 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CreativeGAN: Editing Generative Adversarial Networks for Creative Design Synthesis
Mar 10, 2021
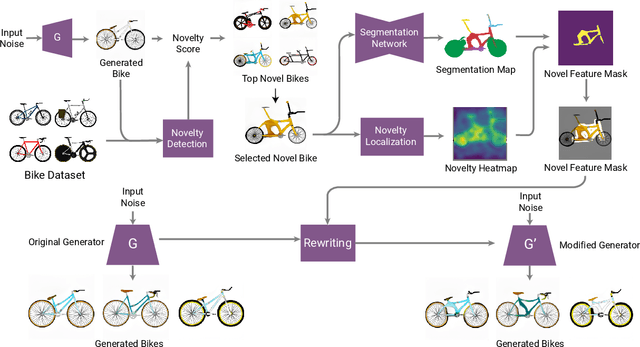
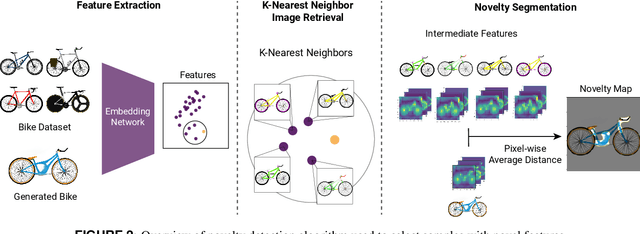
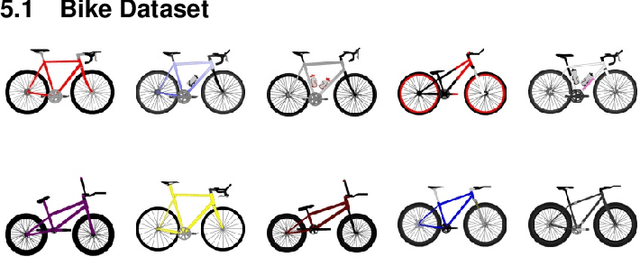

Modern machine learning techniques, such as deep neural networks, are transforming many disciplines ranging from image recognition to language understanding, by uncovering patterns in big data and making accurate predictions. They have also shown promising results for synthesizing new designs, which is crucial for creating products and enabling innovation. Generative models, including generative adversarial networks (GANs), have proven to be effective for design synthesis with applications ranging from product design to metamaterial design. These automated computational design methods can support human designers, who typically create designs by a time-consuming process of iteratively exploring ideas using experience and heuristics. However, there are still challenges remaining in automatically synthesizing `creative' designs. GAN models, however, are not capable of generating unique designs, a key to innovation and a major gap in AI-based design automation applications. This paper proposes an automated method, named CreativeGAN, for generating novel designs. It does so by identifying components that make a design unique and modifying a GAN model such that it becomes more likely to generate designs with identified unique components. The method combines state-of-art novelty detection, segmentation, novelty localization, rewriting, and generative models for creative design synthesis. Using a dataset of bicycle designs, we demonstrate that the method can create new bicycle designs with unique frames and handles, and generalize rare novelties to a broad set of designs. Our automated method requires no human intervention and demonstrates a way to rethink creative design synthesis and exploration.
