 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to Extract a Video Sequence from a Single Motion-Blurred Image
Apr 11, 2018



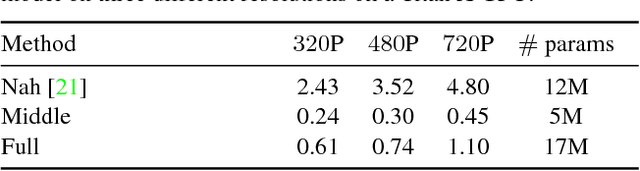
We present a method to extract a video sequence from a single motion-blurred image. Motion-blurred images are the result of an averaging process, where instant frames are accumulated over time during the exposure of the sensor. Unfortunately, reversing this process is nontrivial. Firstly, averaging destroys the temporal ordering of the frames. Secondly, the recovery of a single frame is a blind deconvolution task, which is highly ill-posed. We present a deep learning scheme that gradually reconstructs a temporal ordering by sequentially extracting pairs of frames. Our main contribution is to introduce loss functions invariant to the temporal order. This lets a neural network choose during training what frame to output among the possible combinations. We also address the ill-posedness of deblurring by designing a network with a large receptive field and implemented via resampling to achieve a higher computational efficiency. Our proposed method can successfully retrieve sharp image sequences from a single motion blurred image and can generalize well on synthetic and real datasets captured with different cameras.
Learning domain-agnostic visual representation for computational pathology using medically-irrelevant style transfer augmentation
Feb 02, 2021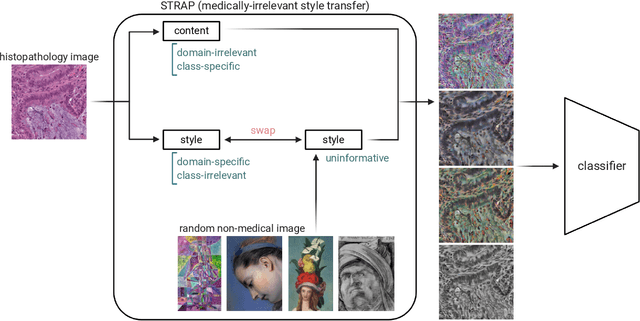



Suboptimal generalization of machine learning models on unseen data is a key challenge which hampers the clinical applicability of such models to medical imaging. Although various methods such as domain adaptation and domain generalization have evolved to combat this challenge, learning robust and generalizable representations is core to medical image understanding, and continues to be a problem. Here, we propose STRAP (Style TRansfer Augmentation for histoPathology), a form of data augmentation based on random style transfer from artistic paintings, for learning domain-agnostic visual representations in computational pathology. Style transfer replaces the low-level texture content of images with the uninformative style of randomly selected artistic paintings, while preserving high-level semantic content. This improves robustness to domain shift and can be used as a simple yet powerful tool for learning domain-agnostic representations. We demonstrate that STRAP leads to state-of-the-art performance, particularly in the presence of domain shifts, on a particular classification task of predicting microsatellite status in colorectal cancer using digitized histopathology images.
