 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep learning-based synthetic-CT generation in radiotherapy and PET: a review
Feb 04, 2021
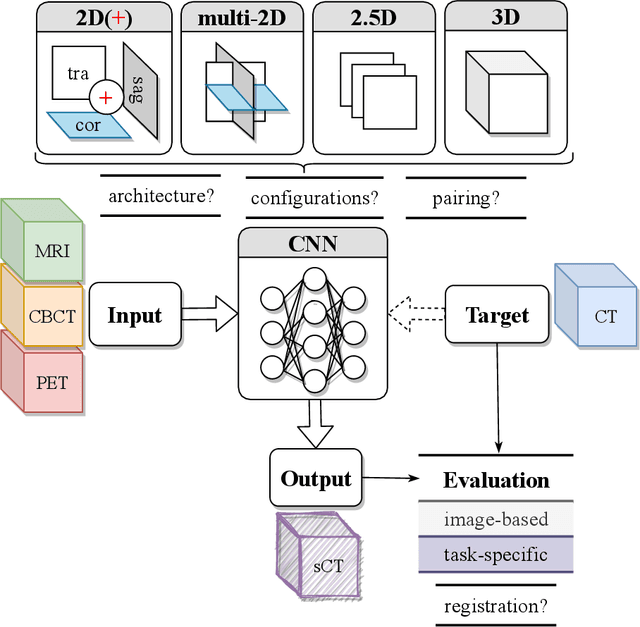

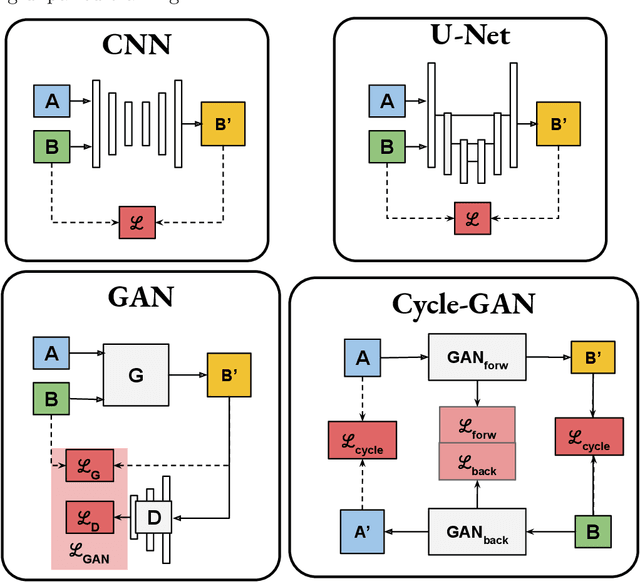
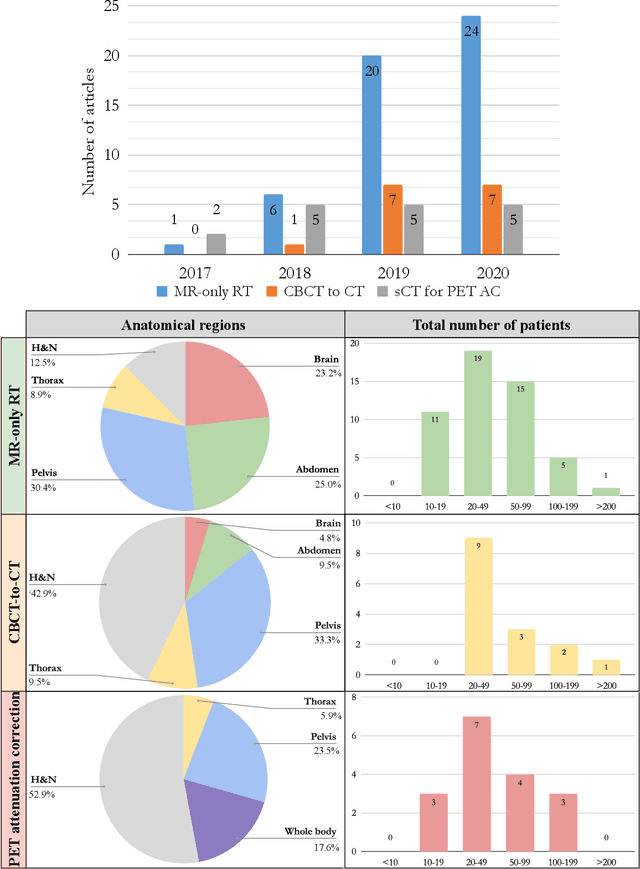
Recently, deep learning (DL)-based methods for the generation of synthetic computed tomography (sCT) have received significant research attention as an alternative to classical ones. We present here a systematic review of these methods by grouping them into three categories, according to their clinical applications: I) to replace CT in magnetic resonance (MR)-based treatment planning, II) facilitate cone-beam computed tomography (CBCT)-based image-guided adaptive radiotherapy, and III) derive attenuation maps for the correction of Positron Emission Tomography (PET). Appropriate database searching was performed on journal articles published between January 2014 and December 2020. The DL methods' key characteristics were extracted from each eligible study, and a comprehensive comparison among network architectures and metrics was reported. A detailed review of each category was given, highlighting essential contributions, identifying specific challenges, and summarising the achievements. Lastly, the statistics of all the cited works from various aspects were analysed, revealing the popularity and future trends, and the potential of DL-based sCT generation. The current status of DL-based sCT generation was evaluated, assessing the clinical readiness of the presented methods.
