 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Video-based Hierarchical Species Classification for Longline Fishing Monitoring
Feb 06, 2021

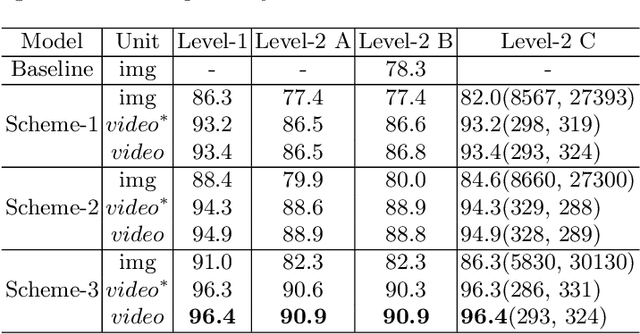
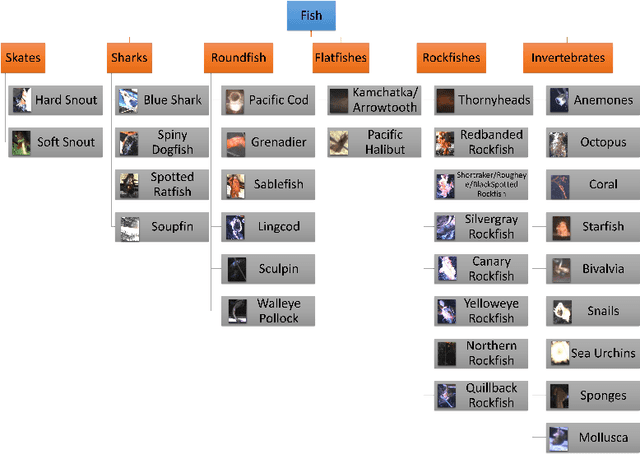
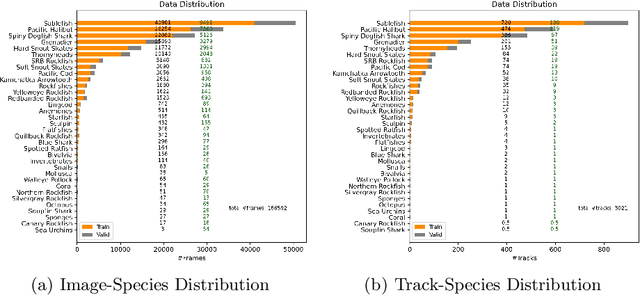
The goal of electronic monitoring (EM) of longline fishing is to monitor the fish catching activities on fishing vessels, either for the regulatory compliance or catch counting. Hierarchical classification based on videos allows for inexpensive and efficient fish species identification of catches from longline fishing, where fishes are under severe deformation and self-occlusion during the catching process. More importantly, the flexibility of hierarchical classification mitigates the laborious efforts of human reviews by providing confidence scores in different hierarchical levels. Some related works either use cascaded models for hierarchical classification or make predictions per image or predict one overlapping hierarchical data structure of the dataset in advance. However, with a known non-overlapping hierarchical data structure provided by fisheries scientists, our method enforces the hierarchical data structure and introduces an efficient training and inference strategy for video-based fisheries data. Our experiments show that the proposed method outperforms the classic flat classification system significantly and our ablation study justifies our contributions in CNN model design, training strategy, and the video-based inference schemes for the hierarchical fish species classification task.
Generating Natural Questions About an Image
Jun 09, 2016



There has been an explosion of work in the vision & language community during the past few years from image captioning to video transcription, and answering questions about images. These tasks have focused on literal descriptions of the image. To move beyond the literal, we choose to explore how questions about an image are often directed at commonsense inference and the abstract events evoked by objects in the image. In this paper, we introduce the novel task of Visual Question Generation (VQG), where the system is tasked with asking a natural and engaging question when shown an image. We provide three datasets which cover a variety of images from object-centric to event-centric, with considerably more abstract training data than provided to state-of-the-art captioning systems thus far. We train and test several generative and retrieval models to tackle the task of VQG. Evaluation results show that while such models ask reasonable questions for a variety of images, there is still a wide gap with human performance which motivates further work on connecting images with commonsense knowledge and pragmatics. Our proposed task offers a new challenge to the community which we hope furthers interest in exploring deeper connections between vision & language.
