 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Prediction of neonatal mortality in Sub-Saharan African countries using data-level linkage of multiple surveys
Nov 25, 2020
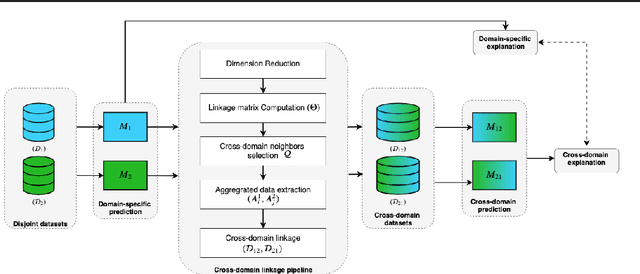
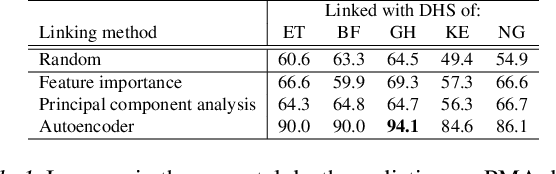
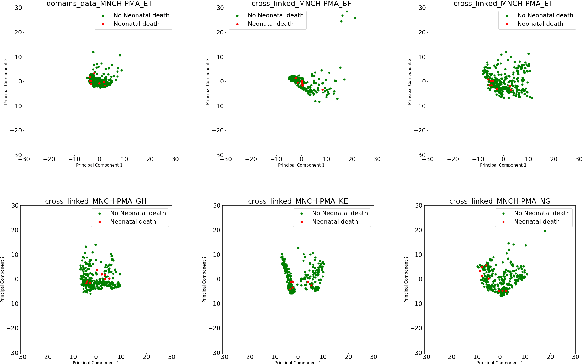
Existing datasets available to address crucial problems, such as child mortality and family planning discontinuation in developing countries, are not ample for data-driven approaches. This is partly due to disjoint data collection efforts employed across locations, times, and variations of modalities. On the other hand, state-of-the-art methods for small data problem are confined to image modalities. In this work, we proposed a data-level linkage of disjoint surveys across Sub-Saharan African countries to improve prediction performance of neonatal death and provide cross-domain explainability.
Defense-friendly Images in Adversarial Attacks: Dataset and Metrics forPerturbation Difficulty
Nov 05, 2020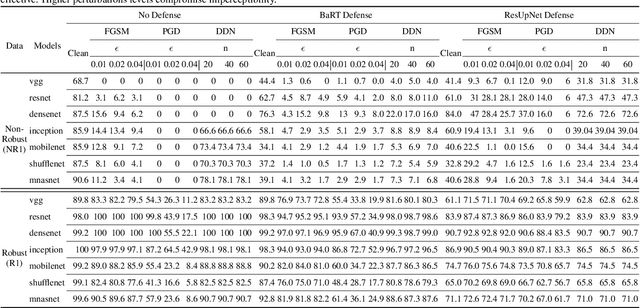
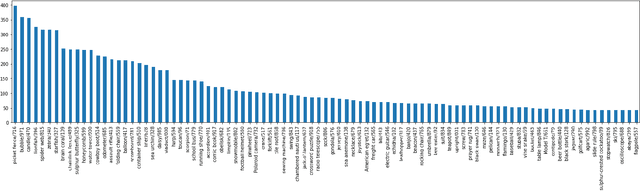
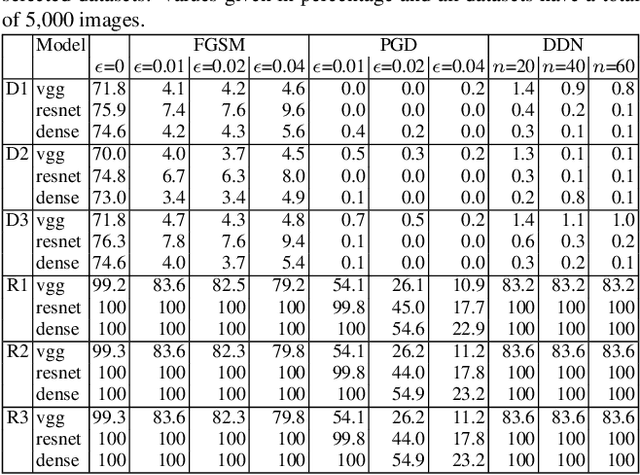

Dataset bias is a problem in adversarial machine learn-ing, especially in the evaluation of defenses. An adversarial attack or defense algorithm may show better results on the reported dataset than can be replicated on other datasets.Even when two algorithms are compared, their relative performance can vary depending on the dataset. Deep learn-ing offers state-of-the-art solutions for image recognition, but deep models are vulnerable even to small perturbations.Research in this area focuses primarily on adversarial at-tacks and defense algorithms. In this paper, we report for the first time, a class of robust images that are both resilient to attacks and that recover better than random images un-der adversarial attacks using simple defense techniques.Thus, a test dataset with a high proportion of robust images gives a misleading impression about the performance of an adversarial attack or defense. We propose three metrics to determine the proportion of