 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks
Nov 28, 2017

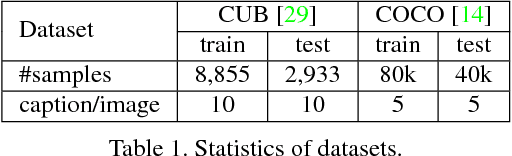
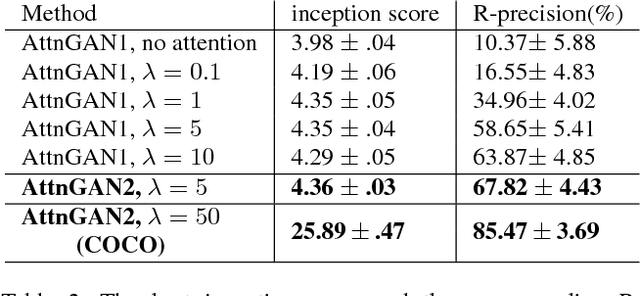
In this paper, we propose an Attentional Generative Adversarial Network (AttnGAN) that allows attention-driven, multi-stage refinement for fine-grained text-to-image generation. With a novel attentional generative network, the AttnGAN can synthesize fine-grained details at different subregions of the image by paying attentions to the relevant words in the natural language description. In addition, a deep attentional multimodal similarity model is proposed to compute a fine-grained image-text matching loss for training the generator. The proposed AttnGAN significantly outperforms the previous state of the art, boosting the best reported inception score by 14.14% on the CUB dataset and 170.25% on the more challenging COCO dataset. A detailed analysis is also performed by visualizing the attention layers of the AttnGAN. It for the first time shows that the layered attentional GAN is able to automatically select the condition at the word level for generating different parts of the image.
Accelerate Your CNN from Three Dimensions: A Comprehensive Pruning Framework
Oct 10, 2020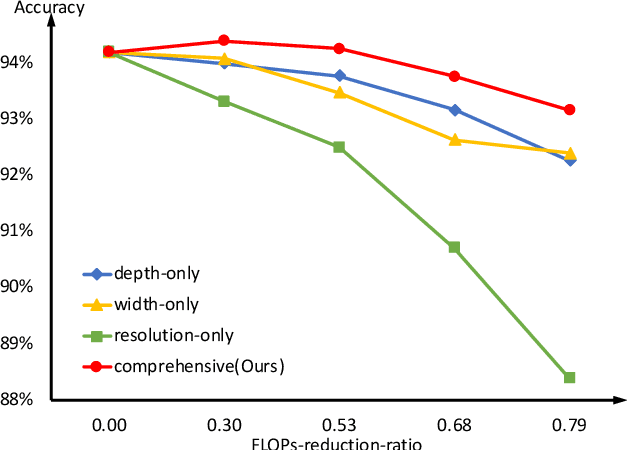
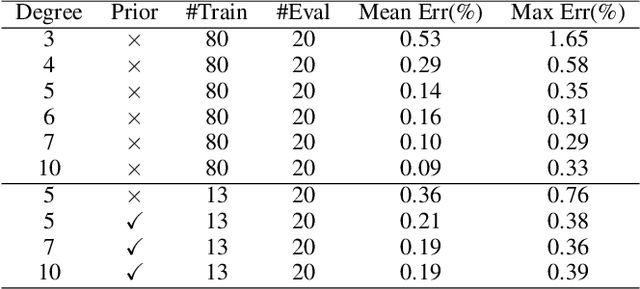
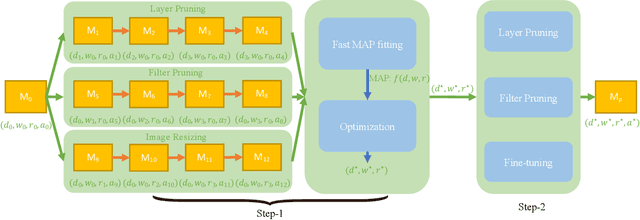
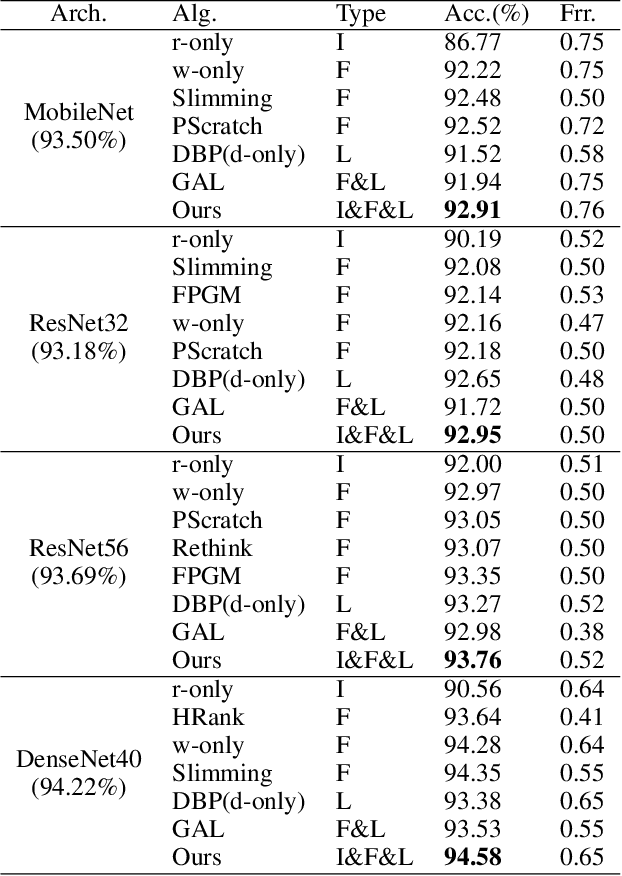
To deploy a pre-trained deep CNN on resource-constrained mobile devices, neural network pruning is often used to cut down the model's computational cost. For example, filter-level pruning (reducing the model's width) or layer-level pruning (reducing the model's depth) can both save computations with some sacrifice of accuracy. Besides, reducing