 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FrugalMCT: Efficient Online ML API Selection for Multi-Label Classification Tasks
Feb 18, 2021
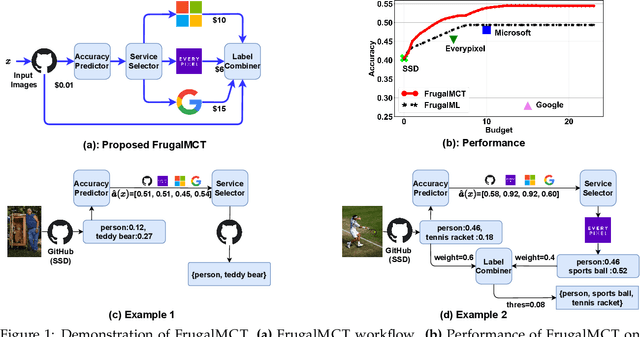
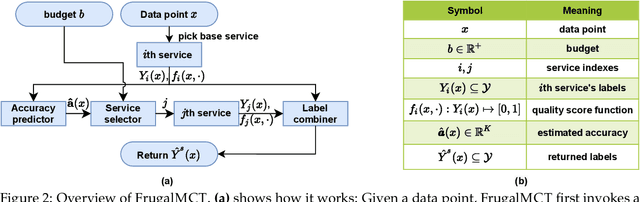
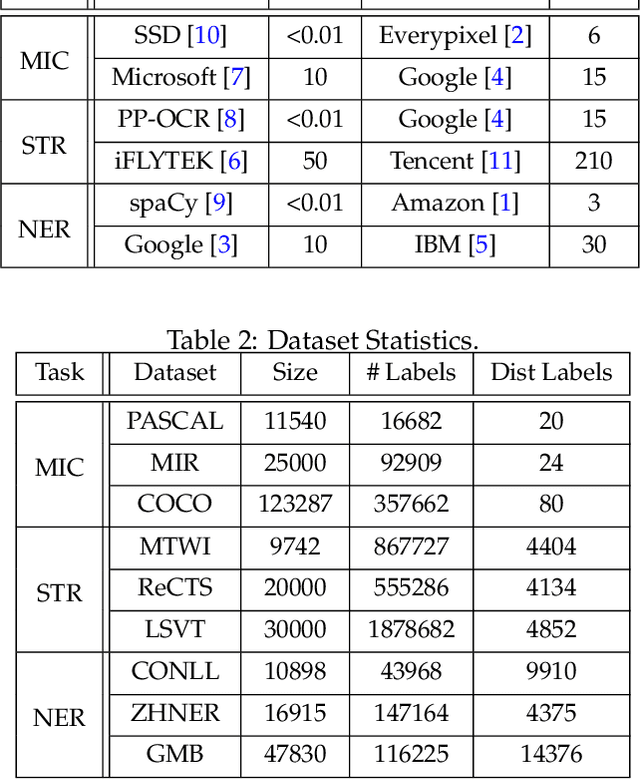
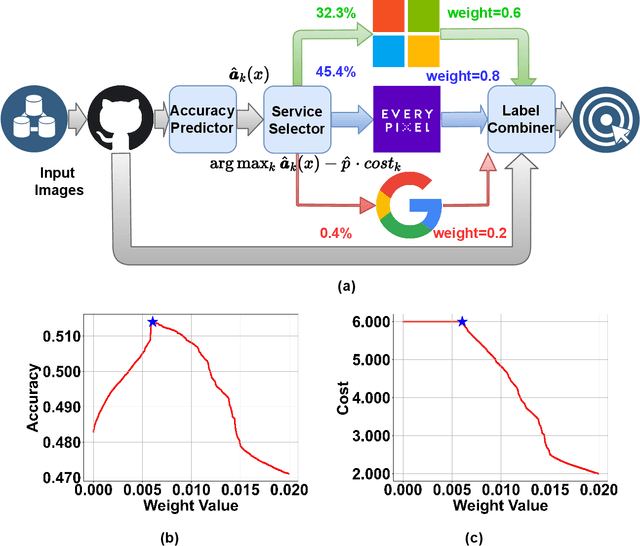
Multi-label classification tasks such as OCR and multi-object recognition are a major focus of the growing machine learning as a service industry. While many multi-label prediction APIs are available, it is challenging for users to decide which API to use for their own data and budget, due to the heterogeneity in those APIs' price and performance. Recent work shows how to select from single-label prediction APIs. However the computation complexity of the previous approach is exponential in the number of labels and hence is not suitable for settings like OCR. In this work, we propose FrugalMCT, a principled framework that adaptively selects the APIs to use for different data in an online fashion while respecting user's budget. The API selection problem is cast as an integer linear program, which we show has a special structure that we leverage to develop an efficient online API selector with strong performance guarantees. We conduct systematic experiments using ML APIs from Google, Microsoft, Amazon, IBM, Tencent and other providers for tasks including multi-label image classification, scene text recognition and named entity recognition. Across diverse tasks, FrugalMCT can achieve over 90% cost reduction while matching the accuracy of the best single API, or up to 8% better accuracy while matching the best API's cost.
