 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FAIM -- A ConvNet Method for Unsupervised 3D Medical Image Registration
Nov 22, 2018
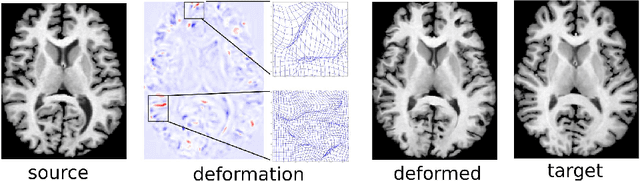

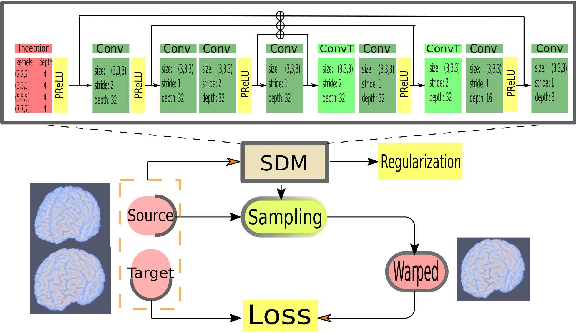

We present a new unsupervised learning algorithm, "FAIM", for 3D medical image registration. Based on a convolutional neural net, FAIM learns from a training set of pairs of images, without needing ground truth information such as landmarks or dense registrations. Once trained, FAIM can register a new pair of images in less than a second, with competitive quality. We compared FAIM with a similar method, VoxelMorph, as well as a diffeomorphic method, uTIlzReg GeoShoot, on the LPBA40 and Mindboggle101 datasets. Results for FAIM were comparable or better than the other methods on pairwise registrations. The effect of different regularization choices on the predicted deformations is briefly investigated. Finally, an application to fast construction of a template and atlas is demonstrated.
Machine learning methods for histopathological image analysis
Dec 03, 2017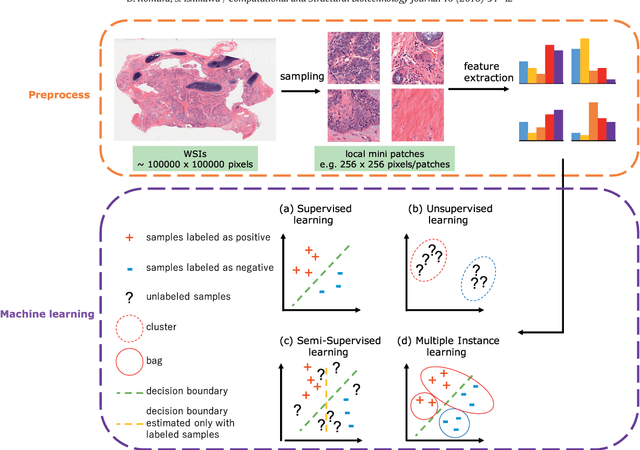

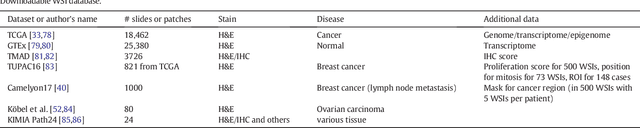
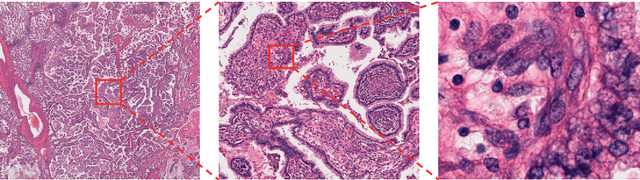
Abundant accumulation of digital histopathological images has led to the increased demand for their analysis, such as computer-aided diagnosis using machine learning techniques. However, digital pathological images and related tasks have some issues to be considered. In this mini-review, we introduce the application of digital pathological image analysis using machine learning algorithms, address some problems specific to such analysis, and propose possible solutions.