the resolution of input images can also reach the same goal. Most previous methods focus on reducing one or two of these dimensions (i.e., depth, width, and image resolution) for acceleration. However, excessive reduction of any single dimension will lead to unacceptable accuracy loss, and we have to prune these three dimensions comprehensively to yield the best result. In this paper, a simple yet effective pruning framework is proposed to comprehensively consider these three dimensions. Our framework falls into two steps: 1) Determining the optimal depth (d*), width (w*), and image resolution (r) for the model. 2) Pruning the model in terms of (d*, w*, r*). Specifically, at the first step, we formulate model acceleration as an optimization problem. It takes depth (d), width (w) and image resolution (r) as variables and the model's accuracy as the optimization objective. Although it is hard to determine the expression of the objective function, approximating it with polynomials is still feasible, during which several properties of the objective function are utilized to ease and speedup the fitting process. Then the optimal d*, w* and r* are attained by maximizing the objective function with Lagrange multiplier theorem and KKT conditions. Extensive experiments are done on several popular architectures and datasets. The results show that we have outperformd the state-of-the-art pruning methods. The code will be published soon.
A Universal Model for Cross Modality Mapping by Relational Reasoning
Feb 26, 2021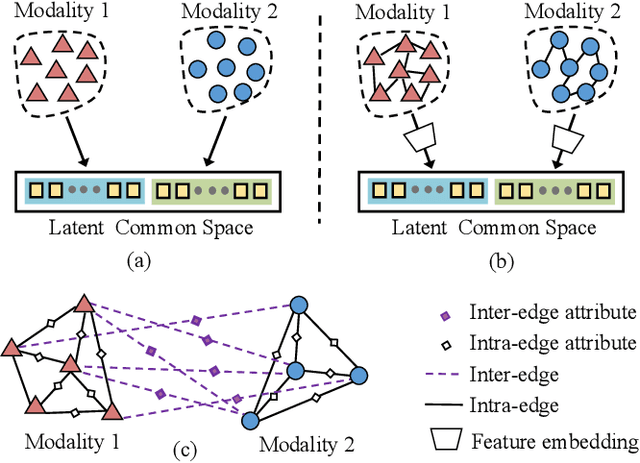
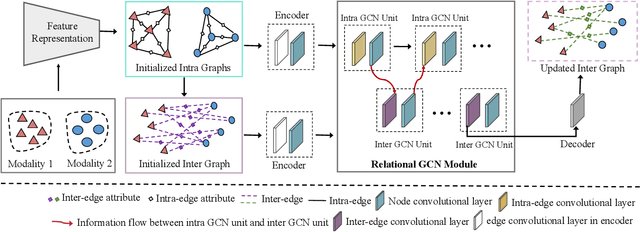
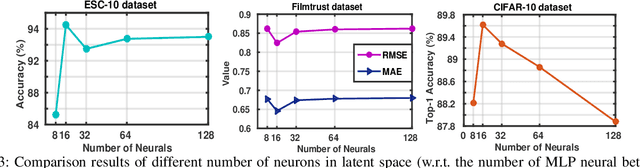
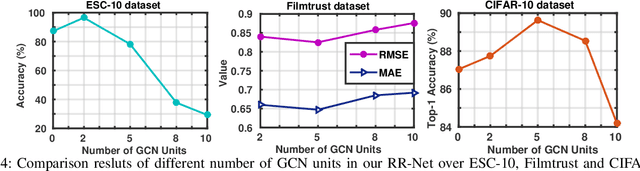
