 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Predicting Visual Features from Text for Image and Video Caption Retrieval
Jul 14, 2018
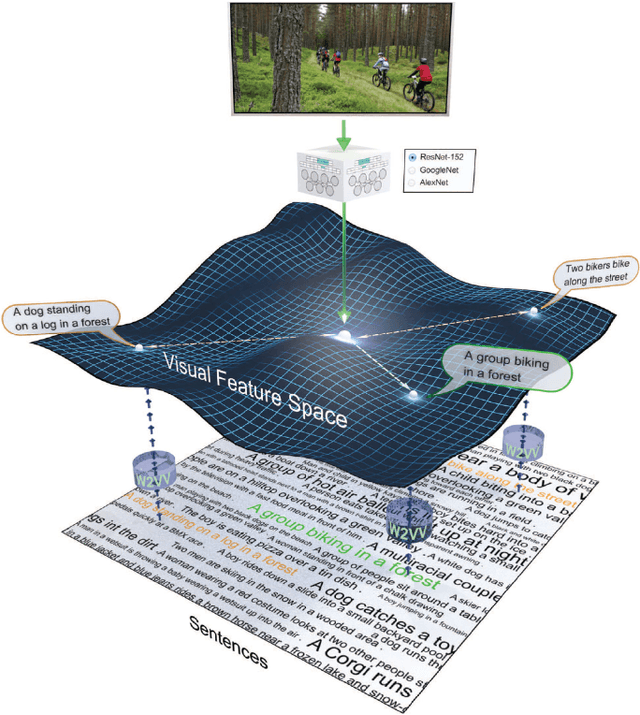

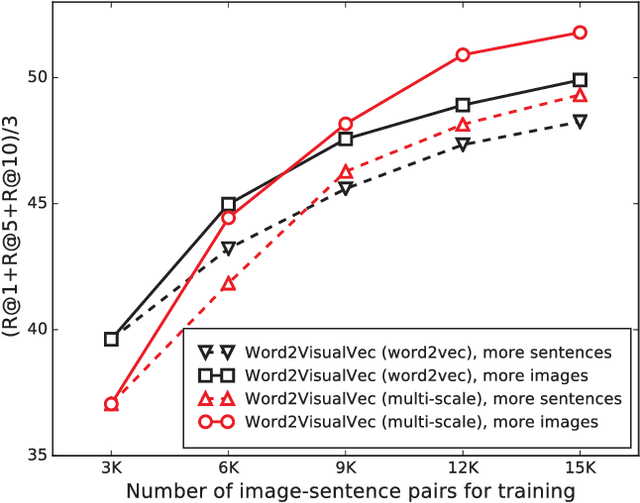
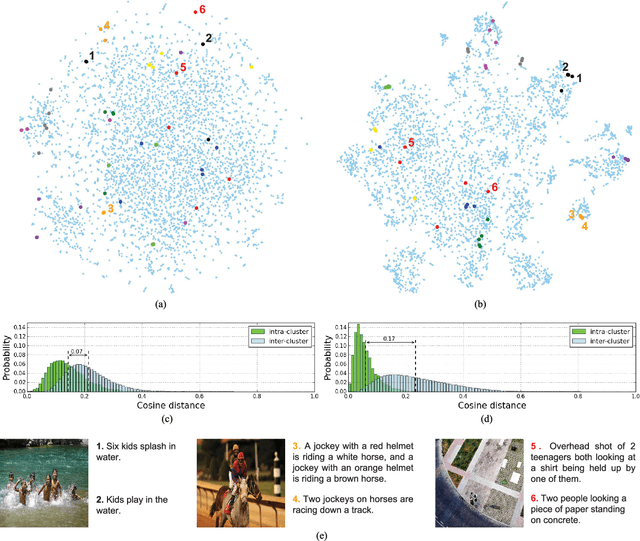
This paper strives to find amidst a set of sentences the one best describing the content of a given image or video. Different from existing works, which rely on a joint subspace for their image and video caption retrieval, we propose to do so in a visual space exclusively. Apart from this conceptual novelty, we contribute \emph{Word2VisualVec}, a deep neural network architecture that learns to predict a visual feature representation from textual input. Example captions are encoded into a textual embedding based on multi-scale sentence vectorization and further transferred into a deep visual feature of choice via a simple multi-layer perceptron. We further generalize Word2VisualVec for video caption retrieval, by predicting from text both 3-D convolutional neural network features as well as a visual-audio representation. Experiments on Flickr8k, Flickr30k, the Microsoft Video Description dataset and the very recent NIST TrecVid challenge for video caption retrieval detail Word2VisualVec's properties, its benefit over textual embeddings, the potential for multimodal query composition and its state-of-the-art results.