Unsupervised Shadow Removal Using Target Consistency Generative Adversarial Network
Oct 03, 2020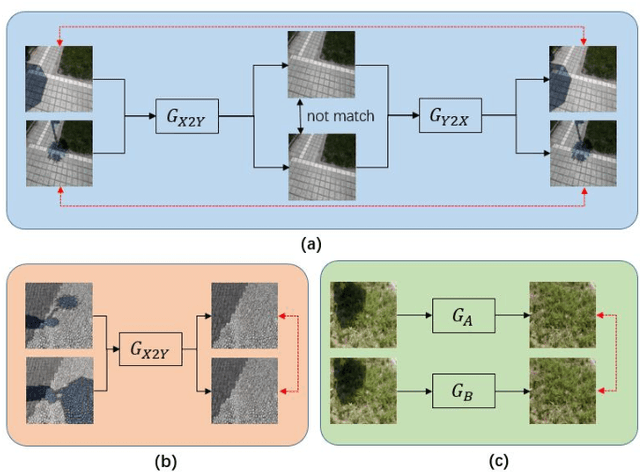
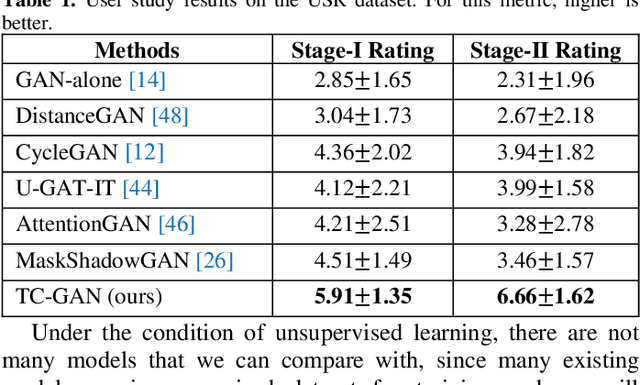
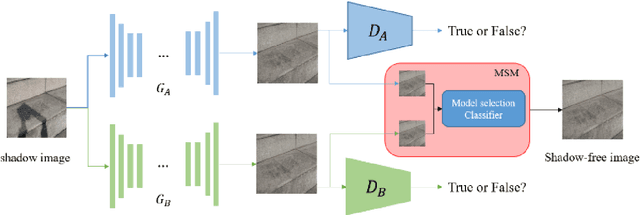
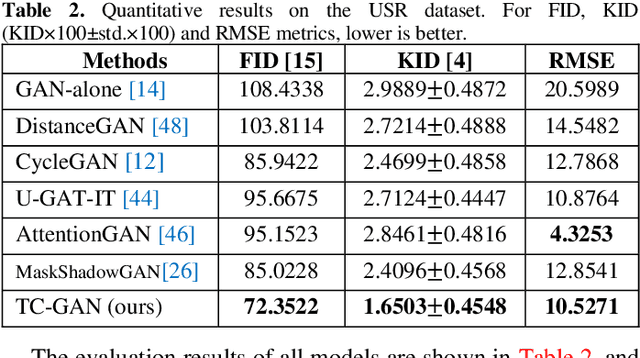
Unsupervised shadow removal aims to learn a non-linear function to map the original image from shadow domain to non-shadow domain in the absence of paired shadow and non-shadow data. In this paper, we develop a simple yet efficient target-consistency generative adversarial network (TC-GAN) for the shadow removal task in the unsupervised manner. Compared with the bidirectional mapping in cycle-consistency GAN based methods for shadow removal, TC-GAN tries to learn a one-sided mapping to cast shadow images into shadow-free ones. With the proposed target-consistency constraint, the correlations between shadow images and the output shadow-free image are strictly confined. Extensive comparison experiments results show that TC-GAN outperforms the state-of-the-art unsupervised shadow removal methods by 14.9% in terms of FID and 31.5% in terms of KID. It is rather remarkable that TC-GAN achieves comparable performance with supervised shadow removal methods.
Visualizing Transfer Learning
Jul 15, 2020



We provide visualizations of individual neurons of a deep image recognition network during the temporal process of transfer learning. These visualizations qualitatively demonstrate various novel properties of the transfer learning process regarding the speed and characteristics of adaptation, neuron reuse, spatial scale of the represented image features, and behavior of transfer learning to small data. We publish the large-scale dataset that we have created for the purposes of this analysis.