robust images in a dataset and provide scoring to determine the dataset bias. We also pro-vide an ImageNet-R dataset of 15000+ robust images to facilitate further research on this intriguing phenomenon of image strength under attack. Our dataset, combined with the proposed metrics, is valuable for unbiased benchmark-ing of adversarial attack and defense algorithms
Do Generative Models Know Disentanglement? Contrastive Learning is All You Need
Feb 21, 2021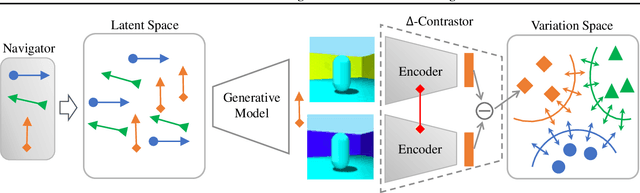
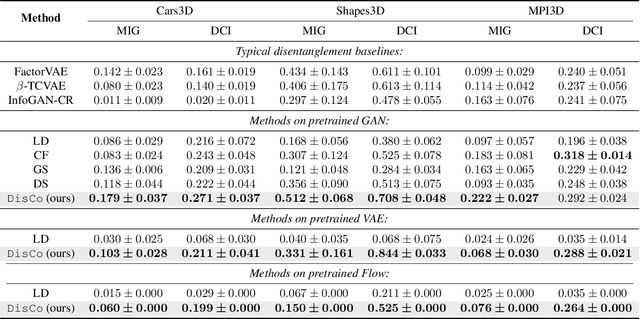
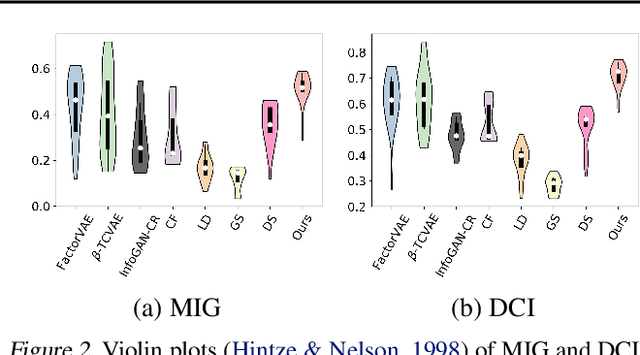
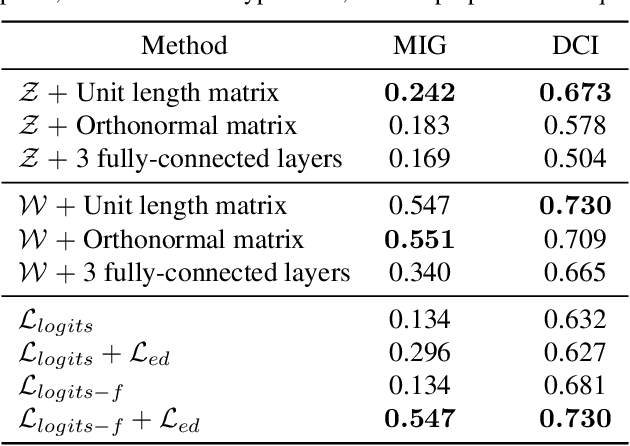
Disentangled generative models are typically trained with an extra regularization term, which encourages the traversal of each latent factor to make a distinct and independent change at the cost of generation quality. When traversing the latent space of generative models trained without the disentanglement term, the generated samples show semantically meaningful change, raising the question: do generative models know disentanglement? We propose an unsupervised and model-agnostic method: Disentanglement via Contrast (DisCo) in the Variation Space. DisCo consists of: (i) a Navigator providing traversal directions in the latent space, and (ii) a $\Delta$-Contrastor composed of two shared-weight Encoders, which encode image pairs along these directions to disentangled representations respectively, and a difference operator to map the encoded representations to the Variation Space. We propose two more key techniques for DisCo: entropy-based domination loss to make the encoded representations more disentangled and the strategy of flipping hard negatives to address directions with the same semantic meaning. By optimizing the Navigator to discover disentangled directions in the latent space and Encoders to extract disentangled representations from images with Contrastive Learning, DisCo achieves the state-of-the-art disentanglement given pretrained non-disentangled generative models, including GAN, VAE, and Flow. Project page at https://github.com/xrenaa/DisCo.
