 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Object Detection Made Simpler by Eliminating Heuristic NMS
Feb 25, 2021
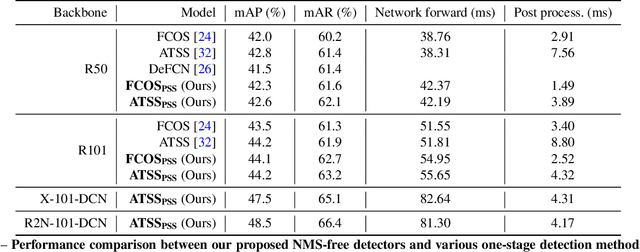
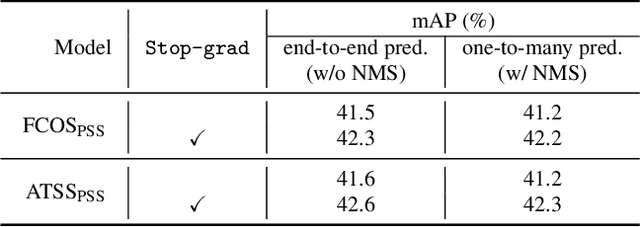
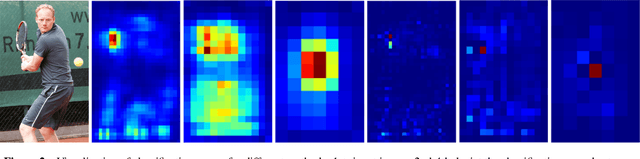
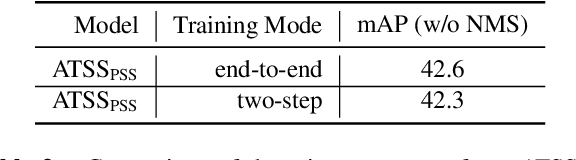
We show a simple NMS-free, end-to-end object detection framework, of which the network is a minimal modification to a one-stage object detector such as the FCOS detection model [Tian et al. 2019]. We attain on par or even improved detection accuracy compared with the original one-stage detector. It performs detection at almost the same inference speed, while being even simpler in that now the post-processing NMS (non-maximum suppression) is eliminated during inference. If the network is capable of identifying only one positive sample for prediction for each ground-truth object instance in an image, then NMS would become unnecessary. This is made possible by attaching a compact PSS head for automatic selection of the single positive sample for each instance (see Fig. 1). As the learning objective involves both one-to-many and one-to-one label assignments, there is a conflict in the labels of some training examples, making the learning challenging. We show that by employing a stop-gradient operation, we can successfully tackle this issue and train the detector. On the COCO dataset, our simple design achieves superior performance compared to both the FCOS baseline detector with NMS post-processing and the recent end-to-end NMS-free detectors. Our extensive ablation studies justify the rationale of the design choices.
CoADNet: Collaborative Aggregation-and-Distribution Networks for Co-Salient Object Detection
Nov 10, 2020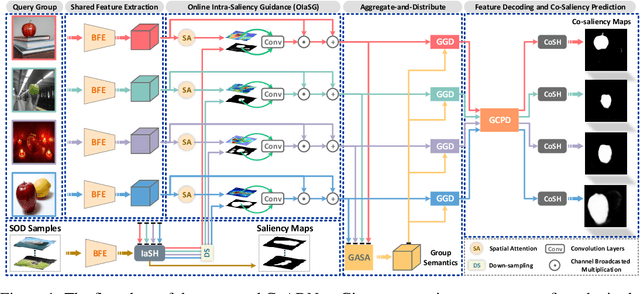
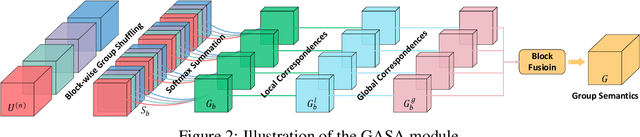
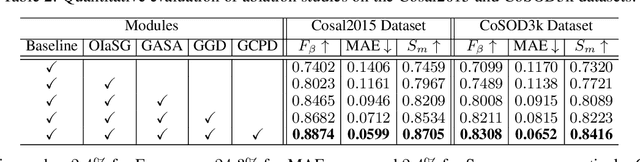

Co-Salient Object Detection (CoSOD) aims at discovering salient objects that repeatedly appear in a given query group containing two or more relevant images. One challenging issue is how to effectively capture co-saliency cues by modeling and exploiting inter-image relationships. In this paper, we present an end-to-end collaborative aggregation-and-distribution network (CoADNet) to capture both salient and repetitive visual patterns from multiple images. First, we integrate saliency priors into the backbone features to suppress the redundant background information through an online intra-saliency guidance structure. After that, we design a two-stage aggregate-and-distribute architecture to explore group-wise semantic interactions and produce the co-saliency features. In the first stage, we propose a group-attentional semantic aggregation module that models inter-image relationships to generate the group-wise semantic representations. In the second stage, we propose a gated group distribution module that adaptively distributes the learned group semantics to different individuals in a dynamic gating mechanism. Finally, we develop a group consistency preserving decoder tailored for the CoSOD task, which maintains group constraints during feature decoding to predict more consistent full-resolution co-saliency maps. The proposed CoADNet is evaluated on four prevailing CoSOD benchmark datasets, which demonstrates the remarkable performance improvement over ten state-of-the-art competitors.