Deep correction of breathing-related artifacts in MR-thermometry
Nov 10, 2020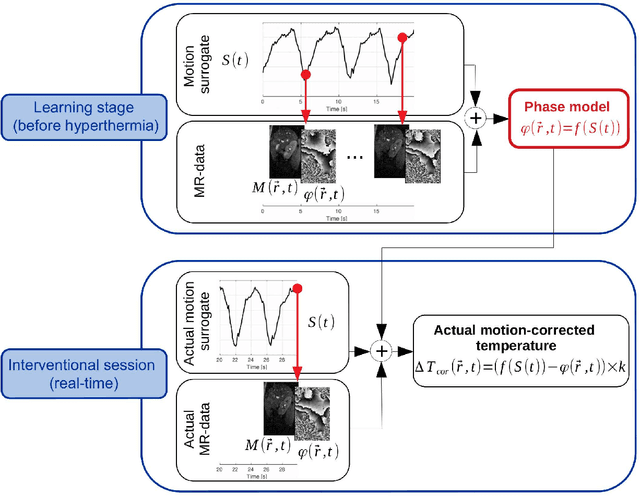
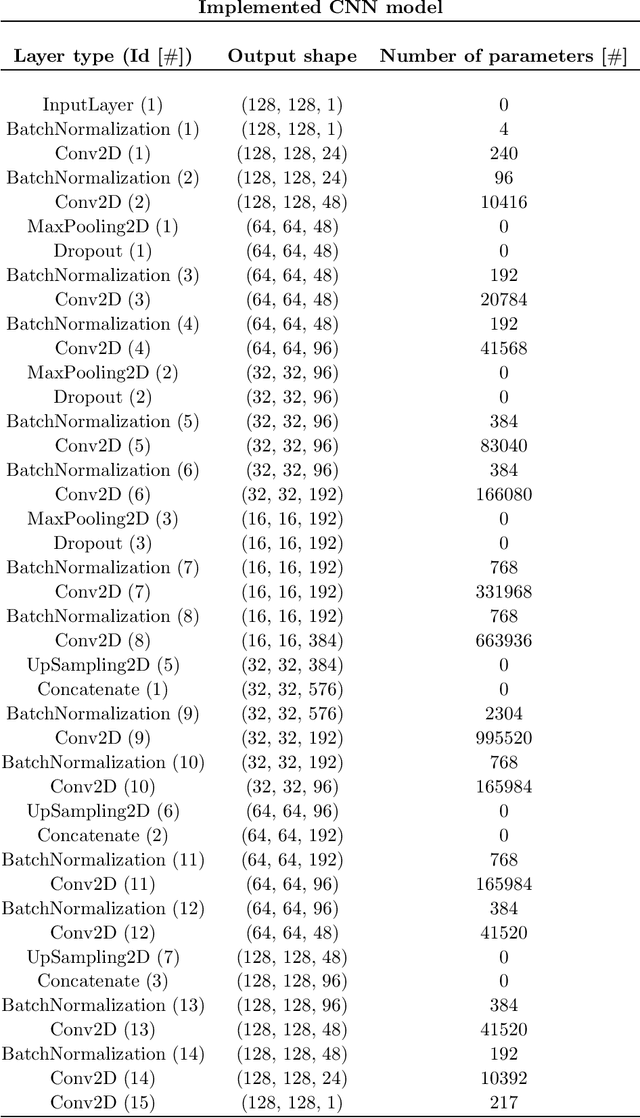
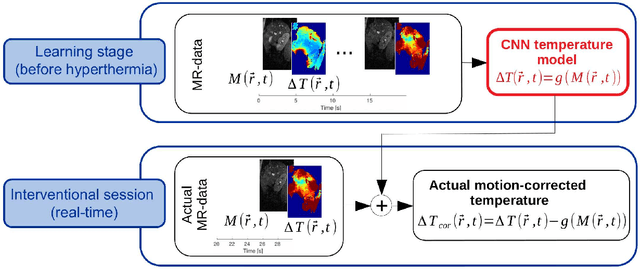
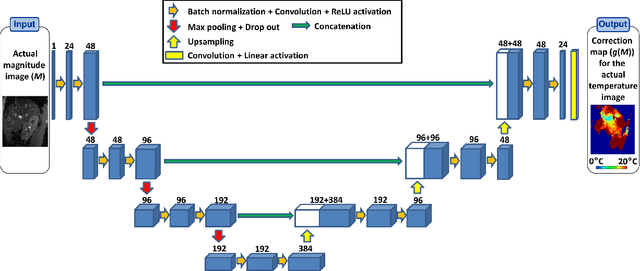
Real-time MR-imaging has been clinically adapted for monitoring thermal therapies since it can provide on-the-fly temperature maps simultaneously with anatomical information. However, proton resonance frequency based thermometry of moving targets remains challenging since temperature artifacts are induced by the respiratory as well as physiological motion. If left uncorrected, these artifacts lead to severe errors in temperature estimates and impair therapy guidance. In this study, we evaluated deep learning for on-line correction of motion related errors in abdominal MR-thermometry. For this, a convolutional neural network (CNN) was designed to learn the apparent temperature perturbation from images acquired during a preparative learning stage prior to hyperthermia. The input of the designed CNN is the most recent magnitude image and no surrogate of motion is needed. During the subsequent hyperthermia procedure, the recent magnitude image is used as an input for the CNN-model in order to generate an on-line correction for the current temperature map. The method's artifact suppression performance was evaluated on 12 free breathing volunteers and was found robust and artifact-free in all examined cases. Furthermore, thermometric precision and accuracy was assessed for in vivo ablation using high intensity focused ultrasound. All calculations involved at the different stages of the proposed workflow were designed to be compatible with the clinical time constraints of a therapeutic procedure.
