 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Geometric Style Transfer
Jul 10, 2020

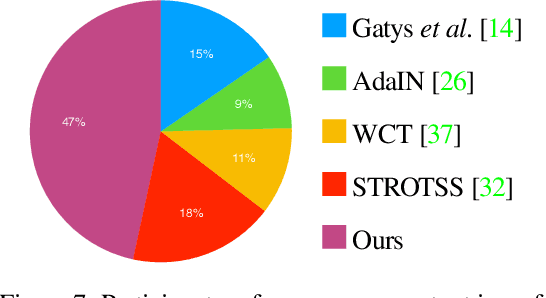
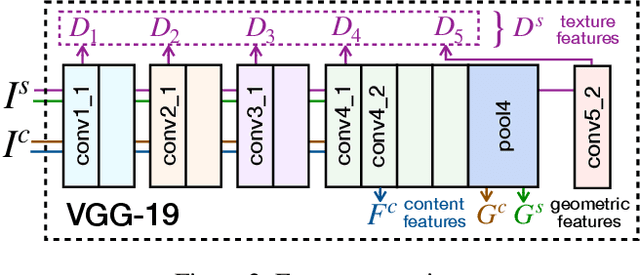
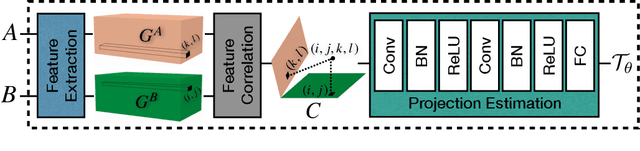
Neural style transfer (NST), where an input image is rendered in the style of another image, has been a topic of considerable progress in recent years. Research over that time has been dominated by transferring aspects of color and texture, yet these factors are only one component of style. Other factors of style include composition, the projection system used, and the way in which artists warp and bend objects. Our contribution is to introduce a neural architecture that supports transfer of geometric style. Unlike recent work in this area, we are unique in being general in that we are not restricted by semantic content. This new architecture runs prior to a network that transfers texture style, enabling us to transfer texture to a warped image. This form of network supports a second novelty: we extend the NST input paradigm. Users can input content/style pair as is common, or they can chose to input a content/texture-style/geometry-style triple. This three image input paradigm divides style into two parts and so provides significantly greater versatility to the output we can produce. We provide user studies that show the quality of our output, and quantify the importance of geometric style transfer to style recognition by humans.
Low-dose spectral CT reconstruction using L0 image gradient and tensor dictionary
Jul 24, 2018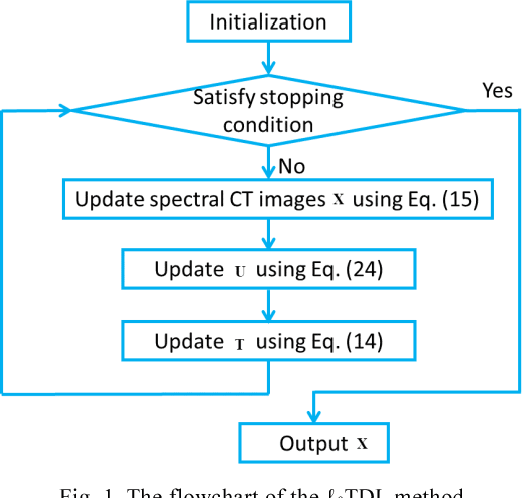



Spectral computed tomography (CT) has a great superiority in lesion detection, tissue characterization and material decomposition. To further extend its potential clinical applications, in this work, we propose an improved tensor dictionary learning method for low-dose spectral CT reconstruction with a constraint of image gradient L0-norm, which is named as L0TDL. The L0TDL method inherits the advantages of tensor dictionary learning (TDL) by employing the similarity of spectral CT images. On the other hand, by introducing the L0-norm constraint in gradient image domain, the proposed method emphasizes the spatial sparsity to overcome the weakness of TDL on preserving edge information. The alternative direction minimization method (ADMM) is employed to solve the proposed method. Both numerical simulations and real mouse studies are perform to evaluate the proposed method. The results show that the proposed L0TDL method outperforms other competing methods, such as total variation (TV) minimization, TV with low rank (TV+LR), and TDL methods.