Deep Bi-Dense Networks for Image Super-Resolution
Oct 11, 2018
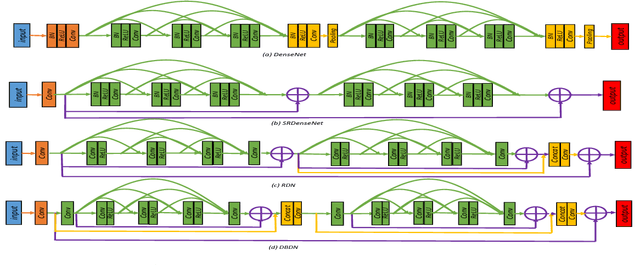
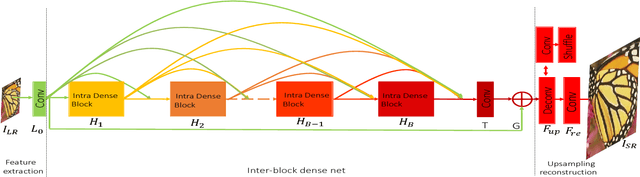
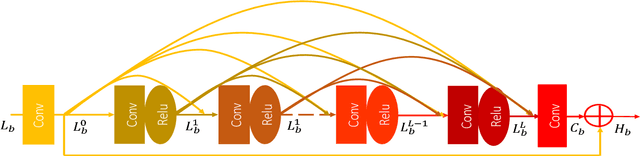
This paper proposes Deep Bi-Dense Networks (DBDN) for single image super-resolution. Our approach extends previous intra-block dense connection approaches by including novel inter-block dense connections. In this way, feature information propagates from a single dense block to all subsequent blocks, instead of to a single successor. To build a DBDN, we firstly construct intra-dense blocks, which extract and compress abundant local features via densely connected convolutional layers and compression layers for further feature learning. Then, we use an inter-block dense net to connect intra-dense blocks, which allow each intra-dense block propagates its own local features to all successors. Additionally, our bi-dense construction connects each block to the output, alleviating the vanishing gradient problems in training. The evaluation of our proposed method on five benchmark datasets shows that our DBDN outperforms the state of the art in SISR with a moderate number of network parameters.
Using GANs to Synthesise Minimum Training Data for Deepfake Generation
Nov 10, 2020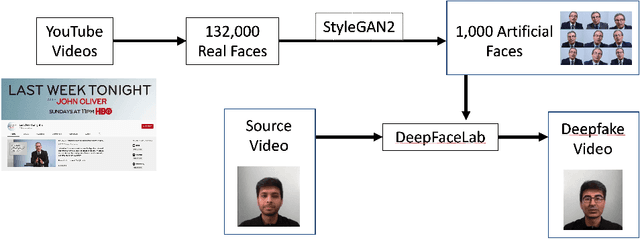
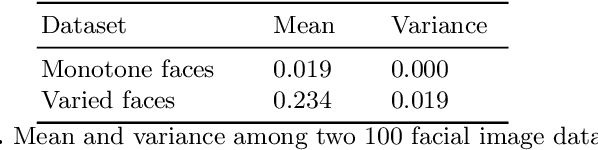
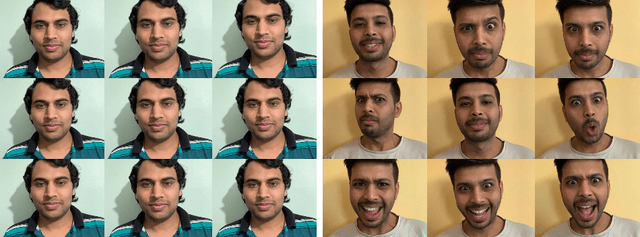
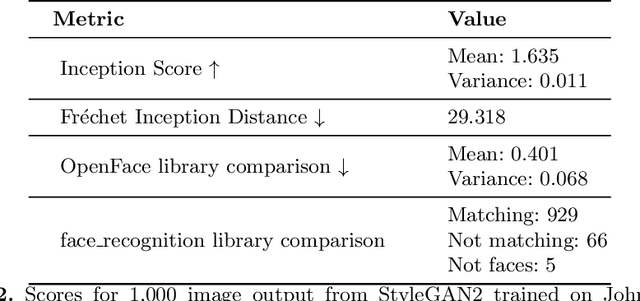
There are many applications of Generative Adversarial Networks (GANs) in fields like computer vision, natural language processing, speech synthesis, and more. Undoubtedly the most notable results have been in the area of image synthesis and in particular in the generation of deepfake videos. While deepfakes have received much negative media coverage, they can be a useful technology in applications like entertainment, customer relations, or even assistive care. One problem with generating deepfakes is the requirement for a lot of image training data of the subject which is not an issue if the subject is a celebrity for whom many images already exist. If there are only a small number of training images then the quality of the deepfake will be poor. Some media reports have indicated that a good deepfake can be produced with as few as 500 images but in practice, quality deepfakes require many thousands of images, one of the reasons why deepfakes of celebrities and politicians have become so popular. In this study, we exploit the property of a GAN to produce images of an individual with variable facial expressions which we then use to generate a deepfake. We observe that with such variability in facial expressions of synthetic GAN-generated training images and a reduced quantity of them, we can produce a near-realistic deepfake videos.