Adversarial Defense of Image Classification Using a Variational Auto-Encoder
Dec 07, 2018
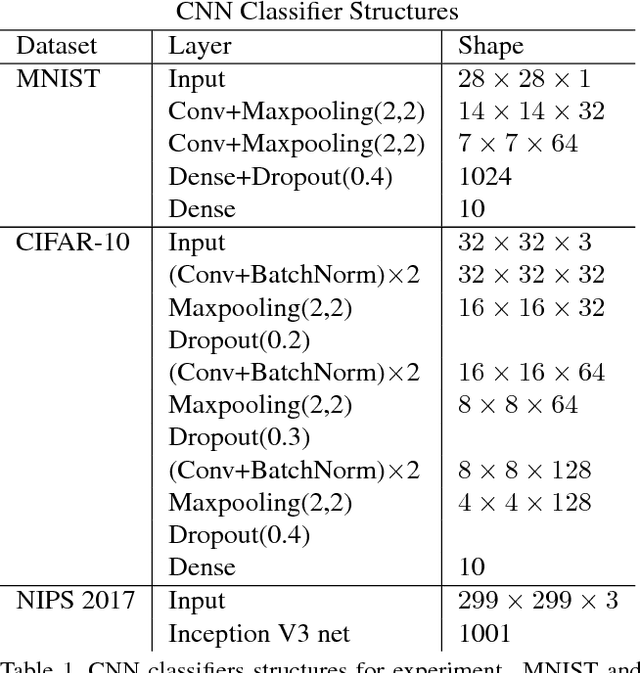
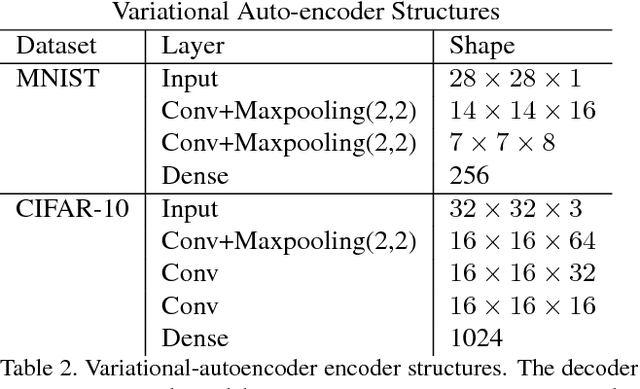
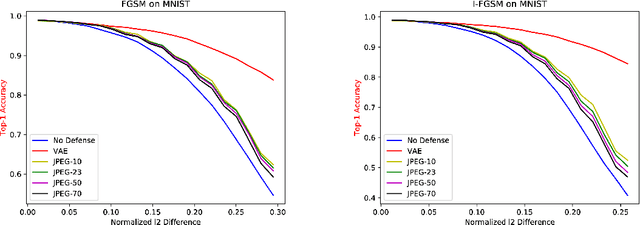
Deep neural networks are known to be vulnerable to adversarial attacks. This exposes them to potential exploits in security-sensitive applications and highlights their lack of robustness. This paper uses a variational auto-encoder (VAE) to defend against adversarial attacks for image classification tasks. This VAE defense has a few nice properties: (1) it is quite flexible and its use of randomness makes it harder to attack; (2) it can learn disentangled representations that prevent blurry reconstruction; and (3) a patch-wise VAE defense strategy is used that does not require retraining for different size images. For moderate to severe attacks, this system outperforms or closely matches the performance of JPEG compression, with the best quality parameter. It also has more flexibility and potential for improvement via training.
