity, but we also found it much more robust to unseen noise levels. While the U-net responded with visible artifacts, our approach preserved the X-ray signal's frequency characteristics.
CholecSeg8k: A Semantic Segmentation Dataset for Laparoscopic Cholecystectomy Based on Cholec80
Dec 23, 2020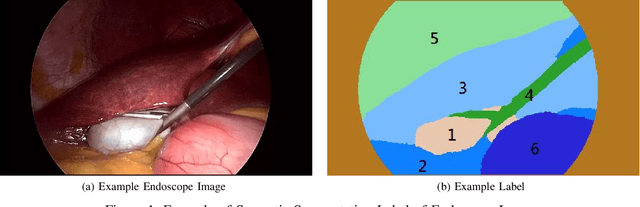
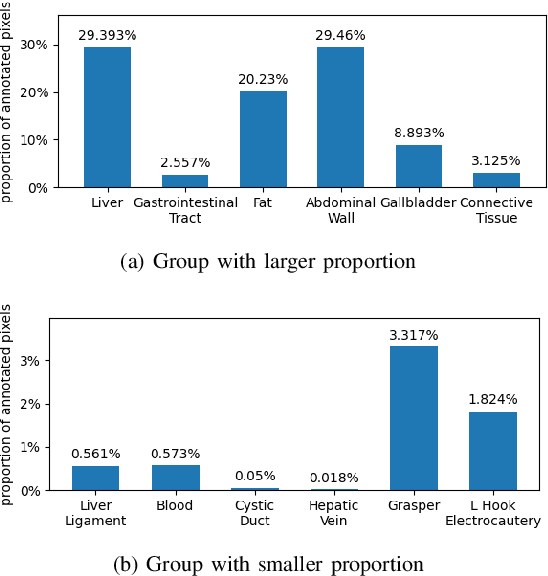
Computer-assisted surgery has been developed to enhance surgery correctness and safety. However, researchers and engineers suffer from limited annotated data to develop and train better algorithms. Consequently, the development of fundamental algorithms such as Simultaneous Localization and Mapping (SLAM) is limited. This article elaborates on the efforts of preparing the dataset for semantic segmentation, which is the foundation of many computer-assisted surgery mechanisms. Based on the Cholec80 dataset [3], we extracted 8,080 laparoscopic cholecystectomy image frames from 17 video clips in Cholec80 and annotated the images. The dataset is named CholecSeg8K and its total size is 3GB. Each of these images is annotated at pixel-level for thirteen classes, which are commonly founded in laparoscopic cholecystectomy surgery. CholecSeg8k is released under the license CC BY- NC-SA 4.0.
LRTA: A Transparent Neural-Symbolic Reasoning Framework with Modular Supervision for Visual Question Answering
Nov 21, 2020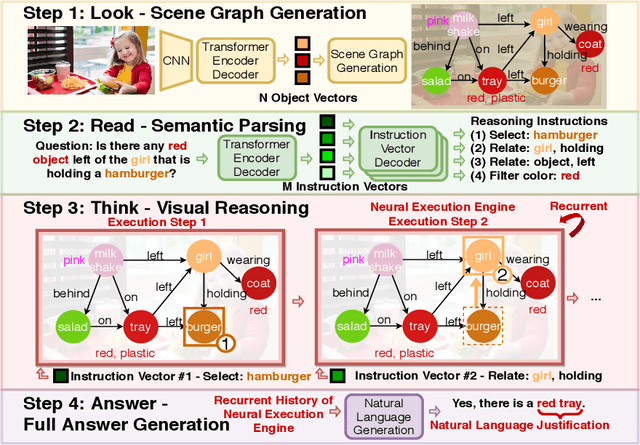
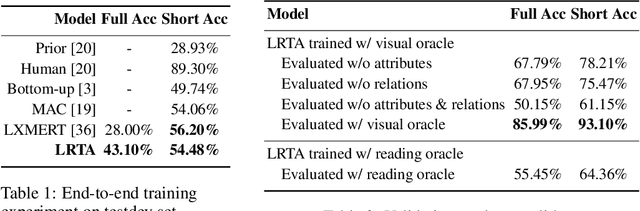
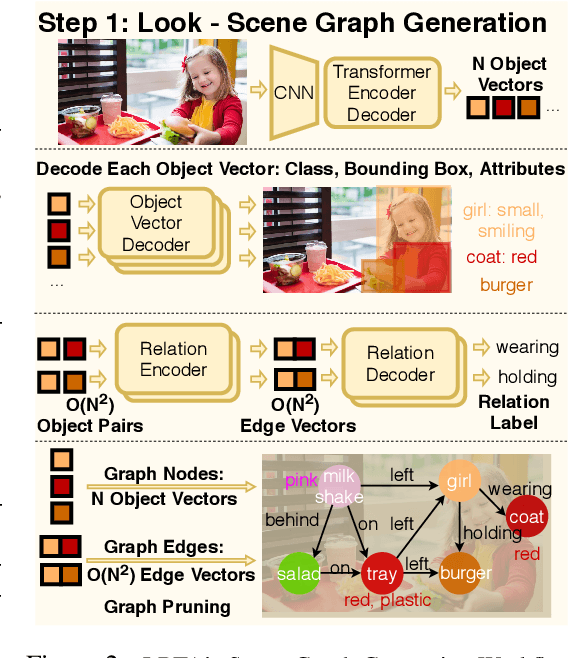
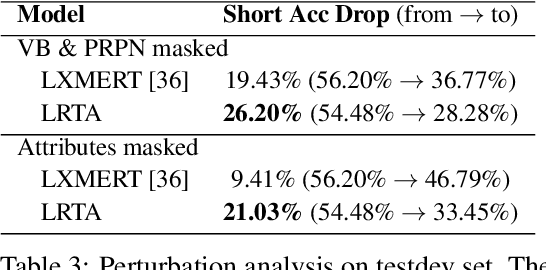
The predominant approach to visual question answering (VQA) relies on encoding the image and question with a "black-box" neural encoder and decoding a single token as the answer like "yes" or "no". Despite this approach's strong quantitative results, it struggles to come up with intuitive, human-readable forms of justification for the prediction process. To address this insufficiency, we reformulate VQA as a full answer generation task, which requires the model to justify its predictions in natural language. We propose LRTA [Look, Read, Think, Answer], a transparent neural-symbolic reasoning framework for visual question answering that solves the problem step-by-step like humans and provides human-readable form of justification at each step. Specifically, LRTA learns to first convert an image into a scene graph and parse a question into multiple reasoning instructions. It then executes the reasoning instructions one at a time by traversing the scene graph using a recurrent neural-symbolic execution module. Finally, it generates a full answer to the given question with natural language