Privacy-Preserving Video Classification with Convolutional Neural Networks
Feb 06, 2021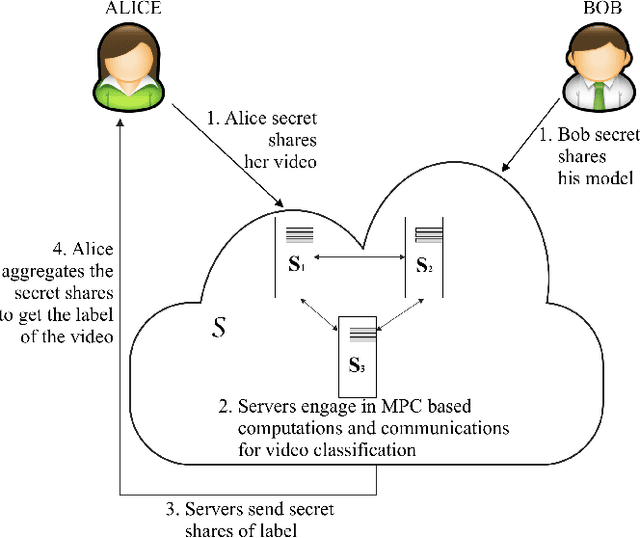
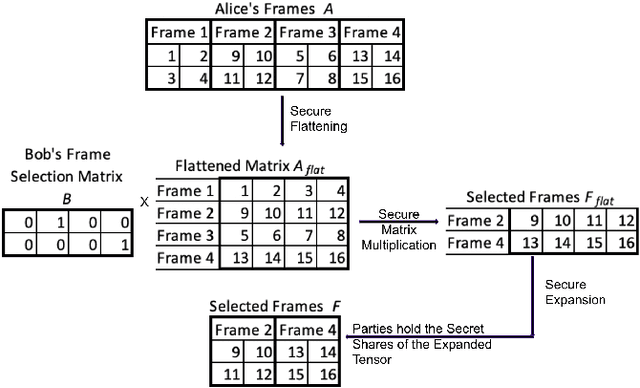


Many video classification applications require access to personal data, thereby posing an invasive security risk to the users' privacy. We propose a privacy-preserving implementation of single-frame method based video classification with convolutional neural networks that allows a party to infer a label from a video without necessitating the video owner to disclose their video to other entities in an unencrypted manner. Similarly, our approach removes the requirement of the classifier owner from revealing their model parameters to outside entities in plaintext. To this end, we combine existing Secure Multi-Party Computation (MPC) protocols for private image classification with our novel MPC protocols for oblivious single-frame selection and secure label aggregation across frames. The result is an end-to-end privacy-preserving video classification pipeline. We evaluate our proposed solution in an application for private human emotion recognition. Our results across a variety of security settings, spanning honest and dishonest majority configurations of the computing parties, and for both passive and active adversaries, demonstrate that videos can be classified with state-of-the-art accuracy, and without leaking sensitive user information.