Infrared and Visible Image Fusion with ResNet and zero-phase component analysis
Jul 31, 2018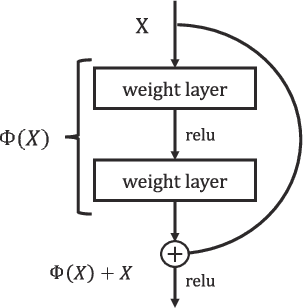
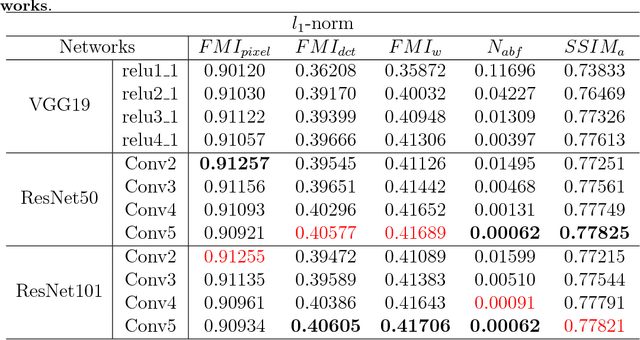
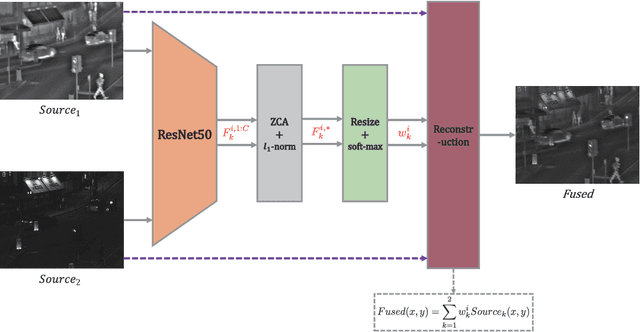
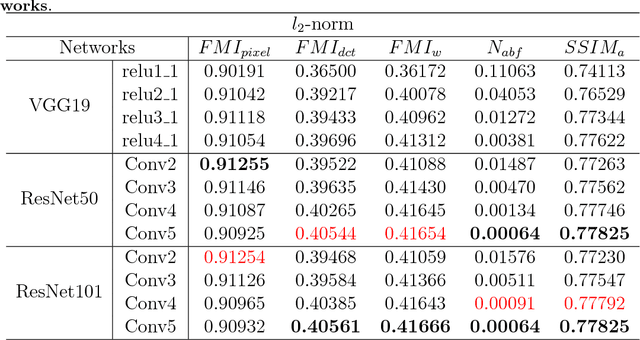
Feature extraction and processing are key tasks in the Image fusion algorithm, while most of deep learning-based methods use deep features directly without feature processing. This leads to the fusion performance degradation in some cases. To solve this drawback, in this paper, a novel fusion framework based on deep features and zero-phase component analysis (ZCA) is proposed. Firstly, the residual network (ResNet) is used to extract deep features from source images. Then ZCA and l_1-norm are utilized to normalize the deep features and obtain initial weight maps. The final weight maps are obtained by employing a soft-max operation in association with the initial weight maps. Finally, the fused image is reconstructed using a weighted-averaging strategy. Compared with the existing fusion methods, experimental results demonstrate that the proposed algorithm achieves better performance in both objective assessment and visual quality. The code of our fusion algorithm is available at https://github.com/exceptionLi/imagefusion_resnet50
Deploying machine learning to assist digital humanitarians: making image annotation in OpenStreetMap more efficient
Sep 17, 2020

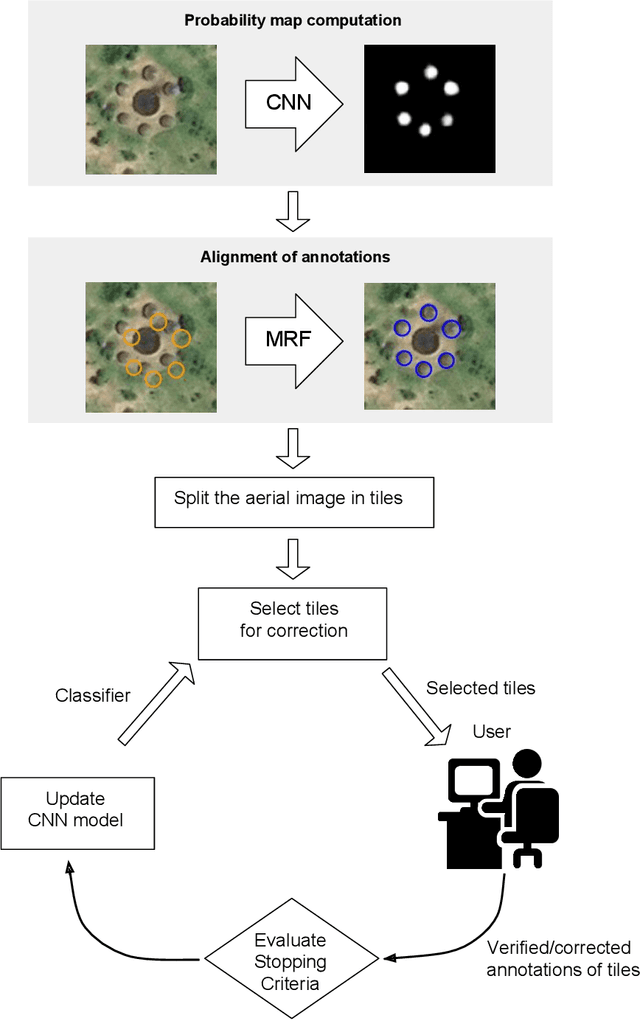
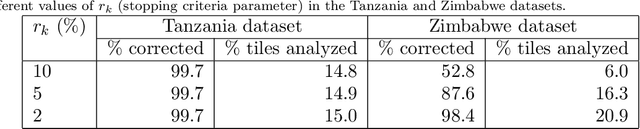
Locating populations in rural areas of developing countries has attracted the attention of humanitarian mapping projects since it is important to plan actions that affect vulnerable areas. Recent efforts have tackled this problem as the detection of buildings in aerial images. However, the quality and the amount of rural building annotated data in open mapping services like OpenStreetMap (OSM) is not sufficient for training accurate models for such detection. Although these methods have the potential of aiding in the update of rural building information, they are not accurate enough to automatically update the rural building maps. In this paper, we explore a human-computer interaction approach and propose an interactive method to support and optimize the work of volunteers in OSM. The user is asked to verify/correct the annotation of selected tiles during several iterations and therefore improving the model with the new annotated data. The experimental results, with simulated and real user annotation corrections, show that the proposed method greatly reduces the amount of data that the volunteers of OSM need to verify/correct. The proposed methodology could benefit humanitarian mapping projects, not only by making more efficient the process of annotation but also by improving the engagement of volunteers.