A first step towards automated species recognition from camera trap images of mammals using AI in a European temperate forest
Mar 19, 2021
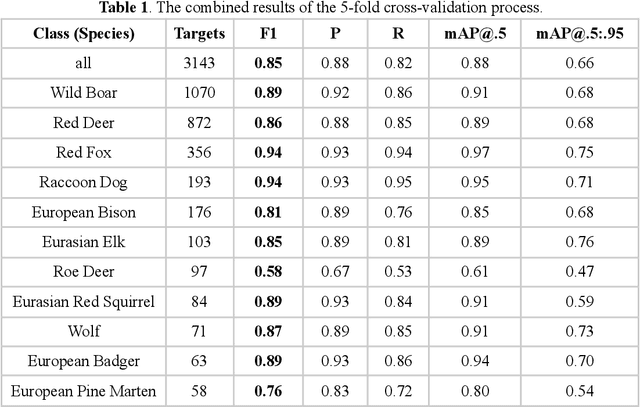
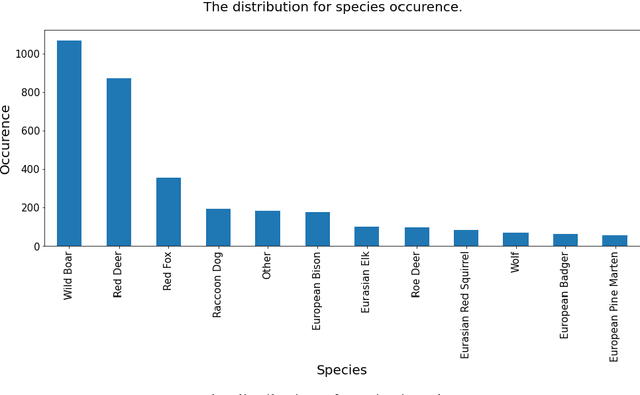

Camera traps are used worldwide to monitor wildlife. Despite the increasing availability of Deep Learning (DL) models, the effective usage of this technology to support wildlife monitoring is limited. This is mainly due to the complexity of DL technology and high computing requirements. This paper presents the implementation of the light-weight and state-of-the-art YOLOv5 architecture for automated labeling of camera trap images of mammals in the Bialowieza Forest (BF), Poland. The camera trapping data were organized and harmonized using TRAPPER software, an open source application for managing large-scale wildlife monitoring projects. The proposed image recognition pipeline achieved an average accuracy of 85% F1-score in the identification of the 12 most commonly occurring medium-size and large mammal species in BF using a limited set of training and testing data (a total 2659 images with animals). Based on the preliminary results, we concluded that the YOLOv5 object detection and classification model is a promising light-weight DL solution after the adoption of transfer learning technique. It can be efficiently plugged in via an API into existing web-based camera trapping data processing platforms such as e.g. TRAPPER system. Since TRAPPER is already used to manage and classify (manually) camera trapping datasets by many research groups in Europe, the implementation of AI-based automated species classification may significantly speed up the data processing workflow and thus better support data-driven wildlife monitoring and conservation. Moreover, YOLOv5 developers perform better performance on edge devices which may open a new chapter in animal population monitoring in real time directly from camera trap devices.
