 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Backdoor Attacks on the DNN Interpretation System
Dec 03, 2020
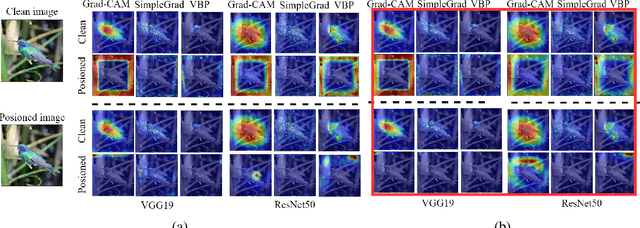
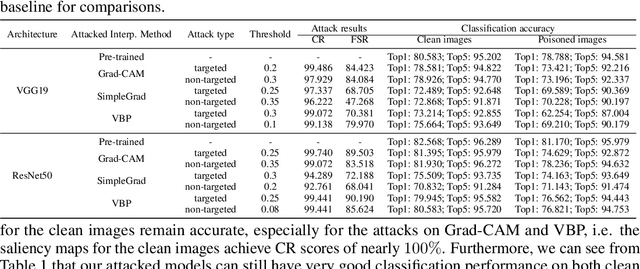
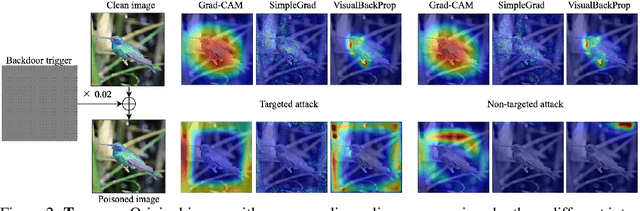
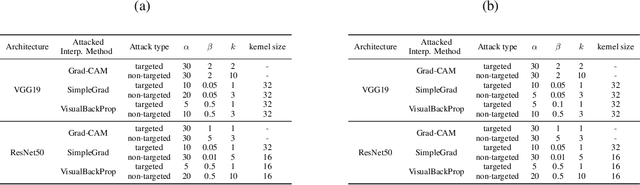
Interpretability is crucial to understand the inner workings of deep neural networks (DNNs) and many interpretation methods generate saliency maps that highlight parts of the input image that contribute the most to the prediction made by the DNN. In this paper we design a backdoor attack that alters the saliency map produced by the network for an input image only with injected trigger that is invisible to the naked eye while maintaining the prediction accuracy. The attack relies on injecting poisoned data with a trigger into the training data set. The saliency maps are incorporated in the penalty term of the objective function that is used to train a deep model and its influence on model training is conditioned upon the presence of a trigger. We design two types of attacks: targeted attack that enforces a specific modification of the saliency map and untargeted attack when the importance scores of the top pixels from the original saliency map are significantly reduced. We perform empirical evaluation of the proposed backdoor attacks on gradient-based and gradient-free interpretation methods for a variety of deep learning architectures. We show that our attacks constitute a serious security threat when deploying deep learning models developed by untrusty sources. Finally, in the Supplement we demonstrate that the proposed methodology can be used in an inverted setting, where the correct saliency map can be obtained only in the presence of a trigger (key), effectively making the interpretation system available only to selected users.