With the aim of matching a pair of instances from two different modalities, cross modality mapping has attracted growing attention in the computer vision community. Existing methods usually formulate the mapping function as the similarity measure between the pair of instance features, which are embedded to a common space. However, we observe that the relationships among the instances within a single modality (intra relations) and those between the pair of heterogeneous instances (inter relations) are insufficiently explored in previous approaches. Motivated by this, we redefine the mapping function with relational reasoning via graph modeling, and further propose a GCN-based Relational Reasoning Network (RR-Net) in which inter and intra relations are efficiently computed to universally resolve the cross modality mapping problem. Concretely, we first construct two kinds of graph, i.e., Intra Graph and Inter Graph, to respectively model intra relations and inter relations. Then RR-Net updates all the node features and edge features in an iterative manner for learning intra and inter relations simultaneously. Last, RR-Net outputs the probabilities over the edges which link a pair of heterogeneous instances to estimate the mapping results. Extensive experiments on three example tasks, i.e., image classification, social recommendation and sound recognition, clearly demonstrate the superiority and universality of our proposed model.
Recovery RL: Safe Reinforcement Learning with Learned Recovery Zones
Oct 29, 2020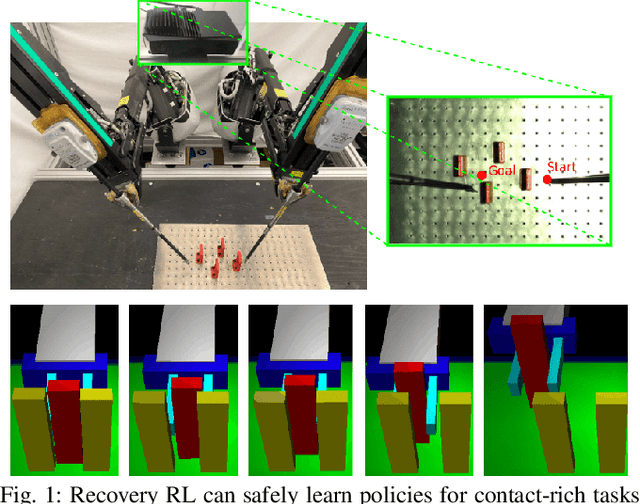
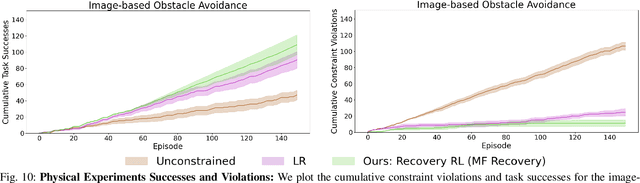
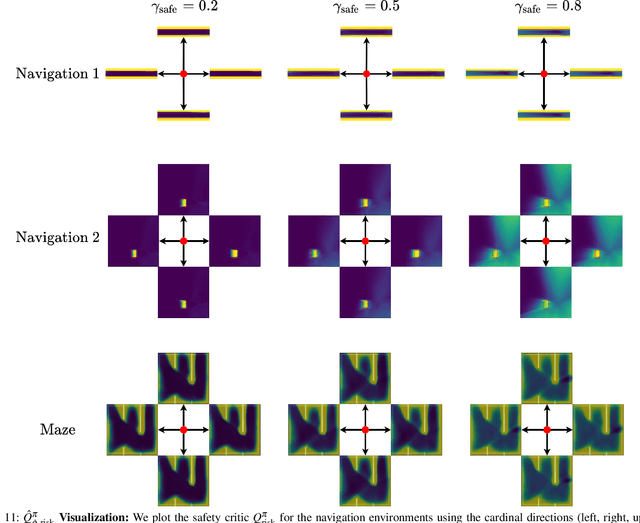
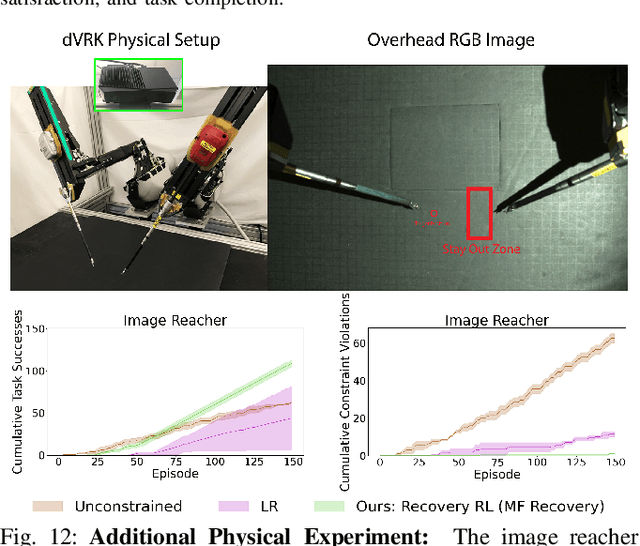
