 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Generative Model-based Quality Control for Cardiac MRI Segmentation
Jun 23, 2020
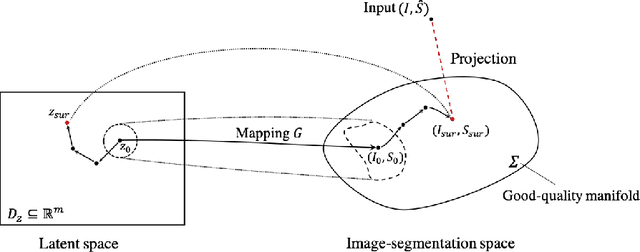
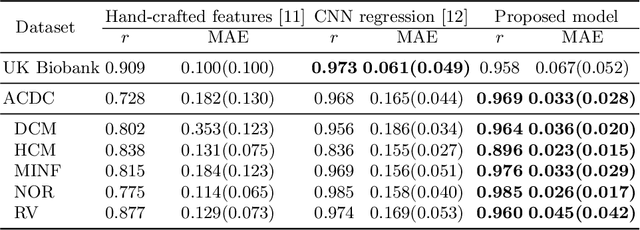
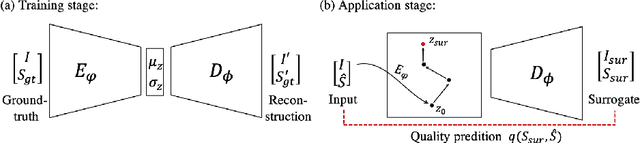
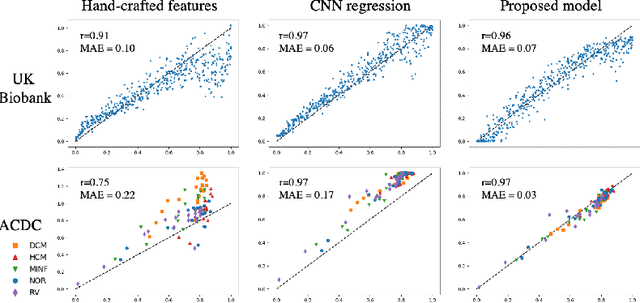
In recent years, convolutional neural networks have demonstrated promising performance in a variety of medical image segmentation tasks. However, when a trained segmentation model is deployed into the real clinical world, the model may not perform optimally. A major challenge is the potential poor-quality segmentations generated due to degraded image quality or domain shift issues. There is a timely need to develop an automated quality control method that can detect poor segmentations and feedback to clinicians. Here we propose a novel deep generative model-based framework for quality control of cardiac MRI segmentation. It first learns a manifold of good-quality image-segmentation pairs using a generative model. The quality of a given test segmentation is then assessed by evaluating the difference from its projection onto the good-quality manifold. In particular, the projection is refined through iterative search in the latent space. The proposed method achieves high prediction accuracy on two publicly available cardiac MRI datasets. Moreover, it shows better generalisation ability than traditional regression-based methods. Our approach provides a real-time and model-agnostic quality control for cardiac MRI segmentation, which has the potential to be integrated into clinical image analysis workflows.
Improving Road Signs Detection performance by Combining the Features of Hough Transform and Texture
Oct 13, 2020With the large uses of the intelligent systems in different domains, and in order to increase the drivers and pedestrians safety, the road and traffic sign recognition system has been a challenging issue and an important task for many years. But studies, done in this field of detection and recognition of traffic signs in an image, which are interested in the Arab context, are still insufficient. Detection of the road signs present in the scene is the one of the main stages of the traffic sign detection and recognition. In this paper, an efficient solution to enhance road signs detection, including Arabic context, performance based on color segmentation, Randomized Hough Transform and the combination of Zernike moments and Haralick features has been made. Segmentation stage is useful to determine the Region of Interest (ROI) in the image. The Randomized Hough Transform (RHT) is used to detect the circular and octagonal shapes. This stage is improved by the extraction of the Haralick features and Zernike moments. Furthermore, we use it as input of a classifier based on SVM. Experimental results show that the proposed approach allows us to perform the measurements precision.
