 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Novel Deep Learning Architecture for Testis Histology Image Classification
Jul 18, 2017
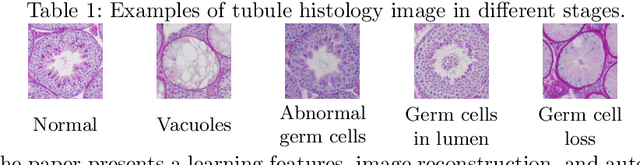
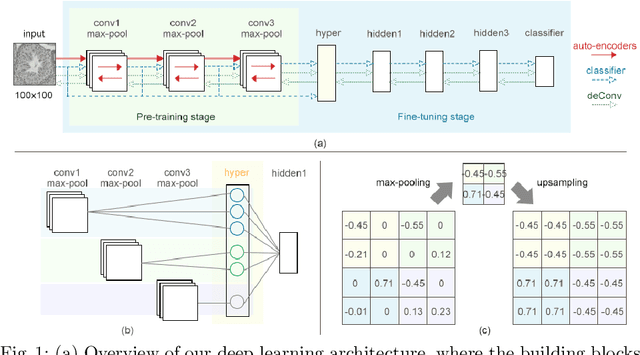
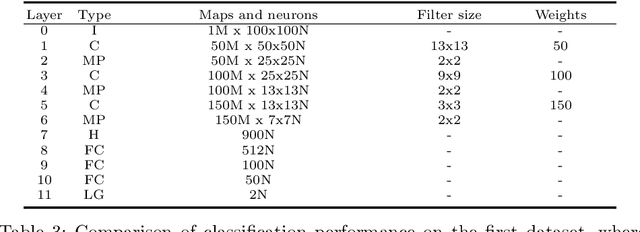
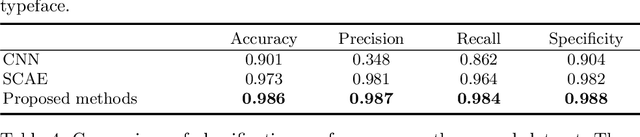
Unlike other histology analysis, classification of tubule status in testis histology is very challenging due to their high similarity of texture and shape. Traditional deep learning networks have difficulties to capture nuance details among different tubule categories. In this paper, we propose a novel deep learning architecture for feature learning, image classification, and image reconstruction. It is based on stacked auto-encoders with an additional layer, called a hyperlayer, which is created to capture features of an image at different layers in the network. This addition effectively combines features at different scales and thus provides a more complete profile for further classification. Evaluation is performed on a set of 10,542 tubule image patches. We demonstrate our approach with two experiments on two different subsets of the dataset. The results show that the features learned from our architecture achieve more than 98% accuracy and represent an improvement over traditional deep network architectures.
Semi-Supervised Action Recognition with Temporal Contrastive Learning
Feb 04, 2021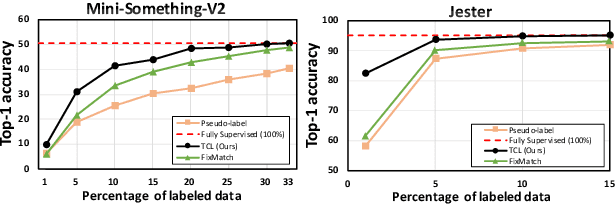
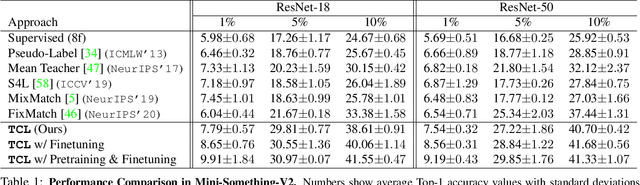
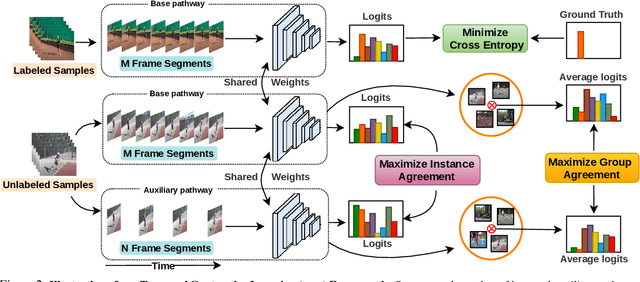
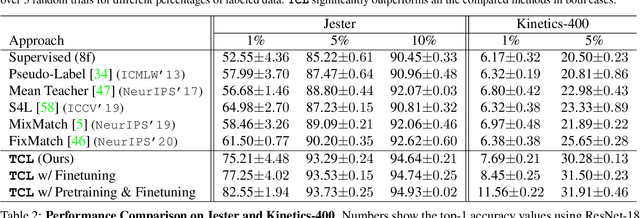
Learning to recognize actions from only a handful of labeled videos is a challenging problem due to the scarcity of tediously collected activity labels. We approach this problem by learning a two-pathway temporal contrastive model using unlabeled videos at two different speeds leveraging the fact that changing video speed does not change an action. Specifically, we propose to maximize the similarity between encoded representations of the same video at two different speeds as well as minimize the similarity between different videos played at different speeds. This way we use the rich supervisory information in terms of 'time' that is present in otherwise unsupervised pool of videos. With this simple yet effective strategy of manipulating video playback rates, we considerably outperform video extensions of sophisticated state-of-the-art semi-supervised image recognition methods across multiple diverse benchmark datasets and network architectures. Interestingly, our proposed approach benefits from out-of-domain unlabeled videos showing generalization and robustness. We also perform rigorous ablations and analysis to validate our approach.