Defending Adversarial Examples via DNN Bottleneck Reinforcement
Aug 12, 2020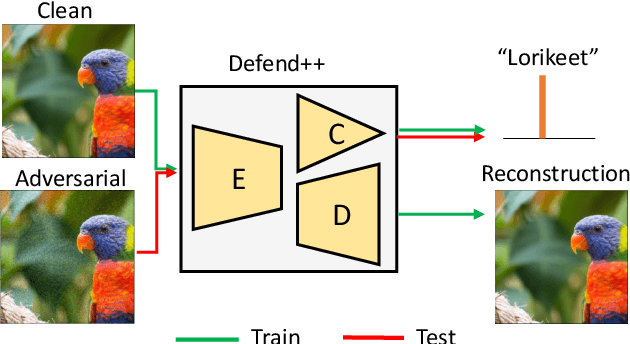
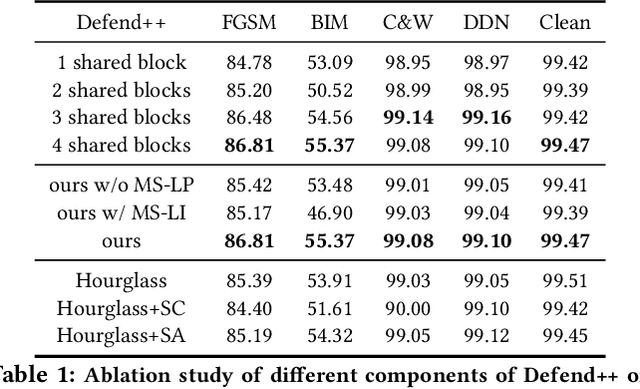

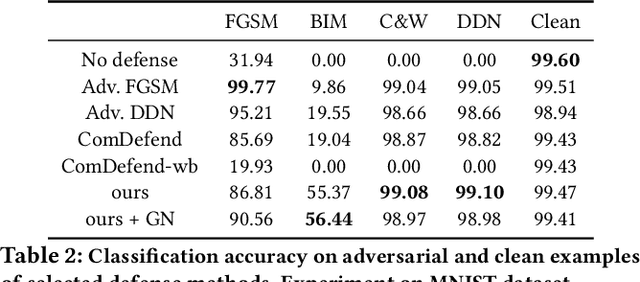
This paper presents a DNN bottleneck reinforcement scheme to alleviate the vulnerability of Deep Neural Networks (DNN) against adversarial attacks. Typical DNN classifiers encode the input image into a compressed latent representation more suitable for inference. This information bottleneck makes a trade-off between the image-specific structure and class-specific information in an image. By reinforcing the former while maintaining the latter, any redundant information, be it adversarial or not, should be removed from the latent representation. Hence, this paper proposes to jointly train an auto-encoder (AE) sharing the same encoding weights with the visual classifier. In order to reinforce the information bottleneck, we introduce the multi-scale low-pass objective and multi-scale high-frequency communication for better frequency steering in the network. Unlike existing approaches, our scheme is the first reforming defense per se which keeps the classifier structure untouched without appending any pre-processing head and is trained with clean images only. Extensive experiments on MNIST, CIFAR-10 and ImageNet demonstrate the strong defense of our method against various adversarial attacks.