CoADNet: Collaborative Aggregation-and-Distribution Networks for Co-Salient Object Detection
Nov 10, 2020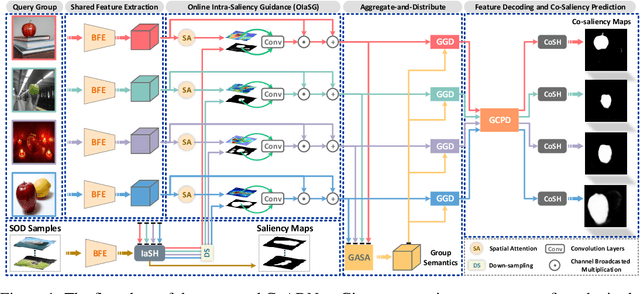
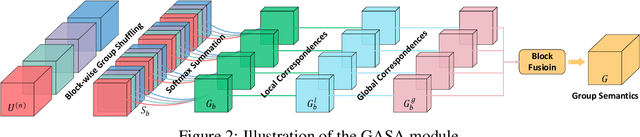
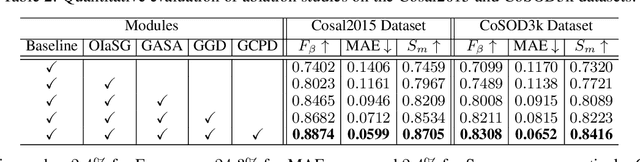

Co-Salient Object Detection (CoSOD) aims at discovering salient objects that repeatedly appear in a given query group containing two or more relevant images. One challenging issue is how to effectively capture co-saliency cues by modeling and exploiting inter-image relationships. In this paper, we present an end-to-end collaborative aggregation-and-distribution network (CoADNet) to capture both salient and repetitive visual patterns from multiple images. First, we integrate saliency priors into the backbone features to suppress the redundant background information through an online intra-saliency guidance structure. After that, we design a two-stage aggregate-and-distribute architecture to explore group-wise semantic interactions and produce the co-saliency features. In the first stage, we propose a group-attentional semantic aggregation module that models inter-image relationships to generate the group-wise semantic representations. In the second stage, we propose a gated group distribution module that adaptively distributes the learned group semantics to different individuals in a dynamic gating mechanism. Finally, we develop a group consistency preserving decoder tailored for the CoSOD task, which maintains group constraints during feature decoding to predict more consistent full-resolution co-saliency maps. The proposed CoADNet is evaluated on four prevailing CoSOD benchmark datasets, which demonstrates the remarkable performance improvement over ten state-of-the-art competitors.
Few-Shot Learning for Road Object Detection
Jan 29, 2021
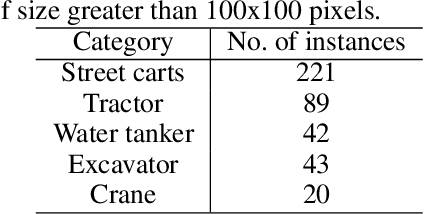
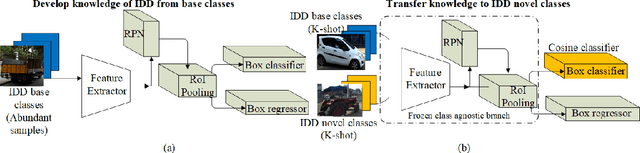

Few-shot learning is a problem of high interest in the evolution of deep learning. In this work, we consider the problem of few-shot object detection (FSOD) in a real-world, class-imbalanced scenario. For our experiments, we utilize the India Driving Dataset (IDD), as it includes a class of less-occurring road objects in the image dataset and hence provides a setup suitable for few-shot learning. We evaluate both metric-learning and meta-learning based FSOD methods, in two experimental settings: (i) representative (same-domain) splits from IDD, that evaluates the ability of a model to learn in the context of road images, and (ii) object classes with less-occurring object samples, similar to the open-set setting in real-world. From our experiments, we demonstrate that the metric-learning method outperforms meta-learning on the novel classes by (i) 11.2 mAP points on the same domain, and (ii) 1.0 mAP point on the open-set. We also show that our extension of object classes in a real-world open dataset offers a rich ground for few-shot learning studies.