Visual Navigation in Real-World Indoor Environments Using End-to-End Deep Reinforcement Learning
Oct 21, 2020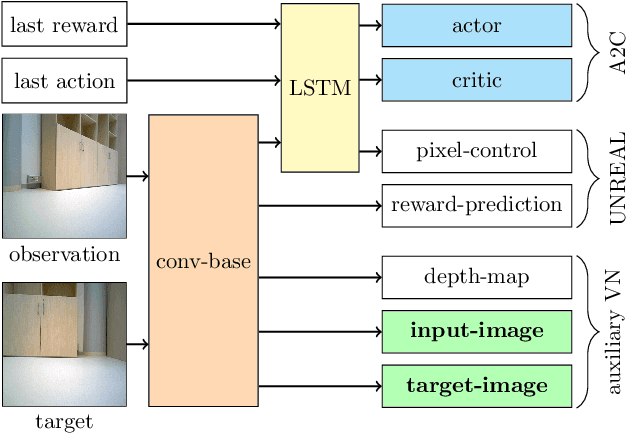

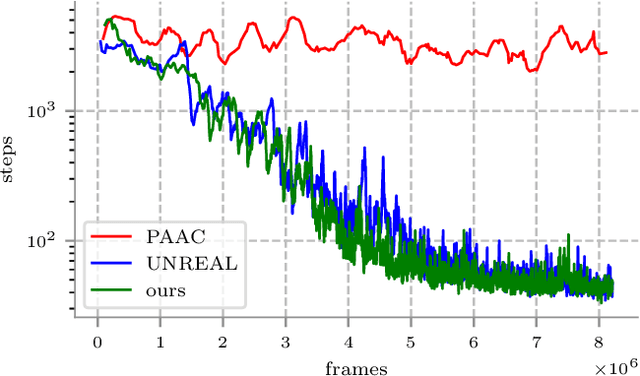

Visual navigation is essential for many applications in robotics, from manipulation, through mobile robotics to automated driving. Deep reinforcement learning (DRL) provides an elegant map-free approach integrating image processing, localization, and planning in one module, which can be trained and therefore optimized for a given environment. However, to date, DRL-based visual navigation was validated exclusively in simulation, where the simulator provides information that is not available in the real world, e.g., the robot's position or image segmentation masks. This precludes the use of the learned policy on a real robot. Therefore, we propose a novel approach that enables a direct deployment of the trained policy on real robots. We have designed visual auxiliary tasks, a tailored reward scheme, and a new powerful simulator to facilitate domain randomization. The policy is fine-tuned on images collected from real-world environments. We have evaluated the method on a mobile robot in a real office environment. The training took ~30 hours on a single GPU. In 30 navigation experiments, the robot reached a 0.3-meter neighborhood of the goal in more than 86.7% of cases. This result makes the proposed method directly applicable to tasks like mobile manipulation.