Towards Real-World Blind Face Restoration with Generative Facial Prior
Jan 11, 2021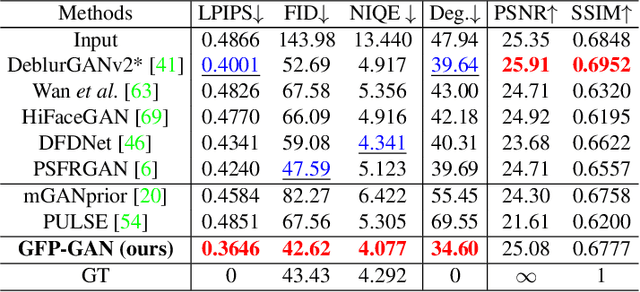
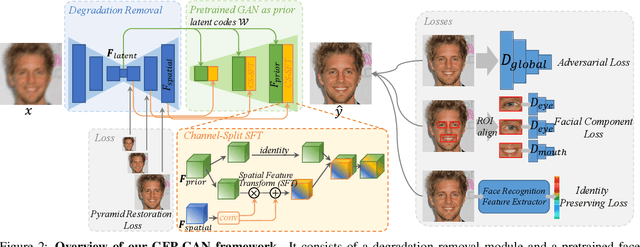

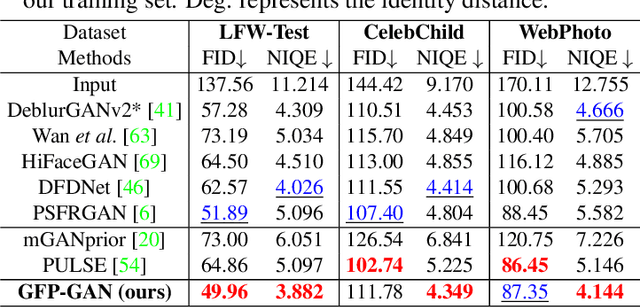
Blind face restoration usually relies on facial priors, such as facial geometry prior or reference prior, to restore realistic and faithful details. However, very low-quality inputs cannot offer accurate geometric prior while high-quality references are inaccessible, limiting the applicability in real-world scenarios. In this work, we propose GFP-GAN that leverages rich and diverse priors encapsulated in a pretrained face GAN for blind face restoration. This Generative Facial Prior (GFP) is incorporated into the face restoration process via novel channel-split spatial feature transform layers, which allow our method to achieve a good balance of realness and fidelity. Thanks to the powerful generative facial prior and delicate designs, our GFP-GAN could jointly restore facial details and enhance colors with just a single forward pass, while GAN inversion methods require expensive image-specific optimization at inference. Extensive experiments show that our method achieves superior performance to prior art on both synthetic and real-world datasets.
Contextual colorization and denoising for low-light ultra high resolution sequences
Jan 05, 2021
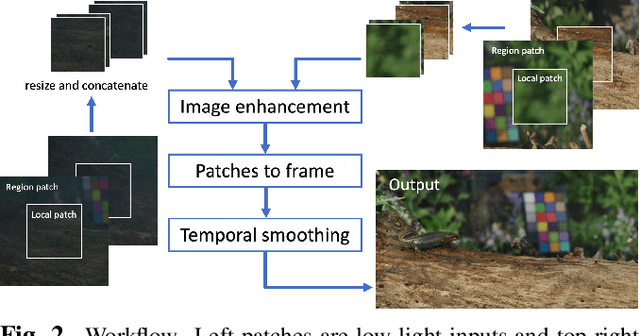


Low-light image sequences generally suffer from spatio-temporal incoherent noise, flicker and blurring of moving objects. These artefacts significantly reduce visual quality and, in most cases, post-processing is needed in order to generate acceptable quality. Most state-of-the-art enhancement methods based on machine learning require ground truth data but this is not usually available for naturally captured low light sequences. We tackle these problems with an unpaired-learning method that offers simultaneous colorization and denoising. Our approach is an adaptation of the CycleGAN structure. To overcome the excessive memory limitations associated with ultra high resolution content, we propose a multiscale patch-based framework, capturing both local and contextual features. Additionally, an adaptive temporal smoothing technique is employed to remove flickering artefacts. Experimental results show that our method outperforms existing approaches in terms of subjective quality and that it is robust to variations in brightness levels and noise.
