 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Shadow Removal Using Target Consistency Generative Adversarial Network
Oct 03, 2020
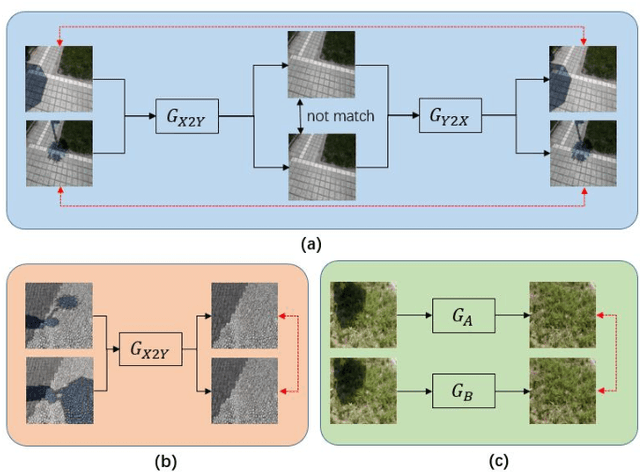
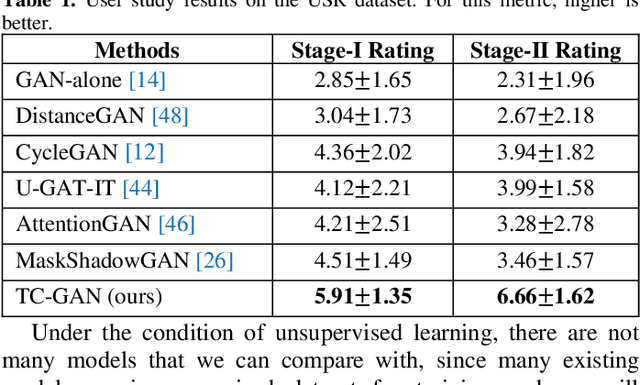
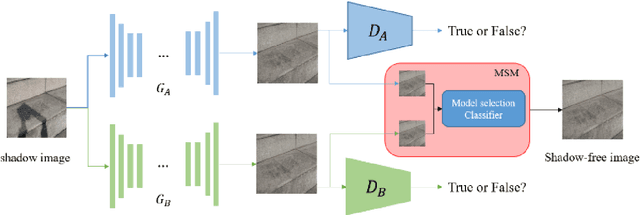
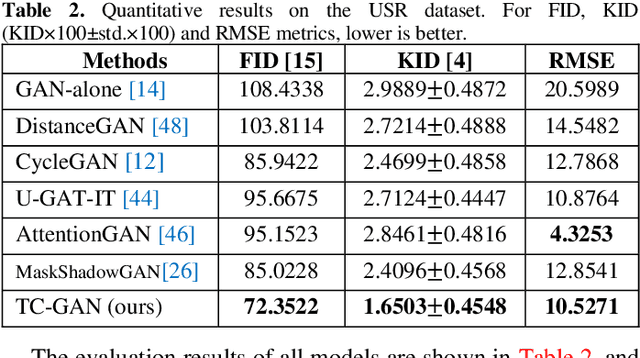
Unsupervised shadow removal aims to learn a non-linear function to map the original image from shadow domain to non-shadow domain in the absence of paired shadow and non-shadow data. In this paper, we develop a simple yet efficient target-consistency generative adversarial network (TC-GAN) for the shadow removal task in the unsupervised manner. Compared with the bidirectional mapping in cycle-consistency GAN based methods for shadow removal, TC-GAN tries to learn a one-sided mapping to cast shadow images into shadow-free ones. With the proposed target-consistency constraint, the correlations between shadow images and the output shadow-free image are strictly confined. Extensive comparison experiments results show that TC-GAN outperforms the state-of-the-art unsupervised shadow removal methods by 14.9% in terms of FID and 31.5% in terms of KID. It is rather remarkable that TC-GAN achieves comparable performance with supervised shadow removal methods.