Fast and Robust Symmetric Image Registration Based on Intensity and Spatial Information
Jul 30, 2018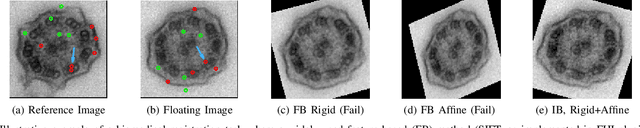
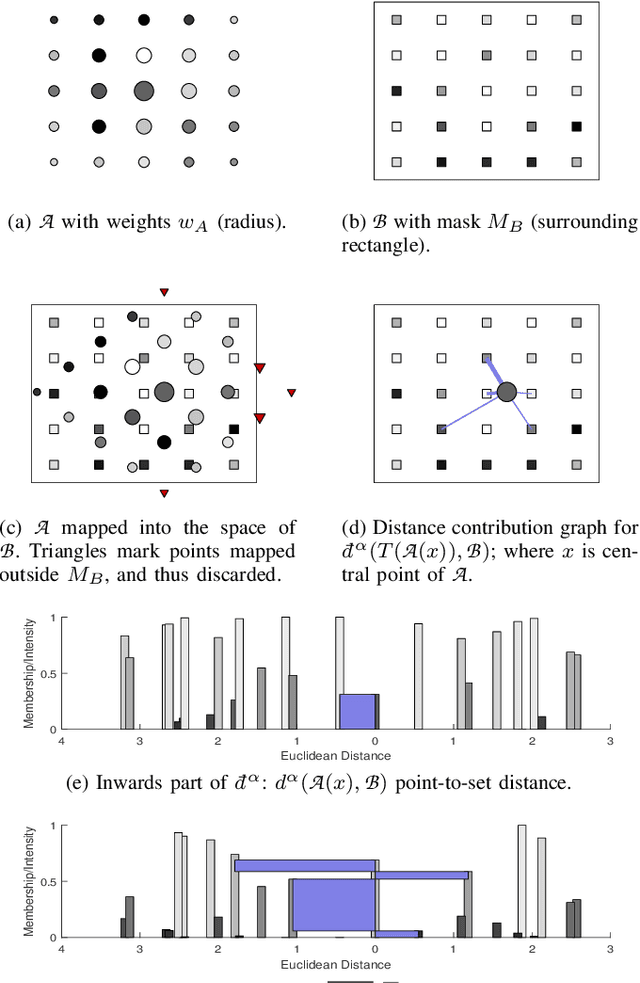
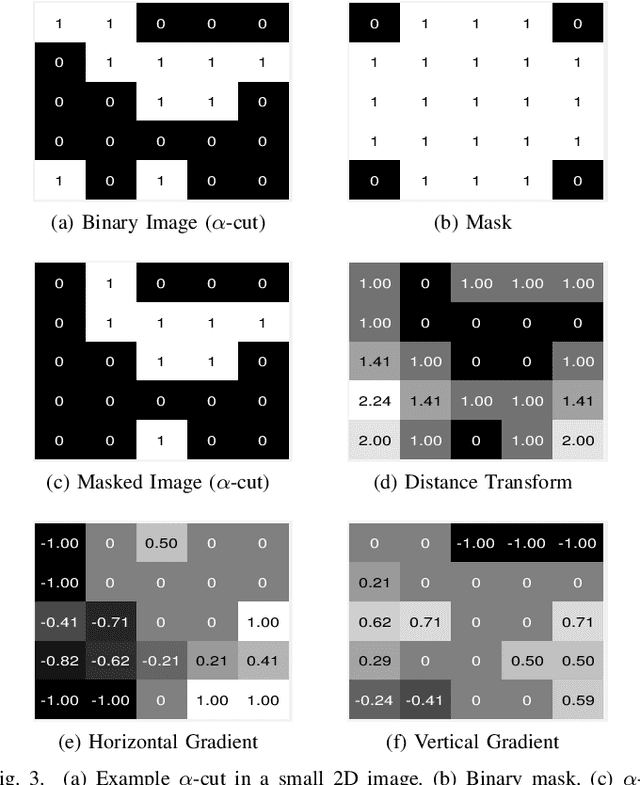
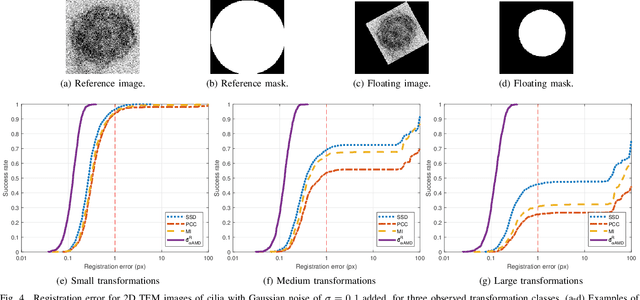
Intensity-based image registration approaches rely on similarity measures to guide the search for geometric correspondences with high affinity between images. The properties of the used measure are vital for the robustness and accuracy of the registration. In this study a symmetric, intensity interpolation-free, affine registration framework based on a combination of intensity and spatial information is proposed. The excellent performance of the framework is demonstrated on a combination of synthetic tests, recovering known transformations in the presence of noise, and real applications in biomedical and medical image registration, for both 2D and 3D images. The method exhibits greater robustness and higher accuracy than similarity measures in common use, when inserted into a standard gradient-based registration framework available as part of the open source Insight Segmentation and Registration Toolkit (ITK). The method is also empirically shown to have a low computational cost, making it practical for real applications. Source code is available.
Learning Visual Representations with Caption Annotations
