 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Combination of Hidden Markov Random Field and Conjugate Gradient for Brain Image Segmentation
Mar 13, 2018
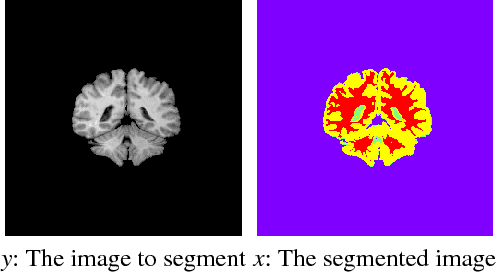

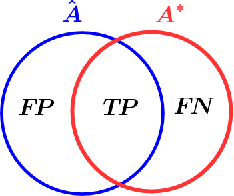
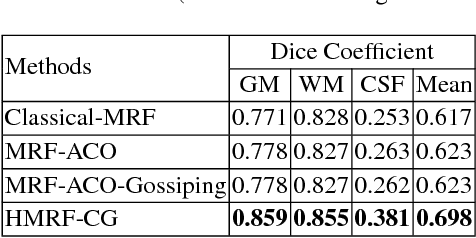
Image segmentation is the process of partitioning the image into significant regions easier to analyze. Nowadays, segmentation has become a necessity in many practical medical imaging methods as locating tumors and diseases. Hidden Markov Random Field model is one of several techniques used in image segmentation. It provides an elegant way to model the segmentation process. This modeling leads to the minimization of an objective function. Conjugate Gradient algorithm (CG) is one of the best known optimization techniques. This paper proposes the use of the Conjugate Gradient algorithm (CG) for image segmentation, based on the Hidden Markov Random Field. Since derivatives are not available for this expression, finite differences are used in the CG algorithm to approximate the first derivative. The approach is evaluated using a number of publicly available images, where ground truth is known. The Dice Coefficient is used as an objective criterion to measure the quality of segmentation. The results show that the proposed CG approach compares favorably with other variants of Hidden Markov Random Field segmentation algorithms.
Deferred Neural Rendering: Image Synthesis using Neural Textures
Apr 28, 2019

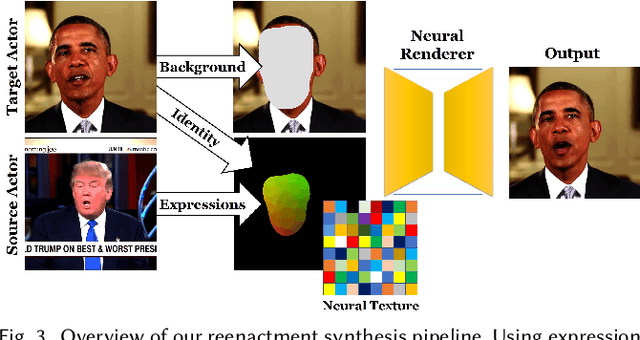
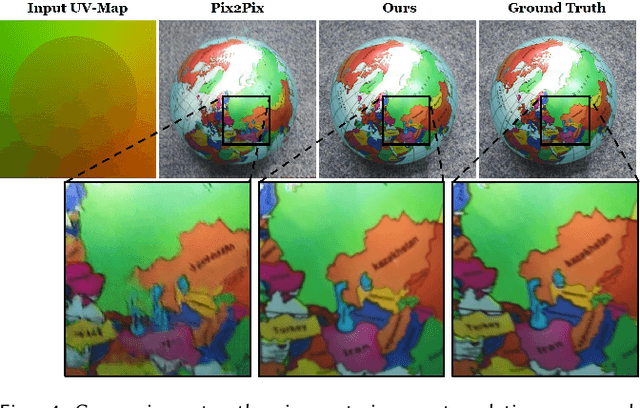
The modern computer graphics pipeline can synthesize images at remarkable visual quality; however, it requires well-defined, high-quality 3D content as input. In this work, we explore the use of imperfect 3D content, for instance, obtained from photo-metric reconstructions with noisy and incomplete surface geometry, while still aiming to produce photo-realistic (re-)renderings. To address this