VDM-DA: Virtual Domain Modeling for Source Data-free Domain Adaptation
Mar 26, 2021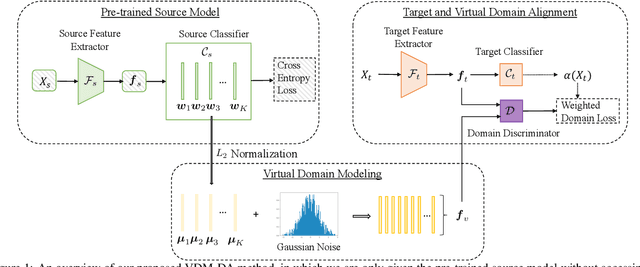
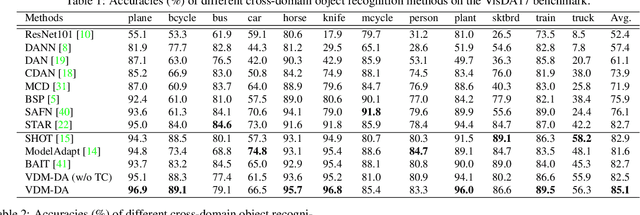
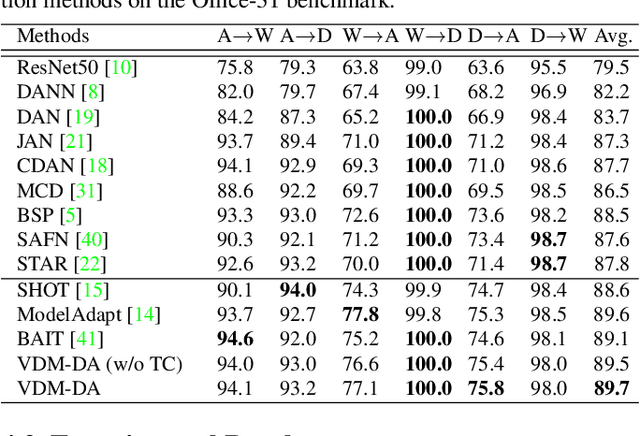
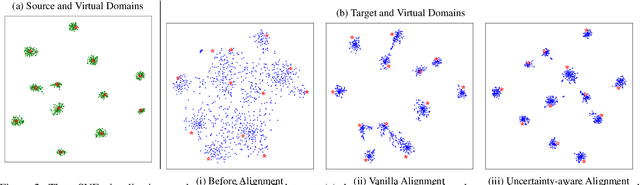
Domain adaptation aims to leverage a label-rich domain (the source domain) to help model learning in a label-scarce domain (the target domain). Most domain adaptation methods require the co-existence of source and target domain samples to reduce the distribution mismatch, however, access to the source domain samples may not always be feasible in the real world applications due to different problems (e.g., storage, transmission, and privacy issues). In this work, we deal with the source data-free unsupervised domain adaptation problem, and propose a novel approach referred to as Virtual Domain Modeling (VDM-DA). The virtual domain acts as a bridge between the source and target domains. On one hand, we generate virtual domain samples based on an approximated Gaussian Mixture Model (GMM) in the feature space with the pre-trained source model, such that the virtual domain maintains a similar distribution with the source domain without accessing to the original source data. On the other hand, we also design an effective distribution alignment method to reduce the distribution divergence between the virtual domain and the target domain by gradually improving the compactness of the target domain distribution through model learning. In this way, we successfully achieve the goal of distribution alignment between the source and target domains by training deep networks without accessing to the source domain data. We conduct extensive experiments on benchmark datasets for both 2D image-based and 3D point cloud-based cross-domain object recognition tasks, where the proposed method referred to Domain Adaptation with Virtual Domain Modeling (VDM-DA) achieves the state-of-the-art performances on all datasets.