FrugalMCT: Efficient Online ML API Selection for Multi-Label Classification Tasks
Feb 18, 2021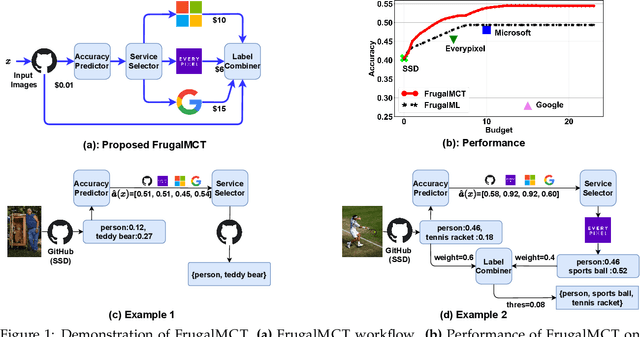
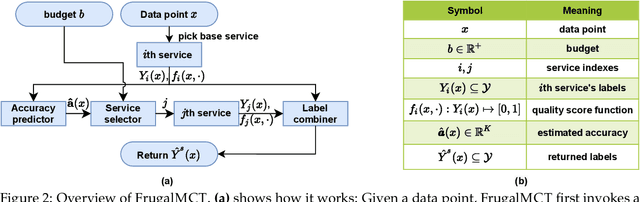
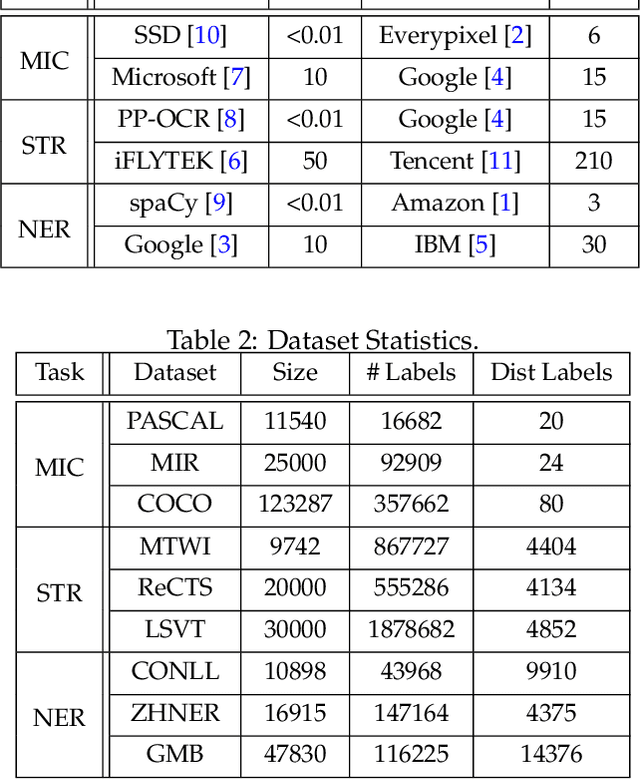
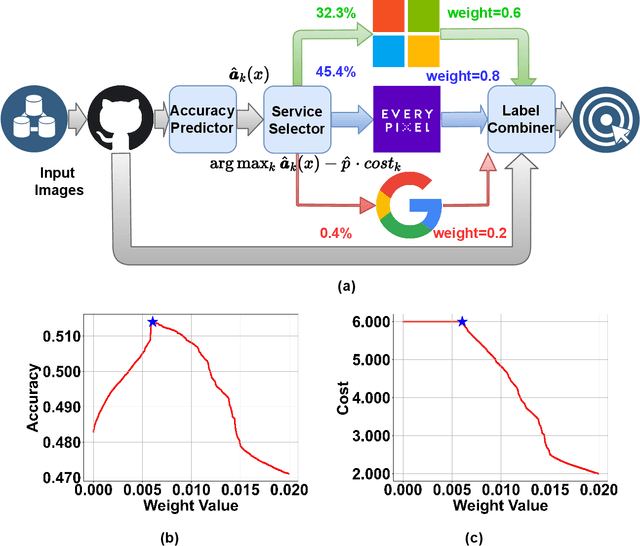
Multi-label classification tasks such as OCR and multi-object recognition are a major focus of the growing machine learning as a service industry. While many multi-label prediction APIs are available, it is challenging for users to decide which API to use for their own data and budget, due to the heterogeneity in those APIs' price and performance. Recent work shows how to select from single-label prediction APIs. However the computation complexity of the previous approach is exponential in the number of labels and hence is not suitable for settings like OCR. In this work, we propose FrugalMCT, a principled framework that adaptively selects the APIs to use for different data in an online fashion while respecting user's budget. The API selection problem is cast as an integer linear program, which we show has a special structure that we leverage to develop an efficient online API selector with strong performance guarantees. We conduct systematic experiments using ML APIs from Google, Microsoft, Amazon, IBM, Tencent and other providers for tasks including multi-label image classification, scene text recognition and named entity recognition. Across diverse tasks, FrugalMCT can achieve over 90% cost reduction while matching the accuracy of the best single API, or up to 8% better accuracy while matching the best API's cost.