Aug 04, 2020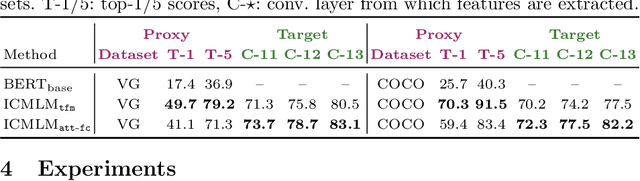
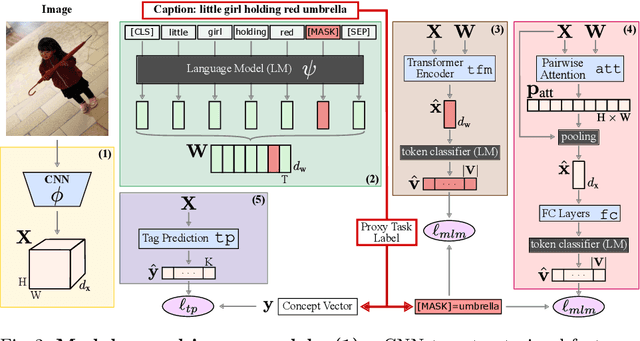
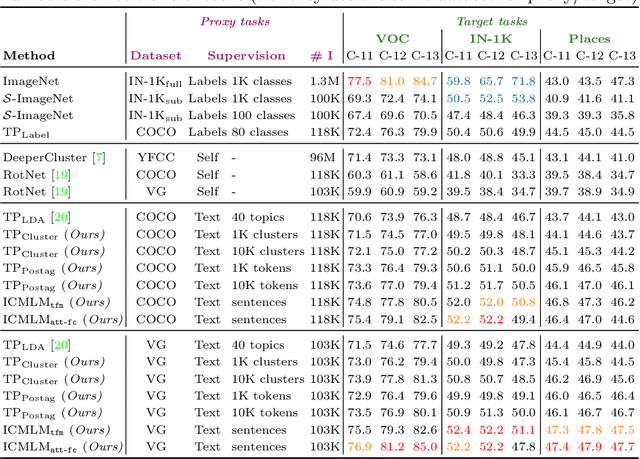

Pretraining general-purpose visual features has become a crucial part of tackling many computer vision tasks. While one can learn such features on the extensively-annotated ImageNet dataset, recent approaches have looked at ways to allow for noisy, fewer, or even no annotations to perform such pretraining. Starting from the observation that captioned images are easily crawlable, we argue that this overlooked source of information can be exploited to supervise the training of visual representations. To do so, motivated by the recent progresses in language models, we introduce {\em image-conditioned masked language modeling} (ICMLM) -- a proxy task to learn visual representations over image-caption pairs. ICMLM consists in predicting masked words in captions by relying on visual cues. To tackle this task, we propose hybrid models, with dedicated visual and textual encoders, and we show that the visual representations learned as a by-product of solving this task transfer well to a variety of target tasks. Our experiments confirm that image captions can be leveraged to inject global and localized semantic information into visual representations. Project website: https://europe.naverlabs.com/icmlm.