Deep learning-based synthetic-CT generation in radiotherapy and PET: a review
Feb 04, 2021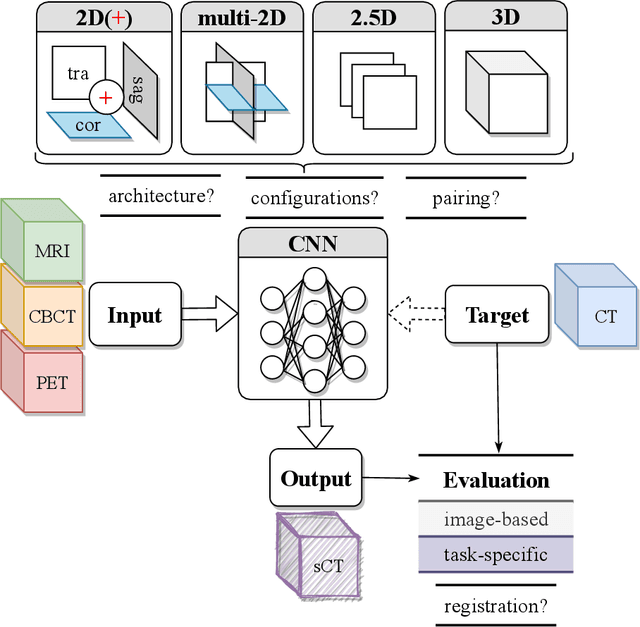

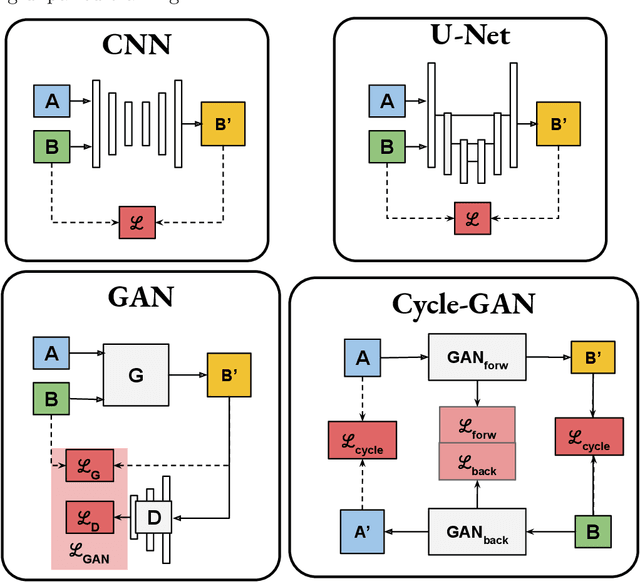
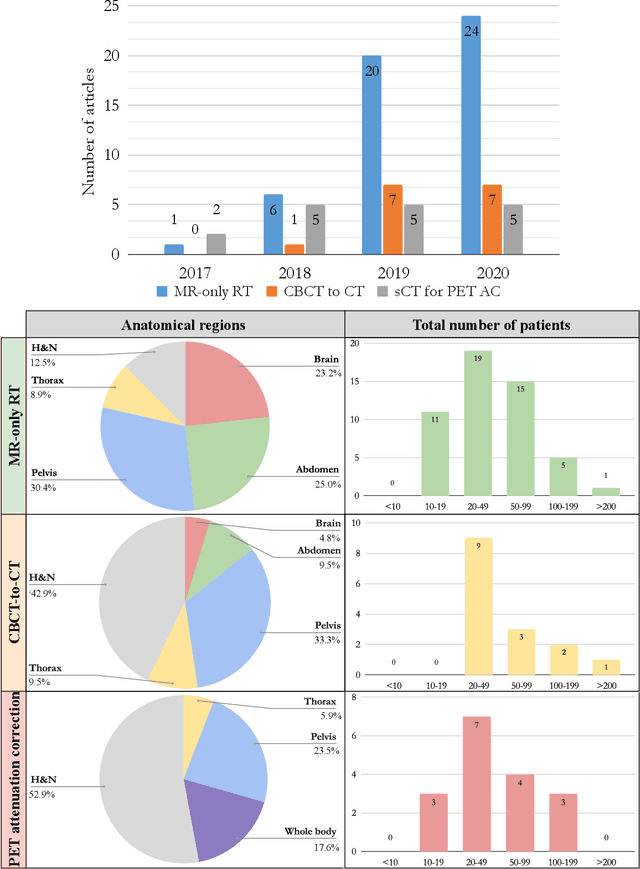
Recently, deep learning (DL)-based methods for the generation of synthetic computed tomography (sCT) have received significant research attention as an alternative to classical ones. We present here a systematic review of these methods by grouping them into three categories, according to their clinical applications: I) to replace CT in magnetic resonance (MR)-based treatment planning, II) facilitate cone-beam computed tomography (CBCT)-based image-guided adaptive radiotherapy, and III) derive attenuation maps for the correction of Positron Emission Tomography (PET). Appropriate database searching was performed on journal articles published between January 2014 and December 2020. The DL methods' key characteristics were extracted from each eligible study, and a comprehensive comparison among network architectures and metrics was reported. A detailed review of each category was given, highlighting essential contributions, identifying specific challenges, and summarising the achievements. Lastly, the statistics of all the cited works from various aspects were analysed, revealing the popularity and future trends, and the potential of DL-based sCT generation. The current status of DL-based sCT generation was evaluated, assessing the clinical readiness of the presented methods.
Pixel-Wise PolSAR Image Classification via a Novel Complex-Valued Deep Fully Convolutional Network