Compressive Image Recovery Using Recurrent Generative Model
May 03, 2017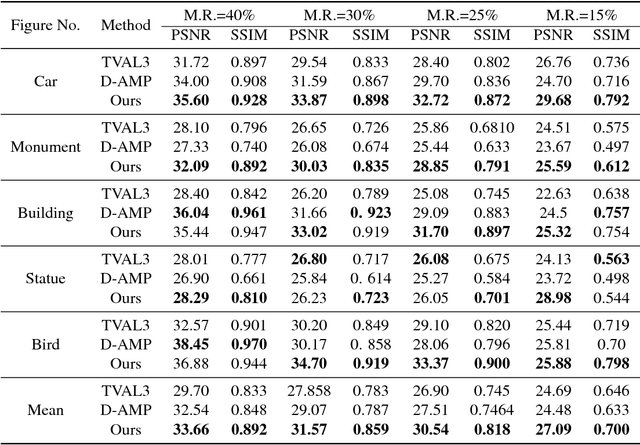



Reconstruction of signals from compressively sensed measurements is an ill-posed problem. In this paper, we leverage the recurrent generative model, RIDE, as an image prior for compressive image reconstruction. Recurrent networks can model long-range dependencies in images and hence are suitable to handle global multiplexing in reconstruction from compressive imaging. We perform MAP inference with RIDE using back-propagation to the inputs and projected gradient method. We propose an entropy thresholding based approach for preserving texture in images well. Our approach shows superior reconstructions compared to recent global reconstruction approaches like D-AMP and TVAL3 on both simulated and real data.
VDM-DA: Virtual Domain Modeling for Source Data-free Domain Adaptation
Mar 26, 2021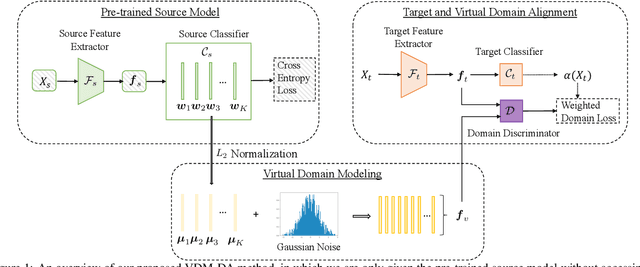
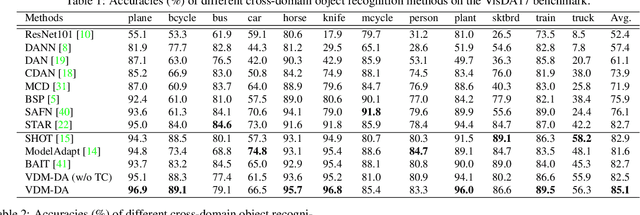
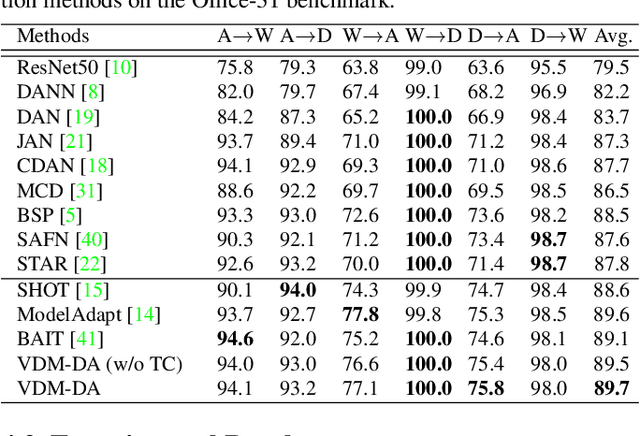
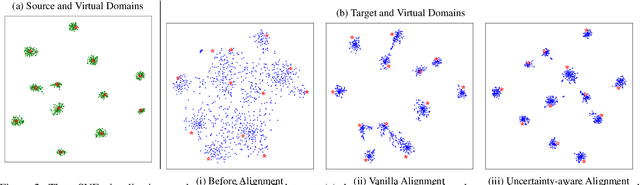
Domain adaptation aims to leverage a label-rich domain (the source domain) to help model learning in a label-scarce domain (the target domain). Most domain adaptation methods require the co-existence of source and target domain samples to reduce the distribution mismatch, however, access to the source domain samples may not always be feasible in the real world applications due to different problems (e.g., storage, transmission, and privacy issues). In this work, we deal with the source data-free unsupervised domain adaptation problem, and propose a novel approach referred to as Virtual Domain Modeling (VDM-DA). The virtual domain acts as a bridge between the source and target domains. On one hand, we generate virtual domain samples based on an approximated Gaussian Mixture Model (GMM) in the feature space with the pre-trained source model, such that the virtual domain maintains a similar distribution with the source domain without accessing to the original source data. On the other hand, we also design an effective distribution alignment method to reduce the distribution divergence between the virtual domain and the target domain