justifications. Our experiments on GQA dataset show that LRTA outperforms the state-of-the-art model by a large margin (43.1% v.s. 28.0%) on the full answer generation task. We also create a perturbed GQA test set by removing linguistic cues (attributes and relations) in the questions for analyzing whether a model is having a smart guess with superficial data correlations. We show that LRTA makes a step towards truly understanding the question while the state-of-the-art model tends to learn superficial correlations from the training data.
Generalizability issues with deep learning models in medicine and their potential solutions: illustrated with Cone-Beam Computed Tomography (CBCT) to Computed Tomography (CT) image conversion
Apr 16, 2020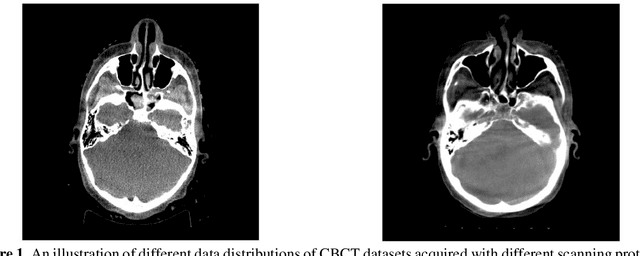
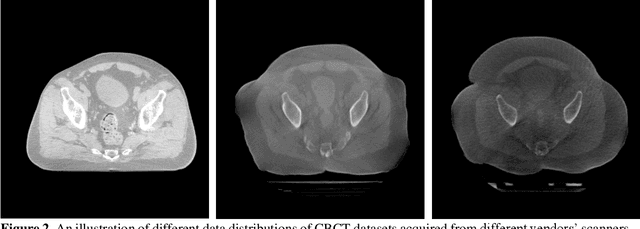
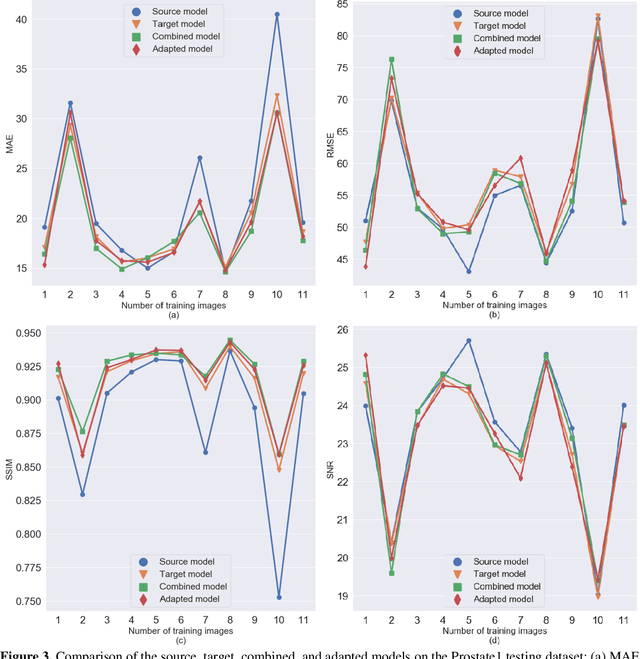
Generalizability is a concern when applying a deep learning (DL) model trained on one dataset to other datasets. Training a universal model that works anywhere, anytime, for anybody is unrealistic. In this work, we demonstrate the generalizability problem, then explore potential solutions based on transfer learning (TL) by using the cone-beam computed tomography (CBCT) to computed tomography (CT) image conversion task as the testbed. Previous works have converted CBCT to CT-like images. However, all of those works studied only one or two anatomical sites and used images from the same vendor's scanners. Here, we investigated how a model trained for one machine and one anatomical site works on other machines and other sites. We trained a model on CBCT images acquired from one vendor's scanners for head and neck cancer patients and applied it to images from another vendor's scanners and for other disease sites. We found that generalizability could be a significant problem for this particular application when applying a trained DL model to datasets from another vendor's scanners. We then explored three practical solutions based on TL to solve this generalization problem: the target model, which is trained on a target domain from scratch; the combined model, which is trained on both source and target domain datasets from scratch; and the adapted model, which fine-tunes the trained source model to a target domain. We found that when there are sufficient data in the target domain, all three models can achieve good performance. When the target dataset is limited, the adapted model works the best, which indicates that using the fine-tuning strategy to adapt the trained model to an unseen target domain dataset is a viable and easy way to implement DL models in the clinic.
