 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Knowledge-Aware Artifact Image Synthesis with LLM-Enhanced Prompting and Multi-Source Supervision
Dec 13, 2023
Ancient artifacts are an important medium for cultural preservation and restoration. However, many physical copies of artifacts are either damaged or lost, leaving a blank space in archaeological and historical studies that calls for artifact image generation techniques. Despite the significant advancements in open-domain text-to-image synthesis, existing approaches fail to capture the important domain knowledge presented in the textual description, resulting in errors in recreated images such as incorrect shapes and patterns. In this paper, we propose a novel knowledge-aware artifact image synthesis approach that brings lost historical objects accurately into their visual forms. We use a pretrained diffusion model as backbone and introduce three key techniques to enhance the text-to-image generation framework: 1) we construct prompts with explicit archaeological knowledge elicited from large language models (LLMs); 2) we incorporate additional textual guidance to correlated historical expertise in a contrastive manner; 3) we introduce further visual-semantic constraints on edge and perceptual features that enable our model to learn more intricate visual details of the artifacts. Compared to existing approaches, our proposed model produces higher-quality artifact images that align better with the implicit details and historical knowledge contained within written documents, thus achieving significant improvements across automatic metrics and in human evaluation. Our code and data are available at https://github.com/danielwusg/artifact_diffusion.
System Integration of Xilinx DPU and HDMI for Real-Time inference in PYNQ Environment with Image Enhancement
Dec 18, 2023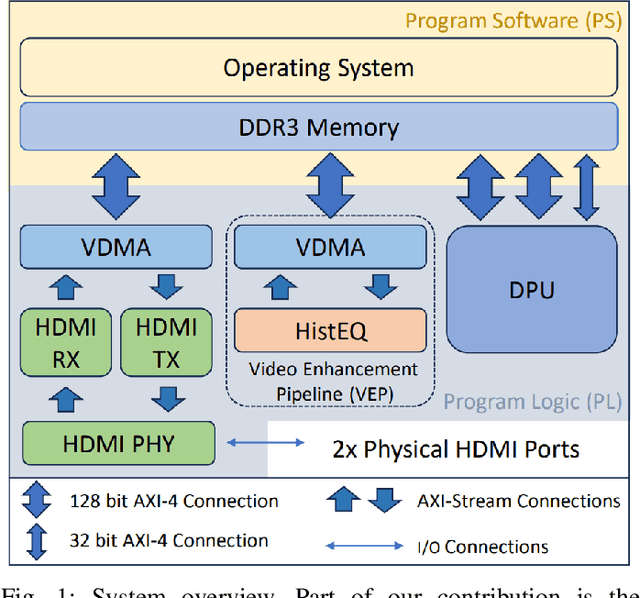


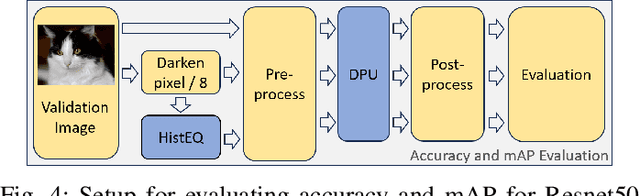
Use of edge computing in application of Computer Vision (CV) is an active field of research. Today, most CV applications make use of Convolutional Neural Networks (CNNs) to inference on and interpret video data. These edge devices are responsible for several CV related tasks, such as gathering, processing and enhancing, inferencing on, and displaying video data. Due to ease of reconfiguration, computation on FPGA fabric is used to achieve such complex computation tasks. Xilinx provides the PYNQ environment as a user-friendly interface that facilitates in Hardware/Software system integration. However, to the best of authors' knowledge there is no end-to-end framework available for the PYNQ environment that allows Hardware/Software system integration and deployment of CNNs for real-time input feed from High Definition Multimedia Interface (HDMI) input to HDMI output, along with insertion of customized hardware IPs. In this work we propose an integration of rea\textbf{L}-time image \textbf{E}nancement IP with \textbf{A}I inferencing engine in the \textbf{P}ynq environment (\textbf{LEAP}), that integrates HDMI, AI acceleration, image enhancement in the PYNQ environment for Xilinx's Microprocessor on Chip (MPSoC) platform. We evaluate our methodology with two well know CNN models, Resnet50 and YOLOv3. To validate our proposed methodology, LEAP, a simple image enhancement algorithm, histogram equalization, is designed and integrated in the FPGA fabric along with Xilinx's Deep Processing Unit (DPU). Our results show successful implementation of end-to-end integration using completely open source information.