Safety remains a central obstacle preventing widespread use of RL in the real world: learning new tasks in uncertain environments requires extensive exploration, but safety requires limiting exploration. We propose Recovery RL, an algorithm which navigates this tradeoff by (1) leveraging offline data to learn about constraint violating zones before policy learning and (2) separating the goals of improving task performance and constraint satisfaction across two policies: a task policy that only optimizes the task reward and a recovery policy that guides the agent to safety when constraint violation is likely. We evaluate Recovery RL on 6 simulation domains, including two contact-rich manipulation tasks and an image-based navigation task, and an image-based obstacle avoidance task on a physical robot. We compare Recovery RL to 5 prior safe RL methods which jointly optimize for task performance and safety via constrained optimization or reward shaping and find that Recovery RL outperforms the next best prior method across all domains. Results suggest that Recovery RL trades off constraint violations and task successes 2 - 80 times more efficiently in simulation domains and 3 times more efficiently in physical experiments. See https://tinyurl.com/rl-recovery for videos and supplementary material.
Robust and efficient post-processing for video object detection
Sep 23, 2020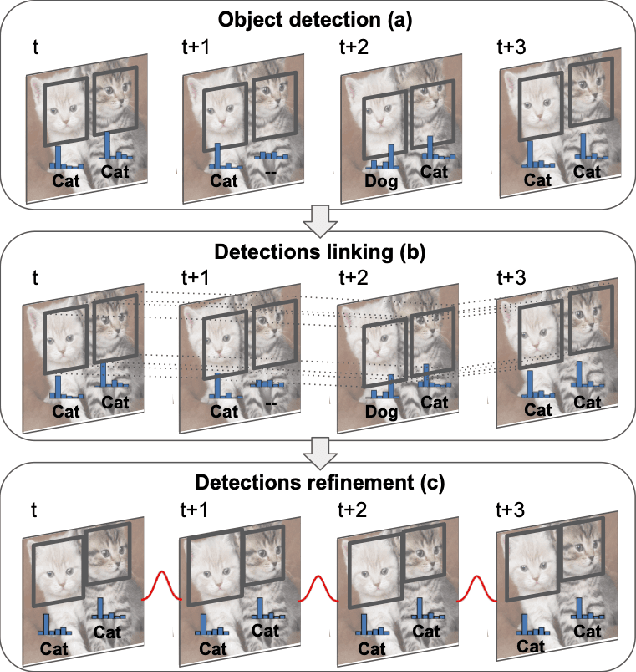
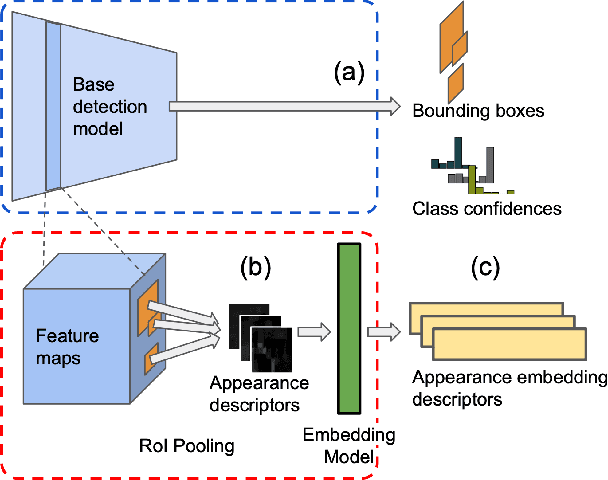
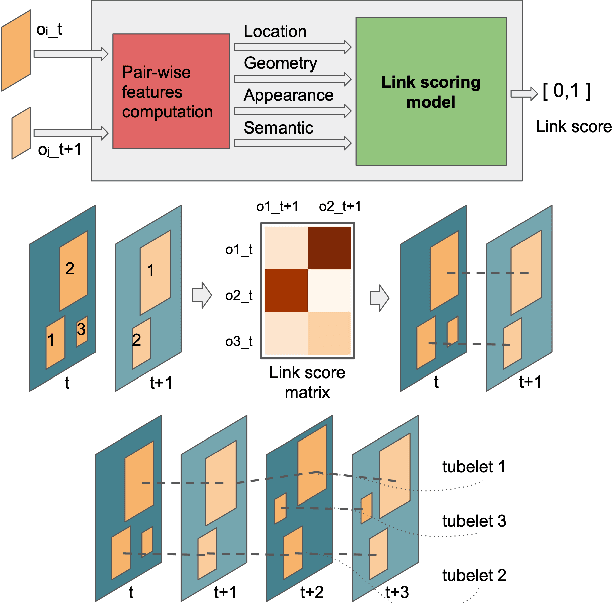

Object recognition in video is an important task for plenty of applications, including autonomous driving perception, surveillance tasks, wearable devices or IoT networks. Object recognition using video data is more challenging than using still images due to blur, occlusions or rare object poses. Specific video detectors with high computational cost or