Structure-Aware Completion of Photogrammetric Meshes in Urban Road Environment
Nov 24, 2020

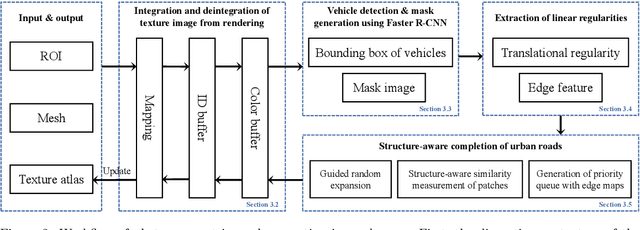

Photogrammetric mesh models obtained from aerial oblique images have been widely used for urban reconstruction. However, the photogrammetric meshes also suffer from severe texture problems, especially on the road areas due to occlusion. This paper proposes a structure-aware completion approach to improve the quality of meshes by removing undesired vehicles on the road seamlessly. Specifically, the discontinuous texture atlas is first integrated to a continuous screen space through rendering by the graphics pipeline; the rendering also records necessary mapping for deintegration to the original texture atlas after editing. Vehicle regions are masked by a standard object detection approach, e.g. Faster RCNN. Then, the masked regions are completed guided by the linear structures and regularities in the road region, which is implemented based on Patch Match. Finally, the completed rendered image is deintegrated to the original texture atlas and the triangles for the vehicles are also flattened for improved meshes. Experimental evaluations and analyses are conducted against three datasets, which are captured with different sensors and ground sample distances. The results reveal that the proposed method can quite realistic meshes after removing the vehicles. The structure-aware completion approach for road regions outperforms popular image completion methods and ablation study further confirms the effectiveness of the linear guidance. It should be noted that the proposed method is also capable to handle tiled mesh models for large-scale scenes. Dataset and code are available at vrlab.org.cn/~hanhu/projects/mesh.
Local Sparse Approximation for Image Restoration with Adaptive Block Size Selection
Dec 20, 2016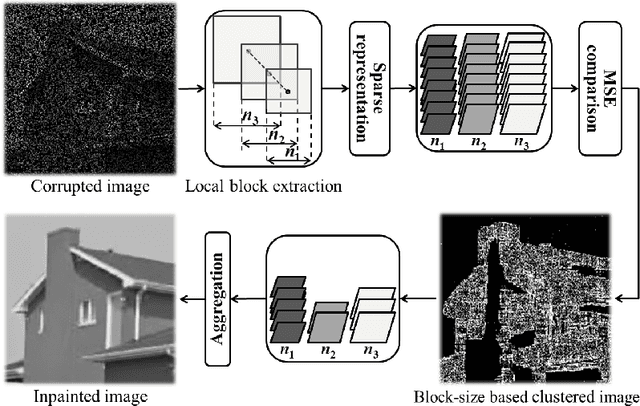
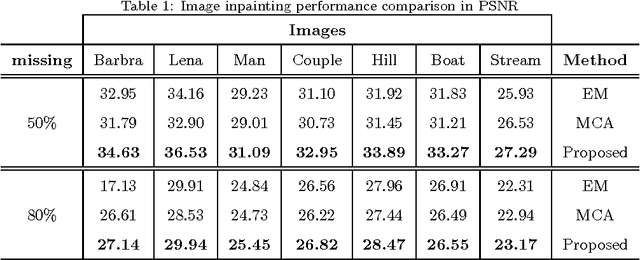

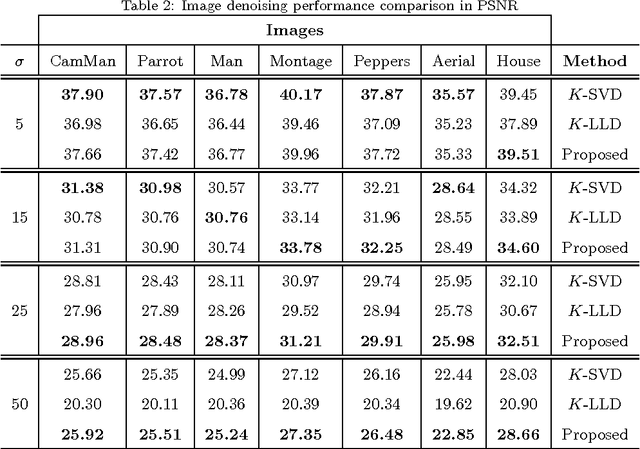