Automatic joint damage quantification using computer vision and deep learning
Oct 29, 2020
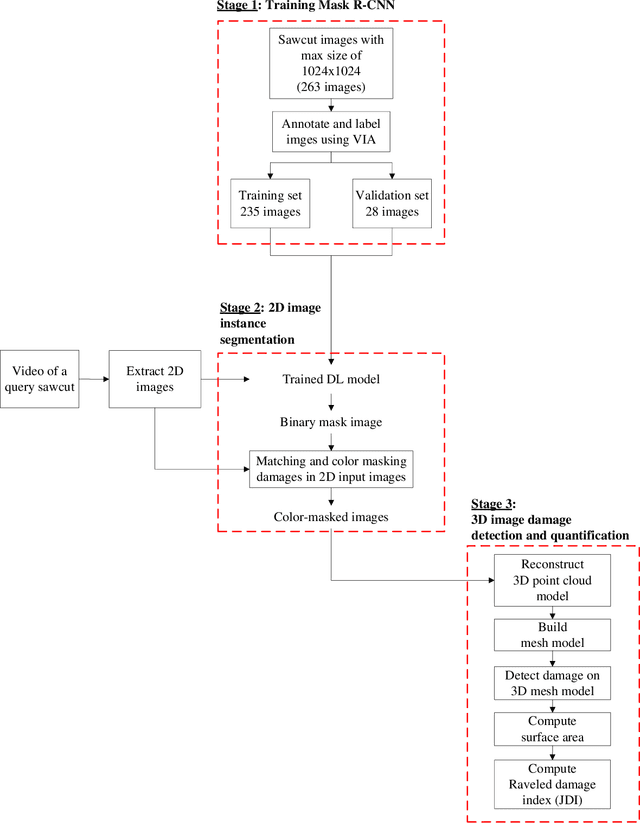
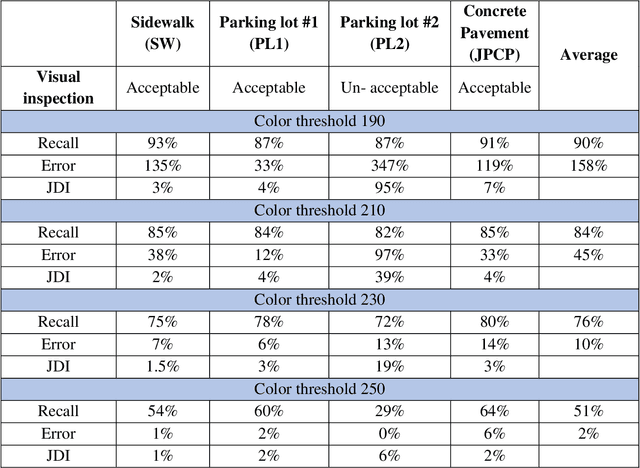
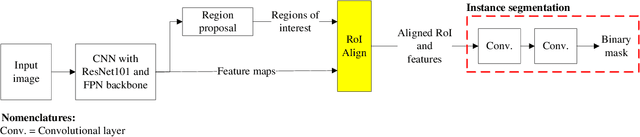
Joint raveled or spalled damage (henceforth called joint damage) can affect the safety and long-term performance of concrete pavements. It is important to assess and quantify the joint damage over time to assist in building action plans for maintenance, predicting maintenance costs, and maximize the concrete pavement service life. A framework for the accurate, autonomous, and rapid quantification of joint damage with a low-cost camera is proposed using a computer vision technique with a deep learning (DL) algorithm. The DL model is employed to train 263 images of sawcuts with joint damage. The trained DL model is used for pixel-wise color-masking joint damage in a series of query 2D images, which are used to reconstruct a 3D image using open-source structure from motion algorithm. Another damage quantification algorithm using a color threshold is applied to detect and compute the surface area of the damage in the 3D reconstructed image. The effectiveness of the framework was validated through inspecting joint damage at four transverse contraction joints in Illinois, USA, including three acceptable joints and one unacceptable joint by visual inspection. The results show the framework achieves 76% recall and 10% error.
Agrupamento de Pixels para o Reconhecimento de Faces
Jun 10, 2020This research starts with the observation that face recognition can suffer a low impact from significant image shrinkage. To explain this fact, we proposed the Pixel Clustering methodology. It defines regions in the image in which its pixels are very similar to each other. We extract features from each region. We used three face databases in the experiments. We noticed that 512 is the maximum number of features needed for high accuracy image recognition. The proposed method is also robust, even if only it uses a few classes from the training set.