ES-Net: Erasing Salient Parts to Learn More in Re-Identification
Mar 10, 2021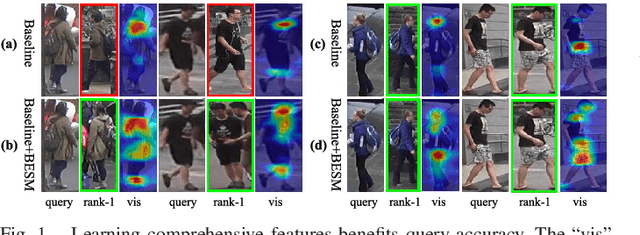
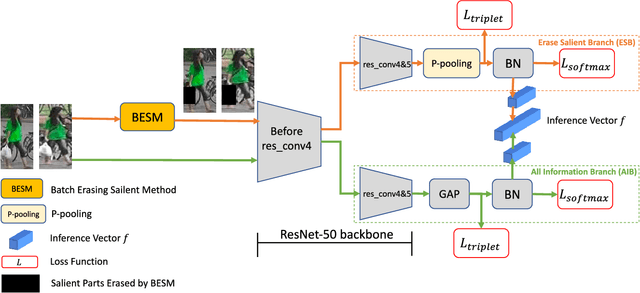
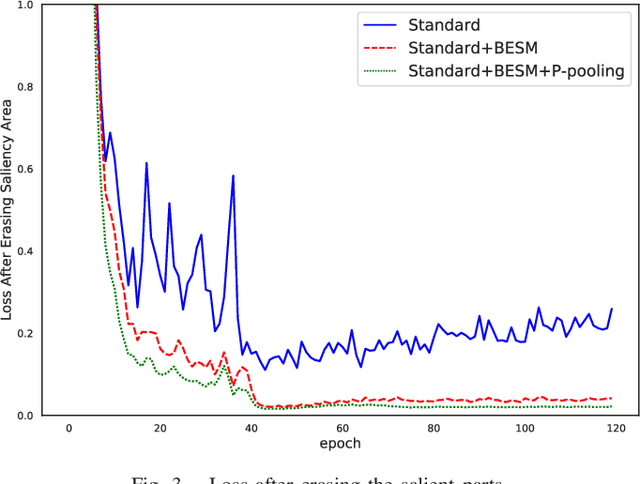

As an instance-level recognition problem, re-identification (re-ID) requires models to capture diverse features. However, with continuous training, re-ID models pay more and more attention to the salient areas. As a result, the model may only focus on few small regions with salient representations and ignore other important information. This phenomenon leads to inferior performance, especially when models are evaluated on small inter-identity variation data. In this paper, we propose a novel network, Erasing-Salient Net (ES-Net), to learn comprehensive features by erasing the salient areas in an image. ES-Net proposes a novel method to locate the salient areas by the confidence of objects and erases them efficiently in a training batch. Meanwhile, to mitigate the over-erasing problem, this paper uses a trainable pooling layer P-pooling that generalizes global max and global average pooling. Experiments are conducted on two specific re-identification tasks (i.e., Person re-ID, Vehicle re-ID). Our ES-Net outperforms state-of-the-art methods on three Person re-ID benchmarks and two Vehicle re-ID benchmarks. Specifically, mAP / Rank-1 rate: 88.6% / 95.7% on Market1501, 78.8% / 89.2% on DuckMTMC-reID, 57.3% / 80.9% on MSMT17, 81.9% / 97.0% on Veri-776, respectively. Rank-1 / Rank-5 rate: 83.6% / 96.9% on VehicleID (Small), 79.9% / 93.5% on VehicleID (Medium), 76.9% / 90.7% on VehicleID (Large), respectively. Moreover, the visualized salient areas show human-interpretable visual explanations for the ranking results.