Customizing First Person Image Through Desired Actions
Apr 01, 2017

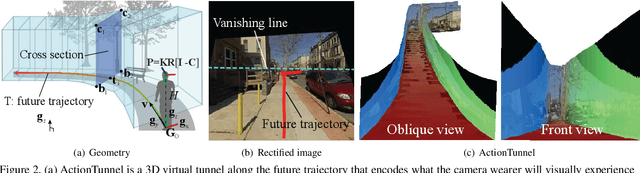
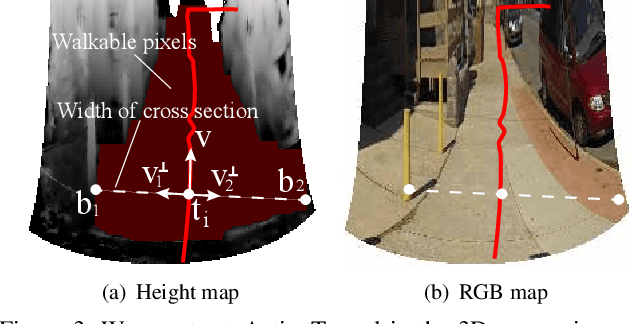
This paper studies a problem of inverse visual path planning: creating a visual scene from a first person action. Our conjecture is that the spatial arrangement of a first person visual scene is deployed to afford an action, and therefore, the action can be inversely used to synthesize a new scene such that the action is feasible. As a proof-of-concept, we focus on linking visual experiences induced by walking. A key innovation of this paper is a concept of ActionTunnel---a 3D virtual tunnel along the future trajectory encoding what the wearer will visually experience as moving into the scene. This connects two distinctive first person images through similar walking paths. Our method takes a first person image with a user defined future trajectory and outputs a new image that can afford the future motion. The image is created by combining present and future ActionTunnels in 3D where the missing pixels in adjoining area are computed by a generative adversarial network. Our work can provide a travel across different first person experiences in diverse real world scenes.