Two-way kernel matrix puncturing: towards resource-efficient PCA and spectral clustering
Feb 25, 2021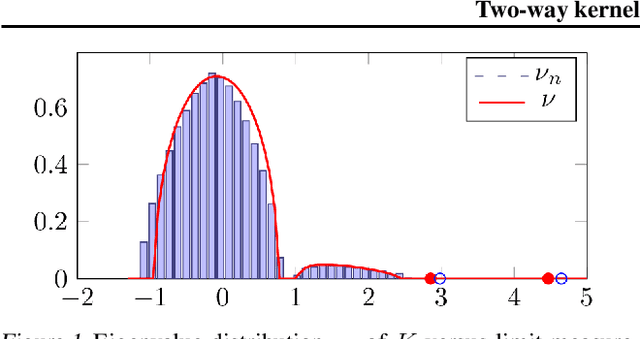
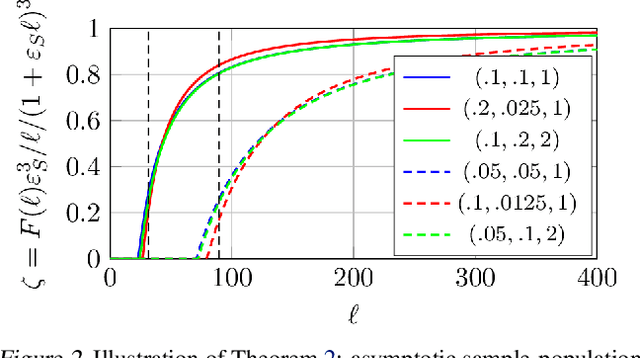
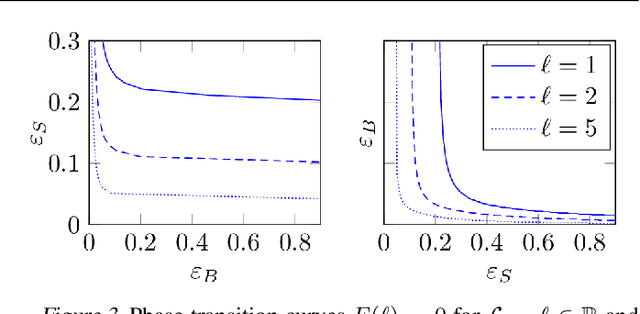
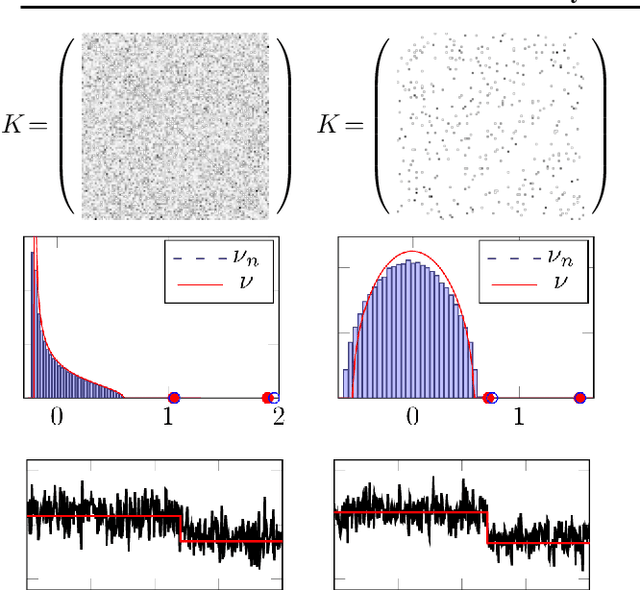
The article introduces an elementary cost and storage reduction method for spectral clustering and principal component analysis. The method consists in randomly "puncturing" both the data matrix $X\in\mathbb{C}^{p\times n}$ (or $\mathbb{R}^{p\times n}$) and its corresponding kernel (Gram) matrix $K$ through Bernoulli masks: $S\in\{0,1\}^{p\times n}$ for $X$ and $B\in\{0,1\}^{n\times n}$ for $K$. The resulting "two-way punctured" kernel is thus given by $K=\frac{1}{p}[(X \odot S)^{\sf H} (X \odot S)] \odot B$. We demonstrate that, for $X$ composed of independent columns drawn from a Gaussian mixture model, as $n,p\to\infty$ with $p/n\to c_0\in(0,\infty)$, the spectral behavior of $K$ -- its limiting eigenvalue distribution, as well as its isolated eigenvalues and eigenvectors -- is fully tractable and exhibits a series of counter-intuitive phenomena. We notably prove, and empirically confirm on GAN-generated image databases, that it is possible to drastically puncture the data, thereby providing possibly huge computational and storage gains, for a virtually constant (clustering of PCA) performance. This preliminary study opens as such the path towards rethinking, from a large dimensional standpoint, computational and storage costs in elementary machine learning models.