by gradually improving the compactness of the target domain distribution through model learning. In this way, we successfully achieve the goal of distribution alignment between the source and target domains by training deep networks without accessing to the source domain data. We conduct extensive experiments on benchmark datasets for both 2D image-based and 3D point cloud-based cross-domain object recognition tasks, where the proposed method referred to Domain Adaptation with Virtual Domain Modeling (VDM-DA) achieves the state-of-the-art performances on all datasets.
Prediction of low-keV monochromatic images from polyenergetic CT scans for improved automatic detection of pulmonary embolism
Feb 23, 2021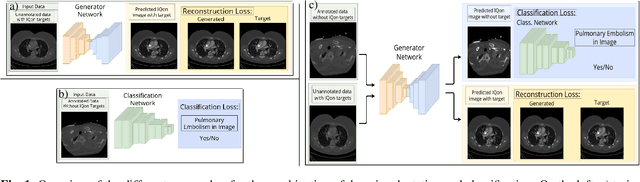
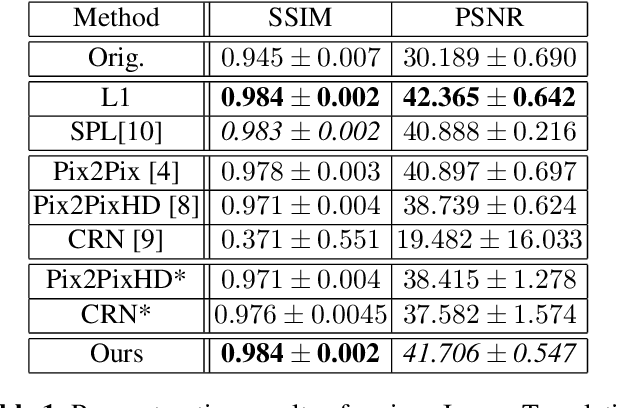
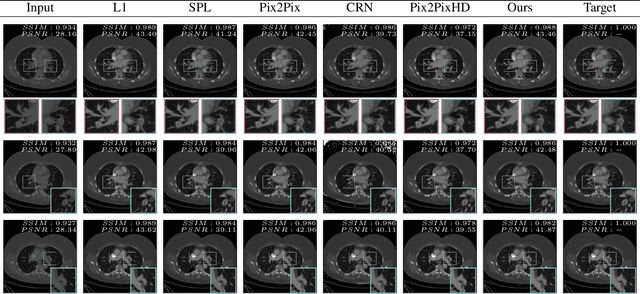

Detector-based spectral computed tomography is a recent dual-energy CT (DECT) technology that offers the possibility of obtaining spectral information. From this spectral data, different types of images can be derived, amongst others virtual monoenergetic (monoE) images. MonoE images potentially exhibit decreased artifacts, improve contrast, and overall contain lower noise values, making them ideal candidates for better delineation and thus improved diagnostic accuracy of vascular abnormalities. In this paper, we are training convolutional neural networks~(CNN) that can emulate the generation of monoE images from conventional single energy CT acquisitions. For this task, we investigate several commonly used image-translation methods. We demonstrate that these methods while creating visually similar outputs, lead to a poorer performance when used for automatic classification of pulmonary embolism (PE). We expand on these methods through the use of a multi-task optimization approach, under which the networks achieve improved classification as well as generation results, as reflected by PSNR and SSIM scores. Further, evaluating our proposed framework on a subset of the RSNA-PE challenge data set shows that we are able to improve the Area under the Receiver Operating Characteristic curve (AuROC) in comparison to a na\"ive classification approach from 0.8142 to 0.8420.