Few-Shot Learning for Road Object Detection
Jan 29, 2021
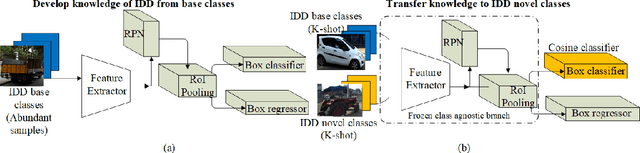

Few-shot learning is a problem of high interest in the evolution of deep learning. In this work, we consider the problem of few-shot object detection (FSOD) in a real-world, class-imbalanced scenario. For our experiments, we utilize the India Driving Dataset (IDD), as it includes a class of less-occurring road objects in the image dataset and hence provides a setup suitable for few-shot learning. We evaluate both metric-learning and meta-learning based FSOD methods, in two experimental settings: (i) representative (same-domain) splits from IDD, that evaluates the ability of a model to learn in the context of road images, and (ii) object classes with less-occurring object samples, similar to the open-set setting in real-world. From our experiments, we demonstrate that the metric-learning method outperforms meta-learning on the novel classes by (i) 11.2 mAP points on the same domain, and (ii) 1.0 mAP point on the open-set. We also show that our extension of object classes in a real-world open dataset offers a rich ground for few-shot learning studies.
Expressway visibility estimation based on image entropy and piecewise stationary time series analysis
Apr 08, 2018



Vision-based methods for visibility estimation can play a critical role in reducing traffic accidents caused by fog and haze. To overcome the disadvantages of current visibility estimation methods, we present a novel data-driven approach based on Gaussian image entropy and piecewise stationary time series analysis (SPEV). This is the first time that Gaussian image entropy is used for estimating atmospheric visibility. To lessen the impact of landscape and sunshine illuminance on visibility estimation, we used region of interest (ROI) analysis and took into account relative ratios of image entropy, to improve estimation accuracy. We assume fog and haze cause blurred images and that fog and haze can be considered as a piecewise stationary signal. We used piecewise stationary time series analysis to construct the piecewise causal relationship between image entropy and visibility. To obtain a real-world visibility measure during fog and haze, a subjective assessment was established through a study with 36 subjects who performed visibility observations. Finally, a total of two million videos were used for training the SPEV model and validate its effectiveness. The videos were collected from the constantly foggy and hazy Tongqi expressway in Jiangsu, China. The contrast model of visibility estimation was used for algorithm performance comparison, and the validation results of the SPEV model were encouraging as 99.14% of the relative errors were less than 10%.
Super Characters: A Conversion from Sentiment Classification to Image Classification
Oct 15, 2018
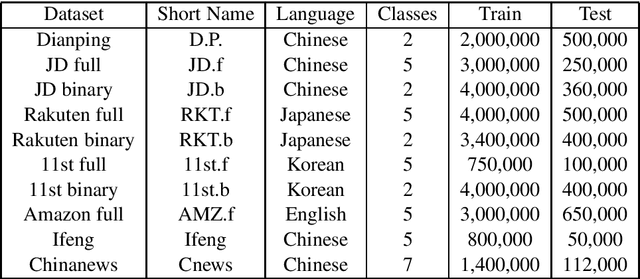


We propose a method named Super Characters for sentiment classification. This method converts the sentiment classification problem into image classification problem by projecting texts into images and then applying CNN models for classification. Text features are extracted automatically from the generated Super Characters images, hence there is no need of any explicit step of embedding the words or characters into numerical vector representations. Experimental results on large social media corpus show that the Super Characters method consistently outperforms other methods for sentiment classification and topic classification tasks on ten large social media datasets of millions of contents in four different languages, including Chinese, Japanese, Korean and English.