challenging problem, we introduce Deferred Neural Rendering, a new paradigm for image synthesis that combines the traditional graphics pipeline with learnable components. Specifically, we propose Neural Textures, which are learned feature maps that are trained as part of the scene capture process. Similar to traditional textures, neural textures are stored as maps on top of 3D mesh proxies; however, the high-dimensional feature maps contain significantly more information, which can be interpreted by our new deferred neural rendering pipeline. Both neural textures and deferred neural renderer are trained end-to-end, enabling us to synthesize photo-realistic images even when the original 3D content was imperfect. In contrast to traditional, black-box 2D generative neural networks, our 3D representation gives us explicit control over the generated output, and allows for a wide range of application domains. For instance, we can synthesize temporally-consistent video re-renderings of recorded 3D scenes as our representation is inherently embedded in 3D space. This way, neural textures can be utilized to coherently re-render or manipulate existing video content in both static and dynamic environments at real-time rates. We show the effectiveness of our approach in several experiments on novel view synthesis, scene editing, and facial reenactment, and compare to state-of-the-art approaches that leverage the standard graphics pipeline as well as conventional generative neural networks.
Image Segmentation Using Hierarchical Merge Tree
Jul 31, 2016
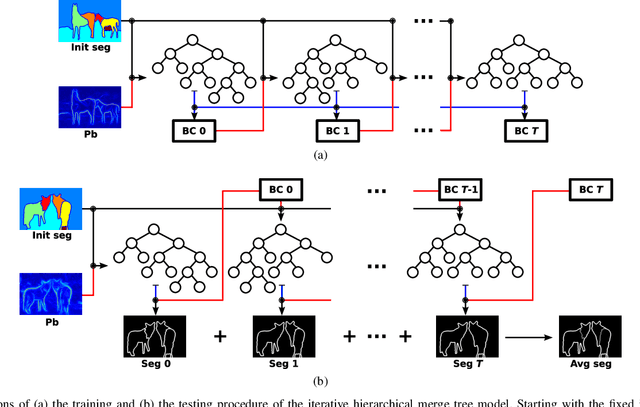
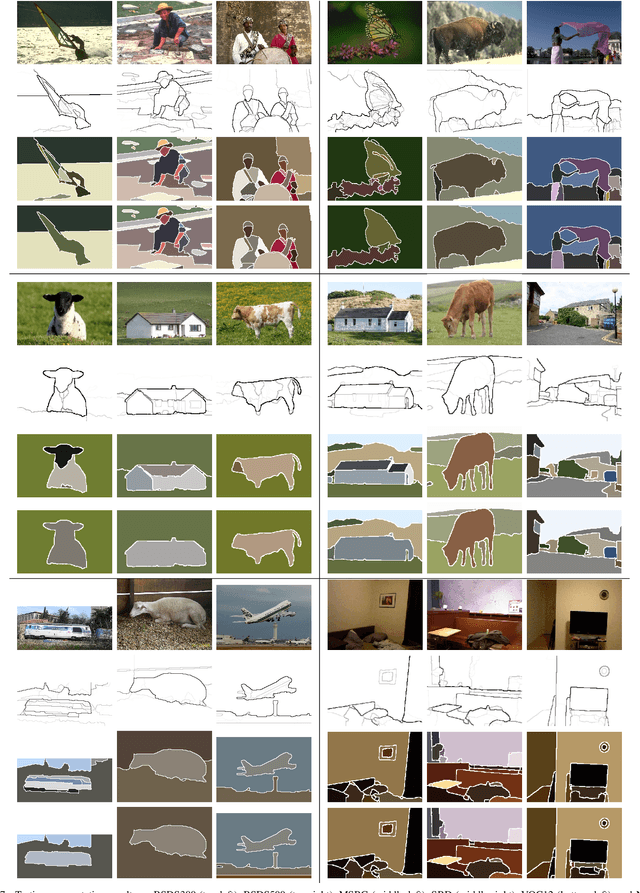
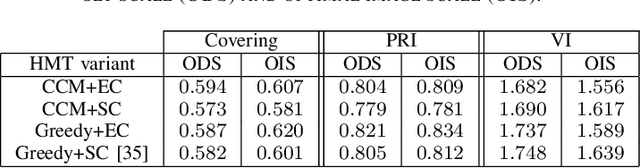
This paper investigates one of the most fundamental computer vision problems: image segmentation. We propose a supervised hierarchical approach to object-independent image segmentation. Starting with over-segmenting superpixels, we use a tree structure to represent the hierarchy of region merging, by