One-Shot Object Localization in Medical Images based on Relative Position Regression
Dec 13, 2020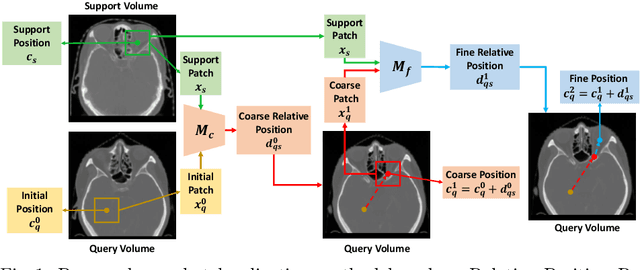
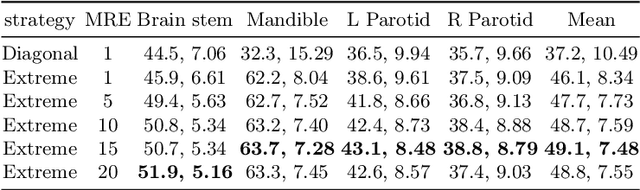
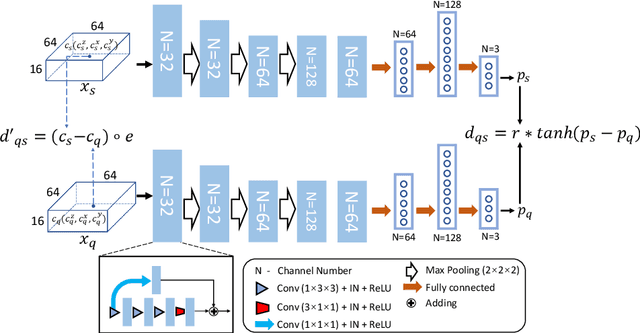
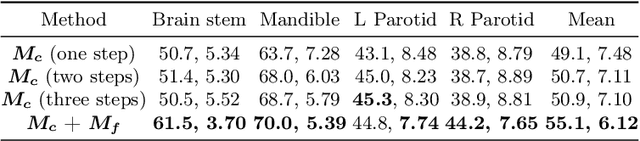
Deep learning networks have shown promising performance for accurate object localization in medial images, but require large amount of annotated data for supervised training, which is expensive and expertise burdensome. To address this problem, we present a one-shot framework for organ and landmark localization in volumetric medical images, which does not need any annotation during the training stage and could be employed to locate any landmarks or organs in test images given a support (reference) image during the inference stage. Our main idea comes from that tissues and organs from different human bodies have a similar relative position and context. Therefore, we could predict the relative positions of their non-local patches, thus locate the target organ. Our framework is composed of three parts: (1) A projection network trained to predict the 3D offset between any two patches from the same volume, where human annotations are not required. In the inference stage, it takes one given landmark in a reference image as a support patch and predicts the offset from a random patch to the corresponding landmark in the test (query) volume. (2) A coarse-to-fine framework contains two projection networks, providing more accurate localization of the target. (3) Based on the coarse-to-fine model, we transfer the organ boundingbox (B-box) detection to locating six extreme points along x, y and z directions in the query volume. Experiments on multi-organ localization from head-and-neck (HaN) CT volumes showed that our method acquired competitive performance in real time, which is more accurate and 10^5 times faster than template matching methods with the same setting. Code is available: https://github.com/LWHYC/RPR-Loc.