Sep 29, 2019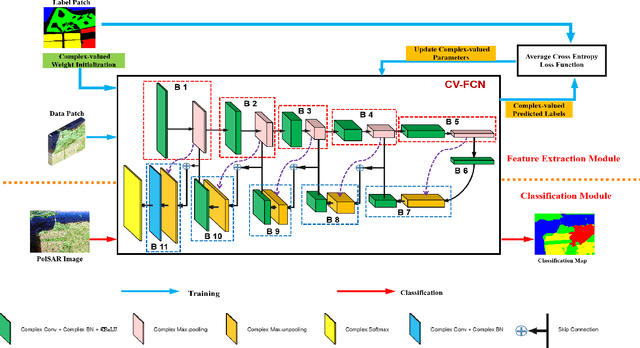
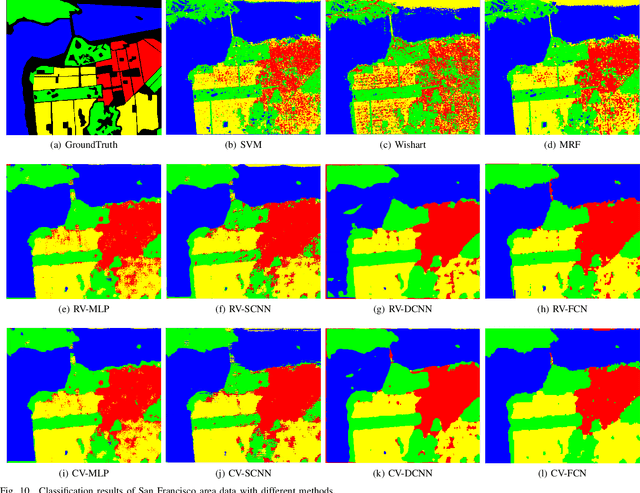
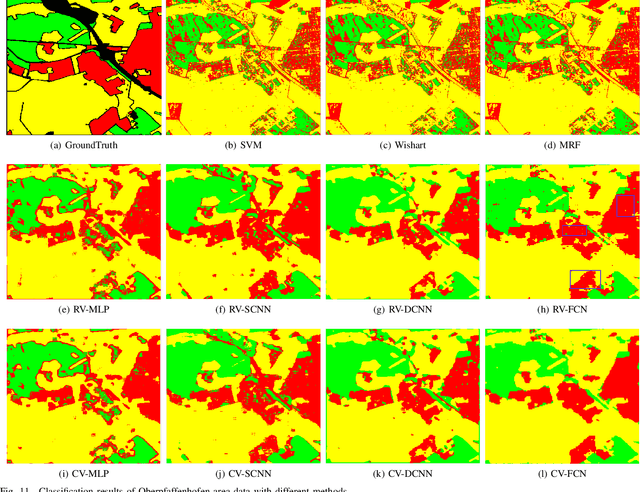
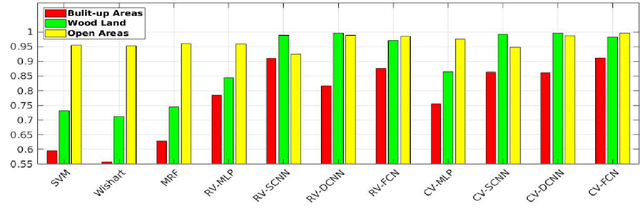
Although complex-valued (CV) neural networks have shown better classification results compared to their real-valued (RV) counterparts for polarimetric synthetic aperture radar (PolSAR) classification, the extension of pixel-level RV networks to the complex domain has not yet thoroughly examined. This paper presents a novel complex-valued deep fully convolutional neural network (CV-FCN) designed for PolSAR image classification. Specifically, CV-FCN uses PolSAR CV data that includes the phase information and utilizes the deep FCN architecture that performs pixel-level labeling. It integrates the feature extraction module and the classification module in a united framework. Technically, for the particularity of PolSAR data, a dedicated complex-valued weight initialization scheme is defined to initialize CV-FCN. It considers the distribution of polarization data to conduct CV-FCN training from scratch in an efficient and fast manner. CV-FCN employs a complex downsampling-then-upsampling scheme to extract dense features. To enrich discriminative information, multi-level CV features that retain more polarization information are extracted via the complex downsampling scheme. Then, a complex upsampling scheme is proposed to predict dense CV labeling. It employs complex max-unpooling layers to greatly capture more spatial information for better robustness to speckle noise. In addition, to achieve faster convergence