In this paper the problem of image restoration (denoising and inpainting) is approached using sparse approximation of local image blocks. The local image blocks are extracted by sliding square windows over the image. An adaptive block size selection procedure for local sparse approximation is proposed, which affects the global recovery of underlying image. Ideally the adaptive local block selection yields the minimum mean square error (MMSE) in recovered image. This framework gives us a clustered image based on the selected block size, then each cluster is restored separately using sparse approximation. The results obtained using the proposed framework are very much comparable with the recently proposed image restoration techniques.
GPR-based Model Reconstruction System for Underground Utilities Using GPRNet
Nov 05, 2020
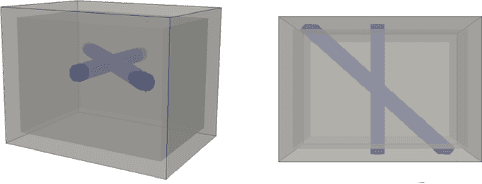
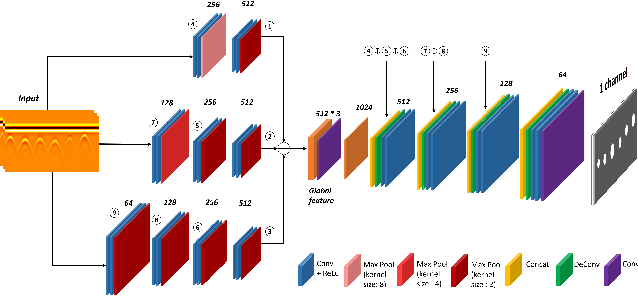
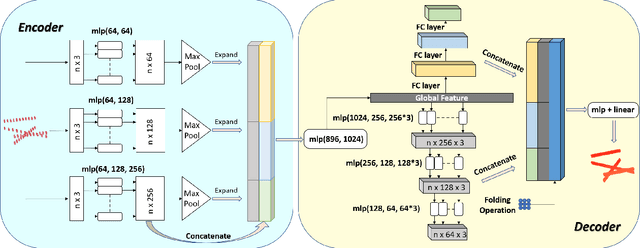
Ground Penetrating Radar (GPR) is one of the most important non-destructive evaluation (NDE) instruments to detect and locate underground objects (i.e. rebars, utility pipes). Many of the previous researches focus on GPR image-based feature detection only, and none can process sparse GPR measurements to successfully reconstruct a very fine and detailed 3D model of underground objects for better visualization. To address this problem, this paper presents a novel robotic system to collect GPR data, localize the underground utilities, and reconstruct the underground objects' dense point cloud model. This system is composed of three modules: 1) visual-inertial-based GPR data collection module which tags the GPR measurements with positioning information provided by an omnidirectional robot; 2) a deep neural network (DNN) migration module to interpret the raw GPR B-scan image into a cross-section of object model; 3) a DNN-based 3D reconstruction module, i.e., GPRNet, to generate underground utility model with the fine 3D point cloud. The experiments show that our method can generate a dense and complete point cloud model of pipe-shaped utilities based on a sparse input, i.e., GPR raw data, with various levels of incompleteness and noise. The experiment results on synthetic data as well as field test data verified the effectiveness of our method.