Crop Classification under Varying Cloud Cover with Neural Ordinary Differential Equations
Dec 04, 2020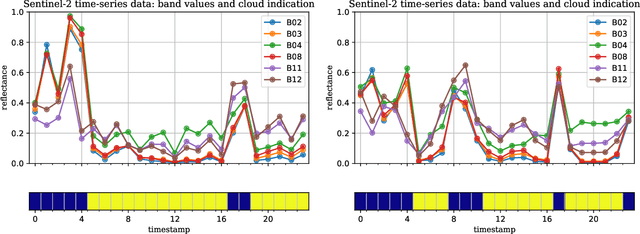

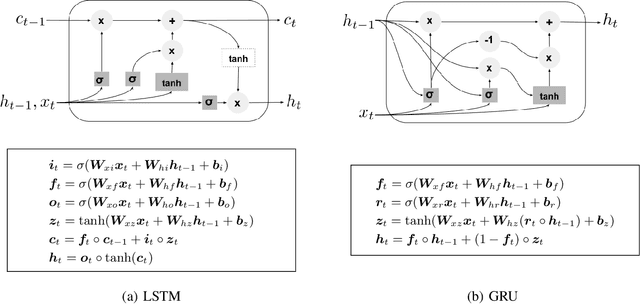
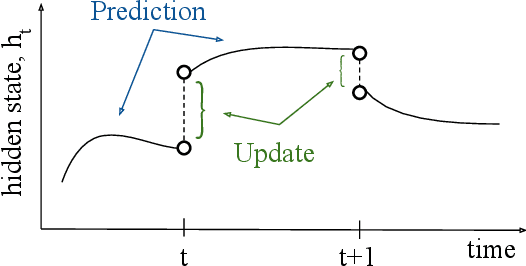
Optical satellite sensors cannot see the Earth's surface through clouds. Despite the periodic revisit cycle, image sequences acquired by Earth observation satellites are therefore irregularly sampled in time. State-of-the-art methods for crop classification (and other time series analysis tasks) rely on techniques that implicitly assume regular temporal spacing between observations, such as recurrent neural networks (RNNs). We propose to use neural ordinary differential equations (NODEs) in combination with RNNs to classify crop types in irregularly spaced image sequences. The resulting ODE-RNN models consist of two steps: an update step, where a recurrent unit assimilates new input data into the model's hidden state; and a prediction step, in which NODE propagates the hidden state until the next observation arrives. The prediction step is based on a continuous representation of the latent dynamics, which has several advantages. At the conceptual level, it is a more natural way to describe the mechanisms that govern the phenological cycle. From a practical point of view, it makes it possible to sample the system state at arbitrary points in time, such that one can integrate observations whenever they are available, and extrapolate beyond the last observation. Our experiments show that ODE-RNN indeed improves classification accuracy over common baselines such as LSTM, GRU, and temporal convolution. The gains are most prominent in the challenging scenario where only few observations are available (i.e., frequent cloud cover). Moreover, we show that the ability to extrapolate translates to better classification performance early in the season, which is important for forecasting.
Optimizing the Trade-off between Single-Stage and Two-Stage Object Detectors using Image Difficulty Prediction
Aug 31, 2018


There are mainly two types of state-of-the-art object detectors. On one hand, we have two-stage detectors, such as Faster R-CNN (Region-based Convolutional Neural Networks) or Mask R-CNN, that (i) use a Region Proposal Network to generate regions of interests in the first stage and (ii) send the region proposals down the pipeline for object classification and bounding-box regression. Such models reach the highest accuracy rates, but are typically slower. On the other hand, we have single-stage detectors, such as YOLO (You Only Look Once) and SSD (Singe Shot MultiBox Detector), that treat object detection as a simple regression problem by taking an input image and learning the class probabilities and bounding box coordinates. Such models reach lower accuracy rates, but are much faster than two-stage object detectors. In this paper, we propose to use an image difficulty predictor to achieve an optimal trade-off between accuracy and speed in object detection. The image difficulty predictor is applied on the test images to split them into easy versus hard images. Once separated, the easy images are sent to the faster single-stage detector, while the hard images are sent to the more accurate two-stage detector. Our experiments on PASCAL VOC 2007 show that using image difficulty compares favorably to a random split of the images. Our method is flexible, in that it allows to choose a desired threshold for splitting the images into easy versus hard.