End-to-end Training for Whole Image Breast Cancer Diagnosis using An All Convolutional Design
Nov 15, 2017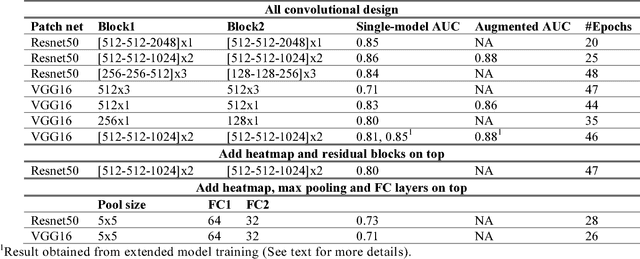
We develop an end-to-end training algorithm for whole-image breast cancer diagnosis based on mammograms. It requires lesion annotations only at the first stage of training. After that, a whole image classifier can be trained using only image level labels. This greatly reduced the reliance on lesion annotations. Our approach is implemented using an all convolutional design that is simple yet provides superior performance in comparison with the previous methods. On DDSM, our best single-model achieves a per-image AUC score of 0.88 and three-model averaging increases the score to 0.91. On INbreast, our best single-model achieves a per-image AUC score of 0.96. Using DDSM as benchmark, our models compare favorably with the current state-of-the-art. We also demonstrate that a whole image model trained on DDSM can be easily transferred to INbreast without using its lesion annotations and using only a small amount of training data. Code availability: https://github.com/lishen/end2end-all-conv
Reducing false-positive biopsies with deep neural networks that utilize local and global information in screening mammograms
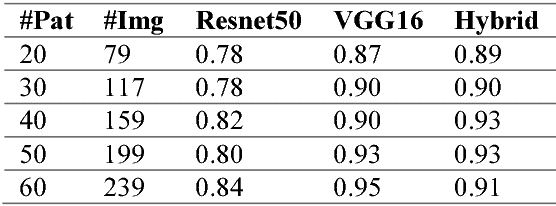
Sep 19, 2020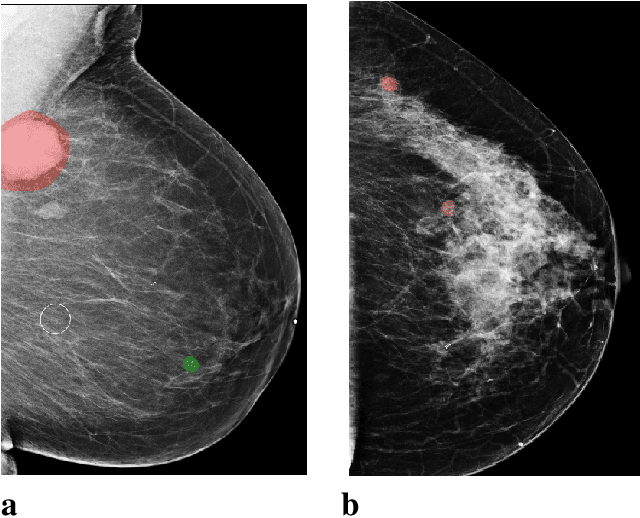
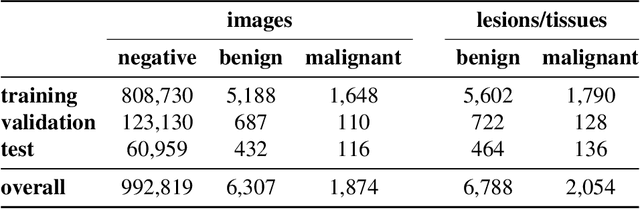
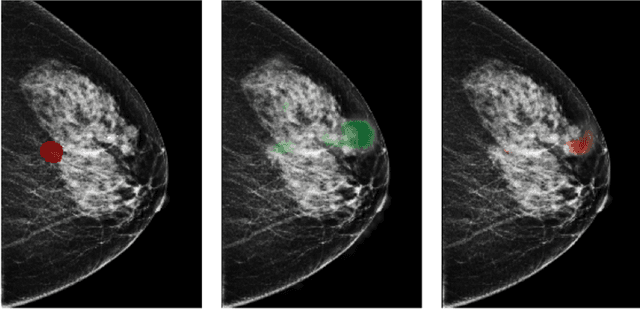
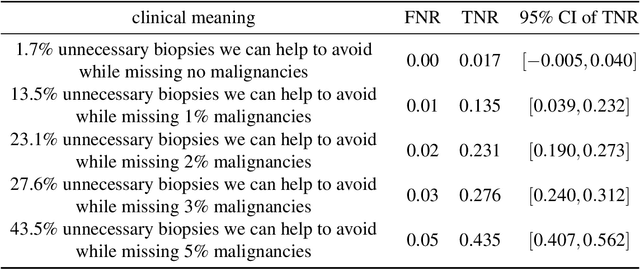
Breast cancer is the most common cancer in women, and hundreds of thousands of unnecessary biopsies are done around the world at a tremendous cost. It is crucial to reduce the rate of biopsies that turn out to be benign tissue. In this study, we build deep neural networks (DNNs) to classify biopsied lesions as being either malignant or benign, with the goal of using these networks as second readers serving radiologists to further reduce the number of false positive findings. We enhance the performance of DNNs that are trained