Superpixel Segmentation using Dynamic and Iterative Spanning Forest
Jul 08, 2020
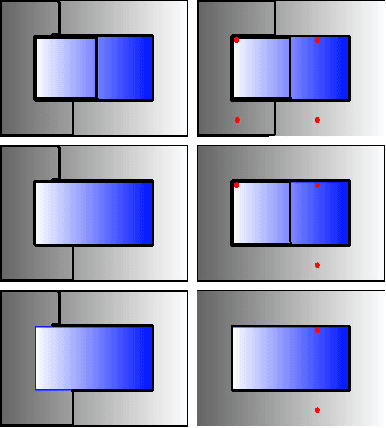

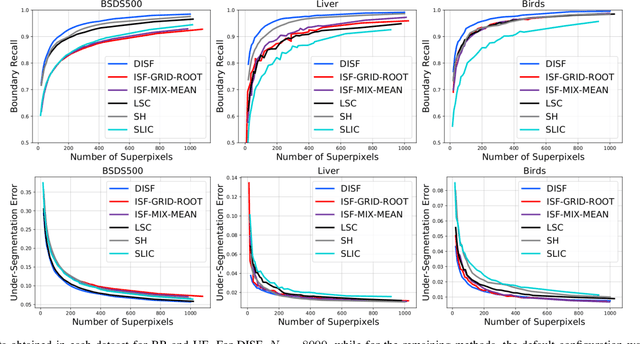
As constituent parts of image objects, superpixels can improve several higher-level operations. However, image segmentation methods might have their accuracy seriously compromised for reduced numbers of superpixels. We have investigated a solution based on the Iterative Spanning Forest (ISF) framework. In this work, we present Dynamic ISF (DISF) -- a method based on the following steps. (a) It starts from an image graph and a seed set with considerably more pixels than the desired number of superpixels. (b) The seeds compete among themselves, and each seed conquers its most closely connected pixels, resulting in an image partition (spanning forest) with connected superpixels. In step (c), DISF assigns relevance values to seeds based on superpixel analysis and removes the most irrelevant ones. Steps (b) and (c) are repeated until the desired number of superpixels is reached. DISF has the chance to reconstruct relevant edges after each iteration, when compared to region merging algorithms. As compared to other seed-based superpixel methods, DISF is more likely to find relevant seeds. It also introduces dynamic arc-weight estimation in the ISF framework for more effective superpixel delineation, and we demonstrate all results on three datasets with distinct object properties.
Toward Quantifying Ambiguities in Artistic Images
Aug 21, 2020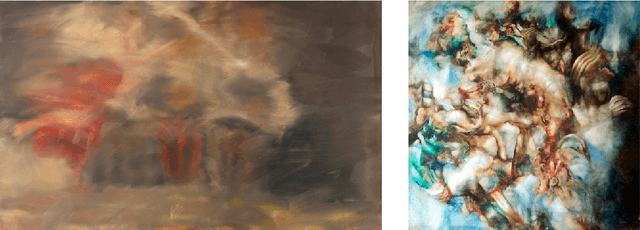
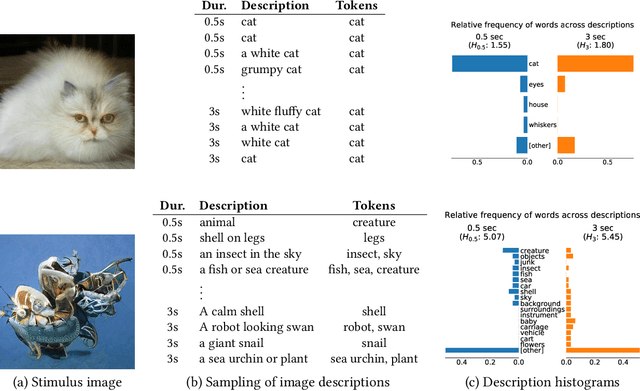


It has long been hypothesized that perceptual ambiguities play an important role in aesthetic experience: a work with some ambiguity engages a viewer more than one that does not. However, current frameworks for testing this theory are limited by the availability of stimuli and data collection methods. This paper presents an approach to measuring the perceptual ambiguity of a collection of images. Crowdworkers are asked to describe image content, after different viewing durations. Experiments are performed using images created with Generative Adversarial Networks, using the Artbreeder website. We show that text processing of viewer responses can provide a fine-grained way to measure and describe image ambiguities.