GIMP-ML: Python Plugins for using Computer Vision Models in GIMP
Apr 27, 2020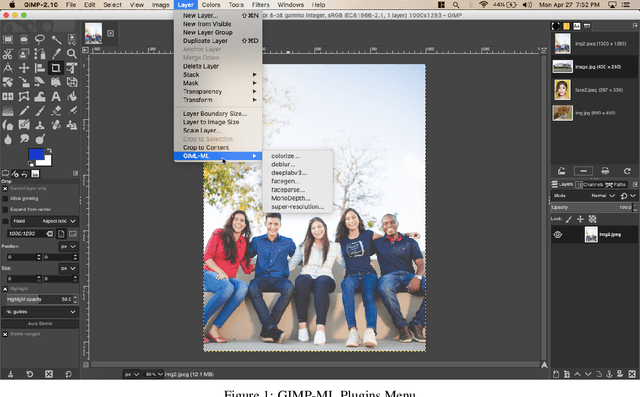
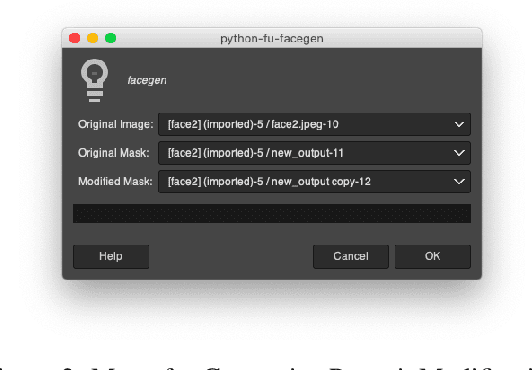
This paper introduces GIMP-ML, a set of Python plugins for the widely popular GNU Image Manipulation Program (GIMP). It enables the use of recent advances in computer vision to the conventional image editing pipeline in an open-source setting. Applications from deep learning such as monocular depth estimation, semantic segmentation, mask generative adversarial networks, image super-resolution, de-noising and coloring have been incorporated with GIMP through Python-based plugins. Additionally, operations on images such as edge detection and color clustering have also been added. GIMP-ML relies on standard Python packages such as numpy, scikit-image, pillow, pytorch, open-cv, scipy. Apart from these, several image manipulation techniques using these plugins have been compiled and demonstrated in the YouTube playlist (https://www.youtube.com/playlist?list=PLo9r5wFmpD5dLWTyo6NOiD6BJjhfEOM5t) with the objective of demonstrating the use-cases for machine learning based image modification. In addition, GIMP-ML also aims to bring the benefits of using deep learning networks used for computer vision tasks to routine image processing workflows. The code and installation procedure for configuring these plugins is available at https://github.com/kritiksoman/GIMP-ML.
Self-Labeling of Fully Mediating Representations by Graph Alignment
Mar 25, 2021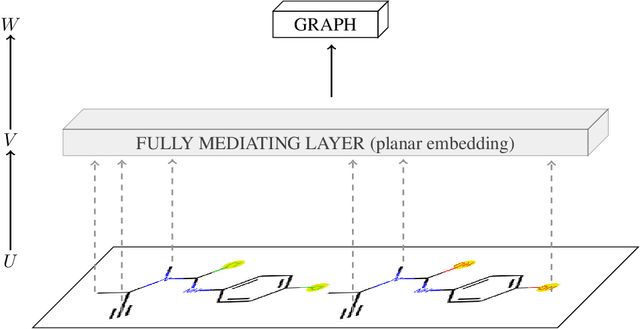

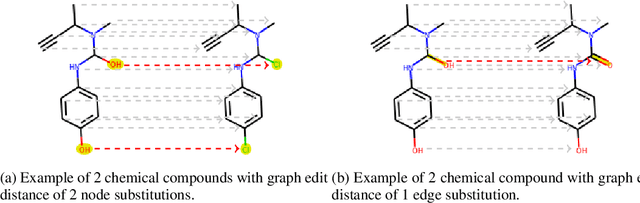
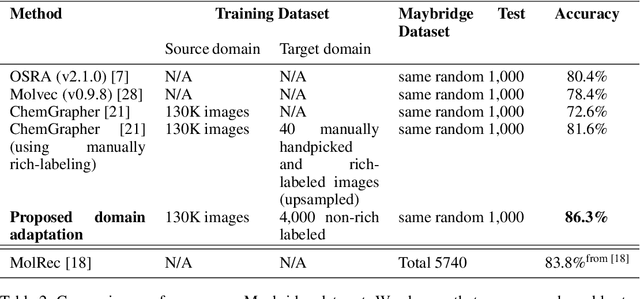
To be able to predict a molecular graph structure ($W$) given a 2D image of a chemical compound ($U$) is a challenging problem in machine learning. We are interested to learn $f: U \rightarrow W$ where we have a fully mediating representation $V$ such that $f$ factors into $U \rightarrow V \rightarrow W$. However, observing V requires detailed and expensive labels. We propose graph aligning approach that generates rich or detailed labels given normal labels $W$. In this paper we investigate the scenario of domain adaptation from the source domain where we have access to the expensive labels $V$ to the target domain where only normal labels W are available. Focusing on the problem of predicting chemical compound graphs from 2D images the fully mediating layer is represented using the planar embedding of the chemical graph structure we are predicting. The use of a fully mediating layer implies some assumptions on the mechanism of the underlying process. However if the assumptions are correct it should allow the machine learning model to be more interpretable, generalize better and be more data efficient at training time. The empirical results show that, using only 4000 data points, we obtain up to 4x improvement of performance after domain adaptation to target domain compared to pretrained model only on the source domain. After domain adaptation, the model is even able to detect atom types that were never seen in the original source domain. Finally, on the Maybridge data set the proposed self-labeling approach reached higher performance than the current state of the art.