ClassSR: A General Framework to Accelerate Super-Resolution Networks by Data Characteristic
Mar 06, 2021
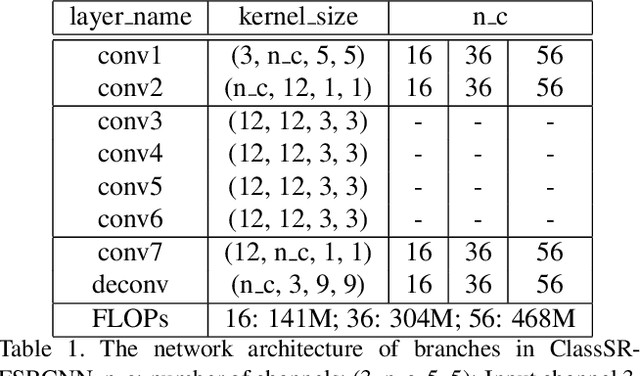
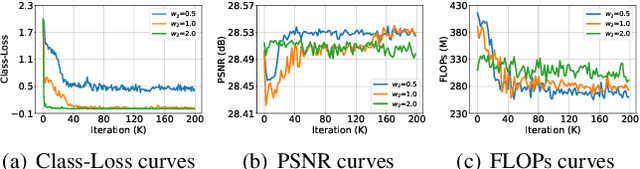
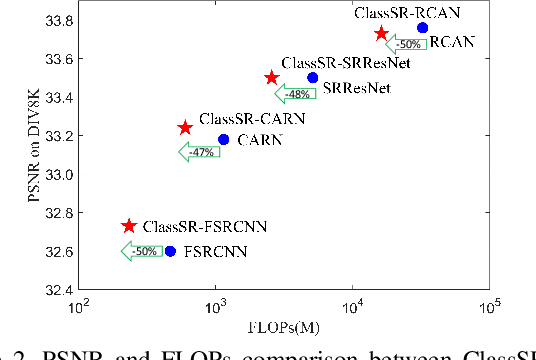
We aim at accelerating super-resolution (SR) networks on large images (2K-8K). The large images are usually decomposed into small sub-images in practical usages. Based on this processing, we found that different image regions have different restoration difficulties and can be processed by networks with different capacities. Intuitively, smooth areas are easier to super-solve than complex textures. To utilize this property, we can adopt appropriate SR networks to process different sub-images after the decomposition. On this basis, we propose a new solution pipeline -- ClassSR that combines classification and SR in a unified framework. In particular, it first uses a Class-Module to classify the sub-images into different classes according to restoration difficulties, then applies an SR-Module to perform SR for different classes. The Class-Module is a conventional classification network, while the SR-Module is a network container that consists of the to-be-accelerated SR network and its simplified versions. We further introduce a new classification method with two losses -- Class-Loss and Average-Loss to produce the classification results. After joint training, a majority of sub-images will pass through smaller networks, thus the computational cost can be significantly reduced. Experiments show that our ClassSR can help most existing methods (e.g., FSRCNN, CARN, SRResNet, RCAN) save up to 50% FLOPs on DIV8K datasets. This general framework can also be applied in other low-level vision tasks.
How Faithful is your Synthetic Data? Sample-level Metrics for Evaluating and Auditing Generative Models
Feb 17, 2021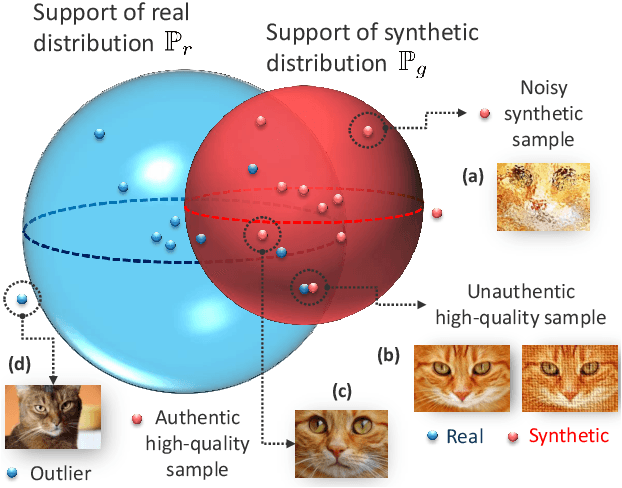

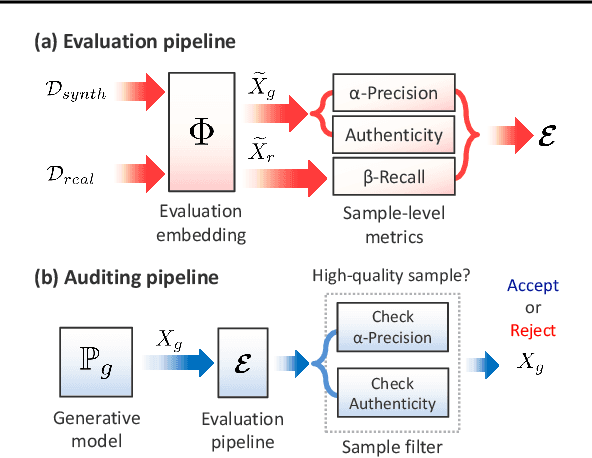
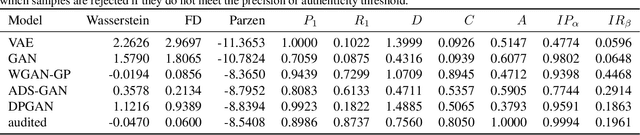
Devising domain- and model-agnostic evaluation metrics for generative models is an important and as yet unresolved problem. Most existing metrics, which were tailored solely to the image synthesis setup, exhibit a limited capacity for diagnosing the different modes of failure of generative models across broader application domains. In this paper, we introduce a 3-dimensional evaluation metric, ($\alpha$-Precision, $\beta$-Recall, Authenticity), that characterizes the fidelity, diversity and generalization performance of any generative model in a domain-agnostic fashion. Our metric unifies statistical divergence measures with precision-recall analysis, enabling sample- and distribution-level diagnoses of model fidelity and diversity. We introduce generalization as an additional, independent dimension (to the fidelity-diversity trade-off) that quantifies the extent to which a model copies training data -- a crucial performance indicator when modeling sensitive data with requirements on privacy. The three metric components correspond to (interpretable) probabilistic quantities, and are estimated via sample-level binary classification. The sample-level nature of our metric inspires a novel use case which we call model auditing, wherein we judge the quality of individual samples generated by a (black-box) model, discarding low-quality samples and hence improving the overall model performance in a post-hoc manner.