and obtain more precise classification results, a novel average cross-entropy loss function is derived for CV-FCN optimization. Experiments on real PolSAR datasets demonstrate that CV-FCN achieves better classification performance than other state-of-art methods.
Embedding based on function approximation for large scale image search
Apr 04, 2017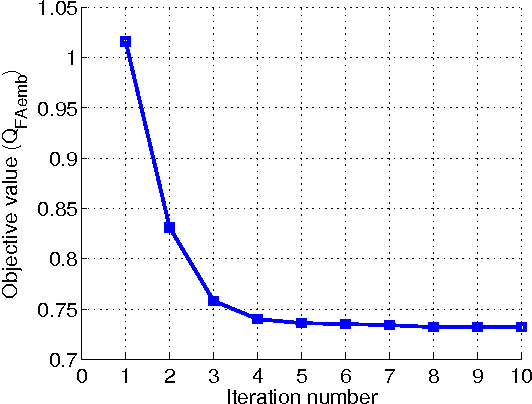


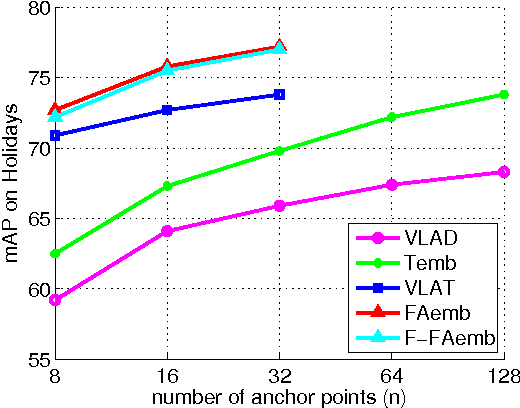
The objective of this paper is to design an embedding method that maps local features describing an image (e.g. SIFT) to a higher dimensional representation useful for the image retrieval problem. First, motivated by the relationship between the linear approximation of a nonlinear function in high dimensional space and the stateof-the-art feature representation used in image retrieval, i.e., VLAD, we propose a new approach for the approximation. The embedded vectors resulted by the function approximation process are then aggregated to form a single representation for image retrieval. Second, in order to make the proposed embedding method applicable to large scale problem, we further derive its fast version in which the embedded vectors can be efficiently computed, i.e., in the closed-form. We compare the proposed embedding methods with the state of the art in the context of image search under various settings: when the images are represented by medium length vectors, short vectors, or binary vectors. The experimental results show that the proposed embedding methods outperform existing the state of the art on the standard public image retrieval benchmarks.