Boosting of Image Denoising Algorithms
Mar 12, 2015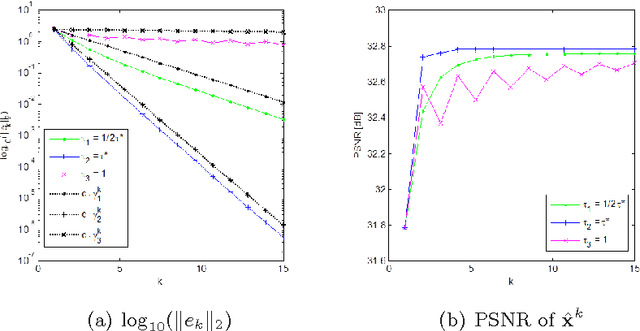


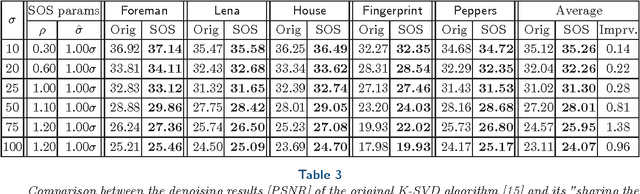
In this paper we propose a generic recursive algorithm for improving image denoising methods. Given the initial denoised image, we suggest repeating the following "SOS" procedure: (i) (S)trengthen the signal by adding the previous denoised image to the degraded input image, (ii) (O)perate the denoising method on the strengthened image, and (iii) (S)ubtract the previous denoised image from the restored signal-strengthened outcome. The convergence of this process is studied for the K-SVD image denoising and related algorithms. Still in the context of K-SVD image denoising, we introduce an interesting interpretation of the SOS algorithm as a technique for closing the gap between the local patch-modeling and the global restoration task, thereby leading to improved performance. In a quest for the theoretical origin of the SOS algorithm, we provide a graph-based interpretation of our method, where the SOS recursive update effectively minimizes a penalty function that aims to denoise the image, while being regularized by the graph Laplacian. We demonstrate the SOS boosting algorithm for several leading denoising methods (K-SVD, NLM, BM3D, and EPLL), showing tendency to further improve denoising performance.