Pixel-Wise PolSAR Image Classification via a Novel Complex-Valued Deep Fully Convolutional Network
Sep 29, 2019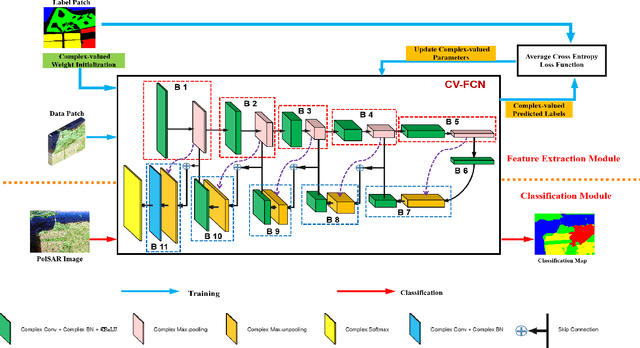
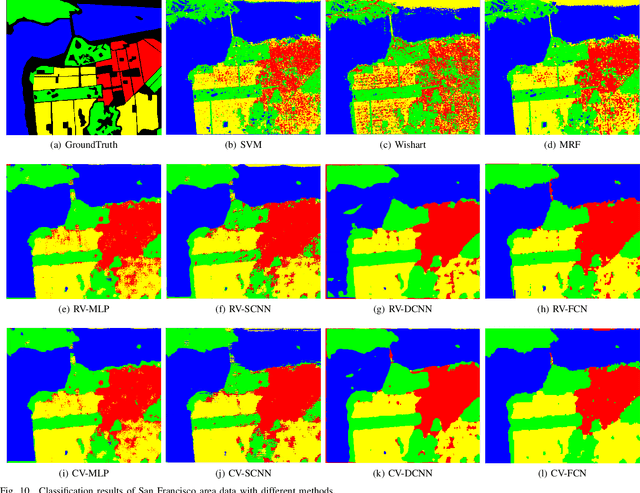
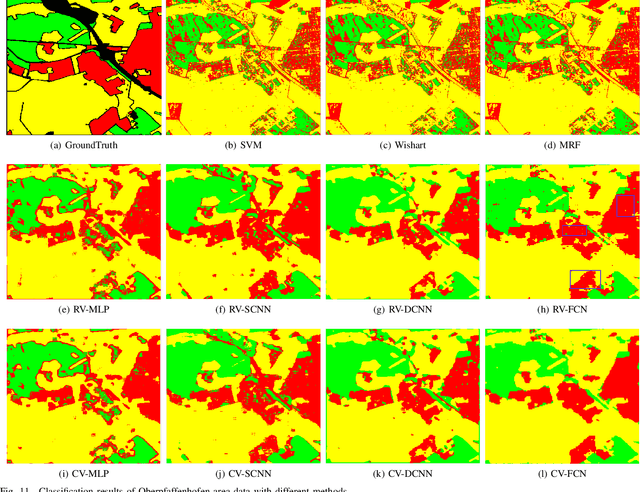
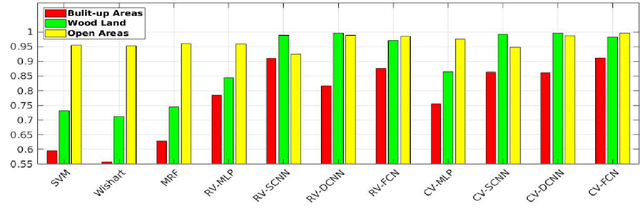
Although complex-valued (CV) neural networks have shown better classification results compared to their real-valued (RV) counterparts for polarimetric synthetic aperture radar (PolSAR) classification, the extension of pixel-level RV networks to the complex domain has not yet thoroughly examined. This paper presents a novel complex-valued deep fully convolutional neural network (CV-FCN) designed for PolSAR image classification. Specifically, CV-FCN uses PolSAR CV data that includes the phase information and utilizes the deep FCN architecture that performs pixel-level labeling. It integrates the feature extraction module and the classification module in a united framework. Technically, for the particularity of PolSAR data, a dedicated complex-valued weight initialization scheme is defined to initialize CV-FCN. It considers the distribution of polarization data to conduct CV-FCN training from scratch in an efficient and fast manner. CV-FCN employs a complex downsampling-then-upsampling scheme to extract dense features. To enrich discriminative information, multi-level CV features that retain more polarization information are extracted via the complex downsampling scheme. Then, a complex upsampling scheme is proposed to predict dense CV labeling. It employs complex max-unpooling layers to greatly capture more spatial information for better robustness to speckle noise. In addition, to achieve faster convergence and obtain more precise classification results, a novel average cross-entropy loss function is derived for CV-FCN optimization. Experiments on real PolSAR datasets demonstrate that CV-FCN achieves better classification performance than other state-of-art methods.