which we reduce the problem of segmenting image regions to finding a set of label assignment to tree nodes. We formulate the tree structure as a constrained conditional model to associate region merging with likelihoods predicted using an ensemble boundary classifier. Final segmentations can then be inferred by finding globally optimal solutions to the model efficiently. We also present an iterative training and testing algorithm that generates various tree structures and combines them to emphasize accurate boundaries by segmentation accumulation. Experiment results and comparisons with other very recent methods on six public data sets demonstrate that our approach achieves the state-of-the-art region accuracy and is very competitive in image segmentation without semantic priors.
The Deep Bootstrap: Good Online Learners are Good Offline Generalizers
Oct 16, 2020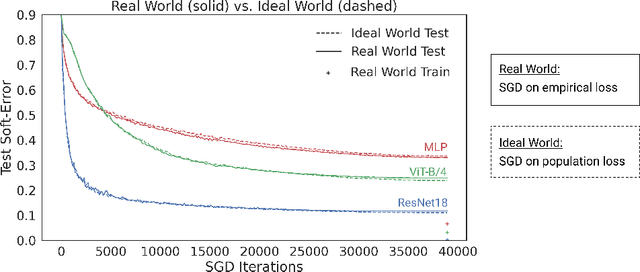

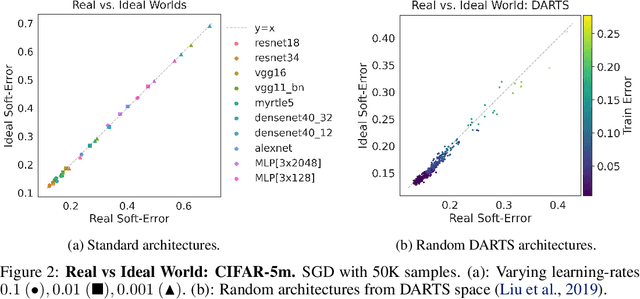

We propose a new framework for reasoning about generalization in deep learning. The core idea is to couple the Real World, where optimizers take stochastic gradient steps on the empirical loss, to an Ideal World, where optimizers take steps on the population loss. This leads to an alternate decomposition of test error into: (1) the Ideal World test error plus (2) the gap between the two worlds. If the gap (2) is universally small, this reduces the problem of generalization in offline learning to the problem of optimization in online learning. We then give empirical evidence that this gap between worlds can be small in realistic deep learning settings, in particular supervised image classification. For example, CNNs generalize better than MLPs on image distributions in the Real World, but this is "because" they optimize faster on the population loss in the Ideal World. This suggests our framework is a useful tool for understanding generalization in deep learning, and lays a foundation for future research in the area.