RV-GAN : Retinal Vessel Segmentation from Fundus Images using Multi-scale Generative Adversarial Networks
Jan 03, 2021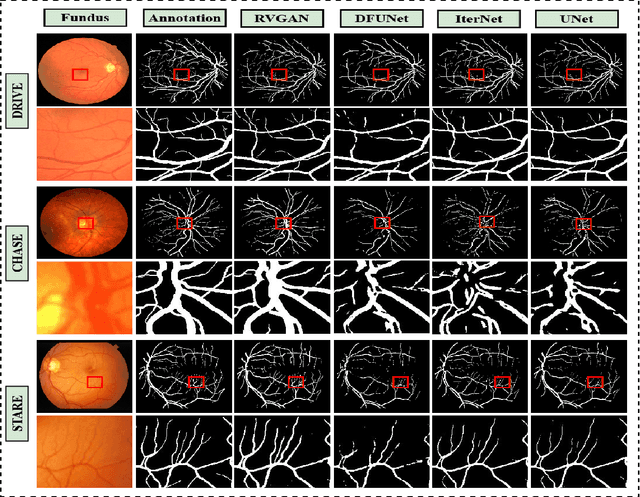
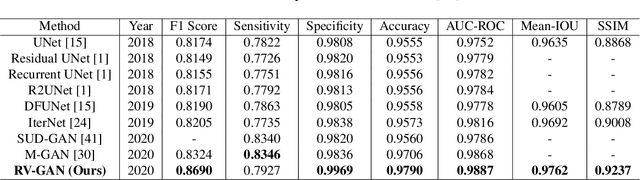
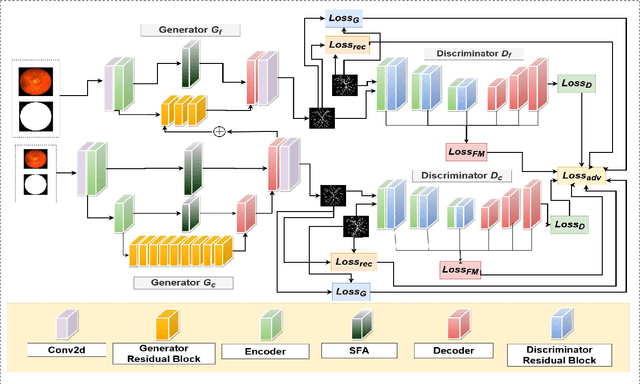
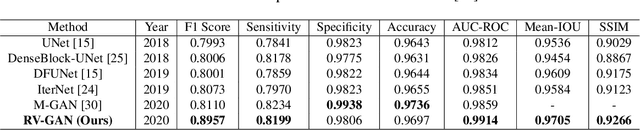
Retinal vessel segmentation contributes significantly to the domain of retinal image analysis for the diagnosis of vision-threatening diseases. With existing techniques the generated segmentation result deteriorates when thresholded with higher confidence value. To alleviate from this, we propose RVGAN, a new multi-scale generative architecture for accurate retinal vessel segmentation. Our architecture uses two generators and two multi-scale autoencoder based discriminators, for better microvessel localization and segmentation. By combining reconstruction and weighted feature matching loss, our adversarial training scheme generates highly accurate pixel-wise segmentation of retinal vessels with threshold >= 0.5. The architecture achieves AUC of 0.9887, 0.9814, and 0.9887 on three publicly available datasets, namely DRIVE, CHASE-DB1, and STARE, respectively. Additionally, RV-GAN outperforms other architectures in two additional relevant metrics, Mean-IOU and SSIM.