Fast and Robust Symmetric Image Registration Based on Intensity and Spatial Information
Jul 30, 2018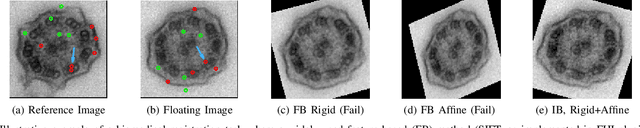
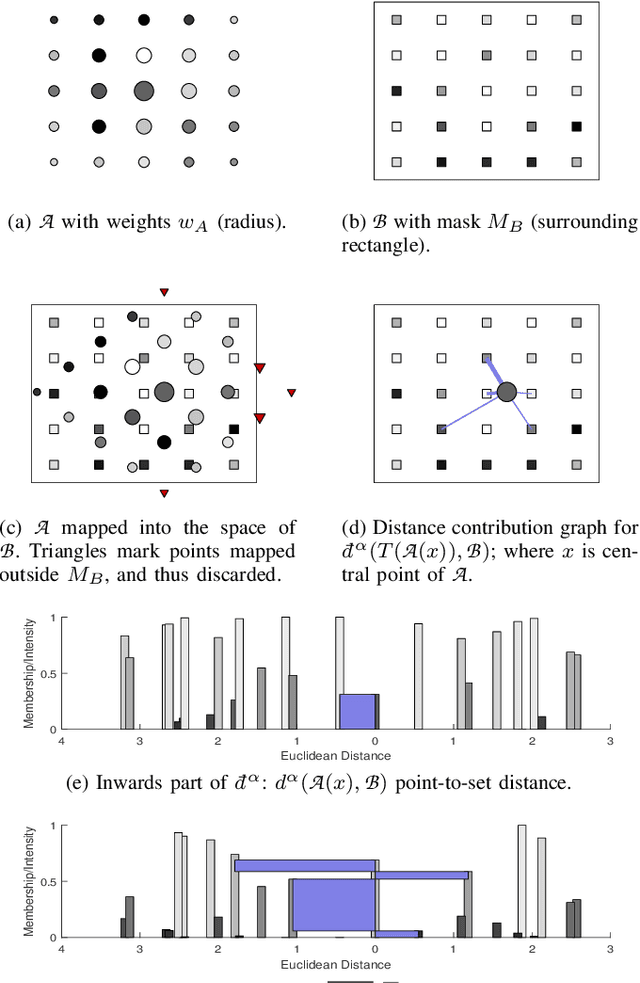
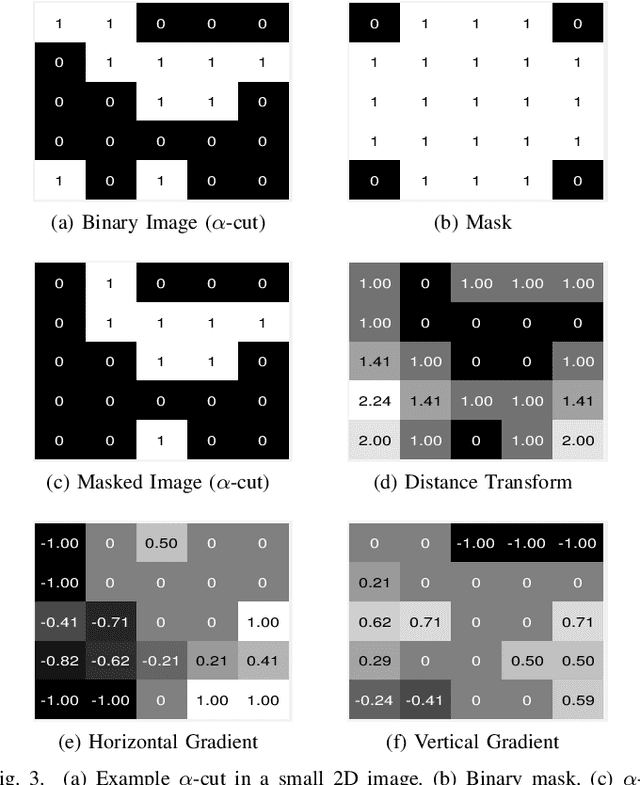
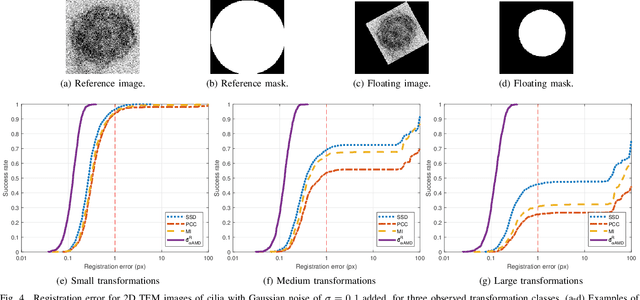
Intensity-based image registration approaches rely on similarity measures to guide the search for geometric correspondences with high affinity between images. The properties of the used measure are vital for the robustness and accuracy of the registration. In this study a symmetric, intensity interpolation-free, affine registration framework based on a combination of intensity and spatial information is proposed. The excellent performance of the framework is demonstrated on a combination of synthetic tests, recovering known transformations in the presence of noise, and real applications in biomedical and medical image registration, for both 2D and 3D images. The method exhibits greater robustness and higher accuracy than similarity measures in common use, when inserted into a standard gradient-based registration framework available as part of the open source Insight Segmentation and Registration Toolkit (ITK). The method is also empirically shown to have a low computational cost, making it practical for real applications. Source code is available.