Prediction of low-keV monochromatic images from polyenergetic CT scans for improved automatic detection of pulmonary embolism
Feb 23, 2021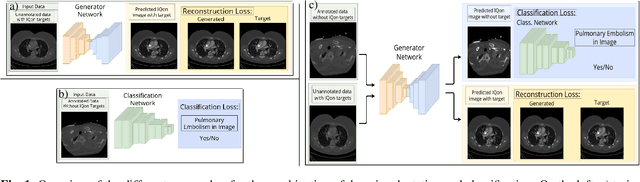
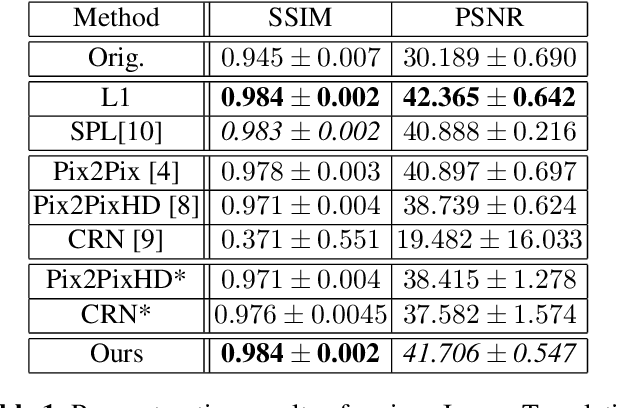
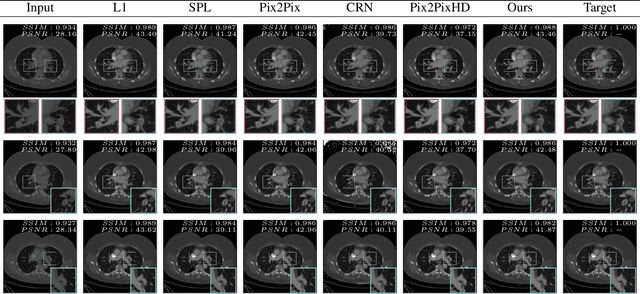

Detector-based spectral computed tomography is a recent dual-energy CT (DECT) technology that offers the possibility of obtaining spectral information. From this spectral data, different types of images can be derived, amongst others virtual monoenergetic (monoE) images. MonoE images potentially exhibit decreased artifacts, improve contrast, and overall contain lower noise values, making them ideal candidates for better delineation and thus improved diagnostic accuracy of vascular abnormalities. In this paper, we are training convolutional neural networks~(CNN) that can emulate the generation of monoE images from conventional single energy CT acquisitions. For this task, we investigate several commonly used image-translation methods. We demonstrate that these methods while creating visually similar outputs, lead to a poorer performance when used for automatic classification of pulmonary embolism (PE). We expand on these methods through the use of a multi-task optimization approach, under which the networks achieve improved classification as well as generation results, as reflected by PSNR and SSIM scores. Further, evaluating our proposed framework on a subset of the RSNA-PE challenge data set shows that we are able to improve the Area under the Receiver Operating Characteristic curve (AuROC) in comparison to a na\"ive classification approach from 0.8142 to 0.8420.