* 11 pages, 6 figures. Accepted for publication in IEEE Transactions on Image Processing 2021
On the Use of Deep Learning for Blind Image Quality Assessment
Apr 04, 2017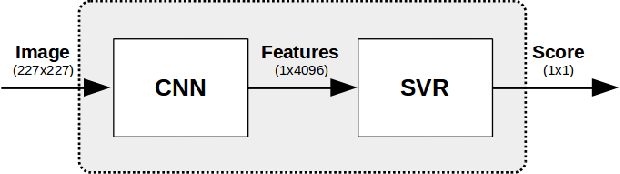
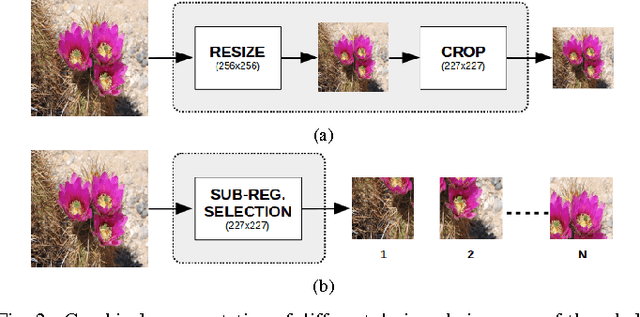
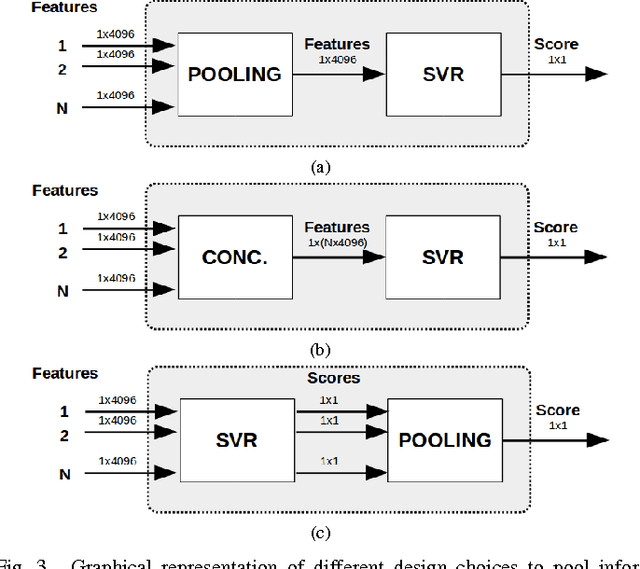

In this work we investigate the use of deep learning for distortion-generic blind image quality assessment. We report on different design choices, ranging from the use of features extracted from pre-trained Convolutional Neural Networks (CNNs) as a generic image description, to the use of features extracted from a CNN fine-tuned for the image quality task. Our best proposal, named DeepBIQ, estimates the image quality by average pooling the scores predicted on multiple sub-regions of the original image. The score of each sub-region is computed using a Support Vector Regression (SVR) machine taking as input features extracted using a CNN fine-tuned for category-based image quality assessment. Experimental results on the LIVE In the Wild Image Quality Challenge Database and on the LIVE Image Quality Assessment Database show that DeepBIQ outperforms the state-of-the-art methods compared, having a Linear Correlation Coefficient (LCC) with human subjective scores of almost 0.91 and 0.98 respectively. Furthermore, in most of the cases, the quality score predictions of DeepBIQ are closer to the average observer than those of a generic human observer.
Run Your Visual-Inertial Odometry on NVIDIA Jetson: Benchmark Tests on a Micro Aerial Vehicle
Mar 02, 2021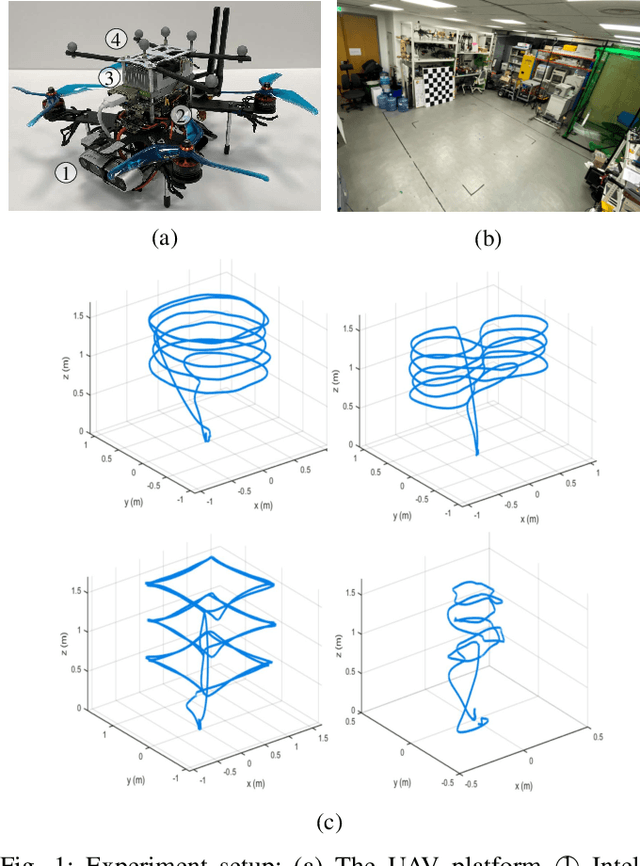