Unsupervised Learning of Anomaly Detection from Contaminated Image Data using Simultaneous Encoder Training
May 27, 2019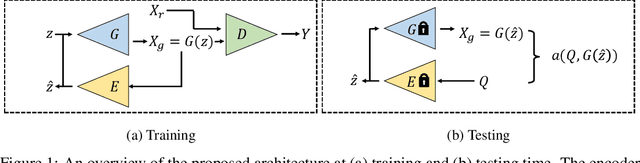
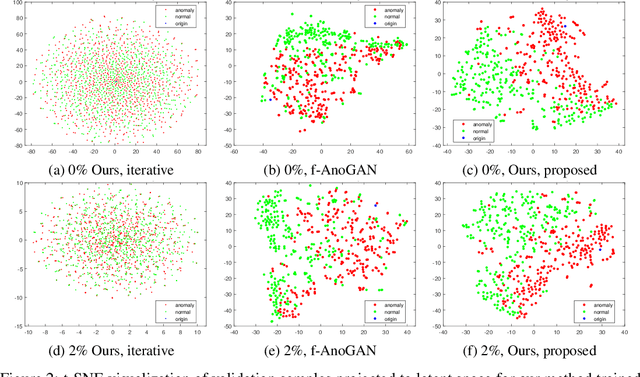
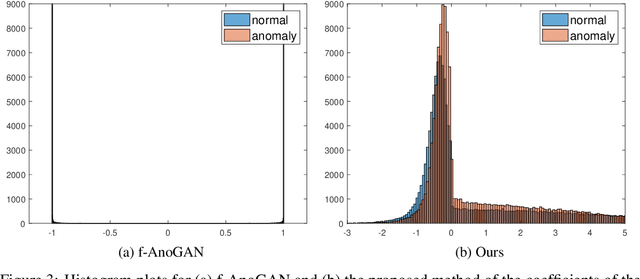
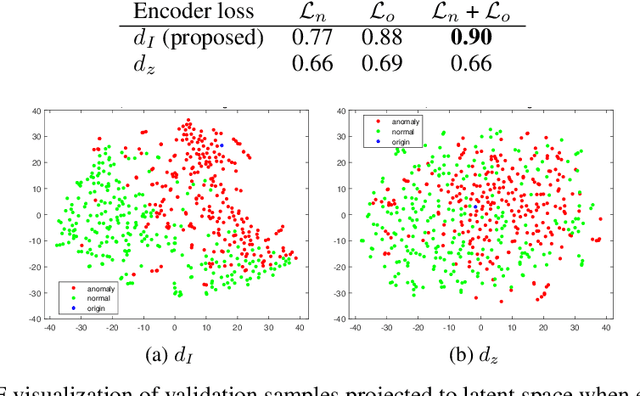
Anomaly detection in high-dimensional data, such as images, is a challenging problem recently subject to intense research. Generative Adversarial Networks (GANs) have the ability to model the normal data distribution and, therefore, detect anomalies. Previously published GAN-based methods often assume that anomaly-free data is available for training. However, in real-life scenarios, this is not always the case. In this work, we examine the effects of contaminating training data with anomalies for state-of-the-art GAN-based anomaly detection methods. As expected, detection performance is reduced. To mitigate this problem, we propose to add an additional encoder network already at training time to adjust the structure of the latent space. As we show in our experiments, the distance in latent space from a query image to the origin is a highly significant cue to discriminate anomalies from normal data. The proposed method achieves state-of-the-art performance on CIFAR-10 as well as on a large new dataset with cell images.