Adversarial Exposure Attack on Diabetic Retinopathy Imagery
Sep 19, 2020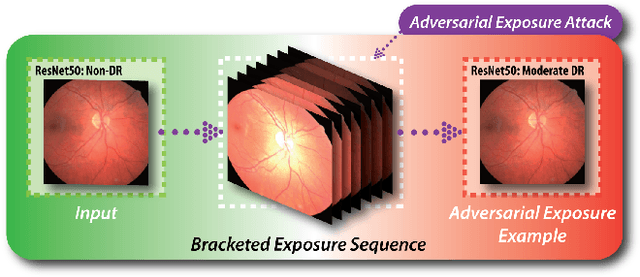
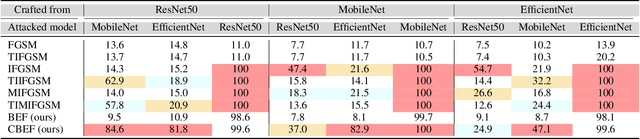
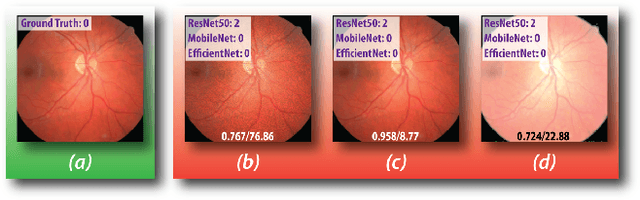

Diabetic retinopathy (DR) is a leading cause of vision loss in the world and numerous cutting-edge works have built powerful deep neural networks (DNNs) to automatically classify the DR cases via the retinal fundus images (RFIs). However, RFIs are usually affected by the widely existing camera exposure while the robustness of DNNs to the exposure is rarely explored. In this paper, we study this problem from the viewpoint of adversarial attack and identify a totally new task, i.e., adversarial exposure attack generating adversarial images by tuning image exposure to mislead the DNNs with significantly high transferability. To this end, we first implement a straightforward method, i.e., multiplicative-perturbation-based exposure attack, and reveal the big challenges of this new task. Then, to make the adversarial image naturalness, we propose the adversarial bracketed exposure fusion that regards the exposure attack as an element-wise bracketed exposure fusion problem in the Laplacian-pyramid space. Moreover, to realize high transferability, we further propose the convolutional bracketed exposure fusion where the element-wise multiplicative operation is extended to the convolution. We validate our method on the real public DR dataset with the advanced DNNs, e.g., ResNet50, MobileNet, and EfficientNet, showing our method can achieve high image quality and success rate of the transfer attack. Our method reveals the potential threats to the DNN-based DR automated diagnosis and can definitely benefit the development of exposure-robust automated DR diagnosis method in the future.
A Fuzzy Brute Force Matching Method for Binary Image Features
Apr 20, 2017
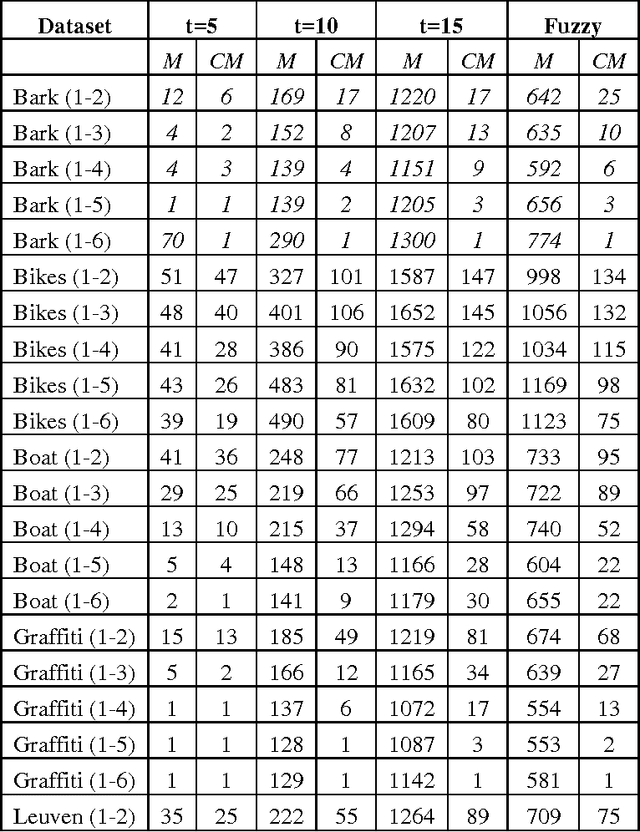
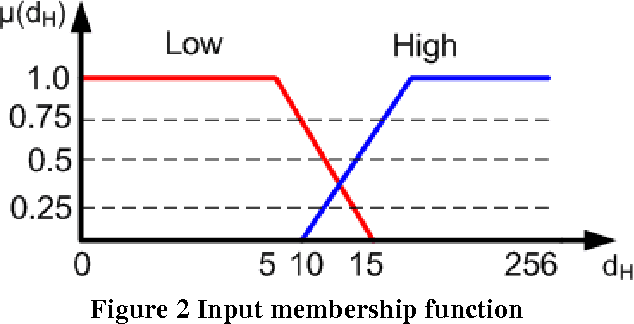
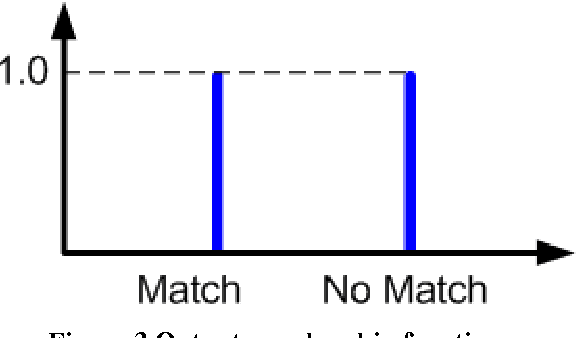
Matching of binary image features is an important step in many different computer vision applications. Conventionally, an arbitrary threshold is used to identify a correct match from incorrect matches using Hamming distance which may improve or degrade the matching results for different input images. This is mainly due to the image content which is affected by the scene, lighting and imaging conditions. This paper presents a fuzzy logic based approach for brute force matching of image features to overcome this situation. The method was tested using a well-known image database with known ground truth. The approach is shown to produce a higher number of correct matches when compared against constant distance thresholds. The nature of fuzzy logic which allows the vagueness of information and tolerance to errors has been successfully exploited in an image processing context. The uncertainty arising from the imaging conditions has been overcome with the use of compact fuzzy matching membership functions.