standard image detectors together with a fast post-processing algorithm achieve the current state-of-the-art. This work introduces a novel post-processing pipeline that overcomes some of the limitations of previous post-processing methods by introducing a learning-based similarity evaluation between detections across frames. Our method improves the results of state-of-the-art specific video detectors, specially regarding fast moving objects, and presents low resource requirements. And applied to efficient still image detectors, such as YOLO, provides comparable results to much more computationally intensive detectors.
Solving Inverse Problems With Deep Neural Networks -- Robustness Included?
Nov 09, 2020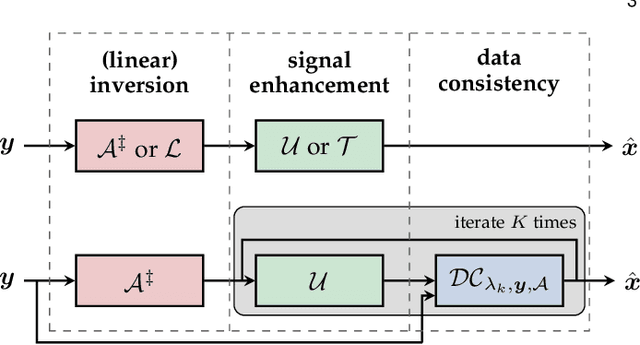
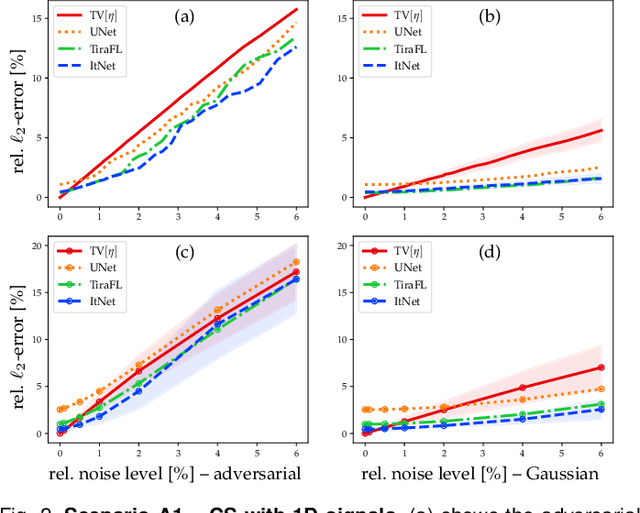
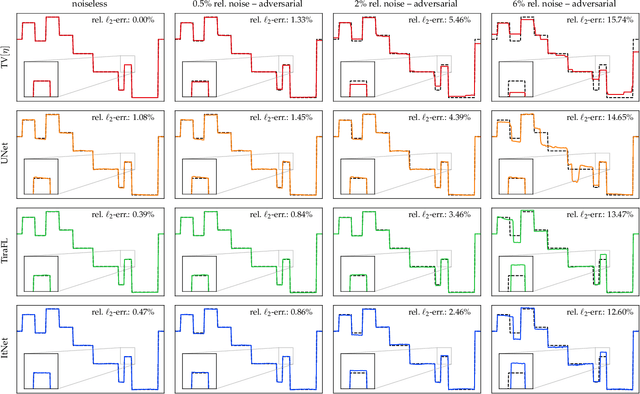
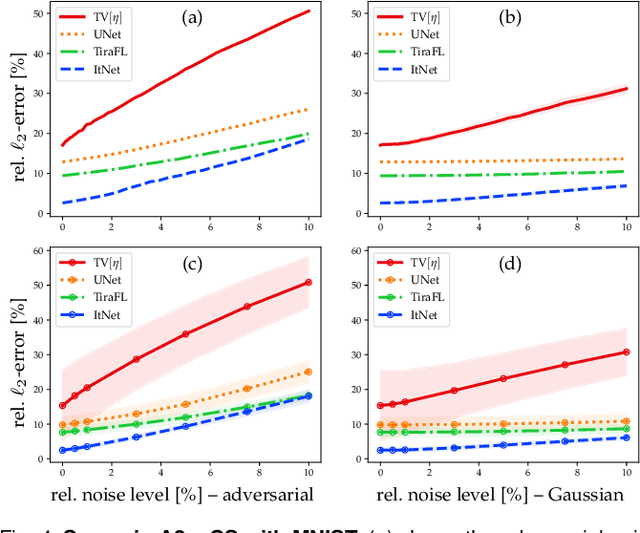
In the past five years, deep learning methods have become state-of-the-art in solving various inverse problems. Before such approaches can find application in safety-critical fields, a verification of their reliability appears mandatory. Recent works have pointed out instabilities of deep neural networks for several image reconstruction tasks. In analogy to adversarial attacks in classification, it was shown that slight distortions in the input domain may cause severe artifacts. The present article sheds new light on this concern, by conducting an extensive study of the robustness of deep-learning-based algorithms for solving underdetermined inverse problems. This covers compressed sensing with Gaussian measurements as well as image recovery from Fourier and Radon measurements, including a real-world scenario for magnetic resonance imaging (using the NYU-fastMRI