to learn from small image patches by integrating global context provided in the form of saliency maps learned from the entire image into their reasoning, similar to how radiologists consider global context when evaluating areas of interest. Our experiments are conducted on a dataset of 229,426 screening mammography exams from 141,473 patients. We achieve an AUC of 0.8 on a test set consisting of 464 benign and 136 malignant lesions.
Reflectance Adaptive Filtering Improves Intrinsic Image Estimation
Jun 12, 2017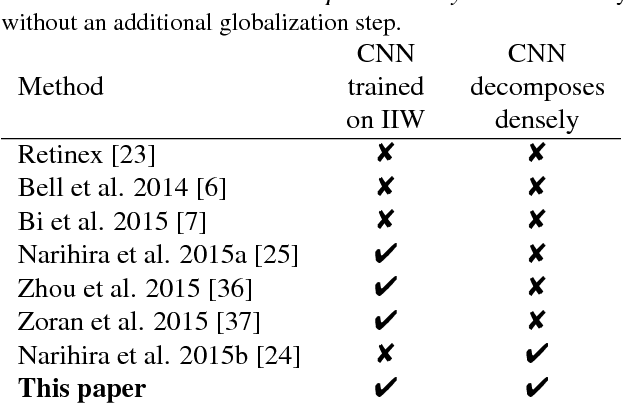
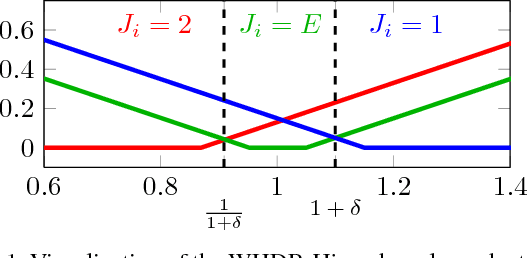

Separating an image into reflectance and shading layers poses a challenge for learning approaches because no large corpus of precise and realistic ground truth decompositions exists. The Intrinsic Images in the Wild~(IIW) dataset provides a sparse set of relative human reflectance judgments, which serves as a standard benchmark for intrinsic images. A number of methods use IIW to learn statistical dependencies between the images and their reflectance layer. Although learning plays an important role for high performance, we show that a standard signal processing technique achieves performance on par with current state-of-the-art. We propose a loss function for CNN learning of dense reflectance predictions. Our results show a simple pixel-wise decision, without any context or prior knowledge, is sufficient to provide a strong baseline on IIW. This sets a competitive baseline which only two other approaches surpass. We then develop a joint bilateral filtering method that implements strong prior knowledge about reflectance constancy. This filtering operation can be applied to any intrinsic image algorithm and we improve several previous results achieving a new state-of-the-art on IIW. Our findings suggest that the effect of learning-based approaches may have been over-estimated so far. Explicit prior knowledge is still at least as important to obtain high performance in intrinsic image decompositions.