Transforming Neural Network Visual Representations to Predict Human Judgments of Similarity
Oct 13, 2020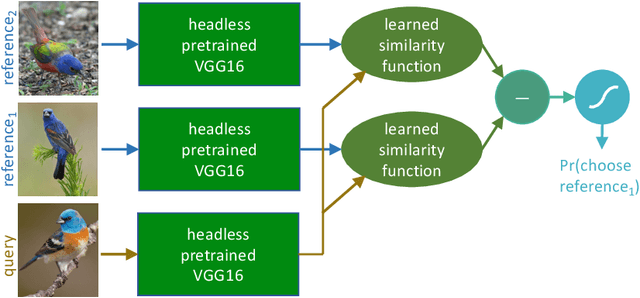
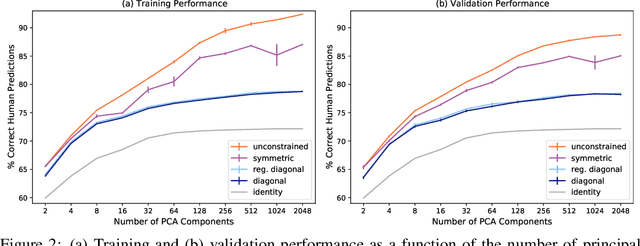
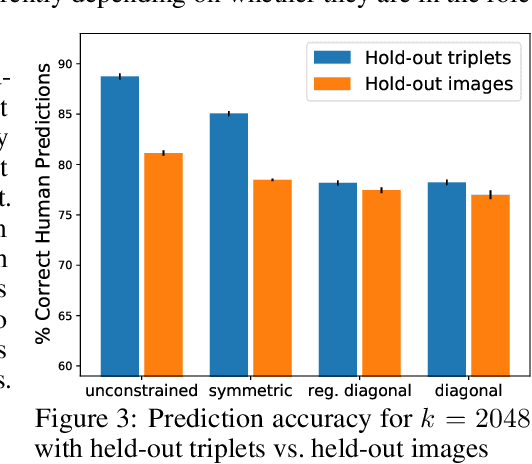
Deep-learning vision models have shown intriguing similarities and differences with respect to human vision. We investigate how to bring machine visual representations into better alignment with human representations. Human representations are often inferred from behavioral evidence such as the selection of an image most similar to a query image. We find that with appropriate linear transformations of deep embeddings, we can improve prediction of human binary choice on a data set of bird images from 72% at baseline to 89%. We hypothesized that deep embeddings have redundant, high (4096) dimensional representations; however, reducing the rank of these representations results in a loss of explanatory power. We hypothesized that the dilation transformation of representations explored in past research is too restrictive, and indeed we found that model explanatory power can be significantly improved with a more expressive linear transform. Most surprising and exciting, we found that, consistent with classic psychological literature, human similarity judgments are asymmetric: the similarity of X to Y is not necessarily equal to the similarity of Y to X, and allowing models to express this asymmetry improves explanatory power.
Confidence from Invariance to Image Transformations
Apr 02, 2018
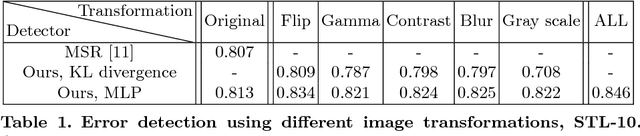

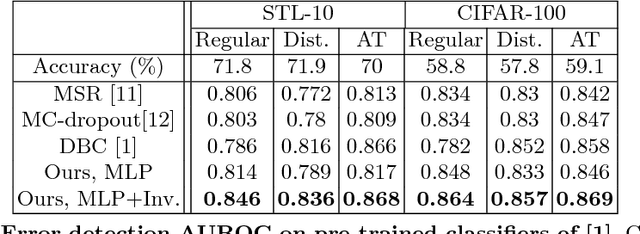
We develop a technique for automatically detecting the classification errors of a pre-trained visual classifier. Our method is agnostic to the form of the classifier, requiring access only to classifier responses to a set of inputs. We train a parametric binary classifier (error/correct) on a representation derived from a set of classifier responses generated from multiple copies of the same input, each subject to a different natural image transformation. Thus, we establish a measure of confidence in classifier's decision by analyzing the invariance of its decision under various transformations. In experiments with multiple data sets (STL-10,CIFAR-100,ImageNet) and classifiers, we demonstrate new state of the art for the error detection task. In addition, we apply our technique to novelty detection scenarios, where we also demonstrate state of the art results.