Blind Image Fusion for Hyperspectral Imaging with the Directional Total Variation
Apr 09, 2018
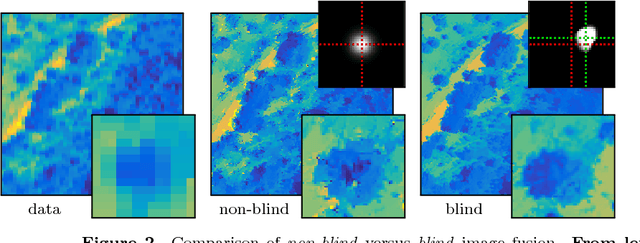
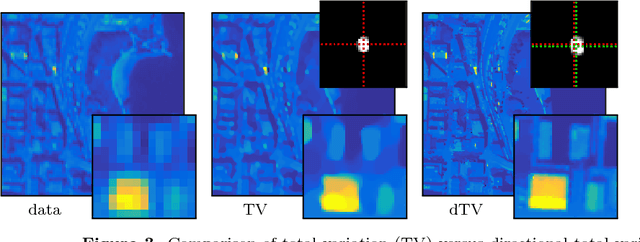

Hyperspectral imaging is a cutting-edge type of remote sensing used for mapping vegetation properties, rock minerals and other materials. A major drawback of hyperspectral imaging devices is their intrinsic low spatial resolution. In this paper, we propose a method for increasing the spatial resolution of a hyperspectral image by fusing it with an image of higher spatial resolution that was obtained with a different imaging modality. This is accomplished by solving a variational problem in which the regularization functional is the directional total variation. To accommodate for possible mis-registrations between the two images, we consider a non-convex blind super-resolution problem where both a fused image and the corresponding convolution kernel are estimated. Using this approach, our model can realign the given images if needed. Our experimental results indicate that the non-convexity is negligible in practice and that reliable solutions can be computed using a variety of different optimization algorithms. Numerical results on real remote sensing data from plant sciences and urban monitoring show the potential of the proposed method and suggests that it is robust with respect to the regularization parameters, mis-registration and the shape of the kernel.
Foveation for Segmentation of Ultra-High Resolution Images
Jul 31, 2020

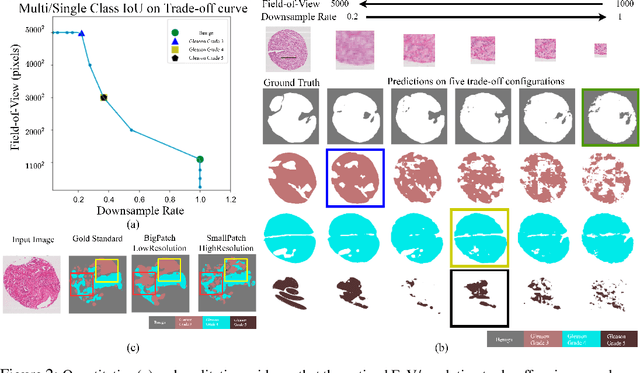
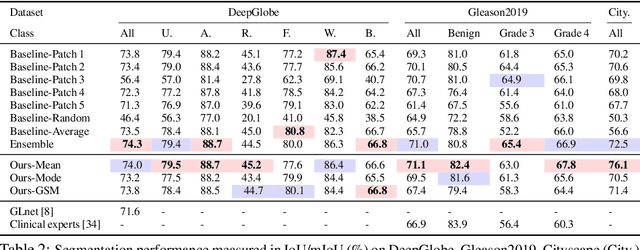
Segmentation of ultra-high resolution images is challenging because of their enormous size, consisting of millions or even billions of pixels. Typical solutions include dividing input images into patches of fixed size and/or down-sampling to meet memory constraints. Such operations incur information loss in the field-of-view (FoV) i.e., spatial coverage and the image resolution. The impact on segmentation performance is, however, as yet understudied. In this work, we start with a motivational experiment which demonstrates that the trade-off between FoV and resolution affects the segmentation performance on ultra-high resolution images---and furthermore, its influence also varies spatially according to the local patterns in different areas. We then introduce foveation module, a learnable "dataloader" which, for a given ultra-high resolution image, adaptively chooses the appropriate configuration (FoV/resolution trade-off) of the input patch to feed to the downstream segmentation model at each spatial location of the image. The foveation module is jointly trained with the segmentation network to maximise the task performance. We demonstrate on three publicly available high-resolution image datasets that the foveation module consistently improves segmentation performance over the cases trained with patches of fixed FoV/resolution trade-off. Our approach achieves the SoTA performance on the DeepGlobe aerial image dataset. On the Gleason2019 histopathology dataset, our model achieves better segmentation accuracy for the two most clinically important and ambiguous classes (Gleason Grade 3 and 4) than the top performers in the challenge by 13.1% and 7.5%, and improves on the average performance of 6 human experts by 6.5% and 7.5%. Our code and trained models are available at $\text{https://github.com/lxasqjc/Foveation-Segmentation}$.