CrossStack: A 3-D Reconfigurable RRAM Crossbar Inference Engine
Feb 07, 2021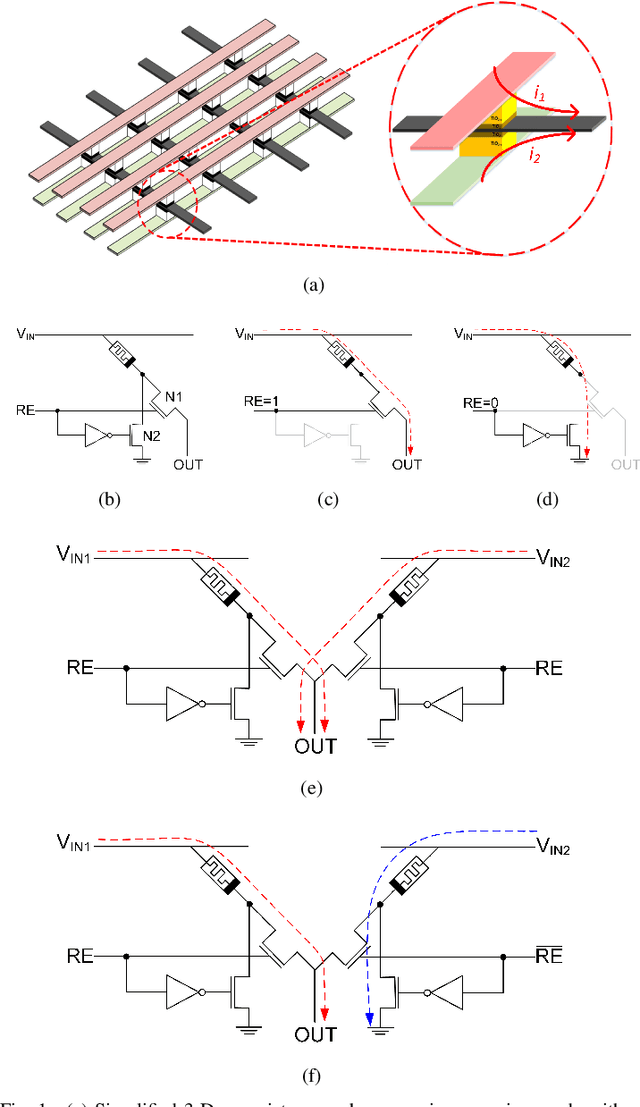

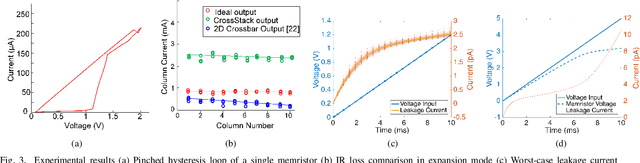
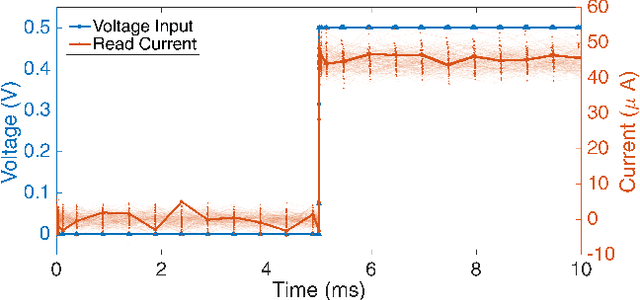
Deep neural network inference accelerators are rapidly growing in importance as we turn to massively parallelized processing beyond GPUs and ASICs. The dominant operation in feedforward inference is the multiply-and-accumlate process, where each column in a crossbar generates the current response of a single neuron. As a result, memristor crossbar arrays parallelize inference and image processing tasks very efficiently. In this brief, we present a 3-D active memristor crossbar array `CrossStack', which adopts stacked pairs of Al/TiO2/TiO2-x/Al devices with common middle electrodes. By designing CMOS-memristor hybrid cells used in the layout of the array, CrossStack can operate in one of two user-configurable modes as a reconfigurable inference engine: 1) expansion mode and 2) deep-net mode. In expansion mode, the resolution of the network is doubled by increasing the number of inputs for a given chip area, reducing IR drop by 22%. In deep-net mode, inference speed per-10-bit convolution is improved by 29\% by simultaneously using one TiO2/TiO2-x layer for read processes, and the other for write processes. We experimentally verify both modes on our $10\times10\times2$ array.