Fast and Incremental Loop Closure Detection with Deep Features and Proximity Graphs
Sep 29, 2020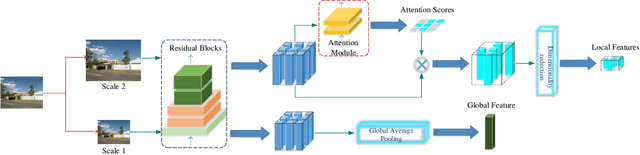

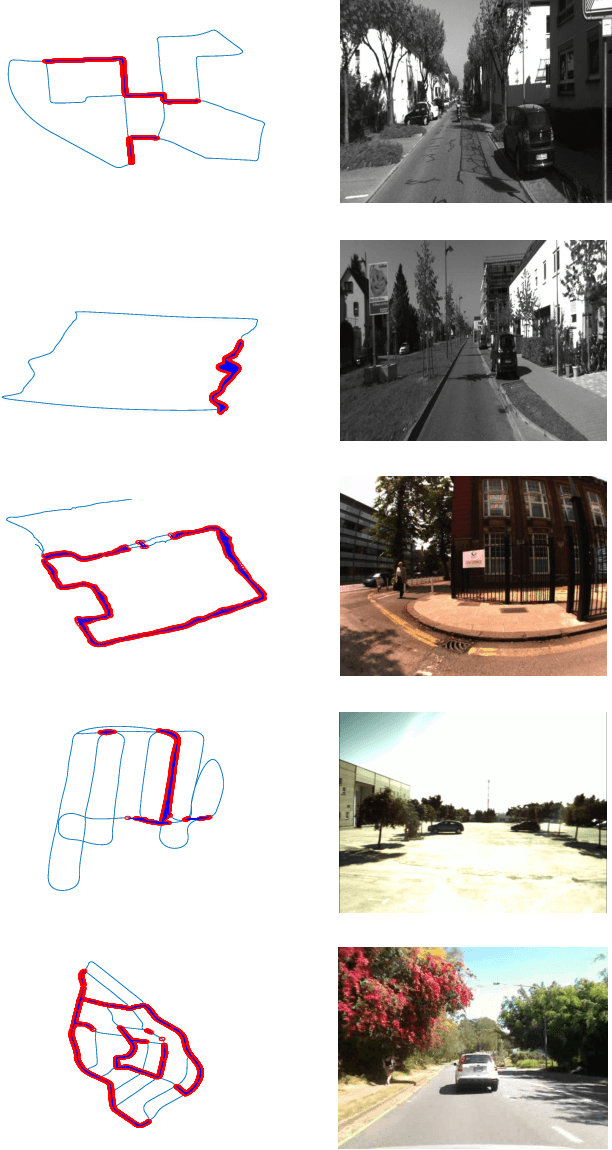
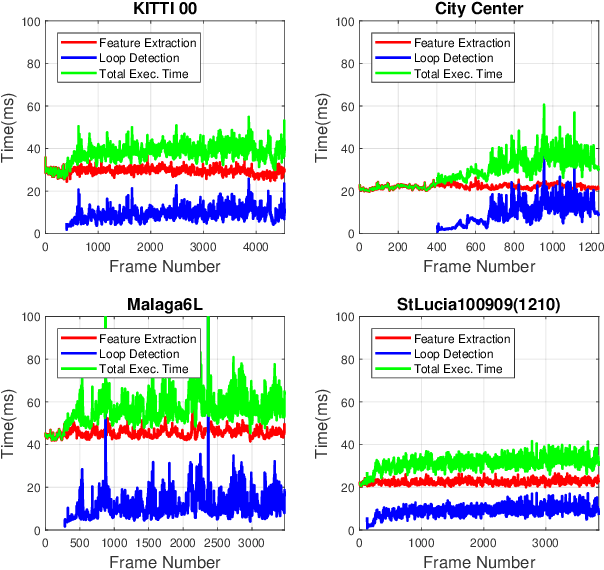
In recent years, methods concerning the place recognition task have been extensively examined from the robotics community within the scope of simultaneous localization and mapping applications. In this article, an appearance-based loop closure detection pipeline is proposed, entitled "FILD++" (Fast and Incremental Loop closure Detection). When the incoming camera observation arrives, global and local visual features are extracted through two passes of a single convolutional neural network. Subsequently, a modified hierarchical-navigable small-world graph incrementally generates a visual database that represents the robot's traversed path based on global features. Given the query sensor measurement, similar locations from the trajectory are retrieved using these representations, while an image-to-image pairing is further evaluated thanks to the spatial information provided by the local features. Exhaustive experiments on several publicly-available datasets exhibit the system's high performance and low execution time compared to other contemporary state-of-the-art pipelines.