Deep Learning based Inter-Modality Image Registration Supervised by Intra-Modality Similarity
Apr 28, 2018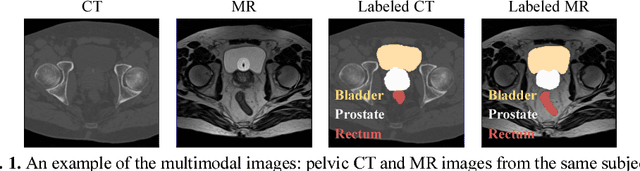
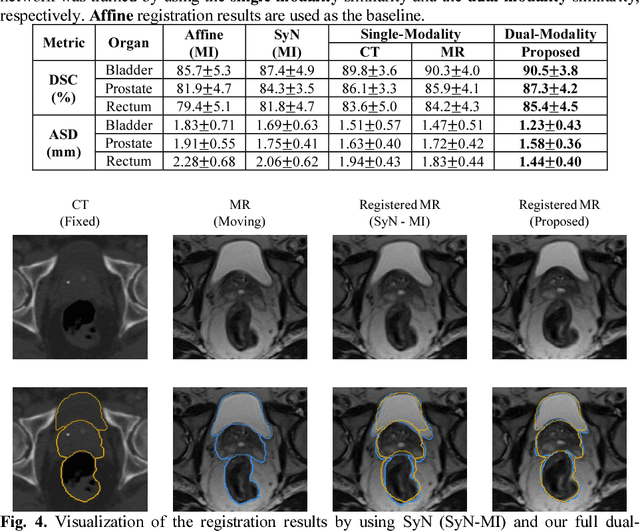

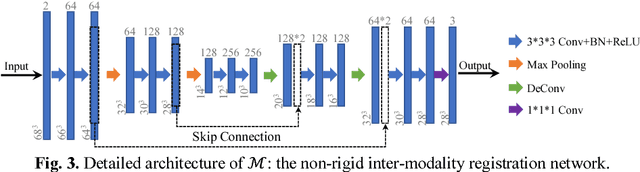
Non-rigid inter-modality registration can facilitate accurate information fusion from different modalities, but it is challenging due to the very different image appearances across modalities. In this paper, we propose to train a non-rigid inter-modality image registration network, which can directly predict the transformation field from the input multimodal images, such as CT and MR images. In particular, the training of our inter-modality registration network is supervised by intra-modality similarity metric based on the available paired data, which is derived from a pre-aligned CT and MR dataset. Specifically, in the training stage, to register the input CT and MR images, their similarity is evaluated on the warped MR image and the MR image that is paired with the input CT. So that, the intra-modality similarity metric can be directly applied to measure whether the input CT and MR images are well registered. Moreover, we use the idea of dual-modality fashion, in which we measure the similarity on both CT modality and MR modality. In this way, the complementary anatomies in both modalities can be jointly considered to more accurately train the inter-modality registration network. In the testing stage, the trained inter-modality registration network can be directly applied to register the new multimodal images without any paired data. Experimental results have shown that, the proposed method can achieve promising accuracy and efficiency for the challenging non-rigid inter-modality registration task and also outperforms the state-of-the-art approaches.
Automatic Test Suite Generation for Key-points Detection DNNs Using Many-Objective Search
Dec 11, 2020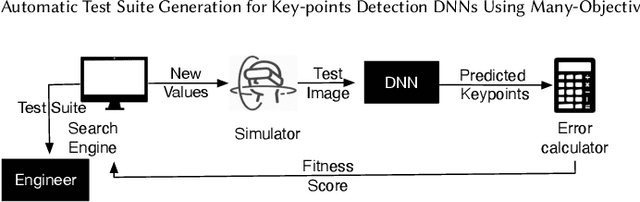
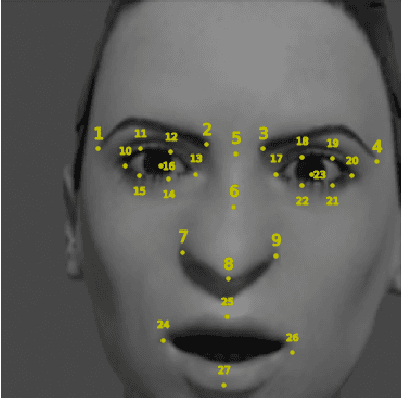

Automatically detecting the positions of key-points (e.g., facial key-points or finger key-points) in an image is an essential problem in many applications, such as driver's gaze detection and drowsiness detection in automated driving systems. With the recent advances of Deep Neural Networks (DNNs), Key-Points detection DNNs (KP-DNNs) have been increasingly employed for that purpose. Nevertheless, KP-DNN testing and validation have remained a challenging problem because KP-DNNs predict many independent key-points at the same time -- where each individual key-point may be critical in the targeted application -- and images can vary a great deal according to many factors. In this paper, we present an approach to automatically generate test data for KP-DNNs using many-objective search. In our experiments, focused on facial key-points detection DNNs developed for an industrial automotive application, we show that our approach can generate test suites to severely mispredict, on average, more than 93% of all key-points. In comparison, random search-based test data generation can only severely mispredict 41% of them. Many of these mispredictions, however, are not avoidable and should not therefore be considered failures. We also empirically compare state-of-the-art, many-objective search algorithms and their variants, tailored for test suite generation. Furthermore, we investigate and demonstrate how to learn specific conditions, based on image characteristics (e.g., head posture and skin color), that lead to severe mispredictions. Such conditions serve as a basis for risk analysis or DNN retraining.