Multimodal Pivots for Image Caption Translation
Jun 13, 2016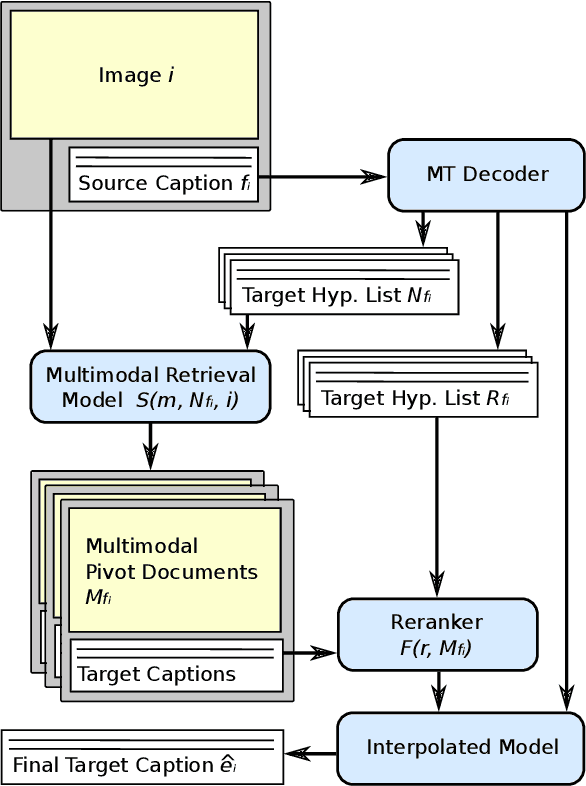
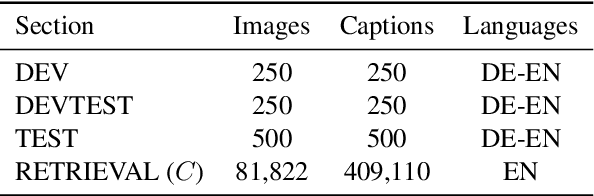
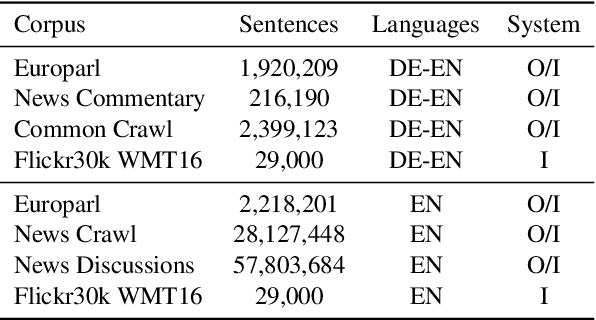
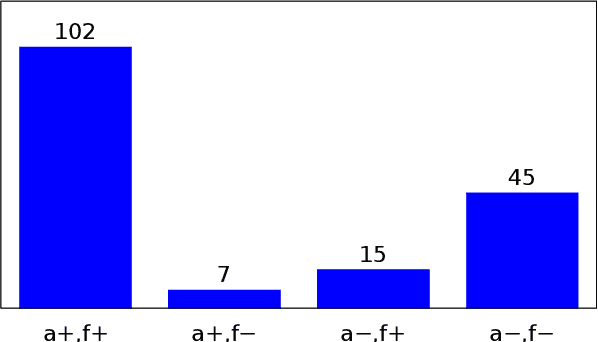
We present an approach to improve statistical machine translation of image descriptions by multimodal pivots defined in visual space. The key idea is to perform image retrieval over a database of images that are captioned in the target language, and use the captions of the most similar images for crosslingual reranking of translation outputs. Our approach does not depend on the availability of large amounts of in-domain parallel data, but only relies on available large datasets of monolingually captioned images, and on state-of-the-art convolutional neural networks to compute image similarities. Our experimental evaluation shows improvements of 1 BLEU point over strong baselines.