Machine learning methods for histopathological image analysis
Dec 03, 2017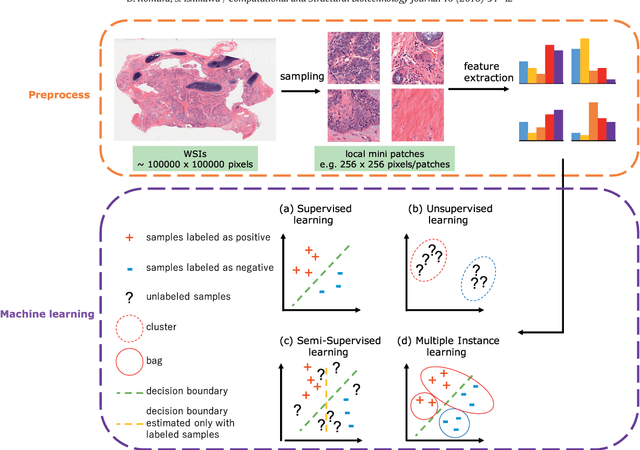

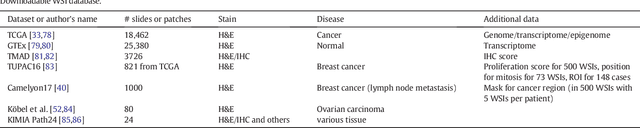
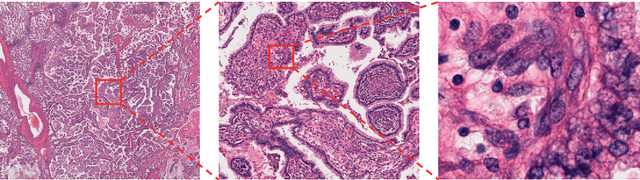
Abundant accumulation of digital histopathological images has led to the increased demand for their analysis, such as computer-aided diagnosis using machine learning techniques. However, digital pathological images and related tasks have some issues to be considered. In this mini-review, we introduce the application of digital pathological image analysis using machine learning algorithms, address some problems specific to such analysis, and propose possible solutions.
On the Effectiveness of Image Rotation for Open Set Domain Adaptation
Jul 24, 2020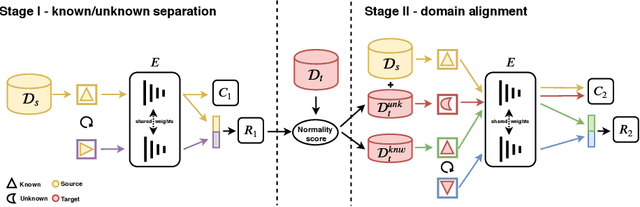
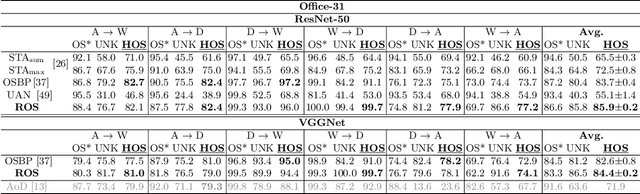

Open Set Domain Adaptation (OSDA) bridges the domain gap between a labeled source domain and an unlabeled target domain, while also rejecting target classes that are not present in the source. To avoid negative transfer, OSDA can be tackled by first separating the known/unknown target samples and then aligning known target samples with the source data. We propose a novel method to addresses both these problems using the self-supervised task of rotation recognition. Moreover, we assess the performance with a new open set metric that properly balances the contribution of recognizing the known classes and rejecting the unknown samples. Comparative experiments with existing OSDA methods on the standard Office-31 and Office-Home benchmarks show that: (i) our method outperforms its competitors, (ii) reproducibility for this field is a crucial issue to tackle, (iii) our metric provides a reliable tool to allow fair open set evaluation.