Deep correction of breathing-related artifacts in MR-thermometry
Nov 10, 2020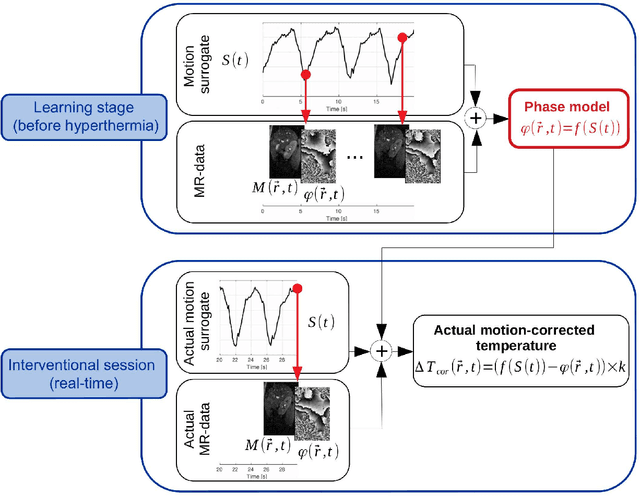
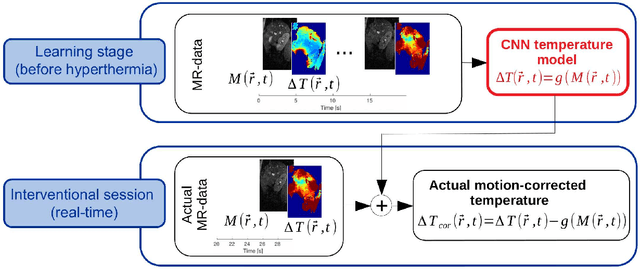
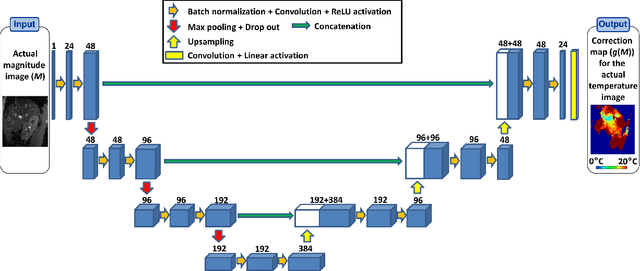
Real-time MR-imaging has been clinically adapted for monitoring thermal therapies since it can provide on-the-fly temperature maps simultaneously with anatomical information. However, proton resonance frequency based thermometry of moving targets remains challenging since temperature artifacts are induced by the respiratory as well as physiological motion. If left uncorrected, these artifacts lead to severe errors in temperature estimates and impair therapy guidance. In this study, we evaluated deep learning for on-line correction of motion related errors in abdominal MR-thermometry. For this, a convolutional neural network (CNN) was designed to learn the apparent temperature perturbation from images acquired during a preparative learning stage prior to hyperthermia. The input of the designed CNN is the most recent magnitude image and no surrogate of motion is needed. During the subsequent hyperthermia procedure, the recent magnitude image is used as an input for the CNN-model in order to generate an on-line correction for the current temperature map. The method's artifact suppression performance was evaluated on 12 free breathing volunteers and