Machine Learning Techniques for Biomedical Image Segmentation: An Overview of Technical Aspects and Introduction to State-of-Art Applications
Nov 06, 2019In recent years, significant progress has been made in developing more accurate and efficient machine learning algorithms for segmentation of medical and natural images. In this review article, we highlight the imperative role of machine learning algorithms in enabling efficient and accurate segmentation in the field of medical imaging. We specifically focus on several key studies pertaining to the application of machine learning methods to biomedical image segmentation. We review classical machine learning algorithms such as Markov random fields, k-means clustering, random forest, etc. Although such classical learning models are often less accurate compared to the deep learning techniques, they are often more sample efficient and have a less complex structure. We also review different deep learning architectures, such as the artificial neural networks (ANNs), the convolutional neural networks (CNNs), and the recurrent neural networks (RNNs), and present the segmentation results attained by those learning models that were published in the past three years. We highlight the successes and limitations of each machine learning paradigm. In addition, we discuss several challenges related to the training of different machine learning models, and we present some heuristics to address those challenges.
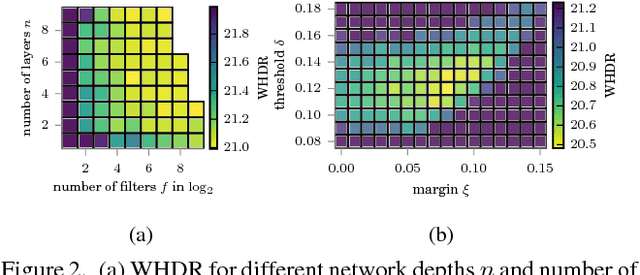
Towards glass-box CNNs
Jan 11, 2021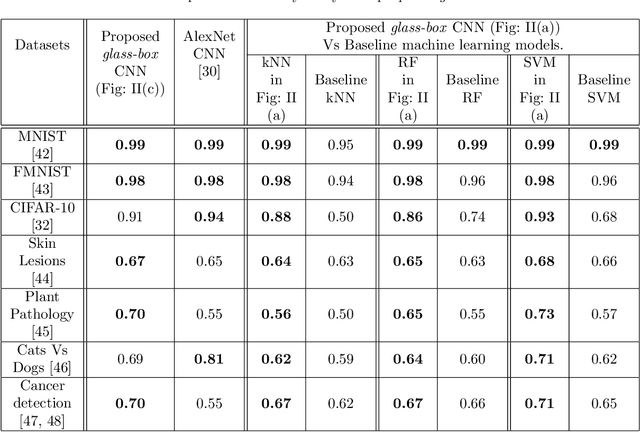
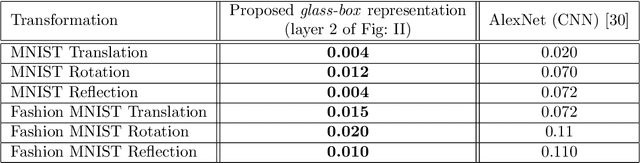
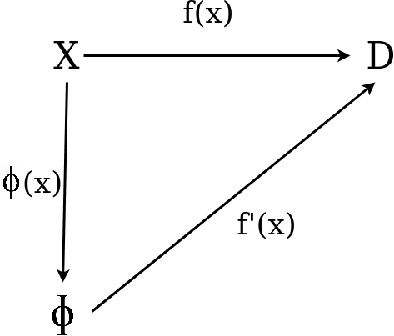
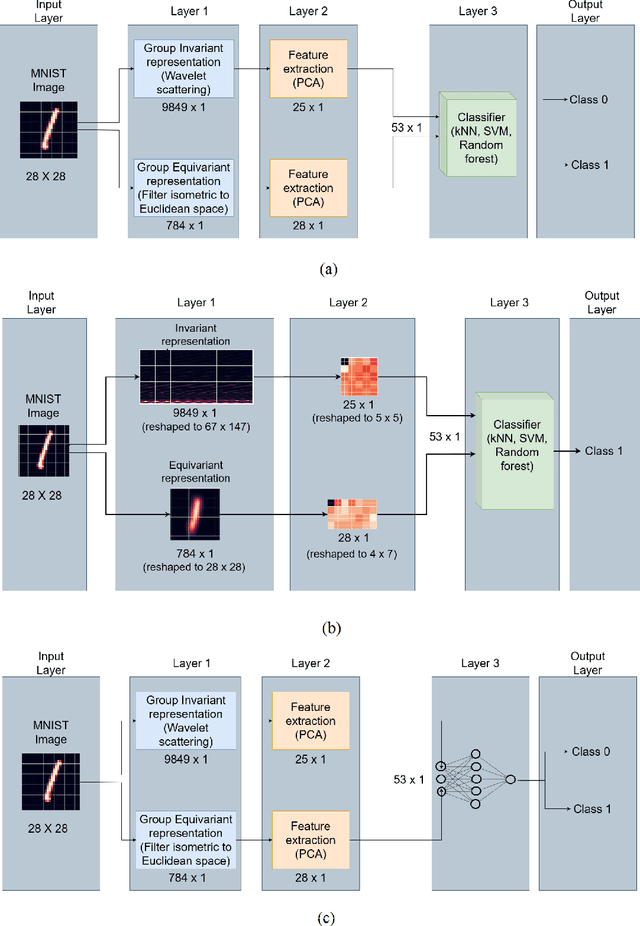