Trainable Activation Function Supported CNN in Image Classification
Apr 28, 2020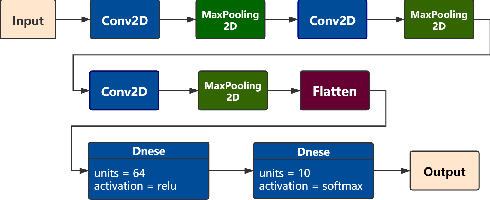
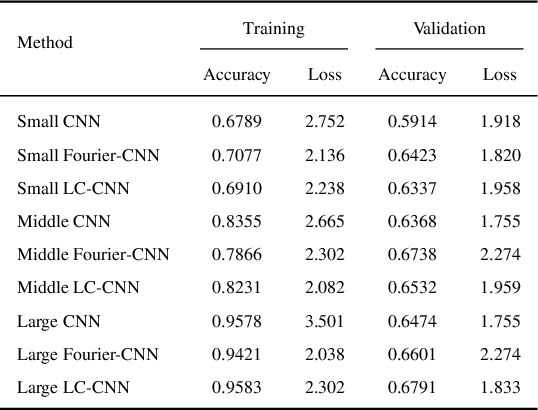
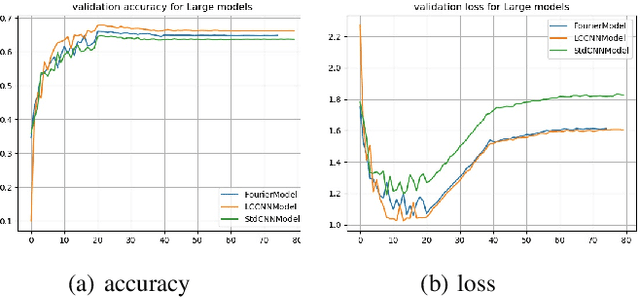
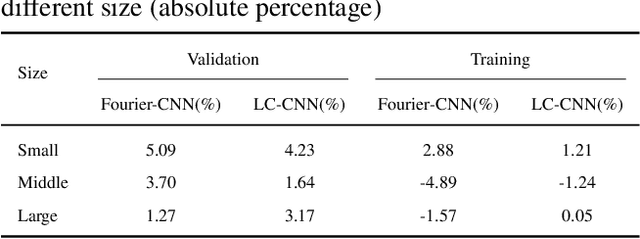
In the current research of neural networks, the activation function is manually specified by human and not able to change themselves during training. This paper focus on how to make the activation function trainable for deep neural networks. We use series and linear combination of different activation functions make activation functions continuously variable. Also, we test the performance of CNNs with Fourier series simulated activation(Fourier-CNN) and CNNs with linear combined activation function (LC-CNN) on Cifar-10 dataset. The result shows our trainable activation function reveals better performance than the most used ReLU activation function. Finally, we improves the performance of Fourier-CNN with Autoencoder, and test the performance of PSO algorithm in optimizing the parameters of networks
Cloud Removal for Remote Sensing Imagery via Spatial Attention Generative Adversarial Network
Sep 28, 2020
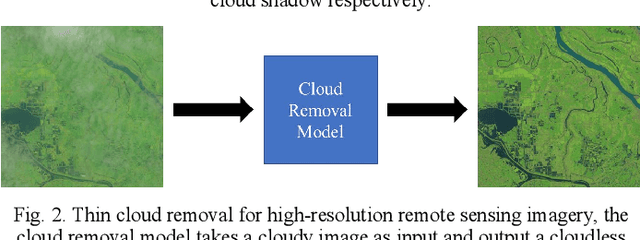
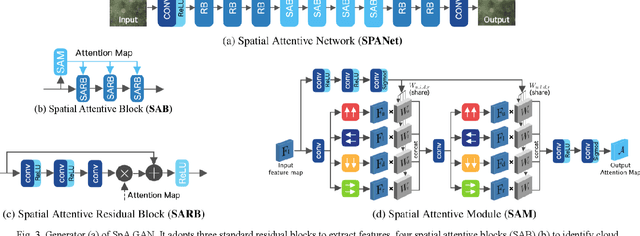

Optical remote sensing imagery has been widely used in many fields due to its high resolution and stable geometric properties. However, remote sensing imagery is inevitably affected by climate, especially clouds. Removing the cloud in the high-resolution remote sensing satellite image is an indispensable pre-processing step before analyzing it. For the sake of large-scale training data, neural networks have been successful in many image processing tasks, but the use of neural networks to remove cloud in remote sensing imagery is still relatively small. We adopt generative adversarial network to solve this task and