was found robust and artifact-free in all examined cases. Furthermore, thermometric precision and accuracy was assessed for in vivo ablation using high intensity focused ultrasound. All calculations involved at the different stages of the proposed workflow were designed to be compatible with the clinical time constraints of a therapeutic procedure.
Multimodal Pivots for Image Caption Translation
Jun 13, 2016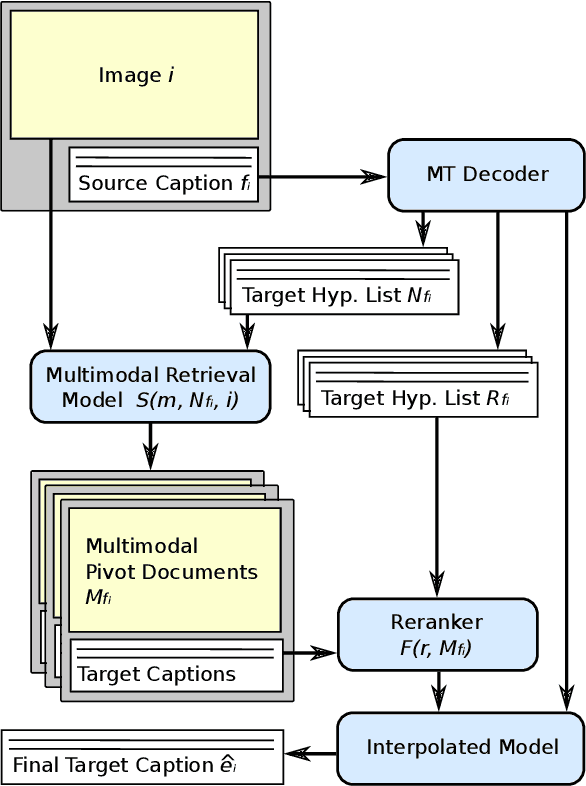
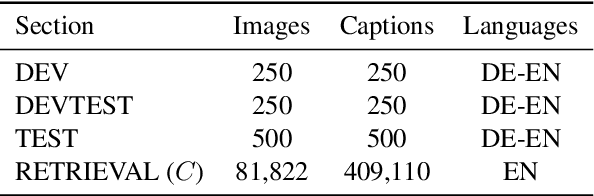
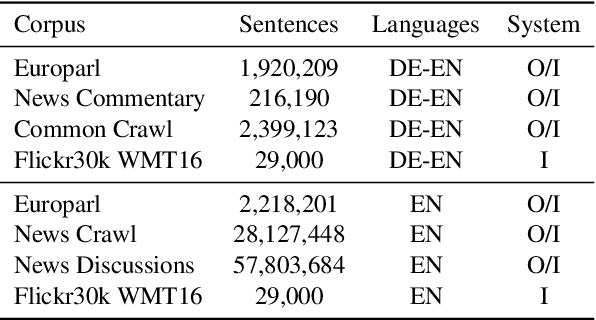
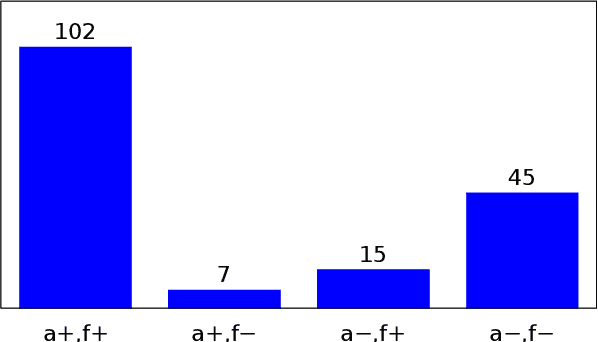
We present an approach to improve statistical machine translation of image descriptions by multimodal pivots defined in visual space. The key idea is to perform image retrieval over a database of images that are captioned in the target language, and use the captions of the most similar images for crosslingual reranking of translation outputs. Our approach does not depend on the availability of large amounts of in-domain parallel data, but only relies on available large datasets of monolingually captioned images, and on state-of-the-art convolutional neural networks to compute image similarities. Our experimental evaluation shows improvements of 1 BLEU point over strong baselines.
A Detail Based Method for Linear Full Reference Image Quality Prediction
Nov 05, 2017