Convolution neural networks (CNNs) are brain-inspired architectures popular for their ability to train and relearn visually complex tasks. It is incremental and scalable; however, CNN is mostly treated as black-box and involves multiple trial & error runs. We observe that CNN constructs powerful internal representations that help achieve state-of-the-art performance. Here we propose three layer glass-box (analytical) CNN for two-class image classifcation problems. First is a representation layer that encompasses both the class information (group invariant) and symmetric transformations (group equivariant) of input images. It is then passed through dimension reduction layer (PCA). Finally the compact yet complete representation is provided to a classifer. Analytical machine learning classifers and multilayer perceptrons are used to assess sensitivity. Proposed glass-box CNN is compared with equivariance of AlexNet (CNN) internal representation for better understanding and dissemination of results. In future, we would like to construct glass-box CNN for multiclass visually complex tasks.
Multilingual Image Description with Neural Sequence Models
Nov 18, 2015
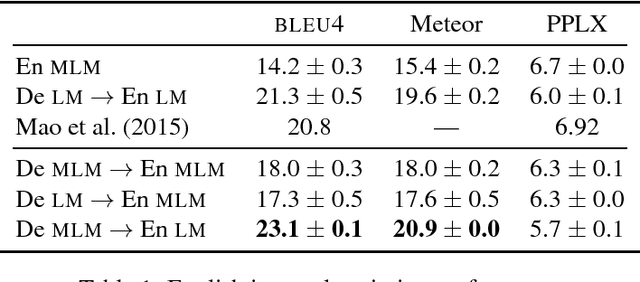
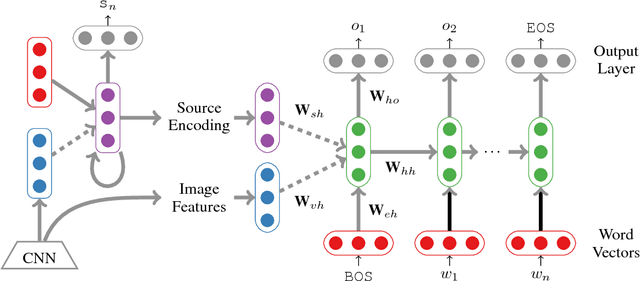
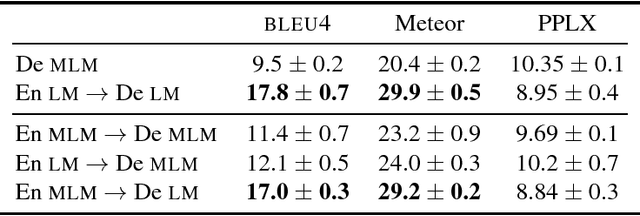
In this paper we present an approach to multi-language image description bringing together insights from neural machine translation and neural image description. To create a description of an image for a given target language, our sequence generation models condition on feature vectors from the image, the description from the source language, and/or a multimodal vector computed over the image and a description in the source language. In image description experiments on the IAPR-TC12 dataset of images aligned with English and German sentences, we find significant and substantial improvements in BLEU4 and Meteor scores for models trained over multiple languages, compared to a monolingual baseline.