CoADNet: Collaborative Aggregation-and-Distribution Networks for Co-Salient Object Detection
Nov 10, 2020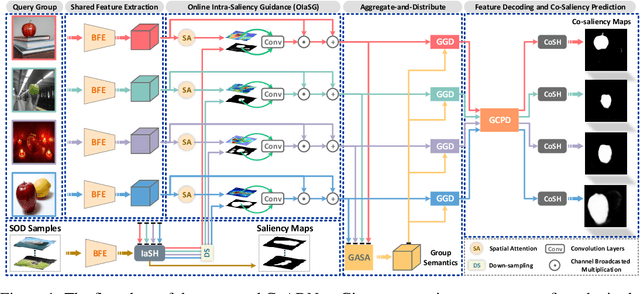
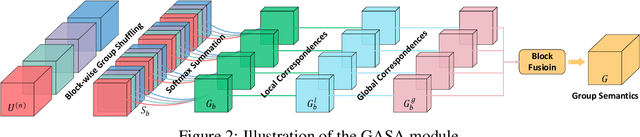
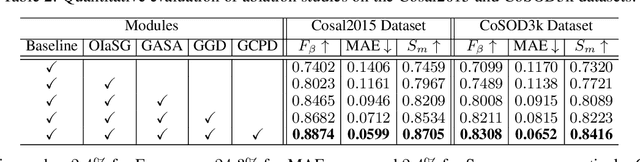

Co-Salient Object Detection (CoSOD) aims at discovering salient objects that repeatedly appear in a given query group containing two or more relevant images. One challenging issue is how to effectively capture co-saliency cues by modeling and exploiting inter-image relationships. In this paper, we present an end-to-end collaborative aggregation-and-distribution network (CoADNet) to capture both salient and repetitive visual patterns from multiple images. First, we integrate saliency priors into the backbone features to suppress the redundant background information through an online intra-saliency guidance structure. After that, we design a two-stage aggregate-and-distribute architecture to explore group-wise semantic interactions and produce the co-saliency features. In the first stage, we propose a group-attentional semantic aggregation module that models inter-image relationships to generate the group-wise semantic representations. In the second stage, we propose a gated group distribution module that adaptively distributes the learned group semantics to different individuals in a dynamic gating mechanism. Finally, we develop a group consistency preserving decoder tailored for the CoSOD task, which maintains group constraints during feature decoding to predict more consistent full-resolution co-saliency maps. The proposed CoADNet is evaluated on four prevailing CoSOD benchmark datasets, which demonstrates the remarkable performance improvement over ten state-of-the-art competitors.
Efficient Subsampling for Generating High-Quality Images from Conditional Generative Adversarial Networks
Mar 20, 2021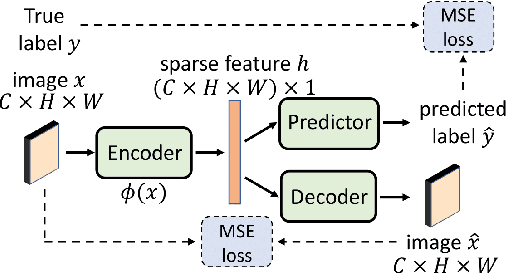
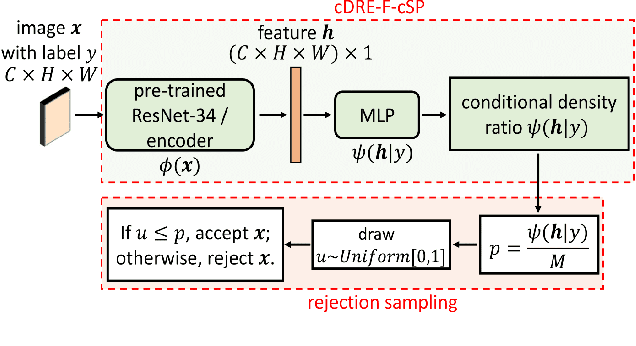
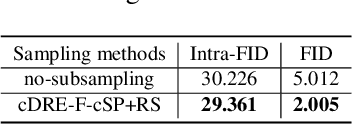
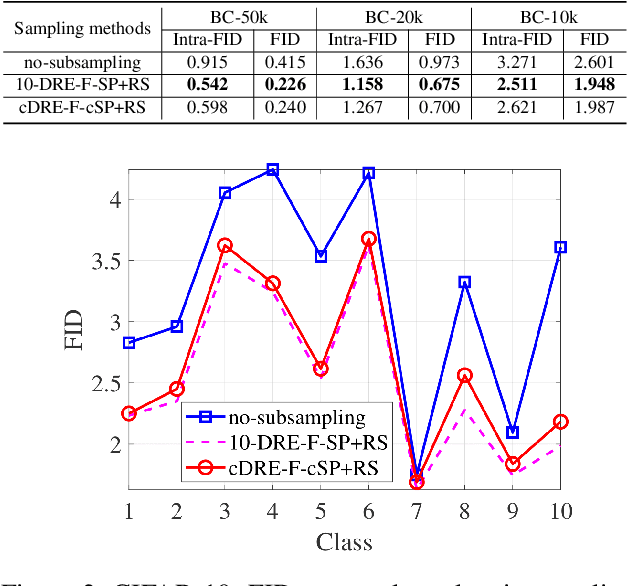
Subsampling unconditional generative adversarial networks (GANs) to improve the overall image quality has been studied recently. However, these methods often require high training costs (e.g., storage space, parameter tuning) and may be inefficient or even inapplicable for subsampling conditional GANs, such as class-conditional GANs and continuous conditional GANs (CcGANs), when the condition has many distinct values. In this paper, we propose an efficient method called conditional density ratio estimation in feature space with conditional Softplus loss (cDRE-F-cSP). With cDRE-F-cSP, we estimate an image's conditional density ratio based on a novel conditional Softplus (cSP) loss in