Semi-supervised Left Atrium Segmentation with Mutual Consistency Training
Mar 04, 2021
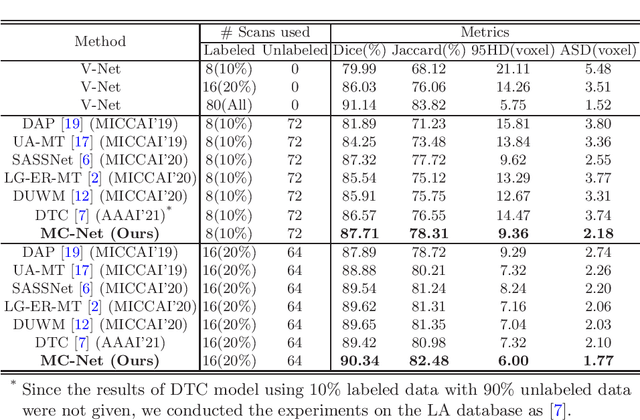
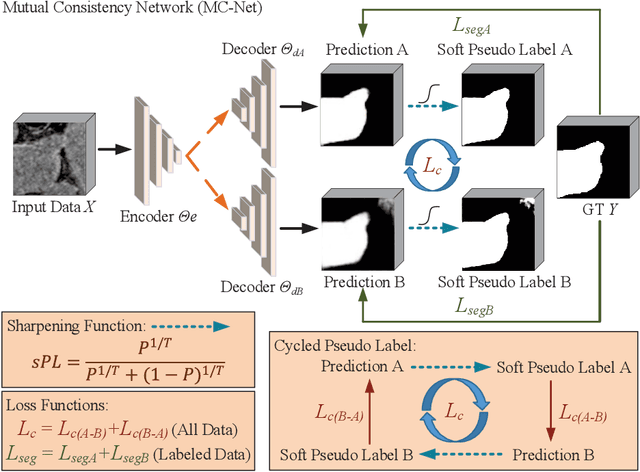
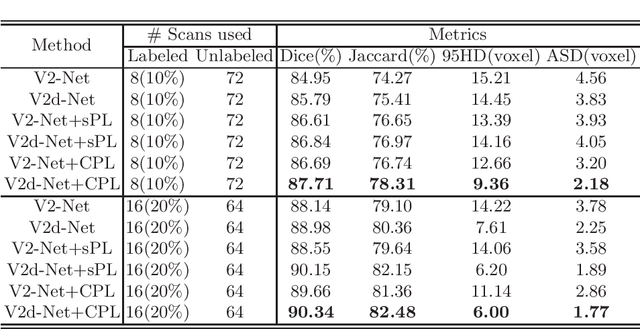
Semi-supervised learning has attracted great attention in the field of machine learning, especially for medical image segmentation tasks, since it alleviates the heavy burden of collecting abundant densely annotated data for training. However, most of existing methods underestimate the importance of challenging regions (e.g. small branches or blurred edges) during training. We believe that these unlabeled regions may contain more crucial information to minimize the uncertainty prediction for the model and should be emphasized in the training process. Therefore, in this paper, we propose a novel Mutual Consistency Network (MC-Net) for semi-supervised left atrium segmentation from 3D MR images. Particularly, our MC-Net consists of one encoder and two slightly different decoders, and the prediction discrepancies of two decoders are transformed as an unsupervised loss by our designed cycled pseudo label scheme to encourage mutual consistency. Such mutual consistency encourages the two decoders to have consistent and low-entropy predictions and enables the model to gradually capture generalized features from these unlabeled challenging regions. We evaluate our MC-Net on the public Left Atrium (LA) database and it obtains impressive performance gains by exploiting the unlabeled data effectively. Our MC-Net outperforms six recent semi-supervised methods for left atrium segmentation, and sets the new state-of-the-art performance on the LA database.
Learning to Model and Ignore Dataset Bias with Mixed Capacity Ensembles
Nov 07, 2020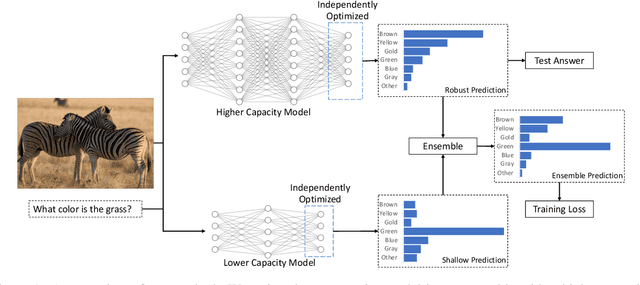
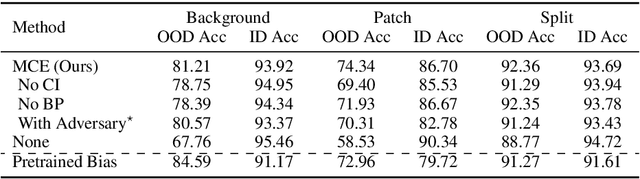


Many datasets have been shown to contain incidental correlations created by idiosyncrasies in the data collection process. For example, sentence entailment datasets can have spurious word-class correlations if nearly all contradiction sentences contain the word "not", and image recognition datasets can have tell-tale object-background correlations if dogs are always indoors. In this paper, we propose a method that can automatically detect and ignore these kinds of dataset-specific patterns, which we call dataset biases. Our method trains a lower capacity model in an ensemble with a higher capacity model. During training, the lower capacity model learns to capture relatively shallow correlations, which we hypothesize are likely to reflect dataset bias. This frees the higher capacity model to focus on patterns that should generalize better. We ensure the models learn non-overlapping approaches by introducing a novel method to make them conditionally independent. Importantly, our approach does not require the bias to be known in advance. We evaluate performance on synthetic datasets, and four datasets built to penalize models that exploit known biases on textual entailment, visual question answering, and image recognition tasks. We show improvement in all settings, including a 10 point gain on the visual question answering dataset.