Deep Learning-Based Regression and Classification for Automatic Landmark Localization in Medical Images
Jul 10, 2020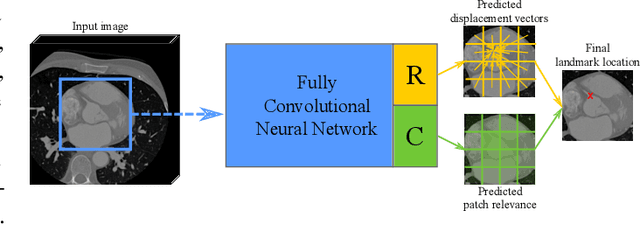
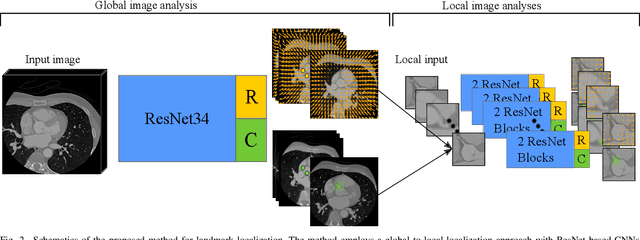
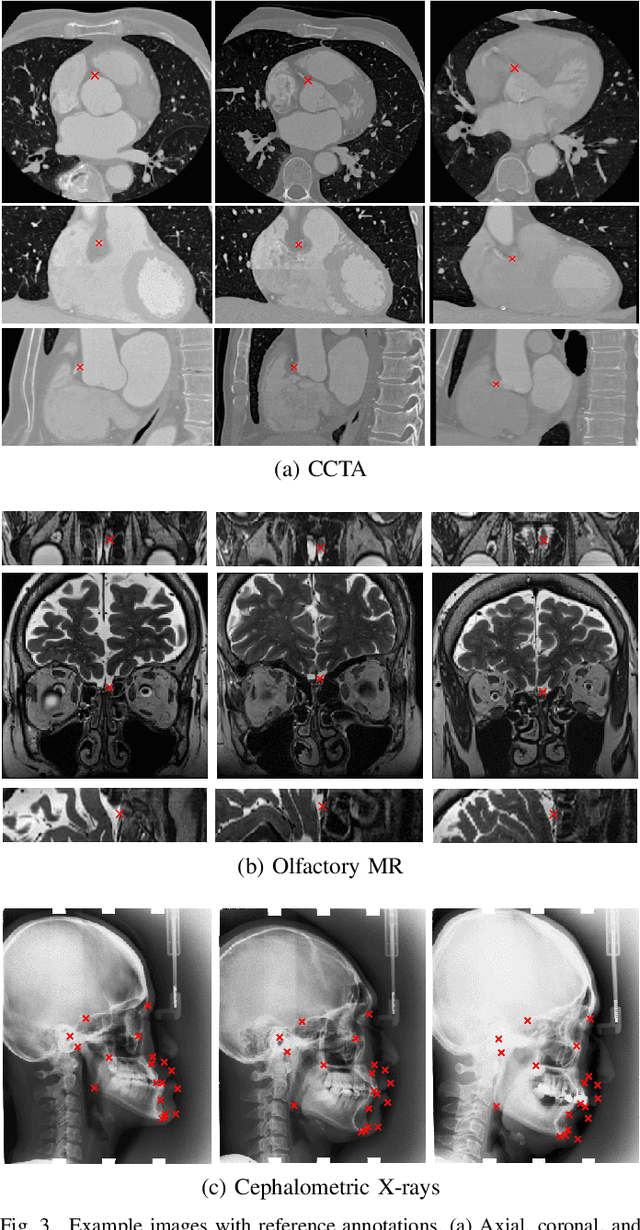
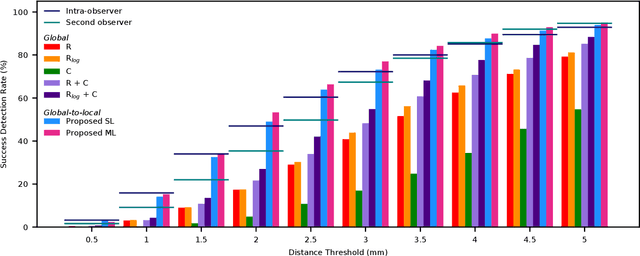
In this study, we propose a fast and accurate method to automatically localize anatomical landmarks in medical images. We employ a global-to-local localization approach using fully convolutional neural networks (FCNNs). First, a global FCNN localizes multiple landmarks through the analysis of image patches, performing regression and classification simultaneously. In regression, displacement vectors pointing from the center of image patches towards landmark locations are determined. In classification, presence of landmarks of interest in the patch is established. Global landmark locations are obtained by averaging the predicted displacement vectors, where the contribution of each displacement vector is weighted by the posterior classification probability of the patch that it is pointing from. Subsequently, for each landmark localized with global localization, local analysis is performed. Specialized FCNNs refine the global landmark locations by analyzing local sub-images in a similar manner, i.e. by performing regression and classification simultaneously and combining the results. Evaluation was performed through localization of 8 anatomical landmarks in CCTA scans, 2 landmarks in olfactory MR scans, and 19 landmarks in cephalometric X-rays. We demonstrate that the method performs similarly to a second observer and is able to localize landmarks in a diverse set of medical images, differing in image modality, image dimensionality, and anatomical coverage.