the feature space learned by a specially designed ResNet-34 or sparse autoencoder. We then derive the error bound of a conditional density ratio model trained with the proposed cSP loss. Finally, we propose a rejection sampling scheme, termed cDRE-F-cSP+RS, which can subsample both class-conditional GANs and CcGANs efficiently. An extra filtering scheme is also developed for CcGANs to increase the label consistency. Experiments on CIFAR-10 and Tiny-ImageNet datasets show that cDRE-F-cSP+RS can substantially improve the Intra-FID and FID scores of BigGAN. Experiments on RC-49 and UTKFace datasets demonstrate that cDRE-F-cSP+RS also improves Intra-FID, Diversity, and Label Score of CcGANs. Moreover, to show the high efficiency of cDRE-F-cSP+RS, we compare it with the state-of-the-art unconditional subsampling method (i.e., DRE-F-SP+RS). With comparable or even better performance, cDRE-F-cSP+RS only requires about \textbf{10}\% and \textbf{1.7}\% of the training costs spent respectively on CIFAR-10 and UTKFace by DRE-F-SP+RS.
How Faithful is your Synthetic Data? Sample-level Metrics for Evaluating and Auditing Generative Models
Feb 17, 2021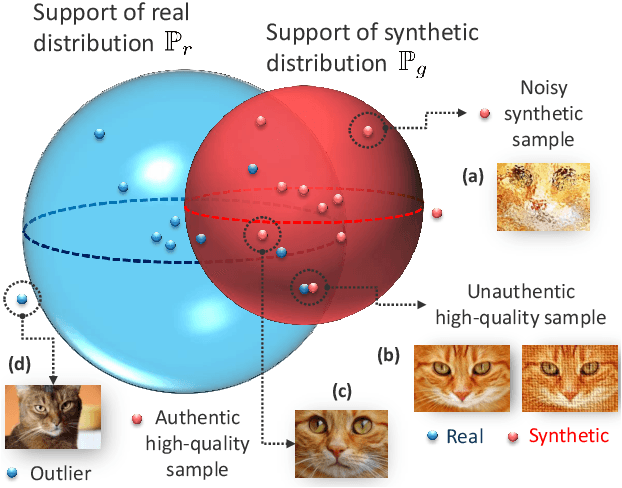

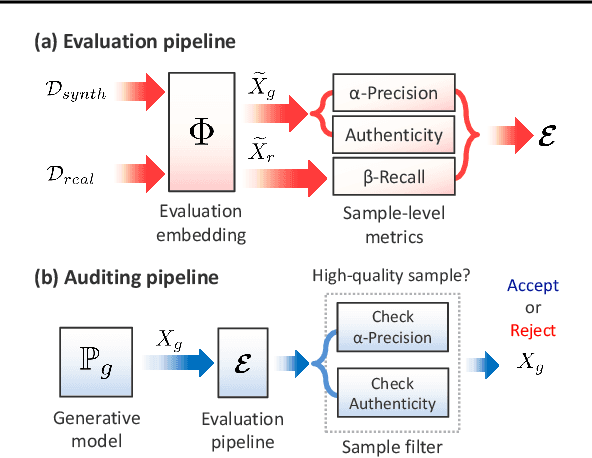
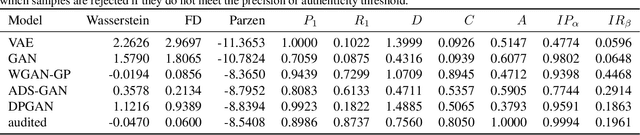
Devising domain- and model-agnostic evaluation metrics for generative models is an important and as yet unresolved problem. Most existing metrics, which were tailored solely to the image synthesis setup, exhibit a limited capacity for diagnosing the different modes of failure of generative models across broader application domains. In this paper, we introduce a 3-dimensional evaluation metric, ($\alpha$-Precision, $\beta$-Recall, Authenticity), that characterizes the fidelity, diversity and generalization performance of any generative model in a domain-agnostic fashion. Our metric unifies statistical divergence measures with precision-recall analysis, enabling sample- and distribution-level diagnoses of model fidelity and diversity. We introduce generalization as an additional, independent dimension (to the fidelity-diversity trade-off) that quantifies the extent to which a model copies training data -- a crucial performance indicator when modeling sensitive data with requirements on privacy. The three metric components correspond to (interpretable) probabilistic quantities, and are estimated via sample-level binary classification. The sample-level nature of our metric inspires a novel use case which we call model auditing, wherein we judge the quality of individual samples generated by a (black-box) model, discarding low-quality samples and hence improving the overall model performance in a post-hoc manner.