SmartEdit: Exploring Complex Instruction-based Image Editing with Multimodal Large Language Models
Dec 11, 2023Current instruction-based editing methods, such as InstructPix2Pix, often fail to produce satisfactory results in complex scenarios due to their dependence on the simple CLIP text encoder in diffusion models. To rectify this, this paper introduces SmartEdit, a novel approach to instruction-based image editing that leverages Multimodal Large Language Models (MLLMs) to enhance their understanding and reasoning capabilities. However, direct integration of these elements still faces challenges in situations requiring complex reasoning. To mitigate this, we propose a Bidirectional Interaction Module that enables comprehensive bidirectional information interactions between the input image and the MLLM output. During training, we initially incorporate perception data to boost the perception and understanding capabilities of diffusion models. Subsequently, we demonstrate that a small amount of complex instruction editing data can effectively stimulate SmartEdit's editing capabilities for more complex instructions. We further construct a new evaluation dataset, Reason-Edit, specifically tailored for complex instruction-based image editing. Both quantitative and qualitative results on this evaluation dataset indicate that our SmartEdit surpasses previous methods, paving the way for the practical application of complex instruction-based image editing.
MedTransformer: Accurate AD Diagnosis for 3D MRI Images through 2D Vision Transformers
Jan 12, 2024Automated diagnosis of AD in brain images is becoming a clinically important technique to support precision and efficient diagnosis and treatment planning. A few efforts have been made to automatically diagnose AD in magnetic resonance imaging (MRI) using three-dimensional CNNs. However, due to the complexity of 3D models, the performance is still unsatisfactory, both in terms of accuracy and efficiency. To overcome the complexities of 3D images and 3D models, in this study, we aim to attack this problem with 2D vision Transformers. We propose a 2D transformer-based medical image model with various transformer attention encoders to diagnose AD in 3D MRI images, by cutting the 3D images into multiple 2D slices.The model consists of four main components: shared encoders across three dimensions, dimension-specific encoders, attention across images from the same dimension, and attention across three dimensions. It is used to obtain attention relationships among multiple sequences from different dimensions (axial, coronal, and sagittal) and multiple slices. We also propose morphology augmentation, an erosion and dilation based method to increase the structural difference between AD and normal images. In this experiment, we use multiple datasets from ADNI, AIBL, MIRAID, OASIS to show the performance of our model. Our proposed MedTransformer demonstrates a strong ability in diagnosing AD. These results demonstrate the effectiveness of MedTransformer in learning from 3D data using a much smaller model and its capability to generalize among different medical tasks, which provides a possibility to help doctors diagnose AD in a simpler way.
MVPatch: More Vivid Patch for Adversarial Camouflaged Attacks on Object Detectors in the Physical World
Jan 12, 2024Recent investigations demonstrate that adversarial patches can be utilized to manipulate the result of object detection models. However, the conspicuous patterns on these patches may draw more attention and raise suspicions among humans. Moreover, existing works have primarily focused on enhancing the efficacy of attacks in the physical domain, rather than seeking to optimize their stealth attributes and transferability potential. To address these issues, we introduce a dual-perception-based attack framework that generates an adversarial patch known as the More Vivid Patch (MVPatch). The framework consists of a model-perception degradation method and a human-perception improvement method. To derive the MVPatch, we formulate an iterative process that simultaneously constrains the efficacy of multiple object detectors and refines the visual correlation between the generated adversarial patch and a realistic image. Our method employs a model-perception-based approach that reduces the object confidence scores of several object detectors to boost the transferability of adversarial patches. Further, within the human-perception-based framework, we put forward a lightweight technique for visual similarity measurement that facilitates the development of inconspicuous and natural adversarial patches and eliminates the reliance on additional generative models. Additionally, we introduce the naturalness score and transferability score as metrics for an unbiased assessment of various adversarial patches' natural appearance and transferability capacity. Extensive experiments demonstrate that the proposed MVPatch algorithm achieves superior attack transferability compared to similar algorithms in both digital and physical domains while also exhibiting a more natural appearance. These findings emphasize the remarkable stealthiness and transferability of the proposed MVPatch attack algorithm.
CLIP-guided Source-free Object Detection in Aerial Images
Jan 10, 2024Domain adaptation is crucial in aerial imagery, as the visual representation of these images can significantly vary based on factors such as geographic location, time, and weather conditions. Additionally, high-resolution aerial images often require substantial storage space and may not be readily accessible to the public. To address these challenges, we propose a novel Source-Free Object Detection (SFOD) method. Specifically, our approach is built upon a self-training framework; however, self-training can lead to inaccurate learning in the absence of labeled training data. To address this issue, we further integrate Contrastive Language-Image Pre-training (CLIP) to guide the generation of pseudo-labels, termed CLIP-guided Aggregation. By leveraging CLIP's zero-shot classification capability, we use it to aggregate scores with the original predicted bounding boxes, enabling us to obtain refined scores for the pseudo-labels. To validate the effectiveness of our method, we constructed two new datasets from different domains based on the DIOR dataset, named DIOR-C and DIOR-Cloudy. Experiments demonstrate that our method outperforms other comparative algorithms.