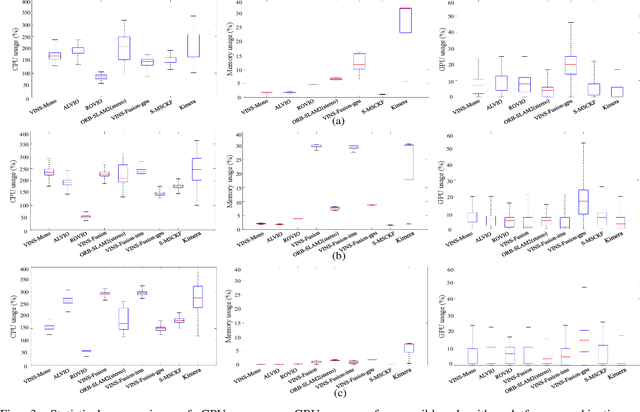
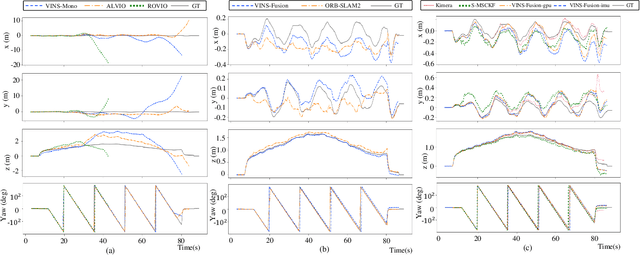
This paper presents benchmark tests of various visual(-inertial) odometry algorithms on NVIDIA Jetson platforms. The compared algorithms include mono and stereo, covering Visual Odometry (VO) and Visual-Inertial Odometry (VIO): VINS-Mono, VINS-Fusion, Kimera, ALVIO, Stereo-MSCKF, ORB-SLAM2 stereo, and ROVIO. As these methods are mainly used for unmanned aerial vehicles (UAVs), they must perform well in situations where the size of the processing board and weight is limited. Jetson boards released by NVIDIA satisfy these constraints as they have a sufficiently powerful central processing unit (CPU) and graphics processing unit (GPU) for image processing. However, in existing studies, the performance of Jetson boards as a processing platform for executing VO/VIO has not been compared extensively in terms of the usage of computing resources and accuracy. Therefore, this study compares representative VO/VIO algorithms on several NVIDIA Jetson platforms, namely NVIDIA Jetson TX2, Xavier NX, and AGX Xavier, and introduces a novel dataset 'KAIST VIO dataset' for UAVs. Including pure rotations, the dataset has several geometric trajectories that are harsh to visual(-inertial) state estimation. The evaluation is performed in terms of the accuracy of estimated odometry, CPU usage, and memory usage on various Jetson boards, algorithms, and trajectories. We present the {results of the} comprehensive benchmark test and release the dataset for the computer vision and robotics applications.