FrugalMCT: Efficient Online ML API Selection for Multi-Label Classification Tasks
Feb 18, 2021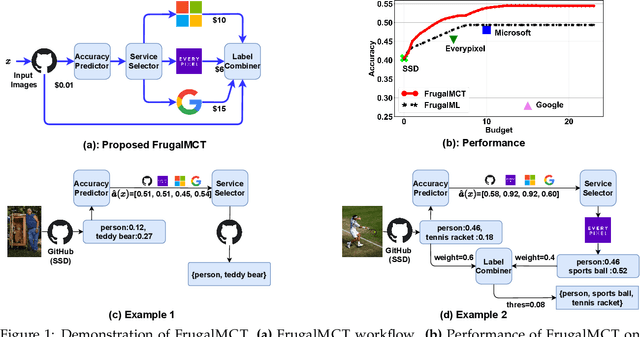
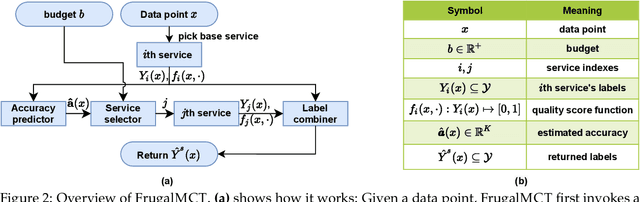
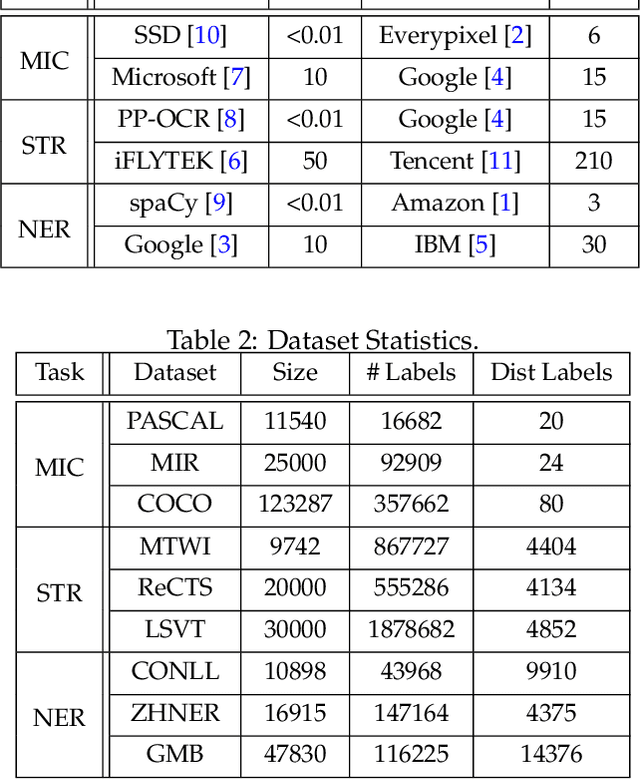
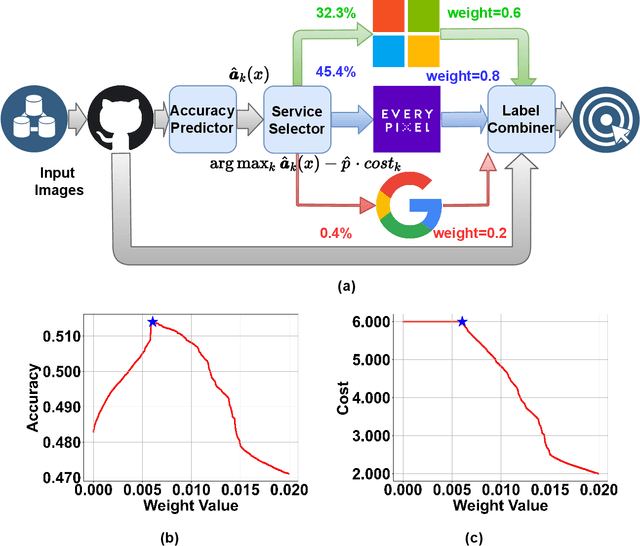
Multi-label classification tasks such as OCR and multi-object recognition are a major focus of the growing machine learning as a service industry. While many multi-label prediction APIs are available, it is challenging for users to decide which API to use for their own data and budget, due to the heterogeneity in those APIs' price and performance. Recent work shows how to select from single-label prediction APIs. However the computation complexity of the previous approach is exponential in the number of labels and hence is not suitable for settings like OCR. In this work, we propose FrugalMCT, a principled framework that adaptively selects the APIs to use for different data in an online fashion while respecting user's budget. The API selection problem is cast as