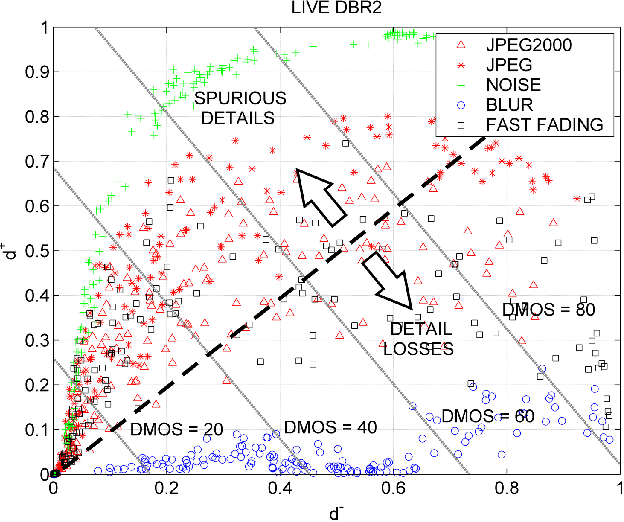
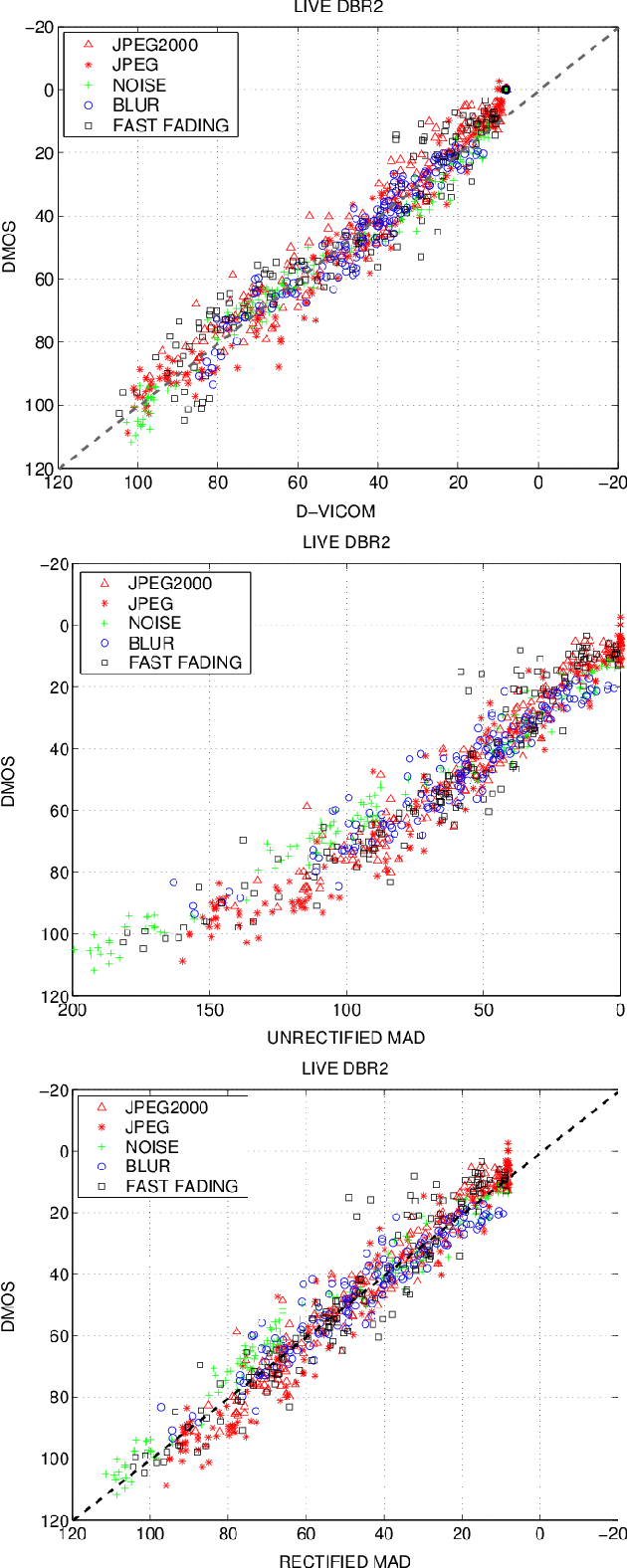
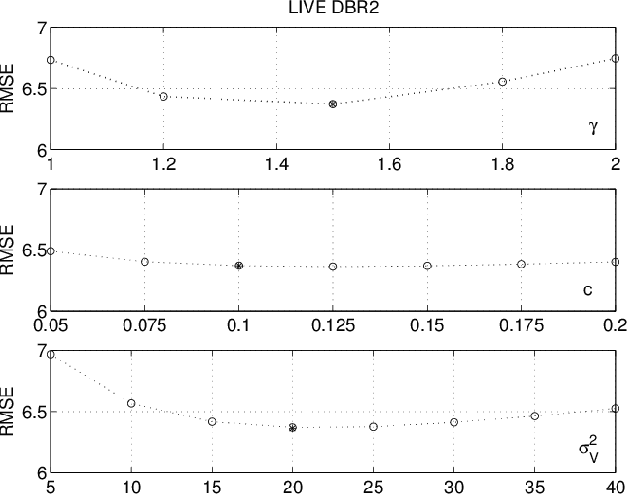
In this paper, a novel Full Reference method is proposed for image quality assessment, using the combination of two separate metrics to measure the perceptually distinct impact of detail losses and of spurious details. To this purpose, the gradient of the impaired image is locally decomposed as a predicted version of the original gradient, plus a gradient residual. It is assumed that the detail attenuation identifies the detail loss, whereas the gradient residuals describe the spurious details. It turns out that the perceptual impact of detail losses is roughly linear with the loss of the positional Fisher information, while the perceptual impact of the spurious details is roughly proportional to a logarithmic measure of the signal to residual ratio. The affine combination of these two metrics forms a new index strongly correlated with the empirical Differential Mean Opinion Score (DMOS) for a significant class of image impairments, as verified for three independent popular databases. The method allowed alignment and merging of DMOS data coming from these different databases to a common DMOS scale by affine transformations. Unexpectedly, the DMOS scale setting is possible by the analysis of a single image affected by additive noise.