Audio-Visual Self-Supervised Terrain Type Discovery for Mobile Platforms
Oct 13, 2020
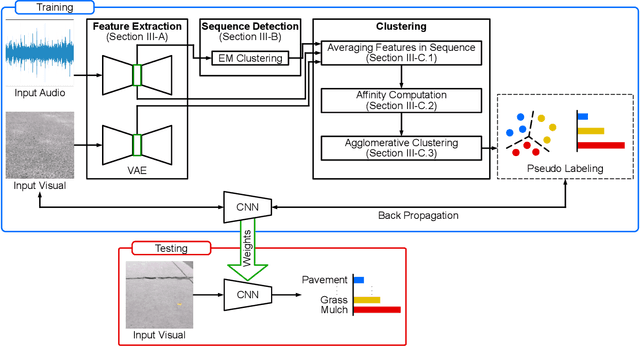
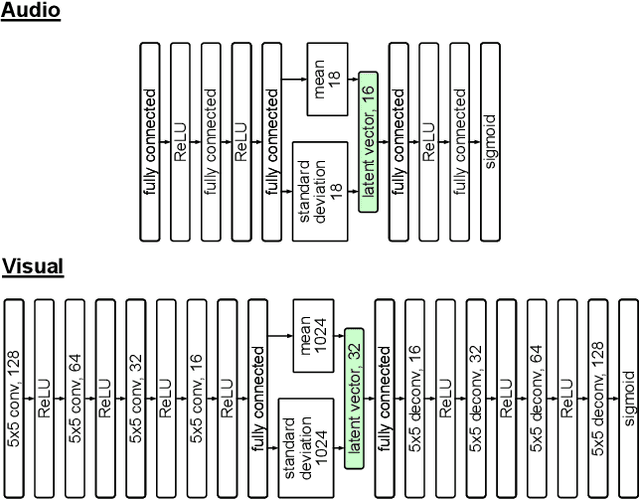

The ability to both recognize and discover terrain characteristics is an important function required for many autonomous ground robots such as social robots, assistive robots, autonomous vehicles, and ground exploration robots. Recognizing and discovering terrain characteristics is challenging because similar terrains may have very different appearances (e.g., carpet comes in many colors), while terrains with very similar appearance may have very different physical properties (e.g. mulch versus dirt). In order to address the inherent ambiguity in vision-based terrain recognition and discovery, we propose a multi-modal self-supervised learning technique that switches between audio features extracted from a mic attached to the underside of a mobile platform and image features extracted by a camera on the platform to cluster terrain types. The terrain cluster labels are then used to train an image-based convolutional neural network to predict changes in terrain types. Through experiments, we demonstrate that the proposed self-supervised terrain type discovery method achieves over 80% accuracy, which greatly outperforms several baselines and suggests strong potential for assistive applications.
Scalable Deep Compressive Sensing
Jan 22, 2021
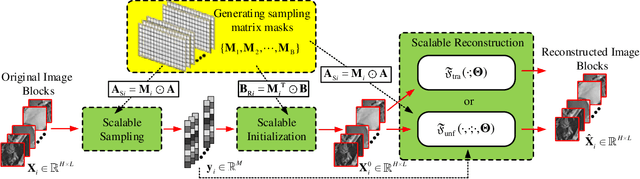
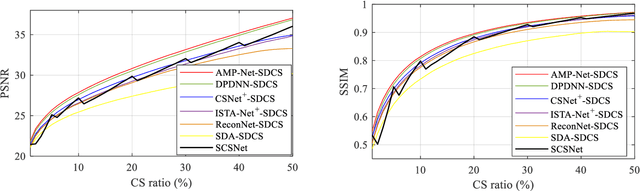
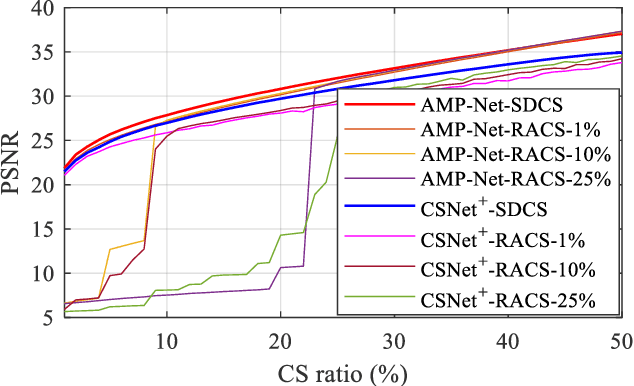
Deep learning has been used to image compressive sensing (CS) for enhanced reconstruction performance. However, most existing deep learning methods train different models for different subsampling ratios, which brings additional hardware burden. In this paper, we develop a general framework named scalable deep compressive sensing (SDCS) for the scalable sampling and reconstruction (SSR) of all existing end-to-end-trained models. In the proposed way, images are measured and initialized linearly. Two sampling masks are introduced to flexibly control the subsampling ratios used in sampling and reconstruction, respectively. To make the reconstruction model adapt to any subsampling ratio, a training strategy dubbed scalable training is developed. In scalable training, the model is trained with the sampling matrix and the initialization matrix at various subsampling ratios by integrating different sampling matrix masks. Experimental results show that models with SDCS can achieve SSR without changing their structure while maintaining good performance, and SDCS outperforms other SSR methods.