Autonomous Robotic Suction to Clear the Surgical Field for Hemostasis using Image-based Blood Flow Detection
Oct 16, 2020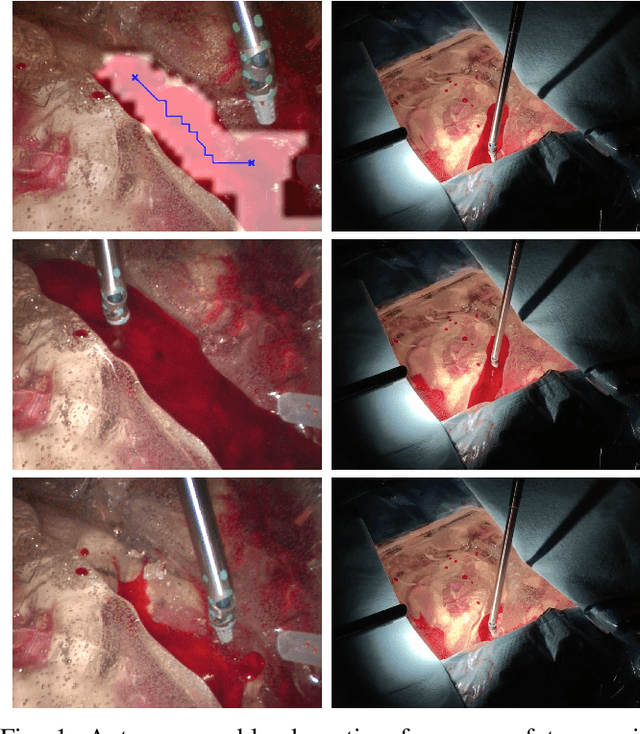
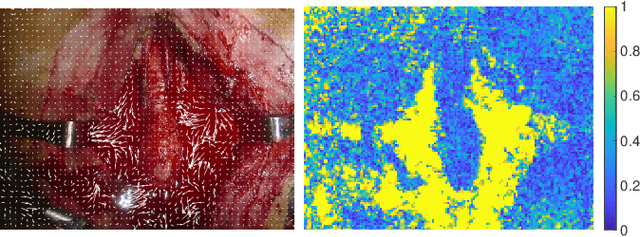
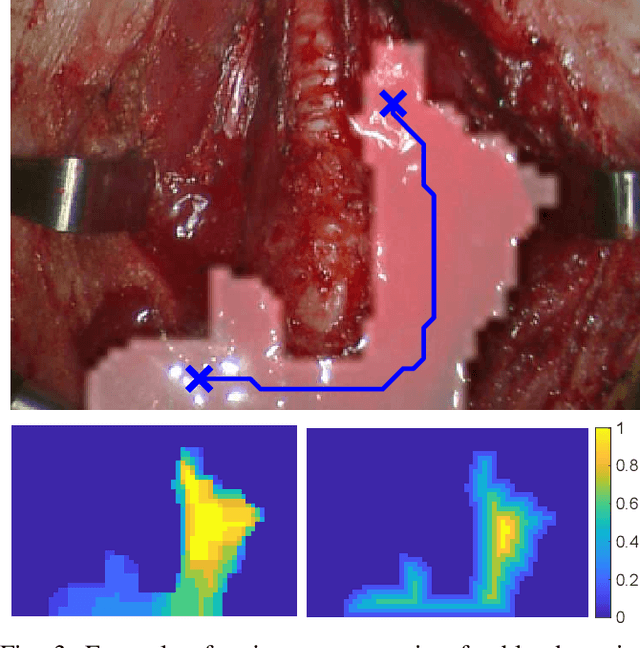

Autonomous robotic surgery has seen significant progression over the last decade with the aims of reducing surgeon fatigue, improving procedural consistency, and perhaps one day take over surgery itself. However, automation has not been applied to the critical surgical task of controlling tissue and blood vessel bleeding--known as hemostasis. The task of hemostasis covers a spectrum of bleeding sources and a range of blood velocity, trajectory, and volume. In an extreme case, an un-controlled blood vessel fills the surgical field with flowing blood. In this work, we present the first, automated solution for hemostasis through development of a novel probabilistic blood flow detection algorithm and a trajectory generation technique that guides autonomous suction tools towards pooling blood. The blood flow detection algorithm is tested in both simulated scenes and in a real-life trauma scenario involving a hemorrhage that occurred during thyroidectomy. The complete solution is tested in a physical lab setting with the da Vinci Research Kit (dVRK) and a simulated surgical cavity for blood to flow through. The results show that our automated solution has accurate detection, a fast reaction time, and effective removal of the flowing blood. Therefore, the proposed methods are powerful tools to clearing the surgical field which can be followed by either a surgeon or future robotic automation developments to close the vessel rupture.