an integer linear program, which we show has a special structure that we leverage to develop an efficient online API selector with strong performance guarantees. We conduct systematic experiments using ML APIs from Google, Microsoft, Amazon, IBM, Tencent and other providers for tasks including multi-label image classification, scene text recognition and named entity recognition. Across diverse tasks, FrugalMCT can achieve over 90% cost reduction while matching the accuracy of the best single API, or up to 8% better accuracy while matching the best API's cost.
ITSELF: Iterative Saliency Estimation fLexible Framework
Jun 30, 2020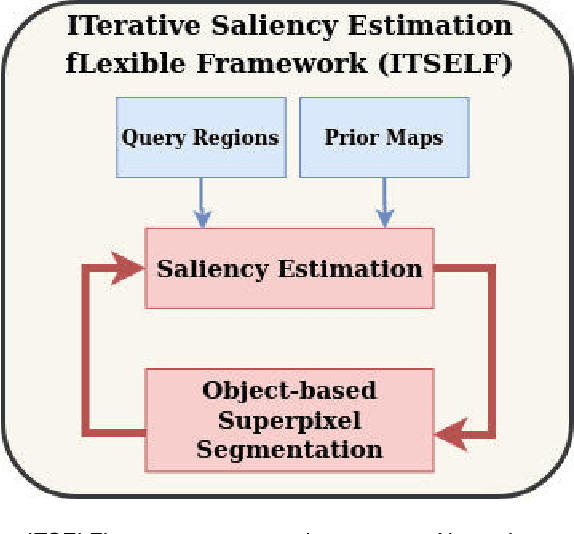
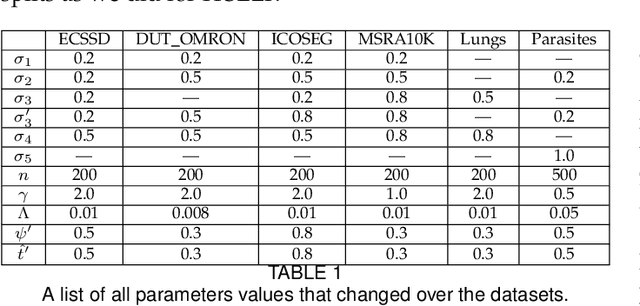
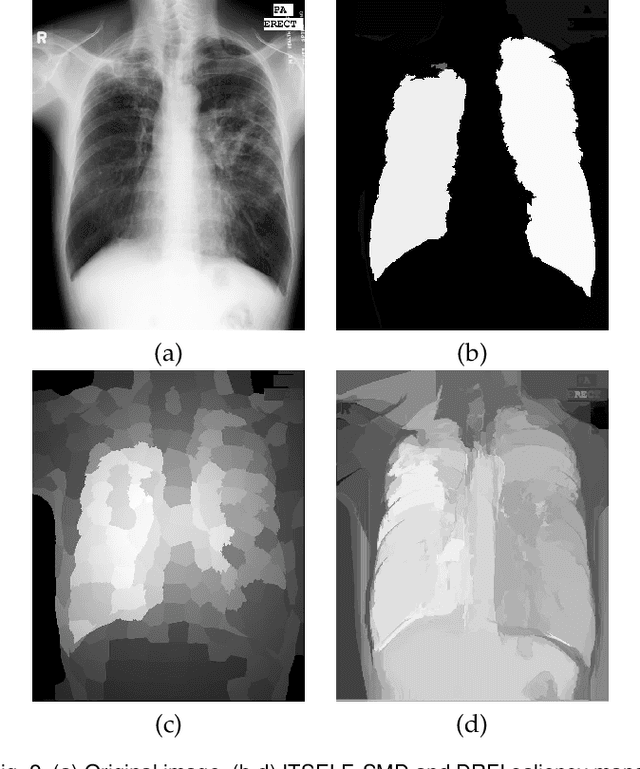
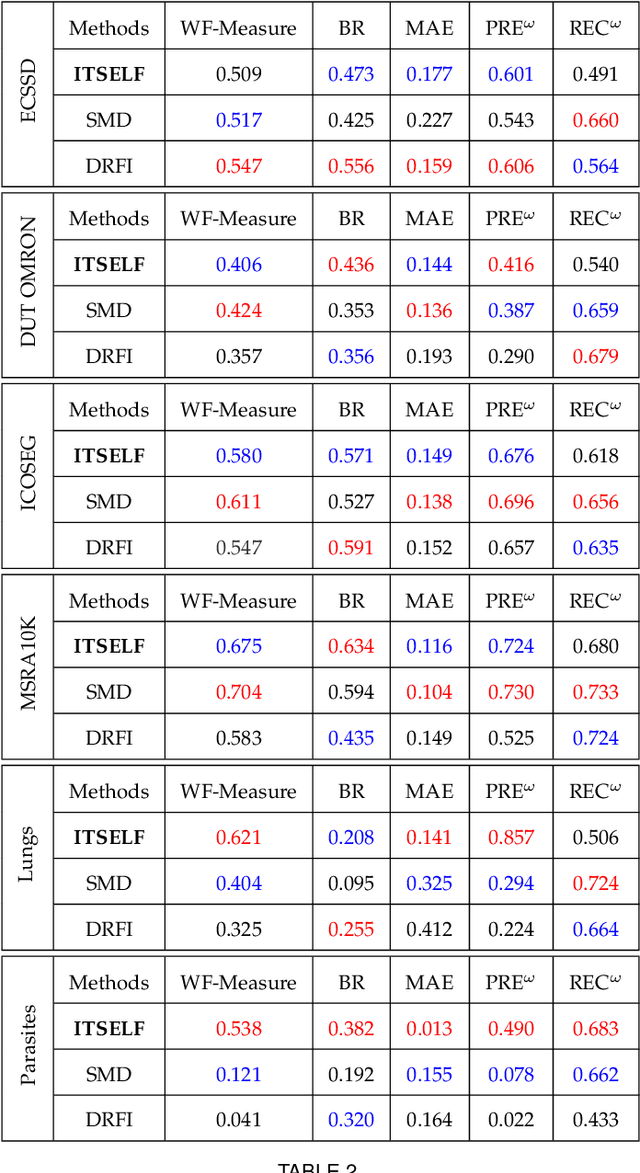
Saliency object detection estimates the objects that most stand out in an image. The available unsupervised saliency estimators rely on a pre-determined set of assumptions of how humans perceive saliency to create discriminating features. By fixing the pre-selected assumptions as integral part of their models, these methods cannot be easily extended for specific settings and different image domains. We then propose an superpixel-based ITerative Saliency Estimation fLexible Framework (ITSELF) that allows any number of user-defined assumptions to be added to the model when required. Thanks to recent advancement on superpixel segmentation algorithms, saliency-maps can be used to improve superpixel delineation. By combining a saliency-based superpixel algorithm to a superpixel-based saliency estimator, we propose a novel saliency/superpixel self-improving loop to iteratively enhance saliency maps. We compared ITSELF to two state-of-the-art saliency estimators on five metrics and six datasets, four of which are composed of natural-images, and two of biomedical-images. Experiments show that our approach is more robust than the compared methods, presenting competitive results on natural-image datasets and outperforming them on biomedical-image datasets.