Randomized kernels for large scale Earth observation applications
Dec 07, 2020Dealing with land cover classification of the new image sources has also turned to be a complex problem requiring large amount of memory and processing time. In order to cope with these problems, statistical learning has greatly helped in the last years to develop statistical retrieval and classification models that can ingest large amounts of Earth observation data. Kernel methods constitute a family of powerful machine learning algorithms, which have found wide use in remote sensing and geosciences. However, kernel methods are still not widely adopted because of the high computational cost when dealing with large scale problems, such as the inversion of radiative transfer models or the classification of high spatial-spectral-temporal resolution data. This paper introduces an efficient kernel method for fast statistical retrieval of bio-geo-physical parameters and image classification problems. The method allows to approximate a kernel matrix with a set of projections on random bases sampled from the Fourier domain. The method is simple, computationally very efficient in both memory and processing costs, and easily parallelizable. We show that kernel regression and classification is now possible for datasets with millions of examples and high dimensionality. Examples on atmospheric parameter retrieval from hyperspectral infrared sounders like IASI/Metop; large scale emulation and inversion of the familiar PROSAIL radiative transfer model on Sentinel-2 data; and the identification of clouds over landmarks in time series of MSG/Seviri images show the efficiency and effectiveness of the proposed technique.
Deep Learning-based Single Image Face Depth Data Enhancement
Jun 19, 2020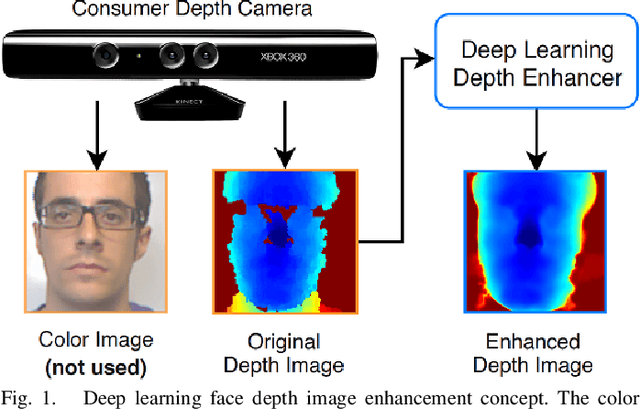
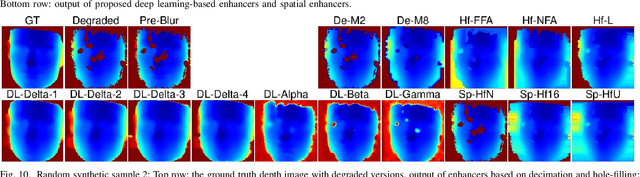
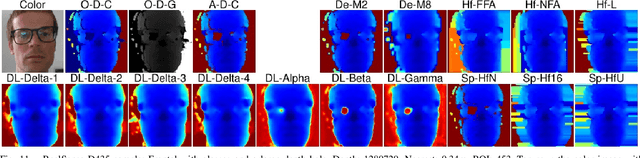
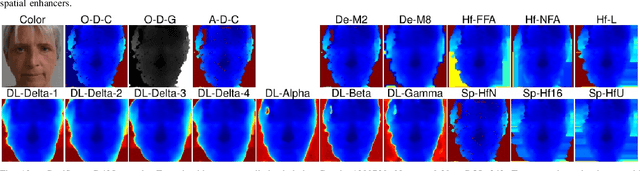
Face recognition can benefit from the utilization of depth data captured using low-cost cameras, in particular for presentation attack detection purposes. Depth video output from these capture devices can however contain defects such as holes, as well as general depth inaccuracies. This work proposes a deep learning-based face depth enhancement method. The trained artificial neural networks utilize U-Net-like architectures, and are compared against general enhancer types. All tested enhancer types exclusively use depth data as input, which differs from methods that enhance depth based on additional input data such as visible light color images. Due to the noted apparent lack of real-world camera datasets with suitable properties, face depth ground truth images and degraded forms thereof are synthesized with help of PRNet, both for the deep learning training and for an experimental quantitative evaluation of all enhancer types. Generated enhancer output samples are also presented for real camera data, namely custom RealSense D435 depth images and Kinect v1 data from the KinectFaceDB. It is concluded that the deep learning enhancement approach is superior to the tested general enhancers, without overly falsifying depth data when non-face input is provided.