Measuring and Predicting Tag Importance for Image Retrieval
Jan 09, 2017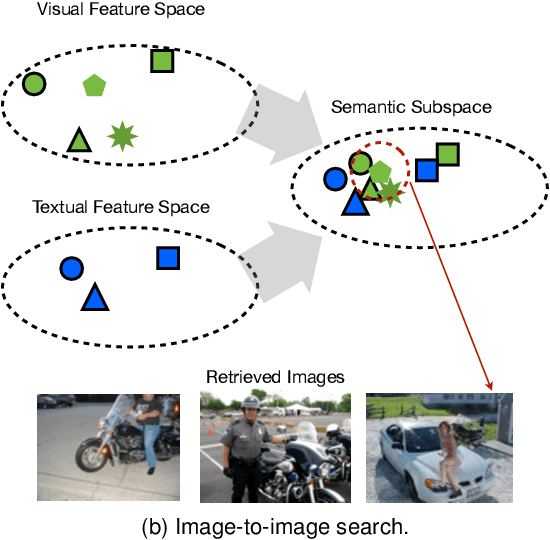
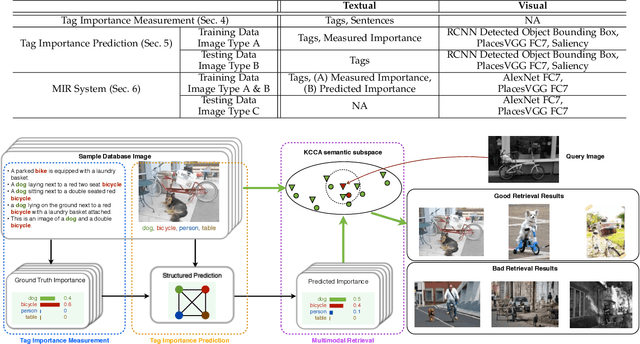

Textual data such as tags, sentence descriptions are combined with visual cues to reduce the semantic gap for image retrieval applications in today's Multimodal Image Retrieval (MIR) systems. However, all tags are treated as equally important in these systems, which may result in misalignment between visual and textual modalities during MIR training. This will further lead to degenerated retrieval performance at query time. To address this issue, we investigate the problem of tag importance prediction, where the goal is to automatically predict the tag importance and use it in image retrieval. To achieve this, we first propose a method to measure the relative importance of object and scene tags from image sentence descriptions. Using this as the ground truth, we present a tag importance prediction model to jointly exploit visual, semantic and context cues. The Structural Support Vector Machine (SSVM) formulation is adopted to ensure efficient training of the prediction model. Then, the Canonical Correlation Analysis (CCA) is employed to learn the relation between the image visual feature and tag importance to obtain robust retrieval performance. Experimental results on three real-world datasets show a significant performance improvement of the proposed MIR with Tag Importance Prediction (MIR/TIP) system over other MIR systems.
Sewer-ML: A Multi-Label Sewer Defect Classification Dataset and Benchmark
Mar 19, 2021
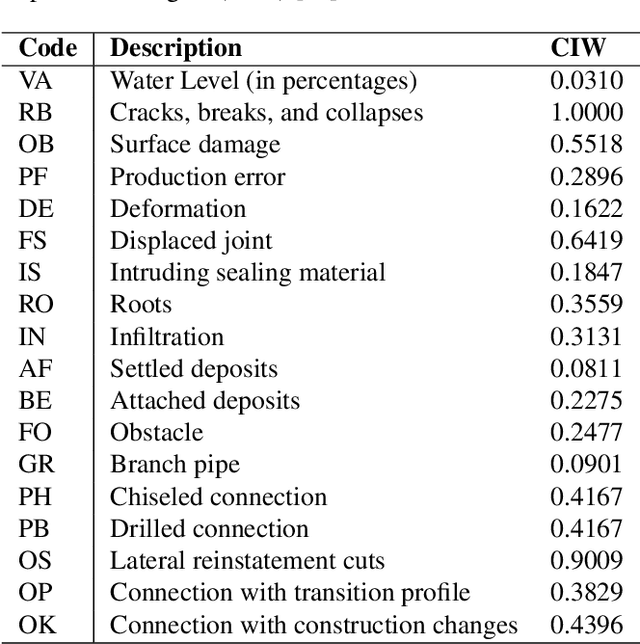
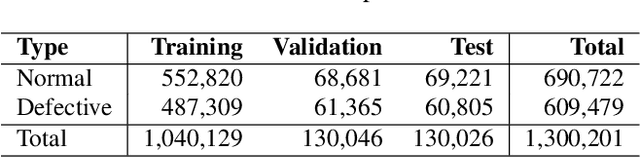
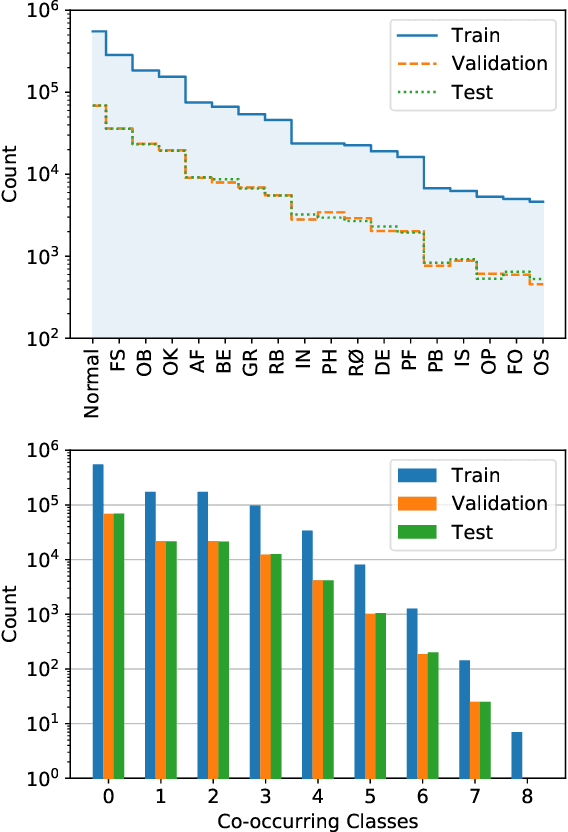
Perhaps surprisingly sewerage infrastructure is one of the most costly infrastructures in modern society. Sewer pipes are manually inspected to determine whether the pipes are defective. However, this process is limited by the number of qualified inspectors and the time it takes to inspect a pipe. Automatization of this process is therefore of high interest. So far, the success of computer vision approaches for sewer defect classification has been limited when compared to the success in other fields mainly due to the lack of public datasets. To this end, in this work we present a large novel and publicly available multi-label classification dataset for image-based sewer defect classification called Sewer-ML. The Sewer-ML dataset consists of 1.3 million images annotated by professional sewer inspectors from three different utility companies across