A Fully Progressive Approach to Single-Image Super-Resolution
Apr 10, 2018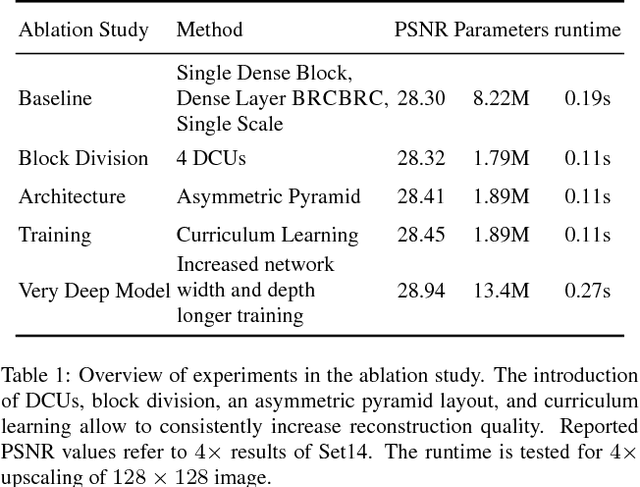
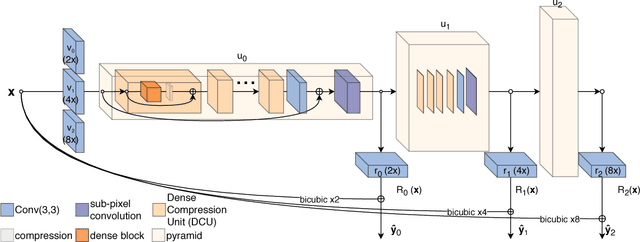

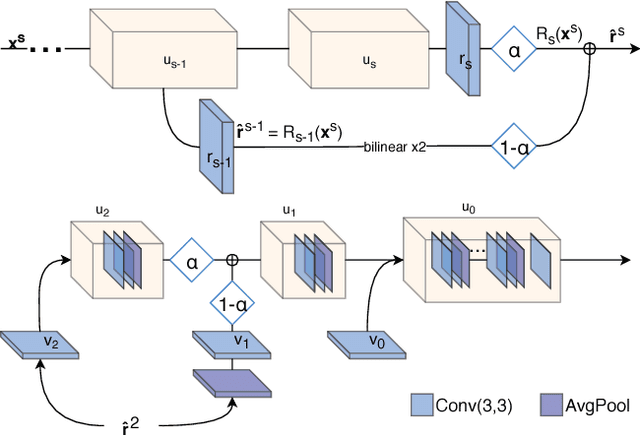
Recent deep learning approaches to single image super-resolution have achieved impressive results in terms of traditional error measures and perceptual quality. However, in each case it remains challenging to achieve high quality results for large upsampling factors. To this end, we propose a method (ProSR) that is progressive both in architecture and training: the network upsamples an image in intermediate steps, while the learning process is organized from easy to hard, as is done in curriculum learning. To obtain more photorealistic results, we design a generative adversarial network (GAN), named ProGanSR, that follows the same progressive multi-scale design principle. This not only allows to scale well to high upsampling factors (e.g., 8x) but constitutes a principled multi-scale approach that increases the reconstruction quality for all upsampling factors simultaneously. In particular ProSR ranks 2nd in terms of SSIM and 4th in terms of PSNR in the NTIRE2018 SISR challenge [34]. Compared to the top-ranking team, our model is marginally lower, but runs 5 times faster.