* 15 pages, 9 figures. Copyright notice: The paper has been accepted for publication on the IEEE Trans. on Image Processing on 19/09/2017 and the copyright has been transferred to the IEEE
Deploying machine learning to assist digital humanitarians: making image annotation in OpenStreetMap more efficient
Sep 17, 2020

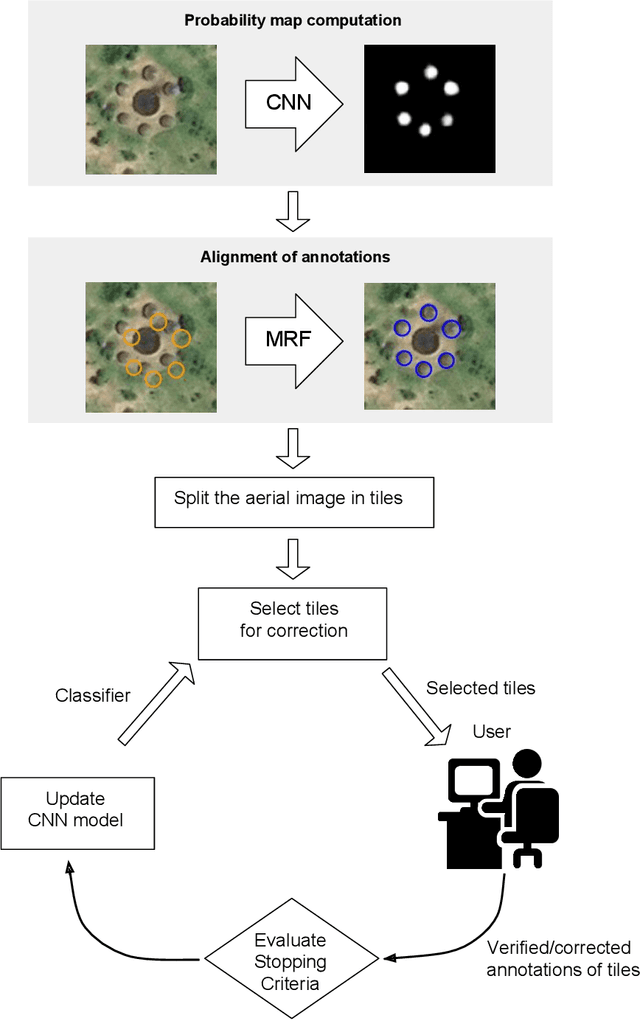
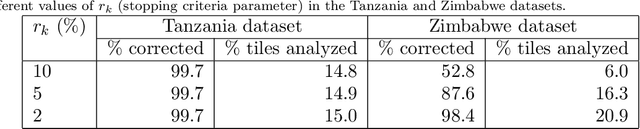
Locating populations in rural areas of developing countries has attracted the attention of humanitarian mapping projects since it is important to plan actions that affect vulnerable areas. Recent efforts have tackled this problem as the detection of buildings in aerial images. However, the quality and the amount of rural building annotated data in open mapping services like OpenStreetMap (OSM) is not sufficient for training accurate models for such detection. Although these methods have the potential of aiding in the update of rural building information, they are not accurate enough to automatically update the rural building maps. In this paper, we explore a human-computer interaction approach and propose an interactive method to support and optimize the work of volunteers in OSM. The user is asked to verify/correct the annotation of selected tiles during several iterations and therefore improving the model with the new annotated data. The experimental results, with simulated and real user annotation corrections, show that the proposed method greatly reduces the amount of data that the volunteers of OSM need to verify/correct. The proposed methodology could benefit humanitarian mapping projects, not only by making more efficient the process of annotation but also by improving the engagement of volunteers.