dataset). Our main focus is on computing adversarial perturbations of the measurements that maximize the reconstruction error. A distinctive feature of our approach is the quantitative and qualitative comparison with total-variation minimization, which serves as a provably robust reference method. In contrast to previous findings, our results reveal that standard end-to-end network architectures are not only resilient against statistical noise, but also against adversarial perturbations. All considered networks are trained by common deep learning techniques, without sophisticated defense strategies.
EEC: Learning to Encode and Regenerate Images for Continual Learning
Jan 14, 2021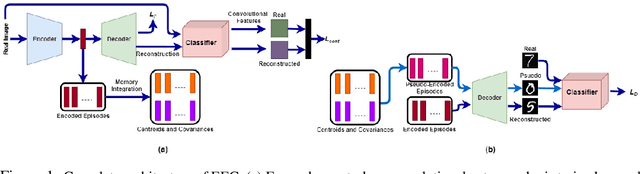
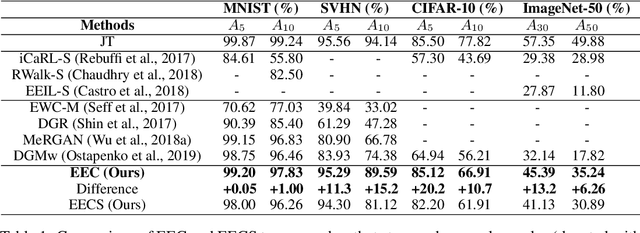

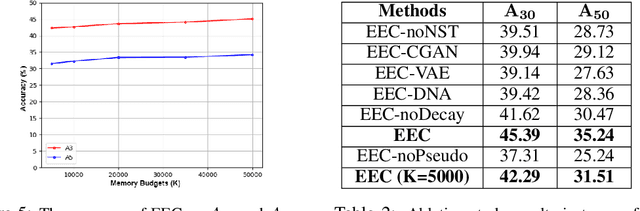
The two main impediments to continual learning are catastrophic forgetting and memory limitations on the storage of data. To cope with these challenges, we propose a novel, cognitively-inspired approach which trains autoencoders with Neural Style Transfer to encode and store images. During training on a new task, reconstructed images from encoded episodes are replayed in order to avoid catastrophic forgetting. The loss function for the reconstructed images is weighted to reduce its effect during classifier training to cope with image degradation. When the system runs out of memory the encoded episodes are converted into centroids and covariance matrices, which are used to generate pseudo-images during classifier training, keeping classifier performance stable while using less memory. Our approach increases classification accuracy by 13-17% over state-of-the-art methods on benchmark datasets, while requiring 78% less storage space.