Convolution Neural Network Hyperparameter Optimization Using Simplified Swarm Optimization
Mar 06, 2021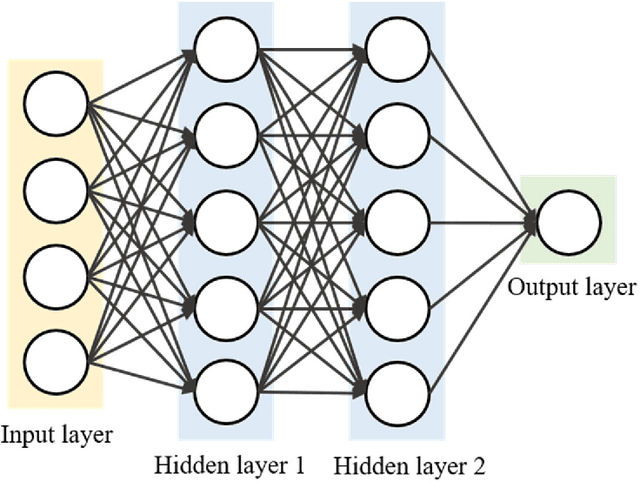
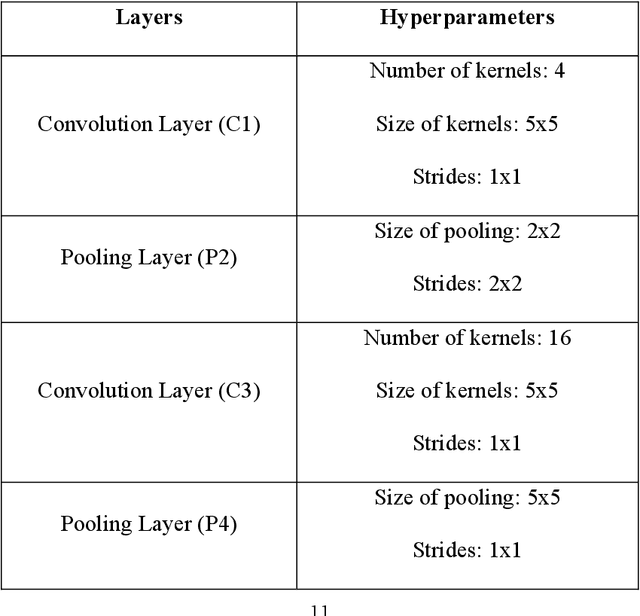
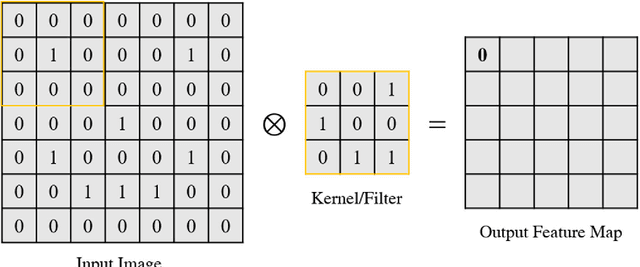
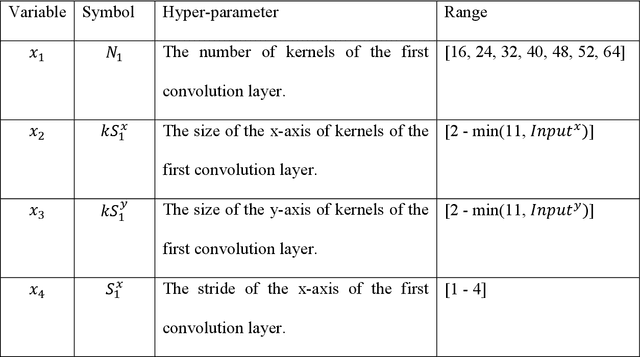
Among the machine learning approaches applied in computer vision, Convolutional Neural Network (CNN) is widely used in the field of image recognition. However, although existing CNN models have been proven to be efficient, it is not easy to find a network architecture with better performance. Some studies choose to optimize the network architecture, while others chose to optimize the hyperparameters, such as the number and size of convolutional kernels, convolutional strides, pooling size, etc. Most of them are designed manually, which requires relevant expertise and takes a lot of time. Therefore, this study proposes the idea of applying Simplified Swarm Optimization (SSO) on the hyperparameter optimization of LeNet models while using MNIST, Fashion MNIST, and Cifar10 as validation. The experimental results show that the proposed algorithm has higher accuracy than the original LeNet model, and it only takes a very short time to find a better hyperparameter configuration after training. In addition, we also analyze the output shape of the feature map after each layer, and surprisingly, the results were mostly rectangular. The contribution of the study is to provide users with a simpler way to get better results with the existing model., and this study can also be applied to other CNN architectures.