Supervised Transfer Learning at Scale for Medical Imaging
Jan 21, 2021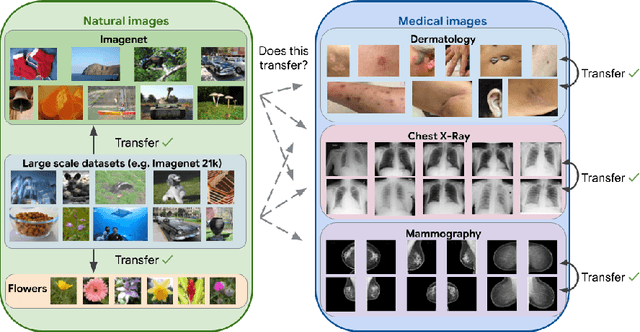
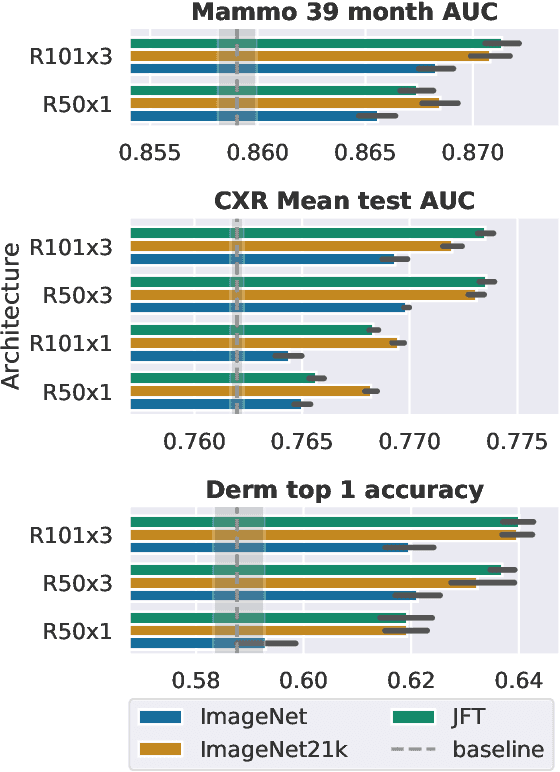
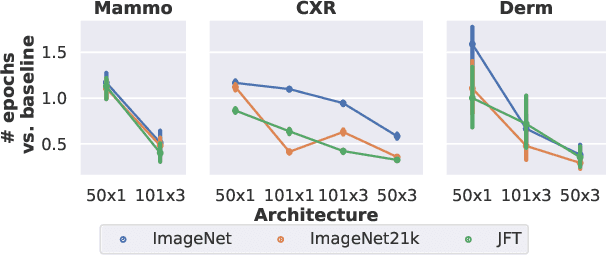
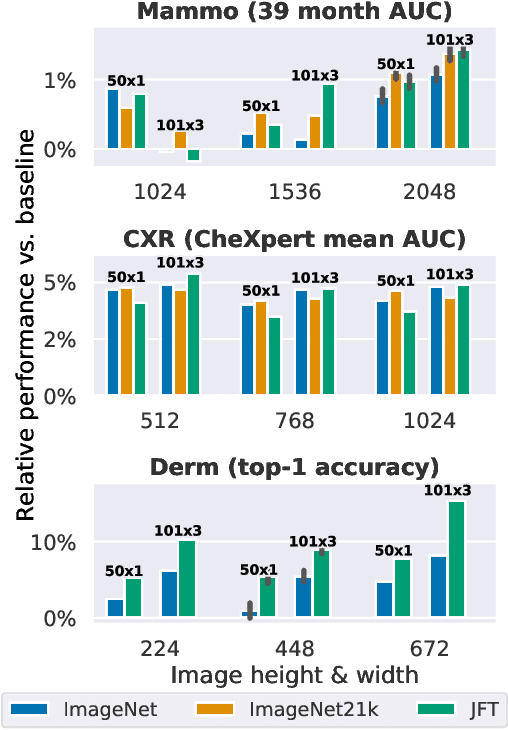
Transfer learning is a standard technique to improve performance on tasks with limited data. However, for medical imaging, the value of transfer learning is less clear. This is likely due to the large domain mismatch between the usual natural-image pre-training (e.g. ImageNet) and medical images. However, recent advances in transfer learning have shown substantial improvements from scale. We investigate whether modern methods can change the fortune of transfer learning for medical imaging. For this, we study the class of large-scale pre-trained networks presented by Kolesnikov et al. on three diverse imaging tasks: chest radiography, mammography, and dermatology. We study both transfer performance and critical properties for the deployment in the medical domain, including: out-of-distribution generalization, data-efficiency, sub-group fairness, and uncertainty estimation. Interestingly, we find that for some of these properties transfer from natural to medical images is indeed extremely effective, but only when performed at sufficient scale.