Space-Time Crop & Attend: Improving Cross-modal Video Representation Learning
Mar 18, 2021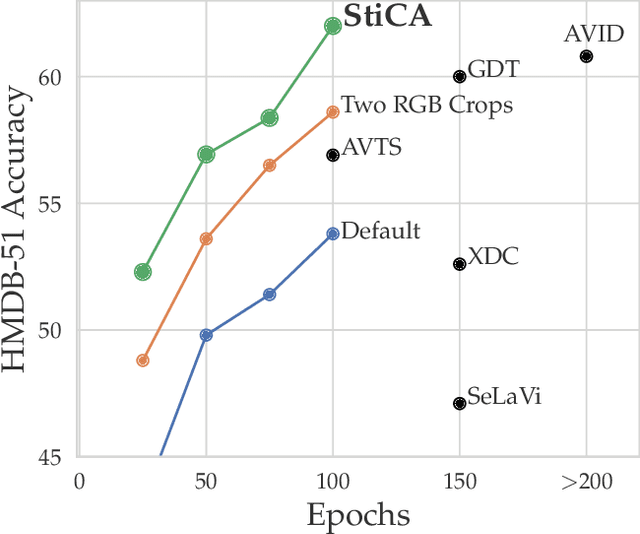
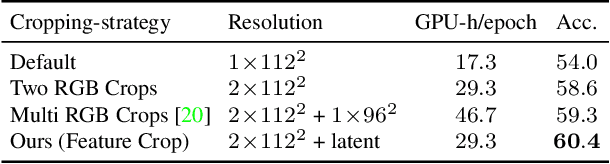
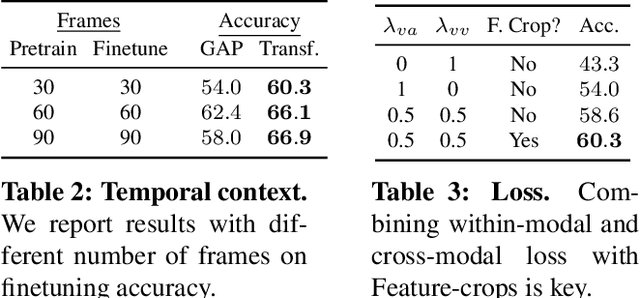
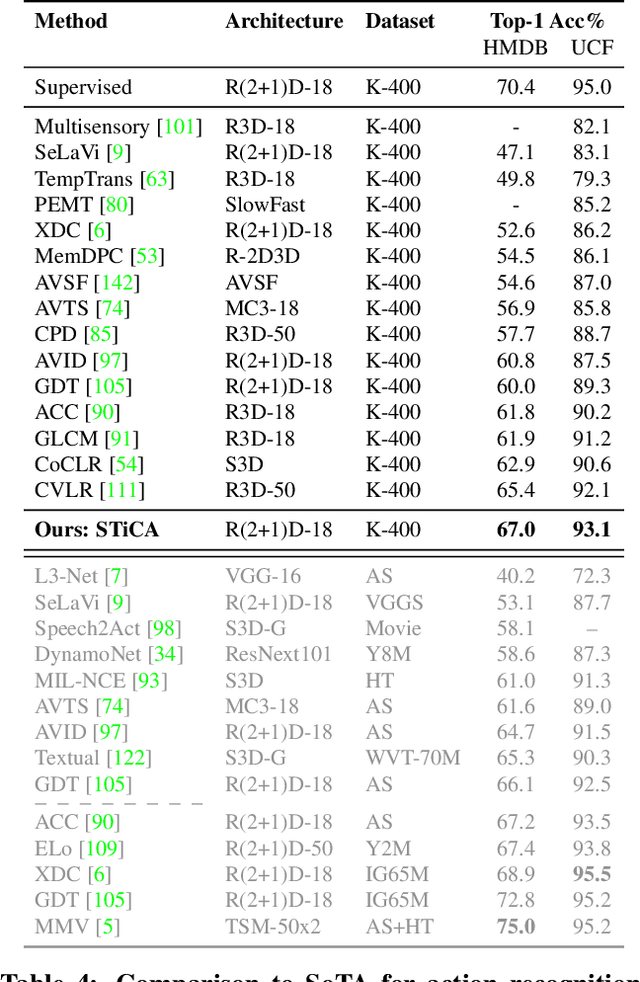
The quality of the image representations obtained from self-supervised learning depends strongly on the type of data augmentations used in the learning formulation. Recent papers have ported these methods from still images to videos and found that leveraging both audio and video signals yields strong gains; however, they did not find that spatial augmentations such as cropping, which are very important for still images, work as well for videos. In this paper, we improve these formulations in two ways unique to the spatio-temporal aspect of videos. First, for space, we show that spatial augmentations such as cropping do work well for videos too, but that previous implementations, due to the high processing and memory cost, could not do this at a scale sufficient for it to work well. To address this issue, we first introduce Feature Crop, a method to simulate such augmentations much more efficiently directly in feature space. Second, we show that as opposed to naive average pooling, the use of transformer-based attention improves performance significantly, and is well suited for processing feature crops. Combining both of our discoveries into a new method, Space-time Crop & Attend (STiCA) we achieve state-of-the-art performance across multiple video-representation learning benchmarks. In particular, we achieve new state-of-the-art accuracies of 67.0% on HMDB-51 and 93.1% on UCF-101 when pre-training on Kinetics-400.