Fast and Incremental Loop Closure Detection with Deep Features and Proximity Graphs
Sep 29, 2020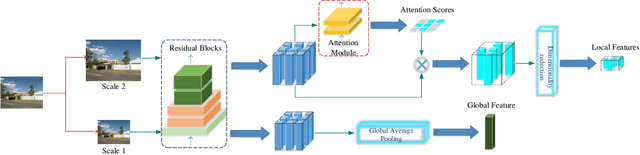

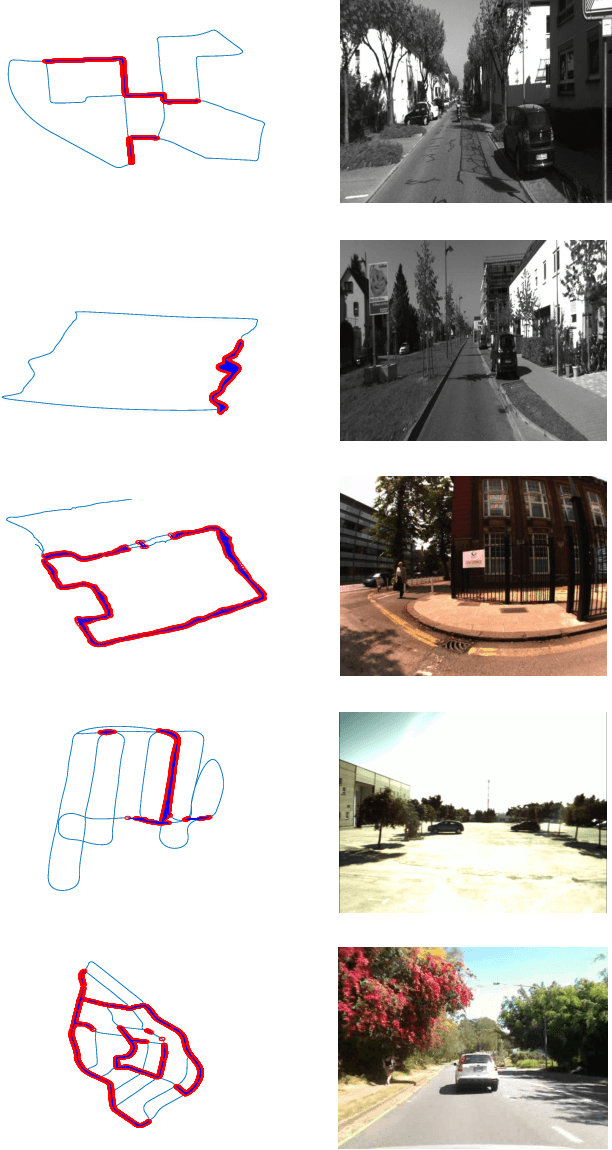
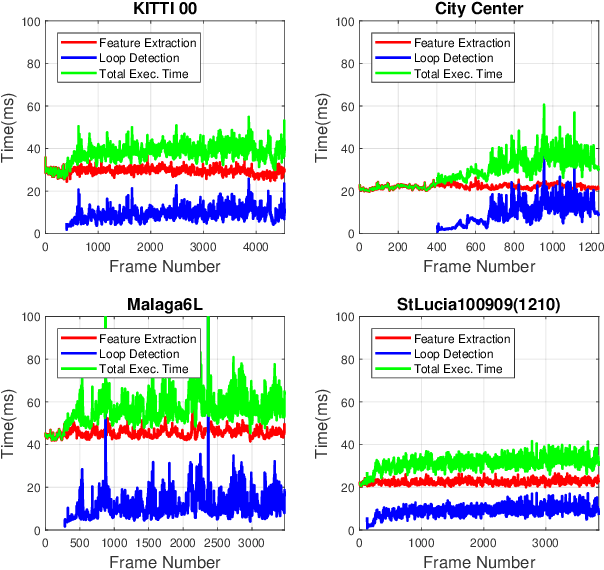
In recent years, methods concerning the place recognition task have been extensively examined from the robotics community within the scope of simultaneous localization and mapping applications. In this article, an appearance-based loop closure detection pipeline is proposed, entitled "FILD++" (Fast and Incremental Loop closure Detection). When the incoming camera observation arrives, global and local visual features are extracted through two passes of a single convolutional neural network. Subsequently, a modified hierarchical-navigable small-world graph incrementally generates a visual database that represents the robot's traversed path based on global features. Given the query sensor measurement, similar locations from the trajectory are retrieved using these representations, while an image-to-image pairing is further evaluated thanks to the spatial information provided by the local features. Exhaustive experiments on several publicly-available datasets exhibit the system's high performance and low execution time compared to other contemporary state-of-the-art pipelines.