Dense Contrastive Learning for Self-Supervised Visual Pre-Training
Nov 18, 2020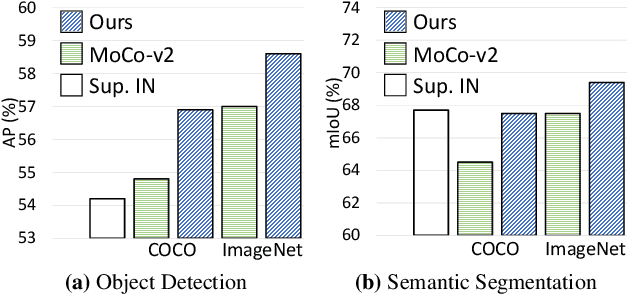



To date, most existing self-supervised learning methods are designed and optimized for image classification. These pre-trained models can be sub-optimal for dense prediction tasks due to the discrepancy between image-level prediction and pixel-level prediction. To fill this gap, we aim to design an effective, dense self-supervised learning method that directly works at the level of pixels (or local features) by taking into account the correspondence between local features. We present dense contrastive learning, which implements self-supervised learning by optimizing a pairwise contrastive (dis)similarity loss at the pixel level between two views of input images. Compared to the baseline method MoCo-v2, our method introduces negligible computation overhead (only <1% slower), but demonstrates consistently superior performance when transferring to downstream dense prediction tasks including object detection, semantic segmentation and instance segmentation; and outperforms the state-of-the-art methods by a large margin. Specifically, over the strong MoCo-v2 baseline, our method achieves significant improvements of 2.0% AP on PASCAL VOC object detection, 1.1% AP on COCO object detection, 0.9% AP on COCO instance segmentation, 3.0% mIoU on PASCAL VOC semantic segmentation and 1.8% mIoU on Cityscapes semantic segmentation. Code is available at: https://git.io/AdelaiDet