Synthetic Generation of Three-Dimensional Cancer Cell Models from Histopathological Images
Jan 26, 2021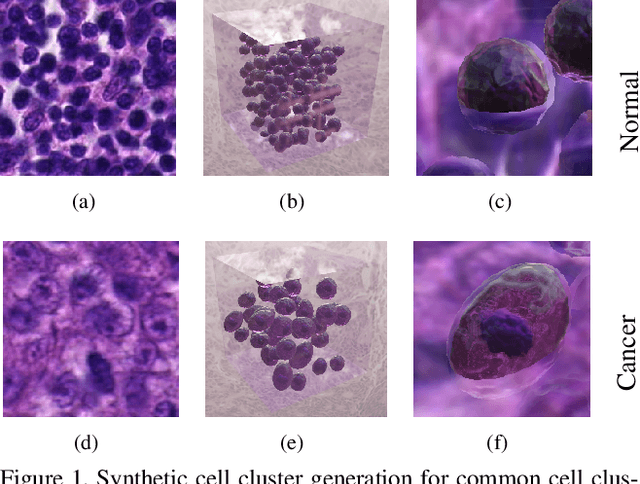
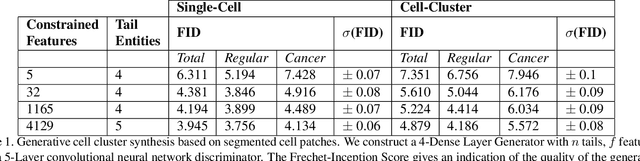
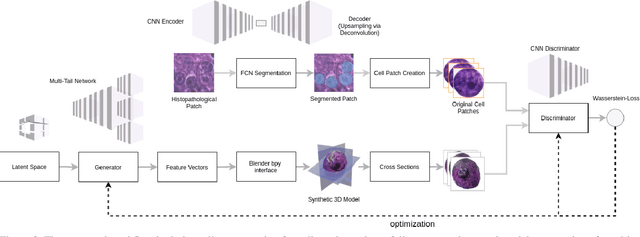
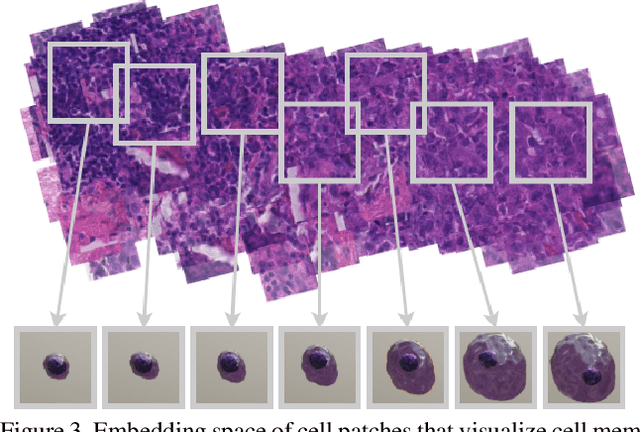
Synthetic generation of three-dimensional cell models from histopathological images enables an enhanced understanding of cell mutation, spatial context, and progression of cancer, necessary for clinical assessment and optimal treatment. Classical reconstruction algorithms based on image registration of consecutive slides of stained tissues are prone to errors and often not suitable for the training of three-dimensional segmentation algorithms. We propose a novel framework to generate synthetic three-dimensional histological models based on a generator-discriminator pattern optimizing constrained features that construct a 3D model via a blender interface exploiting smooth shape continuity typical for biological specimens. Simultaneously a discriminator is trained to distinguish between the original cell patches and projections of the three-dimensional model. To capture the spatial context of entire cell clusters we deploy a similar architecture expanded by style transfer capability. Models based on clusters of adjoined embedding points are generated to analyze the characteristic cell mutation process of breast cancer.