Reversible Image Merging for Low-level Machine Vision
Apr 13, 2016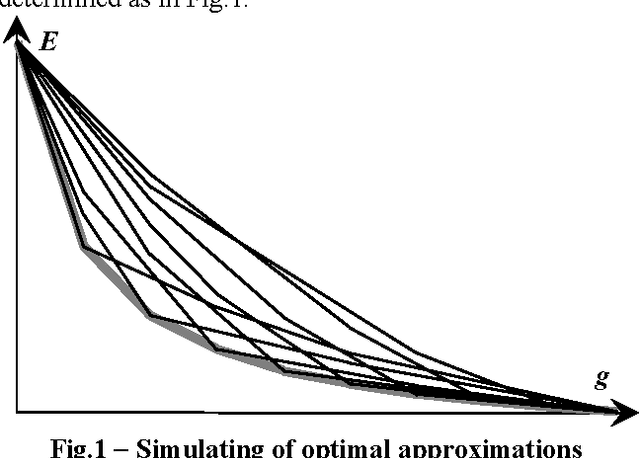

In this paper a hierarchical model for pixel clustering and image segmentation is developed. In the model an image is hierarchically structured. The original image is treated as a set of nested images, which are capable to reversibly merge with each other. An object is defined as a structural element of an image, so that, an image is regarded as a maximal object. The simulating of none-hierarchical optimal pixel clustering by hierarchical clustering is studied. To generate a hierarchy of optimized piecewise constant image approximations, estimated by the standard deviation of approximation from the image, the conversion of any hierarchy of approximations into the hierarchy described in relation to the number of intensity levels by convex sequence of total squared errors is proposed.
* 5 pages, 3 figures, 6 formulas, submitted to the 13th International Conference on Pattern Recognition and Information Processing October 3-5, 2016, Minsk, Belarus
DT-Net: A novel network based on multi-directional integrated convolution and threshold convolution
Sep 26, 2020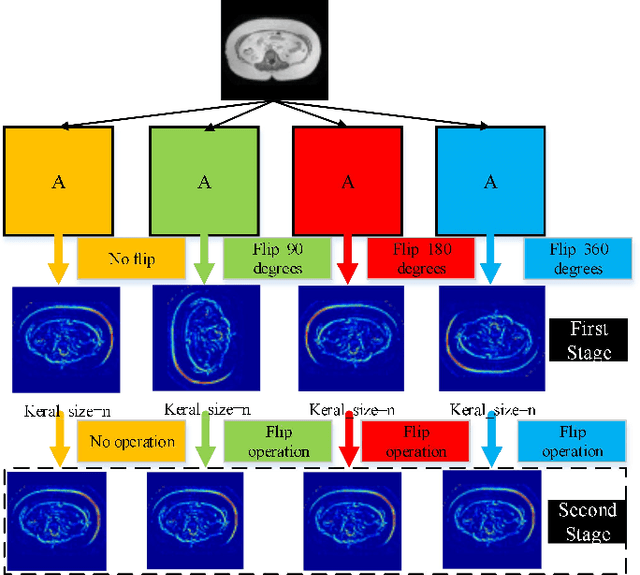
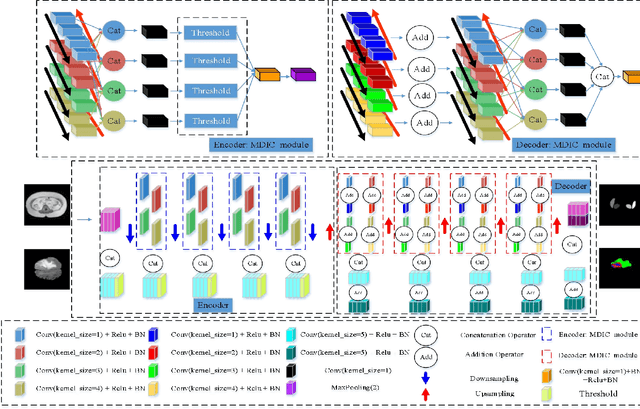
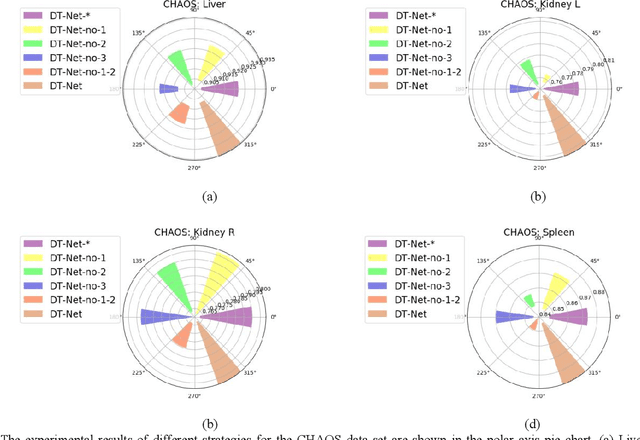
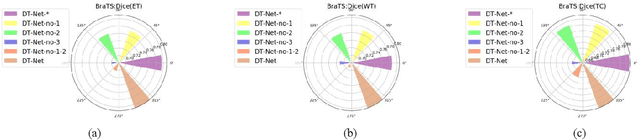