Exploiting latent representation of sparse semantic layers for improved short-term motion prediction with Capsule Networks
Mar 02, 2021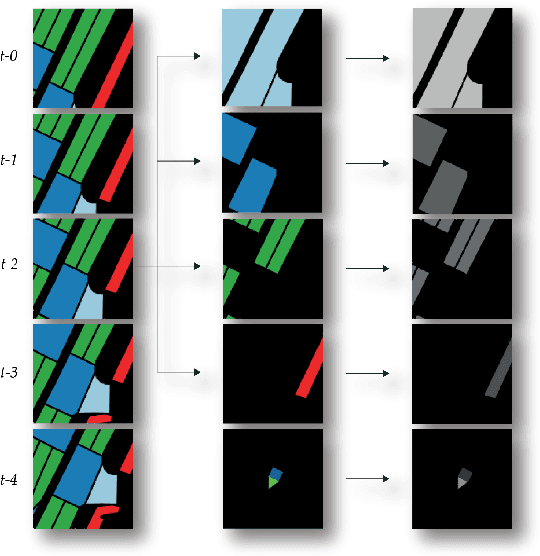
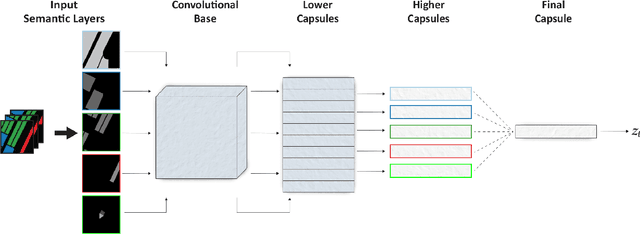

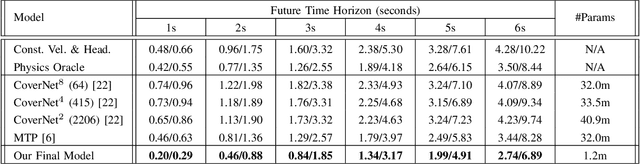
As urban environments manifest high levels of complexity it is of vital importance that safety systems embedded within autonomous vehicles (AVs) are able to accurately anticipate short-term future motion of nearby agents. This problem can be further understood as generating a sequence of coordinates describing the future motion of the tracked agent. Various proposed approaches demonstrate significant benefits of using a rasterised top-down image of the road, with a combination of Convolutional Neural Networks (CNNs), for extraction of relevant features that define the road structure (eg. driveable areas, lanes, walkways). In contrast, this paper explores use of Capsule Networks (CapsNets) in the context of learning a hierarchical representation of sparse semantic layers corresponding to small regions of the High-Definition (HD) map. Each region of the map is dismantled into separate geometrical layers that are extracted with respect to the agent's current position. By using an architecture based on CapsNets the model is able to retain hierarchical relationships between detected features within images whilst also preventing loss of spatial data often caused by the pooling operation. We train and evaluate our model on publicly available dataset nuTonomy scenes and compare it to recently published methods. We show that our model achieves significant improvement over recently published works on deterministic prediction, whilst drastically reducing the overall size of the network.
High-quality Panorama Stitching based on Asymmetric Bidirectional Optical Flow
Jun 19, 2020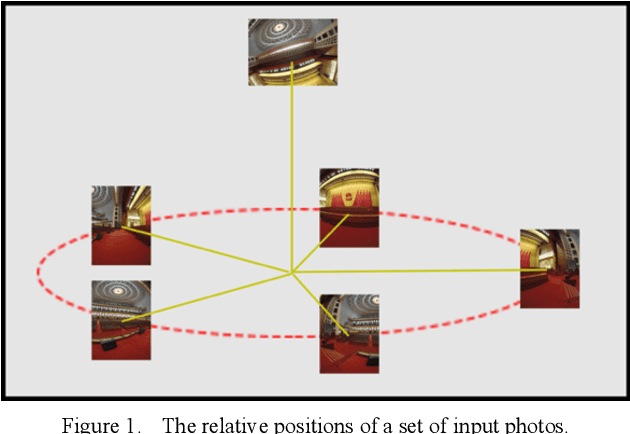
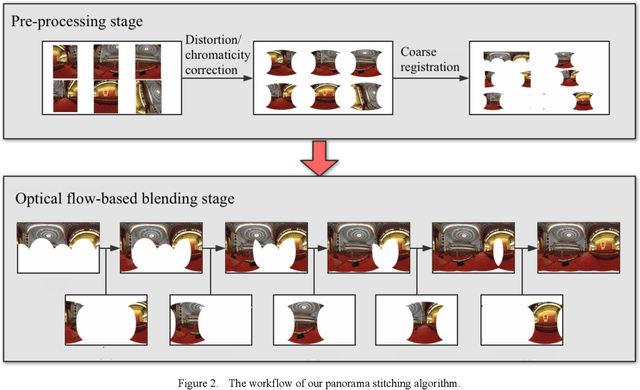

In this paper, we propose a panorama stitching algorithm based on asymmetric bidirectional optical flow. This algorithm expects multiple photos captured by fisheye lens cameras as input, and then, through the proposed algorithm, these photos can be merged into a high-quality 360-degree spherical panoramic image. For photos taken from a distant perspective, the parallax among them is relatively small, and the obtained panoramic image can be nearly seamless and undistorted. For photos taken from a close perspective or with a relatively large parallax, a seamless though partially distorted panoramic image can also be obtained. Besides, with the help of Graphics Processing Unit (GPU), this algorithm can complete the whole stitching process at a very fast speed: typically, it only takes less than 30s to obtain a panoramic image of 9000-by-4000 pixels, which means our panorama stitching algorithm is of high value in many real-time applications. Our code is available at https://github.com/MungoMeng/Panorama-OpticalFlow.