SipMask: Spatial Information Preservation for Fast Image and Video Instance Segmentation
Jul 29, 2020
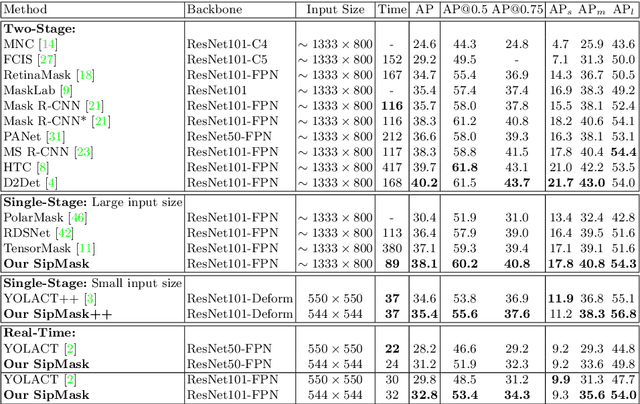
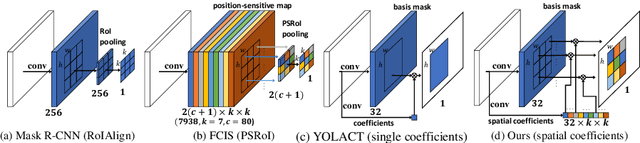
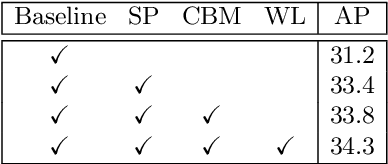
Single-stage instance segmentation approaches have recently gained popularity due to their speed and simplicity, but are still lagging behind in accuracy, compared to two-stage methods. We propose a fast single-stage instance segmentation method, called SipMask, that preserves instance-specific spatial information by separating mask prediction of an instance to different sub-regions of a detected bounding-box. Our main contribution is a novel light-weight spatial preservation (SP) module that generates a separate set of spatial coefficients for each sub-region within a bounding-box, leading to improved mask predictions. It also enables accurate delineation of spatially adjacent instances. Further, we introduce a mask alignment weighting loss and a feature alignment scheme to better correlate mask prediction with object detection. On COCO test-dev, our SipMask outperforms the existing single-stage methods. Compared to the state-of-the-art single-stage TensorMask, SipMask obtains an absolute gain of 1.0% (mask AP), while providing a four-fold speedup. In terms of real-time capabilities, SipMask outperforms YOLACT with an absolute gain of 3.0% (mask AP) under similar settings, while operating at comparable speed on a Titan Xp. We also evaluate our SipMask for real-time video instance segmentation, achieving promising results on YouTube-VIS dataset. The source code is available at https://github.com/JialeCao001/SipMask.
Towards Universal Physical Attacks On Cascaded Camera-Lidar 3D Object Detection Models
Jan 26, 2021
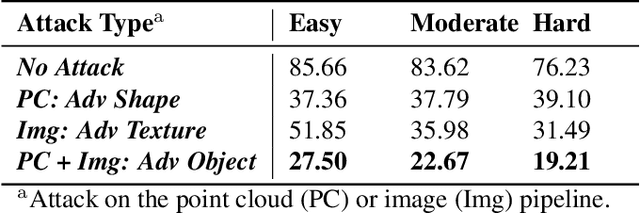
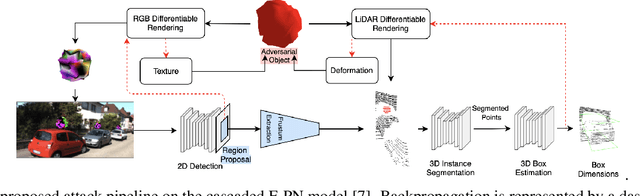
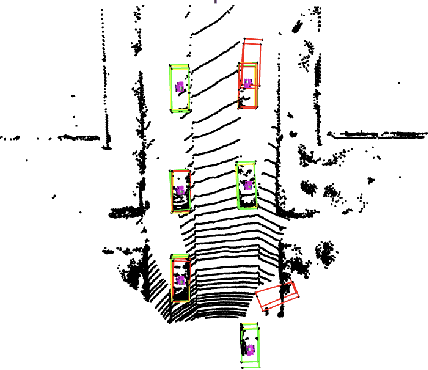
We propose a universal and physically realizable adversarial attack on a cascaded multi-modal deep learning network (DNN), in the context of self-driving cars. DNNs have achieved high performance in 3D object detection, but they are known to be vulnerable to adversarial attacks. These attacks have been heavily investigated in the RGB image domain and more recently in the point cloud domain, but rarely in both domains simultaneously - a gap to be filled in this paper. We use a single 3D mesh and differentiable rendering to explore how perturbing the mesh's geometry and texture can reduce the robustness of DNNs to adversarial attacks. We attack a prominent cascaded multi-modal DNN, the Frustum-Pointnet model. Using the popular KITTI benchmark, we showed that the proposed universal multi-modal attack was successful in reducing the model's ability to detect a car by nearly 73%. This work can aid in the understanding of what the cascaded RGB-point cloud DNN learns and its vulnerability to adversarial attacks.