Beyond Convolutions: A Novel Deep Learning Approach for Raw Seismic Data Ingestion
Feb 26, 2021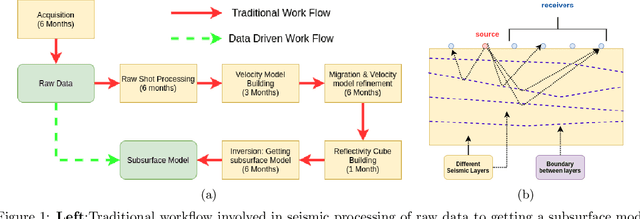

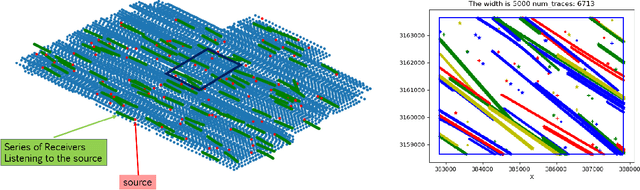
Traditional seismic processing workflows (SPW) are expensive, requiring over a year of human and computational effort. Deep learning (DL) based data-driven seismic workflows (DSPW) hold the potential to reduce these timelines to a few minutes. Raw seismic data (terabytes) and required subsurface prediction (gigabytes) are enormous. This large-scale, spatially irregular time-series data poses seismic data ingestion (SDI) as an unconventional yet fundamental problem in DSPW. Current DL research is limited to small-scale simplified synthetic datasets as they treat seismic data like images and process them with convolution networks. Real seismic data, however, is at least 5D. Applying 5D convolutions to this scale is computationally prohibitive. Moreover, raw seismic data is highly unstructured and hence inherently non-image like. We propose a fundamental shift to move away from convolutions and introduce SESDI: Set Embedding based SDI approach. SESDI first breaks down the mammoth task of large-scale prediction into an efficient compact auxiliary task. SESDI gracefully incorporates irregularities in data with its novel model architecture. We believe SESDI is the first successful demonstration of end-to-end learning on real seismic data. SESDI achieves SSIM of over 0.8 on velocity inversion task on real proprietary data from the Gulf of Mexico and outperforms the state-of-the-art U-Net model on synthetic datasets.
Auxiliary Signal-Guided Knowledge Encoder-Decoder for Medical Report Generation
Jun 06, 2020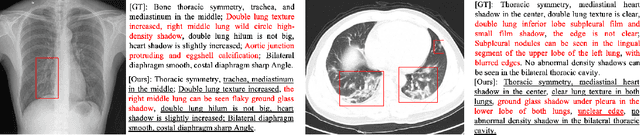
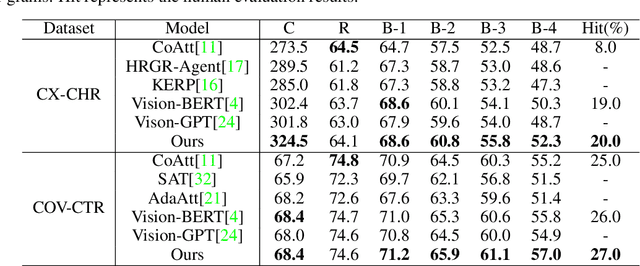
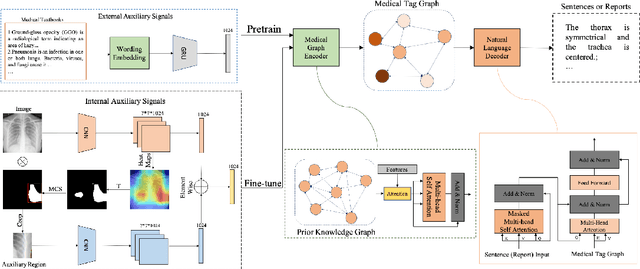
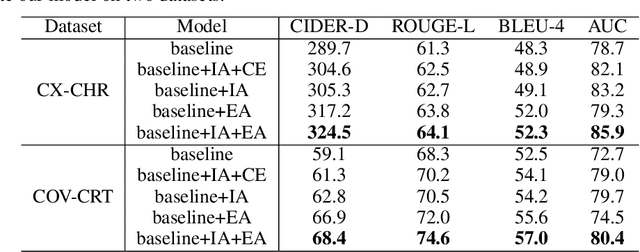
Beyond the common difficulties faced in the natural image captioning, medical report generation specifically requires the model to describe a medical image with a fine-grained and semantic-coherence paragraph that should satisfy both medical commonsense and logic. Previous works generally extract the global image features and attempt to generate a paragraph that is similar to referenced reports; however, this approach has two limitations. Firstly, the regions of primary interest to radiologists are usually located in a small area of the global image, meaning that the remainder parts of the image could be considered as irrelevant noise in the training procedure. Secondly, there are many similar sentences used in each medical report to describe the normal regions of the image, which causes serious data bias. This deviation is likely to teach models to generate these inessential sentences on a regular basis. To address these problems, we propose an Auxiliary Signal-Guided Knowledge Encoder-Decoder (ASGK) to mimic radiologists' working patterns. In more detail, ASGK integrates internal visual feature fusion and external medical linguistic information to guide medical knowledge transfer and learning. The core structure of ASGK consists of a medical graph encoder and a natural language decoder, inspired by advanced Generative Pre-Training (GPT). Experiments on the CX-CHR dataset and our COVID-19 CT Report dataset demonstrate that our proposed ASGK is able to generate a robust and accurate report, and moreover outperforms state-of-the-art methods on both medical terminology classification and paragraph generation metrics.