Bayesian Imaging With Data-Driven Priors Encoded by Neural Networks: Theory, Methods, and Algorithms
Mar 18, 2021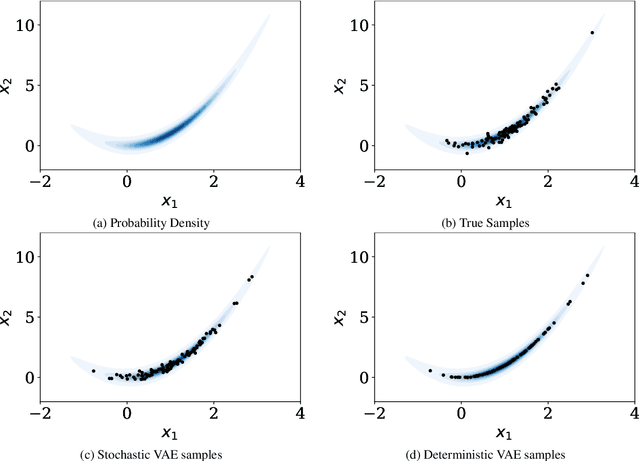

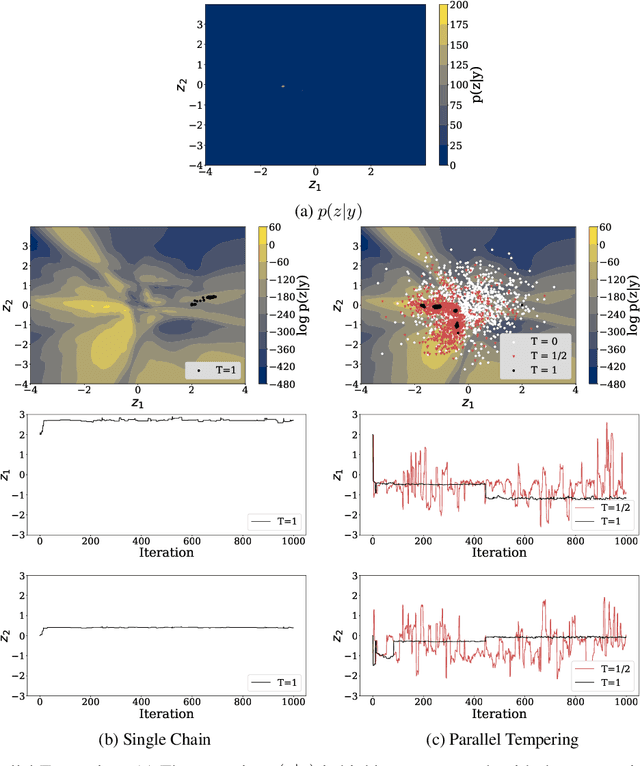
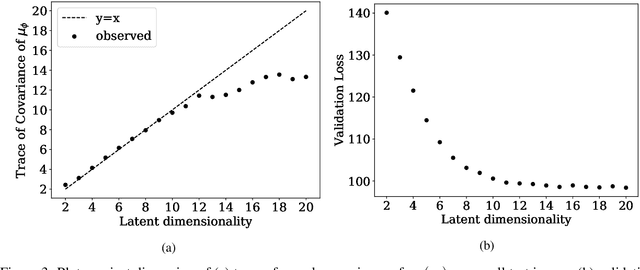
This paper proposes a new methodology for performing Bayesian inference in imaging inverse problems where the prior knowledge is available in the form of training data. Following the manifold hypothesis and adopting a generative modelling approach, we construct a data-driven prior that is supported on a sub-manifold of the ambient space, which we can learn from the training data by using a variational autoencoder or a generative adversarial network. We establish the existence and well-posedness of the associated posterior distribution and posterior moments under easily verifiable conditions, providing a rigorous underpinning for Bayesian estimators and uncertainty quantification analyses. Bayesian computation is performed by using a parallel tempered version of the preconditioned Crank-Nicolson algorithm on the manifold, which is shown to be ergodic and robust to the non-convex nature of these data-driven models. In addition to point estimators and uncertainty quantification analyses, we derive a model misspecification test to automatically detect situations where the data-driven prior is unreliable, and explain how to identify