Planning Paths Through Unknown Space by Imagining What Lies Therein
Nov 14, 2020
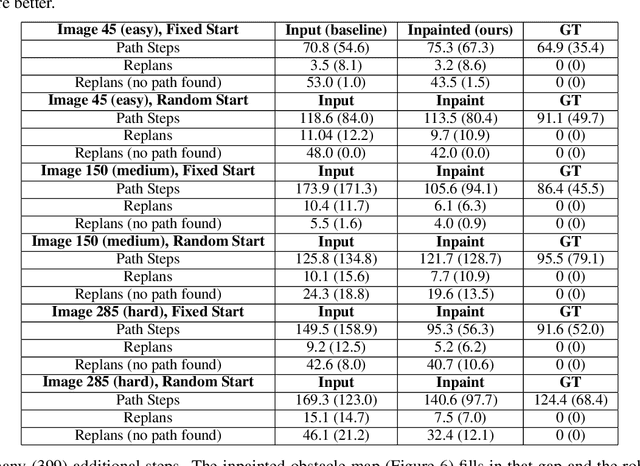


This paper presents a novel framework for planning paths in maps containing unknown spaces, such as from occlusions. Our approach takes as input a semantically-annotated point cloud, and leverages an image inpainting neural network to generate a reasonable model of unknown space as free or occupied. Our validation campaign shows that it is possible to greatly increase the performance of standard pathfinding algorithms which adopt the general optimistic assumption of treating unknown space as free.
Masked Linear Regression for Learning Local Receptive Fields for Facial Expression Synthesis
Nov 18, 2020

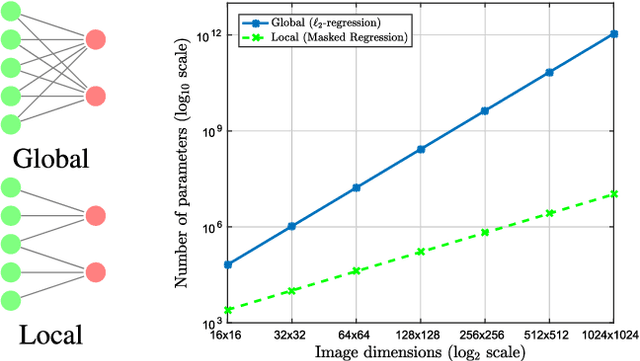
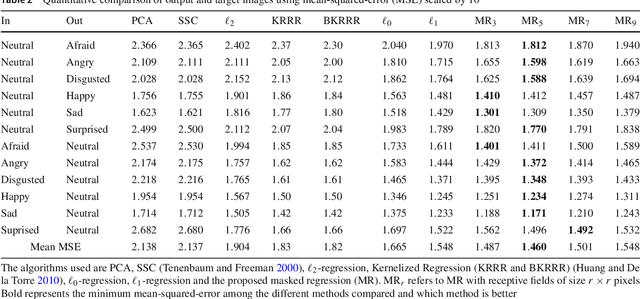
Compared to facial expression recognition, expression synthesis requires a very high-dimensional mapping. This problem exacerbates with increasing image sizes and limits existing expression synthesis approaches to relatively small images. We observe that facial expressions often constitute sparsely distributed and locally correlated changes from one expression to another. By exploiting this observation, the number of parameters in an expression synthesis model can be significantly reduced. Therefore, we propose a constrained version of ridge regression that exploits the local and sparse structure of facial expressions. We consider this model as masked regression for learning local receptive fields. In contrast to the existing approaches, our proposed model can be efficiently trained on larger image sizes. Experiments using three publicly available datasets demonstrate that our model is significantly better than $\ell_0, \ell_1$ and $\ell_2$-regression, SVD based approaches, and kernelized regression in terms of mean-squared-error, visual quality as well as computational and spatial complexities. The reduction in the number of parameters allows our method to generalize better even after training on smaller datasets. The proposed algorithm is also compared with state-of-the-art GANs including Pix2Pix, CycleGAN, StarGAN and GANimation. These GANs produce photo-realistic results as long as the testing and the training distributions are similar. In contrast, our results demonstrate significant generalization of the proposed algorithm over out-of-dataset human photographs, pencil sketches and even animal faces.
* IJCV Journal