Efficient Image Splicing Localization via Contrastive Feature Extraction
Jan 22, 2019
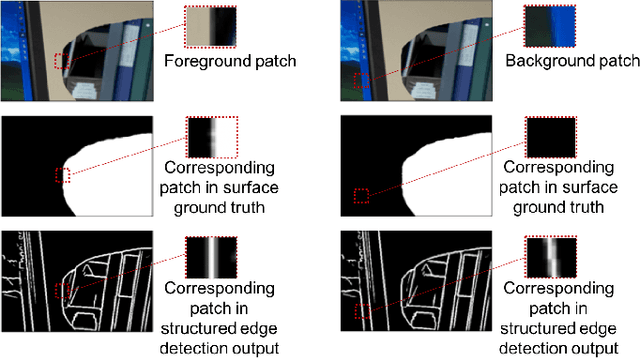
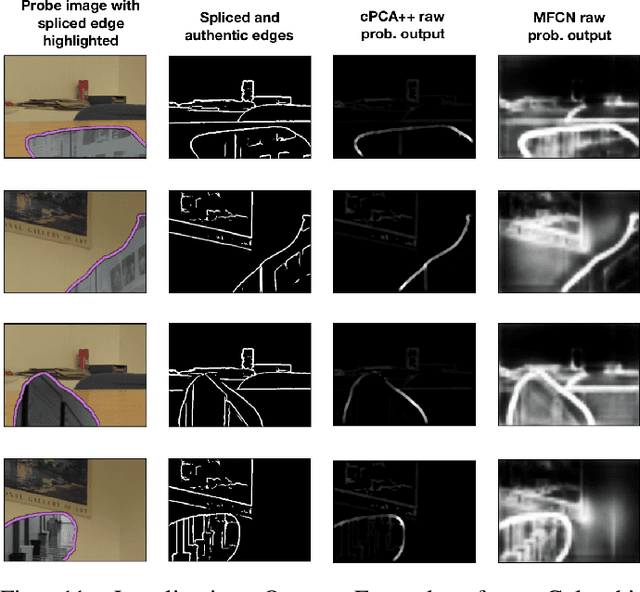

In this work, we propose a new data visualization and clustering technique for discovering discriminative structures in high-dimensional data. This technique, referred to as cPCA++, utilizes the fact that the interesting features of a "target" dataset may be obscured by high variance components during traditional PCA. By analyzing what is referred to as a "background" dataset (i.e., one that exhibits the high variance principal components but not the interesting structures), our technique is capable of efficiently highlighting the structure that is unique to the "target" dataset. Similar to another recently proposed algorithm called "contrastive PCA" (cPCA), the proposed cPCA++ method identifies important dataset specific patterns that are not detected by traditional PCA in a wide variety of settings. However, the proposed cPCA++ method is significantly more efficient than cPCA, because it does not require the parameter sweep in the latter approach. We applied the cPCA++ method to the problem of image splicing localization. In this application, we utilize authentic edges as the background dataset and the spliced edges as the target dataset. The proposed method is significantly more efficient than state-of-the-art methods, as the former does not require iterative updates of filter weights via stochastic gradient descent and backpropagation, nor the training of a classifier. Furthermore, the cPCA++ method is shown to provide performance scores comparable to the state-of-the-art Multi-task Fully Convolutional Network (MFCN).
Linear Regression with Distributed Learning: A Generalization Error Perspective
Jan 22, 2021



Distributed learning provides an attractive framework for scaling the learning task by sharing the computational load over multiple nodes in a network. Here, we investigate the performance of distributed learning for large-scale linear regression where the model parameters, i.e., the unknowns, are distributed over the network. We adopt a statistical learning approach. In contrast to works that focus on the performance on the training data, we focus on the generalization error, i.e., the performance on unseen data. We provide high-probability bounds on the generalization error for both isotropic and correlated Gaussian data as well as sub-gaussian data. These results reveal the dependence of the generalization performance on the partitioning of the model over the network. In particular, our results show that the generalization error of the distributed solution can be substantially higher than that of the centralized solution even when the error on the training data is at the same level for both the centralized and distributed approaches. Our numerical results illustrate the performance with both real-world image data as well as synthetic data.