Toward Quantifying Ambiguities in Artistic Images
Aug 21, 2020
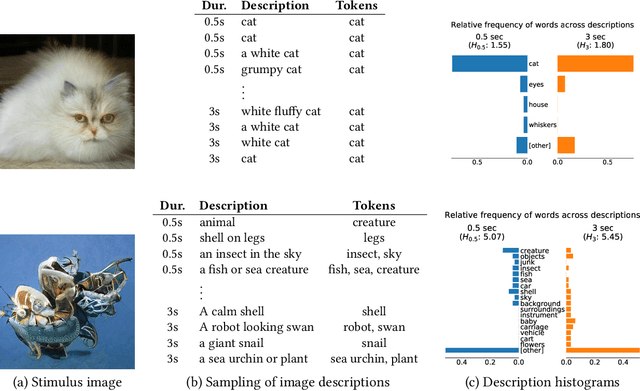


It has long been hypothesized that perceptual ambiguities play an important role in aesthetic experience: a work with some ambiguity engages a viewer more than one that does not. However, current frameworks for testing this theory are limited by the availability of stimuli and data collection methods. This paper presents an approach to measuring the perceptual ambiguity of a collection of images. Crowdworkers are asked to describe image content, after different viewing durations. Experiments are performed using images created with Generative Adversarial Networks, using the Artbreeder website. We show that text processing of viewer responses can provide a fine-grained way to measure and describe image ambiguities.
Classifying high-dimensional Gaussian mixtures: Where kernel methods fail and neural networks succeed
Feb 23, 2021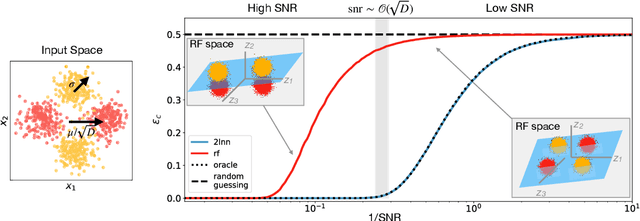
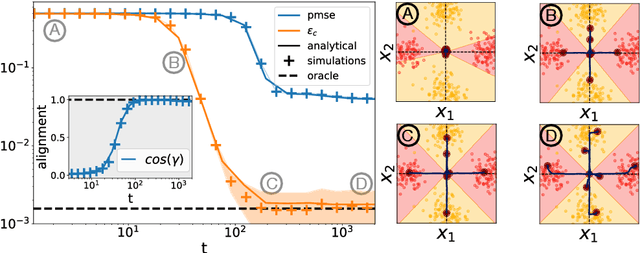
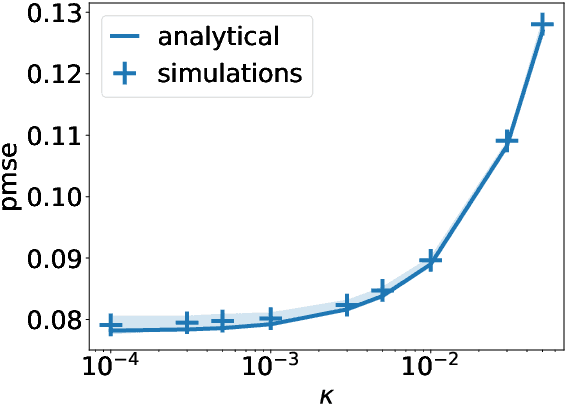
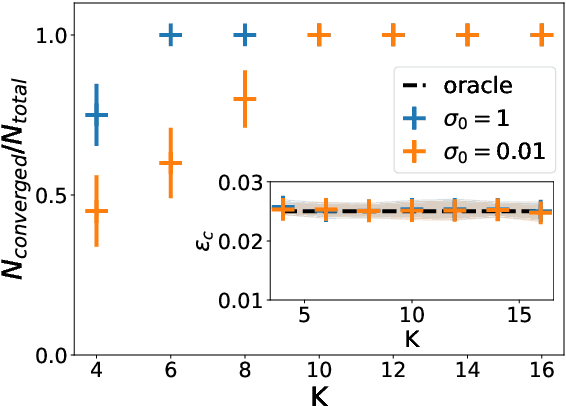
A recent series of theoretical works showed that the dynamics of neural networks with a certain initialisation are well-captured by kernel methods. Concurrent empirical work demonstrated that kernel methods can come close to the performance of neural networks on some image classification tasks. These results raise the question of whether neural networks only learn successfully if kernels also learn successfully, despite neural networks being more expressive. Here, we show theoretically that two-layer neural networks (2LNN) with only a few hidden neurons can beat the performance of kernel learning on a simple Gaussian mixture classification task. We study the high-dimensional limit where the number of samples is linearly proportional to the input dimension, and show that while small 2LNN achieve near-optimal performance