nine years. Together with the dataset, we also present a benchmark algorithm and a novel metric for assessing performance. The benchmark algorithm is a result of evaluating 12 state-of-the-art algorithms, six from the sewer defect classification domain and six from the multi-label classification domain, and combining the best performing algorithms. The novel metric is a class-importance weighted F2 score, $\text{F}2_{\text{CIW}}$, reflecting the economic impact of each class, used together with the normal pipe F1 score, $\text{F}1_{\text{Normal}}$. The benchmark algorithm achieves an $\text{F}2_{\text{CIW}}$ score of 55.11% and $\text{F}1_{\text{Normal}}$ score of 90.94%, leaving ample room for improvement on the Sewer-ML dataset. The code, models, and dataset are available at the project page https://vap.aau.dk/sewer-ml/
Fine-Grained Off-Road Semantic Segmentation and Mapping via Contrastive Learning
Mar 05, 2021
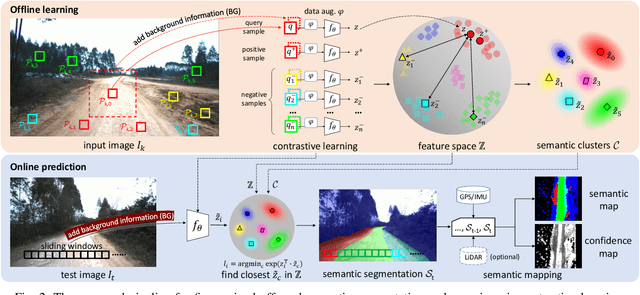

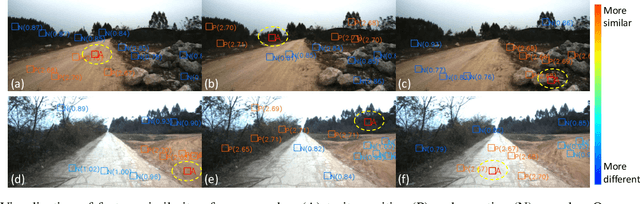
Road detection or traversability analysis has been a key technique for a mobile robot to traverse complex off-road scenes. The problem has been mainly formulated in early works as a binary classification one, e.g. associating pixels with road or non-road labels. Whereas understanding scenes with fine-grained labels are needed for off-road robots, as scenes are very diverse, and the various mechanical performance of off-road robots may lead to different definitions of safe regions to traverse. How to define and annotate fine-grained labels to achieve meaningful scene understanding for a robot to traverse off-road is still an open question. This research proposes a contrastive learning based method. With a set of human-annotated anchor patches, a feature representation is learned to discriminate regions with different traversability, a method of fine-grained semantic segmentation and mapping is subsequently developed for off-road scene understanding. Experiments are conducted on a dataset of three driving segments that represent very diverse off-road scenes. An anchor accuracy of 89.8% is achieved by evaluating the matching with human-annotated image patches in cross-scene validation. Examined by associated 3D LiDAR data, the fine-grained segments of visual images are demonstrated to have different levels of toughness and terrain elevation, which represents their semantical meaningfulness. The resultant maps contain both fine-grained labels and confidence values, providing rich information to support a robot traversing complex off-road scenes.