Since medical image data sets contain few samples and singular features, lesions are viewed as highly similar to other tissues. The traditional neural network has a limited ability to learn features. Even if a host of feature maps is expanded to obtain more semantic information, the accuracy of segmenting the final medical image is slightly improved, and the features are excessively redundant. To solve the above problems, in this paper, we propose a novel end-to-end semantic segmentation algorithm, DT-Net, and use two new convolution strategies to better achieve end-to-end semantic segmentation of medical images. 1. In the feature mining and feature fusion stage, we construct a multi-directional integrated convolution (MDIC). The core idea is to use the multi-scale convolution to enhance the local multi-directional feature maps to generate enhanced feature maps and to mine the generated features that contain more semantics without increasing the number of feature maps. 2. We also aim to further excavate and retain more meaningful deep features reduce a host of noise features in the training process. Therefore, we propose a convolution thresholding strategy. The central idea is to set a threshold to eliminate a large number of redundant features and reduce computational complexity. Through the two strategies proposed above, the algorithm proposed in this paper produces state-of-the-art results on two public medical image datasets. We prove in detail that our proposed strategy plays an important role in feature mining and eliminating redundant features. Compared with the existing semantic segmentation algorithms, our proposed algorithm has better robustness.
Deep Learning Fundus Image Analysis for Diabetic Retinopathy and Macular Edema Grading
Apr 16, 2019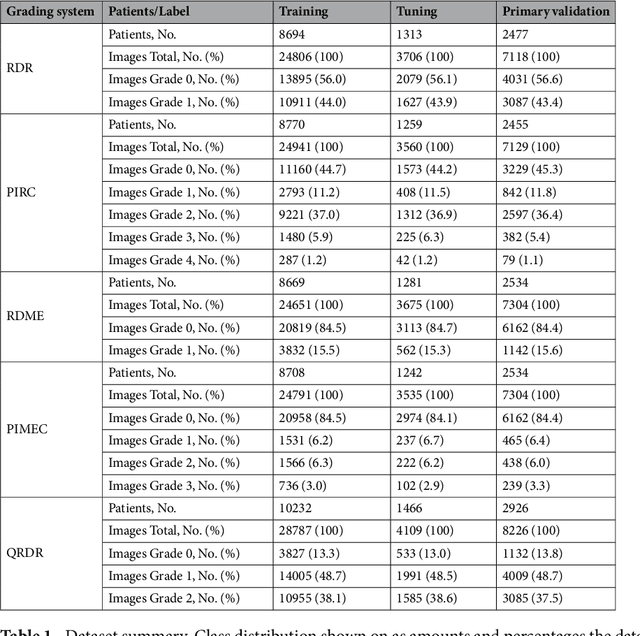
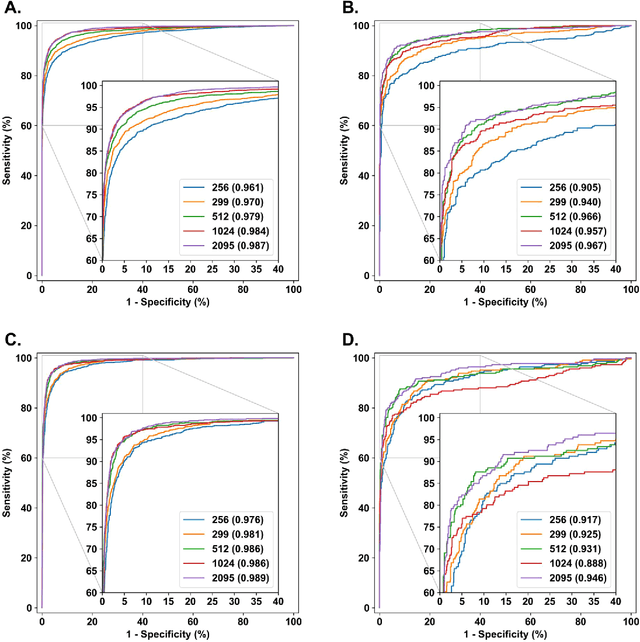
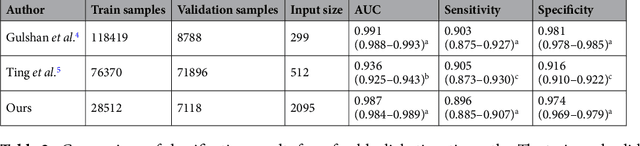
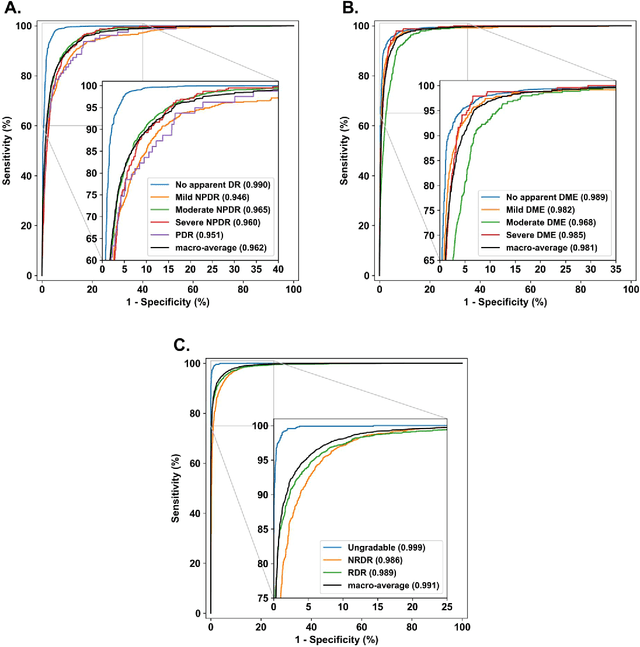
Diabetes is a globally prevalent disease that can cause visible microvascular complications such as diabetic retinopathy and macular edema in the human eye retina, the images of which are today used for manual disease screening. This labor-intensive task could greatly benefit from automatic detection using deep learning technique. Here we present a deep learning system that identifies referable diabetic retinopathy comparably or better than presented in the previous studies, although we use only a small fraction of images (<1/4) in training but are aided with higher image resolutions. We also provide novel results for five different screening and clinical grading systems for diabetic retinopathy and macular edema classification, including results for accurately classifying images according to clinical five-grade diabetic retinopathy and four-grade diabetic macular edema scales. These results suggest, that a deep learning system could increase the cost-effectiveness of screening while attaining higher than recommended performance, and that the system could be applied in clinical examinations requiring finer grading.