on this task, lazy training approaches such as random features and kernel methods do not. Our analysis is based on the derivation of a closed set of equations that track the learning dynamics of the 2LNN and thus allow to extract the asymptotic performance of the network as a function of signal-to-noise ratio and other hyperparameters. We finally illustrate how over-parametrising the neural network leads to faster convergence, but does not improve its final performance.
Model-based Iterative Restoration for Binary Document Image Compression with Dictionary Learning
Apr 24, 2017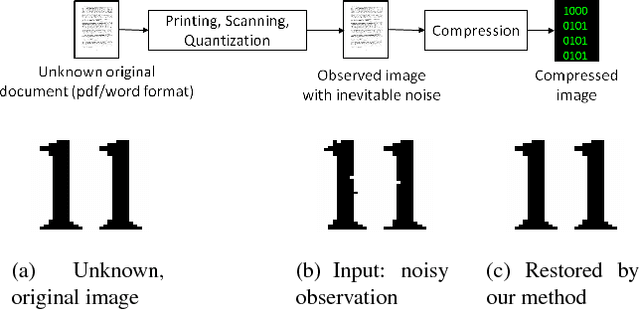

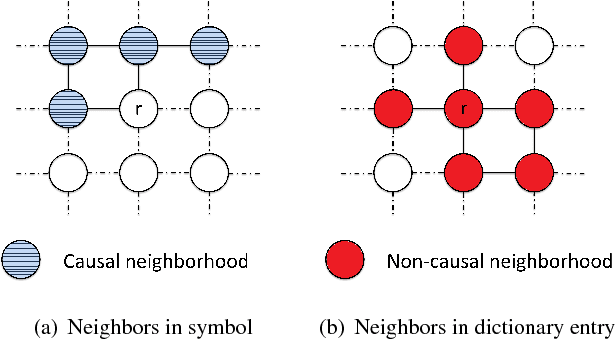
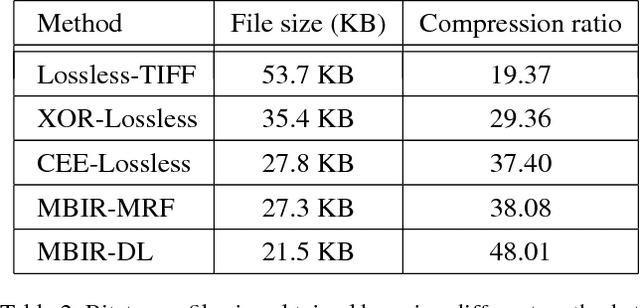
The inherent noise in the observed (e.g., scanned) binary document image degrades the image quality and harms the compression ratio through breaking the pattern repentance and adding entropy to the document images. In this paper, we design a cost function in Bayesian framework with dictionary learning. Minimizing our cost function produces a restored image which has better quality than that of the observed noisy image, and a dictionary for representing and encoding the image. After the restoration, we use this dictionary (from the same cost function) to encode the restored image following the symbol-dictionary framework by JBIG2 standard with the lossless mode. Experimental results with a variety of document images demonstrate that our method improves the image quality compared with the observed image, and simultaneously improves the compression ratio. For the test images with synthetic noise, our method reduces the number of flipped pixels by 48.2% and improves the compression ratio by 36.36% as compared with the best encoding methods. For the test images with real noise, our method visually improves the image quality, and outperforms the cutting-edge method by 28.27% in terms of the compression ratio.