Adversarial Exposure Attack on Diabetic Retinopathy Imagery
Sep 19, 2020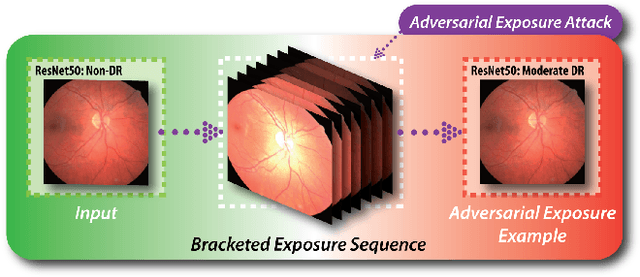
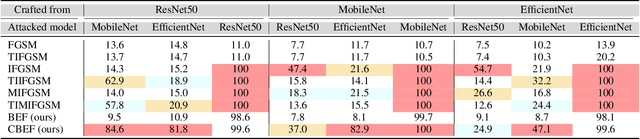
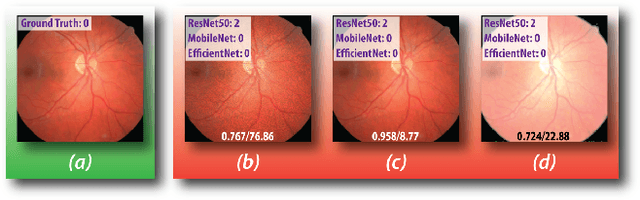

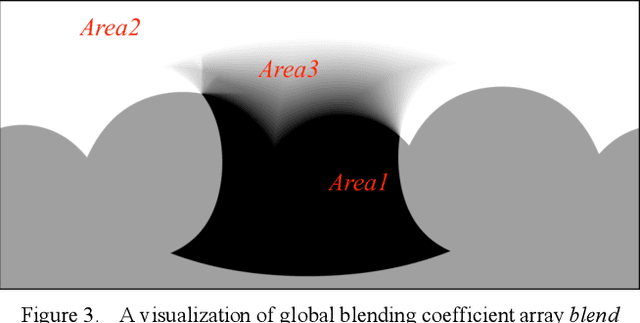
Diabetic retinopathy (DR) is a leading cause of vision loss in the world and numerous cutting-edge works have built powerful deep neural networks (DNNs) to automatically classify the DR cases via the retinal fundus images (RFIs). However, RFIs are usually affected by the widely existing camera exposure while the robustness of DNNs to the exposure is rarely explored. In this paper, we study this problem from the viewpoint of adversarial attack and identify a totally new task, i.e., adversarial exposure attack generating adversarial images by tuning image exposure to mislead the DNNs with significantly high transferability. To this end, we first implement a straightforward method, i.e., multiplicative-perturbation-based exposure attack, and reveal the big challenges of this new task. Then, to make the adversarial image naturalness, we propose the adversarial bracketed exposure fusion that regards the exposure attack as an element-wise bracketed exposure fusion problem in the Laplacian-pyramid space. Moreover, to realize high transferability, we further propose the convolutional bracketed exposure fusion where the element-wise multiplicative operation is extended to the convolution. We validate our method on the real public DR dataset with the advanced DNNs, e.g., ResNet50, MobileNet, and EfficientNet, showing our method can achieve high image quality and success rate of the transfer attack. Our method reveals the potential threats to the DNN-based DR automated diagnosis and can definitely benefit the development of exposure-robust automated DR diagnosis method in the future.