Semi-supervised Left Atrium Segmentation with Mutual Consistency Training
Mar 04, 2021
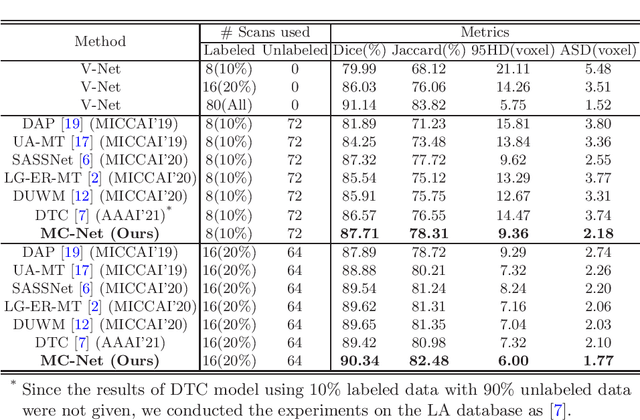
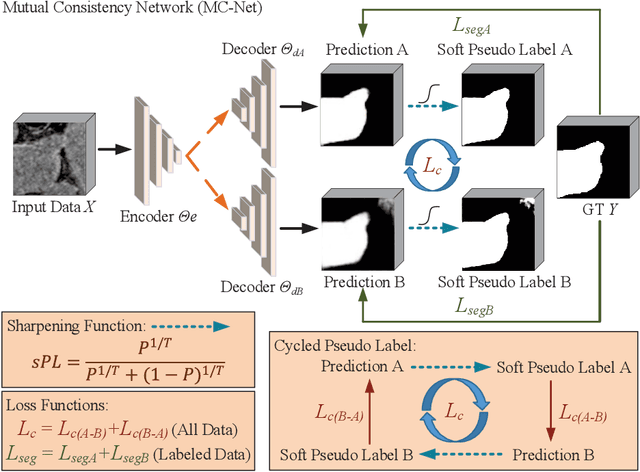
Semi-supervised learning has attracted great attention in the field of machine learning, especially for medical image segmentation tasks, since it alleviates the heavy burden of collecting abundant densely annotated data for training. However, most of existing methods underestimate the importance of challenging regions (e.g. small branches or blurred edges) during training. We believe that these unlabeled regions may contain more crucial information to minimize the uncertainty prediction for the model and should be emphasized in the training process. Therefore, in this paper, we propose a novel Mutual Consistency Network (MC-Net) for semi-supervised left atrium segmentation from 3D MR images. Particularly, our MC-Net consists of one encoder and two slightly different decoders, and the prediction discrepancies of two decoders are transformed as an unsupervised loss by our designed cycled pseudo label scheme to encourage mutual consistency. Such mutual consistency encourages the two decoders to have consistent and low-entropy predictions and enables the model to gradually capture generalized features from these unlabeled challenging regions. We evaluate our MC-Net on the public Left Atrium (LA) database and it obtains impressive performance gains by exploiting the unlabeled data effectively. Our MC-Net outperforms six recent semi-supervised methods for left atrium segmentation, and sets the new state-of-the-art performance on the LA database.