Joint Sensing and Task-Oriented Communications with Image and Wireless Data Modalities for Dynamic Spectrum Access
Dec 21, 2023This paper introduces a deep learning approach to dynamic spectrum access, leveraging the synergy of multi-modal image and spectrum data for the identification of potential transmitters. We consider an edge device equipped with a camera that is taking images of potential objects such as vehicles that may harbor transmitters. Recognizing the computational constraints and trust issues associated with on-device computation, we propose a collaborative system wherein the edge device communicates selectively processed information to a trusted receiver acting as a fusion center, where a decision is made to identify whether a potential transmitter is present, or not. To achieve this, we employ task-oriented communications, utilizing an encoder at the transmitter for joint source coding, channel coding, and modulation. This architecture efficiently transmits essential information of reduced dimension for object classification. Simultaneously, the transmitted signals may reflect off objects and return to the transmitter, allowing for the collection of target sensing data. Then the collected sensing data undergoes a second round of encoding at the transmitter, with the reduced-dimensional information communicated back to the fusion center through task-oriented communications. On the receiver side, a decoder performs the task of identifying a transmitter by fusing data received through joint sensing and task-oriented communications. The two encoders at the transmitter and the decoder at the receiver are jointly trained, enabling a seamless integration of image classification and wireless signal detection. Using AWGN and Rayleigh channel models, we demonstrate the effectiveness of the proposed approach, showcasing high accuracy in transmitter identification across diverse channel conditions while sustaining low latency in decision making.
Symmetrical Bidirectional Knowledge Alignment for Zero-Shot Sketch-Based Image Retrieval
Dec 16, 2023This paper studies the problem of zero-shot sketch-based image retrieval (ZS-SBIR), which aims to use sketches from unseen categories as queries to match the images of the same category. Due to the large cross-modality discrepancy, ZS-SBIR is still a challenging task and mimics realistic zero-shot scenarios. The key is to leverage transferable knowledge from the pre-trained model to improve generalizability. Existing researchers often utilize the simple fine-tuning training strategy or knowledge distillation from a teacher model with fixed parameters, lacking efficient bidirectional knowledge alignment between student and teacher models simultaneously for better generalization. In this paper, we propose a novel Symmetrical Bidirectional Knowledge Alignment for zero-shot sketch-based image retrieval (SBKA). The symmetrical bidirectional knowledge alignment learning framework is designed to effectively learn mutual rich discriminative information between teacher and student models to achieve the goal of knowledge alignment. Instead of the former one-to-one cross-modality matching in the testing stage, a one-to-many cluster cross-modality matching method is proposed to leverage the inherent relationship of intra-class images to reduce the adverse effects of the existing modality gap. Experiments on several representative ZS-SBIR datasets (Sketchy Ext dataset, TU-Berlin Ext dataset and QuickDraw Ext dataset) prove the proposed algorithm can achieve superior performance compared with state-of-the-art methods.
Improving the Stability of Diffusion Models for Content Consistent Super-Resolution
Dec 30, 2023The generative priors of pre-trained latent diffusion models have demonstrated great potential to enhance the perceptual quality of image super-resolution (SR) results. Unfortunately, the existing diffusion prior-based SR methods encounter a common problem, i.e., they tend to generate rather different outputs for the same low-resolution image with different noise samples. Such stochasticity is desired for text-to-image generation tasks but problematic for SR tasks, where the image contents are expected to be well preserved. To improve the stability of diffusion prior-based SR, we propose to employ the diffusion models to refine image structures, while employing the generative adversarial training to enhance image fine details. Specifically, we propose a non-uniform timestep learning strategy to train a compact diffusion network, which has high efficiency and stability to reproduce the image main structures, and finetune the pre-trained decoder of variational auto-encoder (VAE) by adversarial training for detail enhancement. Extensive experiments show that our proposed method, namely content consistent super-resolution (CCSR), can significantly reduce the stochasticity of diffusion prior-based SR, improving the content consistency of SR outputs and speeding up the image generation process. Codes and models can be found at {https://github.com/csslc/CCSR}.
Denoising Vision Transformers
Jan 05, 2024We delve into a nuanced but significant challenge inherent to Vision Transformers (ViTs): feature maps of these models exhibit grid-like artifacts, which detrimentally hurt the performance of ViTs in downstream tasks. Our investigations trace this fundamental issue down to the positional embeddings at the input stage. To address this, we propose a novel noise model, which is universally applicable to all ViTs. Specifically, the noise model dissects ViT outputs into three components: a semantics term free from noise artifacts and two artifact-related terms that are conditioned on pixel locations. Such a decomposition is achieved by enforcing cross-view feature consistency with neural fields in a per-image basis. This per-image optimization process extracts artifact-free features from raw ViT outputs, providing clean features for offline applications. Expanding the scope of our solution to support online functionality, we introduce a learnable denoiser to predict artifact-free features directly from unprocessed ViT outputs, which shows remarkable generalization capabilities to novel data without the need for per-image optimization. Our two-stage approach, termed Denoising Vision Transformers (DVT), does not require re-training existing pre-trained ViTs and is immediately applicable to any Transformer-based architecture. We evaluate our method on a variety of representative ViTs (DINO, MAE, DeiT-III, EVA02, CLIP, DINOv2, DINOv2-reg). Extensive evaluations demonstrate that our DVT consistently and significantly improves existing state-of-the-art general-purpose models in semantic and geometric tasks across multiple datasets (e.g., +3.84 mIoU). We hope our study will encourage a re-evaluation of ViT design, especially regarding the naive use of positional embeddings.