Iterative Deep Convolutional Encoder-Decoder Network for Medical Image Segmentation
Aug 11, 2017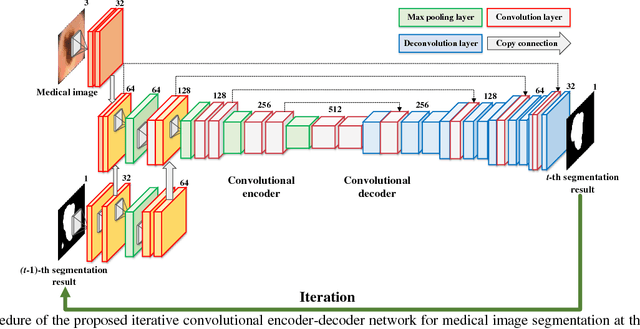
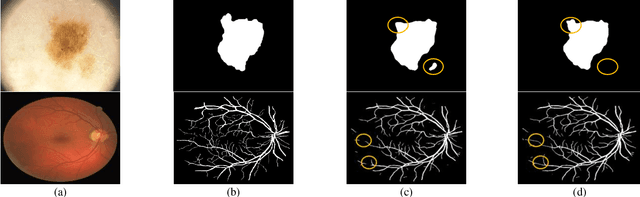
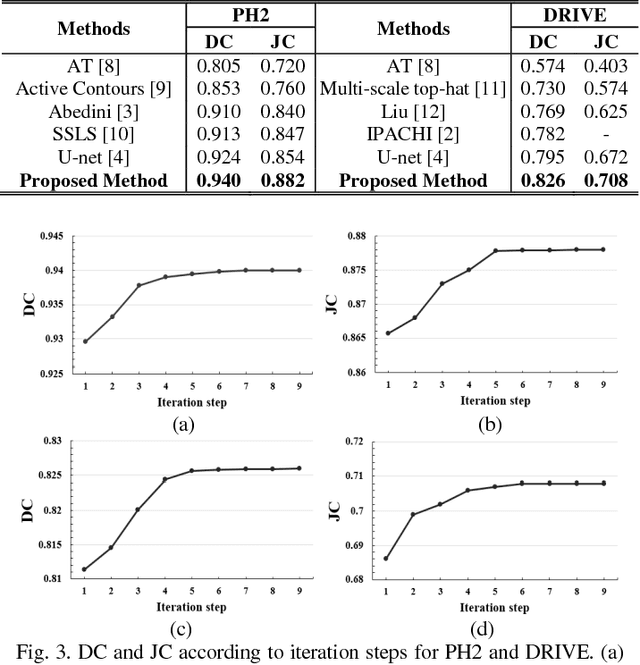
In this paper, we propose a novel medical image segmentation using iterative deep learning framework. We have combined an iterative learning approach and an encoder-decoder network to improve segmentation results, which enables to precisely localize the regions of interest (ROIs) including complex shapes or detailed textures of medical images in an iterative manner. The proposed iterative deep convolutional encoder-decoder network consists of two main paths: convolutional encoder path and convolutional decoder path with iterative learning. Experimental results show that the proposed iterative deep learning framework is able to yield excellent medical image segmentation performances for various medical images. The effectiveness of the proposed method has been proved by comparing with other state-of-the-art medical image segmentation methods.