the dimension of the latent space directly from the training data. The proposed approach is illustrated with a range of experiments with the MNIST dataset, where it outperforms alternative image reconstruction approaches from the state of the art. A model accuracy analysis suggests that the Bayesian probabilities reported by the data-driven models are also remarkably accurate under a frequentist definition of probability.
The ND-IRIS-0405 Iris Image Dataset
Jun 15, 2016
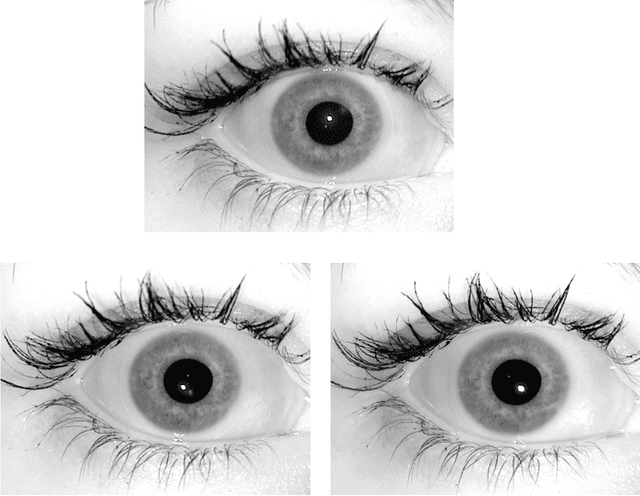
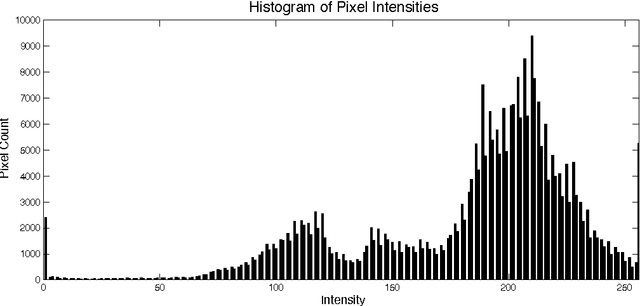
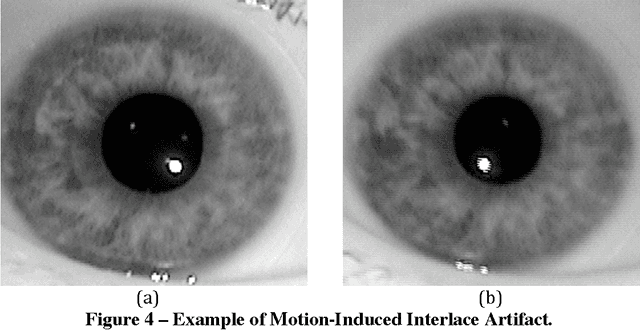
The Computer Vision Research Lab at the University of Notre Dame began collecting iris images in the spring semester of 2004. The initial data collections used an LG 2200 iris imaging system for image acquisition. Image datasets acquired in 2004-2005 at Notre Dame with this LG 2200 have been used in the ICE 2005 and ICE 2006 iris biometric evaluations. The ICE 2005 iris image dataset has been distributed to over 100 research groups around the world. The purpose of this document is to describe the content of the ND-IRIS-0405 iris image dataset. This dataset is a superset of the iris image datasets used in ICE 2005 and ICE 2006. The ND 2004-2005 iris image dataset contains 64,980 images corresponding to 356 unique subjects, and 712 unique irises. The age range of the subjects is 18 to 75 years old. 158 of the subjects are female, and 198 are male. 250 of the subjects are Caucasian, 82 are Asian, and 24 are other ethnicities.