introduce the spatial attention mechanism into the remote sensing imagery cloud removal task, proposes a model named spatial attention generative adversarial network (SpA GAN), which imitates the human visual mechanism, and recognizes and focuses the cloud area with local-to-global spatial attention, thereby enhancing the information recovery of these areas and generating cloudless images with better quality...
Model-based Iterative Restoration for Binary Document Image Compression with Dictionary Learning
Apr 24, 2017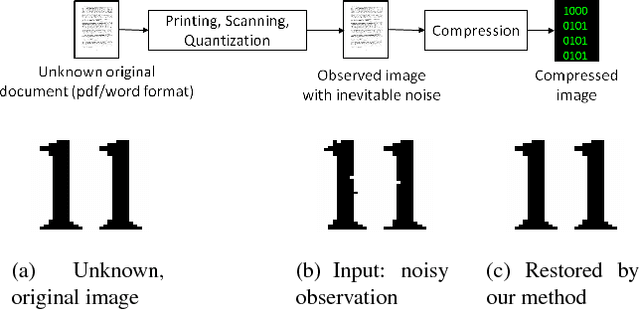

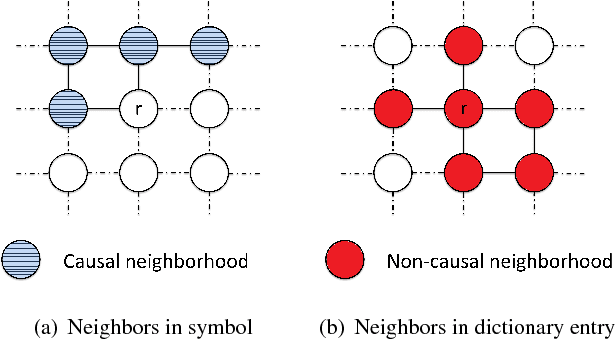
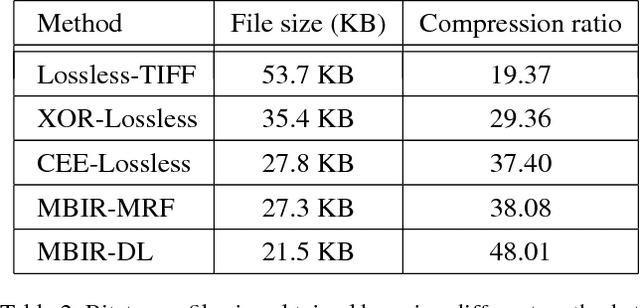
The inherent noise in the observed (e.g., scanned) binary document image degrades the image quality and harms the compression ratio through breaking the pattern repentance and adding entropy to the document images. In this paper, we design a cost function in Bayesian framework with dictionary learning. Minimizing our cost function produces a restored image which has better quality than that of the observed noisy image, and a dictionary for representing and encoding the image. After the restoration, we use this dictionary (from the same cost function) to encode the restored image following the symbol-dictionary framework by JBIG2 standard with the lossless mode. Experimental results with a variety of document images demonstrate that our method improves the image quality compared with the observed image, and simultaneously improves the compression ratio. For the test images with synthetic noise, our method reduces the number of flipped pixels by 48.2% and improves the compression ratio by 36.36% as compared with the best encoding methods. For the test images with real noise, our method visually improves the image quality, and outperforms the cutting-edge method by 28.27% in terms of the compression ratio.