A survey on Kornia: an Open Source Differentiable Computer Vision Library for PyTorch
Sep 21, 2020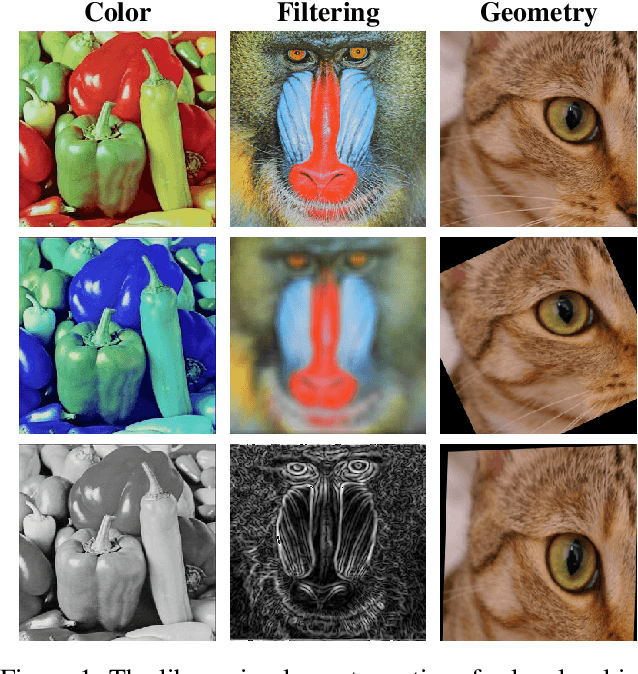

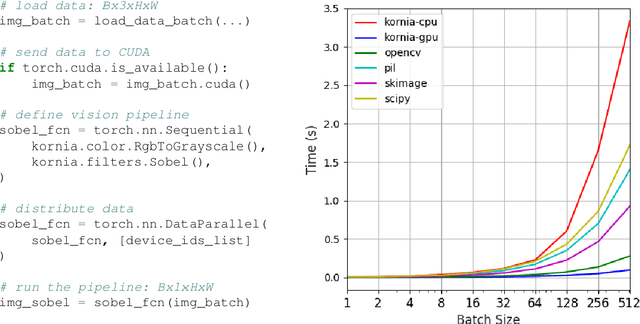
This work presents Kornia, an open source computer vision library built upon a set of differentiable routines and modules that aims to solve generic computer vision problems. The package uses PyTorch as its main backend, not only for efficiency but also to take advantage of the reverse auto-differentiation engine to define and compute the gradient of complex functions. Inspired by OpenCV, Kornia is composed of a set of modules containing operators that can be integrated into neural networks to train models to perform a wide range of operations including image transformations,camera calibration, epipolar geometry, and low level image processing techniques, such as filtering and edge detection that operate directly on high dimensional tensor representations on graphical processing units, generating faster systems. Examples of classical vision problems implemented using our framework are provided including a benchmark comparing to existing vision libraries.
Power-SLIC: Diagram-based superpixel generation
Dec 22, 2020


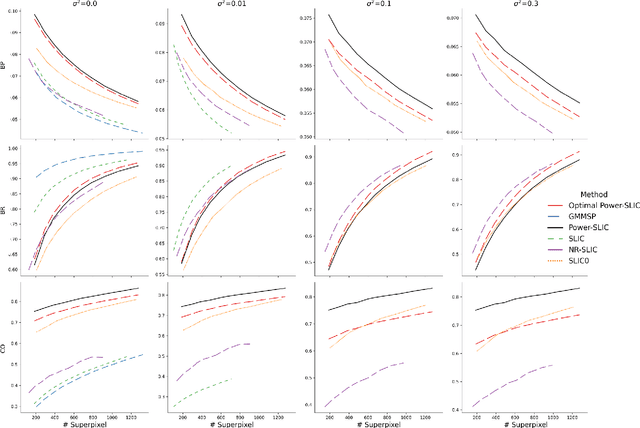
Superpixel algorithms, which group pixels similar in color and other low-level properties, are increasingly used for pre-processing in image segmentation. Commonly important criteria for the computation of superpixels are boundary adherence, speed, and regularity. Boundary adherence and regularity are typically contradictory goals. Most recent algorithms have focused on improving boundary adherence. Motivated by improving superpixel regularity, we propose a diagram-based superpixel generation method called Power-SLIC. On the BSDS500 data set, Power-SLIC outperforms other state-of-the-art algorithms in terms of compactness and boundary precision, and its boundary adherence is the most robust against varying levels of Gaussian noise. In terms of speed, Power-SLIC is competitive with SLIC.