NL-CNN: A Resources-Constrained Deep Learning Model based on Nonlinear Convolution
Jan 30, 2021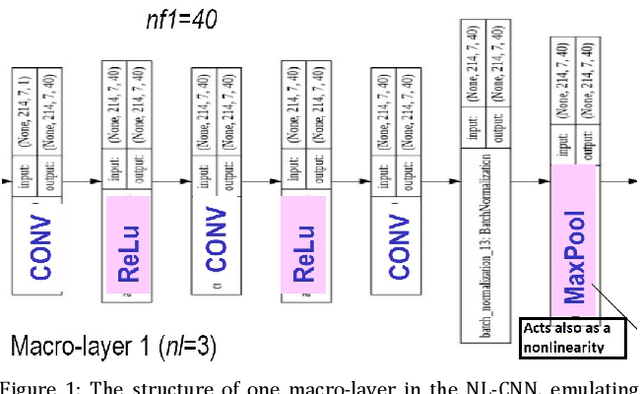
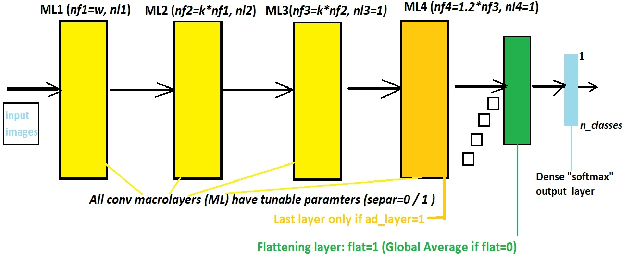

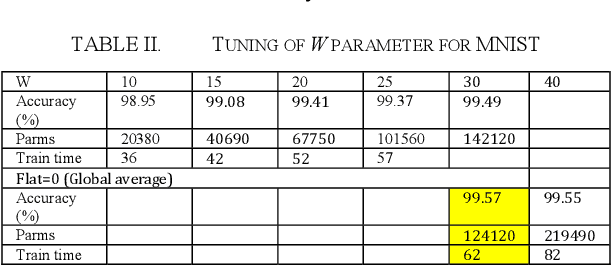
A novel convolution neural network model, abbreviated NL-CNN is proposed, where nonlinear convolution is emulated in a cascade of convolution + nonlinearity layers. The code for its implementation and some trained models are made publicly available. Performance evaluation for several widely known datasets is provided, showing several relevant features: i) for small / medium input image sizes the proposed network gives very good testing accuracy, given a low implementation complexity and model size; ii) compares favorably with other widely known resources-constrained models, for instance in comparison to MobileNetv2 provides better accuracy with several times less training times and up to ten times less parameters (memory occupied by the model); iii) has a relevant set of hyper-parameters which can be easily and rapidly tuned due to the fast training specific to it. All these features make NL-CNN suitable for IoT, smart sensing, bio-medical portable instrumentation and other applications where artificial intelligence must be deployed in energy-constrained environments.