FS-Net: Fast Shape-based Network for Category-Level 6D Object Pose Estimation with Decoupled Rotation Mechanism
Mar 12, 2021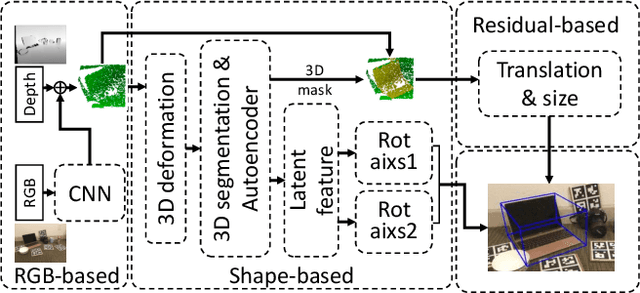
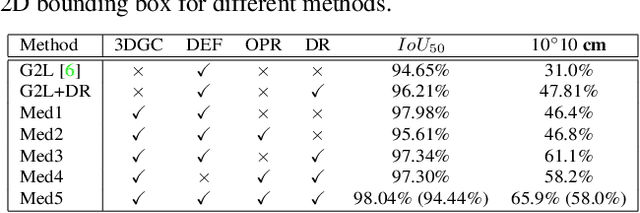
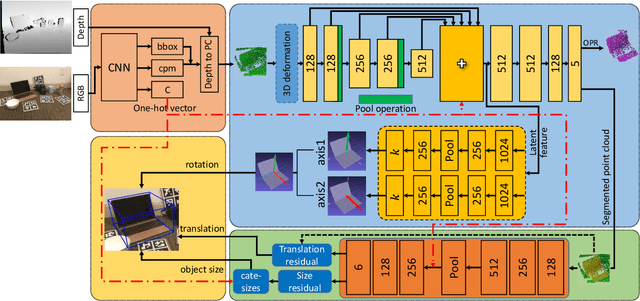
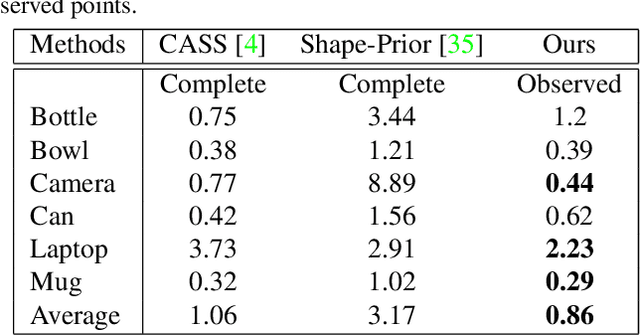
In this paper, we focus on category-level 6D pose and size estimation from monocular RGB-D image. Previous methods suffer from inefficient category-level pose feature extraction which leads to low accuracy and inference speed. To tackle this problem, we propose a fast shape-based network (FS-Net) with efficient category-level feature extraction for 6D pose estimation. First, we design an orientation aware autoencoder with 3D graph convolution for latent feature extraction. The learned latent feature is insensitive to point shift and object size thanks to the shift and scale-invariance properties of the 3D graph convolution. Then, to efficiently decode category-level rotation information from the latent feature, we propose a novel decoupled rotation mechanism that employs two decoders to complementarily access the rotation information. Meanwhile, we estimate translation and size by two residuals, which are the difference between the mean of object points and ground truth translation, and the difference between the mean size of the category and ground truth size, respectively. Finally, to increase the generalization ability of FS-Net, we propose an online box-cage based 3D deformation mechanism to augment the training data. Extensive experiments on two benchmark datasets show that the proposed method achieves state-of-the-art performance in both category- and instance-level 6D object pose estimation. Especially in category-level pose estimation, without extra synthetic data, our method outperforms existing methods by 6.3% on the NOCS-REAL dataset.